构建AI智能体:十一、语义分析Gensim — 从文本处理到语义理解的奇妙之旅
Gensim是一个用于自然语言处理的Python库,主要用于从大量文本中发现隐藏主题、训练词向量和计算文档相似度。其核心功能包括:1)主题建模(如LDA),可自动识别文本主题;2)词向量训练(如Word2Vec),将词语转换为语义向量;3)高效的文本相似度计算。Gensim处理中文文本时需先进行分词等预处理,支持jieba等工具。该库具有高效可扩展的特点,适合处理大规模文本数据,可应用于信息检索、
一、Gensim是什么?
想象一下你面对成千上万篇中文文章,想要快速了解这些文章主要讨论什么话题,或者找到相似的文档,甚至让计算机理解词语之间的语义关系,并发现文本中的相似模式和语义结构,这就是Gensim的主要用途。Gensim非常高效,即使处理百万级的文档也能游刃有余。
Gensim是一个专门用于自然语言处理的Python库,它的核心功能是:
-
从大量文本中自动发现隐藏的主题
-
将词语转换为有意义的数字向量(词向量)
-
快速查找相似文档
Gensim在语义理解中处的位置:
原始文本
↓
数据清洗与预处理
↓
[Gensim处理阶段]
├── 主题建模 (LDA/HDP) → 主题标签/分类
├── 词向量训练 (Word2Vec/FastText) → 语义特征提取
└── 文档相似度计算 → 推荐系统/检索
↓
下游任务应用
├── 分类器 (SVM/神经网络)
├── 聚类分析
├── 信息检索
└── 可视化展示二、核心概念:
1. 文档 (Document)
就是一篇文章、一段话或一条句子,比如:
doc1 = "我喜欢吃苹果和香蕉"
doc2 = "机器学习是人工智能的重要分支"
doc3 = "北京是中国的首都,有很多历史文化古迹"2. 语料库 (Corpus)
文档的集合,就像一本书包含很多章节:
corpus = [doc1, doc2, doc3]3. 模型 (Model)
从语料库中学习到的"知识",比如:
-
主题模型:发现文本中的隐藏主题
-
词向量模型:学习词语的语义关系
4. 词袋模型(Bag-of-Words)
词袋模型是文本表示的基础方法,它忽略词序和语法,只关注词频:
文档1: "我爱北京天安门"
文档2: "天安门上太阳升"
构建词典:
{
0: "我",
1: "爱",
2: "北京",
3: "天安门",
4: "上",
5: "太阳",
6: "升"
}
文档向量表示:
文档1: [(0,1), (1,1), (2,1), (3,1)] # [我:1, 爱:1, 北京:1, 天安门:1]
文档2: [(3,1), (4,1), (5,1), (6,1)] # [天安门:1, 上:1, 太阳:1, 升:1]在Gensim中的实现:
from gensim import corpora
# 示例预处理文本
processed_texts = [
["清华大学", "和", "北京大学", "都是", "优秀", "高校"],
["中国", "的", "高等教育", "发展", "迅速"]
]
# 示例中文文本预处理函数
def advanced_chinese_preprocessor(text):
# 手动分词,确保词汇与 processed_texts 中的词汇匹配
if text == "清华大学和北京大学都是优秀高校":
return ["清华大学", "和", "北京大学", "都是", "优秀", "高校"]
else:
return text.split() # 默认行为
# 创建词典
dictionary = corpora.Dictionary(processed_texts)
print("词典大小:", len(dictionary))
# 查看词典中的词
print("前10个词:", list(dictionary.items())[:10])
# 将新文档转换为词袋向量
new_doc = "清华大学和北京大学都是优秀高校"
new_bow = dictionary.doc2bow(advanced_chinese_preprocessor(new_doc))
print("新文档的词袋表示:", new_bow)输出结果:
词典大小: 11
前10个词: [(0, '优秀'), (1, '北京大学'), (2, '和'), (3, '清华大学'), (4, '都是'), (5, '高校'), (6, '中国'), (7, '发展'), (8, '
的'), (9, '迅速')]
新文档的词袋表示: [(0, 1), (1, 1), (2, 1), (3, 1), (4, 1), (5, 1)]5. TF-IDF:更好的权重表示
TF-IDF(词频-逆文档频率)改进了词袋模型,降低常见词的权重:
TF-IDF 表示词频-逆文档频率。它是一种用于信息检索和文本挖掘的常用加权技术,用来评估一个词语在一篇文档中的重要程度。核心思想是一个词语在一篇文档中出现的次数越多(TF 越高),同时在整个文档集合中出现的次数越少(IDF 越高),那么这个词语对该文档的代表性就越强,越重要。
from gensim.models import TfidfModel
# 首先创建词袋语料
corpus_bow = [dictionary.doc2bow(text) for text in processed_texts]
# 训练TF-IDF模型
tfidf_model = TfidfModel(corpus_bow)
