面试官最爱问的epoll:一文彻底搞懂其原理、模式与代码实现!
本文深入解析了Linux的I/O多路复用机制epoll,通过餐厅服务员的类比形象说明其高效性。文章首先介绍了网络I/O的基本概念和模型,包括阻塞/非阻塞、同步/异步的区别。重点阐述了epoll的工作原理,对比了其与select/poll的性能优势:epoll采用事件通知机制,仅关注活跃连接,支持海量并发。详细说明了epoll的三个核心API(create/ctl/wait)和两种触发模式(水平触发
学不会epoll?看完这篇,你就是朋友圈最懂I/O多路复用的人!
一、背景:网络 IO 概述
在进行网络编程时,理解不同的 I/O 模型很重要,它们直接影响着应用程序的性能和可伸缩性。
网络 IO,会涉及到两个系统对象,一个是用户空间调用 IO 的进程或者线程,另一个是内核空间的内核系统。
- 用户空间进程/线程: 这是发起 I/O 操作(例如
read, write)的应用程序部分。 - 内核空间: 这是操作系统的核心,负责实际的数据传输和管理。
当用户空间的进程或线程发起一个 I/O 操作时(例如 read),它会经历两个阶段:
- 等待数据准备就绪;
- 将数据从内核拷贝到进程或者线程中。
由于这两个阶段存在不同的处理方式,因此衍生出了多种网络 I/O 模型。理解这些模型是编写高性能网络应用程序的基础。
网络 I/O 的核心概念:阻塞、非阻塞、同步和异步。理解网络 I/O 模型,首先需要区分这几个关键概念:
-
阻塞 I/O: 进程/线程发起 I/O 操作后,会被挂起(暂停执行),直到数据准备就绪并拷贝完成后才会被唤醒。
-
非阻塞 I/O: 进程/线程发起 I/O 操作后,立即返回,无论数据是否准备就绪。如果数据未准备好,会返回一个错误码,应用程序需要轮询检查数据是否可用。
-
同步 I/O: 进程/线程需要主动参与到实际的数据传输过程中,无论是等待数据准备还是拷贝数据,都需要进程/线程参与。
-
异步 I/O: 进程/线程发起 I/O 操作后,无需等待,内核会在数据准备好并拷贝完成后通知进程/线程。整个过程,进程/线程不需要主动参与。
本文主要讲解两个核心内容:epoll是什么?epoll的网络编程代码如何实现。
学习建议:理论与实践相结合。在学习网络编程的过程中,切记要将理论知识与实践操作相结合。仅仅阅读文档和博客是远远不够的,只有通过亲自动手编写代码、调试程序,才能真正理解 I/O 模型的原理和应用。特别是像 epoll 和 Reactor 这样的高级技术,更需要在实际项目中反复实践,才能掌握其精髓。
小贴士:技术领域中的很多概念都具有通用性,但往往在具体的实现细节上有所差异。只有通过深入的代码理解,才能避免在技术表达上的不准确,从而更清晰地阐述问题和解决方案。 建议通过实际的代码示例、调试过程,深入理解 I/O 模型的内部机制。
在学习过程中,不要仅阅读,特别是像这种网络开发特别需要动手实践,一定要自己动手实现一遍,写一遍代码。看得再多,也不如自己动手调试一遍来得深刻。
很多东西理论都是通用的,很多人在技术表达的时候不是特别精准,就是因为代码理解上不够深。这就会出现一个现象:好像很多东西都懂,这个也见过、那个也见过,但仔细一想又不是很懂。
二、epoll 是什么?
Linux在早期只适合做嵌入式(大概2007年之前),比如手机、公共设备等嵌入式产品。但是,到了现在,情况就有所不同,比如现在的云主机基本都是Linux系统(当然,偶尔有些会有windows可供选择)。后来因为epoll的出现,Linux才慢慢的支持服务器,在服务器领域有自己的一部分市场。因此,epoll 是非常重要的。
epoll 是 Linux 内核提供的一种 I/O 多路复用机制,用于高效地监控大量文件描述符(file descriptor, fd)上的事件,例如可读、可写、错误等。 它允许一个进程同时监控多个文件描述符,并在某个或某些文件描述符就绪时,通知进程。 这使得单线程的程序可以同时处理多个网络连接或其他 I/O 事件,从而提高程序的并发性能和资源利用率。
可以理解为: 一个餐厅服务员,需要负责多个桌子的客人。
-
传统方法 (如 select/poll): 需要轮流查看每一张桌子,看看有没有客人需要服务(例如,举手示意)。 这很浪费时间,特别是当只有少数几张桌子需要服务的时候。 这种方式效率很低,需要轮询所有文件描述符,效率随文件描述符的数量线性下降。
-
epoll: 给每一张桌子都安装一个指示灯,客人需要服务时,按下按钮,指示灯就会亮起来。 你只需要盯着这些指示灯,一旦有灯亮了,你就知道哪张桌子需要服务了。 这种方式不需要轮询所有桌子,只需要关注有指示灯亮的桌子,效率更高。
主要特点和优势:
epoll不像select和poll那样需要轮询所有文件描述符,而是通过事件通知机制,只有当文件描述符上有事件发生时才会通知进程。- 每次取就绪集合的位置固定。并且一定程度上实现异步解耦。
epoll在处理大量文件描述符时性能更高,能够有效地支持数万、数十万甚至数百万级别的并发连接。 其性能不会随着文件描述符数量的增加而显著下降。epoll使用了内核中的红黑树和就绪列表 等高效数据结构,优化了事件的存储和查找。
epoll 提供了三个主要的 API 函数:
epoll_create(): 创建一个epoll实例,返回一个文件描述符,用于后续的操作。epoll_ctl(): 用于向epoll实例中添加、修改或删除要监控的文件描述符及其事件。epoll_wait(): 阻塞等待,直到有一个或多个文件描述符上有事件发生,然后返回就绪的文件描述符列表。
函数原型:
#include <sys/epoll.h>
int epoll_create(int size);
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);
为什么 select 和 poll 只要 1 个接口函数就可以了,到epoll这却需要 3 个接口函数?
