Surya:太阳物理学的基础模型
摘要: 本文提出Surya,首个366M参数的日球物理学基础模型,基于全分辨率SDO卫星的AIA和HMI多通道数据(4096×4096像素)训练。该模型采用时空Transformer架构,结合频谱门控和长短程注意力机制,通过高分辨率太阳图像预测任务进行预训练,并利用自回归展开调优优化长期预测性能。零样本评估显示其能准确预测太阳动力学和耀斑事件,下游微调在太阳风预测、活动区分割等任务中表现优异(如耀
Surya: Foundation Model for Heliophysics


Abstract
Heliophysics is central to understanding and forecasting space weather events and solar activity. Despite decades of high-resolution observations from the Solar Dynamics Observatory (SDO), most models remain task-specific and constrained by scarce labeled data, limiting their capacity to generalize across solar phenomena. We introduce Surya, a 366M parameters foundation model for heliophysics designed to learn general-purpose solar representations from multi-instrument SDO observations, including eight Atmospheric Imaging Assembly (AIA) channels and five Helioseismic and Magnetic Imager (HMI) products. Surya employs a spatiotemporal transformer architecture with spectral gating and long–short range attention, pretrained on high-resolution solar image forecasting tasks and further optimized through autoregressive rollout tuning. Zero-shot evaluations demonstrate its ability to forecast solar dynamics and flare events, while downstream fine-tuning with parameter-efficient Low-Rank Adaptation (LoRA) adaptation shows strong performance on solar wind forecasting, active region segmentation, solar flare forecasting, and EUV spectra. Surya is the first foundation model in heliophysics that uses time advancement as a pretext task on full-resolution SDO’s data. Its novel architecture and performance suggest that the model is able to learn the underlying physics behind solar evolution.
日球物理学(Heliophysics) 是研究与预报空间天气事件和太阳活动的核心。尽管通过太阳动力学观测站(Solar Dynamics Observatory, SDO) 已获得数十年的高分辨率观测数据,但大多数模型仍局限于特定任务,且受限于稀缺的标注数据,从而限制了其跨太阳现象的泛化能力。本文推出了Surya(梵语“太阳”之意),这是一个拥有3.66亿参数的日球物理学基础模型,旨在从多仪器SDO观测数据中学习通用太阳表征,包括8个大气成像阵列(Atmospheric Imaging Assembly, AIA)通道和5个日震与磁像仪(Helioseismic and Magnetic Imager, HMI)产品。Surya采用了一种时空Transformer架构,配备谱门控(spectral gating) 和长短程注意力机制(long–short range attention),通过高分辨率太阳图像预测任务进行预训练,并经由自回归展开调优(autoregressive rollout tuning) 进一步优化。零样本(zero-shot)评估展示了其预测太阳动力学和耀斑事件的能力,而通过参数高效的低秩自适应(Low-Rank Adaptation, LoRA) 进行下游微调后,在太阳风预测、活动区分割、太阳耀斑预报和极紫外(EUV)光谱分析等任务中表现出强劲性能。Surya是日球物理学中首个以时间推进为预训练任务、基于全分辨率SDO数据的基础模型。其新颖架构与性能表明,该模型能够学习太阳演化背后的底层物理规律。
1. Introduction
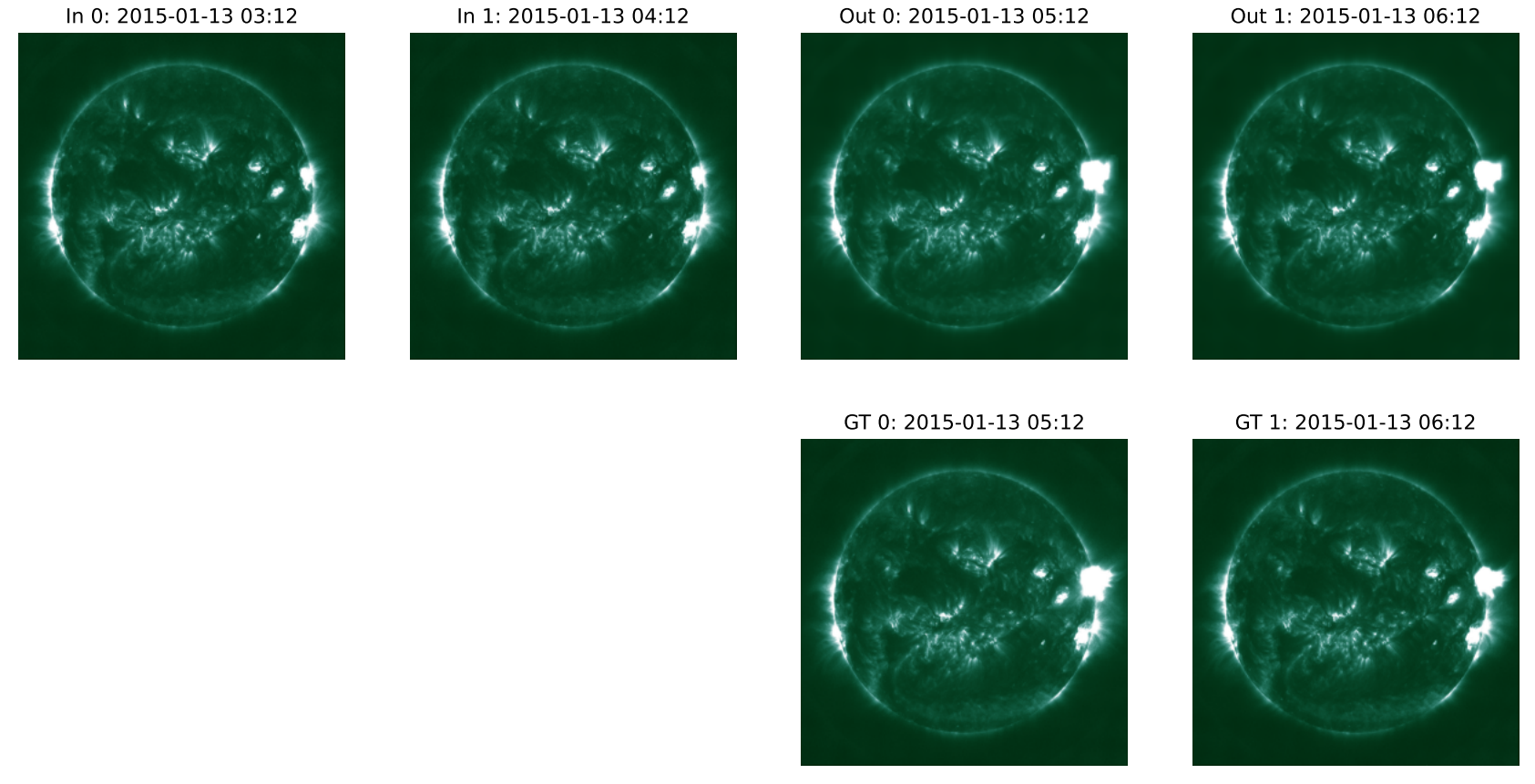
图1:Surya预测的2015年1月13日发生的M级太阳耀斑。AIA,94Å波段。顶行左两列为模型输入(“In”),顶行右两列为模型输出(“Out”)。底行为对应真实值(“GT”)。
日球物理学的核心研究对象是太阳及其对太阳系的影响,其中空间天气(space weather) 研究尤为关键,它涉及由太阳耀斑(solar flares) 和日冕物质抛射(CMEs) 等太阳活动引发的现象,这些现象可能严重干扰现代技术系统(如通信、导航、电网)并对人类社会构成广泛威胁。
近年来,机器学习(ML) 方法在该领域显示出显著优势,被应用于太阳特征检测(如冕洞(CHs)、活动区(ARs))、事件预报和物理建模等任务。然而,现有ML模型通常存在任务特定性强、依赖标注数据、易过拟合及对稀有事件泛化能力不足的问题。
基础模型(Foundation Models, FMs) 的出现为解决这些局限性提供了路径。通过从多源、高分辨率数据中学习泛化的、物理感知的表征,FMs能够减少对标注数据的依赖,提升对极端事件的预测能力,并支持多种下游任务的高效微调,从而推动数据驱动的日球物理学发展。
日球物理学基础模型可通过从丰富的高分辨率、多仪器太阳数据中学习泛化的、物理感知的表征来解决这些限制,从而在广泛的预测、诊断和分析任务中实现强劲性能。
通过利用大型太阳观测数据库进行预训练,FMs可以缓解监督瓶颈(supervision bottleneck),减少对标注数据的需求,并提高在预测稀有或极端事件时的实际性能。其多功能性和适应性允许针对多样下游应用进行微调,包括太阳特征检测(如冕洞、太阳黑子(sunspots)、活动区)、瞬变事件预报(如空间天气)和日球层建模,且只需最少的额外监督。
FMs还提供了改进的泛化能力,有效处理阻碍传统模型的数据分布偏移,其可扩展性确保了与日益增长的大规模高分辨率数据集的兼容性,用于太阳动力学的多尺度建模。
此外,它们的多模态集成能力可以解锁对太阳活动和日球层状况更准确、更全面的预测。总体而言,这些能力将基础模型定位为迈向下一代数据驱动日球物理学的变革性一步。
本文提出的Surya模型是这一方向的代表工作。它是一个基于全分辨率SDO数据训练的日球物理基础模型,采用预训练和自监督学习范式,旨在学习通用的太阳表征,并在包括活动区分割、耀斑预报、太阳风预测等多种任务中展现出强劲且可迁移的性能,体现了基础模型在该领域的重大潜力。
2 Surya FM
2.1 SDO Data
太阳动力学观测站(SDO) 于2010年2月11日发射,是美国国家航空航天局(NASA)“与恒星共存(Living With a Star, LWS)”计划的首个任务。它致力于推动本文对太阳变率(solar variability) 及其对地球和近地空间影响的理解。通过在多个波长(wavelengths) 以高空间和时间分辨率观测太阳大气,SDO研究太阳磁场(magnetic field) 是如何产生、结构和释放的,从而驱动太阳风(solar wind)、高能粒子(energetic particles) 和辐照度变化(irradiance variations)。这些观测旨在实现对影响地球上生命和技术系统的太阳变化的预测能力,这些影响统称为空间天气(space weather)。
本研究利用了SDO 上两个主要成像仪器的观测数据:
- 大气成像阵列(AIA),它记录极紫外(EUV) 和紫外(UV) 光度强度;
- 日震与磁像仪(HMI),它提供用于推导矢量磁场(vector magnetic fields) 和视向速度(line-of-sight velocities) 的光谱偏振(spectropolarimetric) 测量。
两个仪器均使用 4096×4096像素的CCD探测器,以亚角秒的空间分辨率捕获全日面(full-disk) 图像。
选择 AIA 和 HMI 的 SDO 数据是因为它们独特地提供了最高的空间分辨率、高时间频率(high cadence)的全日面太阳观测。SDO提供了一个时间跨度15年、覆盖超过一个完整太阳活动周的近乎连续且均匀的数据集。
此外,SDO是一项正在进行的任务,与GOES-SUVI业务卫星(该卫星也进行EUV成像观测)以及GONG网络的地面磁图(magnetogram) 和多普勒(Doppler) 测量同时运行。这确保了Surya基础模型将持续适用于未来的未见数据,从而将其效用扩展到历史记录之外。
2.1.1 数据集准备
通过统一化(homogenizing) 来自 aia.lev1_euv_12s 和 aia.lev1_uv_24s 序列的多通道AIA EUV/UV图像,以及来自 hmi.M_720s(视向)、hmi.B_720s(矢量)和 hmi.V_720s(视向)序列的HMI产品来构建本文的数据集。
所有数据均从联合科学操作中心(JSOC) 下载。
时间频率(temporal cadence)标准化为12分钟,以匹配HMI矢量磁场数据序列,AIA观测在可能的情况下在±2分钟内进行时间共对准(co-aligned),并经过质量标志(quality flag) 检查。
表1 总结了本研究中使用的各个通道的属性,包括它们仪器特定的时间和空间分辨率以及测量的动态范围(dynamic range)。
Table 1:Key properties of the SDO/AIA and SDO/HMI instruments. Cadence values refer to both instrument-native and standardized dataset cadence.
