构建可信与可控的AI内容生成系统
它指的是我们能够通过各种技术手段,精确地引导和约束模型的生成行为,使其严格按照用户的特定指令和预设的规范来产生内容。该架构将复杂的系统划分为五个逻辑清晰、职责明确的层次,从底层的数据与知识到顶层的治理与运营,形成一个端到端的闭环体系。更严峻的是,这些系统也成为恶意行为者的新目标,他们通过对抗性提示、数据投毒等手段,诱导模型泄露敏感信息、生成非法内容,甚至利用模型漏洞进行更深层次的攻击。具体对模型的
一、相关背景与核心矛盾
自2022年以来,以大型语言模型(LLM)为代表的生成式人工智能技术以前所未有的速度席卷全球。从文本、图像到代码和视频,AIGC正在深刻变革内容创作、科学研究、软件开发和商业决策等众多领域。然而,这场技术盛宴的背后,一个深刻的核心矛盾日益凸显:AIGC所展现的强大生成能力与其内在的不可预测性、不可靠性之间存在着剧烈冲突。
一方面,通过大模型能够撰写流畅的报告、生成逼真的图像、编写复杂的代码,极大地提升了生产力。另一方面,它们也带来了前所未有的风险。其中最广为人知的是“幻觉”(Hallucination)问题,即模型会生成看似合理但与事实完全不符的错误信息[1]。此外,模型可能复现并放大训练数据中潜藏的社会偏见,产生歧视性或有害内容[2]。更严峻的是,这些系统也成为恶意行为者的新目标,他们通过对抗性提示、数据投毒等手段,诱导模型泄露敏感信息、生成非法内容,甚至利用模型漏洞进行更深层次的攻击[3]。
如何构建可信(Trustworthy)、可控(Controllable)的AI内容生成系统,已经从一个纯粹的技术探索问题,演变为决定AIGC能否成功从实验室走向广泛产业应用、并最终实现社会价值的关键瓶颈。
为了构建一个清晰的讨论框架,我们首先需要对两个核心概念——“可信”与“可控”——进行精确定义。
可信AI(Trustworthy AI)是一个多维度的综合性概念,全球各大组织和机构已形成广泛共识。它并非指AI系统永远不会犯错,而是指系统在整个生命周期内都应满足一系列严格的要求。
可控性(Controllability)则更侧重于生成过程本身的技术实现。它指的是我们能够通过各种技术手段,精确地引导和约束模型的生成行为,使其严格按照用户的特定指令和预设的规范来产生内容。这包括对生成内容的风格、格式、主题、情感、事实依据乃至背后所蕴含的价值观进行有效控制[4]。可控性是实现可信AI,特别是可靠性和安全性的重要技术前提。
本文目标旨在提出一个技术架构。通过分层解耦的系统设计,我们将展示如何将抽象的“可信””可控”原则转化为具体的工程实践。
二、分层结构的系统技术架构
为了将上述设计原则落地为可执行的工程方案,我们提出一个分层解耦的系统技术架构。该架构将复杂的系统划分为五个逻辑清晰、职责明确的层次,从底层的数据与知识到顶层的治理与运营,形成一个端到端的闭环体系。
以下是该架构的详细蓝图,以表格形式呈现,清晰地阐述了每一层的核心目标、关键模块及其技术选型示例。
|
架构层级 |
核心目标 |
关键模块 |
|
数据与知识层 (Data & Knowledge Layer) |
保证输入数据的质量、安全与知识的实时性、准确性。 |
高质量指令与偏好数据集构建 |
|
模型与能力层 (Model & Capability Layer) |
具备基础生成能力且针对特定任务进行优化(例如价值观)的生成模型能力核心。 |
基础大模型 |
|
控制与对齐层 (Control & Alignment Layer) |
在模型交互前后施加约束,确保生成过程与输出结果符合可信原则。 |
输入端安全检测 输出端内容审核与修正 |
|
应用与编排层 (Application & Orchestration Layer) |
封装底层能力,响应复杂的上层应用任务。 |
智能体/工具编排 |
|
治理与运营层 (Governance & Operations Layer) |
实现AI系统全生命周期的监控、迭代与审计。 |
风险与性能监控 |
架构设计解析——
该五层架构的核心思想是“关注点分离”。
- 数据与知识层是系统的基石,它决定了模型认知世界的基础和边界。通过集成外部知识库(RAG),我们从根本上解决了LLM知识静态和幻觉的问题[5]。
- 模型与能力层是系统的“引擎”。选择合适的LLM并利用PEFT等技术进行高效微调,可以在成本可控的前提下,使模型更好地适应特定领域的任务和风格要求。
- 控制与对齐层是系统的“缰绳”和“护栏”。它独立于核心模型,通过在输入和输出两端设置检查点,强制执行安全、伦理和价值观约束。这种外挂式的控制方式比直接修改模型内部结构更具灵活性和可扩展性。
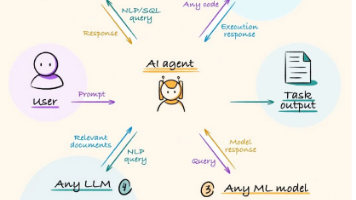
- 应用与编排层是系统的“指挥官”。它将底层的原子能力(如生成、检索、工具调用)编排成复杂的工作流,以完成用户的最终任务。