主要是因为它们的设计哲学和实现机制不同。select 和 poll 只需要一个接口函数,是因为它们的设计比较简单,都是基于轮询的。 而 epoll 为了实现高性能,采用了复杂的设计,需要三个 API 函数来完成不同的任务:创建 epoll 实例、控制 epoll 实例、等待事件发生。 这种设计使得 epoll 能够在高并发场景下提供更好的性能。 可以认为 epoll_create 负责初始化数据结构,epoll_ctl 负责管理需要监控的fd,而 epoll_wait 负责等待事件发生并返回结果。
比如有一个 server,它监听在某个端口(比如 9999端口),监听的也有一个fd;现在有客户端 A 连接到服务器,此时就会产生一个fd专门为客户端A服务;与此同时,又有两个客户端B、C连接到server,同样也会分别产生一个fd专门为它们服务。
epoll_wait() 提供了两种主要的工作模式,以及一种较少使用的模式:
-
默认的水平触发(Level Triggered,LT): 当文件描述符上有数据可读/可写时,
epoll_wait()会持续返回该文件描述符,直到数据被完全读取/写入。只要条件满足(缓冲区有数据未读,或者可以写入数据),就会一直通知;类似于水面,只要水面超过某个高度,警报就会一直响起。优点是 保证了数据不会丢失,实现简单,容错性好。 缺点: 如果应用程序没有及时处理就绪事件,epoll_wait()可能会频繁地返回同一个文件描述符,造成忙等待,降低效率。 -
边缘触发(Edge Triggered,ET): 只有当文件描述符的状态发生变化时(例如,从不可读变为可读,或者从不可写变为可写),
epoll_wait()才会返回该文件描述符。只有在状态 改变 的时候才会通知一次;类似于开关,只有在开关状态发生变化的时候才会触发警报。优点: 效率更高,因为只有状态变化时才会通知。缺点: 需要应用程序一次性读取/写入所有的数据,否则可能会丢失事件。 实现复杂,需要更高的编程技巧,对程序员要求较高。 如果程序没有一次性读取所有数据,后续将不会再收到通知,导致数据丢失。 通常需要配合非阻塞 I/O 一起使用。 -
One Shot (EPOLLET | EPOLLONESHOT): 一个文件描述符只会被通知一次,即使事件仍然存在。 在处理完这个事件后,需要重新注册这个文件描述符才能再次接收事件。这个模式可以避免多个线程同时处理同一个文件描述符,从而减少锁的使用和提高性能。通常用于多线程/多进程环境下的并发控制。
注意一下epoll_wait的最后一个参数timeout,它的单位是毫秒(milliseconds)。
- 如果设置为
-1,则会阻塞,知道有事件就绪才会返回。 - 如果设置为
0,则会立即返回,不管有没有事件就绪。 - 如果设置大于
0的数(比如1000),如果在超时期间有事件就绪就会返回;如果一直没有事件就绪,则在超时后会返回。
要利用好epoll_wait的这个参数,有时可以用来作为计时器使用。
与其他 I/O 多路复用机制的比较 (select/poll):
(1)select:
- 时间复杂度为 O(n),需要轮询所有文件描述符。
- 支持的文件描述符数量有限制 (通常为 1024)。
- 每次调用都需要将文件描述符集合从用户空间拷贝到内核空间。
(2)poll:
- 与 select 类似,时间复杂度为 O(n),需要轮询所有文件描述符。
- 没有文件描述符数量的限制。
- 每次调用都需要将文件描述符集合从用户空间拷贝到内核空间。
(3)epoll:
- 不需要循环遍历所有的
fd。 - 时间复杂度为 O(1) (在事件就绪的情况下)。
- 支持海量连接。
- 只需要在开始时将文件描述符集合拷贝到内核空间,后续操作不需要重复拷贝。
epoll的适用场景:
- 高并发的网络服务器,例如 Web 服务器、游戏服务器等。
- 需要同时处理大量 I/O 事件的应用程序。
- 需要监控大量文件描述符的应用程序。
三、代码实现
3.1、初始化网络监听
首先初始化一个网络监听套接字(socket),绑定到指定端口并开始监听连接请求。
(1)创建套接字:调用 socket() 创建一个 TCP 套接字(AF_INET 表示 IPv4,SOCK_STREAM 表示面向连接的 TCP)。
int listenfd = socket(AF_INET, SOCK_STREAM, 0);
(2)设置地址结构:初始化 sockaddr_in 结构体,清零后设置协议族(AF_INET)、端口号(port 转换为网络字节序)和 IP 地址(INADDR_ANY 表示监听所有本地接口)。
struct sockaddr_in addr;
memset(&addr, 0, sizeof(addr));
addr.sin_family = AF_INET;
addr.sin_port = htons(port);
addr.sin_addr.s_addr = htonl(INADDR_ANY);
(3)绑定套接字:将套接字绑定到指定的地址和端口。
bind(listenfd, (struct sockaddr*)&addr, sizeof(addr))
(4)开始监听:将套接字设为监听状态,MAX_LISTEN 指定等待连接队列的最大长度。
