【大模型LLM学习】Research Agent学习笔记
本文介绍了两种研究型智能体(Research Agent)的架构设计——Search-O1和MetaGPT的Researcher
·
【大模型LLM学习】Research Agent学习笔记
前言
这里research agent指的是不是一个简单的Q-A交互就能回答的问题或者完成的任务,需要调用搜索引擎搜索、复杂推理分析后,得到一个答案或者报告。
1 Search-O1
- 回答一个需要查资料、多步推理的问题时,RAG的流程是先搜索得到相关文档(或者先任务拆解然后每个任务搜索、推理回答),然后把文档或者浓缩结果给模型,模型推理得到结果
- Search-o1的编排流程更加智能,可以一定程度上避免模型乱猜
- Search-o1整体是顺序执行,每步下决定是否需要搜索和总结,再把每步的结果融到完整的推理上下文里面得出最终的结论
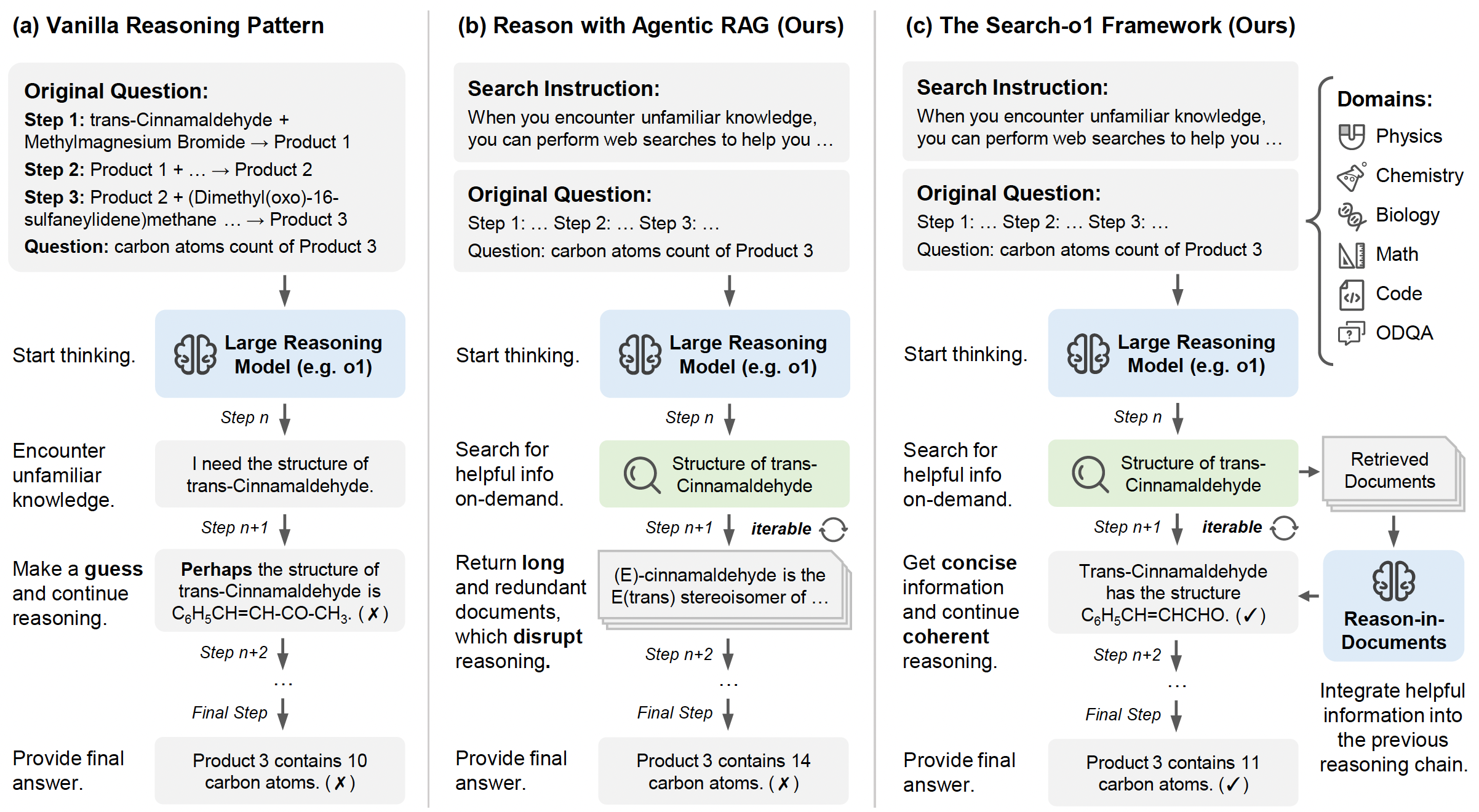
1.1 具体的prompt
1.1(a) Agentic RAG
RAG信息获取部分,也是分为获取摘要和完整网页信息
search-o1:在前面推理结果的基础上,继续获取和推理
2 MetaGPT的Researcher
2.1 整体架构
模仿人写报告,包括这些步骤:
- 子任务分解
把给定的研究问题,分解为若干个适合通过搜索引擎查找的子问题 - 搜索子问题
使用搜索引擎逐一对每个子问题进行检索 - 评估搜索结果
