一句话,AI帮你P图!Qwen-Image-Edit本地部署教程:能转能改能加字
Qwen-Image-Edit基于 20B Qwen-Image 模型,成功地将 Qwen-Image 独特的文本渲染能力扩展到了图像编辑任务中,实现了精确的文本编辑。此外,Qwen-Image-Edit 同时将输入图像馈送到 Qwen2.5-VL(用于视觉语义控制)和 VAE 编码器(用于视觉外观控制),从而在语义和外观编辑方面都具备了能力。
一、模型介绍
Qwen-Image-Edit基于 20B Qwen-Image 模型,成功地将 Qwen-Image 独特的文本渲染能力扩展到了图像编辑任务中,实现了精确的文本编辑。此外,Qwen-Image-Edit 同时将输入图像馈送到 Qwen2.5-VL(用于视觉语义控制)和 VAE 编码器(用于视觉外观控制),从而在语义和外观编辑方面都具备了能力。

- 语义和外观编辑 :Qwen-Image-Edit 支持低级视觉外观编辑(例如添加、删除或修改元素,要求图像的其他区域完全不变)和高级视觉语义编辑(例如 IP 创建、对象旋转和风格转换,允许整体像素变化同时保持语义一致性)。
- 精确文本编辑 :Qwen-Image-Edit 支持双语(中文和英文)文本编辑,允许直接在图像中添加、删除和修改文本,同时保留原始字体、大小和样式。
- 强大的基准性能 :在多个公共基准上的评估表明,Qwen-Image-Edit 在图像编辑任务中达到了最先进的(SOTA)性能,确立了其作为强大基础模型的地位。
二、模型部署
快速部署及使用方法,请通过文末卡片进入算家云,参考“镜像社区”。
基础环境最低配置推荐
| 环境名称 | 版本信息 |
|---|---|
| Ubuntu | 22.04.4 LTS |
| Python | 3.12 |
| CUDA | 12.4 |
| NVIDIA Corporation | RTX 4090 * 4 |
注:该模型支持多卡与单卡
1.更新基础软件包、配置镜像源
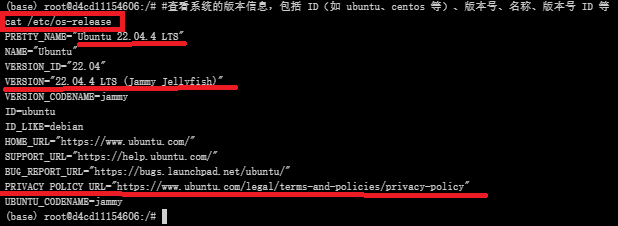
查看系统版本信息
#查看系统的版本信息,包括 ID(如 ubuntu、centos 等)、版本号、名称、版本号 ID 等
cat /etc/os-release
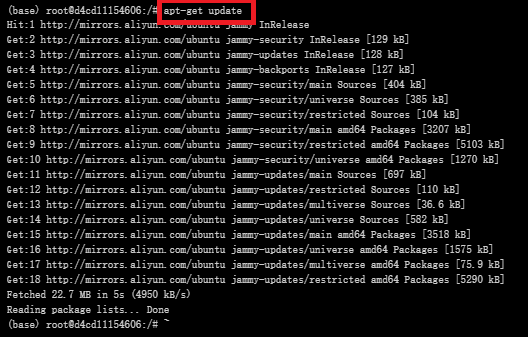
更新软件包列表
#更新软件列表
apt-get update
配置国内镜像源(阿里云)
具体而言,vim 指令编辑文件 sources.list
#编辑源列表文件
vim /etc/apt/sources.list
![]()
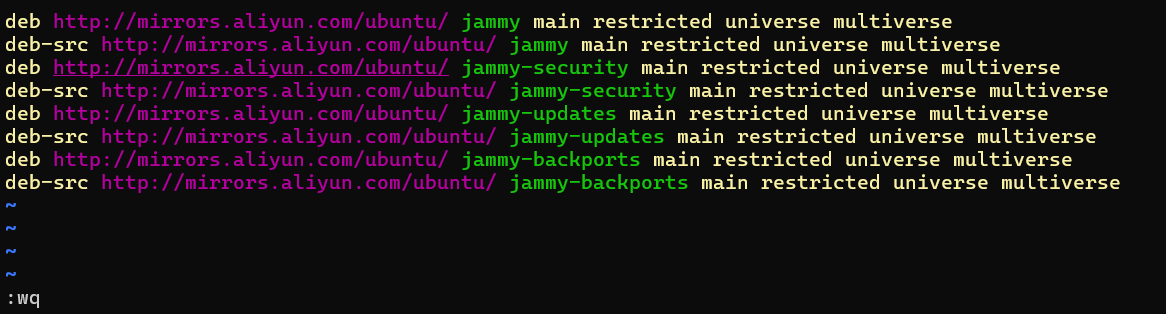
按 “i” 进入编辑模式,将如下内容插入至 sources.list 文件中
deb http://mirrors.aliyun.com/ubuntu/ jammy main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ jammy main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ jammy-security main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ jammy-security main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ jammy-updates main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ jammy-updates main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ jammy-backports main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ jammy-backports main restricted universe multiverse
最后,按 "esc" 键退出编辑模式,输入 :wq 命令并按下 “enter” 键便可保存并退出 sources.list 文件