listen(listenfd, MAX_LISTEN);
关键点:
- 错误处理:每一步都检查系统调用返回值,失败时打印错误信息(通过
strerror(errno))并清理资源。 - 资源管理:确保套接字在失败时被正确关闭。
- 网络字节序:
htons和htonl用于将主机字节序转换为网络字节序。 - 通过
INADDR_ANY监听所有可用网络接口。
这是初始化网络监听的核心部分,为后续的事件驱动(如 epoll/select)处理连接请求奠定基础。
初始化网络监听的完整代码如下:
bool initListen(short port)
{
int listenfd = socket(AF_INET, SOCK_STREAM, 0);
if (listenfd < 0) {
std::cerr << "create socket error: " << strerror(errno) << std::endl;
return false;
}
struct sockaddr_in addr;
memset(&addr, 0, sizeof(addr));
addr.sin_family = AF_INET;
addr.sin_port = htons(port);
addr.sin_addr.s_addr = htonl(INADDR_ANY);
if (bind(listenfd, (struct sockaddr*)&addr, sizeof(addr)) < 0) {
std::cerr << "bind socket error: " << strerror(errno) << std::endl;
closeSocket(_listenfd);
return false;
}
if (listen(listenfd, MAX_LISTEN) < 0) {
std::cerr << "listen socket error: " << strerror(errno) << std::endl;
closeSocket(listenfd);
return false;
}
std::cout << "listen on port: " << _port << std::endl;
return true;
}
3.2、监听 I/O 事件。
实现基于epoll的事件循环,主要用于监听文件描述符上的I/O事件。
首先调用epoll_create创建一个epoll实例,参数1是历史遗留值(内核会忽略)。
int epollfd = epoll_create(1);
epoll_create()的参数非常有意思:在 epoll_create() 的最初实现中,size 参数是作为内核预先分配内部数据结构空间的一个“提示”值。它告诉内核调用者预期会向 epoll 实例添加多少个文件描述符(前期是通过数组来保存就绪事件)。如果实际添加的文件描述符数量超过了这个提示值,内核会动态地分配更多的空间。
然而,自 Linux 内核 2.6.8 版本开始,这个 size 参数就被忽略了,不再作为内核预分配空间的依据。内核现在能够动态地调整所需的数据结构大小(使用了类似链表的数据结构保存就绪事件),无需这个提示。
尽管如此,size 参数仍然必须大于 0。这是为了确保向后兼容性,即使在较新的内核上运行为旧版本 epoll 编写的应用程序,也能正常工作。如果 size 参数不大于 0,epoll_create() 函数会返回错误 EINVAL (Invalid argument)。
SYSCALL_DEFINE1(epoll_create, int, size)
{
if (size <= 0)
return -EINVAL;
return sys_epoll_create1(0);
}
因此,虽然 size 参数在现代 Linux 内核中失去了其最初的意义,但它仍然是一个必需的参数,并且必须传入一个正整数,通常传入 1 即可满足要求。
值得注意的是,Linux 2.6.27 版本引入了 epoll_create1() 函数,这个函数取消了 size 参数,取而代之的是一个 flags 参数,用于指定额外的行为(例如 EPOLL_CLOEXEC)。如果 flags 为 0,epoll_create1() 的行为与 epoll_create() 相同,只是不再需要 size 参数。
其次,设置监听事件:初始化epoll_event结构体,指定监听EPOLLIN(可读事件),并关联到服务器的监听socket。
struct epoll_event ev;
ev.events = EPOLLIN; // 监听可读事件
ev.data.fd = _listenfd; // 关联的文件描述符(通常是监听socket)
然后,注册事件到epoll:调用epoll_ctl将要监听的fd添加到epoll监听列表中。
epoll_ctl(epollfd, EPOLL_CTL_ADD, listenfd, &ev);
最后,进入无限事件循环,调用epoll_wait阻塞等待事件发生(-1表示无限等待)。
struct epoll_event events[MAX_EVENT];
