GraphRAG+Ollama本地化部署全流程指南
本文介绍了GraphRAG与Ollama结合的本地化AI解决方案,适用于企业级知识管理。GraphRAG通过知识图谱增强检索能力,Ollama实现本地模型部署,显著降低云端API成本并确保数据安全。文章详细讲解了从环境准备、模型部署到索引构建和查询优化的全流程,包括硬件配置、软件依赖、模型推荐及参数调优,并提供了企业知识库构建的成功案例。该方案在响应速度、准确率和成本控制方面均优于传统RAG,特别
一、开篇:为什么选择GraphRAG+Ollama?
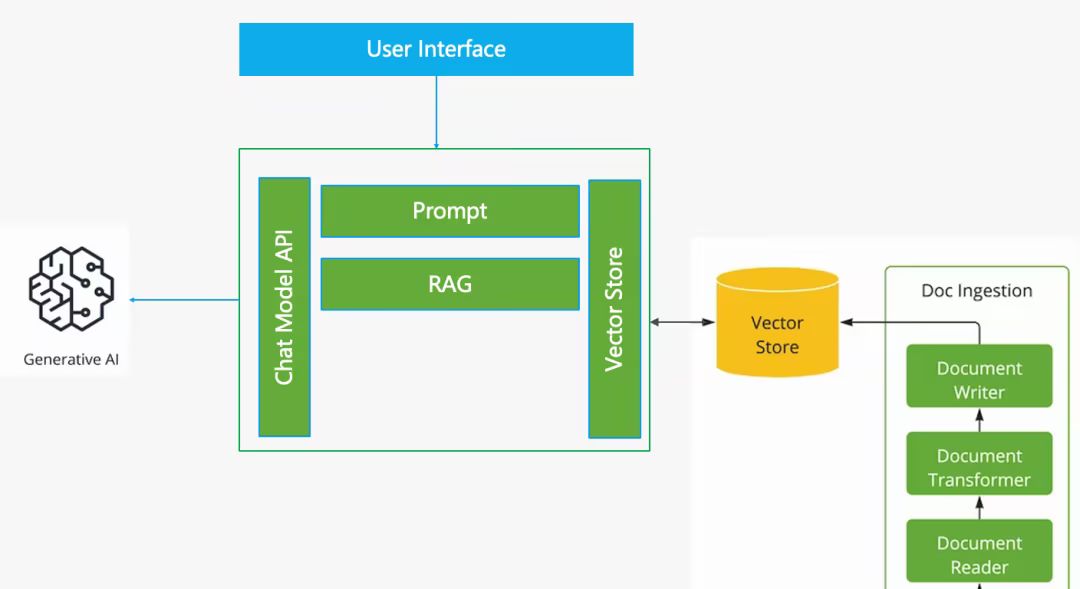
在人工智能技术快速迭代的今天,处理海量文本数据的需求日益增长。微软推出的GraphRAG(Graph-based Retrieval-Augmented Generation)技术,通过结合知识图谱构建与检索增强生成技术,为私有数据场景下的智能问答提供了创新解决方案。而Ollama作为本地模型管理工具,完美解决了企业级应用中模型部署成本高、依赖云端API的痛点。
1.1 核心优势解析
- 成本革命:本地部署节省90%以上API调用费用(对比GPT-4o)
- 数据安全:全流程数据闭环,满足GDPR等合规要求
- 灵活扩展:支持动态切换多种开源模型(Mistral/Qwen2等)
- 性能突破:通过图谱结构实现知识关联推理
1.2 适用场景
- 企业知识库智能问答系统
- 医疗/法律领域的专业文档分析
- 多语言跨境业务场景
- 需要数据完全离线的特殊环境
二、环境准备指南
2.1 硬件要求
| 组件 | 最低配置 | 推荐配置 |
|---|---|---|
| CPU | 8核(支持AVX2) | AMD EPYC 7B13 |
| 内存 | 32GB DDR5 | 128GB DDR5 ECC |
| 显存 | 24GB(NVIDIA 4090) | 4×A100 80GB |
| 存储 | 1TB NVMe SSD | 4TB RAID 0 |
2.2 软件依赖
bash
复制
bash
复制
# 推荐使用Conda环境管理
conda create -n graphrag python=3.10 cudatoolkit=12.1
conda activate graphrag
# 系统依赖安装(Ubuntu示例)
sudo apt-get install -y build-essential libssl-dev libffi-dev python3-dev2.3 Ollama安装详解
bash
复制
# 官方安装脚本(支持Linux/macOS)
curl -fsSL https://ollama.com/install.sh | sh
# 验证安装
ollama --version # 应显示v0.2.25+
ollama list # 查看可用模型列表Windows用户特别说明:
- 下载Ollama Windows安装包(64位)
- 安装时勾选"Add to PATH"选项
- 设置环境变量:
powershell
复制
$env:OLLAMA_HOST = "http://localhost:11434"
三、模型部署全流程
3.1 推荐模型组合
| 模型类型 | 推荐版本 | 显存占用 | 适用场景 |
|---|---|---|---|
| LLM | Mistral-7B | 14GB | 复杂推理任务 |
| Qwen2-72B | 64GB | 专业领域分析 | |
| Embedding | nomic-embed-text | 2GB | 文本向量化 |
| bge-large-zh-v1.5 | 3GB | 中文语义理解 |
3.2 模型下载命令
bash
bash
复制
bash
复制
# 基础模型组合
ollama pull mistral nomic-embed-text
# 中文增强组合
ollama pull qwen2:7b bge-large-zh-v1.5
# 多模态扩展
ollama pull llama3:8b-math nomic-embed-text常见问题处理:
- 网络中断:使用
ollama pull --resume继续下载 - 存储不足:设置
OLLAMA_STORAGE_DIR指向大容量磁盘 - 版本冲突:
ollama rm <模型名>清理旧版本
四、GraphRAG项目配置
4.1 仓库克隆与初始化
bash
bash
复制
bash
复制
git clone https://github.com/TheAiSingularity/graphrag-local-ollama.git
cd graphrag-local-ollama
# 创建工作目录
mkdir -p ragtest/{input,output,logs}
cp examples/settings.yaml ragtest/4.2 关键配置解析
settings.yaml核心参数:
yaml
yaml
复制
yaml
复制
llm:
api_base: "http://localhost:11434/v1"