Instrument Resolution Cadence (instr./dataset) Dynamic range Channels / Measurements AIA 1.2′′ (≈725 km) 12 s, 24 s / 12 min 0–16,383 DN 94, 131, 171, 193, 211, 304, 335, 1600 Å HMI 1.0′′ (≈870 km) 45 s, 12 min / 12 min ±4,500 G (B), ±104 m/s (V) Bx, By, Bz, Blos, Vlos
Level 1.0 的AIA数据经过预处理,包括
- 更新航天器指向(spacecraft pointing)
- 将图像的y轴与太阳北(solar north) 对齐
- 重新缩放到统一的 0.6角秒/像素(0.6′′/pixel) 网格
- 将日面中心(solar disk center) 移至图像中心
- 归一化(normalizing) 曝光时间变异性
使用校准因子(calibration factors) 校正时间相关的仪器性能衰减,并将值钳制(clamped) 在仪器的动态范围内以避免饱和伪影(saturation artifacts)。
Level 1.5的HMI数据(像素尺度为0.5角秒/像素)经过预处理,通过使用双线性插值(bilinear interpolation) 进行重投影(reprojecting)(这也校正了HMI的滚动角(roll angle)),使其在0.6角秒/像素的图像尺度上与预处理后的AIA图像对齐。
最后,两个数据集中的太阳圆盘半径被固定为一个常数值,以消除由于地球椭圆轨道(elliptical orbit) 导致的表观太阳圆盘半径的非物理变化。
最终得到的数据库由经过空间和时间对准、预处理的多波长(multi-wavelength)太阳图像组成,非常适合机器学习应用。
这种统一化的处理流程(harmonized processing pipeline) 确保了数据集内的变化主要源于物理过程而非仪器或几何因素,从而实现了在日球物理学和空间天气中稳健的下游应用。
图2展示了本研究中使用的八个AIA通道和五个HMI通道的一组预处理后的图像示例。
图2:用于训练Surya的SDO太阳图像示意图:来自AIA的日冕EUV/UV图像(8个通道:94、131、171、193、211、304、335、1600 Å)以及来自HMI的太阳表面速度和磁场图(5个通道:hmiV, hmiBx, hmiBy, hmiBz, hmiM)

2.1.2 数据集统计
数据库包含从2010年5月13日到2024年12月31日捕获的可用于机器学习(ML-ready)的SDO数据。在此时间间隔内,hmi.M_720s序列约有2.9%的数据不可用(总时间戳623,280个中的18,261个)。
处理后的level 1.5 AIA和HMI数据以netCDF文件(float32格式)存储,每个时间频率一个文件。每个文件包含该小时内五个12分钟时间步长的数据,数据形状为 [13, 4096, 4096]。每个netCDF文件使用lz4压缩以提高训练性能(约提升30%),大小约为630 MB。该数据集的总大小约为257 TB。
数据细节
将一次太阳观测定义为一个多通道、共配准(co-registered)的光栅(raster),代表来自SDO上的AIA和HMI的同步测量。每次观测被编码为一个三维张量:X ∈ ℛ^(13×4096×4096)。
其中 13 是通道数,4096×4096 是空间维度。
通道组成信息
13个通道组成如下:
- 8个通道来自AIA:94, 131, 171, 193, 211, 304, 335, 1600 Å。
- 5个通道来自HMI:hmiV (视向速度), hmiBx (磁场x分量), hmiBy (磁场y分量), hmiBz (磁场z分量), hmiM (磁场总强度)。
每个AIA通道提供太阳大气的EUV或UV强度测量,在不同温度区间(temperature regimes) 捕获日冕(coronal) 和色球(chromospheric) 辐射。
HMI衍生的通道捕获光球层(photospheric) 矢量磁场观测和视向等离子体(plasma) 运动。
训练/测试划分(Train/test split)
对于训练-测试划分,2011年至2019年的观测按年积日(day-of-year) 进行分割。每年的第1-14天和第32-45天被排除,作为时间缓冲区(temporal buffers),以减轻由于太阳活动中的短期时间自相关(short-term temporal autocorrelation) 而导致的潜在信息泄露(information leakage)。
每年第15-31天的时间间隔专门保留给测试集(test set),第46天开始的所有剩余天数则分配给训练集(training set)。
虽然第25太阳活动周(Solar Cycle 25)的数据可用,但本文将其排除,以便在扩展的预训练任务和下游应用(存在潜在隐式数据泄露风险)中进行进一步验证。
归一化(Normalization)
由于描绘宁静太阳(quiet sun) 的像素占主导地位以及少量描绘极端事件(如太阳耀斑)的像素存在,SDO数据是高度偏斜(highly skewed) 的。
对此类数据建模通常受益于在应用标准缩放之前进行对数变换(log-transformation)。
具体来说,考虑正负号对数变换(signum-log transform) sign(x) × log1p(1p(|X|)),它可以同等地应用于严格为正的AIA通道和包含正负值的HMI通道(其中log1p(x)是1+x的自然对数)。
然而,如图 3 所示,标准的正负号对数变换有一个缺点,即它拉伸了HMI通道固有的低磁场范围噪声,而牺牲了具有高信噪比的数据点。
图3:缩放的正负号对数变换减少了噪声主导的范围。
(A) 标准正负号对数变换。
(B) 使用比例因子10^(-2)的缩放正负号对数变换。
(C) 正负号对数变换后的HMI_m通道值直方图。
(D) 使用比例因子10^(-2)的缩放正负号对数变换后的HMI_m通道值直方图。红线表示磁场强度小于15高斯噪声水平的范围界限。
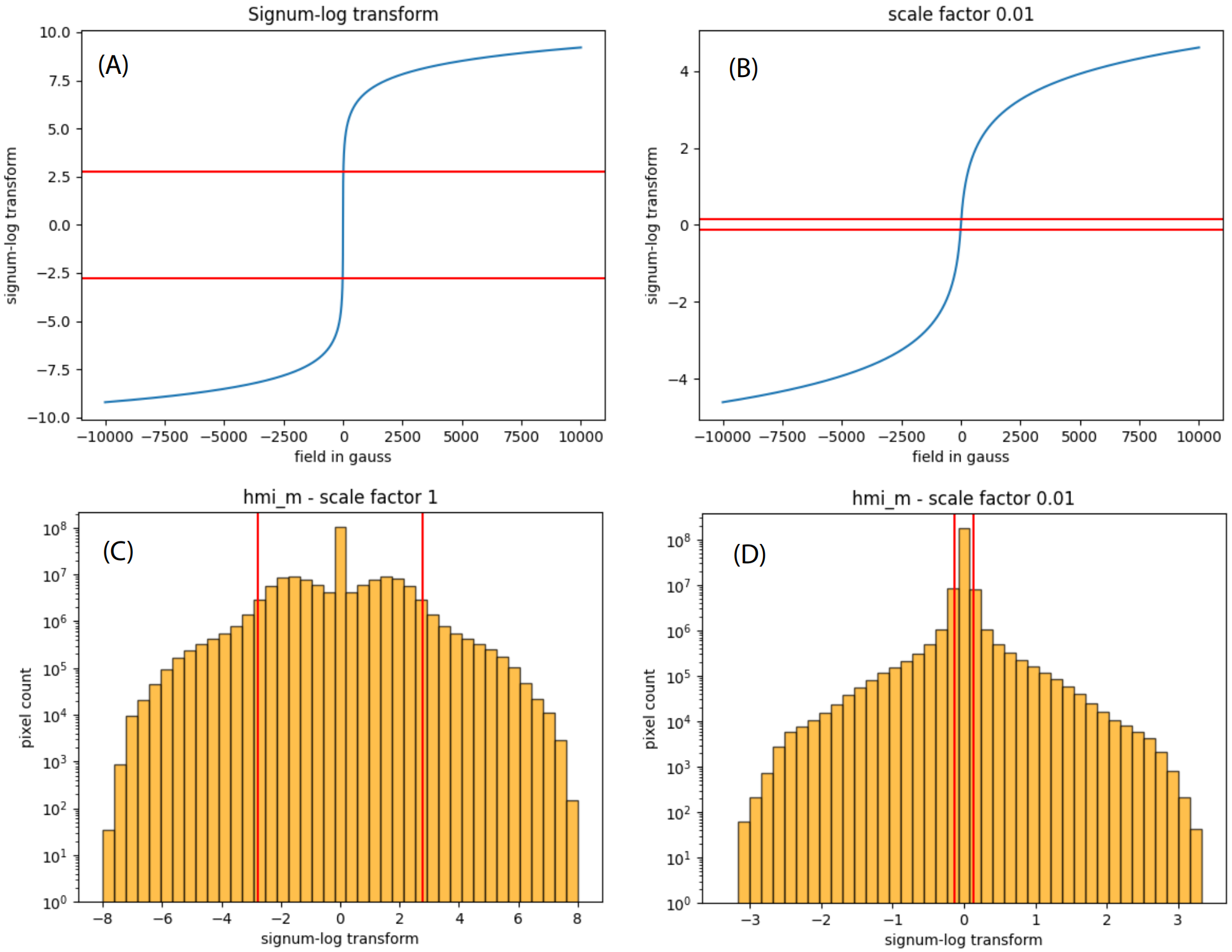
鉴于HMI_m通道的固有噪声水平为15高斯(Gauss),变换后的尺度约有1/3将被探测器噪声主导的数据占据,而极端事件的动态范围可能被压缩过多。
作为应用完整正负号对数变换或完全不应用变换之间的折衷,本文建议在应用正负号对数变换之前,对原始数据应用一个10^(-2)的比例因子。在此变换之后,对每个通道进行标准缩放。因此,每个通道的完整变换是:
![]() (1)
(1)
此处,μ 和 σ 是经过正负号对数变换后每个通道的全局均值(global means) 和标准差(standard deviations);ϵ 是一个小常数,使用10^(-8)。
图3(D)中结果数据分布的直方图显示,固有噪声值现在占据的范围要窄得多,模型可以专注于学习太阳重要的中间活动范围和极端活动范围(intermediate and extreme activity ranges)。
2.2 预训练任务(Pretext task)与基线(Baselines)
