AI实验管理神器:WandB全功能解析
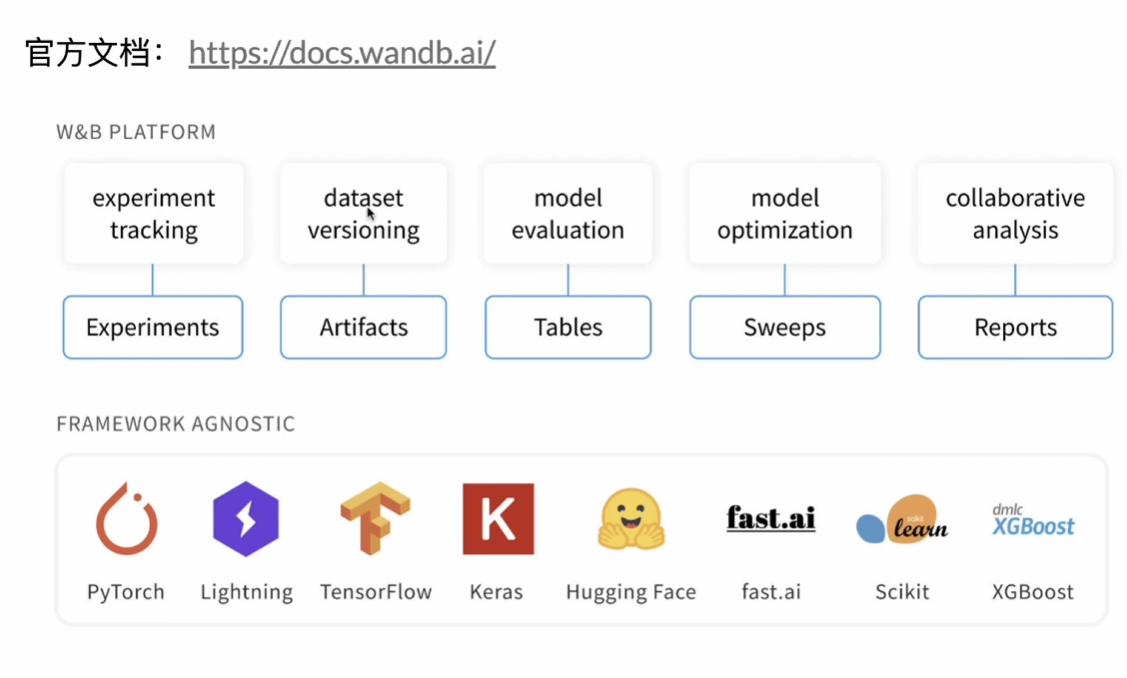
本文介绍了基于WandB的实验跟踪与自动化调参工具的核心功能。主要包括:1)支持多账号登录和版本关联;2)交互式表格支持图像、音频等多媒体数据展示;3)自动化模型调参和并行训练能力;4)实验跟踪通过wandb.log记录指标,实现跨设备分布式训练;5)可视化Case分析功能简化大规模数据展示;6)Sweep功能实现超参数自动优化,支持多机分布式调参。系统通过sweep_id实现任务绑定,可在不同设
·
1注册
谷歌账号或github或者微软账户

api-key登录时需要
