实现自己的AI视频监控系统-第二章-AI分析模块 1
在上一章节我们实现了多路rtsp视频的拉流和解码,并提供了动态的接口形式实现开启和暂停,在本章节,我们将开始AI分析模块的设计,实现真正智能的监控系统。本章节包括但不限于以下内容:常见视觉算法简介、基本视觉算法的实现、多平台模型推理测试、算法的量化加速、多线程多提高分析并发、AI分析模块的代码设计。本章节是重点内容,有疑问或者想了解的请在评论区留言,综合考虑后会动态添加新的内容。计算机视觉作为人工
前言
在上一章节我们实现了多路rtsp视频的拉流和解码,并提供了动态的接口形式实现开启和暂停,在本章节,我们将开始AI分析模块的设计,实现真正智能的监控系统。本章节包括但不限于以下内容:常见视觉算法简介、基本视觉算法的实现、多平台模型推理测试、算法的量化加速、多线程多提高分析并发、AI分析模块的代码设计。本章节是重点内容,有疑问或者想了解的请在评论区留言,综合考虑后会动态添加新的内容。
一、常见的视觉算法简介
计算机视觉作为人工智能领域的重要分支,致力于让计算机能够像人类一样"看懂"图像和视频。随着深度学习技术的快速发展,视觉算法在近年来取得了突破性进展,广泛应用于自动驾驶、医疗影像分析、安防监控、工业检测、增强现实等众多领域。本文将系统介绍常见的视觉算法,从基础图像处理到前沿的深度学习方法。
1. 图像预处理算法
图像预处理是计算机视觉流程的第一步,目的是改善图像质量,为后续处理做准备。
- 图像增强:通过直方图均衡化、对比度拉伸、伽马校正等技术增强图像的视觉效果。直方图均衡化通过重新分布图像的像素值,使直方图尽可能平坦,从而增强图像对比度。自适应直方图均衡化(CLAHE)则是将图像分成小块,对每个小块单独进行直方图均衡化,避免过度增强噪声。
- 图像去噪:常见的去噪算法有高斯滤波、中值滤波、双边滤波等。高斯滤波通过高斯函数对图像进行加权平均,有效去除高斯噪声;中值滤波用像素邻域内的中值替换中心像素,对椒盐噪声有良好效果;双边滤波则同时考虑空间距离和像素值差异,在去噪的同时保持边缘清晰。
- 图像锐化:通过拉普拉斯算子、Unsharp Masking等技术增强图像边缘和细节。拉普拉斯算子是一种二阶微分算子,对图像中的边缘有很强的响应;Unsharp Masking则是通过原图减去模糊后的图像得到细节,再将细节加回原图。
- 图像几何变换:包括缩放、旋转、仿射变换、透视变换等,用于校正图像几何畸变或进行数据增强。插值算法如最近邻插值、双线性插值、双三次插值等在几何变换中起到关键作用。
2. 特征提取算法
特征提取是计算机视觉中的核心环节,目的是从图像中提取有区分度的信息,用于后续的识别、匹配等任务。
- SIFT(尺度不变特征变换):由David Lowe于1999年提出,是一种具有尺度不变性和旋转不变性的特征提取算法。SIFT通过构建高斯金字塔和差分金字塔检测尺度空间极值点,确定关键点的位置、尺度和方向,最后生成128维的SIFT描述子。SIFT对光照变化、几何变换、噪声等具有很强的鲁棒性,但计算复杂度高。
- SURF(加速鲁棒特征):由Herbert Bay等人于2006年提出,是对SIFT的改进。SURF使用盒式滤波器代替高斯滤波,利用积分图像加速计算,大幅提高了运算速度。SURF特征描述子基于Haar小波响应,具有64维或128维,保持了与SIFT相当的鲁棒性,但速度提高了数倍。
- ORB(定向FAST和旋转BRIEF):由Ethan Rublee等人于2011年提出,是一种快速二进制特征描述子。ORB结合了FAST角点检测和BRIEF描述子,并添加了方向计算,使其具有旋转不变性。ORB特征提取速度快,内存占用小,适合实时应用,但对尺度变化和大视角变化的鲁棒性不如SIFT和SURF。
- HOG(方向梯度直方图):由Navneet Dalal和Bill Triggs于2005年提出,主要用于行人检测。HOG通过计算图像局部区域的梯度方向直方图来描述物体外观和形状。HOG特征对光照变化和小幅度位移不敏感,在物体检测任务中表现优异。
3. 目标检测算法
目标检测是计算机视觉中的基础任务,旨在识别图像中的物体并确定其位置。目标检测算法经历了从传统方法到深度学习的演进。
-
传统目标检测算法:
- Viola-Jones检测器:由Paul Viola和Michael Jones于2001年提出,使用Haar-like特征和AdaBoost级联分类器,主要用于人脸检测。该算法通过积分图像快速计算特征,使用AdaBoost选择最具区分度的特征并构建级联结构,实现了实时人脸检测。
HOG+SVM:结合HOG特征和SVM分类器,在行人检测等任务中取得了良好效果。HOG提取图像的梯度方向直方图特征,SVM则用于分类。 - DPM(可变形部件模型):由Felzenszwalb等人于2008年提出,使用可变形部件模型处理物体形变问题。DPM将物体表示为多个部件的集合,通过弹簧模型连接部件,能够处理一定程度的形变和视角变化。
- Viola-Jones检测器:由Paul Viola和Michael Jones于2001年提出,使用Haar-like特征和AdaBoost级联分类器,主要用于人脸检测。该算法通过积分图像快速计算特征,使用AdaBoost选择最具区分度的特征并构建级联结构,实现了实时人脸检测。
-
基于深度学习的目标检测方法:
- R-CNN系列:包括R-CNN、Fast R-CNN、Faster R-CNN等,是两阶段检测器的代表。R-CNN首先使用选择性搜索生成候选区域,然后对每个区域提取CNN特征并分类;Fast R-CNN通过共享卷积计算加速;Faster R-CNN则引入区域提议网络(RPN)替代选择性搜索,实现端到端训练。
- YOLO(You Only Look Once):由Joseph Redmon等人于2016年提出,是单阶段检测器的代表。YOLO将目标检测视为回归问题,直接在整张图像上预测边界框和类别概率,实现了实时检测。后续的YOLOv5、YOLOv8、YOLO11、YOLO12等版本不断改进网络结构和性能。
- SSD(单次多框检测器):由Wei Liu等人于2016年提出,结合了YOLO的回归思想和Faster R-CNN的锚框机制,在不同尺度的特征图上进行检测,对小目标检测效果更好。
- DETR(检测Transformer):由Nicolas Carion等人于2020年提出,首次将Transformer架构应用于目标检测,摒弃了锚框和非极大值抑制等手工设计组件,实现了端到端的目标检测。
4. 图像分割算法
图像分割是将图像划分为多个不同区域或对象的过程,是计算机视觉中的重要任务。
- 传统图像分割方法:
- 阈值分割:通过设定一个或多个阈值将图像分为前景和背景。全局阈值适用于光照均匀的图像,而自适应阈值则根据局部区域特性确定阈值,适合光照不均匀的情况。
- 区域生长:从种子点开始,根据相似性准则(如灰度、颜色、纹理等)逐步合并相邻像素,形成分割区域。区域生长算法简单直观,但对种子点选择和相似性准则敏感。
- 分水岭算法:将图像视为地形图,灰度值代表高度,从局部极小值开始"淹没"图像,形成分割区域。分水岭算法对微弱边缘敏感,容易产生过分割问题,通常需要与其他方法结合使用。
- 基于深度学习的图像分割方法:
- FCN(全卷积网络):由Jonathan Long等人于2015年提出,是首个端到端的深度学习图像分割网络。FCN将全连接层替换为卷积层,使网络可以接受任意尺寸的输入图像,并通过上采样恢复空间分辨率,实现像素级预测。
- U-Net:由Olaf Ronneberger等人于2015年提出,专为医学图像分割设计。U-Net采用编码器-解码器结构,编码器提取特征,解码器恢复空间分辨率,并通过跳跃连接将编码器不同层次的特征融合到解码器中,有效保留细节信息。
- Mask R-CNN:由Kaiming He等人于2017年提出,在Faster R-CNN的基础上添加了分割分支,实现了实例分割(同时检测和分割)。Mask R-CNN采用RoIAlign替代RoIPooling,解决了区域不对齐问题,提高了分割精度。
- yolo-seg:yolo系列的分割算法
5. 人脸识别算法
人脸识别是计算机视觉中的重要应用,涉及人脸检测、特征提取和匹配等步骤。
- 人脸检测算法:
- MTCNN(多任务级联卷积网络):由Kaipeng Zhang等人于2016年提出,采用三阶段级联网络结构同时完成人脸检测和关键点定位。MTCNN在不同尺度的图像上运行,通过P-Net、R-Net和O-Net三个网络逐步筛选和精炼人脸候选框,实现了高精度的人脸检测。
- RetinaFace:通过深度神经网络直接回归人脸边界框和关键点位置,在复杂场景下仍能保持高精度。
- 人脸特征提取与匹配算法:
- DeepFace:由Facebook团队于2014年提出,使用9层深度神经网络提取人脸特征,在LFW数据集上达到了接近人类的准确率。
- FaceNet:由Google团队于2015年提出,通过三元组损失函数学习人脸嵌入,使得同一个人的不同图像在特征空间中距离更近,不同人的图像距离更远。FaceNet在多个基准测试中取得了当时最好的结果。
- ArcFace:由Jiankang Deng等人于2019年提出,通过添加角度间隔增强类间区分度,进一步提高了人脸识别的准确率。ArcFace及其变体(如CosFace、SphereFace等)已成为当前人脸识别的主流方法。
6. 三维视觉算法
三维视觉算法旨在从二维图像中恢复三维结构信息,是实现场景理解、机器人导航、增强现实等应用的关键。
- 立体视觉:通过两个或多个相机从不同视角拍摄同一场景,计算视差并恢复深度信息。立体视觉算法包括特征匹配、视差计算和深度估计等步骤。传统的立体匹配算法如BM(块匹配)、SGBM(半全局块匹配)等,而基于深度学习的方法如PSMNet、GC-Net等通过端到端学习提高了匹配精度。
- SLAM(同步定位与地图构建):同时进行定位和地图构建,是机器人导航和AR/VR的核心技术。SLAM算法分为基于滤波的方法(如EKF-SLAM、FastSLAM)和基于优化的方法(如PTAM、ORB-SLAM)。近年来,深度学习也被引入SLAM领域,如DSO(直接稀疏里程计)、VINS-Mono等算法在视觉里程计方面取得了显著进展。
- 深度估计:从单张图像中估计深度信息。传统方法利用阴影、纹理、透视等线索进行深度估计,而基于深度学习的方法如Monodepth2、MiDaS等通过监督或自监督学习实现了高精度的单目深度估计。
7. 视觉Transformer
Transformer最初在自然语言处理领域取得巨大成功,近年来也被引入计算机视觉领域,形成了视觉Transformer(Vision Transformer, ViT)系列模型。
- ViT(视觉Transformer):由Dosovitskiy等人于2020年提出,首次将纯Transformer架构应用于图像分类任务。ViT将图像分割成固定大小的块,线性嵌入后添加位置编码,然后输入标准的Transformer编码器。在大规模数据集上预训练后,ViT在多个图像分类基准上超越了CNN模型。
- Swin Transformer:由Liu等人于2021年提出,引入了层次化结构和移动窗口机制,使Transformer更适合视觉任务。Swin Transformer在图像分类、目标检测和语义分割等多个任务上都取得了当时最好的结果。
- 视觉Transformer在目标检测和分割中的应用:如DETR、Swin Transformer检测器、SETR、SegFormer等,将Transformer的自注意力机制用于目标检测和图像分割,实现了全局上下文建模和端到端处理。
8.其它
- 未来视觉算法的发展趋势可能包括:多模态融合、自监督学习、小样本学习、高效推理、可解释性AI以及三维视觉与物理世界交互等。随着计算能力的提升和算法的不断创新,视觉算法将在更多领域发挥重要作用,推动人工智能技术的进一步发展和应用。
二、初识目标检测算法
1. 目标检测算法详解
目标检测是计算机视觉的核心任务之一,其目标是在图像或视频中识别出特定类别的物体,并用边界框(Bounding Box)精确标出它们的位置。它比图像分类(只判断整张图是什么)更复杂,比图像分割(精确到像素级)更粗粒度但计算效率更高。
- 目标检测的核心挑战
尺度变化: 同一类物体在图像中可能大小差异巨大(如远处的小车和近处的大车)。
视角变化: 物体可能以不同角度、姿态出现。
遮挡: 物体可能被其他物体部分或完全遮挡。
光照变化: 不同光照条件影响物体外观。
背景干扰: 复杂背景中区分目标物体。
实时性要求: 许多应用(如自动驾驶、视频监控)需要高帧率处理。
小目标检测: 检测图像中占比很小的物体(如远处行人、卫星图像中的车辆)。
-
目标检测算法的演进历程
目标检测算法大致经历了三个主要阶段:
-
阶段一:传统方法(基于手工特征 + 滑动窗口)
- 核心思想:
- 特征提取: 使用手工设计的特征描述子(如 HOG - 方向梯度直方图、Haar 小波、SIFT - 尺度不变特征变换)来表示图像局部区域。
- 滑动窗口: 在图像上以不同尺度和位置滑动一个固定大小的窗口。
- 分类器: 对每个窗口提取的特征,使用训练好的分类器(如 SVM - 支持向量机、AdaBoost)判断该窗口内是否包含目标物体以及是什么类别。
- 代表算法:
Viola-Jones (Haar + AdaBoost): 早期人脸检测的里程碑,速度较快,但主要针对刚性物体。
HOG + SVM: 广泛用于行人检测,对形变有一定鲁棒性。 - 缺点:
- 计算效率极低: 需要穷举所有位置和尺度,速度慢,难以满足实时需求。
- 特征表达能力有限: 手工特征难以捕捉复杂语义和外观变化。
- 对遮挡和形变敏感。
- 核心思想:
-
阶段二:两阶段检测器(Two-Stage Detectors)
- 核心思想: 将检测过程分解为两个阶段:
- 区域提议(Region Proposal): 首先在图像中找出可能包含物体的候选区域(Region of Interest, RoI)。这些区域通常数量远少于滑动窗口(如几千个 vs 几百万个)。
- 分类与回归: 对每个候选区域,进行精细的分类(判断具体类别)和边界框回归(微调边界框位置和大小)。
- 代表算法:
- R-CNN (Regions with CNN features): 开创性工作,首次将 CNN 引入目标检测。使用选择性搜索(Selective Search)生成区域提议,对每个区域裁剪并输入 CNN 提取特征,再用 SVM 分类和线性回归调整框。速度极慢(GPU 上处理一张图需数十秒)。
Fast R-CNN: 改进 R-CNN。将整张图输入 CNN 一次得到特征图,然后在特征图上提取 RoI 特征(使用 RoI Pooling 层),共享计算,速度显著提升。 - Faster R-CNN: 里程碑式突破。引入 区域提议网络(Region Proposal Network, RPN)。RPN 是一个小的全卷积网络,直接在 CNN 提取的特征图上生成高质量的区域提议,取代了耗时的选择性搜索,实现了端到端的训练和检测,速度和精度大幅提升,成为两阶段检测器的标杆。
- Feature Pyramid Networks (FPN): 解决了多尺度检测问题。构建特征金字塔,将高层强语义特征与高层强定位特征融合,使网络能同时检测大物体和小物体,显著提升小目标检测性能。常与 Faster R-CNN 等结合使用。
- Mask R-CNN: 在 Faster R-CNN 基础上扩展,增加了一个并行的分支用于预测每个 RoI 的像素级分割掩码(Mask),实现了实例分割(Instance Segmentation)。
- R-CNN (Regions with CNN features): 开创性工作,首次将 CNN 引入目标检测。使用选择性搜索(Selective Search)生成区域提议,对每个区域裁剪并输入 CNN 提取特征,再用 SVM 分类和线性回归调整框。速度极慢(GPU 上处理一张图需数十秒)。
- 优点:
- 精度高: 两阶段处理(先粗定位再精细分类回归)通常能达到更高的检测精度(mAP)。
- 定位准: 边界框回归效果通常更好。
- 缺点:
- 速度相对较慢: 即使是 Faster R-CNN,在实时性要求高的场景(如 30+ FPS)仍有压力。
- 结构相对复杂。
- 核心思想: 将检测过程分解为两个阶段:
-
阶段三:单阶段检测器(One-Stage Detectors)
- 核心思想: 省略区域提议阶段,直接在图像上密集采样(预设固定网格或锚框),一次性预测所有物体的类别和位置。追求极致的速度。
- 代表算法:
-
