大模型别再 “瞎琢磨” 了!美团新方法VSRM让推理效率飙升,还不丢正确率
大型推理模型(LRM)在复杂推理任务上近期取得了显著进展,主要得益于可验证奖励的强化学习。然而,LRM 往往存在“过度思考”问题:在简单问题上耗费过多计算,降低整体效率。现有高效推理方法通常需要准确评估任务难度,以预设 token 预算或选择推理模式,这限制了它们的灵活性与可靠性。本文重新思考过度思考的本质,发现关键在于鼓励有效步骤、惩罚无效步骤。
摘要:大型推理模型(LRM)在复杂推理任务上近期取得了显著进展,主要得益于可验证奖励的强化学习。然而,LRM 往往存在“过度思考”问题:在简单问题上耗费过多计算,降低整体效率。现有高效推理方法通常需要准确评估任务难度,以预设 token 预算或选择推理模式,这限制了它们的灵活性与可靠性。本文重新思考过度思考的本质,发现关键在于鼓励有效步骤、惩罚无效步骤。为此,我们提出一种新颖的基于规则的可验证逐步奖励机制(VSRM),根据推理轨迹中各中间状态的表现来分配奖励。该方法直观自然,契合推理任务的逐步特性。我们在 AIME24 和 AIME25 等标准数学推理基准上进行大量实验,将 VSRM 与 PPO 及 Reinforce++ 结合。结果表明,该方法在保持原有推理性能的同时,显著减少了输出长度,实现了效率与准确率的最佳平衡。进一步分析训练前后的过度思考频率与 pass@k 分数,证实本方法确实能有效抑制无效步骤、鼓励有效推理,从根本上缓解过度思考问题。
论文标题: "Promoting Efficient Reasoning with Verifiable Stepwise Reward"
作者: "Chuhuai Yue, Chengqi Dong, Yinan Gao"
会议/期刊: "arXiv preprint"
发表年份: 2025
原文链接: "https://arxiv.org/abs/2508.10293"
关键词: ["大型推理模型", "过度思考", "逐步奖励", "强化学习", "高效推理"]
研究背景:为什么LRMs总是"想太多"?
近年来,大型推理模型(Large Reasoning Models, LRMs)如OpenAI O1和DeepSeek-R1通过测试时扩展(Test-Time Scaling, TTS)技术,在数学推理、代码生成等复杂任务上取得了突破。它们通过生成更长的思维链(Chain-of-Thought, CoT)来分解问题,探索多种解法,就像学生解题时"写草稿"一样。但这种"多多益善"的策略也带来了致命问题——过度思考(Overthinking):模型会为简单问题分配过多计算资源,不仅延长推理时间(有时甚至生成8000+token的冗余内容),还可能因思路混乱导致错误。
现有方法的三大痛点:
-
"一刀切"的长度限制:如ThinkPrune等方法预设固定token预算,强制模型在限定长度内完成推理,但简单问题可能"预算过剩",复杂问题又"预算不足"。
-
隐性长度偏见:通过奖励函数直接惩罚长输出(如GRPO-LEAD),可能导致模型为了压缩长度而跳过关键推理步骤,牺牲准确性。
-
缺乏动态评估:传统强化学习(RLVR)仅基于最终结果给予奖励,无法区分推理过程中哪些步骤有效、哪些是冗余,模型难以学到"高效推理"的模式。
论文通过对500个数学问题的分析发现,超过60%的LRM输出包含无效步骤——这些步骤既不提升准确性,也不帮助探索新解法,纯粹是"自我怀疑"或"重复计算"。例如在求解"[-500,0]中有多少负整数"这样的简单问题时,模型可能生成8734个token的冗长推理,最终还得出错误答案(正确答案是500,模型却算成499)。

图2展示了模型在计算区间内整数数量时的过度思考:反复质疑"从-1到-500到底有多少个数",消耗大量token却得出错误结论。
方法总览:VSRM如何让模型"聪明地思考"?
