多模态大模型-BLIP
我们提出了BLIP,这是一种新的视觉-语言预训练(VLP)框架,在广泛的下游视觉-语言任务上具有最先进的性能,包括基于理解和基于生成的任务。BLIP使用从大规模噪声图像-文本对中引导构建的数据集,通过注入多样化的合成字幕并去除噪声字幕,对编码器-解码器混合多模态模型进行预训练。我们发布了引导构建的数据集,以促进未来的视觉-语言研究。
本文首发于微信公众号:人工智能与图像处理
一,BLIP
BLIP(Bootstrapping Language-Image Pre-training)是由Salesforce Research提出的多模态大模型系列,旨在统一视觉语言理解与生成任务。其核心创新在于解决传统模型的局限性:兼顾理解与生成能力,并高效处理噪声数据。以下是BLIP的核心解析与技术演进:
一、核心创新与架构
1. MED混合架构(Multimodal Mixture of Encoder-Decoder)
BLIP提出统一架构处理多任务,包含三个关键组件:
- 视觉编码器:基于ViT提取图像特征。
- 文本编码器与解码器:共享参数(除自注意力层外),支持双向理解(编码器)与自回归生成(解码器)。
- 多模态交互:通过跨注意力机制融合视觉与文本特征。

2. 预训练任务
联合优化三个目标,提升跨模态对齐能力:
- 图文对比损失(ITC):对齐图像与文本特征空间,增强相似性度量。
- 图文匹配损失(ITM):二分类任务,判断图文是否匹配,采用难负例挖掘提升判别力。
- 语言建模损失(LM):自回归生成图像描述,替代传统MLM任务,提升生成连贯性。
二、数据优化:CapFilt方法
针对网络爬取数据的噪声问题,BLIP提出Captioner与Filter双模块:
- Captioner:基于人工标注数据微调的解码器,为网络图像生成合成描述Ts。
- Filter:基于编码器的二分类模型,剔除原始网络文本Tw和合成文本Ts中不匹配的噪声。
效果:清洗后数据训练的新模型,在检索与生成任务中性能显著提升(例如COCO图像描述任务BLEU-4得分提高2.7%)。
三、BLIP系列演进
1. BLIP-2:冻结预训练模型的桥梁
- Q-Former轻量模块:连接冻结的图像编码器(如ViT)与大语言模型(如OPT、FlanT5),通过两阶段训练:
-
阶段1:使用ITC、ITM、ITG任务训练Q-Former,提取与文本相关的视觉特征。
-
阶段2:将Q-Former输出映射为LLM的软提示(soft prompts),激发LLM生成能力。
- 优势:参数量减少至Flamingo的1/54,支持零样本视觉问答与图像描述。
2. BLIP3-o:统一理解与生成的新突破
- 先理解后生成策略:
-
理解阶段:CLIP编码图像为高层语义特征。
-
生成阶段:自回归模型生成中间视觉特征,输入扩散解码器(如DiT)重建图像。
- Flow Matching替代MSE:提升生成多样性与质量,解决确定性输出限制。
- 应用扩展:支持图像编辑、视觉对话等复杂任务,在医疗影像分析(准确率96.8%)与工业质检(缺陷检测99.3%)中表现突出。
四、应用场景
- 图像描述与视觉问答(VQA):为卡通图像生成精准描述(如《纽约客》漫画)。
- 图文检索:跨模态搜索(如电商商品匹配)。
- 智能创作:基于文本提示生成广告设计(如赛博朋克风格图像)。
- 教育/工业:物理概念可视化、工业缺陷检测。
总结