2.创建虚拟环境
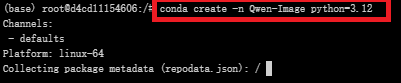
创建虚拟环境
#创建名为Qwen-Image的虚拟环境,python版本:3.12
conda create -n Qwen-Image python=3.12
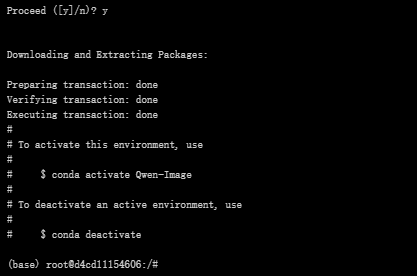
激活虚拟环境
conda activate Qwen-Image
![]()
3.克隆项目
创建 Qwen-Image 文件夹
#创建Qwen-Image文件夹
mkdir Qwen-Image
![]()
![]()
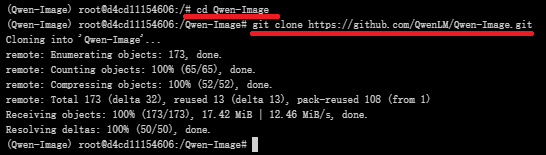
Qwen-Image-Edit模型基于我们的 20B Qwen-Image 模型,故可以直接克隆,github(QwenLM/Qwen-Image:Qwen-Image 是一个强大的图像生成基础模型,能够进行复杂的文本渲染和精确的图像编辑。)中克隆项目代码文件至该目录
#进入Qwen-Image目录
cd Qwen-Image
#克隆仓库
git clone https://github.com/QwenLM/Qwen-Image.git
4.下载依赖
requirements.txt 文件
pip install -r requirements.txt
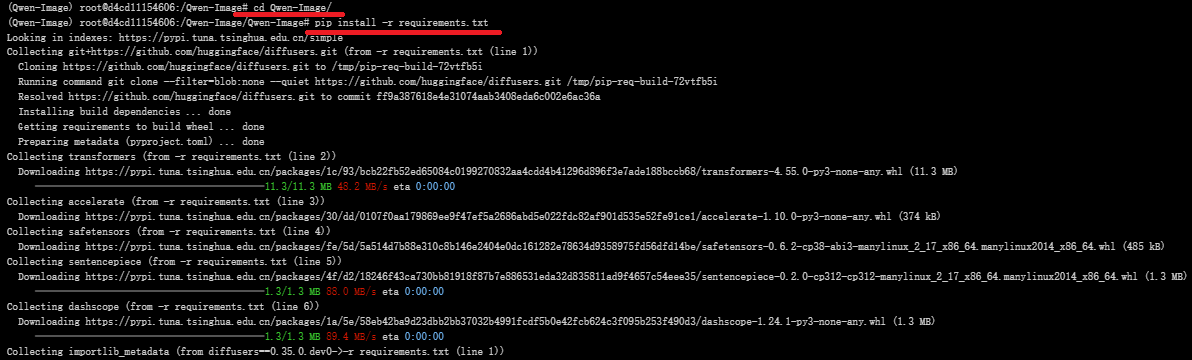
文件内容:
git+https://github.com/huggingface/diffusers.git
transformers
accelerate
safetensors
sentencepiece
dashscope
5.模型下载
转到魔塔社区官网下载模型文件:Qwen-Image · 模型库
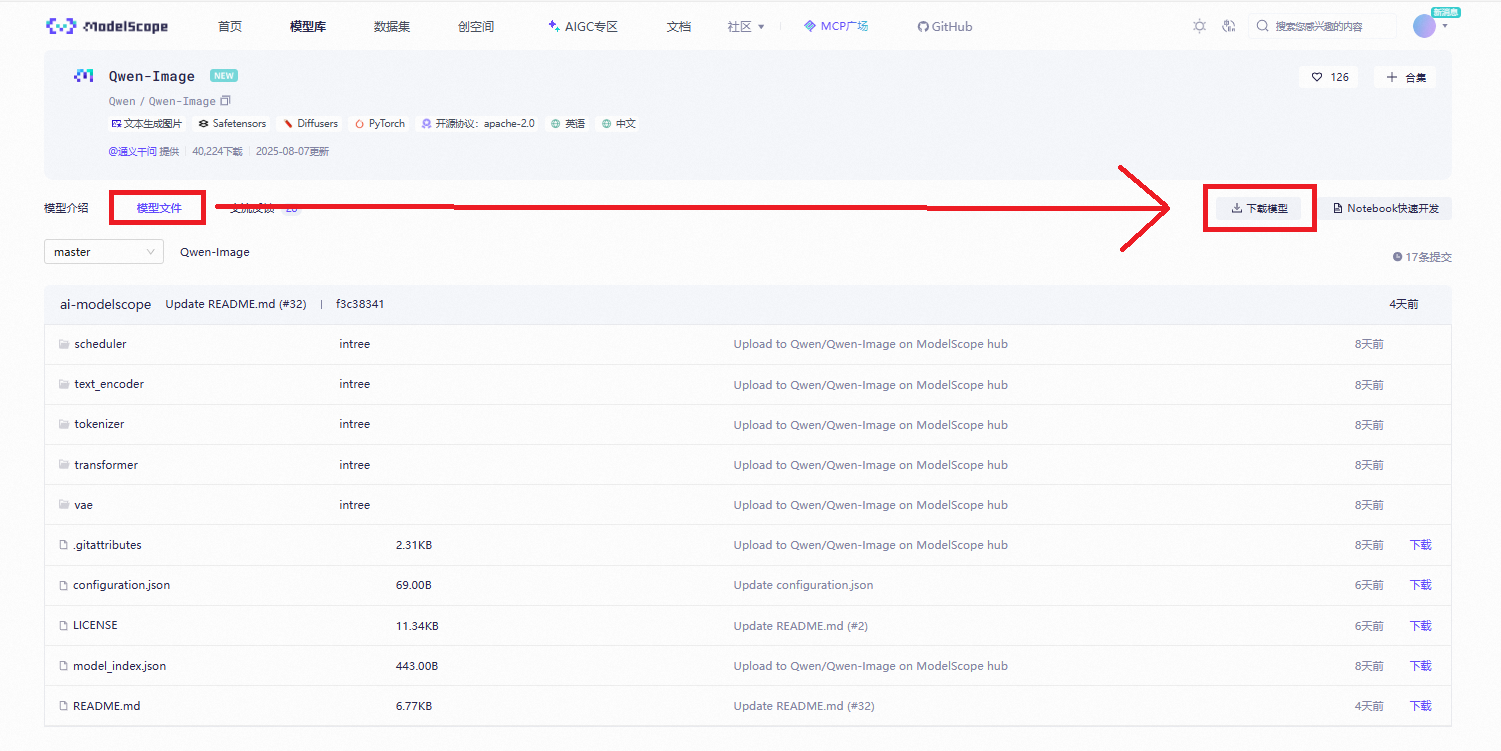
进入堡垒机使用命令行下载完整模型库
#启用代理
source /data/models_and_datasets/Script/SJ-proxy.sh && proxy_on
#下载命令
modelscope download --model Qwen/Qwen-Image-Edit --local_dir /data/models_and_datasets/LargeModel/Qwen-Image-Edit
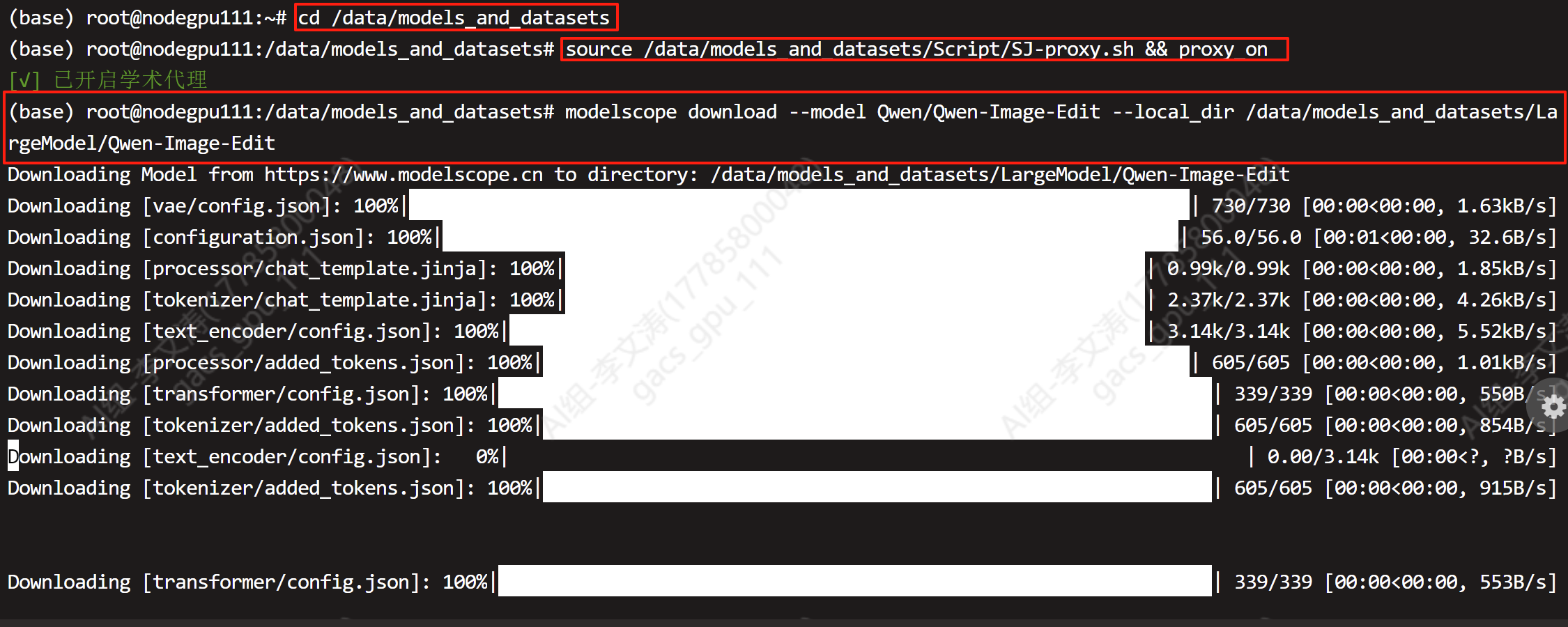
返回实例终端输入命令检查模型是否下载
cd /root/sj-data/LargeModel/Qwen-Image-Edit/Qwen/Qwen-Image-Edit
三、web 页面启动
Qwen-Image-Edit模型没有发布web页面相关代码,自己创建一个app.py文件
import os
import sys
import logging
import traceback
from datetime import datetime
# 设置日志
def setup_logging():
# 创建日志目录
log_dir = "/Qwen-Image/logs"
os.makedirs(log_dir, exist_ok=True)
# 创建日志文件名(带时间戳)
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
log_file = os.path.join(log_dir, f"qwen_image_edit_{timestamp}.log")
# 配置日志
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler(log_file, encoding='utf-8'),
logging.StreamHandler(sys.stdout)
]
)
return logging.getLogger(__name__)
# 初始化日志
logger = setup_logging()
# 环境变量设置
os.environ.setdefault("PYTORCH_CUDA_ALLOC_CONF", "expandable_segments:True,max_split_size_mb:128")