2.2.1 以预测未来SDO图像作为预训练任务
在考虑AI架构之前,需要决定一个预训练任务。这里可以从计算机视觉以及地球观测或大气物理学等其他科学领域的先前工作中汲取灵感。最主要的自监督训练方法是掩码重建(masked reconstruction)、对比目标(contrastive objectives),最后是自编码器。
近期大气物理学的工作还表明,AI模型可以通过回归(regressing) 到未来时间步长,纯粹从数据中学习复杂的时间动力学。掩码重建已成功用于地球观测,而Schmude et al. (2024) 使用了结合重建与预测的混合目标。
本文最终注意到的下游任务本质上是时间性的,因此选择预测作为预训练目标。
在日球物理学中,Majid et al. (2024) 使用了提前12小时的预测目标进行训练,而Walsh et al. (2024) 探索了MAEs(Masked Autoencoders) 和自编码器。这两篇论文都是在512x512像素分辨率下进行的。
对于未来的工作,波段到波段转换(band-to-band translation) 预训练任务(Jakubik et al., 2025 在地球观测中非常成功地使用了该方法)如果与时间目标相结合,可能是一个强有力的替代方案,尤其是考虑到SDO数据固有的多模态性(multi-modality)。
无论哪种情况,本文使用两个相隔60分钟的时间戳作为模型输入,并通过回归未来60分钟的SDO数据来训练模型。
正如现在大气物理学模型的标准做法,随后进行第二阶段的预训练,其中将Surya的输出用作输入来预测未来120、180……分钟。这通常被称为“自回归展开调优(autoregressive rollout tuning)”。在展开调优期间,本文对所有时间步的损失取平均。
将其形式化,将观测到的帧表示为 X_t,模型表示为 f_θ。然后使用均方误差(MSE) 目标训练Surya:
![]() (2)
(2)
如果进一步将模型输出表示为 ![]() ,则自回归预测(autoregressive prediction) 的形式为:
,则自回归预测(autoregressive prediction) 的形式为:
![]() (3)
(3)
展开损失(rollout loss) 则为:
![]() (4)
(4)
多步展开的情况类似。在推理(inference) 时,该方案能够从两个初始观测(相隔一小时)进行更长的预测。
2.2.2 Baseline scores
确定了预训练任务后,确定一系列基线分数进行比较至关重要。目的是在训练和开发过程中将模型损失置于上下文中。
第一个基线是简单的持续性(persistence)。使用第2.2.1节的符号,持续性预测简单地就是 X̂_{t+1} = X_t。
从技术上讲,注意到可以通过沿 X̂_{t+1} = (X_t + X_{t-1}) / 2 的思路对多个时间戳取平均来获得改进的持续性预测。原因是平均过程平滑了尖锐的特征。特别是由于太阳的自转,尖锐的特征会导致持续性预测的MSE损失产生双重惩罚(double penalty)。
然而,本文的持续性分数仅作为基线,因此本文使用 X̂_{t+1} = X_t。
Table 2:Baseline scores for 1 hour ahead forecasting. In model units.
Baseline Parameters Loss (MSE) Persistence N/A 0.594044030 Learned flow 642 0.337624282
另一个相关的基线由太阳自转(solar rotation) 给出。本文不是通过已知方程硬编码旋转,而是决定从数据中学习这种效应。为此,将坐标 [-1, 1] × [-1, 1] 分配给4096 x 4096像素。即,左下角像素是 (-1, -1),右上角像素是 (1, 1) 等。然后训练一个非常小的多层感知器(MLP),它以每个像素的这些坐标作为输入并产生一个向量作为输出。结果是一个学习到的向量场,沿着它插值数据。
由于输入与数据无关,这训练了一个恒定流场(constant flow-field),数据沿该场移动以有效学习旋转。如果本文将每个像素的坐标表示为 x,MLP表示为 M_θ,沿向量进行插值的操作表示为 ↗,按如下方式训练此基线:
![]() (5)
(5)
Implementation wise, we use the F.grid_sample method from PyTorch for interpolation. I.e. F.grid_sample(x, flow_field, mode="bilinear"), where x is the data X and flow_field the output of the MLP M_θ.
MLP由两个线性层(linear layers) 和一个内部维度(internal dimension) 为128的GELU激活函数(GELU activation) 组成。因此,它总共有642个参数(parameters)。
表2 显示了模型单位(方程1)中的基线分数。
2.3 Architecture
图4:(A). Surya基础模型的架构,该模型使用2个频谱块(spectral blocks)、8个基于长短程注意力(long-short attention)的注意力块和1个解码器块。在执行FFT后使用一个可学习的权重参数(W_c)来估计频率分量的权重。然后本文执行逆FFT将信息转换回物理空间。注意力头基于长短程注意力原理设计,其中通过滑动窗口(sliding window)计算短程注意力(short-term attention),通过动态投影(dynamic projections)计算长程注意力。
(B). 4步展开微调(4-step rollout finetuning)概述,其中模型被给予2个时间步输入,然后自回归地预测接下来的4步。
(C). 模型的推理,具有2个时间步输入和一小时预测。
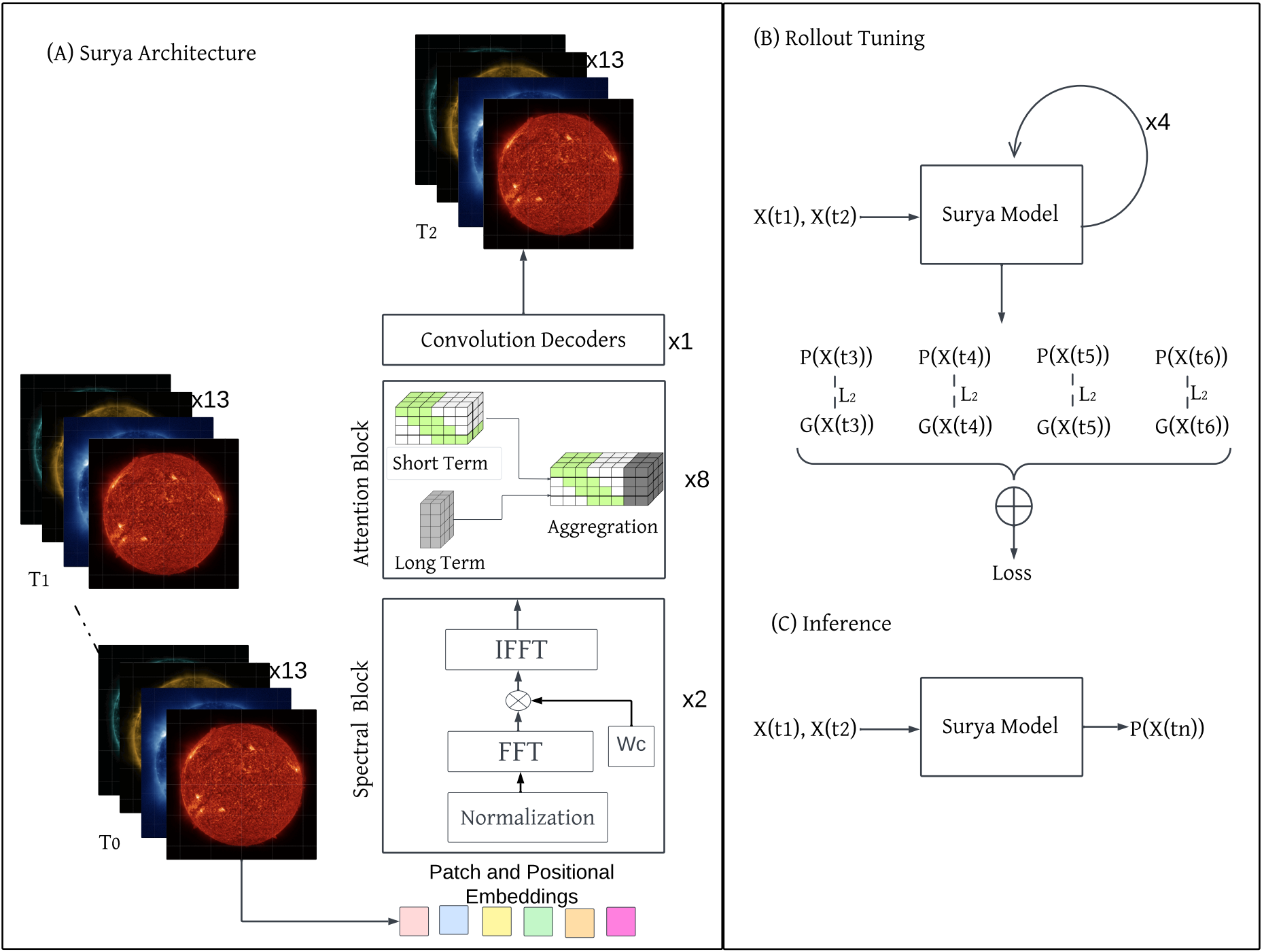
2.3.1 Surya模型架构概述
Surya(图4)是一个用于高分辨率预测SDO图像和太阳动力学的二维Transformer架构。它集成了频域滤波与高效的多尺度注意力,以捕获精细尺度(fine-scale) 和全局的时空依赖性(spatio-temporal dependencies)。
如图4所示,该架构由两个频谱门控块、八个长短程注意力块 和一个用于在物理域进行重建的解码器块组成。消融研究见附录A.1节。
Tokenization
Surya的原始输入数据是来自13个不同通道的SDO数据,根据方程1进行了缩放。使用两个时间戳,输入数据初始形状为 13 × 2 × 4096 × 4096。为了对数据进行标记化,本文简单地展平(flatten) 通道和时间维度,并使用一个简单的线性层(linear layer)。内部维度(internal dimension) 为 D = 1280。给定 块大小(patch size) 为 16 × 16,本文最终得到 N = 65,536 个标记(tokens):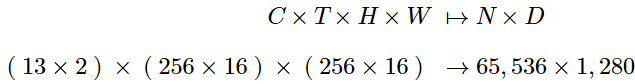 (6)
(6)
Surya使用傅里叶位置编码(Fourier position embedding)。