BLIP系列通过统一架构设计(MED/Q-Former)、数据优化技术(CapFilt)及训练策略创新(Flow Matching),解决了多模态任务中理解与生成的兼容性问题,并为低成本部署(冻结预训练模型)与高质量生成(BLIP3-o)铺平道路。其开源生态(代码/模型/数据全公开)正推动多模态技术向工业级应用落地。
二,论文翻译:
摘要
视觉 - 语言预训练(VLP)已推动许多视觉 - 语言任务的性能提升。然而,大多数现有预训练模型仅在基于理解的任务或基于生成的任务中表现出色。此外,性能提升在很大程度上依赖于从网络收集的含噪声图像 - 文本对来扩展数据集,而这类数据作为监督信号并非最优选择。
本文提出 BLIP, 一种新型 VLP 框架,可灵活适配视觉 - 语言理解与生成任务。BLIP 通过引导字幕处理有效利用含噪声的网络数据:一方面利用字幕生成器创建合成字幕,另一方面通过过滤器剔除噪声字幕。实验结果表明,BLIP 在多种视觉 - 语言任务上实现了当前最优性能:
-
图文检索任务中平均召回率 @1 提升 2.7%
-
图像描述任务中 CIDEr 指标提升 2.8%
-
视觉问答任务中 VQA 分数提升 1.6%
此外,BLIP 在零样本迁移至视频 - 语言任务时展现出强大的泛化能力。相关代码、模型与数据集已公开。
1,引言
视觉 - 语言预训练近期在各类多模态下游任务中取得了显著进展。然而,现有方法存在两大局限性:
模型层面:多数方法要么采用基于编码器的模型,要么采用编码器 - 解码器模型。但基于编码器的模型难以直接适配文本生成任务(如图像描述),而编码器 - 解码器模型尚未成功应用于图文检索任务。
数据层面:当前主流方法(如 CLIP、ALBEF、SimVLM)依赖从网络收集的图像 - 文本对进行预训练。尽管扩展数据集能提升性能,但本文表明,含噪声的网络文本并非视觉 - 语言学习的最优监督信号。
为此,我们提出 BLIP(引导式语言 - 图像预训练框架),旨在实现视觉 - 语言理解与生成任务的统一。BLIP 作为新型 VLP 框架,相比现有方法能支持更广泛的下游任务,其创新点从模型与数据层面可概括为:
(a)编码器 - 解码器多模态混合模型(MED):一种适用于高效多任务预训练和灵活迁移学习的新型架构。MED 可作为单模态编码器、图像锚定文本编码器或图像锚定文本解码器运行。该模型通过三个视觉 - 语言目标联合预训练:图文对比学习、图文匹配和图像条件语言建模。
(b)字幕生成与过滤(CapFilt):一种从含噪声图文对中学习的新型数据集引导方法。我们将预训练的 MED 微调为两个模块:一个用于根据网页图像生成合成字幕的字幕生成器,以及一个从原始网页文本和合成文本中剔除噪声字幕的过滤器。
我们开展了广泛的实验与分析,并得出以下关键发现:
• 实验表明,字幕生成器与过滤器通过联合引导字幕处理,在多种下游任务中实现了显著的性能提升。此外我们发现,更具多样性的字幕可带来更大的增益。
• BLIP在图像-文本检索、图像描述、视觉问答、视觉推理和视觉对话等一系列视觉-语言任务上均达到了当前最优性能。当将模型直接零样本迁移至文本-视频检索和视频问答这两项视频-语言任务时,也实现了领先的零样本学习性能。
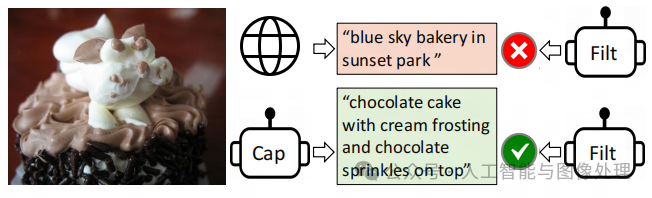
图1. 我们使用字幕生成器(Cap)为网页图像生成合成字幕,并使用过滤器(Filt)剔除噪声字幕
2.1 视觉 - 语言预训练