while(true) {
int nready = epoll_wait(epollfd, events, MAX_EVENT, -1);
if (nready < 0) {
std::cerr << "epoll_wait error: " << strerror(errno) << std::endl;
break;
}
for (int i = 0; i < nready; ++i) {
// TODO: handle events
}
}
因此,构建epoll的步骤如下:
-
epoll_create(1) / epoll_create1(0): 创建一个epoll实例,返回一个文件描述符,代表这个epoll实例。 -
epoll_ctl(EPOLL_CTL_ADD, listenfd, ...): 告诉epoll实例关注listenfd上的事件。 -
epoll_wait(...): 程序调用epoll_wait阻塞等待epoll实例通知它所监控的文件描述符上有事件发生。 -
客户端连接: 当有客户端连接到服务器时,
listenfd变为可读,这意味着有新的连接请求可以接受。 -
epoll通知: 由于listenfd已经被注册到epoll实例,并且listenfd上发生了EPOLLIN事件(可读),epoll_wait就会返回,并告知用户程序listenfd可读。
代码:
bool epollRun()
{
int epollfd = epoll_create(1);
if (epollfd < 0) {
std::cerr << "create epoll error: " << strerror(errno) << std::endl;
return false;
}
struct epoll_event ev;
ev.events = EPOLLIN;
ev.data.fd = _listenfd;
if (epoll_ctl(epollfd, EPOLL_CTL_ADD, _listenfd, &ev) < 0) {
std::cerr << "epoll_ctl error: " << strerror(errno) << std::endl;
return false;
}
struct epoll_event events[MAX_EVENT];
while(true) {
int nready = epoll_wait(_epollfd, events, MAX_EVENT, -1);
if (nready < 0) {
std::cerr << "epoll_wait error: " << strerror(errno) << std::endl;
break;
}
for (int i = 0; i < nready; ++i) {
// 处理事件
// ......
}
}
return true;
}
可以注意到一个问题:epoll 不是应该在有事件时通知吗?为什么在最开始的时候要先epoll_ctl添加listenfd?
它触及了epoll运作的核心机制。epoll的确是在有事件发生时才通知,但epoll_ctl(EPOLL_CTL_ADD, listenfd, ...)这个调用并非是为了让 epoll 立即通知 listenfd 上的事件,而是为了注册 istenfd,让epoll监控它,以便将来在listenfd上有事件发生时能够通知用户程序。
epoll_ctl(EPOLL_CTL_ADD, listenfd, …) 这一步至关重要。它告诉epoll实例:“请开始监控listenfd这个文件描述符,我关心它上面的特定事件(例如EPOLLIN,表示可读事件)”。 这就像订阅一个频道,你订阅之后,频道上有新内容才会推送给你。 此时,listenfd上并没有任何事件,epoll自然也不会通知。
因此,epoll_ctl(EPOLL_CTL_ADD, listenfd, ...) 是为了预先注册 listenfd,告诉 epoll 关注它,以便在将来 listenfd 上发生事件(例如新连接到来)时,epoll 可以及时通知程序。 这就像设置一个陷阱,只有设置好陷阱,才能在猎物出现时触发。
3.3、事件处理
从服务端的视角来看,I/O事件可以被清晰地划分为两大核心类别,这种划分不仅有助于理解网络通信的本质,更是实现高效、可伸缩服务器的关键。
-
监听套接字事件: 这类事件发生在用于监听传入连接请求的套接字上,通常被称为监听文件描述符(
listenfd)。当一个客户端尝试与服务器建立新的TCP连接时,listenfd上就会产生一个可读事件(或更准确地说,是连接就绪事件),表明有新的连接等待被接受。 -
已连接套接字事件: 这类事件发生在成功建立连接后,用于与特定客户端进行数据通信的套接字上。这些套接字是由
accept()系统调用返回的,通常被称为连接文件描述符(connectedfd)。connectedfd上的事件通常包括:- 数据可读事件 (
EPOLLIN):客户端发送了数据到服务器。 - 数据可写事件 (
EPOLLOUT):服务器可以向客户端发送数据。 - 连接断开事件:客户端关闭了连接。
- 数据可读事件 (
为何需要区分这两类事件?