YOLO (You Only Look Once): 开创单阶段检测先河。将图像划分为 SxS 网格,每个网格负责预测中心点落在该网格内的物体。每个网格预测 B 个边界框(包含位置、大小、置信度)和 C 个类别的概率。速度极快(YOLOv1 在 Titan X 上达 45 FPS),但早期版本精度不如两阶段,对小目标检测和密集物体检测效果一般。
- YOLO 系列持续进化:
- v3: 引入 FPN 思想(多尺度预测)、Darknet-53 主干网络、更好的锚框聚类,精度大幅提升,速度依然很快。
- v4/v5: 引入大量先进的训练技巧(如 Mosaic 数据增强、自对抗训练、CSPNet 主干、PANet 特征融合、SPP 模块等)和新的激活函数/归一化层,在保持高速度的同时,精度逼近甚至超越两阶段检测器。Ultralytics YOLOv5 是 v5 的一个极其流行且易用的实现。
- v7: 引入可重参数化卷积(RepConv)、模型缩放策略等,进一步优化速度和精度平衡。
- v8: Ultralytics 的最新力作。采用无锚框(Anchor-Free)设计、解耦头(Decoupled Head)、新的损失函数(DFL + CIoU),在速度、精度和易用性上再次达到新高度,成为当前最主流的目标检测框架之一。
- v11:yolo11在v8基础上修改了模型深度和宽度,修改了 backbone 的内部结构(C2f 更换为 C3k2),在 SPPF 后增加了一层 C2PSA,Head 检测头内部 cv3,分类头变为并行的 DWConv 处理。
- v12:提出区域注意力模块(A2, Area Attention),引入了残差高效层聚合网络(R-ELAN),引入 FlashAttention 以解决注意力机制的内存访问问题,移除位置编码加速推理,是attention在yolo系列模型上的成熟应用。
- YOLO 系列持续进化:
-
SSD (Single Shot MultiBox Detector): 结合了 YOLO 的回归思想和锚框(Anchor Box)机制。在特征图的不同层级(多尺度)上使用不同大小和长宽比的预设锚框进行预测。兼顾速度和精度,对小目标检测比早期 YOLO 好。
RetinaNet: 解决单阶段检测器精度普遍低于两阶段的关键问题。提出 Focal Loss,有效解决了训练过程中大量简单负样本(背景)主导梯度、淹没难样本(目标)的问题。显著提升了单阶段检测器的精度,使其达到甚至超越当时两阶段检测器的水平。 -
其他: FCOS (Fully Convolutional One-Stage)、CenterNet (基于关键点检测)、YOLOX (基于 YOLOv3 的改进,引入解耦头、SimOTA 标签分配、强数据增强) 等。
-
- 优点:
- 速度极快: 单次前向传播完成检测,非常适合实时应用。
- 结构相对简单: 端到端训练和推理。
- 精度持续提升: 随着技术进步(如 Focal Loss, 先进主干网络,特征融合,标签分配策略),现代单阶段检测器精度已与两阶段相当甚至更高。
- 缺点:
- 早期版本精度较低: 已被现代单阶段检测器克服。
- 对密集小物体检测可能仍有挑战: 虽然通过多尺度预测和改进设计(如 YOLOv8)已大幅改善。
- 关键技术组件
- 主干网络(Backbone): 负责从输入图像中提取多尺度特征图。常用:VGG, ResNet, ResNeXt, DarkNet (YOLO 系列), CSPNet, EfficientNet, MobileNet (轻量化), Vision Transformer (ViT, Swin Transformer - 用于更高精度场景)。
- 颈部网络(Neck): 融合主干网络提取的不同层级的特征图,增强多尺度表示能力。常用:FPN (自顶向下), PANet (FPN + 自底向上), BiFPN (双向加权融合)。
- 头部网络(Head): 基于融合后的特征图进行最终预测(类别概率和边界框坐标)。设计包括:
- 锚框 vs 无锚框: 锚框预设参考框,学习偏移量;无锚框直接预测物体中心点或关键点。
- 耦合头 vs 解耦头: 耦合头同时预测类别和位置;解耦头分开预测,通常效果更好。
- 损失函数(Loss Function): 驱动模型学习。通常包含:
- 分类损失(Classification Loss): 如交叉熵损失(Cross-Entropy Loss), Focal Loss(解决类别不平衡)。
- 定位损失(Localization Loss): 如 L1/L2 Loss, IoU Loss, GIoU Loss, DIoU Loss, CIoU Loss(更符合检测任务评价标准), Distribution Focal Loss (DFL - YOLOv8)。
- 置信度损失(Confidence Loss): 判断锚框/预测框内是否有物体(如二元交叉熵)。
- 非极大值抑制(Non-Maximum Suppression, NMS): 后处理步骤,用于消除对同一物体的冗余检测框(保留置信度最高的框,抑制与其 IoU 过高的框)。
- 评价指标
- IoU (Intersection over Union): 预测框与真实框的交并比,衡量定位精度。
- Precision & Recall: 精确率(预测为正中真正为正的比例)和召回率(所有真实正例中被正确预测的比例)。
- AP (Average Precision): 单个类别的平均精度,是 Precision-Recall 曲线下的面积。
- mAP (mean Average Precision): 所有类别 AP 的平均值,是目标检测最核心的综合评价指标。常用mAP@0.5(IoU 阈值 0.5)和 mAP@0.5:0.95(IoU 阈值从 0.5 到 0.95,步长 0.05,计算平均 mAP,更严格)。
2.Ultralytics 框架简介
Ultralytics 不仅仅是一个算法,它是一个开源的、以 YOLO 系列为核心、集训练、验证、部署、追踪于一体的现代化计算机视觉框架。它极大地降低了使用最先进目标检测(以及分割、分类、姿态估计)模型的门槛。
- 核心定位与目标
口号: “Train, validate and deploy YOLO models with ease.” (轻松训练、验证和部署 YOLO 模型)。
核心目标: 让最前沿的计算机视觉模型(尤其是 YOLOv5/v8)变得极其易用、高性能、可扩展,服务于研究、开发和生产环境。 - 核心特性与优势
-
易用性 (Usability) - 核心杀手锏:
极简 API: 提供高度抽象的 Python API (ultralytics.YOLO)。几行代码即可完成模型加载、训练、验证、预测、导出,且接口稳定。from ultralytics import YOLO # 加载预训练模型 model = YOLO('yolov8n.pt') # 'n' 表示 nano 版本 # 训练模型 results = model.train(data='coco128.yaml', epochs=100, imgsz=640) # 验证模型 metrics = model.val() # 预测单张图片 results = model('path/to/image.jpg') # 导出模型 (如 ONNX) model.export(format='onnx') -
高性能 (Performance):
- 基于 PyTorch: 充分利用 PyTorch 的灵活性和 GPU 加速能力。
- 优化实现: 对 YOLOv5/v8 的核心组件(如骨干、颈部、头部、损失函数)进行了高度优化,确保训练和推理速度达到顶尖水平。
- 多尺度训练/预测: 内置支持,提升模型鲁棒性。
- 混合精度训练 (AMP): 自动启用,加速训练并减少显存占用。
- 分布式训练: 支持 DataParallel 和 DistributedDataParallel,可利用多 GPU 加速训练。
-
先进模型 (State-of-the-Art Models):紧跟时代发展,涵盖yolo12,rtdetr、SAM等多种视觉先进模型
-
任务扩展: 不仅支持目标检测 (detect),还原生支持:
- 实例分割 (segment): YOLOv8-Seg。
- 图像分类 (classify): 基于 YOLO 骨干或 ViT 的分类器。
- 姿态估计 (pose): YOLOv8-Pose,检测人体关键点。
- 目标追踪 (track): 集成 BoT-SORT 或 ByteTrack 算法,实现视频流中的多目标追踪。
-
强大的数据集支持与预处理:
- 自动数据集加载: 支持 YOLO 格式的 data.yaml 文件,自动解析数据集路径、类别信息、训练/验证集划分。
- 内置数据增强: 提供丰富且可配置的数据增强策略(如 Mosaic, MixUp, HSV 调整, 仿射变换, 剪裁等),显著提升模型泛化能力。
- 自动缓存: 支持将预处理后的数据缓存到 RAM 或磁盘,加速训练。
-
训练与验证:
- 丰富的训练选项: 可配置学习率、优化器 (SGD, Adam, AdamW)、权重衰减、动量、批量大小、图像尺寸、训练轮次、早停策略等。
- 实时监控: 集成 TensorBoard 和 Comet 等工具,实时可视化训练过程中的损失、学习率、mAP 等指标。
- 自动验证: 训练过程中和训练结束后自动在验证集上评估模型性能 (mAP, precision, recall 等)。
- 模型保存: 自动保存最佳模型(基于验证集 mAP)和最终模型。
-
预测与推理:
- 多源输入: 支持图片、视频流、摄像头、目录、多种 URL 协议 (RTSP, HTTP 等) 作为输入源。
- 灵活输出: 可返回结果对象(包含边界框、掩码、关键点、置信度、类别等信息),或直接保存带标注的图片/视频。
- 高性能推理: 优化推理速度,支持批处理。
- 追踪集成: 一行代码即可在预测时启用目标追踪。
-
模型导出与部署:
多格式导出: 支持将训练好的 PyTorch 模型导出为多种部署友好的格式:- ONNX: 跨平台标准,支持 ONNX Runtime, TensorRT 等。
- TensorRT: NVIDIA GPU 上的高性能推理引擎。
- CoreML: Apple 设备 (iOS, macOS)。
- TensorFlow SavedModel / TFLite: TensorFlow 生态,尤其适合移动端和嵌入式设备 (TFLite)。
- OpenVINO: Intel CPU/GPU/VPU。
- PaddlePaddle: 百度飞桨框架。
-
活跃的社区与生态:
- GitHub 星标众多: Ultralytics YOLOv5 和 YOLOv8 仓库是 GitHub 上最活跃的计算机视觉项目之一。
- 详尽文档: 提供非常全面的官方文档,涵盖安装、使用、API 参考、教程、常见问题解答。
- 社区支持: 拥有庞大的用户社区,在 GitHub Discussions、Discord 等渠道提供活跃的技术支持和经验分享。
-
HUB: Ultralytics 提供云端平台 (Ultralytics HUB),用于数据集管理、模型训练、版本控制、协作和部署(部分功能需订阅)。
-
- 使用场景
- 快速原型开发: 研究人员和开发者可以迅速用 YOLOv5/v8 验证想法。
- 学术研究: 作为基准模型或进行改进研究的起点。
- 工业应用: 广泛应用于:
- 工业质检: 检测产品缺陷、异物。
- 安防监控: 行人检测、车辆检测、异常行为识别。
- 自动驾驶: 检测车辆、行人、交通标志、车道线。
- 医疗影像: 检测病灶、细胞计数。
- 农业: 检测作物病虫害、果实计数。
- 零售: 客流统计、商品识别。
- 机器人: 物体抓取、导航避障。
- 教育与教学: 作为学习目标检测和深度学习的优秀实践工具。
三、基于yolo11n的行人检测
在上一章节,我们实现了基本的多路视频拉流和展示,在这一章节,我们基于ultralytics框架,以yolo11n直接对8路视频进行检测和分析,这一章节暂未考虑到模型的优化,多路并行的问题,一切以实现和可用为主。
1.拉流解码模块(VideoStreamDecoder 模块)
- 流程示意如下所示
开始
│
├─> 初始化解码器
│ ├─> 设置流参数 (stream_url, buffer_size, timeout等)
│ ├─> 设置模型管理器引用
│ └─> 初始化状态变量
│
├─> 连接流
│ ├─> 设置连接状态为"connecting"
│ ├─> 使用av.open打开流
│ ├─> 获取视频流
│ ├─> 设置关键帧模式(如果启用)
│ ├─> 创建解码迭代器
│ └─> 更新连接状态为"connected"
│
├─> 启动解码线程
│ ├─> 设置运行标志为True
│ └─> 创建并启动_decode_loop线程
│
├─> 解码循环(_decode_loop)
│ │
│ ├─> 循环直到运行标志为False
│ │ │
│ │ ├─> 从迭代器获取下一帧
│ │ ├─> 更新帧计数器
│ │ ├─> 转换为numpy数组
│ │ ├─> 添加时间戳
│ │ ├─> 更新_last_frame
│ │ │
│ │ ├─> 如果检测已启用
│ │ │ ├─> 检查抽帧条件
│ │ │ ├─> 通过ModelManager异步处理帧
│ │ │ └─> 更新_last_processed_frame(通过回调)
│ │ │
│ │ └─> 如果发生错误
│ │ ├─> 更新连接状态
│ │ ├─> 关闭当前容器
│ │ └─> 尝试重连
│ │
│ └─> 循环结束
│
├─> 获取帧(get_frame)
│ ├─> 根据processed参数
│ │ ├─> 返回处理后的帧(如果可用)
│ │ └─> 否则返回原始帧
│ └─> 使用锁确保线程安全
│
├─> 更新设置(update_settings)
│ ├─> 更新允许的参数
│ └─> 如果需要重启则重启流
│
├─> 启用/禁用检测(enable_detection)
│ ├─> 设置detection_enabled标志
│ └─> 重置帧计数器
│
└─> 停止(stop)
├─> 设置运行标志为False
├─> 等待解码线程结束
├─> 关闭容器
└─> 更新连接状态为"disconnected"
- 流程图mermaid代码如下
flowchart TD
Start[VideoStreamDecoder Start] --> Init[初始化解码器]
Init --> Connect[连接流]
Connect --> ConnectStatus[设置连接状态为connecting]
Connect --> AvOpen[使用av.open打开流]
Connect --> GetStream[获取视频流]
Connect --> SetKeyframe[设置关键帧模式]
Connect --> CreateIterator[创建解码迭代器]
Connect --> Connected[更新连接状态为connected]
Connect --> StartThread[启动解码线程]
StartThread --> SetRunning[设置运行标志为True]
StartThread --> CreateThread[创建_decode_loop线程]
CreateThread --> DecodeLoop[解码循环]
subgraph DecodeLoop [解码循环]
direction TB
DL_Start[循环开始] --> DL_Check{运行标志为True?}
DL_Check -- 是 --> DL_GetFrame[从迭代器获取下一帧]
DL_GetFrame --> DL_UpdateCounter[更新帧计数器]
DL_GetFrame --> DL_Convert[转换为numpy数组]
DL_Convert --> DL_AddTimestamp[添加时间戳]
DL_AddTimestamp --> DL_UpdateFrame[更新_last_frame]
DL_UpdateFrame --> DL_CheckDetection{检测已启用?}
DL_CheckDetection -- 是 --> DL_CheckSkip{符合抽帧条件?}
DL_CheckDetection -- 否 --> DL_ResetProcessed[重置_last_processed_frame]
DL_CheckSkip -- 是 --> DL_AsyncProcess[通过ModelManager异步处理帧]