视觉 - 语言预训练(VLP)旨在通过在大规模图像 - 文本对上预训练模型,提升下游视觉和语言任务的性能。由于获取人工标注文本的成本过高,大多数方法使用从网络爬取的图像和替代文本(alt-text)对。尽管采用了简单的基于规则的过滤方法,网络文本中的噪声仍然普遍存在。然而,噪声的负面影响在很大程度上被数据集规模扩大带来的性能提升所掩盖。我们的论文表明,带噪声的网络文本并非视觉 - 语言学习的最佳选择,并提出了 CapFilt 方法,以更有效的方式利用网络数据集。
许多人尝试将各种视觉和语言任务统一到单个框架中。最大的挑战在于设计能够同时执行基于理解的任务(如图文检索)和基于生成的任务(如图像字幕生成)的模型架构。基于编码器的模型和基于编解码器的模型都无法在两类任务上均表现出色,而单一的统一编解码器也限制了模型的能力。我们提出的多模态混合编解码器模型在广泛的下游任务上提供了更高的灵活性和更好的性能,同时保持了预训练的简洁性和高效性。
2.2 知识蒸馏
知识蒸馏(KD)旨在通过从教师模型中提取知识来提升学生模型的性能。自蒸馏是 KD 的一种特殊情况,其中教师模型和学生模型规模相同。研究表明,自蒸馏在图像分类和最近的视觉语言预训练(VLP)中均有效。与大多数现有 KD 方法(仅强制学生模型输出与教师模型相同的类别预测)不同,我们提出的 CapFilt 可被视为在 VLP 场景中执行 KD 的更有效方式:其中,字幕生成器(captioner)通过语义丰富的合成字幕提取知识,而过滤器(filter)通过去除噪声字幕提取知识。
2.3. 数据增强
尽管数据增强(DA)在计算机视觉领域已被广泛采用,但针对语言任务的数据增强却并非易事。近年来,生成式语言模型已被用于为各种自然语言处理(NLP)任务合成示例。与这些专注于低资源纯语言任务的方法不同,我们的方法展示了在大规模视觉 - 语言预训练中合成字幕的优势。
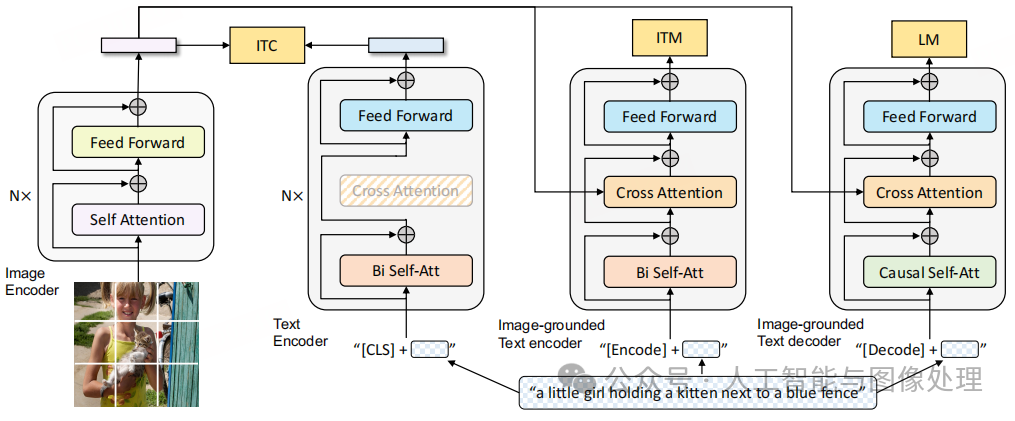
图2:BLIP的预训练模型架构和目标(相同的参数具有相同的颜色)。我们建议多模式混合
编码器-解码器是一种统一的视觉语言模型,可以在三种功能之一中运行:(1)单峰编码器使用图像-文本对比(ITC)损失进行训练,以对齐视觉和语言表示。(2)图像接地文本编码器使用用于模拟视觉语言交互的额外交叉注意力层,并使用图像文本匹配(ITM)损失进行训练以区分在正图像和负图像文本对之间。(3)图像接地文本解码器用并且与编码器共享相同的交叉注意层和前馈网络。解码器经过训练使用语言建模(LM)损失来生成给定图像的字幕。
3. 方法
我们提出了 BLIP,一个从嘈杂的图像 - 文本对中学习的统一视觉语言预训练(VLP)框架。本节首先介绍我们新的模型架构 MED 及其预训练目标,然后阐述用于数据集自举的 CapFilt 方法。
3.1. 模型架构
我们采用视觉 Transformer作为图像编码器,该编码器将输入图像划分为多个图块,并将它们编码为嵌入序列,同时使用额外的 [CLS] 标记来表示全局图像特征。与使用预训练目标检测器进行视觉特征提取的方法相比,使用 ViT 更具计算效率,并且已被最新的方法所采用。
为了预训练一个同时具备理解和生成能力的统一模型,我们提出了编码器 - 解码器多模态混合(MED)模型,这是一种多任务模型,可在以下三种功能之一中运行:
-
1)单模态编码器,用于分别编码图像和文本。文本编码器与 BERT相同,在文本输入的开头附加 [CLS] 标记以总结句子。