os.environ.setdefault("CUDA_LAUNCH_BLOCKING", "0")
os.environ.setdefault("TOKENIZERS_PARALLELISM", "false")
# 记录环境信息
logger.info("=" * 60)
logger.info("启动 Qwen-Image-Edit 应用")
logger.info("=" * 60)
logger.info(f"Python版本: {sys.version}")
logger.info(f"工作目录: {os.getcwd()}")
try:
import torch
import gradio as gr
from PIL import Image
from diffusers import DiffusionPipeline
logger.info(f"PyTorch版本: {torch.__version__}")
logger.info(f"CUDA可用: {torch.cuda.is_available()}")
if torch.cuda.is_available():
logger.info(f"GPU数量: {torch.cuda.device_count()}")
for i in range(torch.cuda.device_count()):
props = torch.cuda.get_device_properties(i)
logger.info(f"GPU {i}: {props.name}, 显存: {props.total_memory/1024**3:.2f} GiB")
except ImportError as e:
logger.error(f"导入依赖失败: {e}")
logger.error("请确保已安装所有依赖: torch, gradio, Pillow, diffusers")
sys.exit(1)
# 兼容不同 diffusers 版本的 Qwen Image Edit 入口
try:
from diffusers import QwenImageEditPipeline
_HAS_QWEN_EDIT = True
logger.info("成功导入 QwenImageEditPipeline")
except Exception as e:
_HAS_QWEN_EDIT = False
logger.warning(f"无法导入 QwenImageEditPipeline: {e}")
logger.warning("将使用通用的 DiffusionPipeline")
# -------------------------
# 实用函数
# -------------------------
def _gpu_summary() -> str:
if not torch.cuda.is_available():
return "CUDA 不可用,使用 CPU"
parts = []
for i in range(torch.cuda.device_count()):
props = torch.cuda.get_device_properties(i)
parts.append(f"[{i}] {props.name} {props.total_memory/1024**3:.2f} GiB")
return " | ".join(parts)
def _free_cuda():
if torch.cuda.is_available():
torch.cuda.empty_cache()
torch.cuda.synchronize()
def _pick_dtype():
if torch.cuda.is_available():
dtype = torch.bfloat16 if torch.cuda.is_bf16_supported() else torch.float16
logger.info(f"选择数据类型: {dtype}")
return dtype
logger.info("使用CPU模式,数据类型: float32")
return torch.float32