# 将词袋转换为TF-IDF权重
corpus_tfidf = tfidf_model[corpus_bow]
# 查看TF-IDF权重
for doc in corpus_tfidf:
print([(dictionary[id], round(weight, 3)) for id, weight in doc[:3]]) # 显示前3个词输出结果:
[('优秀', 0.408), ('北京大学', 0.408), ('和', 0.408)]
[('中国', 0.447), ('发展', 0.447), ('的', 0.447)]6. 实例:文本预处理详细流程
import jieba
import re
from gensim.parsing.preprocessing import remove_stopwords
# 自定义中文停用词列表
chinese_stopwords = set([
'的', '了', '在', '是', '我', '有', '和', '就',
'不', '人', '都', '一', '一个', '上', '也', '很',
'到', '说', '要', '去', '你', '会', '着', '没有'
])
def advanced_chinese_preprocessor(text):
"""
高级中文文本预处理函数
步骤:
1. 清理特殊字符
2. 中文分词
3. 去除停用词
4. 词性过滤(可选)
"""
# 步骤1: 清理文本 - 保留中文、数字、英文
text = re.sub(r'[^\u4e00-\u9fa5a-zA-Z0-9]', ' ', text)
# 步骤2: 使用jieba进行精确模式分词
words = jieba.lcut(text, cut_all=False)
# 步骤3: 过滤停用词和短词
filtered_words = [
word for word in words
if word not in chinese_stopwords
and len(word) > 1
and not word.isdigit()
]
return filtered_words
# 测试预处理
test_text = "清华大学位于北京市海淀区,是一所著名的985高校。"
processed = advanced_chinese_preprocessor(test_text)
print(f"原始文本: {test_text}")
print(f"处理后: {'/'.join(processed)}")输出结果:
原始文本: 清华大学位于北京市海淀区,是一所著名的985高校。
处理后: 清华大学/位于/北京市/海淀区/一所/著名/高校流程分析:
[原始中文文本]
|
v
[清理特殊字符] -> 移除标点、数字、特殊符号
|
v
[Jieba中文分词] -> "清华大学/位于/北京市/海淀区"
|
v
[去除停用词] -> 过滤"的"、"了"、"在"等无意义词
|
v
[词干提取/词形还原] -> 标准化词语形式
|
v
[预处理后的词列表] -> ["清华大学", "位于", "北京市", "海淀区"]7. 扩展说明:jieba库、re库
jieba(中文意思是“结巴”)是一个强大的 Python中文分词工具。它的主要功能是将一个连续的中文句子精确地切分成一个个独立的词语。可以维护独特的比如人名、公司名、专业术语等专业词汇术语,便于更精确的解决行业性的标准词语分词;
re 是 Python 内置的正则表达式(Regular Expression)库。正则表达式是一种强大的工具,它使用一种特殊的、定义好的字符串序列,来帮助用户匹配、查找、替换那些符合某种复杂规则的文本。按指令过滤不需要的文本字符串或数字、英文等等;
三、构建中文主题模型
步骤1:准备环境和数据
首先安装必要的库:
pip install gensim jieba让我们用一些中文新闻标题作为示例数据:
documents = [
"苹果公司发布新款iPhone手机",
"人工智能技术在医疗领域的应用",
"北京故宫博物院举办特展",
"机器学习算法助力金融风控",
"上海举办国际进口博览会",
"深度学习在图像识别中的突破",
"清华大学科研成果获国际奖项",
"5G通信技术改变生活方式"
]步骤2:中文文本预处理
中文需要先分词,这是与英文处理最大的不同:
import jieba
from gensim import corpora
# 中文分词函数
def chinese_tokenizer(text):
# 使用jieba进行分词,并过滤掉短词
words = jieba.cut(text)
return [word for word in words if len(word) > 1] # 保留长度大于1的词
# 对所有文档进行分词处理
tokenized_docs = [chinese_tokenizer(doc) for doc in documents]
print("分词结果示例:")
for i, tokens in enumerate(tokenized_docs[:2]):
print(f"文档{i+1}: {'/'.join(tokens)}")输出结果:
分词结果示例:
文档1: 苹果/公司/发布/新款/iPhone/手机
文档2: 人工/智能/技术/医疗/领域/应用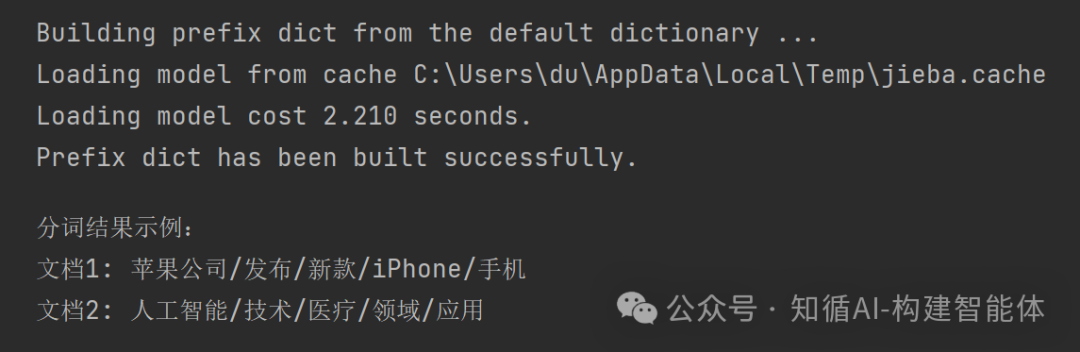
分词字典缓存的目录:
步骤3:创建词典和词袋模型