-
2)以图像为基础的文本编码器,通过在文本编码器的每个Transformer 块的自注意力(SA)层和前馈网络(FFN)之间插入一个额外的交叉注意力(CA)层来注入视觉信息。将特定任务的 [Encode] 标记附加到文本上,[Encode] 的输出嵌入用作图像 - 文本对的多模态表示。
-
3)以图像为基础的文本解码器,将以图像为基础的文本编码器中的双向自注意力层替换为因果自注意力层。使用 [Decode] 标记表示序列的开始,使用序列结束标记表示序列的结束。
3.2. 预训练目标
我们在预训练期间联合优化三个目标,其中两个是基于理解的目标,一个是基于生成的目标。每个图像 - 文本对仅需对计算量较大的视觉 Transformer 进行一次前向传播,并对文本 Transformer 进行三次前向传播,通过激活不同的功能来计算如下所述的三种损失。
图像 - 文本对比损失(ITC)激活单模态编码器。其目的是通过促使正样本图像 - 文本对在特征空间中的表示相似,而负样本对的表示不同,来对齐视觉 Transformer 和文本 Transformer 的特征空间。已有研究表明,该目标对于改善视觉和语言理解非常有效。我们采用 Li 等人的 ITC 损失,其中引入动量编码器来生成特征,并从动量编码器创建软标签作为训练目标,以考虑负样本对中可能存在的正样本。
图像 - 文本匹配损失(ITM)激活以图像为基础的文本编码器。其目的是学习能够捕捉视觉和语言之间细粒度对齐的图像 - 文本多模态表示。ITM 是一项二分类任务,模型使用 ITM 头部(线性层)根据图像 - 文本对的多模态特征,预测其是正样本(匹配)还是负样本(不匹配)。为了找到更多信息丰富的负样本,我们采用 Li 等人的硬负样本挖掘策略,即批次中对比相似度较高的负样本对更有可能被选来计算损失。
语言建模损失(LM)激活以图像为基础的文本解码器,其目的是在给定图像的情况下生成文本描述。它优化交叉熵损失,训练模型以自回归方式最大化文本的似然性。计算损失时,我们应用 0.1 的标签平滑。与视觉语言预训练中广泛使用的掩码语言模型(MLM)损失相比,LM 使模型具备将视觉信息转换为连贯字幕的泛化能力。
为了在利用多任务学习的同时进行高效的预训练,文本编码器和解码器除了自注意力层外共享所有参数。这是因为编码和解码任务的差异主要体现在自注意力层。具体而言,编码器采用双向自注意力来构建当前输入标记的表示,而解码器采用因果自注意力来预测下一个标记。另一方面,嵌入层、交叉注意力层和前馈网络在编码和解码任务中的功能相似,因此共享这些层可以提高训练效率,同时受益于多任务学习。
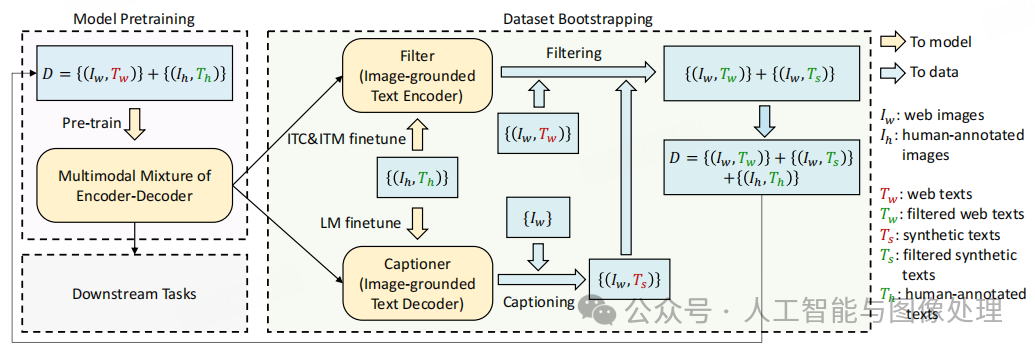
图3. BLIP的学习框架。我们引入了一个字幕器来为网络图像生成字幕,以及一个过滤器来删除噪声图像文本对。字幕器和过滤器从相同的预训练模型初始化,并在小规模上单独微调人类注释数据集。引导数据集用于预训练新模型。
3.3. CapFilt
由于注释成本过高,高质量的人工注释图像文本对 {(I_h, T_h)} 数量有限(例如 COCO)。最近的工作利用了从网络自动收集的大量图像和替代文本对 {(I_w, T_w)}。然而,这些替代文本通常不能准确描述图像的视觉内容,使其成为次优的视觉语言对齐学习信号。