# -------------------------
# 模型初始化
# -------------------------
def init_pipeline(
model_name: str = "/root/sj-data/LargeModel/Qwen-Image-Edit/Qwen/Qwen-Image-Edit",
prefer_balanced: bool = True,
):
logger.info(f"开始初始化模型: {model_name}")
logger.info(f"GPU状态: {_gpu_summary()}")
dtype = _pick_dtype()
n_gpu = torch.cuda.device_count() if torch.cuda.is_available() else 0
max_mem = None
if n_gpu >= 2:
max_mem = {i: "22GiB" for i in range(n_gpu)}
max_mem["cpu"] = "64GiB"
logger.info(f"设置多GPU内存限制: {max_mem}")
def _common_post_init(pipe: DiffusionPipeline):
logger.info("执行通用后初始化步骤")
# 显存优化开关
if hasattr(pipe, "enable_attention_slicing"):
pipe.enable_attention_slicing(slice_size="max")
logger.info("启用注意力切片")
if hasattr(pipe, "enable_vae_slicing"):
pipe.enable_vae_slicing()
logger.info("启用VAE切片")
if hasattr(pipe, "enable_vae_tiling"):
pipe.enable_vae_tiling()
logger.info("启用VAE平铺")
if hasattr(pipe, "set_progress_bar_config"):
pipe.set_progress_bar_config(disable=False)
logger.info("启用进度条")
# flash/Math SDP
try:
torch.backends.cuda.matmul.allow_tf32 = True
torch.backends.cuda.enable_flash_sdp(True)
torch.backends.cuda.enable_mem_efficient_sdp(True)
torch.backends.cuda.enable_math_sdp(True)
logger.info("启用CUDA优化设置")
except Exception as e:
logger.warning(f"CUDA优化设置失败: {e}")
return pipe
common_kwargs = dict(
pretrained_model_name_or_path=model_name,
torch_dtype=dtype,
safety_checker=None,
)
# 多卡均衡
if n_gpu >= 2 and prefer_balanced:
try:
logger.info("尝试 device_map='balanced' + max_memory 多卡均衡切分")
pipe = (QwenImageEditPipeline if _HAS_QWEN_EDIT else DiffusionPipeline).from_pretrained(
**common_kwargs,
device_map="balanced",
max_memory=max_mem,
)
_common_post_init(pipe)
logger.info("初始化成功:balanced")
return pipe, "balanced"
except Exception as e:
logger.error(f"balanced 失败:{e}")
_free_cuda()
# 多卡自动切分
if n_gpu >= 2:
try:
logger.info("尝试 device_map='auto' 多卡自动切分")