将I/O事件区分为监听事件和连接事件,是基于它们在服务器生命周期和处理逻辑上的根本差异:
(1)职责不同:
listenfd的核心职责是建立新的连接。它通过accept()系统调用,从内核的连接等待队列中提取一个已完成三次握手的连接,并为其分配一个新的connectedfd。connectedfd的核心职责是进行数据传输。它通过recv()、send()等系统调用,与特定的客户端进行双向的数据交换。
(2)操作模式不同:
- 对
listenfd的操作主要是accept()。 - 对
connectedfd的操作主要是recv()和send()。
(3)生命周期与管理:
listenfd通常在服务器启动时创建,并在服务器运行期间一直保持活跃状态,直到服务器关闭。connectedfd则是动态创建的,每当有新连接建立时就产生一个,并在该连接断开时(无论是客户端主动断开、服务器主动断开还是异常断开)被关闭并释放资源。
因此,为了实现清晰的逻辑分离、高效的资源管理以及避免不同操作之间的相互干扰,将这两种类型的事件分开处理是至关重要且符合网络编程最佳实践的。
事件处理代码实现与解析:区分并处理这两种类型的I/O事件。
void handleEvents(struct epoll_event& event)
{
static char wbuffer[MAX_BUFFER_LENGTH + 1] = { 0 };
static int wLength = 0;
int fd = event.data.fd;
if (fd == _listenfd) {
// accept
struct sockaddr_in addr;
socklen_t len = sizeof(addr);
int connectFd = accept(_listenfd, (struct sockaddr*)&addr, &len);
if (connectFd < 0) {
std::cerr << "accept error: " << strerror(errno) << std::endl;
return;
}
std::cout << "accept from: " << inet_ntoa(addr.sin_addr) << ":" << ntohs(addr.sin_port) << std::endl;
setNonblock(connectFd);
struct epoll_event ev;
ev.events = EPOLLIN;
ev.data.fd = connectFd;
if (epoll_ctl(_epollfd, EPOLL_CTL_ADD, connectFd, &ev) < 0) {
std::cerr << "accept epoll_ctl error: " << strerror(errno) << std::endl;
closeSocket(connectFd);
}
} else if (event.events & EPOLLIN){
// read from client fd
char buffer[MAX_BUFFER_LENGTH + 1];
memset(buffer, 0, MAX_BUFFER_LENGTH + 1);
int n = recv(fd, buffer, MAX_BUFFER_LENGTH, 0);
if (n > 0) {
if (n < MAX_BUFFER_LENGTH)
buffer[n] = '\0';
else
buffer[MAX_BUFFER_LENGTH + 1] = '\0';
std::cout << "recv from client: " << buffer << std::endl;
event.data.fd = fd;
event.events = EPOLLOUT;
memcpy(wbuffer, buffer, n + 1);
wLength = n;
std::cout << "copy to wbuffer: " << wbuffer << std::endl;
if (epoll_ctl(_epollfd, EPOLL_CTL_MOD, fd, &event) < 0) {
std::cerr << "read epoll_ctl error: " << strerror(errno) << std::endl;
closeSocket(fd);
}
} else {
std::cout << "client close" << std::endl;
if(epoll_ctl(_epollfd, EPOLL_CTL_DEL, fd, NULL) < 0) {
std::cerr << "client close epoll_ctl error: " << strerror(errno) << std::endl;
}
closeSocket(fd);
}
} else if (event.events & EPOLLOUT) {
// write to client fd
std::cout << "fd "<< fd << " write to buffer: " << wbuffer << std::endl;
int n = send(fd, wbuffer, MAX_BUFFER_LENGTH, 0);
if (n < 0) {
std::cerr << "fd "<< fd << " send error: " << strerror(errno) << std::endl;
if (epoll_ctl(_epollfd, EPOLL_CTL_DEL, fd, NULL) < 0)
std::cerr << "send epoll_ctl error: " << strerror(errno) << std::endl;
closeSocket(fd);
} else if(n < wLength) {
std::cout << "send partial data" << std::endl;
event.data.ptr = (char*)event.data.ptr + n;
} else {
std::cout << "send success" << std::endl;
event.events = EPOLLIN;
if (epoll_ctl(_epollfd, EPOLL_CTL_MOD, fd, &event) < 0) {
std::cerr << "write epoll_ctl error: " << strerror(errno) << std::endl;
closeSocket(fd);
}
}
} else {
std::cout << "other event: " << event.events << std::endl;
}
}
事件源判断 (if (current_fd == listenfd)): 这是区分两种I/O事件的核心逻辑。
- 如果当前事件的文件描述符
current_fd与listenfd相同,则表示有新的连接请求。 - 否则,表示事件发生在某个已建立的客户端连接
connectedfd上。
从上述代码中是否有一个疑问:为什么不在recv之后立即调用send发送数据?