我们提出了字幕生成与过滤(CapFilt),这是一种提高文本语料库质量的新方法。图 3 展示了 CapFilt 的示意图。它引入了两个模块:一个用于根据网络图像生成字幕的字幕生成器(captioner),以及一个用于去除嘈杂图像文本对的过滤器(filter)。字幕生成器和过滤器均从相同的预训练 MED 模型初始化,并在 COCO 数据集上单独进行微调。微调过程是轻量级的。。
具体来说,字幕生成器是一个以图像为基础的文本解码器。它通过 LM 目标进行微调,以根据图像解码文本。给定网络图像(I_{w}),字幕生成器为每个图像生成一个合成字幕(T_{s})。过滤器是一个以图像为基础的文本编码器。它通过 ITC 和 ITM 目标进行微调,以学习文本是否与图像匹配。过滤器会从原始网络文本(T_{w}) 和合成文本(T_{s}) 中去除嘈杂文本,如果 ITM 头部预测某文本与图像不匹配,则该文本会被视为嘈杂文本。最后,我们将过滤后的图像文本对与人工注释的对合并,形成一个新的数据集,用于预训练新模型。
4.实验与讨论
在本节中,我们首先介绍预培训的细节。然后我们对我们的方法进行了详细的实验分析。
4.1. 预训练细节
我们的模型采用 PyTorch实现,并在两个 16-GPU 节点上进行预训练。图像 Transformer 由在 ImageNet 上预训练的 ViT 初始化,文本 Transformer 则由 BERT 基础模型初始化。
我们探究了两种 ViT 变体:ViT-B/16 和 ViT-L/16。除非另有说明,本文中所有标注为 “BLIP” 的结果均使用 ViT-B。我们使用 2880(ViT-B)/2400(ViT-L)的批量大小对模型进行 20 个轮次的预训练。优化器采用 AdamW,权重衰减设为 0.05。学习率先热身至 3e-4(ViT-B)/2e-4(ViT-L),然后以 0.85 的比率线性衰减。
预训练时,我们对图像进行分辨率为 224×224 的随机裁剪,微调时将图像分辨率提升至 384×384。我们使用与 Li 等人相同的预训练数据集,该数据集总计包含 1400 万张图像,包括两个人工标注数据集(COCO 和视觉基因组,以及三个网络数据集(Conceptual Captions、Conceptual 12M、SBU captions)。我们还对一个额外的网络数据集 LAION进行了实验,该数据集包含 1.15 亿张图像,且文本噪声更多。
4.2. CapFilt 的效果
在表 1 中,我们对比了在不同数据集上预训练的模型,以验证 CapFilt 在下游任务(包括经过微调(FT)和零样本(ZS)设置的图像 - 文本检索和图像字幕任务)中的有效性。
当仅对包含 1400 万张图像的数据集应用字幕生成器(Captioner)或过滤器(Filter)时,可观察到性能提升;而当两者结合使用时,其效果相互补充,与使用原始嘈杂的网页文本相比,性能实现了显著提升2。
CapFilt 可通过更大的数据集和更大的视觉主干网络进一步提升性能,这验证了其在数据规模和模型规模上的可扩展性。此外,通过将大型字幕生成器和过滤器与 ViT-L 结合使用,基础模型的性能也能得到改善。
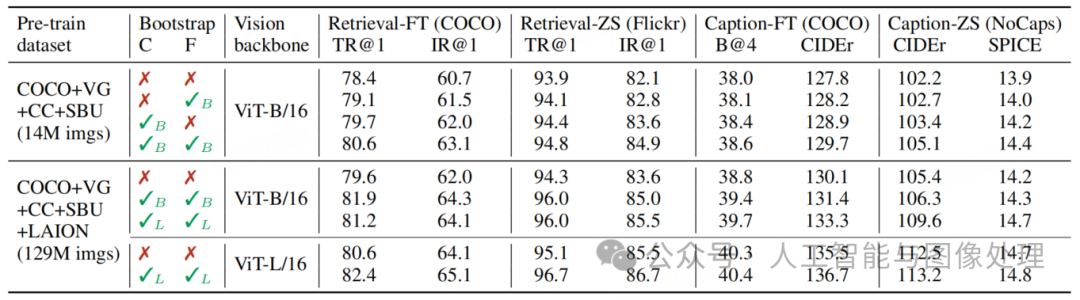
表1. 评估字幕器(C)和过滤器(F)对数据集引导的效果。下游任务包括图像文本检索
以及具有微调(FT)和零样本(ZS)设置的图像字幕。TR/IR@1: recall@1用于文本检索/图像检索。 ✓B/L:字幕或滤镜使用ViT-B/ViT-L作为视觉骨干。