频谱门控块(Spectral Gating Blocks)
令 X ∈ ℝ^(B×N×D) 表示嵌入的时空标记(spatiotemporal tokens),其中 B 是(batch size)。每个频谱块将 X 重塑为 X_s ∈ ℝ^(B×H_p×W_p×D),其中 H_p = W_p = 256 是标记空间(token space) 中的高度和宽度,并应用二维实快速傅里叶变换(2-D real Fast Fourier Transform, rFFT):
![]() (7)
(7)
随后使用可学习的复数值权重(learnable complex-valued weight) W_c ∈ ℂ^(H_f×W_f×D) 进行调制:
![]() (8)
(8)
这里,H_f = 256, W_f = 129,⊙ 表示逐元素复数乘法(element-wise complex multiplication)。这可以自适应地重新加权(adaptively re-weights) 频率分量,以强调信息丰富的频带并抑制噪声。结果通过逆rFFT(inverse rFFT) 转换回物理域:
![]() (9)
(9)
并通过残差连接和前馈网络(FFN) 进行细化:
![]() (10)
(10)
LN(·) 表示层归一化(Layer Normalization),X' 是 X_s' 重塑回序列顺序后的形式。
长短程注意力块(Long-Short Attention Blocks)
注意力主干 由 L = 8 层组成,这些层融合了局部和全局注意力路径,遵循适用于二维时空标记的长短程Transformer的原理。
局部(短程)注意力在大小为 w × w 的非重叠空间窗口(non-overlapping spatial windows) 内操作,捕获精细尺度的依赖性。对于每个窗口 Ω,查询(queries, Q)、键(keys, K) 和值(values, V) 被限制在 Ω 内,产生:
![]() (11)
(11)
其中 Δ_rpe 是一个可选的相对位置偏置,d_k 是每头维度(per-head dimension)。
全局(长程)注意力使用动态低秩投影(dynamic low-rank projection):键和值被内容自适应地(content-adaptively) 压缩成一个秩r(rank-r) 的基(basis),
![]() (12)
(12)
其中 α ∈ ℝ^(B×h×r×N) 是一个从键中学习到的混合权重(mixing weight)。查询然后关注整个序列中的 (K̄, V̄):
![]() (13)
(13)
两个分支(branches) 被归一化以对齐它们的尺度,然后沿键值维度(key-value dimension) 拼接(concatenated):
![]() (14)
(14)
随后是一个残差MLP:
![]() (15)
(15)
该设计高效地结合了局部化建模与全局上下文聚合(global context aggregation),以降低的复杂度实现了多尺度表示学习(multi-scale representation learning)。
解码器
解码器是一个轻量级投影(lightweight projection),将最终的标记表示 X_L 映射回空间域:
![]() (16)
(16)
其中 C 是输出通道的数量。
2.4 预训练(Pretraining)
2.4.1 缩放(Scaling)
在其最终配置中,Surya包含 3.66亿个参数。考虑到两个时间戳的SDO数据包含:
![]() (17)
(17)
的数据,GPU内存是一个主要问题。在patch size 为 16×16 的情况下,本文需要处理 65,536个tokens。为了应对内存压力,本文使用了全分片数据并行(Fully Sharded Data Parallel, FSDP)、混合精度(mixed precision) 以及梯度检查点(gradient checkpointing)。
模型的输入和输出层在 float32 精度下运行,而Transformer层使用 bfloat16 精度。
请注意,频谱门控层(spectral gating layers) 为了执行FFT操作会显式转换为 float32。
表8 显示了Surya以及其消融实验和基线的提前1小时预测性能和内存消耗。其中,“无频谱门控”的消融实验用额外的长短程注意力块 替换了两个频谱门控块。如表所示,使用频谱门控层可以在减少6% GPU内存的情况下达到相同的损失。
Table 8:Architecture ablations & baselines. The table shows MSE loss for 1 hour ahead forecasting in model units of equation 1. All baselines and ablations in this table – including the Surya configuration – were trained on 16 GPUs for 10,000 gradient descent steps.
Type Configuration Parameters Memory usage [MiB] Loss (MSE) Baseline Persistence N/A N/A 0.594044030 Learned flow 642 24976 0.337624282 Ablation Single timestamp 361.93 M 55411 0.228553504 No spectral gating 210.39 M 59823 0.219618767 Perceiver 351.52 M 52721 0.234643415 Surya 366.19 M 56247 0.219778508
2.4.2 预训练协议(Pretraining protocol)
如上所述,Surya的预训练遵循了大气物理学AI预测模型中已成为标准的方法。即,Surya采用两阶段方法 进行训练,包括单步预测(one step ahead forecasting) 和随后的展开调优(rollout tuning)。
单步预测
在第一阶段,本文在128个NVIDIA A100 GPU上对Surya进行了 160,000 步梯度下降(gradient descent steps) 的训练。
模型以batch size 为1(每个GPU)进行训练,有效 batch size为128。在整个训练过程中,本文使用余弦退火(cosine annealing) 将学习率 从 10^(-4) 调整到 10^(-5)。
请注意,本文没有发现需要专门的预热期来稳定训练。本文将梯度在 0.1 处进行裁剪。本文使用PyTorch中的 AdamW优化器,其参数 betas、eps 和 weight_decay 均使用默认值。
展开调优
展开调优阶段对GPU内存提出了额外要求。本文现在在所有十个频谱层和Transformer层之后使用梯度检查点。
首先,本文以恒定的学习率 10^(-5) 进行 提前两步(即初始步加上一个自回归步)的训练,持续20,000个梯度下降步。
然后,本文随后分别以学习率 10^(-6) 进行提前三、四、五步的训练,各持续4,000步。这种不平衡的调度 部分是由于单个梯度下降步所需的时间随着预测时限 的延长而增加。
