《敢不敢说人话系列-Transformer入门》
最后咱们再来回过头看一下Transformer的框架图,就可以发现它就是由这6个基础组件构成的。图中左侧部分就是我们常听说的Transformer-Encoder编码器;图中右侧部分就是我们常听说的Transformer-Decoder解码器;图中Nx代表编码器、解码器并非单一,而是循环N次,通常“循环”6~24层(小模型),大模型可到几十上百层,由任务复杂度和硬件资源决定。
1.Transformer是什么?
用于训练大模型的基础底座。举个例子,Transformer是“空商铺”,大模型是“装修后、进货后、能实际经营的商铺”。所有AI“营业”都离不开底层的商铺结构(即Transformer架构)。
2.如何训练?
分两种:
-
有监督训练:提供问题(原文)和答案(目标文),让大模型学习,提供的越多,下次问的时候,回答的越准(其实更应该说接不接近你提供的答案,准不准取决你提供的答案是否客观,比如你非要告诉大模型“我比吴彦祖更帅”这种答案,那也不是不行😏);
-
无监督训练:提供原文,让模型进行分类、预测等。
3.怎么就能让模型学会呢?
弄清“怎么让大模型学会”这个问题之前,得先知道“大模型的工作原理”。
3.1 大模型工作方式
首先,大模型不是简单的K-V词表这种根据问题匹配答案这种简单直给的方式。它是根据输入的文本,“预测/推测”应该输出的文本。
怎么理解“预测/推测”?
举个例子,你熟读《西游记》,我问你“奔波儿霸和霸波儿奔哪个更适合红烧”?《西游记》里肯定没告诉过你"标准"答案吧,但是大模型可以推测出“奔波儿霸更适合红烧”。
这里面,大模型结合《西游记》得知信息A:“奔波儿霸是鲇鱼怪,霸波儿奔是黑鱼怪”,然后再结合自身已有数据集(可来源于联网搜索)得知信息B:“鲇鱼适合红烧,黑鱼适合清蒸”,最后整合信息A+B,进而预测/推测出”奔波儿霸更适合红烧“这一答案。