DL_CheckSkip -- 否 --> DL_SkipFrame[跳过此帧处理]
DL_AsyncProcess --> DL_UpdateProcessed[更新_last_processed_frame]
DL_SkipFrame --> DL_Next[继续下一帧]
DL_ResetProcessed --> DL_Next
DL_Next --> DL_Check
DL_Check -- 否 --> DL_End[循环结束]
DL_Error[发生错误] --> DL_UpdateStatus[更新连接状态]
DL_UpdateStatus --> DL_CloseContainer[关闭当前容器]
DL_CloseContainer --> DL_Reconnect[尝试重连]
DL_Reconnect --> DL_Next
end
DecodeLoop --> GetFrame[获取帧]
subgraph GetFrame [获取帧流程]
direction TB
GF_Start[get_frame调用] --> GF_CheckProcessed{processed参数为True?}
GF_CheckProcessed -- 是 --> GF_CheckProcessedAvailable{_last_processed_frame可用?}
GF_CheckProcessed -- 否 --> GF_GetOriginal[获取原始帧]
GF_CheckProcessedAvailable -- 是 --> GF_ReturnProcessed[返回处理后的帧]
GF_CheckProcessedAvailable -- 否 --> GF_GetOriginal
GF_GetOriginal --> GF_ReturnOriginal[返回原始帧]
end
GetFrame --> UpdateSettings[更新设置]
subgraph UpdateSettings [更新设置流程]
direction TB
US_Start[update_settings调用] --> US_CheckParams[检查允许的参数]
US_CheckParams --> US_Update[更新参数值]
US_Update --> US_NeedRestart{需要重启?}
US_NeedRestart -- 是 --> US_Restart[重启流]
US_NeedRestart -- 否 --> US_End[结束]
end
UpdateSettings --> ToggleDetection[启用/禁用检测]
subgraph ToggleDetection [启用/禁用检测流程]
direction TB
TD_Start[enable_detection调用] --> TD_SetFlag[设置detection_enabled标志]
TD_SetFlag --> TD_ResetCounter[重置帧计数器]
TD_ResetCounter --> TD_End[结束]
end
ToggleDetection --> Stop[停止解码器]
subgraph Stop [停止流程]
direction TB
S_Start[stop调用] --> S_SetFlag[设置运行标志为False]
S_SetFlag --> S_WaitThread[等待解码线程结束]
S_WaitThread --> S_CloseContainer[关闭容器]
S_CloseContainer --> S_UpdateStatus[更新连接状态为disconnected]
S_UpdateStatus --> S_End[结束]
end
2.多路视频管理模块(StreamManager 模块)
- 流程示意如下所示
开始
│
├─> 初始化管理器
│ ├─> 创建解码器字典
│ └─> 创建ModelManager实例
│
├─> 添加流(add_stream)
│ ├─> 检查流ID是否已存在
│ ├─> 创建VideoStreamDecoder实例
│ ├─> 添加到解码器字典
│ └─> 返回成功/失败
│
├─> 移除流(remove_stream)
│ ├─> 检查流ID是否存在
│ ├─> 停止解码器
│ ├─> 从字典中移除
│ └─> 返回成功/失败
│
├─> 启动流(start_stream)
│ ├─> 检查流ID是否存在
│ ├─> 调用解码器的start方法
│ └─> 返回成功/失败
│
├─> 停止流(stop_stream)
│ ├─> 检查流ID是否存在
│ ├─> 调用解码器的stop方法
│ └─> 返回成功/失败
│
├─> 获取帧(get_frame/get_all_frames)
│ ├─> 检查流ID是否存在
│ ├─> 调用解码器的get_frame方法
│ └─> 返回帧或None
│
├─> 更新流设置(update_stream_settings)
│ ├─> 检查流ID是否存在
│ ├─> 调用解码器的update_settings方法
│ └─> 传递所有有效参数
│
├─> 启用/禁用检测(enable_detection)
│ ├─> 检查流ID是否存在
│ ├─> 调用解码器的enable_detection方法
│ └─> 返回成功/失败
│
├─> 模型管理方法
│ ├─> load_model → 委托给ModelManager
│ ├─> add_model_to_stream → 委托给ModelManager
│ ├─> remove_model_from_stream → 委托给ModelManager
│ ├─> add_alert_condition → 委托给ModelManager
│ ├─> get_stream_models → 委托给ModelManager
│ └─> get_loaded_models → 委托给ModelManager
│
└─> 停止所有(stop_all)
├─> 遍历所有解码器并停止
└─> 调用ModelManager的shutdown方法
- 流程图mermaid代码如下
flowchart TD
Start[StreamManager Start] --> Init[初始化管理器]
Init --> AddStream[添加流]
subgraph AddStream [添加流流程]
direction TB
AS_Start[add_stream调用] --> AS_CheckExist{流ID已存在?}
AS_CheckExist -- 否 --> AS_Create[创建VideoStreamDecoder实例]
AS_Create --> AS_AddToDict[添加到解码器字典]
AS_AddToDict --> AS_Success[返回成功]
AS_CheckExist -- 是 --> AS_Fail[返回失败]
end
AddStream --> RemoveStream[移除流]
subgraph RemoveStream [移除流流程]
direction TB
RS_Start[remove_stream调用] --> RS_CheckExist{流ID存在?}
RS_CheckExist -- 是 --> RS_Stop[停止解码器]
RS_Stop --> RS_Remove[从字典中移除]
RS_Remove --> RS_Success[返回成功]
RS_CheckExist -- 否 --> RS_Fail[返回失败]
end
RemoveStream --> StartStream[启动流]
subgraph StartStream [启动流流程]
direction TB
SS_Start[start_stream调用] --> SS_CheckExist{流ID存在?}
SS_CheckExist -- 是 --> SS_CallStart[调用解码器的start方法]
SS_CallStart --> SS_Success[返回成功]
SS_CheckExist -- 否 --> SS_Fail[返回失败]
end
StartStream --> StopStream[停止流]
subgraph StopStream [停止流流程]
direction TB
StS_Start[stop_stream调用] --> StS_CheckExist{流ID存在?}
StS_CheckExist -- 是 --> StS_CallStop[调用解码器的stop方法]
StS_CallStop --> StS_Success[返回成功]
StS_CheckExist -- 否 --> StS_Fail[返回失败]
end
StopStream --> GetFrame[获取帧]
subgraph GetFrame [获取帧流程]
direction TB
GF_Start[get_frame/get_all_frames调用] --> GF_CheckExist{流ID存在?}
GF_CheckExist -- 是 --> GF_CallGetFrame[调用解码器的get_frame方法]
GF_CallGetFrame --> GF_Return[返回帧或None]
GF_CheckExist -- 否 --> GF_ReturnNone[返回None]
end
GetFrame --> UpdateSettings[更新流设置]
subgraph UpdateSettings [更新流设置流程]
direction TB
US_Start[update_stream_settings调用] --> US_CheckExist{流ID存在?}
US_CheckExist -- 是 --> US_CallUpdate[调用解码器的update_settings方法]
US_CallUpdate --> US_Success[成功]
US_CheckExist -- 否 --> US_Fail[失败]
end
UpdateSettings --> ToggleDetection[启用/禁用检测]
subgraph ToggleDetection [启用/禁用检测流程]
direction TB
TD_Start[enable_detection调用] --> TD_CheckExist{流ID存在?}
TD_CheckExist -- 是 --> TD_CallEnable[调用解码器的enable_detection方法]
TD_CallEnable --> TD_Success[返回成功]
TD_CheckExist -- 否 --> TD_Fail[返回失败]
end
ToggleDetection --> ModelManagement[模型管理]
subgraph ModelManagement [模型管理方法]
direction TB
MM_Load[load_model] --> MM_DelegateLoad[委托给ModelManager]
MM_Add[add_model_to_stream] --> MM_DelegateAdd[委托给ModelManager]
MM_Remove[remove_model_from_stream] --> MM_DelegateRemove[委托给ModelManager]
MM_Alert[add_alert_condition] --> MM_DelegateAlert[委托给ModelManager]
MM_GetStream[get_stream_models] --> MM_DelegateGetStream[委托给ModelManager]
MM_GetLoaded[get_loaded_models] --> MM_DelegateGetLoaded[委托给ModelManager]
end
ModelManagement --> StopAll[停止所有]
subgraph StopAll [停止所有流程]
direction TB
SA_Start[stop_all调用] --> SA_Loop[遍历所有解码器]
SA_Loop --> SA_CallStop[调用每个解码器的stop方法]
SA_CallStop --> SA_Shutdown[调用ModelManager的shutdown方法]
SA_Shutdown --> SA_End[结束]
end
3.模型管理模块(ModelManager 模块)
- 流程示意如下所示
开始
│
├─> 初始化管理器
│ ├─> 创建模型字典
│ ├─> 创建活跃模型字典
│ ├─> 创建AlertHandler实例
│ ├─> 创建线程池执行器
│ └─> 创建进程池执行器
│
├─> 加载模型(load_model)
│ ├─> 创建YOLOv8Model实例
│ ├─> 添加到模型字典
│ └─> 返回模型名称
│
├─> 添加模型到流(add_model_to_stream)
│ ├─> 检查模型是否存在
│ ├─> 添加到活跃模型字典
│ └─> 记录日志
│
├─> 从流移除模型(remove_model_from_stream)
│ ├─> 检查模型是否在流中
│ ├─> 从活跃模型字典移除
│ └─> 记录日志
│
├─> 异步处理帧(process_frame_async)
│ ├─> 检查流是否有激活的模型
│ ├─> 提交处理任务到线程池
│ └─> 设置回调函数
│
├─> 同步处理帧(_process_frame_sync)
│ ├─> 复制帧
│ ├─> 遍历所有激活的模型
│ │ ├─> 进行预测
│ │ ├─> 绘制检测结果
│ │ ├─> 检查报警条件
│ │ └─> 收集所有检测结果
│ └─> 返回处理后的帧和检测结果
│
├─> 添加报警条件(add_alert_condition)
│ └─> 委托给AlertHandler
│
├─> 获取流模型(get_stream_models)
│ └─> 返回活跃模型字典中的列表
│
├─> 获取已加载模型(get_loaded_models)
│ └─> 返回模型字典的键列表
│
└─> 关闭(shutdown)
├─> 关闭线程池执行器
└─> 关闭进程池执行器
- 流程图mermaid代码如下
flowchart TD
Start[ModelManager Start] --> Init[初始化管理器]
Init --> LoadModel[加载模型]
subgraph LoadModel [加载模型流程]
direction TB
LM_Start[load_model调用] --> LM_Create[创建YOLOv8Model实例]
LM_Create --> LM_AddToDict[添加到模型字典]
LM_AddToDict --> LM_Return[返回模型名称]
end
LoadModel --> AddModelToStream[添加模型到流]
subgraph AddModelToStream [添加模型到流流程]
direction TB
AM_Start[add_model_to_stream调用] --> AM_CheckExist{模型存在?}
AM_CheckExist -- 是 --> AM_Add[添加到活跃模型字典]
AM_Add --> AM_Log[记录日志]
AM_CheckExist -- 否 --> AM_Error[抛出错误]
end
AddModelToStream --> RemoveModelFromStream[从流移除模型]
subgraph RemoveModelFromStream [从流移除模型流程]
direction TB
RM_Start[remove_model_from_stream调用] --> RM_CheckInStream{模型在流中?}
RM_CheckInStream -- 是 --> RM_Remove[从活跃模型字典移除]
RM_Remove --> RM_Log[记录日志]
RM_CheckInStream -- 否 --> RM_End[结束]
end
RemoveModelFromStream --> ProcessFrame[处理帧]
subgraph ProcessFrame [处理帧流程]
direction TB
PF_Start[process_frame_async调用] --> PF_CheckActive{流有激活的模型?}
PF_CheckActive -- 是 --> PF_Submit[提交处理任务到线程池]