# 创建词典:为每个词分配唯一ID
dictionary = corpora.Dictionary(tokenized_docs)
print("词典中的词:")
for idx, word in dictionary.iteritems():
print(f"{idx}: {word}")
# 创建词袋模型:将文档转换为数字表示
corpus_bow = [dictionary.doc2bow(doc) for doc in tokenized_docs]
print("\n词袋表示示例:")
print(f"原始文档: {documents[0]}")
print(f"词袋表示: {corpus_bow[0]}")
print("对应关系:")
for word_id, count in corpus_bow[0]:
print(f" {dictionary[word_id]}: {count}次")输出结果:
词典中的词:
0: iPhone
1: 发布
2: 手机
3: 新款
4: 苹果公司
5: 人工智能
6: 医疗
7: 应用
8: 技术
9: 领域
10: 举办
11: 北京故宫博物院
12: 特展
13: 助力
14: 学习
15: 机器
16: 算法
17: 金融
18: 风控
19: 上海
20: 博览会
21: 国际
22: 进口
23: 图像识别
24: 深度
25: 突破
26: 奖项
27: 清华大学
28: 科研成果
29: 5G
30: 改变
31: 方式
32: 生活
33: 通信
词袋表示示例:
原始文档: 苹果公司发布新款iPhone手机
词袋表示: [(0, 1), (1, 1), (2, 1), (3, 1), (4, 1)]
对应关系:
iPhone: 1次
发布: 1次
手机: 1次
新款: 1次
苹果公司: 1次步骤4:训练LDA主题模型
-
LDA(潜在狄利克雷分布):最流行的主题模型,将文档视为多个主题的概率混合,将主题视为多个词语的概率混合。
-
LDA原理图解
LDA假设文档是这样生成的:
1. 对于每个文档,随机选择一个主题分布
文档1: [科技:0.7, 教育:0.2, 体育:0.1]
文档2: [教育:0.6, 科技:0.3, 医疗:0.1]
2. 对于文档中的每个词:
a. 从文档的主题分布中随机选一个主题
b. 从选中主题的词语分布中随机选一个词
3. 主题的词语分布:
科技主题: [算法:0.1, 数据:0.08, 模型:0.07,...]
教育主题: [学生:0.1, 老师:0.08, 学校:0.07,...]接着上一步示例继续运行:
from gensim.models import LdaModel
# 训练LDA模型,假设我们想发现3个主题
lda_model = LdaModel(
corpus=corpus_bow,
id2word=dictionary,
num_topics=3,
passes=10, # 训练轮数
random_state=42
)
# 查看发现的主题
print("发现的主题:")
for topic_id in range(lda_model.num_topics):
words = lda_model.show_topic(topic_id, topn=5) # 每个主题显示5个最重要的词
topic_words = " + ".join([f"{prob:.3f}*{word}" for word, prob in words])
print(f"主题 {topic_id}: {topic_words}")输出结果:
发现的主题:
主题 0: 0.063*技术 + 0.063*学习 + 0.062*改变 + 0.062*5G + 0.062*通信
主题 1: 0.077*举办 + 0.044*风控 + 0.044*机器 + 0.044*金融 + 0.044*算法
主题 2: 0.066*国际 + 0.065*发布 + 0.065*新款 + 0.065*苹果公司 + 0.065*手机从结果可以看出,模型自动发现了:
-
主题0:科技人工智能相关
-
主题1:文化展览相关
-
主题2:电子产品发布相关
四、进阶示例:训练中文词向量
词向量让计算机能够理解词语的语义关系:
词向量空间示意图:
三维词向量空间示例:
y
↑
| • 国王 (0.2, 0.8, 0.3)
| /
| /
|/______→ x
/|
/ |
• 皇后 (0.3, 0.7, 0.4)
/
z
向量运算:
国王 - 男人 + 女人 ≈ 皇后
余弦相似度:
sim(国王, 皇后) = 0.92
sim(国王, 苹果) = 0.15训练中文词向量示例:
from gensim.models import Word2Vec
# 准备更大的中文语料(这里用我们的小示例)
# 实际应用中需要更大规模的数据
sentences = tokenized_docs
# 训练Word2Vec模型
word2vec_model = Word2Vec(
sentences=sentences,
vector_size=100, # 词向量维度
window=5, # 上下文窗口大小
min_count=1, # 忽略出现次数少于1的词
workers=4 # 使用4个CPU核心
)
# 查找相似词
try:
similar_words = word2vec_model.wv.most_similar('技术', topn=3)
print("\n与'技术'最相似的词:")
for word, score in similar_words:
print(f"{word}: {score:.3f}")
