检索过时了?微软KBLaM实现知识库“脑内集成”,推理更稳更快|ICLR 2025高光论文
传统 RAG 像给大模型外挂一座图书馆:先查目录,再搬书,最后让模型读书答题——流程长、延迟高、易翻车。微软在 ICLR 2025 亮相的干脆拆掉这座图书馆,把整座知识库压缩成连续键值向量,直接“缝”进模型注意力层,实现零检索、零延迟、零微调的知识推理。检索已成过去式,知识现在住在大脑的突触里。
前言:
检索已死?让知识直接“长”在模型里
传统 RAG 像给大模型外挂一座图书馆:先查目录,再搬书,最后让模型读书答题——流程长、延迟高、易翻车。微软在 ICLR 2025 亮相的 KBLaM(Knowledge Base augmented Language Model) 干脆拆掉这座图书馆,把整座知识库压缩成连续键值向量,直接“缝”进模型注意力层,实现零检索、零延迟、零微调的知识推理。
一句话总结:检索已成过去式,知识现在住在大脑的突触里。
1:KBLaM彻底抛弃检索,AI终于“记住”而不是“搜索”
不再依赖检索,也不再受上下文长度束缚!ICLR 2025 热议论文《KBLaM: Knowledge Base Augmented Language Models》近日在 GitHub 开源,引爆 AI 社区。
由微软研究院主导的 KBLaM 技术,彻底重构了知识增强语言模型的范式——
🔹 无需外挂检索模块:知识直接内化,告别 RAG 带来的延迟与复杂性
🔹 计算开销线性增长:复杂度从传统注意力的 O(N²) 降至 O(N),扩展性大幅提升
🔹 轻量适配,原模型不动:仅通过小型适配器注入知识能力,不破坏原始架构
这一次,AI 不再“临时查资料”,而是真正“记住了知识”。
1.1 原子宇宙炸裂图:技术原理的 0.1 秒慢镜头
RAG:边查边答,像开卷考试时疯狂翻书;
KBLaM:考前把整本笔记背进脑海,提笔直接默写。
2:三大开源模型实测:Llama 3与Phi-3一键优化全攻略
2.1接入Llama 3和Phi-3:官方支持模型清单及快速扩展技巧
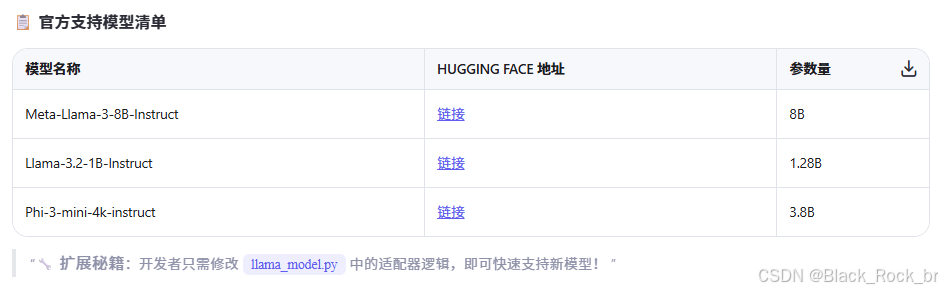
说明:
- 所有模型均来自 Hugging Face 官方仓库,可直接下载使用。
- 支持一键接入,适配灵活,便于集成到现有系统中。
3:5min 光速部署:从 0 到推理,键盘还没敲热就完事了
环境配置(Linux/MacOS)
# 1. 克隆仓库
git clone https://github.com/microsoft/KBLaM
# 2. 安装依赖
pip install -e .
huggingface-cli login # 输入HF token
知识库注入示例

4:决胜五式:核心优势一次亮出不留底
- 零知识泄露:无知识库时输出与原始模型一致,确保行为可控。
- 渐进式增强:支持通过增量训练动态更新知识适配器。
- 多模态扩展:当前支持文本嵌入,架构预留图像等模态扩展接口。
- 高性价比:1B 参数模型结合知识库即可媲美 8B 模型表现。
- 参数冻结设计:完整保留原始模型权重,便于研究与复现。
5:后人类知识奇点:一秒即全知的临界点
随着 KBLaM 的开源,我们正站在语言模型演进的关键拐点——从依赖“内在记忆”的智能,迈向依托“外挂认知”的新范式。这一转变或将催生:
- 企业知识资产的智能激活:让每一份文档都成为AI的实时决策依据;
- 科研世界的动态推理引擎:文献库即知识大脑,实现信息的即时理解与推演;
- 个性化AI的长期记忆体:为每个用户构建可扩展、可更新的认知外脑。
这不仅是模型能力的延伸,更是智能形态的升维。
https://github.com/microsoft/KBLaM![]() https://github.com/microsoft/KBLaM
https://github.com/microsoft/KBLaM

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 22
22 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)