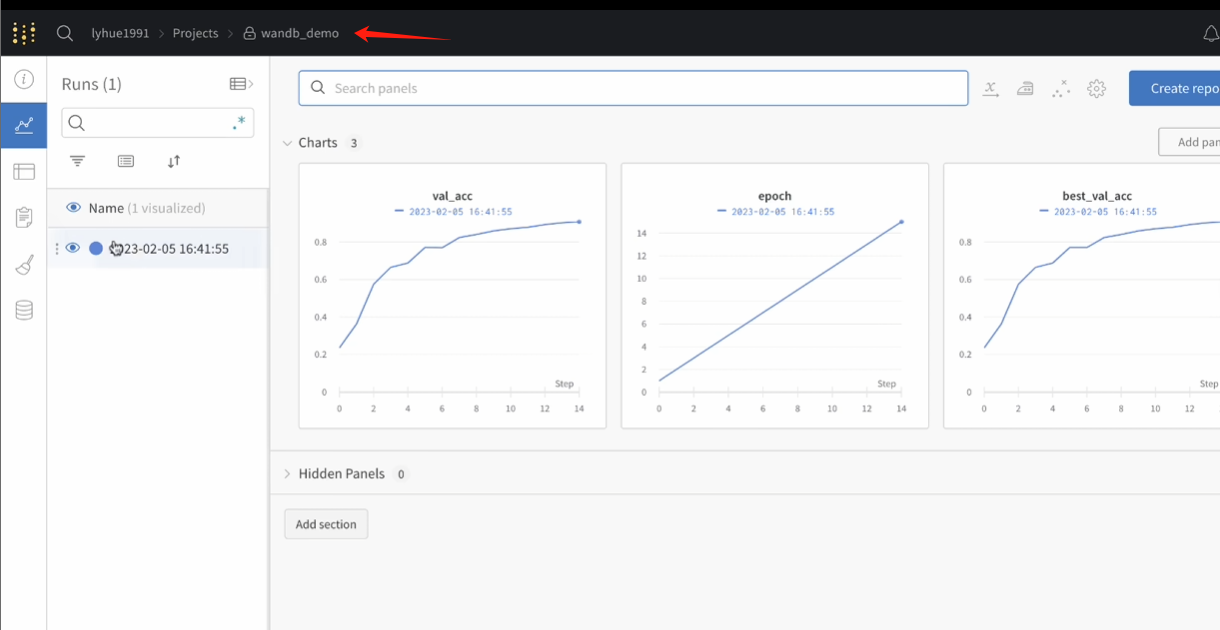
项目->实验(多次)里面很多指标
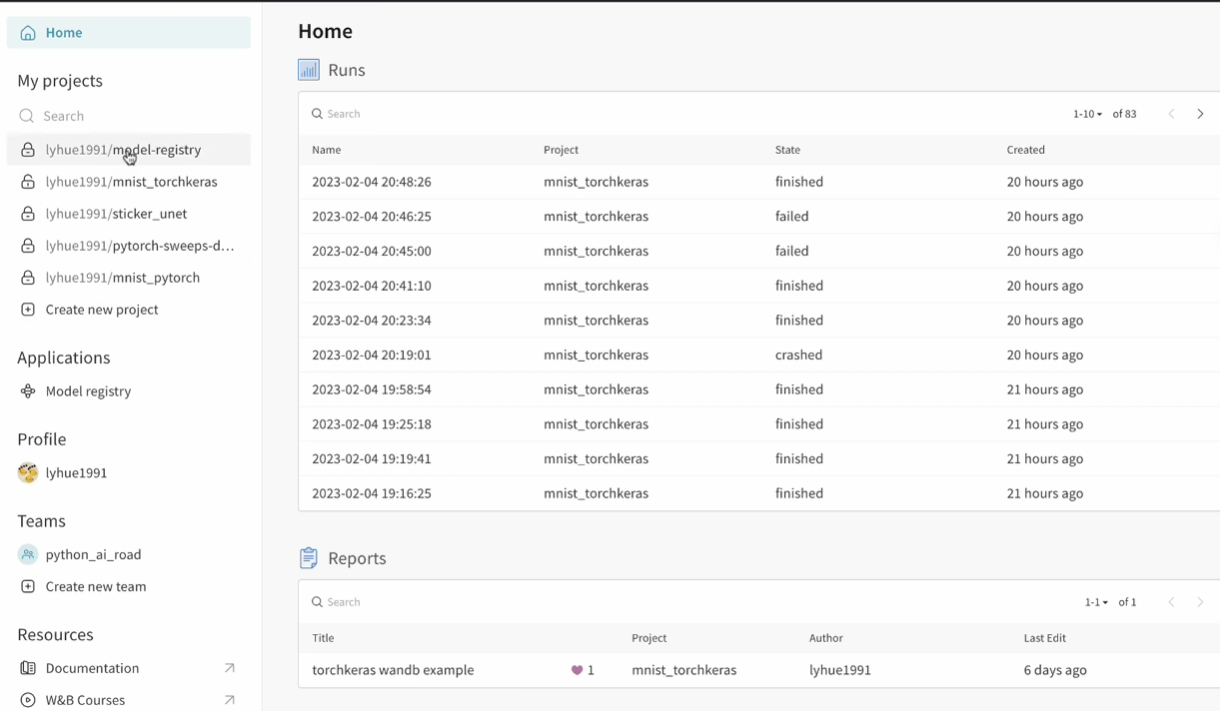
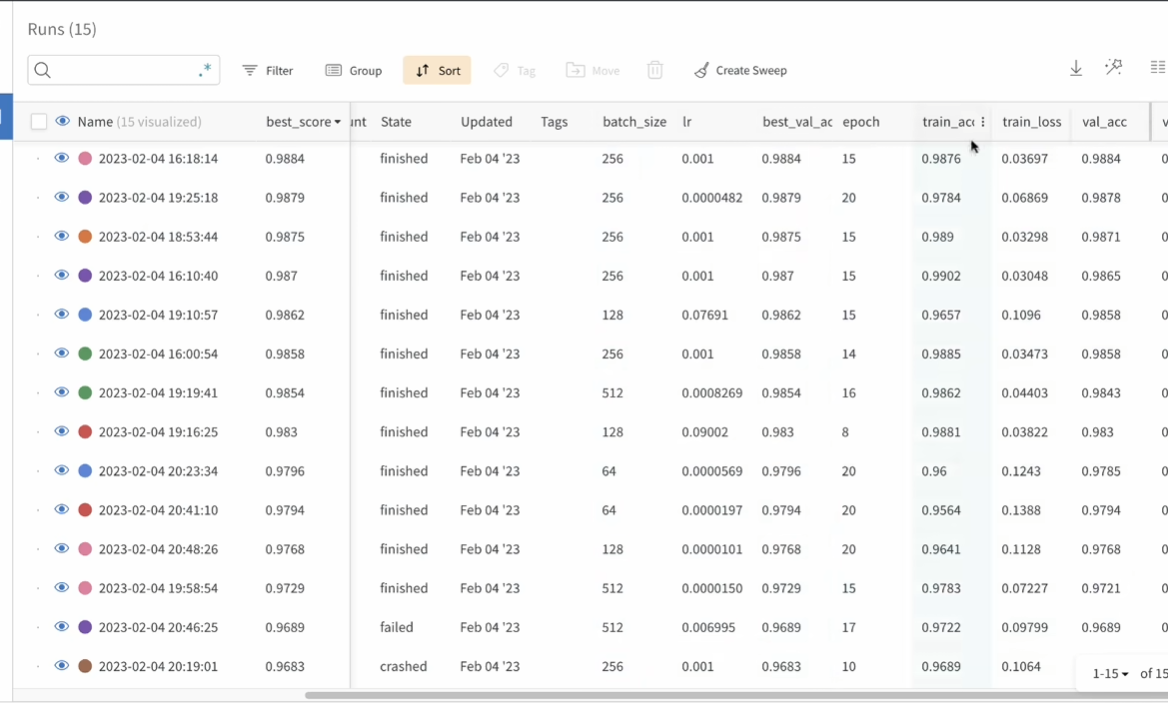
进入版本
2功能

2无需git,版本会和评估指标关联;
3交互式表格,可以放图像,音频;高校进行case分析;
4自动化模型调参;可以并行;(important

3实验跟踪

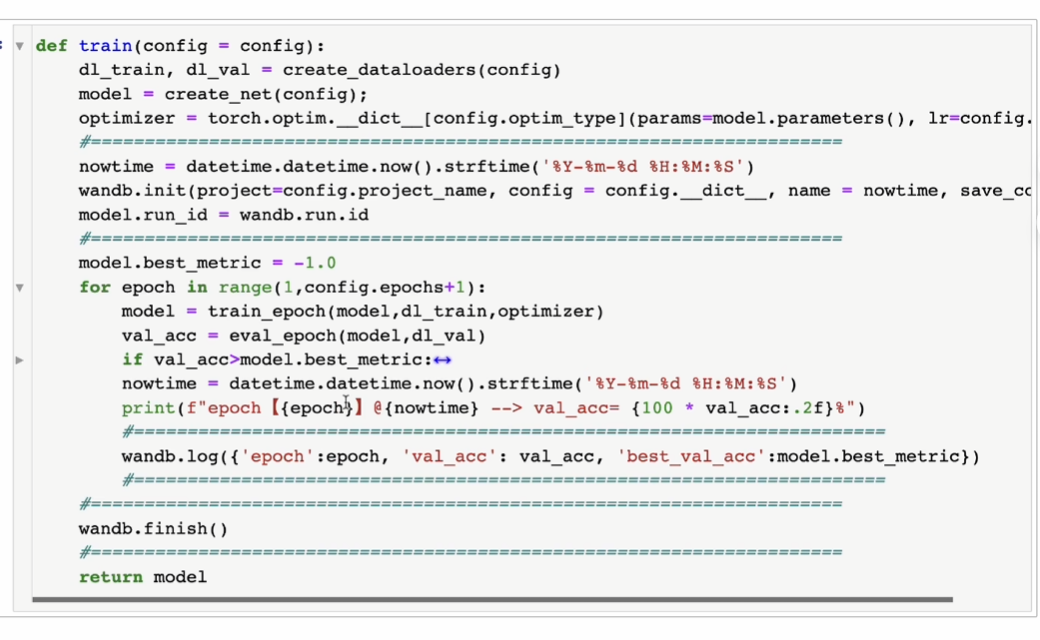
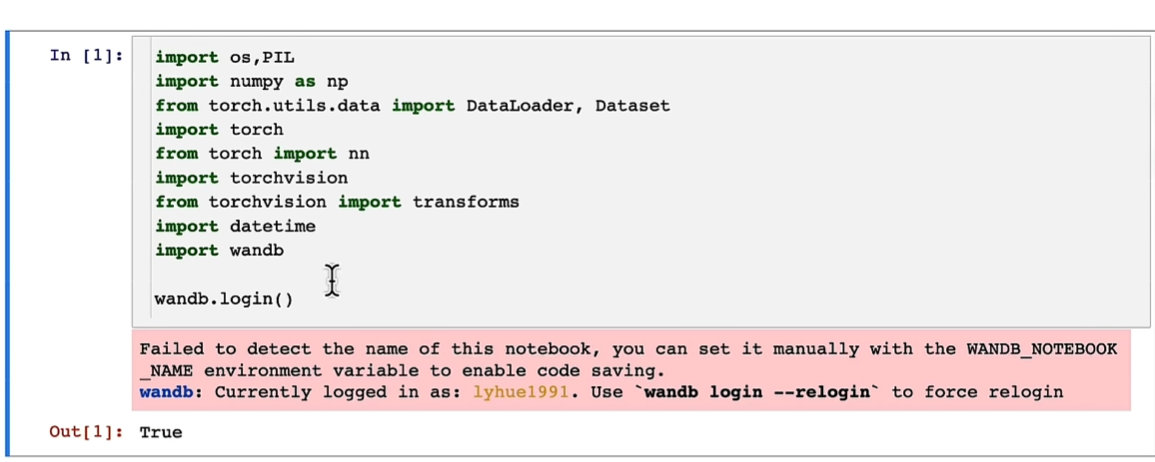
代码
wandb初始化
import os, PIL