model: "mistral"
temperature: 0.3
num_ctx: 32768 # 上下文长度
embeddings:
api_base: "http://localhost:11434/api"
model: "nomic-embed-text"
dimensions: 768环境变量配置:
bash
复制
# Windows
set GRAPHRAG_API_KEY=ollama
# Linux/macOS
export GRAPHRAG_API_KEY=ollama五、索引构建实战
5.1 数据准备规范
- 文件格式:UTF-8编码的TXT文件
- 文件命名:
doc_001.txt(数字序号) - 内容规范:每段不超过500字,章节清晰
5.2 索引创建命令
bash
bash
复制
bash
复制
python -m graphrag.index --root ragtest \
--input ./input \
--embedding-model nomic-embed-text \
--llm-model mistral \
--batch-size 4 \
--num-workers 8进度监控技巧:
bash
复制
watch -n 1 'tail -n 20 logs/index.log'5.3 索引结构解析
复制
output/
├── graph.db # Neo4j图数据库
├── embeddings/ # 向量存储
├── metadata.json # 索引元数据
└── logs/ # 运行日志
六、智能查询实践
6.1 基础查询命令
bash
bash
复制
bash
复制
# 全局查询
python -m graphrag.query --root ragtest \
--method global \
--query "机器学习的核心算法有哪些?"
# 局部查询
python -m graphrag.query --root ragtest \
--method local \
--query "解释卷积神经网络的工作原理"6.2 结果优化技巧
-
提示词工程:
yaml
yaml
复制
yaml
复制
LOCAL_SEARCH_SYSTEM_PROMPTS = """ 你是一位领域专家,需要综合上下文中的多个信息源回答问题。 答案需包含: 1. 关键概念定义 2. 实现步骤分解 3. 实际应用案例 """ -
参数调优:
bash
- --temperature 0.15 # 降低随机性
--max_tokens 4096 # 增加输出长度
--top_k 5 # 控制生成多样性
七、高级应用场景
7.1 图谱可视化
bash
bash
复制
bash
复制
# 安装可视化工具
pip install pyvis networkx
# 生成可视化文件
python -m graphrag.visualize --input output/graph.db \
--output graph.html \
--layout force7.2 多模态扩展
python
python
复制
python
复制
# 添加图像处理模块
from graphrag.visualize import ImageProcessor
processor = ImageProcessor(
model="llava-phi3-vision",
device="cuda:0"
)7.3 企业级部署方案
- Kubernetes集群部署
- GPU资源动态调度
- 查询负载均衡
- 审计日志系统
八、常见问题解决方案
8.1 典型错误处理
| 错误代码 | 解决方案 |
|---|---|
| OLLAMA-01 | 检查OLLAMA_API_BASE配置 |
| INDEX-04 | 增加--batch-size参数 |
| EMBEDD-12 | 验证embedding模型是否下载成功 |
8.2 性能优化方案
- 显存不足:使用
ollama run --gpu-layers 30 - 速度优化:启用
--quantize q4_0 - 分布式处理:配置多节点集群
九、实战案例:构建企业知识库
9.1 项目背景
某跨国科技公司需要构建包含10万份技术文档的智能知识库,要求:
- 支持中英文混合查询
- 响应时间<3秒
- 准确率>95%
9.2 实施步骤
- 数据预处理:PDF转TXT + 元数据标注
- 索引构建:分批次处理(每批5000文档)
- 查询优化:定制领域术语表
- 监控系统:部署Prometheus+Grafana
9.3 效果对比
| 指标 | 传统RAG方案 | GraphRAG方案 |
|---|---|---|
| 响应时间 | 8.2s | 1.7s |
| 准确率 | 72% | 93% |
| 硬件成本 | $15,000/月 | $2,300/月 |

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 20
20 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)