PF_Submit --> PF_SetCallback[设置回调函数]
PF_CheckActive -- 否 --> PF_Callback[直接调用回调函数]
end
ProcessFrame --> ProcessFrameSync[同步处理帧]
subgraph ProcessFrameSync [同步处理帧流程]
direction TB
PFS_Start[_process_frame_sync调用] --> PFS_Copy[复制帧]
PFS_Copy --> PFS_Loop[遍历所有激活的模型]
subgraph PFS_Loop [对每个模型的处理]
direction TB
PFS_Predict[进行预测] --> PFS_Draw[绘制检测结果]
PFS_Draw --> PFS_CheckAlert[检查报警条件]
PFS_CheckAlert --> PFS_Collect[收集检测结果]
end
PFS_Loop --> PFS_Return[返回处理后的帧和检测结果]
end
ProcessFrameSync --> AddAlert[添加报警条件]
subgraph AddAlert [添加报警条件流程]
direction TB
AA_Start[add_alert_condition调用] --> AA_Delegate[委托给AlertHandler]
AA_Delegate --> AA_End[结束]
end
AddAlert --> GetMethods[获取方法]
subgraph GetMethods [获取方法流程]
direction TB
GM_GetStream[get_stream_models] --> GM_ReturnActive[返回活跃模型字典中的列表]
GM_GetLoaded[get_loaded_models] --> GM_ReturnLoaded[返回模型字典的键列表]
end
GetMethods --> Shutdown[关闭管理器]
subgraph Shutdown [关闭流程]
direction TB
SD_Start[shutdown调用] --> SD_ShutdownThread[关闭线程池执行器]
SD_ShutdownThread --> SD_ShutdownProcess[关闭进程池执行器]
SD_ShutdownProcess --> SD_End[结束]
end
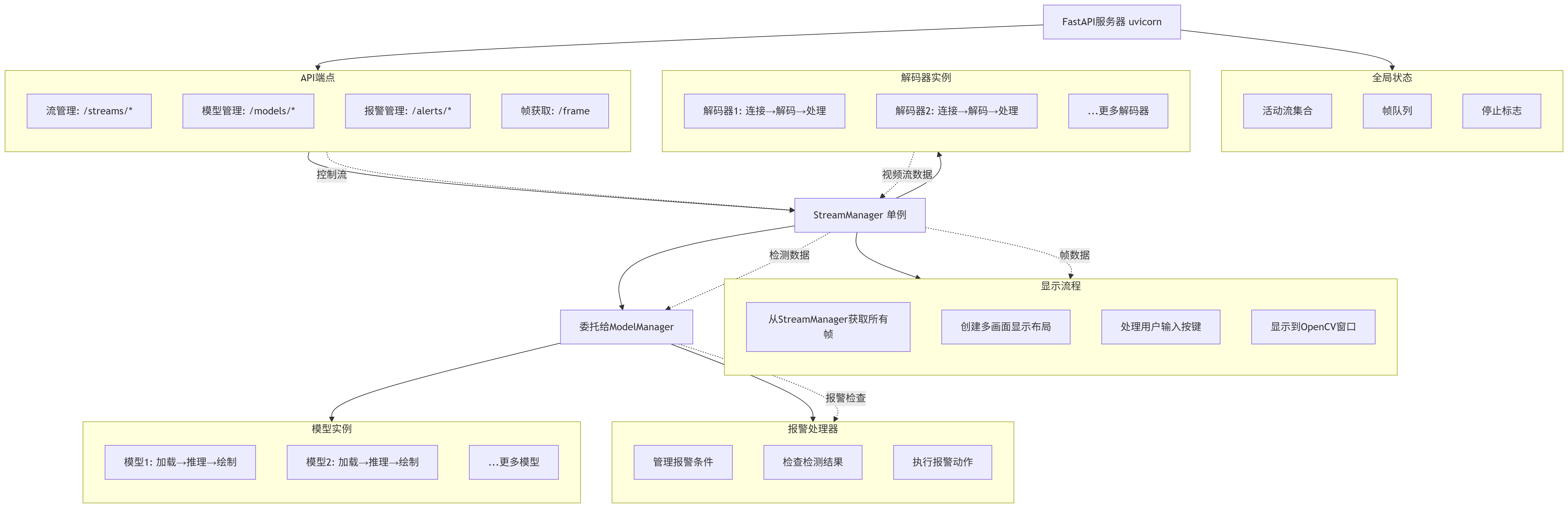
4.系统整体流程关系
- 流程示意如下所示
FastAPI服务器 (uvicorn)
│
├─> RESTful API端点
│ ├─> 流管理: /streams/*
│ ├─> 模型管理: /models/*
│ ├─> 报警管理: /alerts/*
│ └─> 帧获取: /frame
│
├─> StreamManager (单例)
│ ├─> 管理多个VideoStreamDecoder实例
│ │ ├─> 解码器1: 连接→解码→处理
│ │ ├─> 解码器2: 连接→解码→处理
│ │ └─> ...更多解码器
│ │
│ └─> 委托给ModelManager
│ ├─> 管理多个YOLOv8Model实例
│ │ ├─> 模型1: 加载→推理→绘制
│ │ ├─> 模型2: 加载→推理→绘制
│ │ └─> ...更多模型
│ │
│ └─> 使用AlertHandler
│ ├─> 管理报警条件
│ ├─> 检查检测结果
│ └─> 执行报警动作
│
├─> 显示线程(display_loop)
│ ├─> 定期从StreamManager获取所有帧
│ ├─> 创建多画面显示布局
│ ├─> 处理用户输入(按键)
│ └─> 显示到OpenCV窗口
│
└─> 全局状态
├─> 活动流集合
├─> 帧队列
└─> 停止标志
- 示意流程图
5.完整实现代码
5.1 服务代码
import av
import cv2
import time
import logging
import threading
import numpy as np
from typing import Optional, Any, Dict, List, Tuple, Callable
import datetime
from fastapi import FastAPI, HTTPException
from fastapi.responses import JSONResponse, StreamingResponse
from pydantic import BaseModel
import uvicorn
import json
import queue
import asyncio
from ultralytics import YOLO
from collections import defaultdict
import os
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor
import multiprocessing as mp
from multiprocessing import Queue, Process, Value, Array
import copy
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger("StreamDecoder")
# 全局变量
app = FastAPI(title="多路视频流管理系统")
stream_manager = None
display_thread = None
stopped = False
frame_queue = queue.Queue(maxsize=10)
active_streams = set()
# 数据模型
class StreamConfig(BaseModel):
stream_url: str
buffer_size: int = 102400
hw_accel: Optional[str] = None
timeout: int = 5000000
reconnect_delay: int = 5
max_retries: int = -1
keyframe_only: bool = False
frame_skip: int = 3 # 新增:抽帧分析参数,每N帧分析一帧
class StreamUpdate(BaseModel):
buffer_size: Optional[int] = None
hw_accel: Optional[str] = None
timeout: Optional[int] = None
reconnect_delay: Optional[int] = None
max_retries: Optional[int] = None
keyframe_only: Optional[bool] = None
frame_skip: Optional[int] = None # 新增:抽帧分析参数
class DetectionConfig(BaseModel):
model_path: str
confidence_threshold: float = 0.5
classes: Optional[List[int]] = None
class AlertCondition(BaseModel):
class_name: str
min_confidence: float = 0.5
min_count: int = 1
max_count: Optional[int] = None
cooldown: int = 5 # 报警冷却时间(秒)
class AlertAction(BaseModel):
action_type: str # "log", "http", "email", "mqtt"
config: Dict[str, Any]
# YOLOv8 模型推理类
class YOLOv8Model:
def __init__(self, model_path: str, confidence_threshold: float = 0.5,
classes: Optional[List[int]] = None):
cur_path = os.getcwd()
load_path = os.path.join(cur_path, model_path)
print("cur load path is {}".format(load_path))
# 尝试加载模型,设置fuse=False避免融合问题
try:
self.model = YOLO(load_path, verbose=False)
# 尝试设置fuse=False,如果模型支持这个参数
if hasattr(self.model, 'model') and hasattr(self.model.model, 'fuse'):
self.model.model.fuse = False
except Exception as e:
logger.error(f"Failed to load model {load_path}: {e}")
raise
self.confidence_threshold = confidence_threshold
self.classes = classes
self.model_name = model_path.split("/")[-1].split(".")[0]
logger.info(f"Loaded YOLOv8 model: {self.model_name}")
def predict(self, frame: np.ndarray) -> List[Dict]:
"""对帧进行预测并返回检测结果"""
try:
results = self.model(frame, conf=self.confidence_threshold,
classes=self.classes, verbose=False)
detections = []
for result in results:
boxes = result.boxes
if boxes is not None:
for box in boxes:
detection = {
"class_id": int(box.cls),
"class_name": self.model.names[int(box.cls)],
"confidence": float(box.conf),
"bbox": box.xyxy[0].cpu().numpy().tolist() # [x1, y1, x2, y2]
}
detections.append(detection)
return detections
except Exception as e:
logger.error(f"Error during prediction: {e}")
# 返回空检测结果而不是让整个程序崩溃
return []
def draw_detections(self, frame: np.ndarray, detections: List[Dict]) -> np.ndarray:
"""在帧上绘制检测结果"""
for detection in detections:
x1, y1, x2, y2 = detection["bbox"]
label = f"{detection['class_name']} {detection['confidence']:.2f}"
# 绘制边界框
cv2.rectangle(frame, (int(x1), int(y1)), (int(x2), int(y2)), (0, 255, 0), 2)
# 绘制标签背景
text_size = cv2.getTextSize(label, cv2.FONT_HERSHEY_SIMPLEX, 0.5, 2)[0]
cv2.rectangle(frame, (int(x1), int(y1) - text_size[1] - 5),
(int(x1) + text_size[0], int(y1)), (0, 255, 0), -1)
# 绘制标签文本
cv2.putText(frame, label, (int(x1), int(y1) - 5),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 0), 2)
return frame
# 报警处理器
class AlertHandler:
def __init__(self):
self.alert_conditions = {} # model_name -> List[AlertCondition]
self.alert_actions = {} # model_name -> List[AlertAction]
self.last_alert_time = defaultdict(float) # (stream_id, model_name, class_name) -> last_alert_time
def add_alert_condition(self, model_name: str, condition: AlertCondition, action: AlertAction):
"""为模型添加报警条件和动作"""
if model_name not in self.alert_conditions:
self.alert_conditions[model_name] = []
self.alert_actions[model_name] = []
self.alert_conditions[model_name].append(condition)
self.alert_actions[model_name].append(action)
logger.info(f"Added alert condition for {model_name}: {condition.class_name}")
def check_alerts(self, stream_id: str, model_name: str, detections: List[Dict]) -> List[Dict]:
"""检查检测结果是否触发报警条件"""
alerts_triggered = []
if model_name not in self.alert_conditions:
return alerts_triggered
# 按类别分组检测结果
class_detections = defaultdict(list)
for detection in detections:
class_detections[detection["class_name"]].append(detection)
# 检查每个报警条件
for condition, action in zip(self.alert_conditions[model_name], self.alert_actions[model_name]):
class_name = condition.class_name
if class_name in class_detections:
detections_for_class = class_detections[class_name]
confidences = [d["confidence"] for d in detections_for_class]
high_conf_detections = [d for d in detections_for_class if d["confidence"] >= condition.min_confidence]
count = len(high_conf_detections)
if (count >= condition.min_count and
(condition.max_count is None or count <= condition.max_count)):
# 检查冷却时间
alert_key = (stream_id, model_name, class_name)
current_time = time.time()
if current_time - self.last_alert_time[alert_key] >= condition.cooldown:
self.last_alert_time[alert_key] = current_time