这是因为如果在recv之后立即send,内核空间的发送数据缓冲很容易达到饱和。这会导致后面的send因为无法写入缓冲区而发送失败。因此,我们在发送数据之前,需要判断I/O是否可写,也就是EPOLLOUT的作用。
这种设计模式是构建高性能、高并发网络服务器的基础,确保了服务器能够响应大量的并发连接请求,并有效地处理每个连接的数据流。
四、epoll的工作模式详解
epoll核心在于两种不同的事件触发模式:水平触发(Level Triggered, LT)和边沿触发(Edge Triggered, ET)。理解这两种模式的工作原理及其差异,对于编写高效、健壮的网络应用程序至关重要。
当一个I/O事件(例如,新的数据到达可读,或者套接字可写)发生时,epoll会根据其配置的触发模式来通知应用程序:
-
水平触发(Level Triggered, LT):这是
epoll的默认工作模式。在这种模式下,只要文件描述符上存在可用的I/O条件(例如,读缓冲区中仍有数据可读,或者写缓冲区仍有空间可写),epoll就会持续地报告该事件。即使应用程序没有一次性处理完所有数据,只要条件仍然满足,epoll会反复触发该事件,直到所有数据都被处理完毕,或者写缓冲区被填满。 -
边沿触发(Edge Triggered, ET):在这种模式下,
epoll只会在文件描述符上的I/O条件发生变化时(即从“不可用”变为“可用”的瞬间)通知一次事件。一旦事件被通知,即使文件描述符上仍然存在可用的I/O条件,epoll也不会再次触发该事件,直到下一次I/O条件发生新的“边沿”变化。应用程序必须在一次事件通知中尽可能多地处理所有可用的数据或完成所有可写的操作,否则剩余的数据或未完成的操作将不会再次触发事件通知,可能导致数据滞留或饿死。
为了更直观地理解这两种模式,我们通过一个具体的TCP数据读取场景进行分析。
4.1、缓冲区限制下的数据读取
假设设置了一个较小的读取缓冲区大小,例如MAX_BUFFER_LENGTH = 16字节,并通过epoll来监听套接字的可读事件。
场景一:水平触发(LT)模式下的行为
当epoll使用默认的水平触发模式时,如果客户端发送了33个字节的数据:
epoll首次检测到数据可读,触发事件。- 应用程序读取前16个字节。此时,读缓冲区中仍有
33 - 16 = 17个字节的数据。 - 由于读缓冲区中仍有数据,I/O条件依然满足,
epoll会再次触发可读事件。 - 应用程序读取接下来的16个字节。此时,读缓冲区中还剩下
17 - 16 = 1个字节的数据。 - 同样,因为仍有数据,
epoll会第三次触发可读事件。 - 应用程序读取最后1个字节。此时,读缓冲区为空,I/O条件不再满足,
epoll将不再触发该事件。
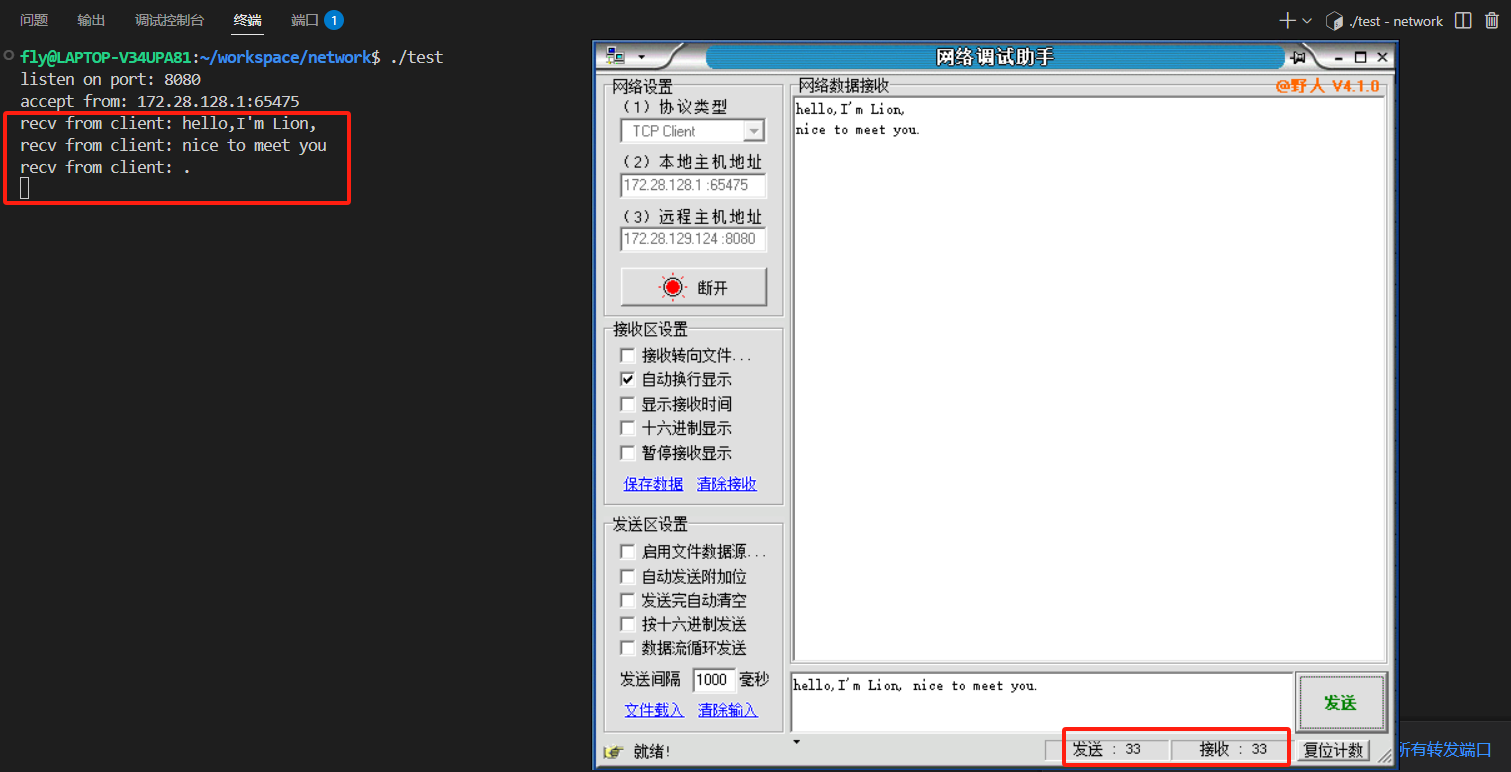
从这个例子可以看出,在水平触发模式下,只要数据没有被完全读取,epoll会持续地通知应用程序,确保数据最终能够被处理。