同时,损失曲线显示提前两步的情况在直到第20,000步之前持续改进。通常,本文使用64个GPU进行展开调优。
2.5 零样本评估(Zero-shot Evaluation)
2.5.1 预测未来SDO数据( forecasting)
图5:Surya的预测性能。所有通道的MSE(模型单位)。左侧显示了持续性(persistence)和用于捕捉太阳自转的流模型(flow model)。两侧都显示了预训练第一阶段(“1小时”)的输出以及展开调优的各个阶段:提前2小时到提前5小时的展开调优。后者是预训练的最后阶段,因此显示了Surya的零样本性能。
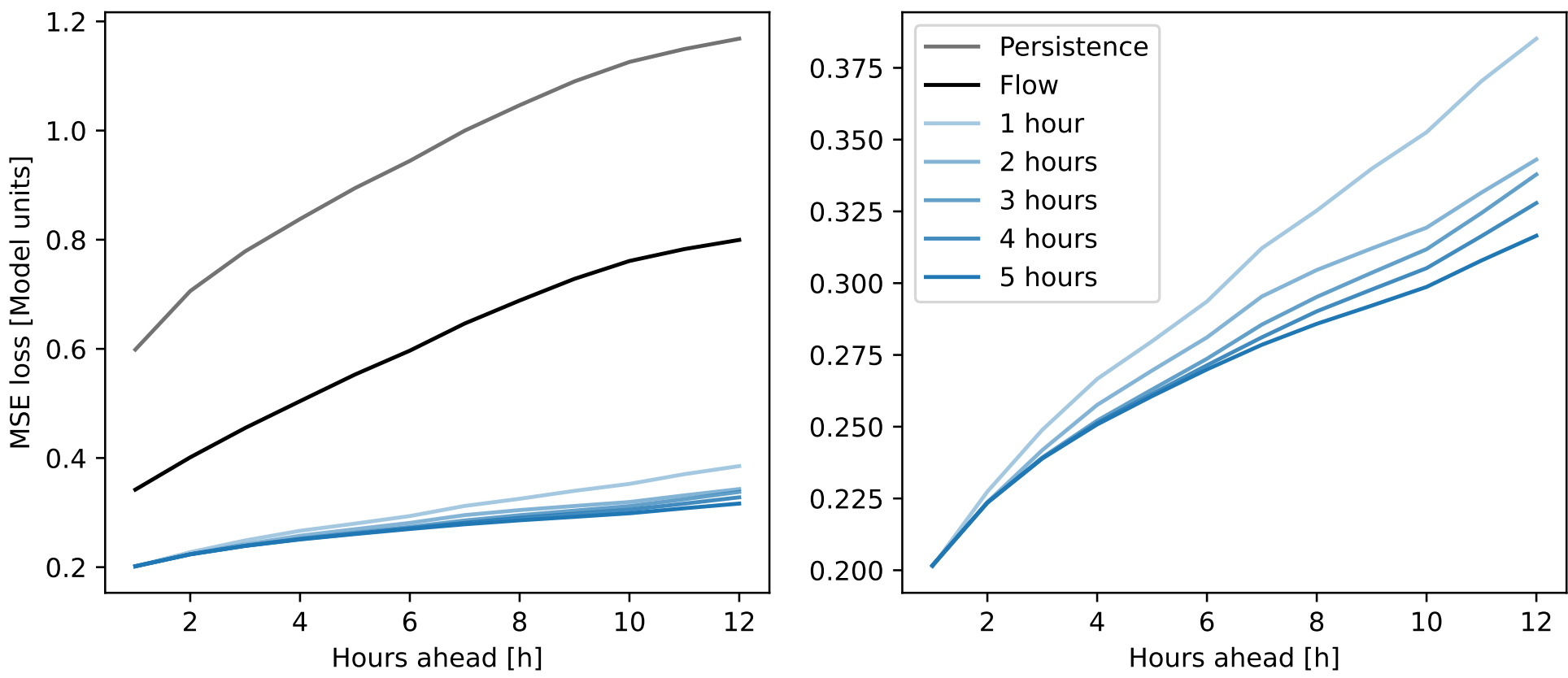
通过预测未来的SDO图像,本文可以初步了解Surya的能力以及预训练协议的有效性。该评估的结果如图5所示。与第一阶段结束后的模型状态相比,展开调优将提前12小时的预测性能分别提高了 10.9%, 12.3%, 14.9%, 和 17.8%。在更长的预测时限上,Surya通过展开调优带来的性能改进尚未达到饱和。
从技术角度来看,在使用80 GB的A100 GPU时,Surya可以在不修改代码的情况下调优至提前24小时预测。这里的限制因素实际上是数据加载速度,GPU经常需要等待数据。未来可能值得进行更长时间限的额外展开调优。
2.5.2 太阳耀斑的视觉预测 Visual prediction of solar flares
图6:Surya模拟的圣帕特里克节事件(St. Patrick’s Day Event)。AIA,131Å波段。顶行左两列为模型输入(“In”)。顶行右两列为模型输出(“Out”)。底行为对应真实值(“GT”)。

为了进一步测试和评估Surya预测未来SDO图像(从而预测太阳未来状态)的能力,本文在一个太阳耀斑事件发生之前初始化Surya。首先,本文在训练数据(即Surya在其预训练期间看到的图像)上进行此操作。图6显示了针对圣帕特里克节事件的结果。比较图6中显示的Surya模型输出,它在UTC时间01:12到02:12之间表现出清晰的演化,与实际观测相符。
当然,这是训练数据的一部分,人们会期望使用MSE目标预训练的模型至少能记住如图6所示的事件。毕竟,耀斑是一个清晰可见的特征,其像素比太阳其余部分亮得多,对MSE分数有强烈影响。因此,关键问题是本文能否在测试数据上做出类似的观测。
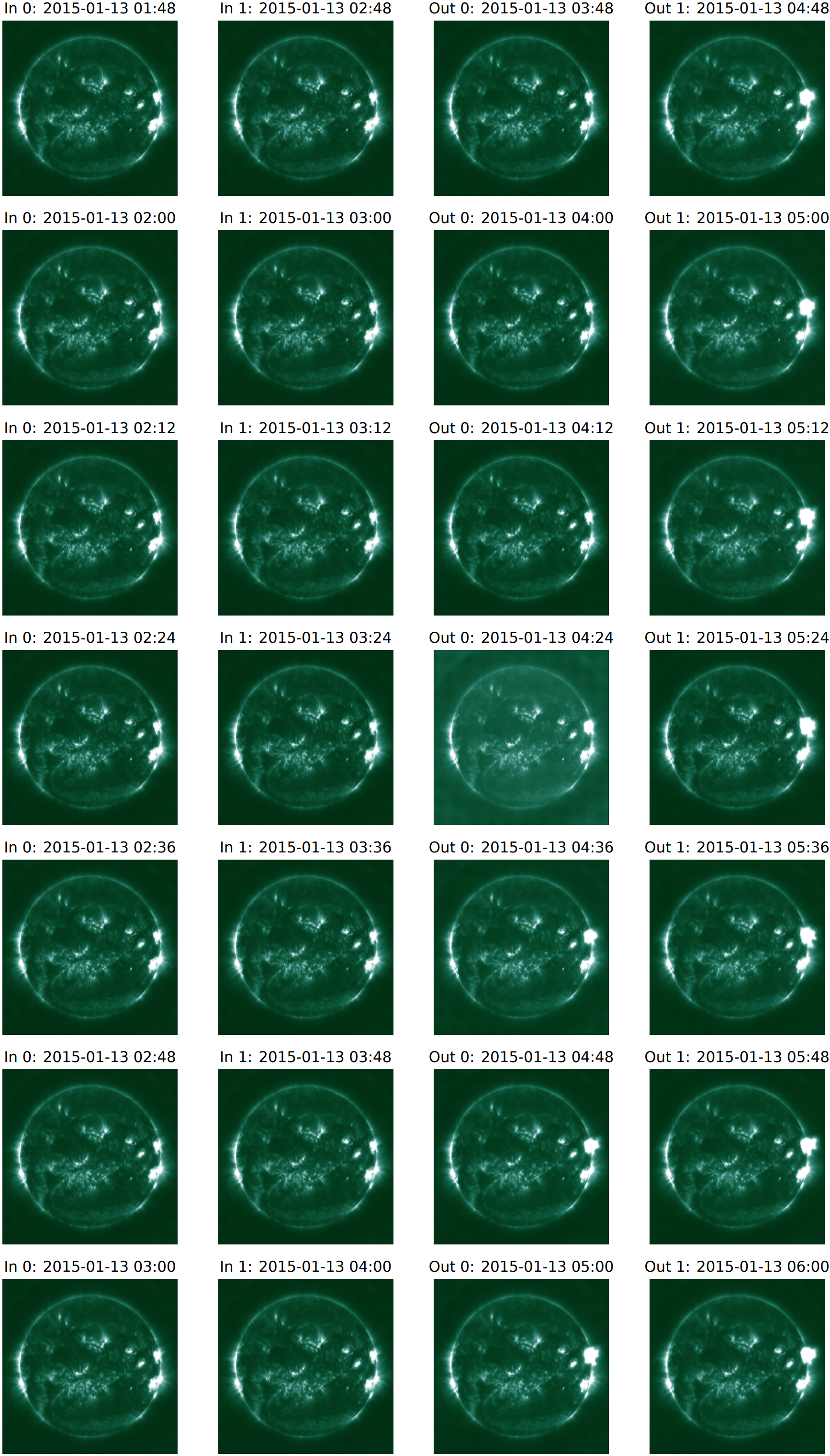
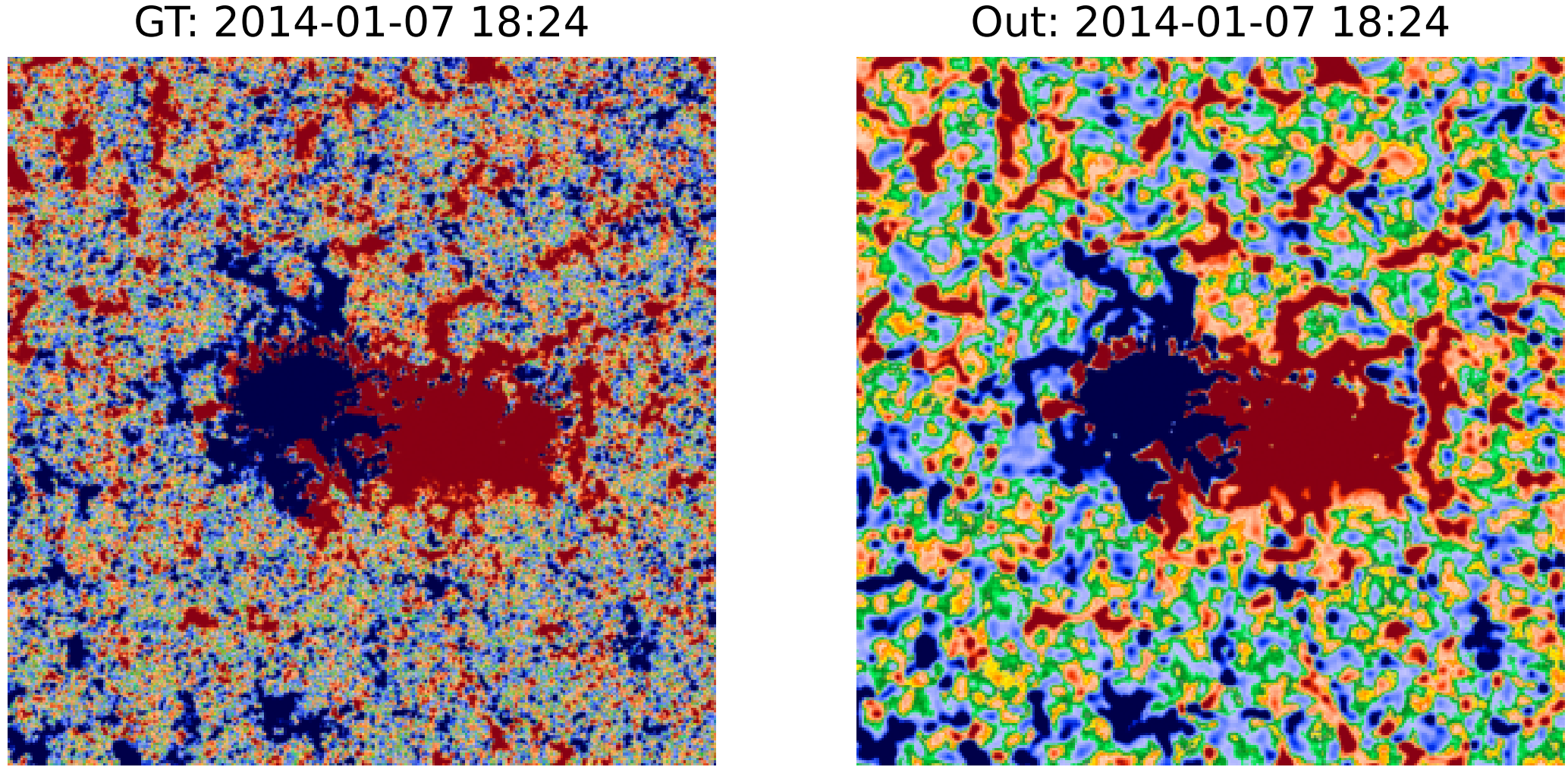
图8、图14以及图1、图12和图13 对此给出了肯定的答案。它们显示了2014年1月7日和2015年1月13日不同初始化时间下的模型输入、输出和真实值。虽然这些并不完全在本文第2.1.2节的测试期内(因为它们位于“时间缓冲区”中),但它们离实际的训练数据足够远,因此泄露和污染(contamination)不是问题。
上述图表显示在94 Å和131 Å通道中有一个强烈的视觉特征在演化。但仅凭这一点并不能让本文将其定性为“耀斑事件”。为此,本文在图7中绘制了2015年1月13日案例的积分辐射(integrated emissions)。
请注意,这里的时间序列是多次运行Surya的组合。每次运行都用两个相隔60分钟的时间戳(照常)初始化,并运行到未来两步(2小时)。值得注意的是,除了1600 Å通道外,Surya的积分输出在所有通道上都紧密跟踪真实值,尤其是在UTC时间04:24左右的快速变化附近。本文将本节讨论的结果视为太阳耀斑事件的视觉预测。这与第2.6节通过微调讨论的传统方法形成对比。
图7:2015年1月13日太阳耀斑事件的积分辐射。即,该图显示了模型输入和输出中所有像素的每通道求和(per-channel sum)。模型在2015年1月13日的多个起始时间初始化,并运行到未来最多2小时(2步)。该时间序列是所有运行的连接(这就是为什么某些时间点显示多个输出)。这与图1和图8的视觉输出相匹配。
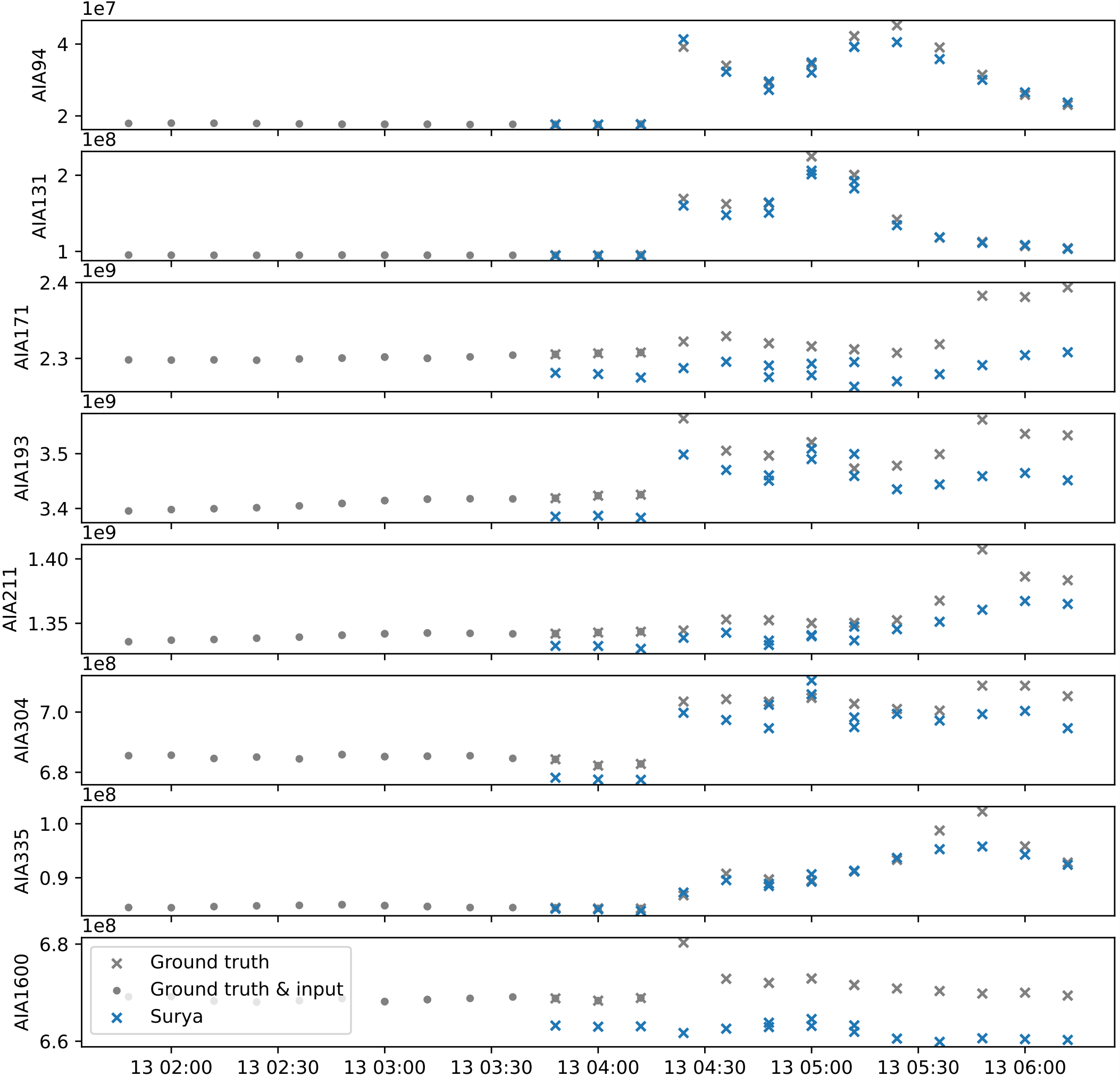
图8:2015年1月13日,不同初始化下的Surya输入和输出。

2.5.3 尖锐特征的模糊化和EUV通道的去噪(Blurring of sharp features and denoising of EUV channels)
图9:真实数据(左)和Surya对应的提前一小时预测输出。171Å波段。图像显示了600x600像素的局部裁剪(local crop)。
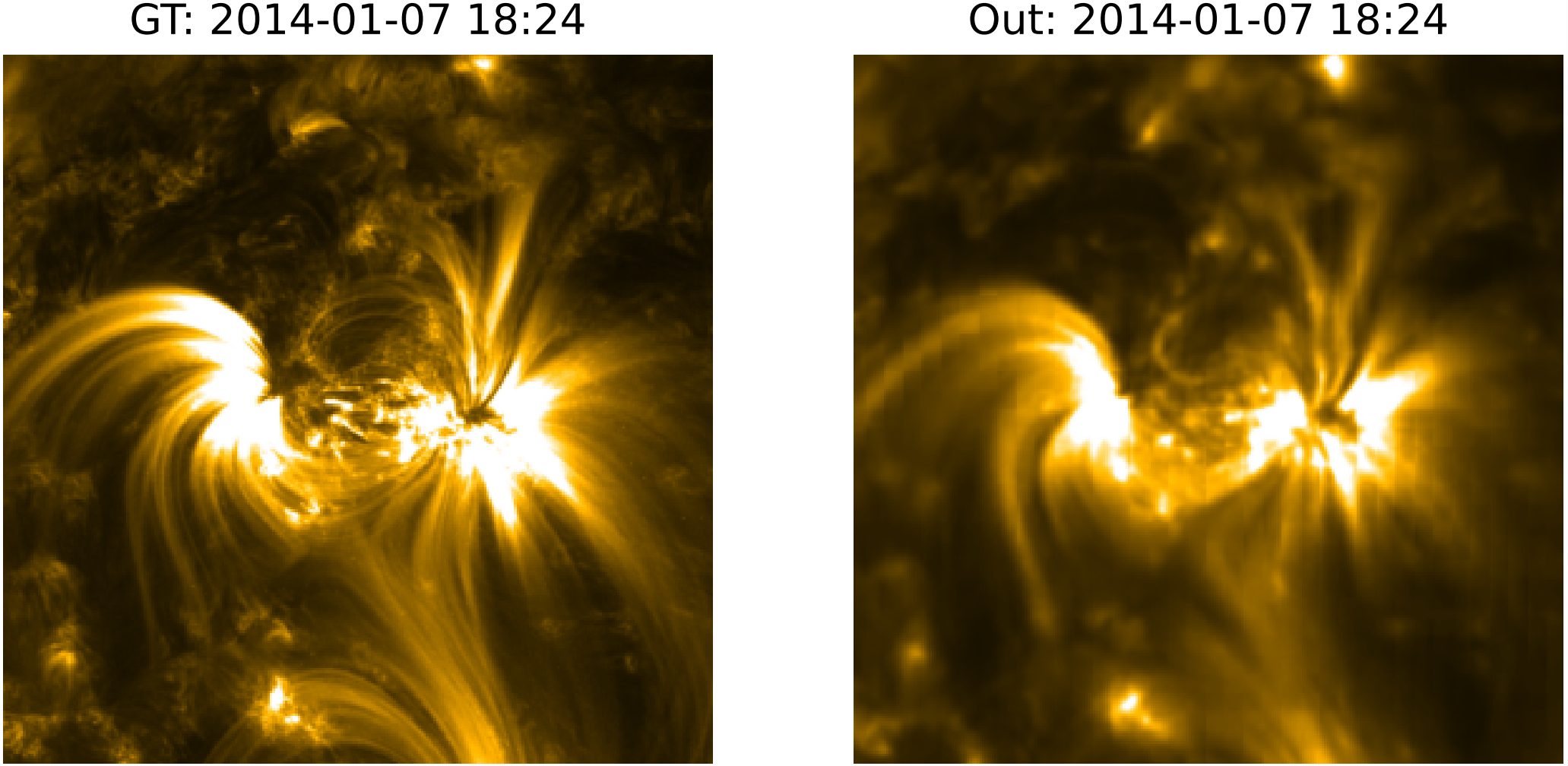
Surya是作为一个完全确定性(fully deterministic) 的模型并使用MSE目标进行训练的。这类模型的一个众所周知的特点是它们倾向于模糊尖锐的特征。
图9和图10显示了Surya在AIA 171 Å以及HMI_m通道上的输出与真实值的局部裁剪。鉴于前述关于Surya架构和预训练目标的选择,本文确实观察到HMI数据中最精细细节的丢失以及AIA波段中的一些模糊。
理论上,可以通过转向概率模型来解决这个问题。这可以通过扩散技术,或通过噪声注入 和合适的损失函数来实现。
本文尝试了后者,在长短程注意力块中使用自适应层归一化(adaptive layer norm) 向模型注入噪声,并在CRPS目标(CRPS objective) 上训练。
但本文发现,虽然它确实产生了改进的细节(特别是在HMI通道中),但它导致了偶尔的标记级伪影(token-level artifacts)。
虽然Surya模糊了高频率、高信噪比的AIA 171 Å通道中的尖锐特征,但它对低信噪比的通道(如AIA 94 Å和AIA 335 Å)产生了积极的去噪效果。
这些通道观测的是太阳大气中最热、能量最高的等离子体(plasma),往往受到低光子数(low photon count) 和高噪声(high amounts of noise) 的影响。Surya有助于使这些数据对分析小尺度特征 更加有用。
图10:真实数据(左)和Surya对应的提前一小时预测输出。HMI_m(磁场强度)。这些图像显示了600x600像素的局部裁剪。
2.6 下游评估(Downstream Evaluation)
2.6.1 微调架构(Fine-tuning architecture)与微调协议(fine-tuning protocol)
微调架构
如第2.2.1节所述,Surya使用预测任务进行预训练。这源于太阳表面和大气的动力学特性(dynamical properties),以及本文的一些下游任务具有明显的预测性质。
另一方面,这在冻结权重(frozen weights) 微调模型时可能带来挑战。
问题在于,通过预训练学习到的表征(即最后一个长短程注意力层的激活值)可以假定是 inherently local 的。
毕竟,在预训练中,本文对这些激活值应用一个线性层,以回归SDO在未来该特定位置看到的图像。这与掩码重建(masked reconstruction) 方法形成对比。
在掩码重建中,编码器学习一个表征,解码器 可以从中重建整个图像。这意味着每个标记学习到的表征可以与其他标记共同用于全局重建。考虑到这一点,本文为Surya实现了多种微调架构。
