AAAI2025:用Label敏感奖励和AI反馈,让模型看懂视频也会聊天
强化学习正处于飞速发展的黄金期,已然成为人工智能领域的关键技术。从AlphaGo的惊艳亮相,到自动驾驶的逐步落地,强化学习的身影无处不在。凭借算法的持续创新,以及与深度学习的深度融合,其在复杂任务中的表现愈发卓越
关注gongzhonghao【计算机sci论文精选】
强化学习正处于飞速发展的黄金期,已然成为人工智能领域的关键技术。从AlphaGo的惊艳亮相,到自动驾驶的逐步落地,强化学习的身影无处不在。凭借算法的持续创新,以及与深度学习的深度融合,其在复杂任务中的表现愈发卓越。
据预测,未来几年,强化学习市场规模将迎来爆发式增长,前景一片光明,想往这方面发展的同学现在就行动起来吧。今天小图给大家精选3篇ACL有关强化学习方向的论文,为大家提供顶会发文最新前沿动态。
论文一:Enhancing Reinforcement Learning with Label-Sensitive Reward for Natural Language Understanding
方法:
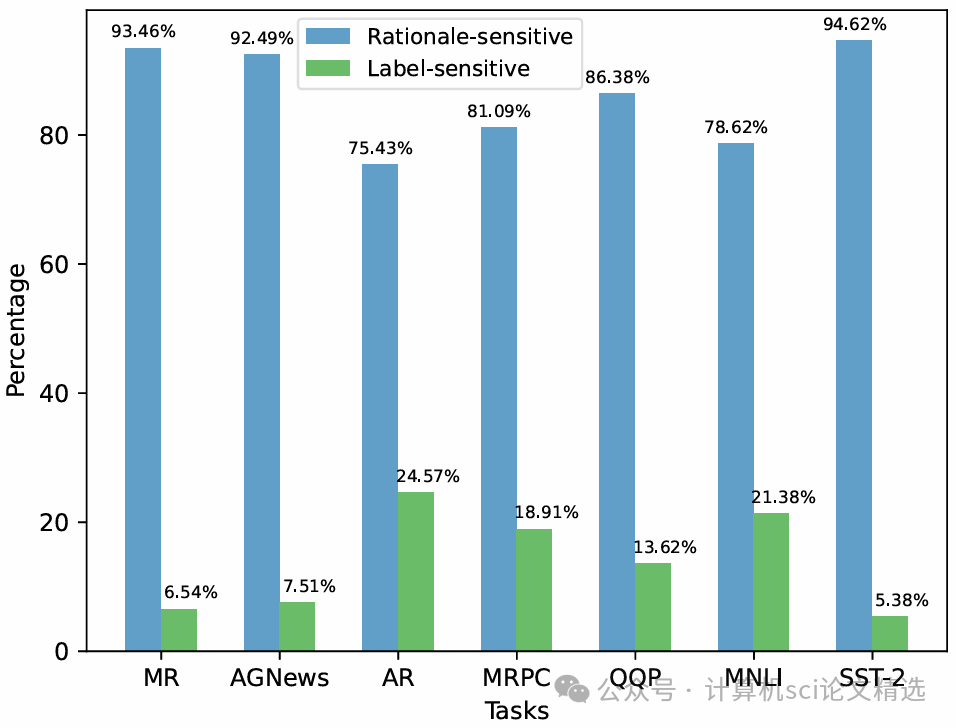
文章在强化学习训练环节中引入了标签敏感奖励设计,使模型能够根据任务标签的不同对预测行为进行有针对性的激励与惩罚,从而实现个性化学习。RLLR框架通过将标签嵌入与奖励信号耦合,动态调整每一步的优化方向,使语言模型在面对多样化语义任务时更为灵活和高效。作者在主流自然语言理解数据集上进行了广泛实验,结果证明该方法不仅提升了整体准确率,还有效改善了模型在细粒度语义分类上的表现。

创新点:
-
首次提出标签敏感奖励函数,根据不同类别标签动态调整强化学习中的奖励,增强模型适应性。
-
设计了RLLR框架,将标签信息深度融入优化流程,提升训练效率和泛化能力。
-
在多项自然语言理解任务上系统验证了新机制的有效性,实验结果显示平均性能提升1.54%,优于传统方法。
论文链接:
https://aclanthology.org/2024.acl-long.231
图灵学术论文辅导
论文二:Tuning Large Multimodal Models for Videos using Reinforcement Learning from AI Feedback
方法:
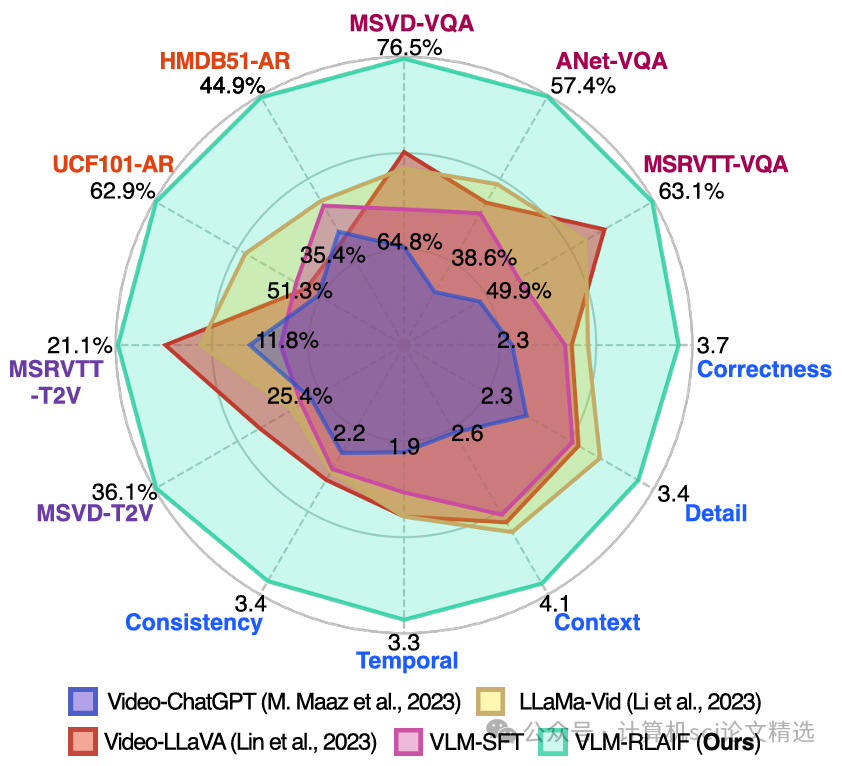