场景二:边沿触发(ET)模式下的行为
现在,我们将epoll事件设置为边沿触发模式,通过修改ev.events为EPOLLIN | EPOLLET。如果客户端分三次发送数据,每次发送33个字节(总共99个字节),并且每次发送都构成一个独立的“事件边沿”:
- 客户端第一次发送33个字节。
epoll检测到新的数据到达,触发一次可读事件。 - 应用程序读取前16个字节。即使读缓冲区中仍有
33 - 16 = 17个字节未读,由于是边沿触发,epoll不会再次触发事件。应用程序必须在这次事件处理中通过循环(例如while (read() > 0))将所有33个字节读完。如果只读取了16字节就停止,剩余的17字节将滞留在内核缓冲区,且不会再有事件通知。 - 客户端第二次发送33个字节。这会产生一个新的“数据到达”边沿,
epoll再次触发一次可读事件。 - 应用程序再次读取数据,同样需要循环读取所有数据。
- 客户端第三次发送33个字节。
epoll第三次触发可读事件。 - 应用程序再次循环读取所有数据。
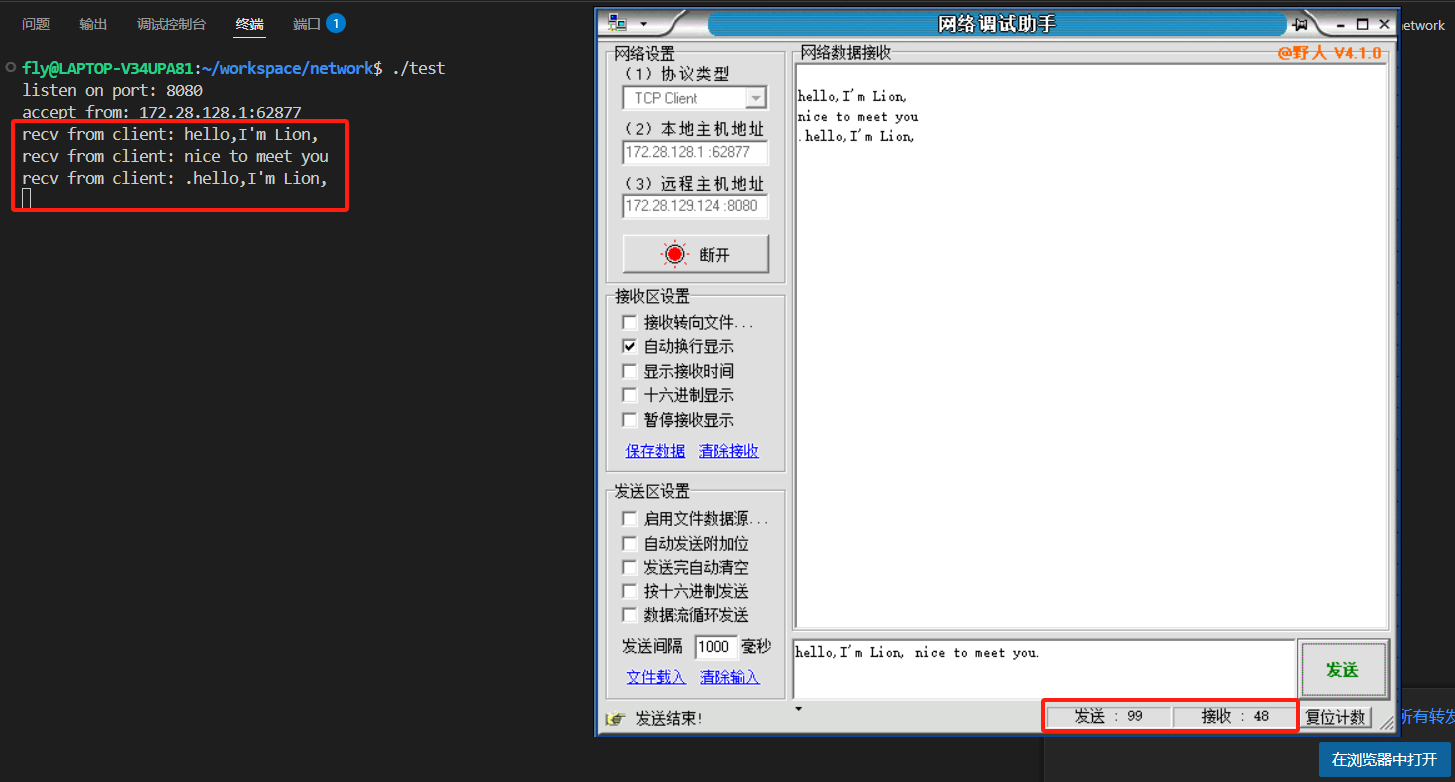
这个例子强调了边沿触发模式下,应用程序必须在一次事件通知中主动、尽可能多地读取所有数据,直到read()返回0或EAGAIN/EWOULDBLOCK,表示数据已读完或暂时无数据可读。
4.2、LT与ET的核心区别
水平触发(LT):
- 持续触发:只要I/O条件满足,就会反复触发事件。
- 处理方式:应用程序可以在一次事件通知中只处理部分数据,因为未处理的数据会在下一次事件循环中再次触发通知。这使得LT模式下的编程逻辑相对简单。
边沿触发(ET):
- 单次触发:只在I/O条件发生变化时触发一次事件。
- 处理方式:应用程序必须在一次事件通知中,通过循环读取或写入,尽可能地处理所有数据,直到操作返回
EAGAIN或EWOULDBLOCK。这要求应用程序必须使用非阻塞I/O,否则在数据未完全到达时,read()或write()可能会阻塞整个事件循环。
关于水平触发和边沿触发哪种效率更高,实际上两者的性能差异非常微小,在大多数应用场景下可以忽略不计。选择哪种模式更多取决于编程习惯、业务逻辑的复杂性以及对资源利用的精细控制:
- 边沿触发的优势:通过一次性循环读取所有数据,可以减少
epoll_wait的调用次数,从而减少用户态与内核态之间的上下文切换。这对于处理大量、连续的数据流可能略有优势,因为它能将一次事件通知中的所有相关数据集中处理,有助于提高CPU缓存的命中率,并简化后续的业务解析流程。因此,ET模式常被高性能网络服务器采用,尤其是在需要最大化吞吐量和最小化延迟的场景。 - 水平触发的优势:编程模型更简单,不易出错。对于小数据量或请求-响应模式的应用,LT模式可以更好地适应业务逻辑,因为即使只读取部分数据,系统也会保证事件再次触发。