alert_info = {
"stream_id": stream_id,
"model_name": model_name,
"class_name": class_name,
"count": count,
"detections": high_conf_detections,
"action": action,
"timestamp": datetime.datetime.now().isoformat()
}
# 执行报警动作
self.execute_alert_action(alert_info)
alerts_triggered.append(alert_info)
return alerts_triggered
def execute_alert_action(self, alert_info: Dict):
"""执行报警动作"""
action = alert_info["action"]
if action.action_type == "log":
logger.warning(
f"ALERT: {alert_info['class_name']} detected in {alert_info['stream_id']} "
f"by {alert_info['model_name']} (count: {alert_info['count']})"
)
elif action.action_type == "http":
# 这里可以实现HTTP请求逻辑
logger.info(f"HTTP alert triggered: {alert_info}")
elif action.action_type == "email":
# 这里可以实现邮件发送逻辑
logger.info(f"Email alert triggered: {alert_info}")
elif action.action_type == "mqtt":
# 这里可以实现MQTT发布逻辑
logger.info(f"MQTT alert triggered: {alert_info}")
# 模型管理器
class ModelManager:
def __init__(self):
self.models = {} # model_name -> YOLOv8Model
self.active_models = defaultdict(list) # stream_id -> List[model_name]
self.alert_handler = AlertHandler()
# 使用线程池进行异步推理
self.executor = ThreadPoolExecutor(max_workers=4)
# 使用进程池进行CPU密集型推理任务
self.process_executor = ProcessPoolExecutor(max_workers=2)
def load_model(self, model_config: DetectionConfig) -> str:
"""加载YOLOv8模型"""
print("model path : ", model_config.model_path)
model = YOLOv8Model(
model_config.model_path,
model_config.confidence_threshold,
model_config.classes
)
self.models[model.model_name] = model
return model.model_name
def add_model_to_stream(self, stream_id: str, model_name: str):
"""为视频流添加模型"""
if model_name not in self.models:
raise ValueError(f"Model {model_name} not loaded")
if model_name not in self.active_models[stream_id]:
self.active_models[stream_id].append(model_name)
logger.info(f"Added model {model_name} to stream {stream_id}")
def remove_model_from_stream(self, stream_id: str, model_name: str):
"""从视频流移除模型"""
if model_name in self.active_models[stream_id]:
self.active_models[stream_id].remove(model_name)
logger.info(f"Removed model {model_name} from stream {stream_id}")
def process_frame_async(self, stream_id: str, frame: np.ndarray, callback: Callable):
"""异步处理帧数据,应用所有激活的模型"""
if stream_id not in self.active_models or not self.active_models[stream_id]:
callback(frame.copy(), [])
return
# 提交到线程池进行异步处理
future = self.executor.submit(self._process_frame_sync, stream_id, frame)
future.add_done_callback(lambda f: callback(*f.result()))
def _process_frame_sync(self, stream_id: str, frame: np.ndarray) -> Tuple[np.ndarray, List[Dict]]:
"""同步处理帧数据"""
result_frame = frame.copy()
all_detections = []
for model_name in self.active_models[stream_id]:
model = self.models[model_name]
detections = model.predict(frame)
result_frame = model.draw_detections(result_frame, detections)
# 检查报警条件
self.alert_handler.check_alerts(stream_id, model_name, detections)
all_detections.extend(detections)
return result_frame, all_detections
def add_alert_condition(self, model_name: str, condition: AlertCondition, action: AlertAction):
"""为模型添加报警条件"""
self.alert_handler.add_alert_condition(model_name, condition, action)
def get_stream_models(self, stream_id: str) -> List[str]:
"""获取视频流激活的模型列表"""
return self.active_models.get(stream_id, [])
def get_loaded_models(self) -> List[str]:
"""获取所有已加载的模型"""
return list(self.models.keys())
def shutdown(self):
"""关闭执行器"""
self.executor.shutdown(wait=True)
self.process_executor.shutdown(wait=True)
def add_timestamp(frame_array):
"""添加时间戳到视频帧"""
current_time = datetime.datetime.now()
time_str = current_time.strftime("%Y-%m-%d %H:%M:%S")
font = cv2.FONT_HERSHEY_SIMPLEX
font_scale = 0.7
font_color = (255, 255, 255)
font_thickness = 2
background_color = (0, 0, 0)
(text_width, text_height), baseline = cv2.getTextSize(time_str, font, font_scale, font_thickness)
margin = 10
text_x = frame_array.shape[1] - text_width - margin
text_y = text_height + margin
bg_rect = np.zeros((text_height + 2 * margin, text_width + 2 * margin, 3), dtype=np.uint8)
bg_rect[:, :] = background_color
alpha = 0.6
y1, y2 = text_y - text_height - margin, text_y + margin
x1, x2 = text_x - margin, text_x + text_width + margin
y1, y2 = max(0, y1), min(frame_array.shape[0], y2)
x1, x2 = max(0, x1), min(frame_array.shape[1], x2)
if y2 > y1 and x2 > x1:
roi = frame_array[y1:y2, x1:x2]
bg_resized = cv2.resize(bg_rect, (x2 - x1, y2 - y1))
blended = cv2.addWeighted(roi, 1 - alpha, bg_resized, alpha, 0)
frame_array[y1:y2, x1:x2] = blended
cv2.putText(
frame_array,
time_str,
(text_x, text_y),
font,
font_scale,
font_color,
font_thickness,
cv2.LINE_AA
)
return frame_array
class VideoStreamDecoder:
def __init__(self, stream_id: str, stream_url: str, buffer_size: int = 102400,
hw_accel: Optional[str] = None, timeout: int = 5000000,
reconnect_delay: int = 5, max_retries: int = -1,
keyframe_only: bool = False, frame_skip: int = 3,
model_manager: Optional[ModelManager] = None):
self.stream_id = stream_id
self.stream_url = stream_url
self.buffer_size = buffer_size
self.hw_accel = hw_accel
self.timeout = timeout
self.reconnect_delay = reconnect_delay
self.max_retries = max_retries
self.keyframe_only = keyframe_only
self.frame_skip = frame_skip # 新增:抽帧分析参数
self.model_manager = model_manager
self.detection_enabled = False
self._retry_count = 0
self._connection_status = "disconnected" # disconnected, connecting, connected, error
self._frame_counter = 0 # 新增:帧计数器用于抽帧
self._container: Optional[av.container.InputContainer] = None
self._video_stream: Optional[av.video.stream.VideoStream] = None
self._current_iterator: Optional[Any] = None
self._last_frame: Optional[np.ndarray] = None
self._last_processed_frame: Optional[np.ndarray] = None
self._frame_count: int = 0
self._keyframe_count: int = 0
self._running = False
self._decode_thread: Optional[threading.Thread] = None
self._options = self._get_codec_options()
self.lock = threading.Lock()
def _get_codec_options(self) -> Dict:
"""根据硬件加速类型获取解码器选项"""
options = {'threads': 'auto'}
if self.hw_accel:
options.update({
'hwaccel': self.hw_accel,
})
return options
def connect(self) -> bool:
"""尝试连接流并初始化视频流"""
try:
self._connection_status = "connecting"
self._container = av.open(
self.stream_url,
options={
'rtsp_flags': 'prefer_tcp',
'buffer_size': str(self.buffer_size),
'stimeout': str(self.timeout),
},
timeout=(self.timeout / 1000000)
)
self._video_stream = next(s for s in self._container.streams if s.type == 'video')
if self.keyframe_only:
self._video_stream.codec_context.skip_frame = 'NONKEY'
self._current_iterator = self._container.decode(self._video_stream)
logger.info(f"Successfully connected to {self.stream_url}")
self._retry_count = 0
self._connection_status = "connected"
return True
except Exception as e:
logger.error(f"Failed to connect to {self.stream_url}: {e}")
self._connection_status = f"error: {str(e)}"
return False
def _process_frame_callback(self, processed_frame: np.ndarray, detections: List[Dict]):
"""处理完成后的回调函数"""
with self.lock:
self._last_processed_frame = processed_frame
def _decode_loop(self):
"""运行在独立线程中的解码循环"""
while self._running:
try:
frame = next(self._current_iterator)
self._frame_count += 1