pipe = (QwenImageEditPipeline if _HAS_QWEN_EDIT else DiffusionPipeline).from_pretrained(
**common_kwargs,
device_map="auto",
max_memory=max_mem,
)
_common_post_init(pipe)
logger.info("初始化成功:auto")
return pipe, "auto"
except Exception as e:
logger.error(f"auto 失败:{e}")
_free_cuda()
# 单卡 + CPU卸载
try:
logger.info("尝试单卡/CPU 初始化 + 顺序卸载")
pipe = (QwenImageEditPipeline if _HAS_QWEN_EDIT else DiffusionPipeline).from_pretrained(
**common_kwargs,
device_map={"": "cpu"},
)
_common_post_init(pipe)
if hasattr(pipe, "enable_sequential_cpu_offload"):
pipe.enable_sequential_cpu_offload()
logger.info("启用顺序CPU卸载")
else:
pipe.enable_model_cpu_offload()
logger.info("启用模型CPU卸载")
logger.info("初始化成功:sequential_cpu_offload")
return pipe, "sequential_cpu_offload"
except Exception as e:
logger.error(f"sequential_cpu_offload 失败:{e}")
logger.error(traceback.format_exc())
raise RuntimeError("所有初始化策略均失败")
# -------------------------
# 图像编辑
# -------------------------
def edit_image(
pipe: DiffusionPipeline,
prompt: str,
image_path: str,
negative_prompt: str = "",
true_cfg_scale: float = 4.0,
guidance_scale: float = 3.5,
num_inference_steps: int = 25,
seed: int = 42,
):
logger.info(f"开始图像编辑: prompt='{prompt}', 图片路径='{image_path}'")
logger.info(f"参数: true_cfg_scale={true_cfg_scale}, guidance_scale={guidance_scale}, steps={num_inference_steps}, seed={seed}")
if image_path is None or image_path == "":
error_msg = "请先上传一张图片。"
logger.error(error_msg)
raise gr.Error(error_msg)
zh_magic = "超清, 4K, 电影级构图"
if any("\u4e00" <= ch <= "\u9fff" for ch in prompt):
prompt = f"{prompt} {zh_magic}"
logger.info(f"添加中文优化提示: {prompt}")
try:
image = Image.open(image_path).convert("RGB")
logger.info(f"成功加载图片: {image.size}")
except Exception as e:
error_msg = f"无法加载图片: {e}"
logger.error(error_msg)
raise gr.Error(error_msg)
generator = None
if seed is not None and int(seed) >= 0:
device_for_gen = "cuda" if torch.cuda.is_available() else "cpu"
generator = torch.Generator(device=device_for_gen).manual_seed(int(seed))
logger.info(f"设置随机种子: {seed}")
is_cuda = torch.cuda.is_available()
amp_dtype = torch.bfloat16 if (is_cuda and torch.cuda.is_bf16_supported()) else (torch.float16 if is_cuda else torch.float32)
logger.info(f"使用精度: {amp_dtype}")
from contextlib import nullcontext
try:
logger.info("开始推理过程")
_free_cuda()
start_time = datetime.now()
with torch.inference_mode():
ctx = torch.autocast(device_type="cuda", dtype=amp_dtype) if is_cuda else nullcontext()
with ctx:
out = pipe(
image=image,
prompt=prompt,
negative_prompt=negative_prompt or None,
true_cfg_scale=true_cfg_scale,
guidance_scale=guidance_scale,
num_inference_steps=int(num_inference_steps),
generator=generator,
)
end_time = datetime.now()
duration = (end_time - start_time).total_seconds()
logger.info(f"推理完成,耗时: {duration:.2f}秒")
return out.images[0]
except torch.cuda.OutOfMemoryError:
error_msg = "显存不足。请降低步数/强度或使用更小图片。"
logger.error(error_msg)
_free_cuda()
raise gr.Error(error_msg)
except Exception as e:
error_msg = f"生成失败: {str(e)}"
logger.error(error_msg)
logger.error(traceback.format_exc())
raise gr.Error(error_msg)
# -------------------------
# Gradio UI
# -------------------------
def launch_gradio():
try:
model_path = os.environ.get("QWEN_IMAGE_EDIT_PATH", "/root/sj-data/LargeModel/Qwen-Image-Edit/Qwen/Qwen-Image-Edit")
logger.info(f"模型路径: {model_path}")
pipe, strat = init_pipeline(model_path)
logger.info(f"模型初始化完成,策略: {strat}")
with gr.Blocks(
title="Qwen-Image-Edit 图像编辑器",
theme=gr.themes.Soft(primary_hue="blue", secondary_hue="gray")
) as demo:
# 标题
gr.Markdown("# 🎨 Qwen-Image-Edit 图像编辑器")
gr.Markdown("多GPU优化 · 高效显存管理 · 快速图像编辑")
with gr.Row():
# 左侧输入区域
with gr.Column(scale=1):
with gr.Group():
gr.Markdown("### 📝 输入设置")