import numpy as np
from torch.utils.data import DataLoader,Dataset
import torch
from torch import nn
import torchvision
from torchvision import transforms
import datetime
import wandb
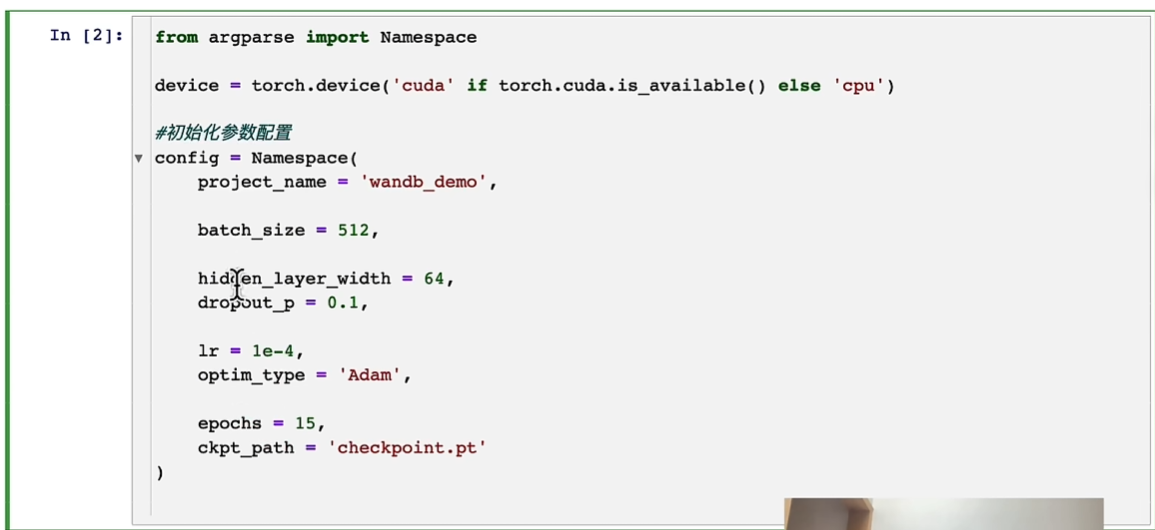
from argparse import Namespace
device =torch,deyice('cuda'if torch.cuda.is available()else 'cpu' )