查看搜索结果的标题、原始 URL、摘要等信息,判断其相关性和可靠性,决定是否需要进一步访问该网页 - 浏览最相关网页
点击需要深入探索的网页链接,进入页面后浏览 - 提取并记录信息
从有价值的网页中提取分析与研究问题相关的关键信息,总结整理 - 汇总信息并撰写报告
将所有总结整理结果进行汇总,撰写一份完整的报告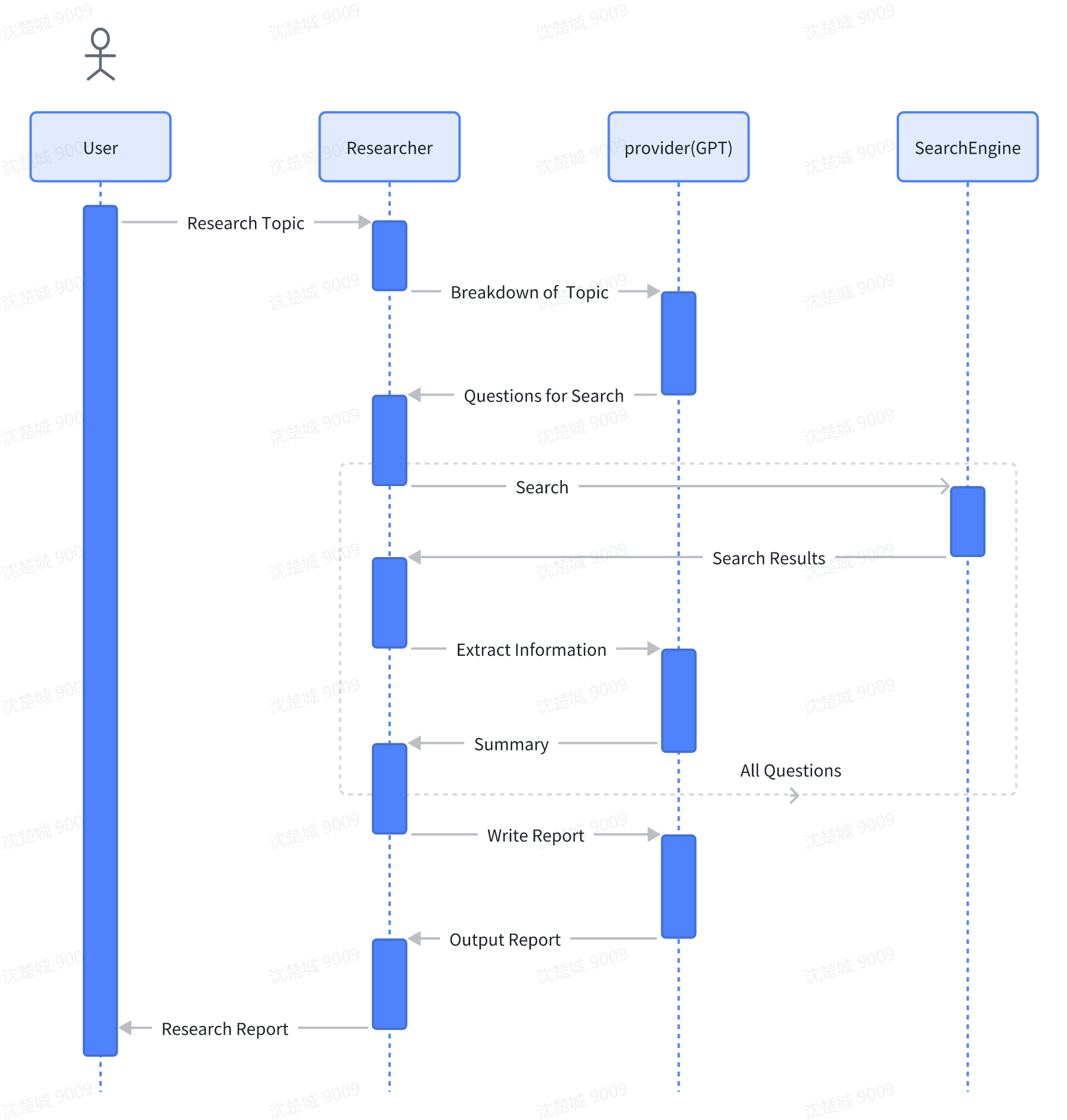
2.2 代码实现
主要包括3个部分:
- 信息搜索
- 网页浏览和总结
- 完成报告
2.2.1 信息搜索
- step1 问题改写 - 把研究问题拆解为多个搜索关键词
- step2 关键词搜索 - 调用搜索引擎从网上收集和关键词有关的信息
- step3 子任务query生成 - 基于关键词和搜索结果,把研究问题拆分为多个子问题【在没有搜索结果前先拆分,很容易出幻觉】
- step4 深度信息检索 - 使用搜索引擎搜索子问题,对搜索结果使用LLM按照相关性和可靠性排序取top【在这里引入当前时间,判断信息是否过时等】
SEARCH_TOPIC_PROMPT = """Please provide up to 2 necessary keywords related to your research topic for Google search. \
Your response must be in JSON format, for example: ["keyword1", "keyword2"]."""