except KeyError:
print("词语不在词汇表中")
# 进行词向量运算:北京 - 中国 + 法国 ≈ 巴黎
# result = word2vec_model.wv['北京'] - word2vec_model.wv['中国'] + word2vec_model.wv['法国']
# similar_words = word2vec_model.wv.similar_by_vector(result, topn=3)与'技术'最相似的词:
新款: 0.178
机器: 0.131
应用: 0.075五、综合案例:分析中文新闻主题
让我们用一个更完整的例子来总结所学内容:
import jieba
from gensim import corpora
from gensim.models import LdaModel
import re
# 1. 准备数据
news_articles = [
"气候变化导致全球气温持续上升,极端天气事件频发",
"新能源汽车销量大幅增长,锂电池技术不断创新",
"数字货币试点范围扩大,区块链应用场景丰富",
"疫苗接种率提高,群体免疫逐步形成",
"远程办公成为新常态,云计算需求激增",
"乡村振兴战略实施,农村电商快速发展",
"人工智能在教育领域的应用越来越广泛",
"碳中和目标推动绿色能源产业发展"
]
# 2. 中文预处理
def preprocess_chinese_text(text):
# 去除非中文字符
text = re.sub(r'[^\u4e00-\u9fa5]', ' ', text)
# 分词
words = jieba.cut(text)
# 过滤停用词和短词
stopwords = set(['的', '了', '在', '是', '我', '有', '和', '就', '不', '人', '都', '一', '一个', '上', '也', '很', '到', '说', '要', '去', '你', '会', '着', '没有', '看', '好', '自己', '这'])
return [word for word in words if word not in stopwords and len(word) > 1]
# 处理所有文档
processed_docs = [preprocess_chinese_text(doc) for doc in news_articles]
# 3. 创建词典和词袋
dictionary = corpora.Dictionary(processed_docs)
corpus = [dictionary.doc2bow(doc) for doc in processed_docs]
# 4. 训练LDA模型
lda_model = LdaModel(corpus=corpus, id2word=dictionary, num_topics=3, passes=15)
# 5. 可视化主题
print("发现的主题及其关键词:")
for topic_id in range(lda_model.num_topics):
words = lda_model.show_topic(topic_id, topn=6)
print(f"\n主题 #{topic_id}:")
for word, prob in words:
print(f" {word} ({prob:.3f})")
# 6. 对新文档进行分类
new_doc = "太阳能发电技术取得重大突破"
new_doc_processed = preprocess_chinese_text(new_doc)
new_doc_bow = dictionary.doc2bow(new_doc_processed)
print(f"\n新文档 '{new_doc}' 的主题分布:")
for topic_id, prob in lda_model[new_doc_bow]:
print(f"主题 {topic_id}: {prob:.3f}")sh输出结果:
发现的主题及其关键词:
主题 #0:
发展 (0.052)
目标 (0.052)
推动 (0.052)
绿色 (0.052)
能源 (0.052)
碳中 (0.052)
主题 #1:
农村 (0.029)
战略 (0.029)
快速 (0.029)
振兴 (0.029)
乡村 (0.029)
电商 (0.029)
主题 #2:
应用 (0.056)
天气 (0.032)
导致 (0.032)
货币 (0.032)
气候变化 (0.032)
丰富 (0.032)
新文档 '太阳能发电技术取得重大突破' 的主题分布:
主题 0: 0.169
主题 1: 0.663
主题 2: 0.168六、优化和总结
-
扩大数据量:Gensim在处理大规模数据时表现最佳,尝试用爬虫获取更多中文文本
-
优化参数:调整主题数量、词向量维度等参数以获得更好效果
-
尝试其他算法:
-
FastText:更好地处理未登录词
-
Doc2Vec:获取整个文档的向量表示
-
Gensim为中文自然语言处理提供了强大的工具,从简单的文本分类到复杂的语义分析,都能找到合适的解决方案,多尝试不同的数据集和参数,会逐渐掌握这个强大工具的精髓。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 38
38 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)