config =Namespace(
project name= "wandb demo",
batch size=512,
hidden layer width=64,
dropout p=0.1,
lr = 1e-4,
optim type='Adam',
epochs =15,
ckpt path='checkpoint.pt')
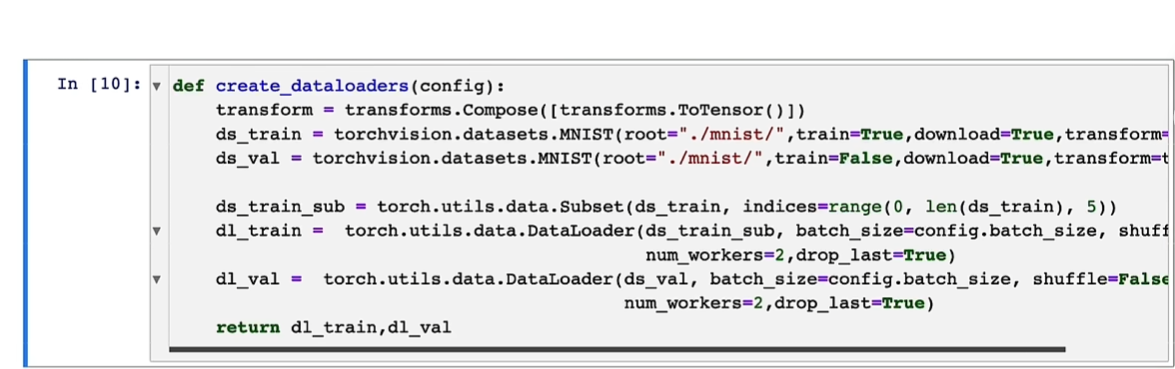
创建数据集;
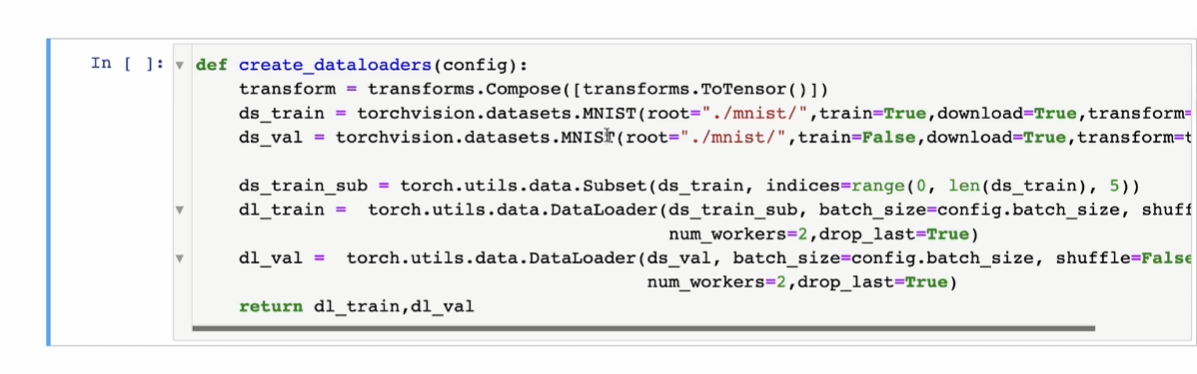
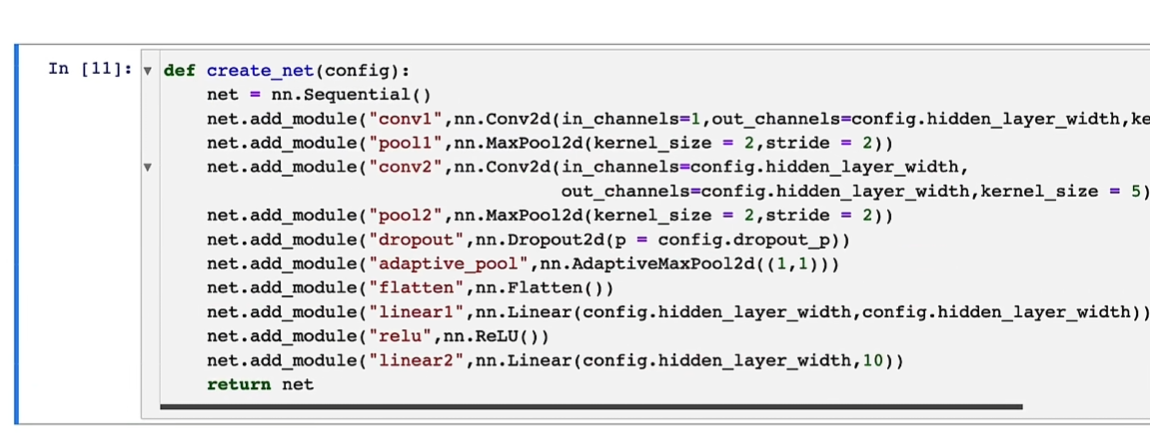
网络构建