本文考虑的问题涵盖全局分类(耀斑预测)和回归(太阳风和EUV光谱预测)。
在这里,本文启用了全局平均池化、全局最大池化、注意力池化、Transformer池化,以及最后使用一个全局类别标记(global class token)。本文简要讨论每一种:
-
全局平均和最大池化很简单:聚合最后一个Transformer块 的激活值,并应用一个或几个线性层。这里最适用前一段的评论:对于一个在预测任务上训练的冻结模型,可以假定全局最大池化会返回输出中最突出(最亮)的像素。事实上,如果在太阳耀斑预测中使用带有冻结权重的全局最大或全局平均池化,可以快速获得合理的性能;但所述性能很快达到一个最大值,可以被真正考虑模式而非最大局部激活值的方法所超越。
-
注意力池化在求和激活值之前应用另一个注意力层。
-
Transformer池化引入一个额外的带有专用类别标记(class token) 的注意力块。
-
对于涉及稀有事件(参见太阳耀斑预测)的下游任务,本文发现注意力和Transformer池化引入了太多参数并且过拟合 严重。
-
全局类别标记,本文简单地在频谱门控层 之后引入一个非局部 标记。该标记用可学习权重初始化。与Swin-transformers相比,长短程注意力代码库的一个优势是引入这个类别标记相对简单。
参数高效微调(LoRA)
请注意,以上所有方法都可以与模型的LoRA微调结合使用。事实上,这正是本文获得最强微调结果的方式。
换句话说,为了高效地适配Surya,选定的线性映射(例如,注意力投影(attention projections) 和MLP层)通过一个低秩残差(low-rank residual) 进行增强,而预训练的权重保持冻结。
对于任何目标权重 W_0 ∈ ℝ^(d_out × d_in),LoRA参数化如下:
![]() (18)
(18)
其中 r 是秩,α 是缩放因子。在微调期间,只有适配器参数(adapter parameters) (A, B) 和任何任务特定头部(task-specific head(s)) 被更新;W_0 是固定的。令 S 索引适配层的集合。
产生的优化问题是:
![]() (19)
(19)
其中 λ_lora 对低秩更新进行正则化。
这种重新参数化(reparameterization) 可以解释为在 W_0 的局部切空间(local tangent space) 中学习一个任务特定的低维扰动(low-dimensional perturbation),保留了预训练模型的归纳偏置(inductive biases),同时通过 r 和 α 控制适应能力。
2.6.2 活动区分割(Active region Segmentation)
Table 3:AR Segmentation results comparing baseline models with Surya
Model Params IoU Dice Coeff Unet 9.2 M 0.688 0.801 Surya 4.1 M 0.768 0.853
图11. 活动区域分割结果。上行:日期:2014-02-01,时间:08:12的SDO数据,中行:模型输出分割掩码,下行:Ground Truth。

太阳活动区(ARs) 是与耀斑 和日冕物质抛射(CMEs) 相关的磁复杂结构(magnetically complex structures)。AR中的一个关键特征是极性反转线(Polarity Inversion Line, PIL),即分隔相反磁极性(magnetic polarities) 的边界,其强烈和剪切(sheared) 的形式是爆发(eruptions) 的可靠前兆(precursors)。因此,准确分割包含PIL的AR对于空间天气预报和推进本文对太阳磁复杂性的理解至关重要。
基于阈值处理和形态学(morphology) 的传统AR/PIL检测流程 可解释但脆弱(brittle)——对噪声、参数选择敏感,并且无法捕捉PIL的细小、丝状结构(filamentary structures)。这促使了基于深度学习的分割框架的发展,该框架直接从太阳数据中学习稳健的、多尺度表征。
本文使用全日面 SDO/HMI 视向磁图(line-of-sight magnetograms)(4096×4096)构建了ARPIL数据集,采用了Cai et al. (2020)的方法。使用 ±50 G 的阈值生成正负极性图(polarity maps),经过过滤以移除小于100像素的区域,用10像素的核 进行膨胀,然后相交以提取PIL。仅保留带有PIL的AR,产生了跨越2011年1月至2024年12月的119,454个二值掩码。
作为基线,本文将一个标准的UNet与本文使用LoRA适配微调后的Surya基础模型进行了比较。仅使用410万 可训练参数,Surya实现了比UNet(交并比 IoU 0.688, Dice系数 0.801)更高的分割质量(IoU 0.768, Dice 0.853)。
2.6.3 太阳耀斑预测(Solar Flare Forecasting)
作为下游应用评估的一部分,太阳耀斑预测被表述为一个二分类问题(binary classification problem),其目标是确定在时间点 t 观测后的未来24小时内是否会发生一次显著耀斑(M级或X级)。
预测窗口(prediction window) 定义为 [t, t+24h) 小时。如果在 [t, t+24h) 内最强耀斑的峰值X射线流量(X-ray flux) 超过 θ_max = 10^(-5) W/m²,则该实例(instance) 被标记为正类(positive (flaring))。
给定太阳观测 x_t ∈ ℝ^(C×H×W)(或对于时间序列为 ℝ^(T×C×H×W)),分类器(classifier) 预测:
![]() (20)
(20)
其中:![]()
本文考虑了真实技巧统计量(True Skill Statistic, TSS)、海德克技巧评分(Heidke Skill Score, HSS) 和 F1分数作为评估指标。
-
TSS 衡量区分耀斑和非耀斑事件的能力。范围从-1(反向预测)到+1(完美预测),0表示无技巧,定义为:
TSS = TP/(TP+FN) - FP/(FP+TN)(21) -
HSS 相对于随机机会评估性能,同时考虑命中(hits) 和误报(false alarms)。范围从-1到1,定义为:
HSS = 2 * (TP*TN - FP*FN) / [ (TP+FN)(FN+TN) + (TP+FP)(FP+TN) ](22) -
F1分数是正类(positive class)(即耀斑)的精确率(precision) 和召回率(recall) 的调和平均数(harmonic mean),平衡了假正例(false positives) 和假负例(false negatives),定义为:
F1 = (2 * TP) / (2*TP + FP + FN)(23)
本文的评估结果如表4所示,本文观察到Surya在所有评估指标上都优于 基线模型。
值得注意的是,Surya在使用更少的可训练参数的情况下取得了优异的结果。其在平衡的预报技巧指标(HSS)上的优势凸显了其在处理太阳耀斑预测中类别不平衡 方面的稳健性。
还应注意,这些模型作为概念验证(proof-of-concept) 研究,并未为端到端或业务化预报用途进行优化。
