AI系统背后的“数据保险箱”:S3与MinIO如何撑起MLOps的数据底座?
项目阶段推荐方案快速验证、小团队AWS S3(省心省力)企业级、合规要求高MinIO(自主可控)混合云/边缘场景MinIO + 多站点复制希望避免厂商锁定抽象存储层,统一使用S3 API🔑核心建议:无论选择哪种后端,都应通过标准接口(如boto3)进行抽象,让上层应用不感知底层差异。这才是MLOps工程化的正确姿势。AI不是一个人的算法秀,而是一群人的系统工程。当你的模型开始频繁迭代、数据不断积
在AI项目从实验室走向生产的过程中,有一个问题始终绕不开:数据和模型文件怎么存、怎么管、怎么用?
很多团队一开始用本地磁盘、NFS甚至Git管理模型和数据集,结果随着项目规模扩大,出现了版本混乱、协作困难、备份缺失、跨地域访问慢等一系列问题。最终发现——没有一个可靠的数据存储底座,AI项目注定走不远。
这时候,对象存储(Object Storage) 成为了MLOps工程师的“刚需”。而在众多对象存储方案中,AWS S3 和 MinIO 是最常被提及的两个名字。
它们为何如此重要?又该如何选择?本文将带你深入理解对象存储在AI系统中的核心作用,并通过实战案例,手把手教你如何用 Python 接入它们。
一、为什么AI项目离不开对象存储?
我们先来看一个典型的AI项目生命周期:
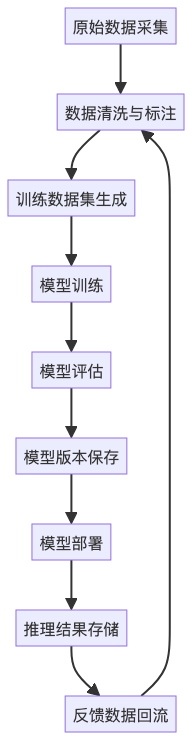
在整个流程中,几乎每个环节都会产生大量非结构化数据:图像、视频、日志、模型权重(.pt、.h5)、特征文件(.pkl)、日志文件等。这些数据有以下几个特点:
- 体积大:单个模型动辄几百MB甚至数GB;
- 数量多:每天训练多个版本,数据集不断迭代;
- 跨团队协作:数据科学家、工程师、运维需要共享访问;
- 长期归档:需保留历史版本用于审计或复现实验。
传统文件系统(如本地磁盘、NAS)难以满足这些需求。而对象存储天生为这类场景设计:
✅ 支持海量数据存储(PB级)
✅ 提供统一命名空间,便于管理
✅ 高可用、高持久性(S3可达99.999999999%持久性)
✅ 支持版本控制、生命周期管理、权限隔离
✅ 通过HTTP API访问,天然支持跨平台、跨地域协作
二、S3 vs MinIO:公有云 vs 自建,怎么选?
|
对比维度 |
AWS S3 |
MinIO |
|
所属厂商 |
Amazon |
开源(可自建) |
|
部署方式 |
公有云托管 |
可私有化部署 |
|
成本 |
按使用量计费(存储+流量+请求) |
初期投入高,长期可能更便宜 |
|
可控性 |
中等(受限于AWS生态) |
高(完全自主控制) |
|
安全合规 |
AWS成熟安全体系 |
可定制安全策略,适合私有云/边缘 |
|
兼容性 |
行业标准 |
完全兼容S3 API |
什么时候选 AWS S3?
- 团队已在使用 AWS 生态(EC2、SageMaker、Lambda)
- 希望快速上线,减少运维负担
- 数据主要在云端处理,无需本地闭环
- 接受按量付费模式
✅ 典型场景:初创公司做AI产品原型、云上训练任务调度
什么时候选 MinIO?