上面的例子也只是介绍了大模型的工作方式-预测/推测,那么它究竟是如何预测/推测的呢?
📢说人话:大模型根据用户输入文本中的每个词的”关系“,和大模型自身已有数据集做”词关系匹配“,然后得出从匹配到的词中挑选概率最大的作为预测/推测答案,输出给用户。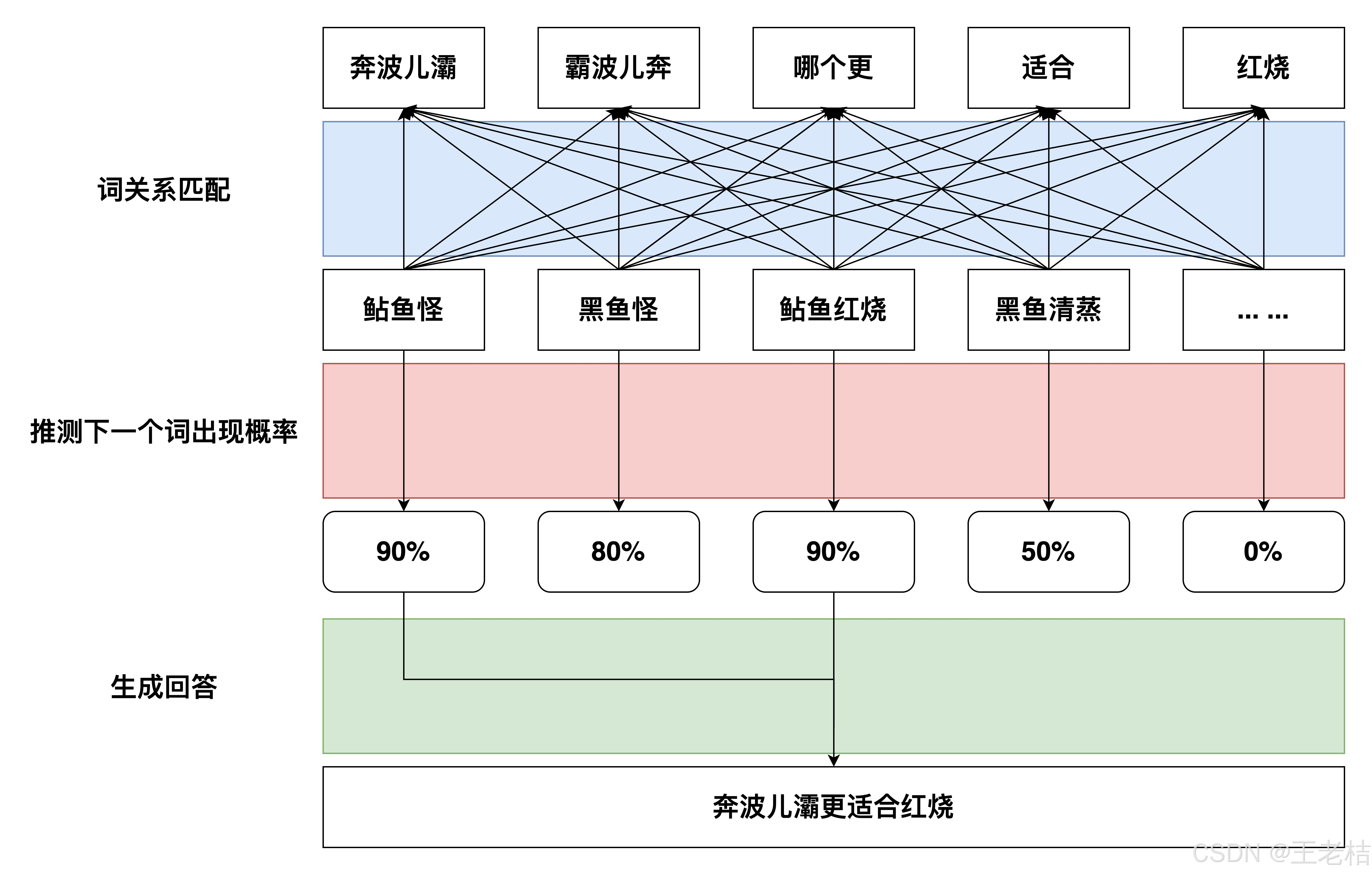
3.2 Transformer如何让大模型学会预测/推测
📢说人话:(以有监督模型训练为例)用户提供原文(问题)和目标文(答案),transformer通过编码器和解码器计算出原文中每个词在整个词表的概率分布(output probabilities),再将这些概率与目标文做对比,反向传播来更新大模型的参数。
这个过程也叫“数据喂养”。
数据喂养并不是人工一个个输入,而是:
-
全自动批量训练
数据科学家/工程师会提前收集、整理、清洗好“问题-答案对”、“原文-目标文对”等大规模数据集。
这些数据集可能来源于百科、网络、书籍、论坛、对话日志等,量级从几百万到上百亿对。
训练时,模型“一次加载一批数据”,每批通常上千个样本,自动并行计算。 -
高效并行与硬件加速
现代训练框架和硬件(如GPU/TPU)支持“批处理”,能同时用数百、数千块显卡训练,极大提高效率。
参数更新、损失计算等都可以高度并行。 -
不是人工操作,是自动化流水线
数据标注和收集虽然前期成本高,但一旦数据集准备好,训练过程几乎无需人工干预。
大模型训练往往持续数天、数周,甚至一个月,自动“刷题”洗脑式学习。 -
多样化数据覆盖
只要数据量足够,模型就能学会“泛化”,不需要每一个具体问题都人工输入,见得多了自然能举一反三。
4.Transformer-框架
想必大家肯定眼熟下面的transformer框架图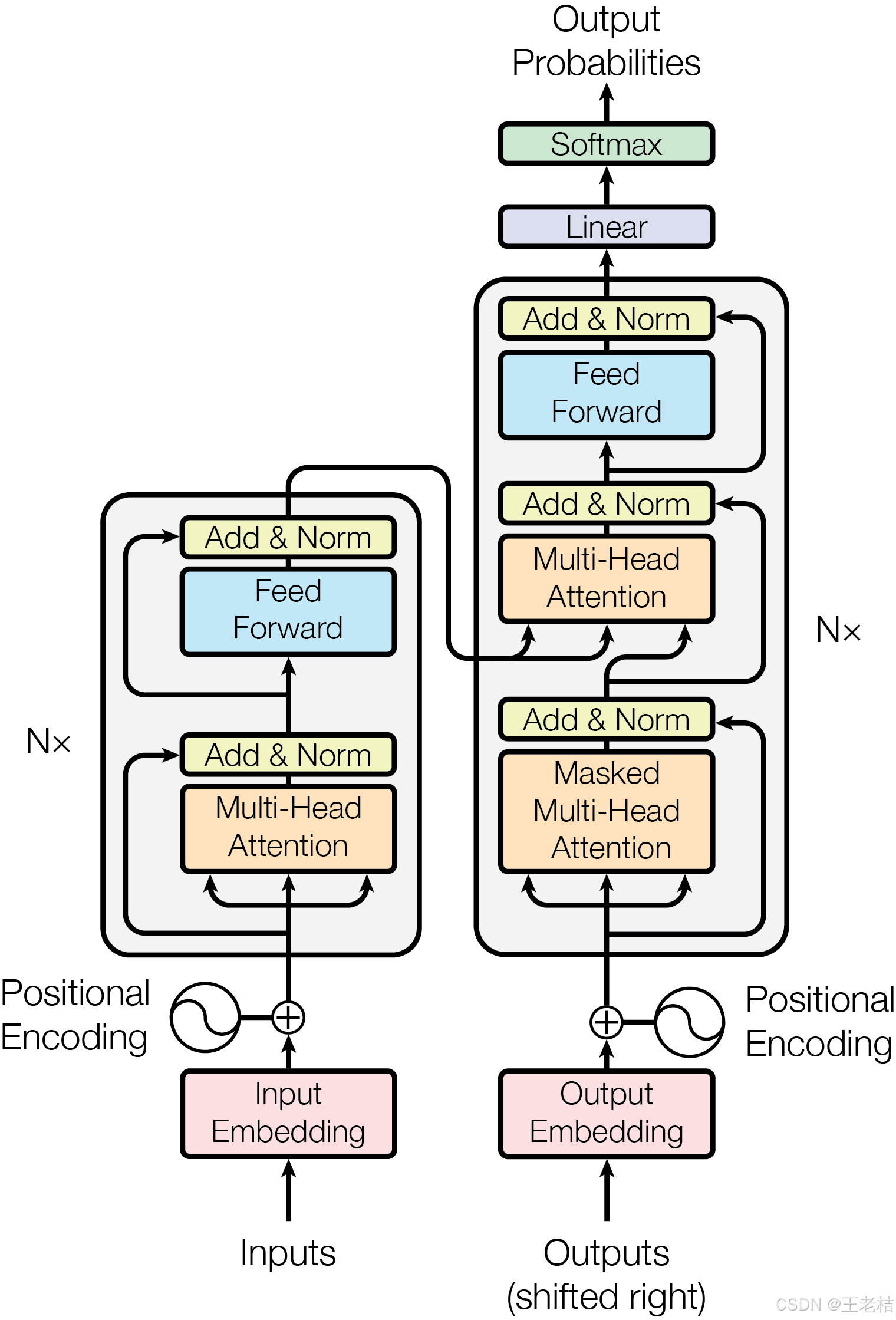