if frame.key_frame:
self._keyframe_count += 1
frame_array = frame.to_ndarray(format='bgr24')
frame_array = add_timestamp(frame_array)
with self.lock:
self._last_frame = frame_array
# 处理检测 - 异步方式
if self.detection_enabled and self.model_manager:
# 抽帧逻辑:每 frame_skip+1 帧处理一帧
if self._frame_counter % (self.frame_skip + 1) == 0:
# 每处理frame_skip帧后略过一帧
# if self._frame_counter % (self.frame_skip) != 0:
self.model_manager.process_frame_async(
self.stream_id, frame_array, self._process_frame_callback
)
self._frame_counter += 1
else:
# 如果没有启用检测,确保处理后的帧为空
with self.lock:
self._last_processed_frame = None
except (av.AVError, StopIteration, ValueError) as e:
logger.warning(f"Decoding error on {self.stream_url}: {e}. Attempting reconnect...")
self._connection_status = f"reconnecting: {str(e)}"
if self._container:
self._container.close()
if not self._attempt_reconnect():
continue
except Exception as e:
logger.error(f"Unexpected error in decode loop for {self.stream_url}: {e}")
self._connection_status = f"error: {str(e)}"
with self.lock:
self._last_frame = None
self._last_processed_frame = None
time.sleep(1)
def _attempt_reconnect(self) -> bool:
"""尝试重连,根据重连策略"""
if self.max_retries > 0 and self._retry_count >= self.max_retries:
logger.error(f"Reached max retries ({self.max_retries}) for {self.stream_url}. Giving up.")
self._connection_status = "disconnected"
return False
self._retry_count += 1
logger.info(f"Attempting to reconnect ({self._retry_count}) in {self.reconnect_delay} seconds...")
time.sleep(self.reconnect_delay)
if self.connect():
return True
return False
def start(self):
"""启动解码线程"""
if self._running:
logger.warning(f"Decoder for {self.stream_url} is already running.")
return
if self._container is None:
if not self.connect():
logger.error(f"Failed to start because connection failed for {self.stream_url}.")
return
self._running = True
self._decode_thread = threading.Thread(target=self._decode_loop, daemon=True)
self._decode_thread.start()
logger.info(f"Started decoder thread for {self.stream_url}.")
def get_frame(self, processed: bool = False) -> Optional[np.ndarray]:
"""获取当前最新的视频帧(numpy array)"""
with self.lock:
if processed and self.detection_enabled and self._last_processed_frame is not None:
return self._last_processed_frame.copy()
elif self._last_frame is not None:
return self._last_frame.copy()
return None
def get_stats(self) -> Dict[str, Any]:
"""获取解码统计信息"""
return {
"frame_count": self._frame_count,
"keyframe_count": self._keyframe_count,
"retry_count": self._retry_count,
"connection_status": self._connection_status,
"detection_enabled": self.detection_enabled,
"frame_skip": self.frame_skip
}
def update_settings(self, **kwargs):
"""动态更新参数"""
allowed_params = ['buffer_size', 'timeout', 'reconnect_delay', 'max_retries', 'keyframe_only', 'frame_skip']
need_restart = False
for key, value in kwargs.items():
if key in allowed_params and hasattr(self, key):
old_value = getattr(self, key)
setattr(self, key, value)
logger.info(f"Updated {key} from {old_value} to {value} for {self.stream_url}.")
if key in ['keyframe_only', 'timeout', 'buffer_size']:
need_restart = True
if need_restart and self._running:
self.restart()
def enable_detection(self, enable: bool):
"""启用或禁用目标检测"""
self.detection_enabled = enable
# 重置帧计数器
self._frame_counter = 0
logger.info(f"{'Enabled' if enable else 'Disabled'} detection for {self.stream_url}")
def stop(self):
"""停止解码并清理资源"""
self._running = False
self._connection_status = "disconnected"
if self._decode_thread and self._decode_thread.is_alive():
self._decode_thread.join(timeout=2.0)
if self._container:
self._container.close()
logger.info(f"Stopped decoder for {self.stream_url}.")
def restart(self):
"""重启流"""
self.stop()
time.sleep(1)
self._container = None
self._video_stream = None
self.start()
class StreamManager:
def __init__(self):
self.decoders: Dict[str, VideoStreamDecoder] = {}
self.model_manager = ModelManager()
self.lock = threading.RLock()
def add_stream(self, stream_id: str, stream_url: str, **kwargs) -> bool:
"""添加一路视频流"""
with self.lock:
if stream_id in self.decoders:
logger.warning(f"Stream ID {stream_id} already exists.")
return False
decoder = VideoStreamDecoder(stream_id, stream_url, model_manager=self.model_manager, **kwargs)
self.decoders[stream_id] = decoder
logger.info(f"Added stream {stream_id} with URL {stream_url}")
return True
def remove_stream(self, stream_id: str) -> bool:
"""移除一路视频流"""
with self.lock:
if stream_id not in self.decoders:
logger.warning(f"Stream ID {stream_id} does not exist.")
return False
decoder = self.decoders[stream_id]
decoder.stop()
del self.decoders[stream_id]
logger.info(f"Removed stream {stream_id}")
return True
def start_stream(self, stream_id: str) -> bool:
"""启动指定视频流"""
with self.lock:
if stream_id not in self.decoders:
logger.warning(f"Stream ID {stream_id} does not exist.")
return False
try:
self.decoders[stream_id].start()
return True
except Exception as e:
logger.error(f"Failed to start stream {stream_id}: {e}")
return False
def stop_stream(self, stream_id: str) -> bool:
"""停止指定视频流"""
with self.lock:
if stream_id not in self.decoders:
logger.warning(f"Stream ID {stream_id} does not exist.")
return False
try:
self.decoders[stream_id].stop()
return True
except Exception as e:
logger.error(f"Failed to stop stream {stream_id}: {e}")
return False
def start_all(self):
"""启动所有视频流"""
with self.lock:
for stream_id, decoder in self.decoders.items():
try:
decoder.start()
except Exception as e:
logger.error(f"Failed to start stream {stream_id}: {e}")
def stop_all(self):
"""停止所有视频流"""
with self.lock:
for stream_id, decoder in self.decoders.items():
try:
decoder.stop()
except Exception as e:
logger.error(f"Failed to stop stream {stream_id}: {e}")
# 关闭模型管理器的执行器
self.model_manager.shutdown()
def get_frame(self, stream_id: str, processed: bool = False) -> Optional[np.ndarray]:
"""获取指定流的当前帧"""
with self.lock:
if stream_id not in self.decoders:
return None
return self.decoders[stream_id].get_frame(processed)
def get_all_frames(self, processed: bool = False) -> Dict[str, Optional[np.ndarray]]:
"""获取所有流的当前帧"""
frames = {}
with self.lock:
for stream_id, decoder in self.decoders.items():
frames[stream_id] = decoder.get_frame(processed)
return frames
def update_stream_settings(self, stream_id: str, **kwargs):
"""更新指定流的设置"""
with self.lock:
if stream_id not in self.decoders:
logger.warning(f"Stream ID {stream_id} does not exist.")
return
self.decoders[stream_id].update_settings(**kwargs)
def get_stream_stats(self, stream_id: str) -> Optional[Dict[str, Any]]:
"""获取指定流的统计信息"""
with self.lock:
if stream_id not in self.decoders:
return None
return self.decoders[stream_id].get_stats()
def get_all_stats(self) -> Dict[str, Dict[str, Any]]:
"""获取所有流的统计信息"""
stats = {}
with self.lock:
for stream_id, decoder in self.decoders.items():
stats[stream_id] = decoder.get_stats()
return stats
def get_active_streams(self) -> List[str]:
"""获取当前活跃的流ID列表"""
with self.lock:
return list(self.decoders.keys())
def enable_detection(self, stream_id: str, enable: bool):
"""启用或禁用指定流的检测功能"""
with self.lock:
if stream_id not in self.decoders:
logger.warning(f"Stream ID {stream_id} does not exist.")