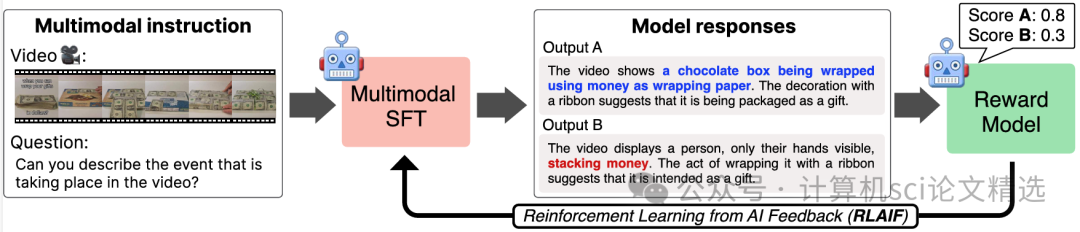
文章设计了一套基于强化学习的多模态模型微调流程,通过收集和利用AI生成的反馈作为奖励信号,推动模型自主优化视频与文本的对齐方式。作者在训练过程中不断调整模型参数,使其能够从复杂的视频内容中提取关键语义,并与文本描述实现高效匹配。最后,方法在多项视频理解和对齐任务中进行了实证检验,结果证明强化学习与AI反馈的结合显著提升了多模态模型的整体表现和泛化能力。
创新点:
-
首次采用AI反馈作为奖励信号,动态指导视频与文本之间的语义对齐过程,有效提升强化学习效果。
-
提出专门针对视频内容理解的多模态微调框架,使模型学习到更细致且一致的跨模态表示。
-
系统性评估了方法在多种真实视频任务上的表现,结果显示对齐质量和内容理解均超越现有主流方案。
论文链接:
https://aclanthology.org/2024.acl-long.52
图灵学术论文辅导
论文三:M-RAG: Reinforcing Large Language Model Performance through Retrieval-Augmented Generation with Multiple Partitions
方法:
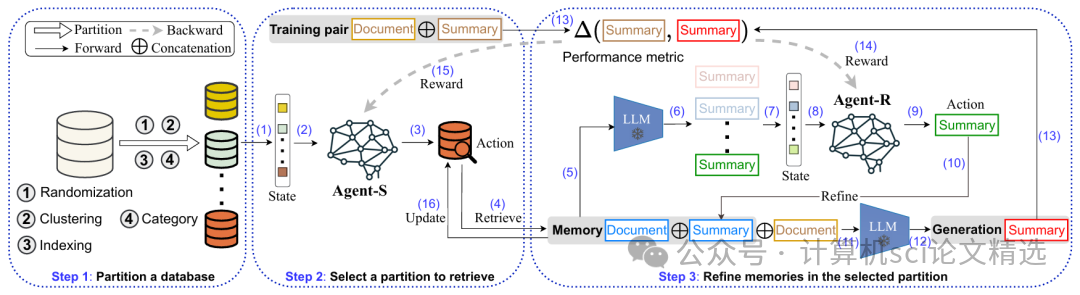
文章首先将外部知识库进行多分区处理,使模型能够针对不同主题或维度进行定向检索,从而获取更相关的信息。随后,通过多智能体强化学习,各智能体分别负责检索与生成任务的不同分区,并根据任务反馈动态调整策略,实现高效协作。最终,作者在多个文本生成和问答任务上对M-RAG框架进行了实证评估,结果显示该方法在准确性、信息覆盖和生成质量方面均取得了显著提升。
创新点:
-
首创多分区检索模块,将外部知识按主题或维度划分,实现针对性的信息增强和高效检索。
-
引入多智能体强化学习机制,各检索智能体独立优化自身分区表现,协同提升整体生成效果。
-
构建M-RAG端到端框架,在多项语言生成任务中系统验证,结果明显优于传统检索增强方法。
论文链接:
https://aclanthology.org/2024.acl-long.108
本文选自gongzhonghao【计算机sci论文精选】

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)