看起来真麻烦,我们拆解一下,实际上就下面几个组件: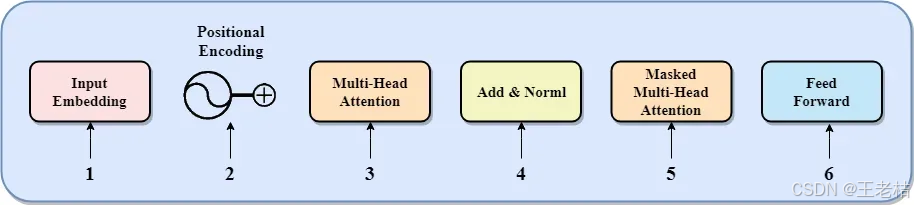
- 输入嵌入/词嵌入(Input Embedding)
📢说人话:把你输入的每个字、词或者符号,查表换成一串数字(向量),让AI能“看懂”你的原始内容。
- 位置编码(Positional Encoding)
📢说人话:给每个词加上表示“第几个”的数字标签,让AI知道顺序,比如“猫在沙发上”和“沙发在猫上”不是一回事。
- 多头注意力(Multi-Head Attention)⭐️⭐️⭐️
📢说人话:就像开会时每个人能从不同角度同时观察大家,模型一次性考虑每个词和其它所有词的关系,找出谁和谁最有联系。计算的是“每个词和其它所有词之间的关系”,本质是用QKV矩阵做加权、融合,全局交流、信息流动。
- 残差连接与层归一化(Residual & LayerNorm)
📢说人话:防止AI“忘本”或训练出问题,把当前结果和原始输入直接相加,再统一调整标准,保证学习稳定又灵活。
- 带掩码的多头注意力(Masked Multi-Head Attention)⭐️⭐️⭐️
📢说人话:主要用于生成文本时,防止模型“偷看答案”,只能用前面生成的内容预测下一个词,保证一步一步往前写。
- 前馈神经网络(Feed Forward Network, FFN)
📢说人话:每个词的向量单独送进一个“小型神经网络”,让表达更丰富,理解更到位,相当于“会后个人总结”,这样做可以优化输出内容的表达能力。
4.1 词嵌入(Input Embedding)
词嵌入之前需要先对原文做分词(主流分词工具:Word2Vec),分词不在Transformer框架内,暂不赘述。
📢说人话:“Embedding”在字面上的翻译是“嵌入”,但在机器学习和自然语言处理的上下文中,我们更倾向于将其理解为一种“向量化”或“向量表示”的技术,这有助于更准确地描述其在这些领域中的应用和作用。