SUMMARIZE_SEARCH_PROMPT = """### Requirements
1. The keywords related to your research topic and the search results are shown in the "Search Result Information" section.
2. Provide up to {decomposition_nums} queries related to your research topic base on the search results.
3. Please respond in the following JSON format: ["query1", "query2", "query3", ...].
### Search Result Information
{search_results}
"""
class CollectLinks(Action):
async def run(
self,
topic: str,
decomposition_nums: int = 4,
url_per_query: int = 4,
system_text: str | None = None,
) -> dict[str, list[str]]:
"""Run the action to collect links.
Args:
topic: The research topic.
decomposition_nums: The number of search questions to generate.
url_per_query: The number of URLs to collect per search question.
system_text: The system text.
Returns:
A dictionary containing the search questions as keys and the collected URLs as values.
"""
system_text = system_text if system_text else RESEARCH_TOPIC_SYSTEM.format(topic=topic)
# step1: 问题改写,得到一系列用于搜索的关键词
keywords = await self._aask(SEARCH_TOPIC_PROMPT, [system_text])
try:
keywords = OutputParser.extract_struct(keywords, list)
keywords = parse_obj_as(list[str], keywords)
except Exception as e:
logger.exception(f"fail to get keywords related to the research topic \"{topic}\" for {e}")
keywords = [topic]
# step2: 关键词搜索,得到搜索结果
results = await asyncio.gather(*(self.search_engine.run(i, as_string=False) for i in keywords))
# step3:根据关键词和搜索结果,把原始research_question拆分为子问题,获得子问题query
def gen_msg():
while True:
search_results = "\n".join(f"#### Keyword: {i}\n Search Result: {j}\n" for (i, j) in zip(keywords, results))
prompt = SUMMARIZE_SEARCH_PROMPT.format(decomposition_nums=decomposition_nums, search_results=search_results)
yield prompt
remove = max(results, key=len)
remove.pop()
if len(remove) == 0:
break
prompt = reduce_message_length(gen_msg(), self.llm.model, system_text, CONFIG.max_tokens_rsp)
logger.debug(prompt)
queries = await self._aask(prompt, [system_text])
try:
queries = OutputParser.extract_struct(queries, list)
queries = parse_obj_as(list[str], queries)
except Exception as e:
logger.exception(f"fail to break down the research question due to {e}")
queries = keywords
ret = {}
# step4: 深度信息检索,搜索子问题,并对结果进行筛选取top
for query in queries:
ret[query] = await self._search_and_rank_urls(topic, query, url_per_query)
return ret
对于搜索到的内容进行排序的方式为
COLLECT_AND_RANKURLS_PROMPT = """### Topic
{topic}
### Query
{query}
### The online search results
{results}
### Requirements
Please remove irrelevant search results that are not related to the query or topic.
If the query is time-sensitive or specifies a certain time frame, please also remove search results that are outdated or outside the specified time frame. Notice that the current time is {time_stamp}.
Then, sort the remaining search results based on the link credibility. If two results have equal credibility, prioritize them based on the relevance.
Provide the ranked results' indices in JSON format, like [0, 1, 3, 4, ...], without including other words.
"""
async def _search_urls(self, query: str, max_results: int) -> list[dict[str, str]]:
"""Use search_engine to get urls.
Returns:
e.g. [{"title": "...", "link": "...", "snippet", "..."}]
"""
return await self.search_engine.run(query, max_results=max_results, as_string=False)
async def _search_and_rank_urls(
self, topic: str, query: str, num_results: int = 4, max_num_results: int = None
) -> list[str]:
"""Search and rank URLs based on a query.
Args:
topic: The research topic.
query: The search query.
num_results: The number of URLs to collect.
max_num_results: The max number of URLs to collect.
Returns:
A list of ranked URLs.