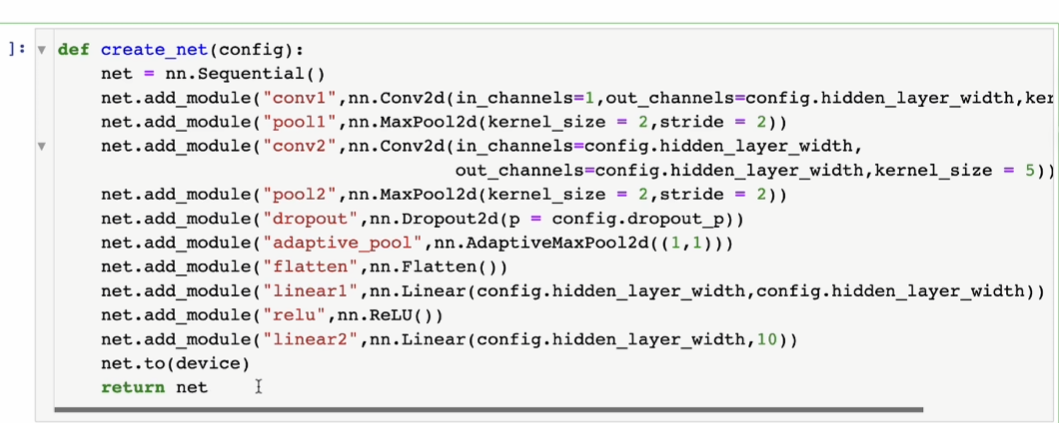
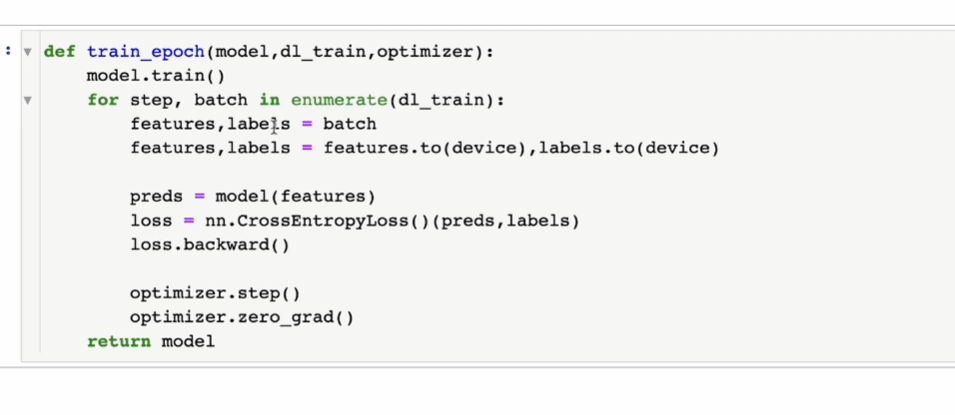
训练循环
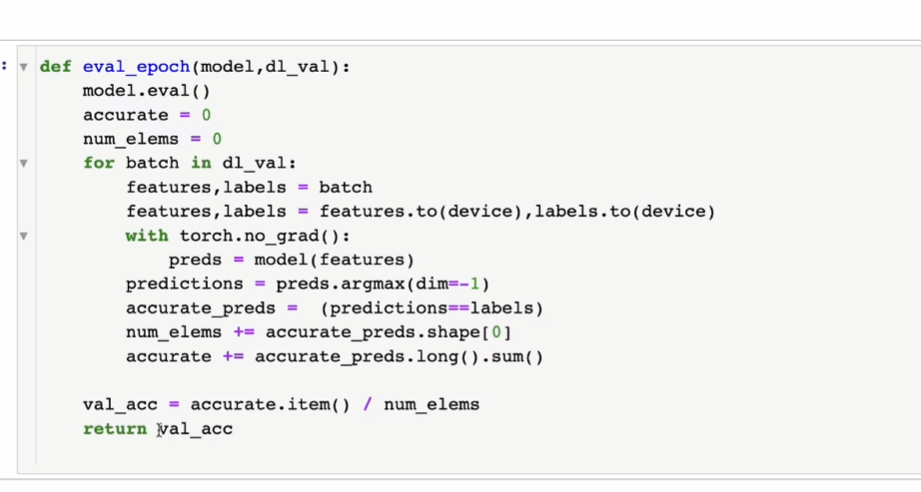
验证
主函数
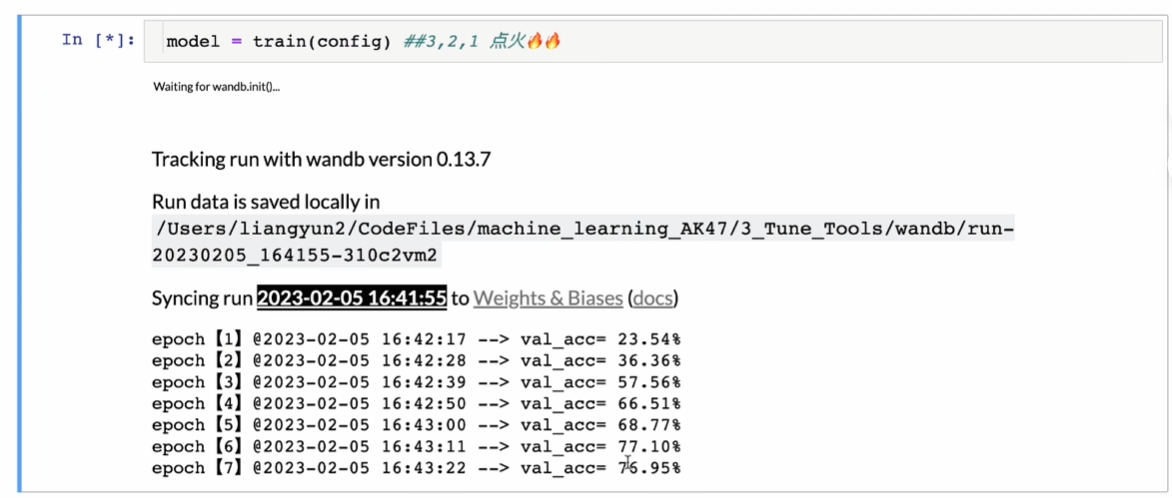
开始
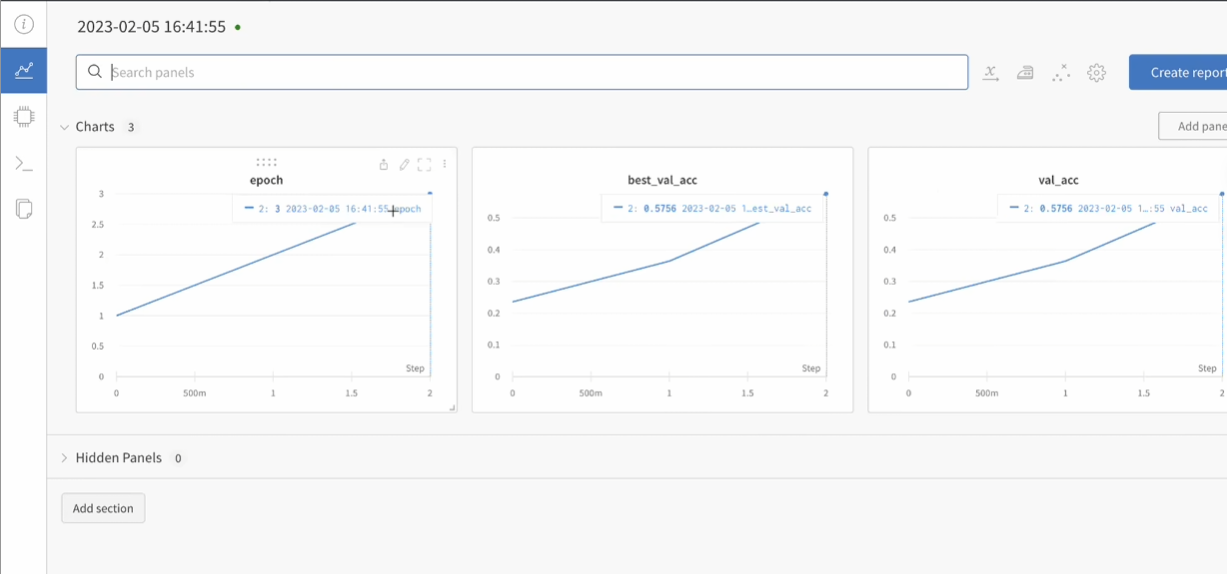
后台
定制能力很强
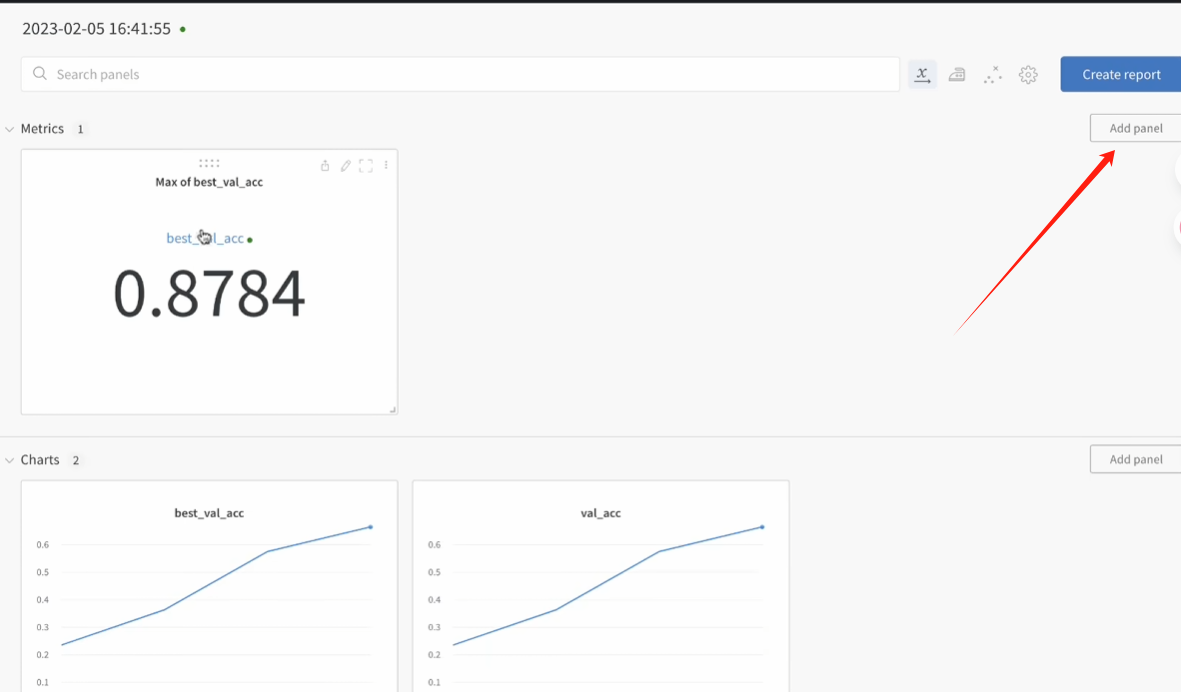
项目页面(同样可以定制化
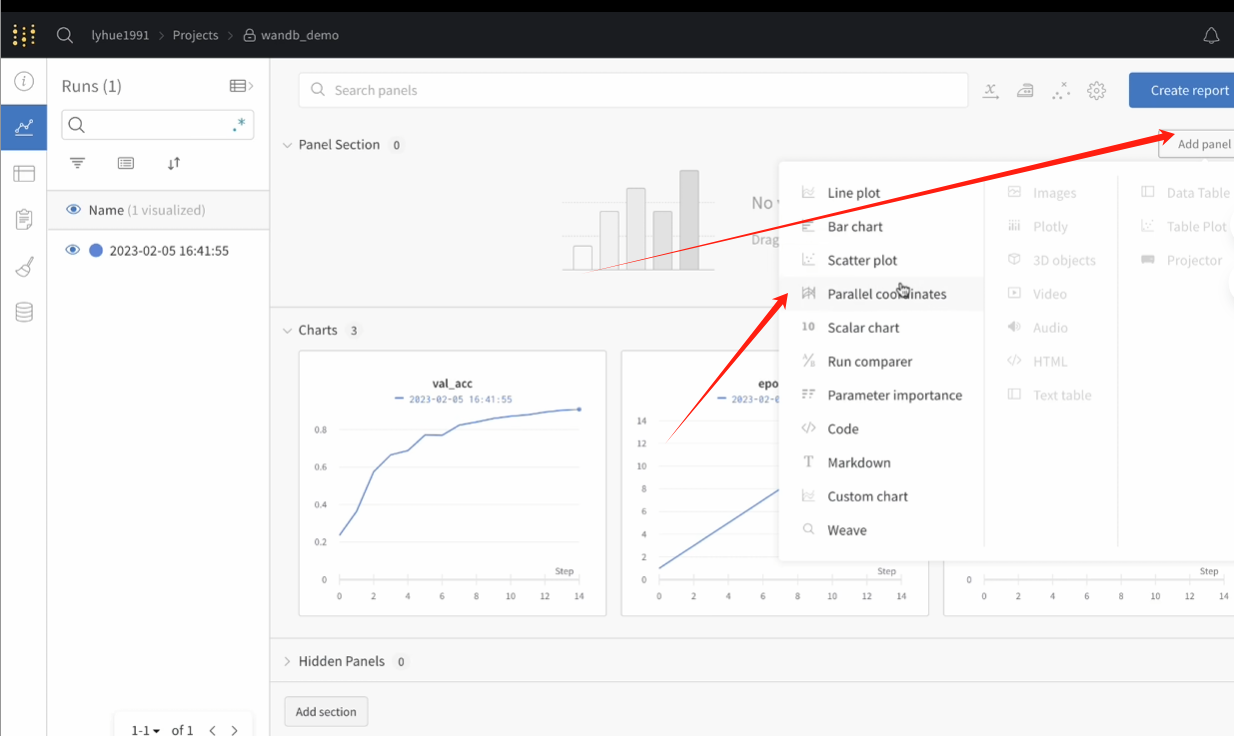