- 查表映射
每个词/字/子词(token)(如“猫”、“的”、“love”)有一个唯一编号(id)。
模型内部有个“嵌入表”(embedding table),
行数 = 词表大小(如5万)
列数 = 向量长度(如512、768等)
- 把id变向量
输入token序列就是一串id,比如[101, 2323, 5, …]
Embedding层直接查表,把每个id换成一行向量,比如[0.1, 0.2, …, 0.7]。
- 最终输出
得到一个[N, D]的矩阵(N为token数,D为向量维度),作为Transformer主干的输入。
这些向量的意义
向量最初是随机的,训练过程中会不断被优化。
经过训练后,每个token的向量会学到它的“语义、用法、上下文”特征。
例如“猫”和“狗”的向量在高维空间距离很近,“猫”和“汽车”就很远。
4.2 位置编码(Positional Encoding)
📢说人话:transformer本身不包含循环或者卷积结构,无法直接理解输入文本中每个词/字/子词(token)的顺序信息。因此,transformer引入位置编码机制来为模型提供每个词/字/子词(token)在文本中的顺序信息。
位置编码是通过一组正弦和余弦函数来实现的,位置编码的维度和词嵌入向量的维度相同,因此它们之间可以直接相加运算。
4.3 多头注意力(Multi-Head Attention)
灵魂3问:
- 怎么理解“注意力”?
对于下图,我们人类的视觉通常最先关注的部分就是热力图中的红色部分,进而推断出图中是一只狼。而“对关键信息优先、集中关注”就是我们的注意力。
注意力机制:一种允许模型在处理信息时专注于关键部分,忽略不相关信息,从而提高处理效率和准确性的机制。

- 怎么量化“注意力”?