在图4中,我们显示了一些示例标题及其相应的图像,定性地证明了字幕生成新文本描述的效果,以及从原始字幕中删除嘈杂字幕的过滤器网络文本和合成文本。

图4. 网络文本Tw和合成文本Ts的示例。绿色文本被过滤器接受,而红色文本被拒绝。
4.3. 合成字幕的多样性至关重要
在CapFilt中,我们采用核采样(nucleus sampling)来生成合成字幕。核采样是一种随机解码方法,其中每个token从累积概率质量超过阈值p(本实验中p=0.9)的token集合中采样。在表2中,我们将其与波束搜索(beam search)进行了对比,后者是一种确定性解码方法,旨在生成概率最高的字幕。尽管核采样生成的字幕从过滤器的噪声率来看更为嘈杂,但其性能明显更优。我们推测原因在于核采样能够生成更多样化且更具新颖性的字幕,其中包含模型可受益的更多新信息。另一方面,波束搜索倾向于生成数据集中常见的保守字幕,因此提供的额外知识较少。

4.4. 参数共享与解耦
在预训练过程中,文本编码器和解码器除自注意力层外共享所有参数。在表3中,我们评估了使用不同参数共享策略预训练的模型,这些模型在包含网页文本的1400万张图像上进行预训练。结果表明,除自注意力层外共享所有层的策略与不共享参数相比,性能更优,同时还能减小模型规模,提升训练效率。如果共享自注意力层,模型性能会因编码任务与解码任务的冲突而下降。
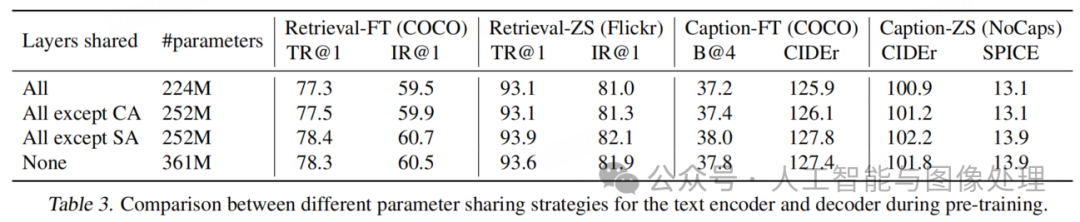
在CapFilt过程中,字幕生成器和过滤器在COCO上分别进行端到端微调。在表4中,我们研究了字幕生成器和过滤器是否按预训练时的相同方式共享参数的影响。下游任务的性能下降,我们主要归因于确认偏差。由于参数共享,字幕生成器产生的嘈杂字幕更难被过滤器移除,如噪声率所示(8%对比25%)。

5. 与最新技术的比较
在本节中,我们将BLIP与现有的VLP方法进行比较关于广泛的视觉语言下游任务2接下来,我们简要介绍每个任务和微调策略。
5.1. 图像 - 文本检索
我们在 COCO 和 Flickr30K数据集上评估了 BLIP 在图像到文本检索(TR)和文本到图像检索(IR)任务上的表现。我们使用 ITC 和 ITM 损失对预训练模型进行微调。为了提高推理速度,我们遵循 Li 等人的方法,首先基于图像 - 文本特征相似度选择 k 个候选,然后根据候选对的 ITM 分数对其重新排序。对于 COCO,我们设置 k=256;对于 Flickr30K,设置 k=128。
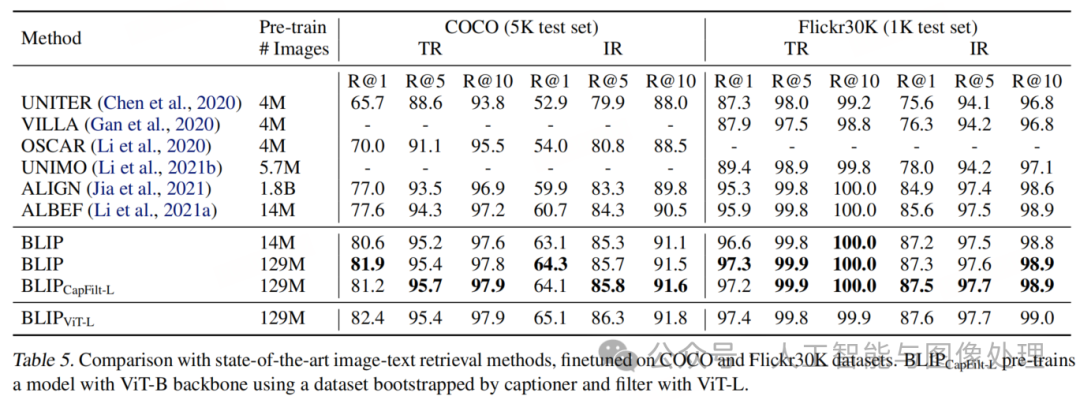
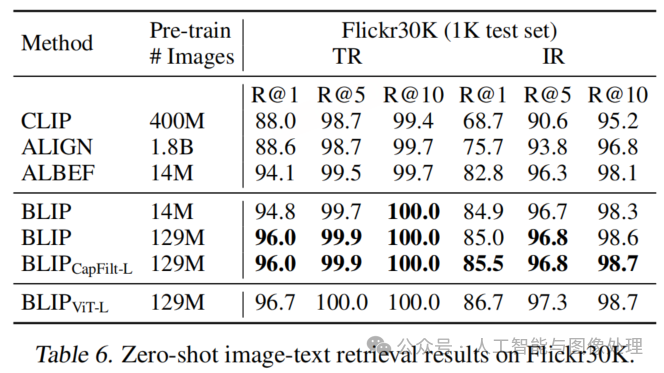
如表 5 所示,与现有方法相比,BLIP 实现了显著的性能提升。使用相同的 1400 万张预训练图像,BLIP 在 COCO 上的平均召回率 @1 比之前的最佳模型 ALBEF 高出 2.7%。我们还通过将在 COCO 上微调的模型直接迁移到 Flickr30K,进行了零样本检索实验。表 6 的结果显示,BLIP 在零样本设置下也大幅优于现有方法。
5.2. 图像字幕生成