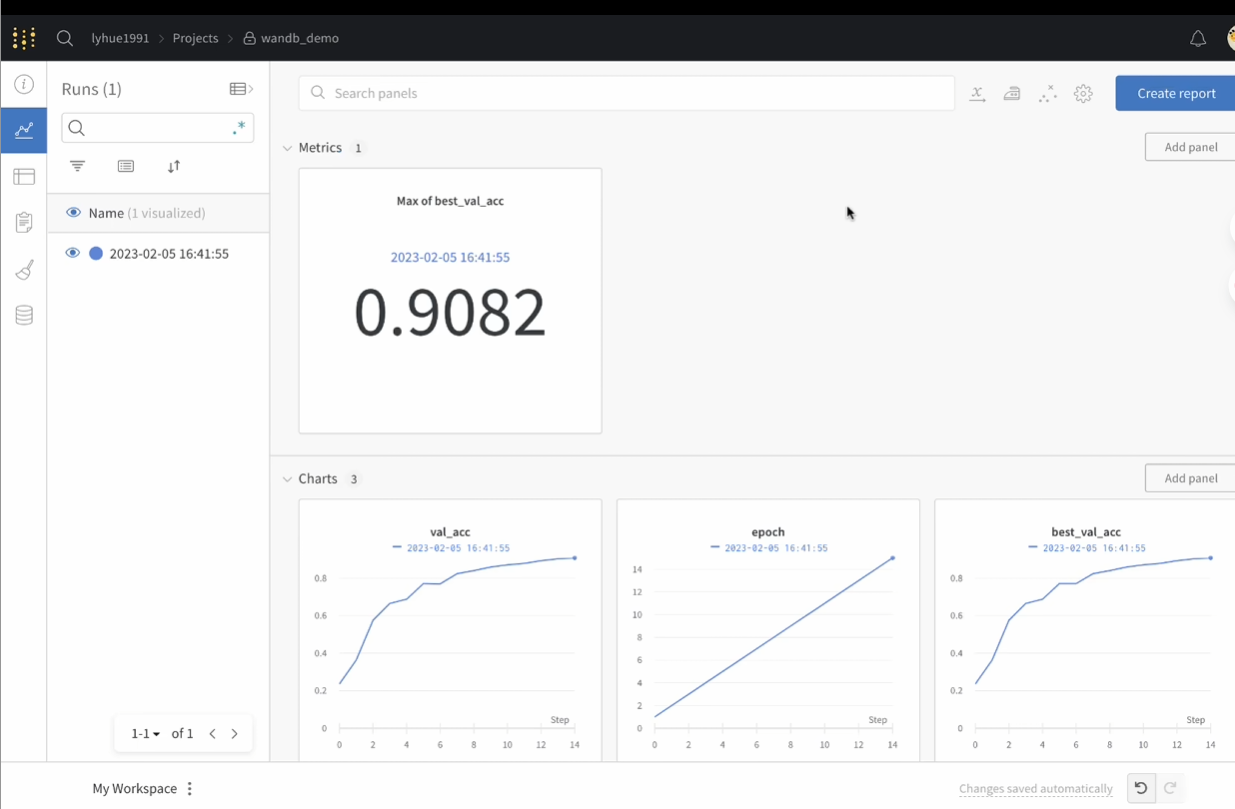
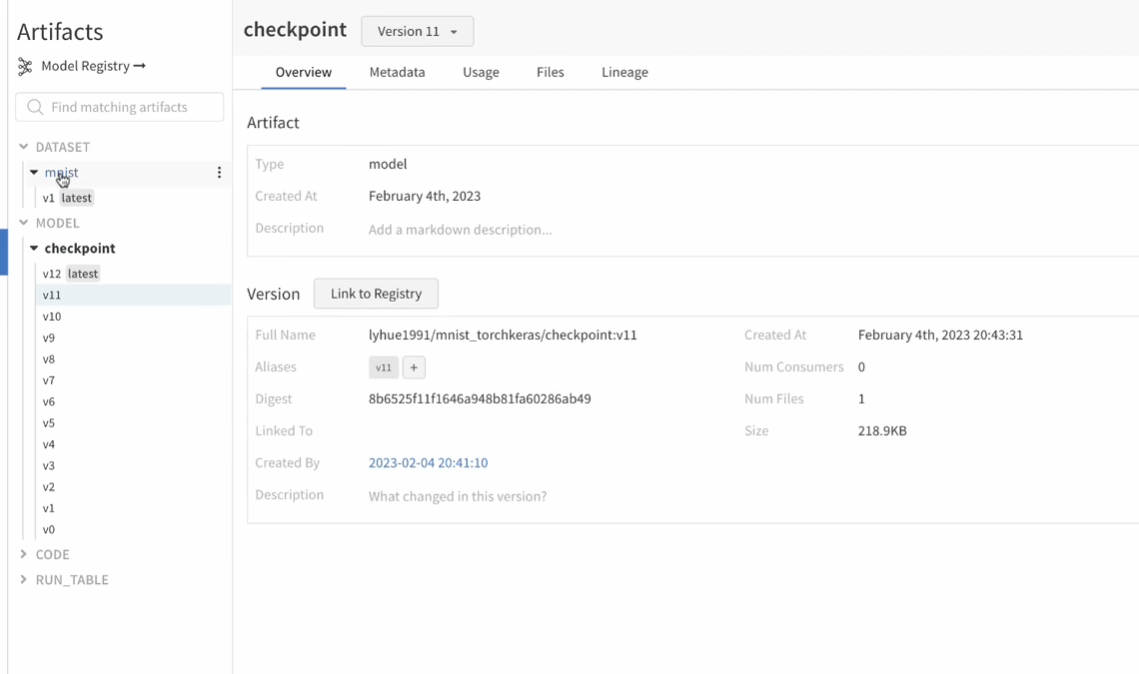
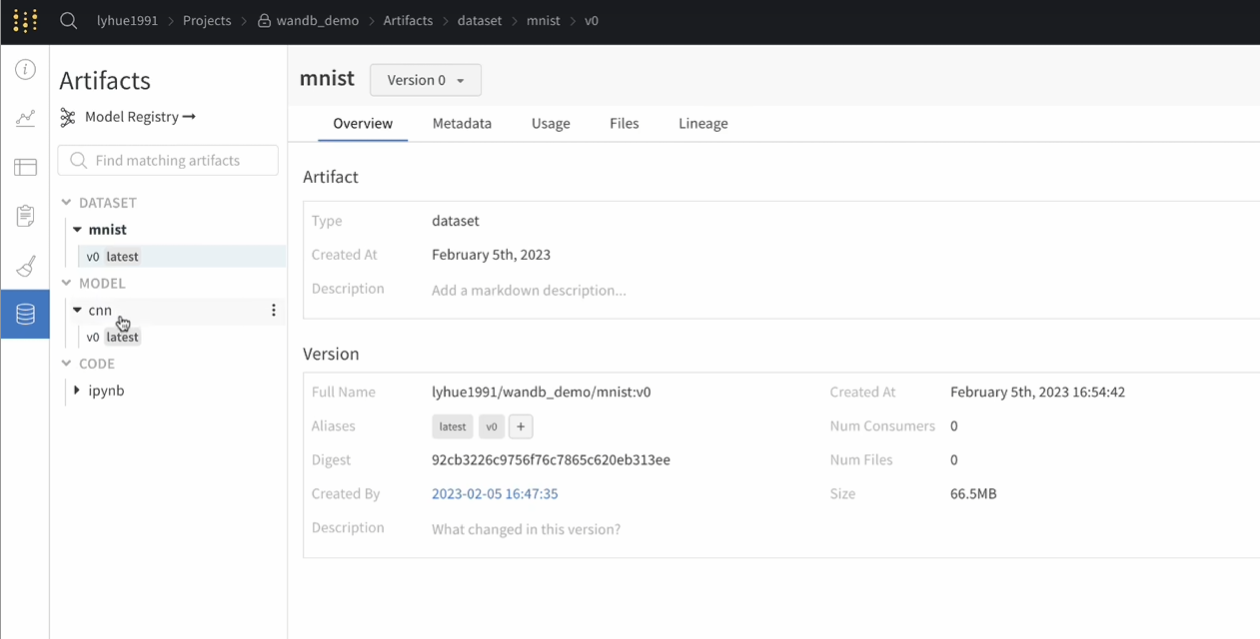
4版本关联

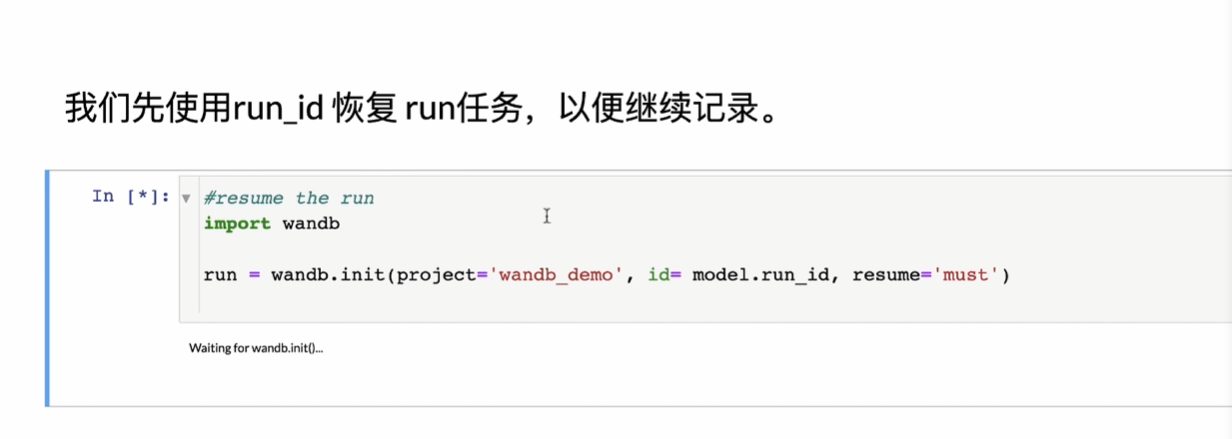
数据集

代码

模型

提交到服务器
后台(版本管理,很好找到最优指标对应版本
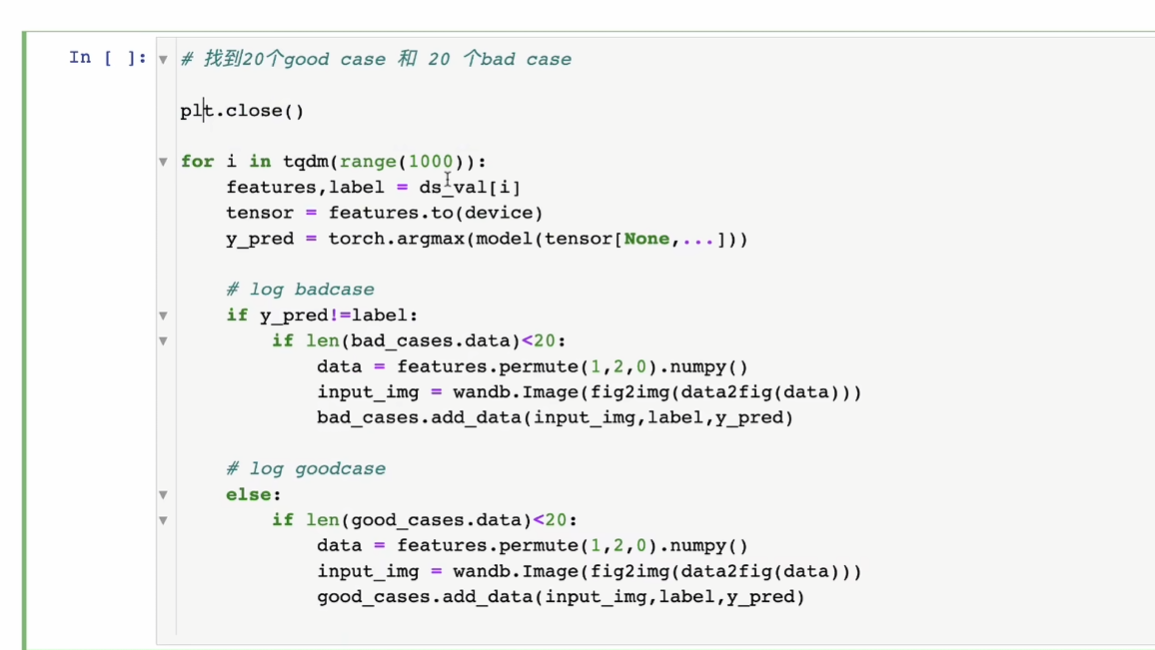
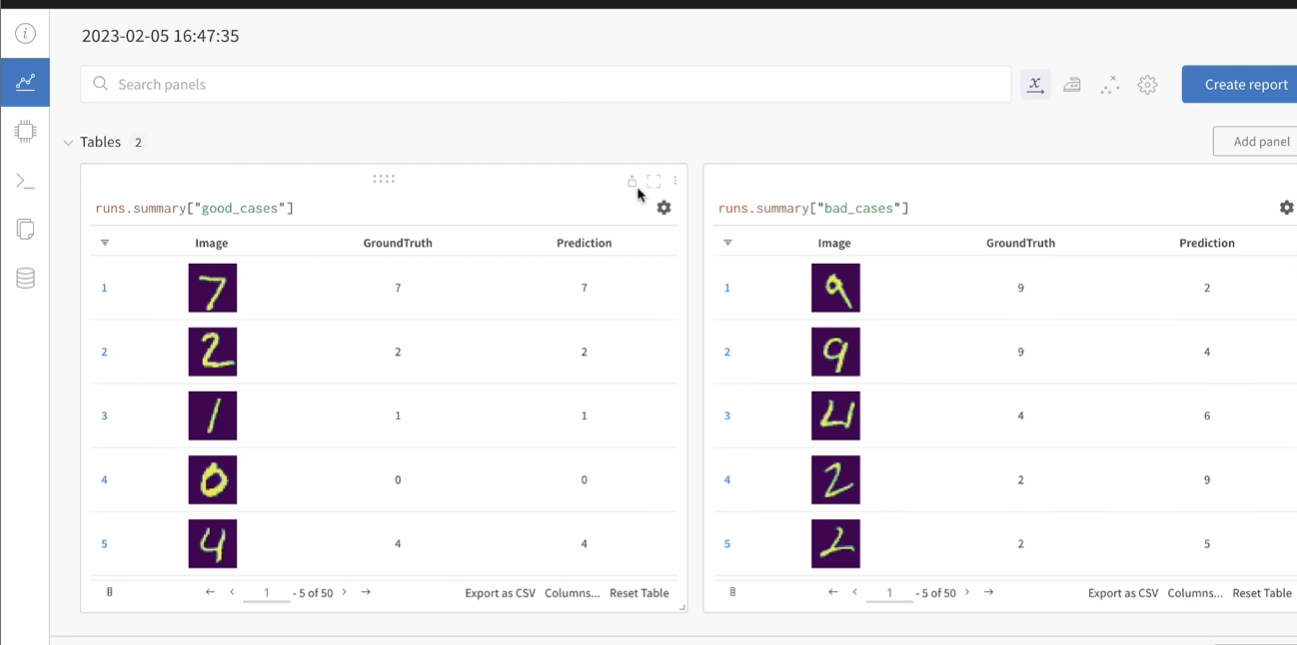
5Case分析