# 提示词输入
prompt = gr.Textbox(
label="提示词(支持中文)",
placeholder="例如:兔子毛色变为黑色",
lines=2
)
# 负面提示词
negative_prompt = gr.Textbox(
label="负面提示词(可选)",
placeholder="请输入您不需要出现的内容",
lines=2
)
# 图片上传
input_image = gr.Image(
label="上传待编辑图片",
type="filepath",
height=200
)
# 高级设置
with gr.Accordion("⚙️ 高级设置", open=False):
true_cfg_scale = gr.Slider(
label="True CFG 强度",
minimum=1.0,
maximum=10.0,
value=4.0,
step=0.5,
info="数值越高越贴近提示词"
)
guidance_scale = gr.Slider(
label="引导强度",
minimum=1.0,
maximum=10.0,
value=3.5,
step=0.1
)
num_inference_steps = gr.Slider(
label="迭代步数",
minimum=10,
maximum=50,
value=25,
step=5
)
seed = gr.Number(
label="随机种子",
value=42,
precision=0,
step=1
)
# 生成按钮
generate_btn = gr.Button(
"🚀 开始生成",
variant="primary",
size="lg"
)
# 右侧输出区域
with gr.Column(scale=1):
with gr.Group():
gr.Markdown("### 🖼️ 编辑结果")
output_image = gr.Image(
type="pil",
interactive=False,
height=400,
label="生成结果"
)
# 状态显示
status_text = gr.Textbox(
label="状态",
value="等待生成...",
interactive=False
)
# 生成函数
def run_generation(prompt, image_path, negative_prompt, true_cfg_scale, guidance_scale, num_inference_steps, seed):
try:
logger.info("用户点击生成按钮")
yield "正在处理图像...", None
result = edit_image(
pipe=pipe,
prompt=prompt,
image_path=image_path,
negative_prompt=negative_prompt,
true_cfg_scale=true_cfg_scale,
guidance_scale=guidance_scale,
num_inference_steps=num_inference_steps,
seed=seed
)
logger.info("图像生成成功")
yield "生成完成!", result
except Exception as e:
error_msg = f"生成过程中出错: {str(e)}"
logger.error(error_msg)
logger.error(traceback.format_exc())
yield error_msg, None
# 绑定事件
generate_btn.click(
fn=run_generation,
inputs=[prompt, input_image, negative_prompt, true_cfg_scale, guidance_scale, num_inference_steps, seed],
outputs=[status_text, output_image]
)
# 启动设置
try:
demo.queue(max_size=2)
except TypeError:
demo.queue()
logger.info("启动 Gradio 服务...")