Table 4:The results of flare forecasting evaluation comparing baseline models used in literature Pandey et al. (2023; 2024) with finetuned Surya-based ones
Model TSS HSS F1 AlexNet 0.358 0.398 0.454 ResNet50 0.018 0.028 0.055 Surya 0.436 0.522 0.561
2.6.4 太阳EUV光谱(Solar EUV spectra)建模
准确模拟太阳极紫外辐照度(irradiance) 对于推进空间天气预报至关重要,因为它直接影响卫星功能、通信基础设施和导航系统。挑战在于模拟1343个光谱波段(spectral bands)(范围从5 nm到35 nm)的辐照度,这些波段编码了通过观测捕获的数百万度太阳等离子体(multi-million degree solar plasma) 复杂的空间和时间动力学。
给定时间 t 的多通道太阳图像(multi-channel solar imagery) x_t ∈ ℝ^(C×H×W),目标是估计一个EUV辐照度测量的连续向量(continuous vector) y_t ∈ ℝ^1343:
![]() (24)
(24)
Table 5:EUV spectra modeling results comparing baseline models with Surya
Model MSE MAE MAPE Alexnet 0.0001311409 0.0061858603 1.6834715604 ResNet50 0.0030414662 0.0529725812 8.8635520935 Surya 0.0001260741 0.0045114677 1.4792510271
表5 显示了surya的EUV光谱建模性能与基线模型的比较。本文发现Surya模型在整个光谱范围内的EUV辐照度预测优于本文的基线AlexNet和ResNet50模型。注意到,当前的业务化模型(operational model)——耀斑辐照度光谱模型(Flare Irradiance Spectral Model, FISM)在测试Surya的相同数据集上取得了平均绝对百分比误差(MAPE)1.5% 和 均方误差(MSE) 0.00031,这比Surya的预测差 2.46倍。
尽管Surya的MAPE与FISM相当,但重要的是要注意FISM依赖于多个仪器:EUV变异性实验(EUV Variability Experiment)、太阳辐射与气候实验(Solar Radiation and Climate Experiment)和XUV光度计系统(XUV Photometer System),以及三个不同的代理指标(proxies)(Penticton F10.7 cm射电流量、Mg II核心翼指数和121.6 nm的H I Lyman-α发射),覆盖了从无线电到X射线的波长,而Surya仅依赖于SDO/AIA和HMI数据。
Surya实现的较低MSE表明其在捕获极端事件(如大耀斑)方面的准确性更高。此外,还注意到Surya模型的表现优于Szenicer et al. (2019) 的深度学习模型,后者获得了中位数MAPE(median MAPE) 1.6% 和 最大MAPE(max MAPE) 4.6%。
还注意到,虽然Szenicer et al. (2019) 预测的是特定光谱线 的强度,但Surya生成EVE(Extreme ultraviolet Variability Experiment) 所有光谱区间(spectral bins) 的预测,提供了完整的光谱读出(full spectral readout)。因此,与文献中报道的Szenicer et al. (2019) 的深度学习模型相比,Surya的预测更全面、更好。
2.6.5 太阳风预测(Solar Wind Forecasting)
太阳风预测旨在预测给定空间点(通常是日地系统中的L1点)的太阳风速度,特别是在观测时间 t 之后的4天预测窗口 内。精确预报太阳风速度对于减轻空间天气对卫星通信系统、导航系统和地球电网的不利影响 至关重要。
该数据集包含地球附近太阳风速度的标量测量,从2010-01-01到2023-12-31每小时记录一次,形成了一个时间上丰富、覆盖了太阳活动周大部分时期的数据集。太阳风速度值表现出显著的变异性(variability),范围从 2.4×10² km/s 到 8.8×10² km/s。
给定观测时间 t 的太阳观测数据(如AIA和HMI多通道太阳成像数据),用 x_t 表示,任务是预测时间 t+Δt 的标量太阳风速度,其中 Δt = 4 天:
![]()
其中 x_t ∈ ℝ^(C×H×W) 代表时间 t 的多通道、高分辨率输入图像数据,y_{t+Δt} ∈ ℝ 代表预测的标量太阳风速度。本文选择 4天 的预测范围,对应于太阳风等离子体的典型传播时间。
下表提到了AlexNet(训练18k步)、ResNet50(训练20k步)和Surya(训练10k步)的各种指标。Surya优于基线,在最少的步数 内取得了最佳结果。
Table 6:Solar Wind Prediction results comparing baseline models with Surya
Model RMSE (km s−1) MAE(km s−1) Validation MSE (km2s−2) AlexNet 118.6 95.7 km 13839.49 ResNet50 93.76 74.65 8547.924 Surya 75.92 58.06 5698.62
本文可以对Surya的太阳风预测与文献中报道的一些模型的性能进行定性比较。这些模型中的每一个都考虑来自相同仪器的数据,但它们在不同的时间段上进行评估。这些结果总结在表7中。
Table 7:Solar wind speed prediction results comparing baseline models with Surya
Model RMSE (km s−1) Surya 75.92 WindNet 193 (1,4) Upendran et al. (2020) 84.33 ± 2.31 WindNet 211 (1,4) Upendran et al. (2020) 85.94 ± 4.67 27-day Persistence Ahn et al. (2025) 89 SDO + solar wind speed model Ahn et al. (2025) 68.6 CH features + solar wind speed model: Collin et al. (2025) 61 – 71 MHD selected rotations Mayank et al. (2022) 47 – 85 ESWF using CH features: Reiss et al. (2016) 108.2 WSA model using photospheric B maps: Reiss et al. (2016) 99.5