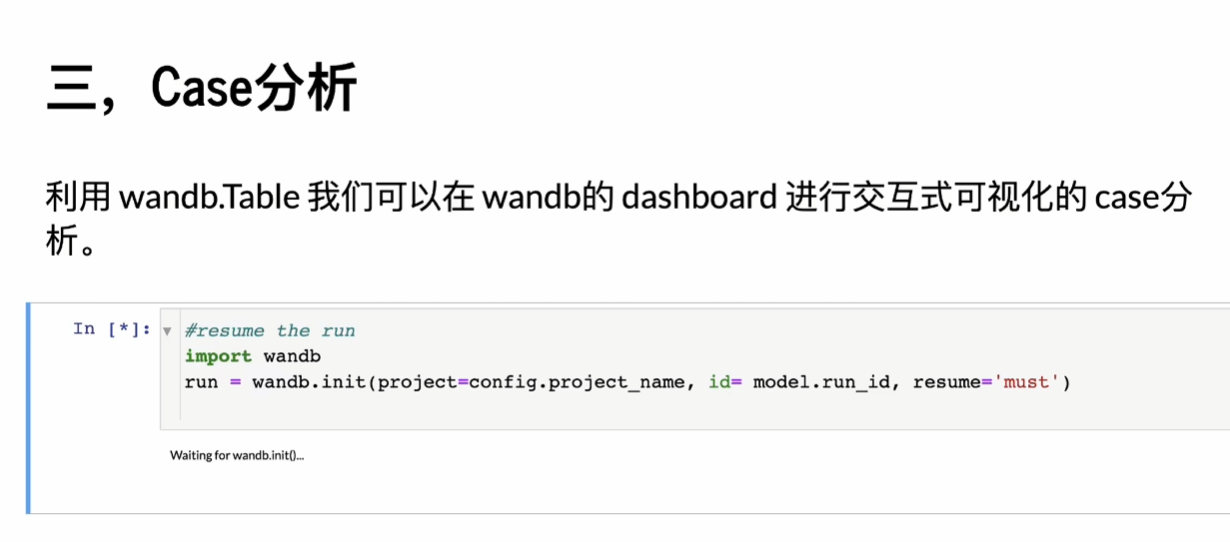
常规
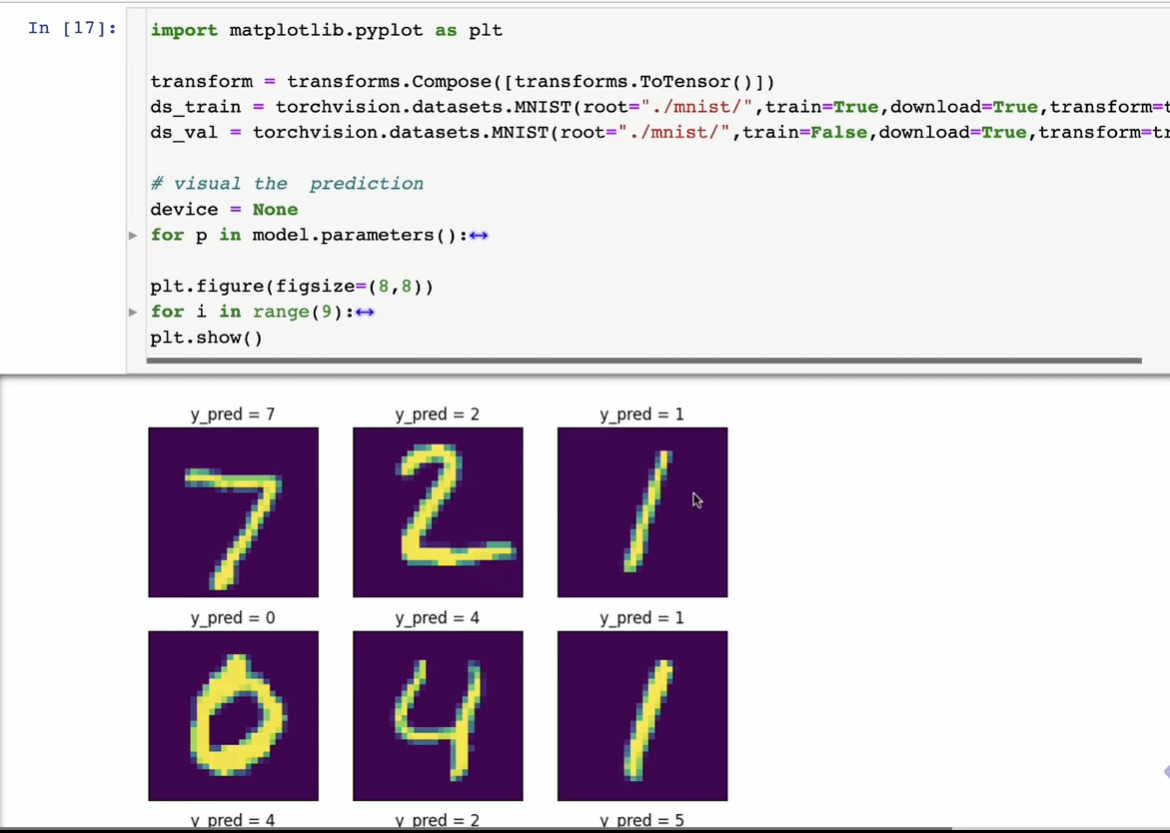
notebook可视化几百张就很麻烦
wandb.table很简单


6可视化自动化调参


分布式,多个机器可以对同一个任务做优化;sweep是服务器,每个机器分别启动任务,非常高效;
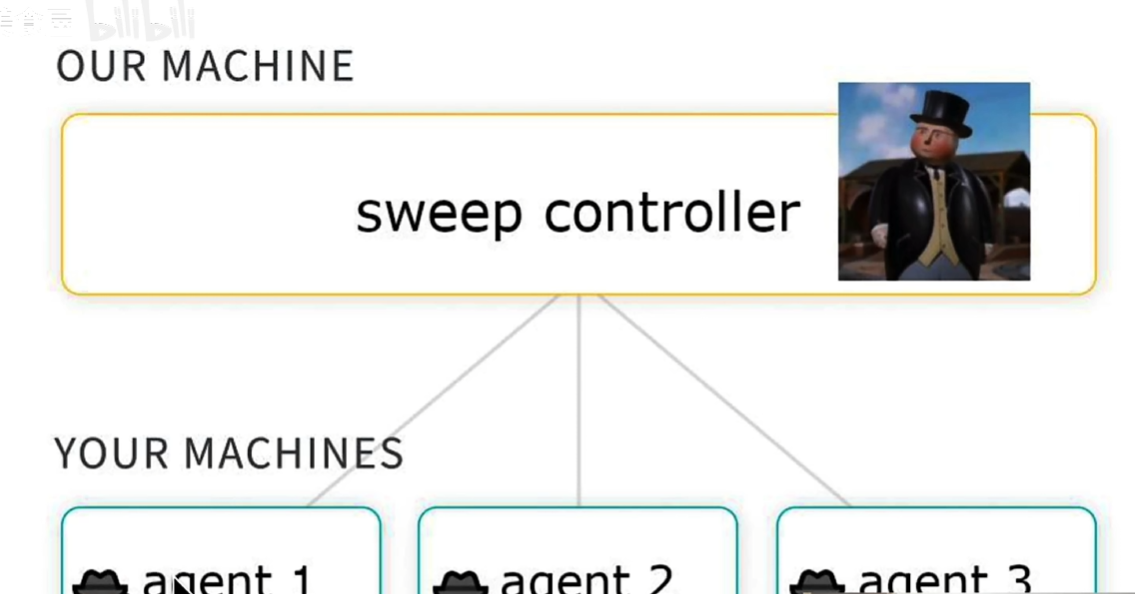
缺点(联网

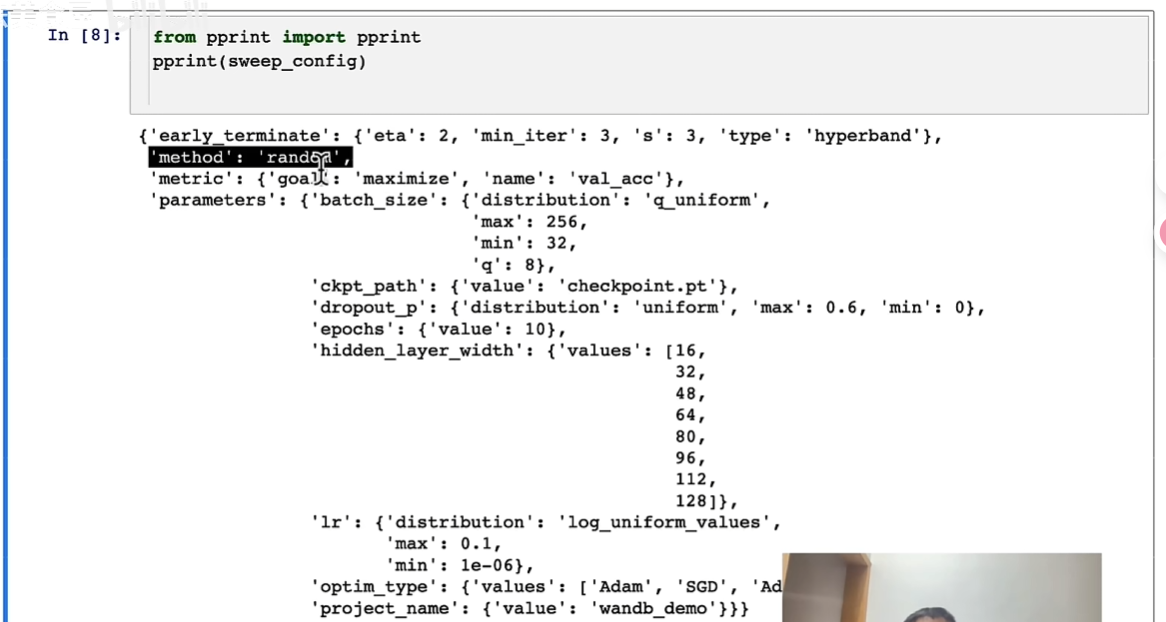
配置

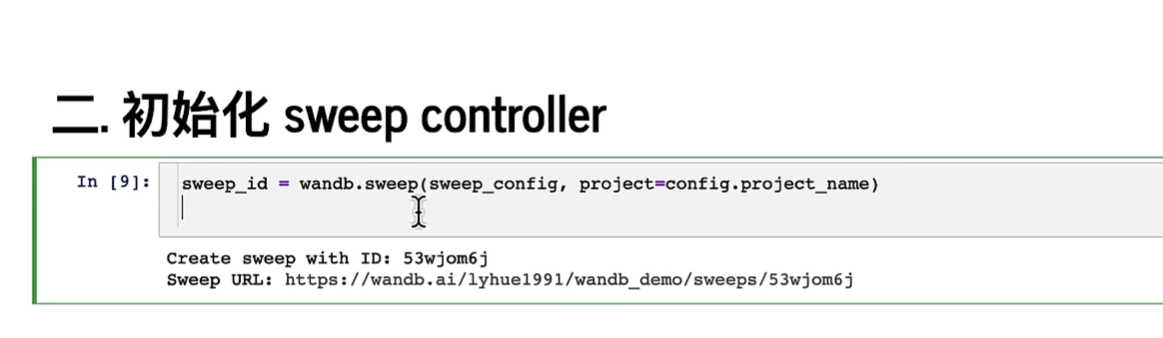