return False
self.decoders[stream_id].enable_detection(enable)
return True
def load_model(self, model_config: DetectionConfig) -> str:
"""加载模型"""
return self.model_manager.load_model(model_config)
def add_model_to_stream(self, stream_id: str, model_name: str):
"""为视频流添加模型"""
self.model_manager.add_model_to_stream(stream_id, model_name)
def remove_model_from_stream(self, stream_id: str, model_name: str):
"""从视频流移除模型"""
self.model_manager.remove_model_from_stream(stream_id, model_name)
def add_alert_condition(self, model_name: str, condition: AlertCondition, action: AlertAction):
"""为模型添加报警条件"""
self.model_manager.add_alert_condition(model_name, condition, action)
def get_stream_models(self, stream_id: str) -> List[str]:
"""获取视频流激活的模型列表"""
return self.model_manager.get_stream_models(stream_id)
def get_loaded_models(self) -> List[str]:
"""获取所有已加载的模型"""
return self.model_manager.get_loaded_models()
def display_loop():
"""显示循环,在主线程中运行"""
global stopped, stream_manager, frame_queue, active_streams
# 定义小屏幕尺寸和总分辨率
SMALL_SCREEN_WIDTH = 856
SMALL_SCREEN_HEIGHT = 480
TOTAL_WIDTH = SMALL_SCREEN_WIDTH * 4 # 4列
TOTAL_HEIGHT = SMALL_SCREEN_HEIGHT * 2 # 2行
# 创建显示窗口
cv2.namedWindow("Multi-Stream Display", cv2.WINDOW_NORMAL)
cv2.resizeWindow("Multi-Stream Display", TOTAL_WIDTH, TOTAL_HEIGHT)
# 定义布局 - 2x4网格 (2行,每行4个)
layout = [
["cam1", "cam2", "cam3", "cam4"],
["cam5", "cam6", "cam7", "cam8"]
]
# 创建状态帧(用于显示连接状态)
def create_status_frame(text, width, height, color=(0, 0, 0)):
frame = np.zeros((height, width, 3), dtype=np.uint8)
frame[:] = color
font = cv2.FONT_HERSHEY_SIMPLEX
font_scale = min(width, height) / 800 # 根据屏幕大小调整字体比例
text_size = cv2.getTextSize(text, font, font_scale, 2)[0]
text_x = (frame.shape[1] - text_size[0]) // 2
text_y = (frame.shape[0] + text_size[1]) // 2
cv2.putText(frame, text, (text_x, text_y), font, font_scale, (255, 255, 255), 2, cv2.LINE_AA)
return frame
while not stopped:
try:
# 创建画布
canvas = np.zeros((TOTAL_HEIGHT, TOTAL_WIDTH, 3), dtype=np.uint8)
# 获取所有流的帧和状态
frames = {}
stats = {}
if stream_manager:
# 获取处理后的帧(带检测结果)
frames = stream_manager.get_all_frames(processed=True)
stats = stream_manager.get_all_stats()
# 填充每个位置
for row_idx, row in enumerate(layout):
for col_idx, stream_id in enumerate(row):
# 计算位置
x_start = col_idx * SMALL_SCREEN_WIDTH
y_start = row_idx * SMALL_SCREEN_HEIGHT
# 获取帧或创建状态帧
if stream_id in frames and frames[stream_id] is not None:
# 有有效帧,调整大小并显示
frame = cv2.resize(frames[stream_id], (SMALL_SCREEN_WIDTH, SMALL_SCREEN_HEIGHT))
# 添加流ID和状态信息
status_text = f"{stream_id}"
if stream_id in stats:
status = stats[stream_id].get("connection_status", "unknown")
# 截断状态文本,避免太长
if len(status) > 20:
status = status[:20] + "..."
status_text += f" - {status}"
# 添加检测状态
detection_enabled = stats[stream_id].get("detection_enabled", False)
if detection_enabled:
status_text += " [DET]"
# 添加抽帧信息
frame_skip = stats[stream_id].get("frame_skip", 0)
if frame_skip > 0:
status_text += f" [SKIP:{frame_skip}]"
cv2.putText(frame, status_text, (10, 30),
cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 255, 0), 2)
else:
# 没有有效帧,显示状态信息
if stream_id in stats:
status = stats[stream_id].get("connection_status", "disconnected")
if "error" in status or "disconnected" in status:
frame = create_status_frame(
f"{stream_id}: {status}",
SMALL_SCREEN_WIDTH,
SMALL_SCREEN_HEIGHT,
(0, 0, 100) # 红色背景表示错误
)
elif "connecting" in status or "reconnecting" in status:
frame = create_status_frame(
f"{stream_id}: {status}",
SMALL_SCREEN_WIDTH,
SMALL_SCREEN_HEIGHT,
(0, 100, 100) # 黄色背景表示连接中
)
else:
frame = create_status_frame(
f"{stream_id}: {status}",
SMALL_SCREEN_WIDTH,
SMALL_SCREEN_HEIGHT,
(0, 0, 0) # 黑色背景表示未知状态
)
else:
frame = create_status_frame(
f"{stream_id}: Not configured",
SMALL_SCREEN_WIDTH,
SMALL_SCREEN_HEIGHT,
(50, 50, 50) # 灰色背景表示未配置
)
# 将帧放置到画布上
canvas[y_start:y_start + SMALL_SCREEN_HEIGHT, x_start:x_start + SMALL_SCREEN_WIDTH] = frame
# 显示画布
cv2.imshow("Multi-Stream Display", canvas)
# 检查按键
key = cv2.waitKey(30) & 0xFF
if key == ord('q'):
stopped = True
break
elif key == ord('d'):
# 切换所有流的检测状态
if stream_manager:
for stream_id in stream_manager.get_active_streams():
current = stream_manager.get_stream_stats(stream_id).get("detection_enabled", False)
stream_manager.enable_detection(stream_id, not current)
except Exception as e:
logger.error(f"Error in display loop: {e}")
time.sleep(1)
cv2.destroyAllWindows()
# FastAPI路由
@app.on_event("startup")
async def startup_event():
"""应用启动时初始化"""
global stream_manager, display_thread
stream_manager = StreamManager()
display_thread = threading.Thread(target=display_loop, daemon=True)
display_thread.start()
logger.info("Multi-stream display system started")
@app.on_event("shutdown")
async def shutdown_event():
"""应用关闭时清理资源"""
global stopped, stream_manager
stopped = True
if stream_manager:
stream_manager.stop_all()
logger.info("Multi-stream display system stopped")
@app.get("/")
async def root():
"""根路由,返回系统信息"""
return {"message": "Multi-Stream Video Management System", "status": "running"}
@app.get("/streams")
async def list_streams():
"""获取所有流列表"""
if not stream_manager:
raise HTTPException(status_code=500, detail="Stream manager not initialized")
streams = stream_manager.get_active_streams()
stats = stream_manager.get_all_stats()
return {
"streams": streams,
"stats": stats
}
@app.post("/streams/{stream_id}")
async def add_stream(stream_id: str, config: StreamConfig):
"""添加新流"""
if not stream_manager:
raise HTTPException(status_code=500, detail="Stream manager not initialized")
if stream_manager.add_stream(stream_id, config.stream_url,
buffer_size=config.buffer_size,
hw_accel=config.hw_accel,
timeout=config.timeout,
reconnect_delay=config.reconnect_delay,
max_retries=config.max_retries,
keyframe_only=config.keyframe_only,
frame_skip=config.frame_skip): # 新增:传递frame_skip参数
return {"message": f"Stream {stream_id} added successfully"}
else:
raise HTTPException(status_code=400, detail=f"Stream {stream_id} already exists")
@app.delete("/streams/{stream_id}")
async def remove_stream(stream_id: str):
"""删除流"""
if not stream_manager:
raise HTTPException(status_code=500, detail="Stream manager not initialized")
if stream_manager.remove_stream(stream_id):
return {"message": f"Stream {stream_id} removed successfully"}
else:
raise HTTPException(status_code=404, detail=f"Stream {stream_id} not found")
@app.post("/streams/{stream_id}/start")
async def start_stream(stream_id: str):
"""启动指定流"""
if not stream_manager:
raise HTTPException(status_code=500, detail="Stream manager not initialized")
if stream_manager.start_stream(stream_id):
return {"message": f"Stream {stream_id} started successfully"}
else:
raise HTTPException(status_code=404, detail=f"Stream {stream_id} not found")
@app.post("/streams/{stream_id}/stop")
async def stop_stream(stream_id: str):
"""停止指定流"""
if not stream_manager:
raise HTTPException(status_code=500, detail="Stream manager not initialized")
if stream_manager.stop_stream(stream_id):
return {"message": f"Stream {stream_id} stopped successfully"}
else:
raise HTTPException(status_code=404, detail=f"Stream {stream_id} not found")
@app.put("/streams/{stream_id}/settings")
async def update_stream_settings(stream_id: str, settings: StreamUpdate):
"""更新流设置"""
if not stream_manager:
raise HTTPException(status_code=500, detail="Stream manager not initialized")
# 过滤掉None值
update_params = {k: v for k, v in settings.model_dump().items() if v is not None}
if not update_params:
raise HTTPException(status_code=400, detail="No valid parameters provided for update")
stream_manager.update_stream_settings(stream_id, **update_params)
return {"message": f"Stream {stream_id} settings updated successfully"}
@app.get("/streams/{stream_id}/frame")
async def get_stream_frame(stream_id: str, processed: bool = True):
"""获取指定流的当前帧(JPEG格式)"""
if not stream_manager:
raise HTTPException(status_code=500, detail="Stream manager not initialized")
frame = stream_manager.get_frame(stream_id, processed)
if frame is None:
raise HTTPException(status_code=404, detail=f"No frame available for stream {stream_id}")
# 将帧编码为JPEG
_, jpeg_frame = cv2.imencode('.jpg', frame)
return StreamingResponse(
iter([jpeg_frame.tobytes()]),
media_type="image/jpeg"
)
@app.post("/streams/{stream_id}/detection")
async def toggle_detection(stream_id: str, enable: bool):
"""启用或禁用目标检测"""
if not stream_manager:
raise HTTPException(status_code=500, detail="Stream manager not initialized")
if stream_manager.enable_detection(stream_id, enable):
status = "enabled" if enable else "disabled"
return {"message": f"Detection {status} for stream {stream_id}"}
else:
raise HTTPException(status_code=404, detail=f"Stream {stream_id} not found")
@app.post("/models")
async def load_model(config: DetectionConfig):
"""加载YOLOv8模型"""
if not stream_manager:
raise HTTPException(status_code=500, detail="Stream manager not initialized")
try:
model_name = stream_manager.load_model(config)
return {"message": f"Model {model_name} loaded successfully", "model_name": model_name}
except Exception as e:
raise HTTPException(status_code=500, detail=f"Failed to load model: {str(e)}")
@app.get("/models")
async def list_models():
"""获取已加载的模型列表"""
if not stream_manager:
raise HTTPException(status_code=500, detail="Stream manager not initialized")
models = stream_manager.get_loaded_models()
return {"models": models}
@app.post("/streams/{stream_id}/models/{model_name}")
async def add_model_to_stream(stream_id: str, model_name: str):
"""为视频流添加模型"""
if not stream_manager:
raise HTTPException(status_code=500, detail="Stream manager not initialized")
try:
stream_manager.add_model_to_stream(stream_id, model_name)
return {"message": f"Model {model_name} added to stream {stream_id}"}
except ValueError as e:
raise HTTPException(status_code=404, detail=str(e))
@app.delete("/streams/{stream_id}/models/{model_name}")
async def remove_model_from_stream(stream_id: str, model_name: str):
"""从视频流移除模型"""