"""
max_results = max_num_results or max(num_results * 2, 6)
results = await self._search_urls(query, max_results=max_results)
if len(results) == 0:
return []
_results = "\n".join(f"{i}: {j}" for i, j in zip(range(max_results), results))
time_stamp = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
prompt = COLLECT_AND_RANKURLS_PROMPT.format(topic=topic, query=query, results=_results, time_stamp=time_stamp)
logger.debug(prompt)
indices = await self._aask(prompt)
try:
indices = OutputParser.extract_struct(indices, list)
assert all(isinstance(i, int) for i in indices)
except Exception as e:
logger.exception(f"fail to rank results for {e}")
indices = list(range(max_results))
results = [results[i] for i in indices]
if self.rank_func:
results = self.rank_func(results)
return [i["link"] for i in results[:num_results]]
2.2.2 网页信息浏览和总结
- 使用selenium+bs4依次获取网页信息(文本格式)
- 总结单条url信息得到chunk:(1) 如果参考资料不能直接来回答子问题,详细总结参考资料;(2)如果参考资料和子问题不相关,回答“不相关”;(3)如果参考资料中有“重要事实信息”包括数字和统计信息,需要全部保留
WEB_BROWSE_AND_SUMMARIZE_PROMPT = """### Requirements
1. Utilize the text in the "Reference Information" section to respond to the question "{query}".
2. If the question cannot be directly answered using the text, but the text is related to the research topic, please provide \
a comprehensive summary of the text.
3. If the text is entirely unrelated to the research topic, please reply with a simple text "Not relevant."
4. Include all relevant factual information, numbers, statistics, etc., if available.
### Reference Information
{content}
"""
class WebBrowseAndSummarize(Action):
async def run(
self,
url: str,
*urls: str,
query: str,
system_text: str = RESEARCH_BASE_SYSTEM,
) -> dict[str, str]:
"""Run the action to browse the web and provide summaries.
Args:
url: The main URL to browse.
urls: Additional URLs to browse.
query: The research question.
system_text: The system text.
Returns:
A dictionary containing the URLs as keys and their summaries as values.
"""
# Web page browsing and content extraction
contents = await self.web_browser_engine.run(url, *urls)
if not urls:
contents = [contents]
# Web page content summarization
summaries = {}
prompt_template = WEB_BROWSE_AND_SUMMARIZE_PROMPT.format(query=query, content="{}")
for u, content in zip([url, *urls], contents):
content = content.inner_text
chunk_summaries = []
# 如果单个资料文本超长,切成chunk的形式
for prompt in generate_prompt_chunk(content, prompt_template, self.llm.model, system_text, CONFIG.max_tokens_rsp):
logger.debug(prompt)
summary = await self._aask(prompt, [system_text])
if summary == "Not relevant.":
continue
chunk_summaries.append(summary)
if not chunk_summaries:
summaries[u] = None
continue
if len(chunk_summaries) == 1:
summaries[u] = chunk_summaries[0]
continue
# 对切分了后的仍然是单个文档的,把summary拼起来
content = "\n".join(chunk_summaries)
prompt = WEB_BROWSE_AND_SUMMARIZE_PROMPT.format(query=query, content=content)
summary = await self._aask(prompt, [system_text])
summaries[u] = summary
return summaries
2.2.3 研究报告生成
RESEARCH_BASE_SYSTEM = """You are an AI critical thinker research assistant. Your sole purpose is to write well \
written, critically acclaimed, objective and structured reports on the given text."""
RESEARCH_TOPIC_SYSTEM = "You are an AI researcher assistant, and your research topic is:\n#TOPIC#\n{topic}"
CONDUCT_RESEARCH_PROMPT = """### Reference Information
{content}
### Requirements
Please provide a detailed research report in response to the following topic: "{topic}", using the information provided \
above. The report must meet the following requirements:
- Focus on directly addressing the chosen topic.
- Ensure a well-structured and in-depth presentation, incorporating relevant facts and figures where available.
- Present data and findings in an intuitive manner, utilizing feature comparative tables, if applicable.
- The report should have a minimum word count of 2,000 and be formatted with Markdown syntax following APA style guidelines.
- Include all source URLs in APA format at the end of the report.
"""
class ConductResearch(Action):
async def run(
self,
topic: str,
content: str,
system_text: str = RESEARCH_BASE_SYSTEM,
) -> str:
"""Run the action to conduct research and generate a research report.
Args:
topic: The research topic.
content: The content for research.
system_text: The system text.
Returns:
The generated research report.
"""
prompt = CONDUCT_RESEARCH_PROMPT.format(topic=topic, content=content)
logger.debug(prompt)
self.llm.auto_max_tokens = True
return await self._aask(prompt, [system_text])
Reference
- search-o1的github:https://github.com/sunnynexus/Search-o1
- metagpt的doc:https://docs.deepwisdom.ai/main/en/guide/use_cases/agent/researcher.html
- metagpt的源代码:https://github.com/FoundationAgents/MetaGPT/blob/main/metagpt/actions/research.py

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 15
15 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)