我们针对两个数据集进行图像字幕生成任务:NoCaps 和 COCO,两者均使用在 COCO 上通过 LM 损失微调的模型进行评估。与 Wang 等人类似,我们在每条字幕开头添加提示词 “a picture of”,这一操作可带来轻微的效果提升。如表 7 所示,使用 1400 万张预训练图像的 BLIP,显著优于使用相近规模预训练数据的方法。配备 1.29 亿张图像的 BLIP,其性能可与使用 2 亿张图像的 LEMON 相媲美。值得注意的是,LEMON 需要计算密集的预训练目标检测器,且输入图像分辨率更高(800×1333),这导致其推理速度明显慢于无检测器的 BLIP—— 后者使用更低分辨率(384×384)的输入图像。
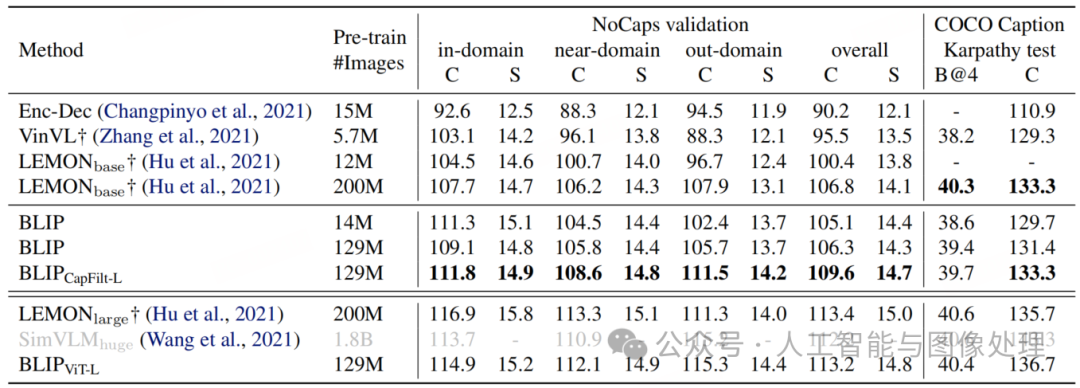
表7. 与NoCaps和COCO Caption上最先进的图像字幕方法进行比较。所有方法都优化了微调过程中的交叉熵损失。C:CIDEr,S:SPICE,B@4:BLEU@4.BLIPCapFilt-L在字幕器引导的数据集上进行预训练使用ViT-L进行滤波。VinVL†和LEMON \8224》需要一个在250万张带有人类注释边界的图像上预先训练过的物体检测器框和高分辨率(800×1333)输入图像。SimVLMmegal使用比ViT-L多13倍的训练数据和更大的视觉骨干。
5.3. 视觉问答(VQA)
VQA要求模型在给定图像和问题的情况下预测答案。我们并未将 VQA 构建为多答案分类任务,而是遵循 Li 等人(2021a)的做法,将其视为答案生成任务,从而支持开放式 VQA。如图 5(a)所示,在微调过程中,我们对预训练模型进行了重构:首先将图像 - 问题对编码为多模态嵌入,然后输入到答案解码器。VQA 模型通过 LM 损失进行微调,以真实答案作为目标。
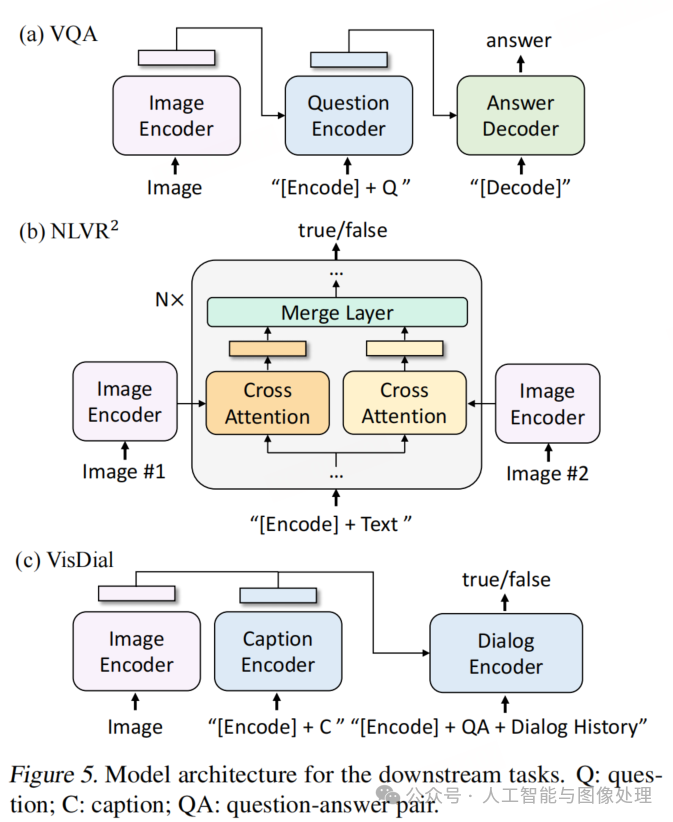
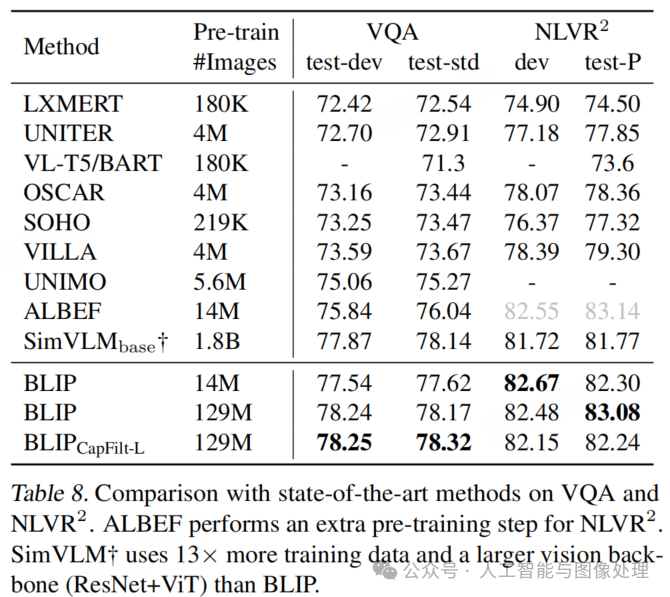
表 8 展示了实验结果。使用 1400 万张图像时,BLIP 在测试集上的表现比 ALBEF 高出 1.64%。使用 1.29 亿张图像时,BLIP 的性能优于 SimVLM—— 后者使用的预训练数据量是 BLIP 的 13 倍,并且采用了更大的视觉主干网络(额外包含卷积阶段)。
5.4. 自然语言视觉推理(NLVR²)
NLVR²要求模型预测一个句子是否描述了一对图像。为了支持对两幅图像的推理,我们对预训练模型进行了简单修改,与之前的方法相比,该架构计算效率更高。如图 5(b)所示,对于以图像为基础的文本编码器中的每个 Transformer 块,存在两个交叉注意力(CA)层来处理两个输入图像,其输出被合并后馈送到前馈网络(FFN)。这两个 CA 层由相同的预训练权重初始化。在编码器的前 6 层中,合并层执行简单的平均池化;在第 6-12 层中,合并层先进行拼接,然后通过线性投影。对 [Encode] 标记的输出嵌入应用 MLP 分类器。如表 8 所示,BLIP 优于所有现有方法,除了 ALBEF—— 后者额外进行了定制化预训练。有趣的是,NLVR² 的性能并未从额外的网页图像中显著受益,这可能是由于网页数据与下游数据之间存在领域差异。
5.5. 视觉对话(VisDial)
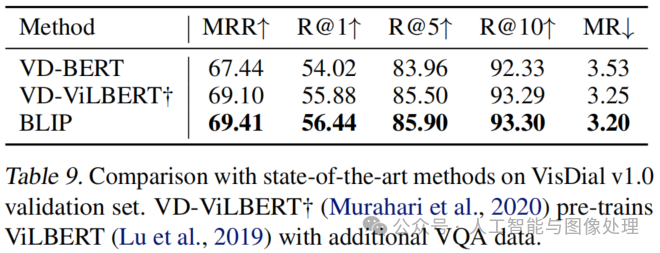