demo.launch(
server_name="0.0.0.0",
server_port=8080,
share=False,
show_error=True
)
except Exception as e:
logger.error(f"应用启动失败: {e}")
logger.error(traceback.format_exc())
raise
# -------------------------
# 异常处理
# -------------------------
def handle_exception(exc_type, exc_value, exc_traceback):
if issubclass(exc_type, KeyboardInterrupt):
sys.__excepthook__(exc_type, exc_value, exc_traceback)
return
logger.error("未捕获的异常:", exc_info=(exc_type, exc_value, exc_traceback))
# 设置全局异常处理
sys.excepthook = handle_exception
# -------------------------
# 入口
# -------------------------
if __name__ == "__main__":
try:
launch_gradio()
except Exception as e:
logger.error(f"应用执行失败: {e}")
logger.error(traceback.format_exc())
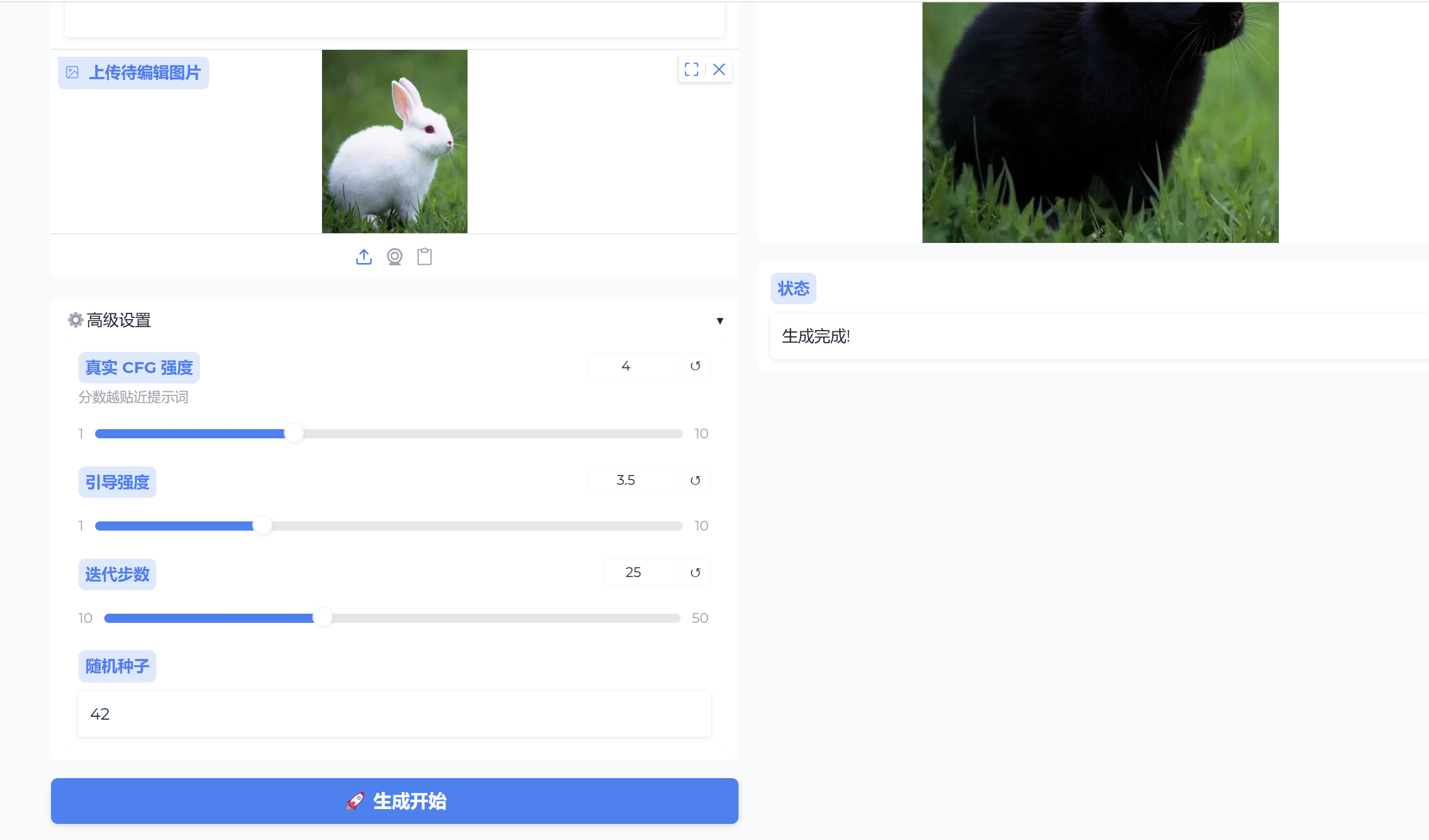
页面展示

用户还可以根据需求,设置高级设置中的各个参数,要达到提高图像质量、缩短生成时间等。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 23
23 0
0- 0



 已为社区贡献34条内容
已为社区贡献34条内容

所有评论(0)