- 数据敏感,需私有化部署(金融、医疗、军工)
- 已有IDC或Kubernetes集群,希望统一存储底座
- 跨地域边缘节点需本地缓存(如车载AI、工厂质检)
- 希望避免厂商锁定,构建可移植MLOps架构
✅ 典型场景:企业级MLOps平台、混合云AI系统、边缘推理集群
📌 关键洞察:MinIO 的最大优势是 兼容 S3 API,这意味着你可以用同样的代码对接两者,实现“一次开发,随处部署”。
三、Python实战:用 boto3 统一访问 S3 和 MinIO
boto3 是 AWS 官方的 Python SDK,但它不仅可以访问 S3,也能访问任何兼容 S3 协议的服务——包括 MinIO。
下面是一个通用的封装示例:
import boto3
from botocore.client import Config
# 配置参数
ENDPOINT_URL = "https://your-minio-server.com" # MinIO 地址;若是S3则留空
ACCESS_KEY = "your-access-key"
SECRET_KEY = "your-secret-key"
BUCKET_NAME = "ai-models"
REGION = "us-east-1"
# 创建客户端(支持S3和MinIO)
s3_client = boto3.client(
's3',
endpoint_url=ENDPOINT_URL, # MinIO必须指定;S3可省略
aws_access_key_id=ACCESS_KEY,
aws_secret_access_key=SECRET_KEY,
region_name=REGION,
config=Config(signature_version='s3v4'),
verify=False # 若MinIO用自签名证书可关闭校验(生产慎用)
)
# 上传模型文件
def upload_model(local_path, s3_key):
s3_client.upload_file(local_path, BUCKET_NAME, s3_key)
print(f"Uploaded {local_path} to s3://{BUCKET_NAME}/{s3_key}")
# 下载数据集
def download_dataset(s3_key, local_path):
s3_client.download_file(BUCKET_NAME, s3_key, local_path)
print(f"Downloaded {s3_key} to {local_path}")
# 列出模型版本
def list_models(prefix=""):
response = s3_client.list_objects_v2(Bucket=BUCKET_NAME, Prefix=prefix)
for obj in response.get('Contents', []):
print(f"{obj['Key']} - {obj['Size']} bytes - {obj['LastModified']}")使用说明:
- 对接 AWS S3:只需去掉
endpoint_url,其他保持不变。 - 对接 MinIO:确保 MinIO 已开启 HTTPS 并配置好用户权限。
- 所有操作通过标准 S3 API 完成,切换存储后端只需改配置,无需改代码。
四、对象存储如何融入MLOps体系?
我们来看一个完整的MLOps数据流架构:
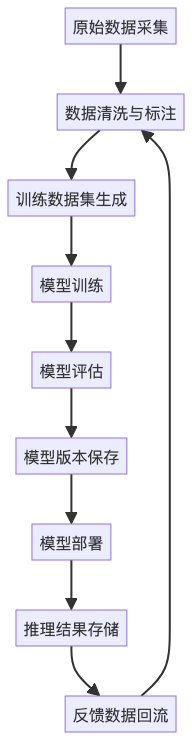
在这个架构中,对象存储扮演了“数据枢纽”的角色:
- 所有数据集、模型、日志统一归档
- MLflow、Kubeflow 等工具通过S3路径引用资源
- 训练与部署解耦:训练完自动上传,部署时按需拉取
- 支持版本控制(S3 Versioning / MinIO Versioning),实现模型可追溯
五、总结:选对“数据保险箱”,AI才能跑得远
|
项目阶段 |
推荐方案 |
|
快速验证、小团队 |
AWS S3(省心省力) |
|
企业级、合规要求高 |
MinIO(自主可控) |
|
混合云/边缘场景 |
MinIO + 多站点复制 |
|
希望避免厂商锁定 |
抽象存储层,统一使用S3 API |
🔑 核心建议:无论选择哪种后端,都应通过标准接口(如boto3)进行抽象,让上层应用不感知底层差异。这才是MLOps工程化的正确姿势。
结语:
AI不是一个人的算法秀,而是一群人的系统工程。当你的模型开始频繁迭代、数据不断积累时,别忘了给它们一个安全、可靠、可扩展的“家”。
S3 和 MinIO,就是这个家的“数据保险箱”。
用好它,你的AI系统才能真正从“能跑”走向“稳跑”。
如果你对 AI 服务开发感兴趣,欢迎关注我的公众号【一只鱼丸yo】,我会持续分享 AI + 后端融合的技术经验。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 25
25 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)