VisDial在自然对话场景中扩展了 VQA 任务,要求模型不仅基于图像 - 问题对,还需考虑对话历史和图像字幕来预测答案。我们遵循判别式设置,即模型对答案候选池进行排序。如图 5(c)所示,我们将图像和字幕的嵌入进行拼接,并通过交叉注意力将其传入对话编码器。对话编码器通过 ITM 损失进行训练,以在给定整个对话历史和图像 - 字幕嵌入的情况下,判别答案对问题是否为真。如表 9 所示,我们的方法在 VisDial v1.0 验证集上取得了最先进的性能。
5.6 视频 - 语言任务的零样本迁移
我们的图像 - 语言模型对视频 - 语言任务具有强大的泛化能力。在表 10 和表 11 中,我们对文本到视频检索和视频问答任务进行了零样本迁移,直接评估了在 COCO 检索和 VQA 任务上训练的模型。为了处理视频输入,我们从每个视频中均匀采样 n 帧(检索任务中 n=8,问答任务中 n=16),并将帧特征连接成一个序列。需要注意的是,这种简单的方法忽略了所有时间信息。
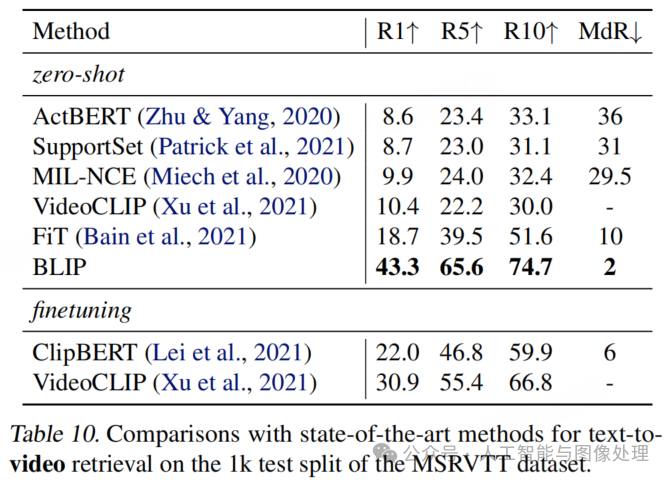
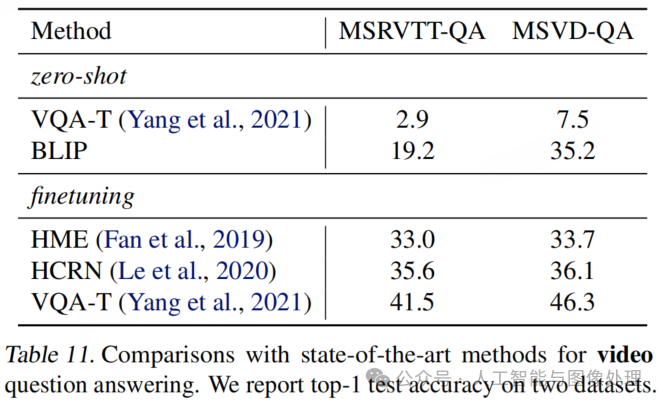
尽管存在领域差异且缺乏时间建模,我们的模型在这两个视频 - 语言任务上都取得了最先进的性能。对于文本到视频检索任务,零样本 BLIP 模型甚至比在目标视频数据集上微调的模型在召回率 @1 上高出 12.4%。如果使用 BLIP 模型初始化一个具有时间建模能力的视频 - 语言模型(例如,用 TimeSformer替换我们的 ViT)并在视频数据上进行微调,还可以进一步提高性能。
6. 额外消融实验
在本节中,我们针对 CapFilt 进行了额外的消融实验。
6.1 CapFilt 的改进并非源于更长的训练时间
由于引导数据集包含的文本量多于原始数据集,使用引导数据集进行相同轮次的训练会花费更长时间。为验证 CapFilt 的有效性并非源于更长的训练时间,我们对原始数据集中的网络文本进行复制,使其每轮训练的样本量与引导数据集相同。如表 12 所示,使用含噪声的网络文本进行更长时间的训练并未提升性能。

6.2 应在引导数据集上训练新模型
引导数据集用于预训练新模型。我们探究了使用引导数据集在先前预训练模型上继续训练的效果。表 13 显示,继续训练的增益低于使用引导数据集训练新模型。这一发现与知识蒸馏的常见实践一致,即学生模型不能从教师模型初始化。

7. 结论
我们提出了BLIP,这是一种新的视觉-语言预训练(VLP)框架,在广泛的下游视觉-语言任务上具有最先进的性能,包括基于理解和基于生成的任务。BLIP使用从大规模噪声图像-文本对中引导构建的数据集,通过注入多样化的合成字幕并去除噪声字幕,对编码器-解码器混合多模态模型进行预训练。我们发布了引导构建的数据集,以促进未来的视觉-语言研究。
有几个可能进一步提升BLIP性能的潜在方向:
(1)多轮数据集引导构建;
(2)为每张图像生成多个合成字幕,以进一步扩大预训练语料库;
(3)通过训练多个不同的字幕生成器和过滤器,并在CapFilt中结合它们的优势来实现模型集成。
我们希望本文能激励未来的研究工作,聚焦于在模型和数据两方面进行改进——这是视觉-语言研究的核心基础。
三,相关地址:
论文地址:https://arxiv.org/abs/2201.12086
代码地址:https://github.com/salesforce/BLIP


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 16
16 0
0- 0



 已为社区贡献32条内容
已为社区贡献32条内容

所有评论(0)