VSRM的核心思想是赏罚分明:通过评估推理过程中每一步的实际贡献,奖励有效步骤、惩罚无效步骤,引导模型学会"该想时想,该停时停"。整体框架分为三个关键步骤:
1. 推理步骤分割:像切香肠一样拆分思维链
首先,模型生成的完整推理轨迹(主轨迹)会被分割为多个子轨迹。分割依据是推理过程中的"自然断点"——论文发现LRMs在转换推理步骤时,常使用"因此"、“然而”、"接下来"等转折词(高熵标记),就像文章的段落分隔符。例如,将"问题重述→公式推导→结果验证"拆分为三个子轨迹。
2. 子轨迹准确性评估:给每段"草稿"打分
对每个子轨迹,模型会生成多个候选答案,通过验证器(如DeepSeek-R1)计算平均准确率(AiA_iAi)。例如,某子轨迹若5次生成中有3次正确,则Ai=0.6A_i=0.6Ai=0.6。
3. 动态奖惩计算:有效步骤加分,无效步骤扣分
通过相邻子轨迹的准确率差异(di=Ai−Ai−1d_i = A_{i} - A_{i-1}di=Ai−Ai−1)计算奖励:
- 若di>0d_i>0di>0:说明当前步骤提升了准确性,给予正奖励;
- 若di<0d_i<0di<0:步骤导致准确率下降,给予负奖励;
- 若di≈0d_i≈0di≈0(微小波动):通过传播衰减机制(Lookahead Window)判断后续步骤是否受当前影响,避免奖励稀疏。
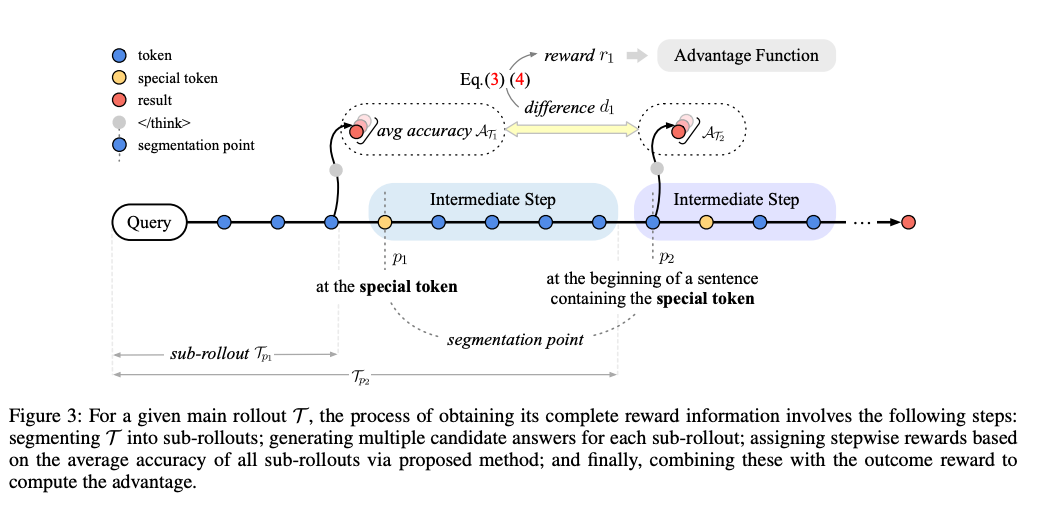
图3清晰展示了VSRM的工作流程:主轨迹(T)被分割为子轨迹(T1-Tk),计算各子轨迹准确率(A1-Ak),再通过差异(d1-dk)生成逐步奖励,最终结合结果奖励优化模型。
关键结论:VSRM的三大突破
-
重新定义过度思考本质:首次提出"无效步骤累积"是核心问题,而非单纯"输出过长",为高效推理提供新优化方向。
-
可解释的逐步奖励:无需训练额外过程奖励模型(PRM),通过规则化子轨迹分割和准确率差异计算奖励,避免了PRM的不稳定性。
-
性能与效率双赢:在AIME24、MATH-500等6个 benchmarks上,VSRM使1.5B模型token消耗减少55%(从12605→7065),同时pass@1提升0.4%;7B模型表现类似,验证了方法在不同规模模型上的普适性。
深度拆解:VSRM的三大核心模块
模块一:基于高熵标记的步骤分割算法
传统步骤分割依赖人工规则(如固定长度),而VSRM利用LRMs推理时的高熵标记(High-Entropy Tokens)——这些标记(如"因此"、“解得”、“考虑”)在推理转折点出现频率显著高于随机文本。论文通过统计发现,包含这些标记的句子边界,子轨迹准确率差异(did_idi)的绝对值比随机分割高37%,说明它们是"自然推理断点"。
分割步骤具体实现:
- 提取推理内容中所有高熵标记位置;
- 确保相邻分割点间距≥100token(避免过细分割);
- 每个子轨迹必须包含完整语义(如一个公式推导或一个子问题求解)。
模块二:动态奖励计算:从"结果导向"到"过程导向"
传统RLVR的奖励函数是"非黑即白"的(正确+1,错误0),而VSRM的逐步奖励函数则像"教练实时反馈":
-