- 治理与运营层是系统的“中枢神经系统”。确保系统在长期运行中始终保持可信、可控的状态。
通过这套架构,开发者可以像搭建乐高积木一样,根据具体的业务需求和风险等级,选择并组合不同层级的模块,构建出功能强大且高度可信的生成式AI应用。
三、关键模块实施路径
本章节将深入探讨前述架构蓝图中的三个核心模块:外部知识库集成(RAG)、输入端安全检测模块和可控性增强微调和事实性增强
模块一:外部知识库集成 (基于RAG)
检索增强生成已成为解决LLM幻觉、提升回答事实性的行业标准方案[5]。其核心思想是在生成答案前,先从一个可靠的外部知识库中检索相关信息,并将这些信息作为上下文提供给LLM,强制其基于给定事实进行回答。
实施步骤:
- 知识库构建与向量化:加载企业内部的PDF、Markdown、Word等格式的文档。将长文档切分为语义完整且大小适中的文本块。合适的块大小和重叠度对检索质量至关重要。初始化选定的嵌入模型,将每个文本块转换为高维向量,并连同其原始文本及元数据(如来源文件名、页码)一同存入向量数据库。
- 检索器:向量数据库封装成一个 `Retriever` 对象。该对象的核心功能是接收一个查询字符串,将其向量化,然后在数据库中执行相似度搜索(通常是余弦相似度),返回最相关的Top-K个文本块。
- 提示词工程:设计一个结构化的提示词模板。该模板必须明确指示LLM,要求它“仅根据”提供的上下文来回答问题,如果上下文中没有相关信息,则明确回答“不知道”。这是抑制幻觉的关键。
- 生成与溯源:构建一个完整的RAG链。该链首先调用检索器获取上下文,然后将上下文和原始问题填入提示词模板,最后将格式化后的提示词发送给LLM生成答案。在返回最终答案的同时,一并返回被检索到的文本块的元数据,作为答案的引用来源,实现可追溯性。
模块二:输入端安全检测模块
输入端安全检测模块(护栏)是在LLM处理用户输入之前或之后执行的一系列安全检查,旨在拦截和处理不当内容。输入端护栏尤其重要,因为它可以从源头上阻止恶意攻击和不当请求。
实施步骤:
- 规则与轻量级分类过滤:定义一个全面的敏感词库,覆盖政治、色情、暴力、仇恨等类别。训练一个轻量级的文本分类器(如FastText或基于BERT的微调模型),用于快速判断输入的基本意图,以及是否包含提示词注入等恶意攻击。
- 基于LLM的自评估防御:利用一个独立的、高度安全的LLM(如QWen,DeepSeek)来评估用户输入的意图是否安全。此层精度高,但成本和延迟也更高。
模块三:可控性增强微调和事实性增强
可控性增强微调和事实性增强是对LLM本身的安全性的增强,旨在通过对模型内部的调整,不显著牺牲主模型主要任务性能的前提下,提升模型在生成内容时对特定敏感信息的敏感度,从而降低生成有害内容的风险。
具体对模型的可控性增强微调的方法是另外一个比较大的话题,涉及数据集的构建, 微调的具体控制以及微调后模型的评估,这里不深入展开。
四、结论
实现可信与可控的关键在于采用一种分层解耦的架构思想。
提升事实性依赖于RAG,保障安全性需要多层护栏,促进公平性要靠去偏算法,而实现可控性则离不开精细的对齐技术和人机协同。最终确保AI的行为始终处于人类的有效监督之下。
参考文献:
- Fadeke Adegbuyi:Understanding and Mitigating AI Hallucination
- Generative AI Security Risks: 8 Critical Threats You Should Know, Generative AI Security Risks: 8 Key Threats to Know - Keepnet
- SentinelOne:10 Generative AI Security Risks
- Vijay K:How do you control the output of generative AI models?,https://www.theaiops.com/how-do-you-control-the-output-of-generative-ai-models/
- Jan Overney:AI Enterprise Systems: A Blueprint for Accurate, Secure, and Scalable GenAI
- Hannah Brown, Leon Lin, Kenji Kawaguchi, Michael Shieh:Self-Evaluation as a Defense Against Adversarial Attacks on LLMs,https://arxiv.org/abs/2407.03234

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)