从表7中,本文发现Surya的太阳风预测优于那些纯粹在SDO/AIA数据或光球层B图(photospheric B maps) 上操作的模型,以及标准的27天持续性基线。
本文还注意到,所选的MHD模型 是在选定的卡林顿旋转(Carrington rotations) 上评估的,参数为每个旋转进行了微调。这相当于在测试集样本上过拟合模型,意味着所选参数不能在整个数据集上泛化。
因此,Surya模型既能在整个太阳活动周上泛化,又击败了文献中的几个专用太阳风速度预测模型。
那些表现出比Surya更好性能的模型也考虑了先前时间步的太阳风速度测量,因此包含了风速状态的记忆度量,这使得与Surya的比较不公平。然而,注意到即使在这种情况下,Surya的性能也接近所述模型,使其离成为有效的业务化模型更近了一步。
3 讨论与结论(Discussion and conclusions)
本文提出了Surya,一个拥有3.66亿参数的日球物理学foundation model,以其原生分辨率4096×4096 和标准化的12分钟时间频率(cadence),基于SDO的AIA和HMI仪器数据进行了训练。
通过在预测任务上进行预训练,Surya学习了通用太阳表征(general-purpose solar representations),能够捕获磁场的精细尺度变率(fine-scale variability) 和太阳大气的大尺度动力学(large-scale dynamics)。
这种预训练策略使模型能够执行太阳活动的零样本(zero-shot) 预测,包括耀斑事件的视觉演化(visual evolution),同时提供可迁移的表征(transferable representations),可以高效地适应各种下游应用。
因此,Surya代表了从狭窄聚焦(narrowly focused)、任务特定(task-specific) 的模型向更通用和可扩展 的日球物理学方法的转变。
这使Surya成为未来日地系统数字孪生(digital twin) 计划的骨干,与欧空局(ESA) 的数字地球孪生(Digital Twin Earth) 和美国国家航空航天局(NASA) 的数字孪生努力保持一致。
--------
一个关键结果是Surya无需额外训练即可预测太阳动力学的能力。例如,在2015年1月耀斑案例中,Surya预测的积分EUV辐射紧密跟踪了观测结果,显示出对与耀斑起始(flare onset) 相关的快速变化的敏感性。
定量来看,与单步预训练 相比,自回归展开调优(autoregressive rollout tuning) 将12小时预测时限 的长期预测技巧(long-range forecasting skill) 提高了高达17.8%。
这些结果表明,该模型不仅仅是记忆过去的模式,而是在某种程度上正在形成物理感知(physics-aware) 的表征。在一小时预测中,它也显著优于(outperforms) 持续性基线(MAE ≈ 0.59)和学习流(learned-flow) 基线(MAE ≈ 0.34)。
--------
对于下游任务的微调,本文采用了参数高效微调(parameter-efficient fine-tuning) 方法LoRA。
对于活动区分割,Surya实现了 0.768的交并比(IoU) 和 0.853的Dice系数,优于U-Net基线(IoU 0.688, Dice 0.801)。
在太阳耀斑预测中,Surya获得了 0.436的TSS、0.522的HSS 和 0.561的F1分数,显著优于AlexNet(TSS = 0.358)和ResNet50(TSS = 0.018)。
对于EUV辐照度建模,它降低了误差,MAE为0.0043,而AlexNet为0.0065,ResNet50为0.0256。
在太阳风速度预测 中,Surya实现了 75.92 km s⁻¹ 的均方根误差(RMSE) 和 58.06 km s⁻¹ 的平均绝对误差(MAE),优于AlexNet(RMSE = 118.6 km s⁻¹)和ResNet50(RMSE = 93.76 km s⁻¹)。
本文进一步注意到,Surya击败了文献中使用SDO/AIA作为唯一输入的模型,同时也优于27天持续性模型。该模型的性能接近于那些使用先前太阳风速度测量 的模型和MHD模型的性能,这显示了基础模型所展示的泛化能力。
然而,本文确实注意到应谨慎对待这种比较,因为验证数据集通常在所有模型中并不完全是相同的时间戳。
--------
本文也观察到一些局限性,可以在未来的工作中改进。作为一个使用MSE目标训练的确定性模型(deterministic model),Surya在磁图和耀斑图像 中表现出尖锐特征的模糊,这是基于回归的生成模型(regression-based generative models) 的常见结果。
概率方法(Probabilistic approaches),如扩散预测(diffusion forecasting) 或使用CRPS等替代损失函数(alternative loss functions) 进行训练,可以通过产生更清晰、更物理真实(physically realistic) 的预测来缓解这个问题。
同样,虽然预测被证明是一种有效的预训练任务,但其他自监督策略,如掩码重建(masked reconstruction) 或波段到波段转换(band-to-band translation),可能会进一步丰富学习到的表征。主要瓶颈不是模型缩放(model-scaling),而是展开训练(rollout training) 期间的数据吞吐量(data throughput),这表明未来大规模的日球物理学基础模型将需要在数据管道 和计算方面进行投资。
--------
总之,Surya代表了首个基于全分辨率SDO数据训练的日球物理学基础模型,建立了一个统一框架,将预测技能与可迁移表征相结合,适用于一系列科学和业务任务。其在分割、分类、回归 和预测 问题上的泛化能力 说明了基础模型在加速科学发现和业务化空间天气预报方面的潜力。
展望未来,本文可以整合多模态、多任务数据集,并采用概率方法,以构建更好、更改进的基础模型,来支持下一代日球物理学和数字孪生计划。
Code and Data Availability
By releasing Surya, its preprocessing pipeline, and downstream evaluation code openly, we align with NASA’s Year of Open Science and the NAIRR pilot, ensuring that the community can build upon this foundation. The model and datasets are publicly available on Huggingface: https://huggingface.co/nasa-ibm-ai4science. Our code for model and downstream tasks is publicly available at https://github.com/NASA-IMPACT/Surya

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献61条内容
已为社区贡献61条内容

所有评论(0)