基础奖励:di=Ai−Ai−1d_i = A_i - A_{i-1}di=Ai−Ai−1,直接反映当前步骤的贡献。例如,子轨迹T1准确率0.3,T2准确率0.7,则T2步骤奖励+0.4。
-
传播衰减机制:当∣di∣<ϵ|d_i| < \epsilon∣di∣<ϵ(微小波动,如0.01)时,向前搜索Lmax(默认4)步内是否有显著变化(∣dj∣≥ϵ|d_j| ≥ \epsilon∣dj∣≥ϵ)。若找到,则当前步骤奖励为sign(dj)×∣dj∣×γj−isign(d_j) \times |d_j| \times \gamma^{j-i}sign(dj)×∣dj∣×γj−i(γ\gammaγ为衰减因子,默认0.7)。例如,步骤i无显著变化,但步骤i+2有+0.5的提升,则步骤i奖励为+0.5×0.72=+0.245+0.5 \times 0.7^2 = +0.245+0.5×0.72=+0.245。
这种设计解决了"奖励稀疏"问题——即使某一步本身无显著贡献,只要它为后续有效步骤铺路,也能获得间接奖励。
模块三:与强化学习的结合:PPO与Reinforce++适配
VSRM生成的逐步奖励(RstepR_{step}Rstep)会与传统结果奖励(RresultR_{result}Rresult)和格式奖励(RformatR_{format}Rformat)结合,形成最终目标函数:
Rtotal=Rstep+α⋅Rresult+β⋅Rformat R_{total} = R_{step} + \alpha \cdot R_{result} + \beta \cdot R_{format} Rtotal=Rstep+α⋅Rresult+β⋅Rformat
其中α=0.8\alpha=0.8α=0.8、β=0.2\beta=0.2β=0.2,确保模型优先优化推理过程,同时不忽视最终结果和格式正确性。实验证明,VSRM与PPO结合(VSRM-PPO)在效率上更优,与Reinforce++结合(VSRM-R++)在复杂任务上性能略好。
实验结果:性能与效率的"双赢"验证
1. 主实验:VSRM vs 主流高效推理方法
论文在6个数学推理数据集(AIME24/25、MATH-500、AMC23、Minerva、OlympiadBench)上对比了VSRM与5种基线方法(LC-R1、ThinkPrune、AdaptThink等),核心指标为pass@1(准确率) 和平均token长度。
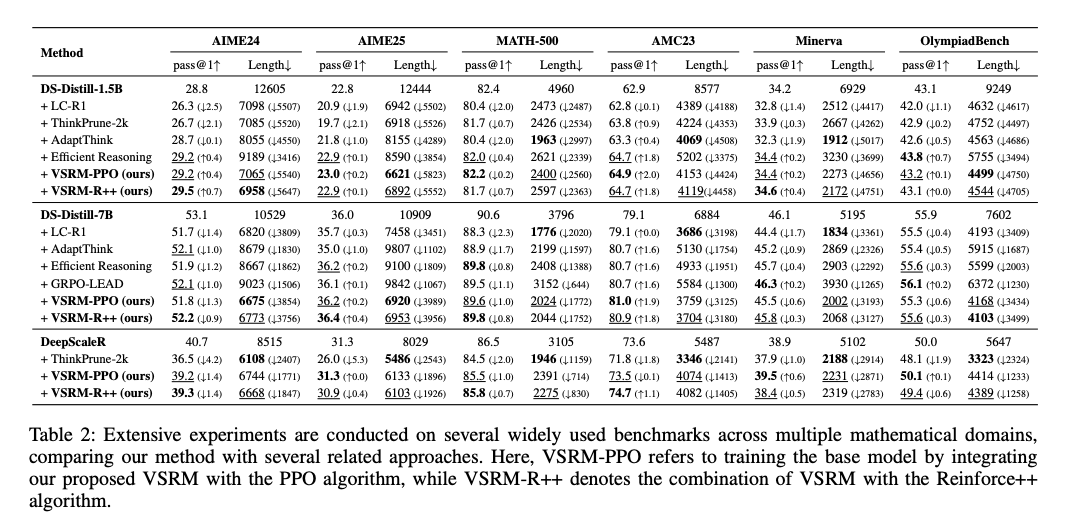
表2关键发现(以1.5B模型为例):
- 效率碾压:VSRM-PPO的平均token长度为7065,比AdaptThink(8055)短12%,比Efficient-Reasoning(9189)短23%,仅略长于ThinkPrune(7085)。
- 性能持平甚至反超:在AIME24上pass@1达29.2%,超过所有基线方法,甚至比原模型(28.8%)提升0.4%;在Minerva数据集上保持34.4%的准确率,与Efficient-Reasoning相当,但长度缩短4656 token。
2. 消融实验:哪些组件对VSRM至关重要?