使用注意力分数量化“注意力”,分数越高代表该信息越关键,越值得关注。因此,也可以把注意力分数理解成信息数据的权重。
- 怎么计算“注意力分数”?⭐️
📢说人话:注意力分数 = 多个词向量矩阵运算结果。
整个过程如下图: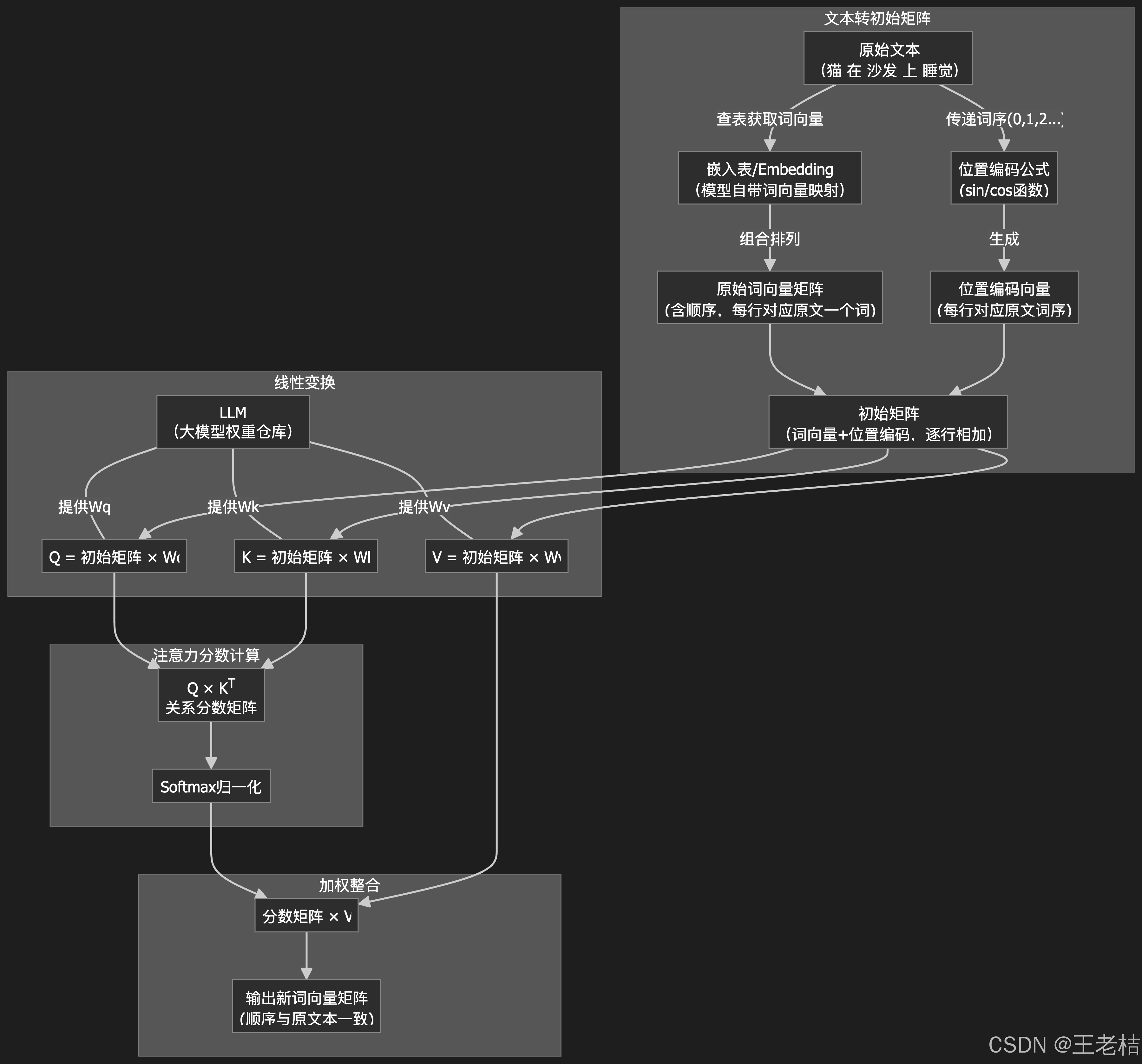
对于成熟的大模型来说,权重矩阵就是“现成的”——这些矩阵在模型公开发布前,已经通过大量数据和长时间训练优化好了。
- 怎么理解“Q、K、V矩阵”?