if not stream_manager:
raise HTTPException(status_code=500, detail="Stream manager not initialized")
stream_manager.remove_model_from_stream(stream_id, model_name)
return {"message": f"Model {model_name} removed from stream {stream_id}"}
@app.get("/streams/{stream_id}/models")
async def get_stream_models(stream_id: str):
"""获取视频流激活的模型列表"""
if not stream_manager:
raise HTTPException(status_code=500, detail="Stream manager not initialized")
models = stream_manager.get_stream_models(stream_id)
return {"stream_id": stream_id, "models": models}
@app.post("/models/{model_name}/alerts")
async def add_alert_condition(model_name: str, condition: AlertCondition, action: AlertAction):
"""为模型添加报警条件"""
if not stream_manager:
raise HTTPException(status_code=500, detail="Stream manager not initialized")
try:
stream_manager.add_alert_condition(model_name, condition, action)
return {"message": f"Alert condition added for model {model_name}"}
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
if __name__ == "__main__":
# 启动FastAPI应用
uvicorn.run(app, host="0.0.0.0", port=8000)
5.2 测试代码
import os.path
import requests
import json
import time
class VideoStreamController:
def __init__(self, base_url="http://localhost:8000"):
self.base_url = base_url
self.session = requests.Session()
def _make_request(self, method, endpoint, data=None):
"""发送HTTP请求"""
url = f"{self.base_url}{endpoint}"
try:
if method == "GET":
response = self.session.get(url)
elif method == "POST":
response = self.session.post(url, json=data)
elif method == "PUT":
response = self.session.put(url, json=data)
elif method == "DELETE":
response = self.session.delete(url)
else:
raise ValueError(f"不支持的HTTP方法: {method}")
if response.status_code >= 200 and response.status_code < 300:
return response.json()
else:
print(f"请求失败: {response.status_code} - {response.text}")
return None
except Exception as e:
print(f"请求出错: {e}")
return None
def add_stream(self, stream_id, stream_url, **kwargs):
"""添加视频流"""
data = {
"stream_url": stream_url,
"buffer_size": 5,
"hw_accel": kwargs.get("hw_accel", None),
"timeout": kwargs.get("timeout", 5000000),
"reconnect_delay": kwargs.get("reconnect_delay", 5),
"max_retries": kwargs.get("max_retries", -1),
"keyframe_only": kwargs.get("keyframe_only", False)
}
return self._make_request("POST", f"/streams/{stream_id}", data)
def start_stream(self, stream_id):
"""启动视频流"""
return self._make_request("POST", f"/streams/{stream_id}/start")
def stop_stream(self, stream_id):
"""停止视频流"""
return self._make_request("POST", f"/streams/{stream_id}/stop")
def remove_stream(self, stream_id):
"""移除视频流"""
return self._make_request("DELETE", f"/streams/{stream_id}")
def list_streams(self):
"""获取所有流列表"""
return self._make_request("GET", "/streams")
def update_stream_settings(self, stream_id, **kwargs):
"""更新流设置"""
data = {}
allowed_params = ["buffer_size", "hw_accel", "timeout", "reconnect_delay", "max_retries", "keyframe_only","frame_skip"]
for key, value in kwargs.items():
if key in allowed_params:
data[key] = value
return self._make_request("PUT", f"/streams/{stream_id}/settings", data)
def get_frame(self, stream_id, processed=True):
"""获取视频帧(返回字节数据)"""
url = f"{self.base_url}/streams/{stream_id}/frame?processed={str(processed).lower()}"
try:
response = self.session.get(url)
if response.status_code == 200:
return response.content
else:
print(f"获取帧失败: {response.status_code} - {response.text}")
return None
except Exception as e:
print(f"请求出错: {e}")
return None
def toggle_detection(self, stream_id, enable):
"""启用或禁用目标检测"""
return self._make_request("POST", f"/streams/{stream_id}/detection?enable={str(enable).lower()}")
def load_model(self, model_path, confidence_threshold=0.5, classes=None):
"""加载YOLOv8模型"""
data = {
"model_path": r"weights/"+str(model_path),
"confidence_threshold": confidence_threshold,
"classes": classes
}
return self._make_request("POST", "/models", data)
def list_models(self):
"""获取已加载的模型列表"""
return self._make_request("GET", "/models")
def add_model_to_stream(self, stream_id, model_name):
"""为视频流添加模型"""
return self._make_request("POST", f"/streams/{stream_id}/models/{model_name}")
def remove_model_from_stream(self, stream_id, model_name):
"""从视频流移除模型"""
return self._make_request("DELETE", f"/streams/{stream_id}/models/{model_name}")
def get_stream_models(self, stream_id):
"""获取视频流激活的模型列表"""
return self._make_request("GET", f"/streams/{stream_id}/models")
def add_alert_condition(self, model_name, class_name, min_confidence=0.5, min_count=1,
max_count=None, cooldown=5, action_type="log", action_config=None):
"""为模型添加报警条件"""
if action_config is None:
action_config = {}
condition = {
"class_name": class_name,
"min_confidence": min_confidence,
"min_count": min_count,
"max_count": max_count,
"cooldown": cooldown
}
action = {
"action_type": action_type,
"config": action_config
}
data = {
"condition": condition,
"action": action
}
return self._make_request("POST", f"/models/{model_name}/alerts", data)
# 使用示例
if __name__ == "__main__":
controller = VideoStreamController()
# 1. 添加视频流
print("1. 添加视频流")
controller.add_stream("cam1", "rtsp://localhost:5001/stream_1")
controller.add_stream("cam2", "rtsp://localhost:5001/stream_2")
controller.add_stream("cam3", "rtsp://localhost:5001/stream_3")
controller.add_stream("cam4", "rtsp://localhost:5001/stream_4")
controller.add_stream("cam5", "rtsp://localhost:5001/stream_1")
controller.add_stream("cam6", "rtsp://localhost:5001/stream_2")
controller.add_stream("cam7", "rtsp://localhost:5001/stream_3")
controller.add_stream("cam8", "rtsp://localhost:5001/stream_4")
# 2. 启动视频流
print("2. 启动视频流")
controller.start_stream("cam1")
controller.start_stream("cam2")
controller.start_stream("cam3")
controller.start_stream("cam4")
controller.start_stream("cam5")
controller.start_stream("cam6")
controller.start_stream("cam7")
controller.start_stream("cam8")
# 等待一段时间让流稳定
time.sleep(3)
# 3. 加载YOLOv8模型
print("3. 加载YOLOv8模型")
result = controller.load_model("yolo11n.pt", confidence_threshold=0.5, classes=[0, 1, 2])
if result:
model_name = result.get("model_name")
print(f"已加载模型: {model_name}")
time.sleep(2)
# 4. 为视频流添加模型
print("4. 为视频流添加模型")
controller.add_model_to_stream("cam1", model_name)
controller.add_model_to_stream("cam2", model_name)
controller.add_model_to_stream("cam3", model_name)
controller.add_model_to_stream("cam4", model_name)
controller.add_model_to_stream("cam5", model_name)
controller.add_model_to_stream("cam6", model_name)
controller.add_model_to_stream("cam7", model_name)
controller.add_model_to_stream("cam8", model_name)
# 5. 启用检测
print("5. 启用检测")
controller.toggle_detection("cam1", True)
controller.toggle_detection("cam2", True)
controller.toggle_detection("cam3", True)
controller.toggle_detection("cam4", True)
controller.toggle_detection("cam5", True)
controller.toggle_detection("cam6", True)
controller.toggle_detection("cam7", True)
controller.toggle_detection("cam8", True)
# 6. 添加报警条件
# print("6. 添加报警条件")
# controller.add_alert_condition(
# model_name,
# "person",
# min_confidence=0.7,
# min_count=1,
# action_type="log"
# )
#
# controller.add_alert_condition(
# model_name,
# "car",
# min_confidence=0.6,
# min_count=2,
# action_type="log"
# )
#
# # 7. 获取带检测结果的帧
# print("7. 获取带检测结果的帧")
# frame_data = controller.get_frame("cam1", processed=True)
# if frame_data:
# with open("detected_frame.jpg", "wb") as f:
# f.write(frame_data)
# print("已保存带检测结果的帧为 detected_frame.jpg")
#
# # 8. 查看当前状态
# print("8. 查看当前状态")
# streams = controller.list_streams()
# if streams:
# print("当前所有流状态:")
# print(json.dumps(streams, indent=2, ensure_ascii=False))
#
# models = controller.list_models()
# if models:
# print("已加载的模型:")
# print(json.dumps(models, indent=2, ensure_ascii=False))
# time.sleep(10)
# controller.update_stream_settings("cam1", frame_skip=5)
# controller.update_stream_settings("cam2", frame_skip=5)
# controller.update_stream_settings("cam3", frame_skip=5)
# controller.update_stream_settings("cam4", frame_skip=5)
# controller.update_stream_settings("cam5", frame_skip=5)
# controller.update_stream_settings("cam6", frame_skip=5)
# controller.update_stream_settings("cam7", frame_skip=5)
# controller.update_stream_settings("cam8", frame_skip=5)
# # 9. 查看特定流的模型
# cam1_models = controller.get_stream_models("cam1")
# if cam1_models:
# print("cam1激活的模型:")
# print(json.dumps(cam1_models, indent=2, ensure_ascii=False))
#
# # 10. 停止检测
# print("10. 停止检测")
# time.sleep(10)
# controller.toggle_detection("cam1", False)
# controller.toggle_detection("cam2", False)
# controller.toggle_detection("cam3", False)
# controller.toggle_detection("cam4", False)
# controller.toggle_detection("cam5", False)
# controller.toggle_detection("cam6", False)
# controller.toggle_detection("cam7", False)
# controller.toggle_detection("cam8", False)
#
# # 11. 从流中移除模型
# print("11. 从流中移除模型")
# controller.remove_model_from_stream("cam1", model_name)
#
# # 12. 停止并移除所有流
# print("12. 停止并移除所有流")
# controller.stop_stream("cam1")
# controller.stop_stream("cam2")
# controller.stop_stream("cam3")
# controller.stop_stream("cam4")
#
# controller.remove_stream("cam1")
# controller.remove_stream("cam2")
# controller.remove_stream("cam3")
# controller.remove_stream("cam4")
# controller.update_stream_settings("cam1", keyframe_only=False,frame_skip = 0)
print("演示完成!")
5.3 结果展示
- 原始视频

- 推理结果(跳帧检测:帧间隔3)

- 推理结果(跳帧检测:间隔5帧)

- 原始画面对比

现存问题
在多路分析的时候,分析帧率较低,画面整体表现卡顿
- 基于ultralytics的推理需要考虑线程安全问题。
- 由于本地环境运行在python3.9上,线程调用存在严重GIL锁问题,整体效率不高。
- 模型推理所占用的资源较多,考虑采用INT8量化后的模型进行资源的合理分配
- pytorch侧重于训练,在推理上并不具备优势。
解决方案
- 针对python GIL锁问题,我们后续会考虑将线程换为进程进行规避。(读者需要的话,我也会实现C/C++版本的高效推理)。
- 采用推理工具对模型进行量化,合理分配资源使用。
- 采用推理工具实现模型的高性能部署。
总结
本章节简要介绍了计算机视觉领域的常见算法以及工业目标检测领域使用的yolo系列模型,在已有拉流展示系统的基础上封装了模型的推理,采用ultralytics提供的yolo11n模型,即可实现对人流的检测。但是为了进一步实现高效的推理,实现真正的多路并发推理,我们还需要有很长的路要走
下期预告
- onnx模型及导出
- onnxruntime GPU推理测试

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 11
11 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)