对于大多数应用,LT模式因其简单性而更受欢迎。只有在对性能有极致要求,并且能够熟练处理非阻塞I/O和循环读取逻辑的场景下,才推荐使用ET模式。
4.3、LT与ET的关键差异点
I/O模式要求:
- 水平触发(LT):可以使用阻塞I/O来接收数据(尽管这通常不推荐,因为它会阻塞整个事件循环,违背了
epoll的并发优势),也可以使用非阻塞I/O。 - 边沿触发(ET):必须配合非阻塞I/O使用。在事件触发后,应用程序需要在一个循环中持续读取或写入数据,直到遇到
EAGAIN或EWOULDBLOCK错误码。如果使用阻塞I/O,一旦没有数据可读或空间可写,read()或write()将阻塞,导致整个事件循环停滞。
事件处理方式:
- 水平触发(LT):在一次事件触发中,通常只进行一次
read()或write()操作。如果数据未处理完,事件会再次触发。 - 边沿触发(ET):在一次事件触发中,应用程序需要在一个
while循环中反复调用read()或write(),直到所有数据都被处理完毕(即read()返回0或遇到EAGAIN/EWOULDBLOCK),或者所有可写空间都被填满。
listen文件描述符的处理:
- 水平触发(LT):对于监听套接字(
listen fd),通常推荐使用LT模式。当有新的连接到来时,epoll会通知一次,应用程序可以调用一次accept()。如果短时间内有多个连接到来,并且accept队列中仍有待处理的连接,epoll会再次触发事件,直到所有连接都被accept。 - 边沿触发(ET):理论上
listen fd也可以与ET模式配合使用,但这要求应用程序在一次accept事件触发后,在一个while循环中持续调用accept(),直到其返回EAGAIN或EWOULDBLOCK。这种做法虽然可行,但相比LT模式更为复杂且容易出错,因此通常不推荐。
业务代码复杂性与性能:
- 两种模式在业务代码的编写上存在显著差异,ET模式通常需要更严谨的非阻塞I/O和循环处理逻辑。
- 然而,它们之间的性能差异非常小,小到在绝大多数实际应用中可以忽略不计。选择哪种模式,更多是基于对编程模型、可靠性和特定场景下资源利用效率的权衡。
五、总结
epoll 是一种高效的 I/O 多路复用机制,适用于高并发的网络编程。 它通过事件触发机制、高效的数据结构和多种工作模式,能够有效地提高程序的并发性能和资源利用率。 虽然使用起来比 select 和 poll 更复杂一些,但其显著的性能优势使其成为构建高性能网络应用的首选方案。 理解 epoll 的工作原理和各种模式对于编写高性能的网络应用程序至关重要。


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 22
22 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)