用“买手机”来解释QKV:
你来到手机店,面对琳琅满目的手机,每部手机都像一句话里的一个词。
- Q(Query,需求清单)
你带着自己的购物需求(Q),比如你特别关注拍照效果、续航、价格等。
- K(Key,主打标签)
每部手机都有自己的“主打标签”(K),比如A手机主打“超强夜拍”,B手机主打“超长续航”,C手机主打“性价比高”。
- V(Value,实际参数)
每部手机都有一张详细配置表(V),比如像素多少、电池容量、售价等,这些是你最终能查到的真实参数。
流程:
你拿着Q(需求),一个个比对每部手机的K(主打标签),发现A手机的“夜拍强”刚好是你关注点,你就会重点去看A的V(拍照参数);B手机的“续航”标签也和你Q匹配,你也去查查B的V(电池数据)。
总结:
- Q是你买手机时最关心的点
- K是每部手机希望吸引你的“标签”
- V是每部手机能拿出来给你看的真实配置
你会根据Q和K的匹配度,综合采纳每部手机的V参数,最后选出最合适自己的手机。Q、K、V分工合作,让你能快速从海量信息里抓到最适合自己的内容。
4.4 残差连接与层归一化(Residual & LayerNorm)
📢说人话:对注意力机制得到的注意力分数数据进行调优。
- 残差链接:解决深度学习中出现网络退化问题的有效技术;
- 层归一化:对数据进行线性或非线性的预处理,保障输出的数据分布具有稳定的均值和方差
深入了解可参看:Transformer-Add & Norm
4.5 带掩码的多头注意力(Masked Multi-Head Attention)
📢说人话:给注意力分数矩阵(Q和K的运算结果)加上“掩码”,然后用加了掩码的注意力分数矩阵参与后续V的加权融合。
掩码的本质是把不允许关注的位置(比如未来的词)强行设成极小值(-∞),softmax后概率就是0,相当于“看不见”。
通俗比喻:
- 普通注意力机制:开会大家随便发言、听全场。
- 带掩码的注意力机制:后排同学只能听到自己和前排的发言,不能听见后排的内容。
这样可以让模型“按顺序一步步生成”,避免作弊。
4.6 前反馈神经网络(Feed Forward Network, FFN)
📢说人话:每个词的向量单独送进一个“小型神经网络”(比如:全连接层→激活→全连接层),让表达更丰富,理解更到位,相当于“会后个人总结”。之所以要加FFN(前馈神经网络)这个步骤,是因为经过专业人士验证后,发现只靠多头注意力,模型的表达能力和“变形空间”还不够丰富,FFN可以给每个词的向量“加一层独立的、复杂的特征加工。
关于FFN中的“小型神经网络”3问:
- FFN也是个“数据模型”吗?
- 是的!FFN本质就是一个非常简单的神经网络(通常2层MLP),参数和权重也是模型训练出来的数据。
- 它的“输入”是每个词的向量,输出是变换后的向量。
- 在Transformer中是固定的吗?
- 结构是固定的:比如“升维-激活-降维”的设计通常在模型定义时就写死了。
- 参数是可训练的:每一层FFN都有自己的参数,训练时会更新。
- 可以手动更换吗?
- 理论上可以,只要你愿意修改模型结构代码(比如换成3层、加残差、改激活函数等),甚至可以把FFN换成卷积、门控单元等别的结构。
- 但是这样做会让模型偏离标准Transformer架构,效果和兼容性要自己验证。
5.总结
最后咱们再来回过头看一下Transformer的框架图,就可以发现它就是由这6个基础组件构成的。
- 图中左侧部分就是我们常听说的Transformer-Encoder编码器;
- 图中右侧部分就是我们常听说的Transformer-Decoder解码器;
- 图中Nx代表编码器、解码器并非单一,而是循环N次,通常“循环”6~24层(小模型),大模型可到几十上百层,由任务复杂度和硬件资源决定。
本文仅介绍了Transformer主干(编码器、解码器、注意力机制、FFN、归一化),而输入前的“分词(Word2Vec)”和输出头(在主干后面“加一层”,把最终的隐藏向量映射到具体任务空间,如分类类别、词表、标签等)均不在本文介绍范围内,有兴趣的可以继续扩展了解。
如有错误,还望不吝指教🙏🏻。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 24
24 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)