为验证各模块作用,论文设计了三组消融实验:
| 方法 | AIME24 pass@1 | 平均token长度 | 关键变化 |
|---|---|---|---|
| 原模型(DS-Distill-1.5B) | 28.8% | 12605 | - |
| + VSRM(无传播衰减) | 28.6% | 8638 | 奖励稀疏导致效率提升有限 |
| + VSRM(仅结果奖励) | 26.3% | 7098 | 牺牲准确率换取长度压缩 |
| + VSRM-PPO(完整版) | 29.2% | 7065 | 性能与效率最优平衡 |
结果显示,传播衰减机制是VSRM的核心:移除后token压缩率从55%降至39%,证明其有效解决了奖励稀疏问题;而仅用结果奖励会导致准确率下降2.5%,说明过程奖励对保持性能至关重要。
3. 推理行为分析:模型真的学会"高效思考"了吗?
为验证VSRM是否真正减少无效步骤,论文用DeepSeek-R1重新评估训练后模型的500个输出:
- 过度思考率:从原模型的62.4%(312/500)降至25.2%(126/500);
- 有效步骤占比:从38.7%提升至69.3%;
- pass@k曲线:随着候选答案数量k增加,VSRM模型的准确率提升趋势与原模型一致,说明压缩长度并未限制模型探索能力。
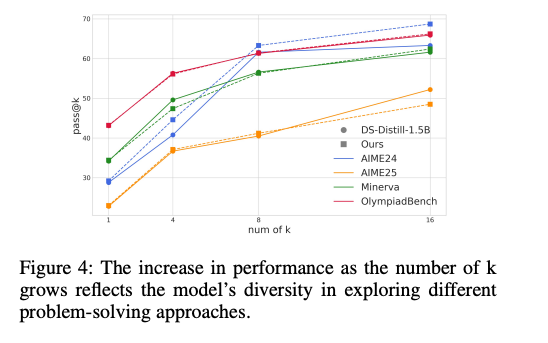
图4显示,VSRM模型在k=16时pass@16达82.3%,与原模型(82.4%)几乎持平,证明其在压缩长度的同时,保留了探索多种解法的能力。
未来工作:VSRM的进阶方向
论文计划探索的方向:
-
跨任务扩展:将VSRM应用于代码调试(需定位错误行)、逻辑推理(需验证每步演绎)等任务,测试其通用性。
-
动态分割优化:当前分割依赖预定义高熵标记,未来可结合问题难度自适应调整分割粒度(简单问题粗分,复杂问题细分)。
-
多模态推理适配:扩展至视觉推理任务(如数学公式OCR),通过子轨迹评估图像理解步骤的有效性。
个人思考:VSRM的潜在挑战
-
计算成本:子轨迹生成和多候选评估会增加训练开销(约为传统RL的1.5倍),如何在效率与成本间平衡?
-
验证器偏差:子轨迹准确率依赖验证器(如R1),若验证器本身存在偏见(如对特定解法偏好),可能误导VSRM奖励。
-
极端场景鲁棒性:在零样本或少样本场景下,子轨迹准确率评估可能不可靠,VSRM是否仍能稳定工作?

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 11
11 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)