先初始化sweep也就是 控制台,然后启动分布式的agent;
eg:
登录
参数配置
后面传入解包即可
调优算法
流程:
选择调优算法
定义优化目标
定义超参数空间





初始化controller
agent启动
才开始

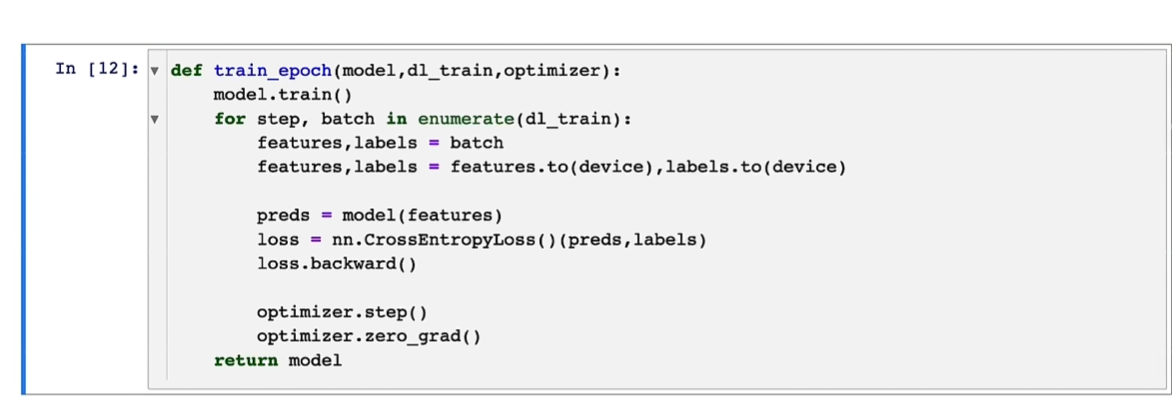
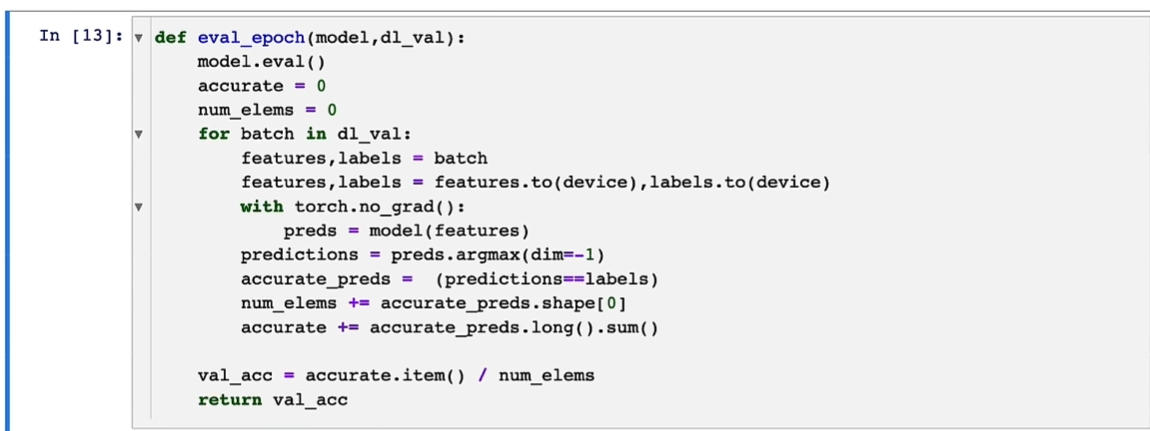
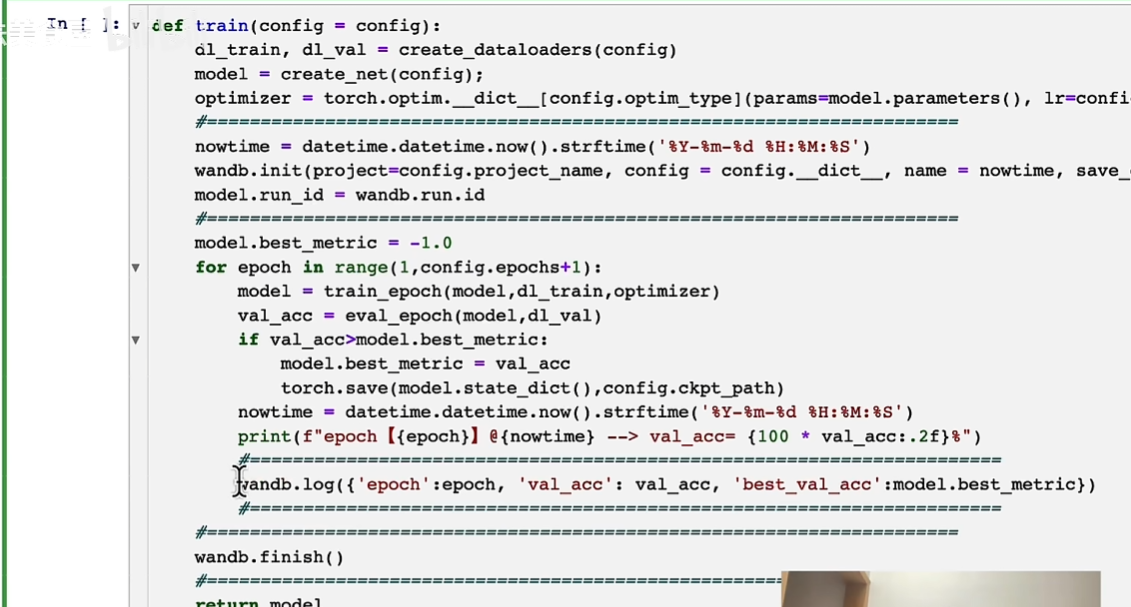
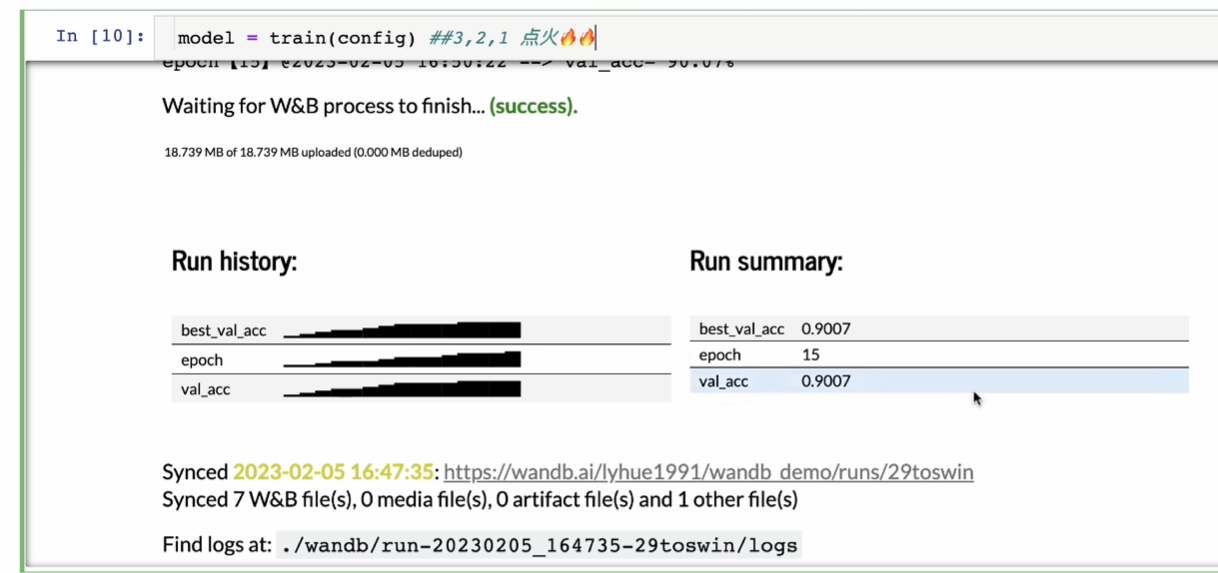
如果就是自己跑,直接model = train(config)
关键就在wandb.log像控制器报告
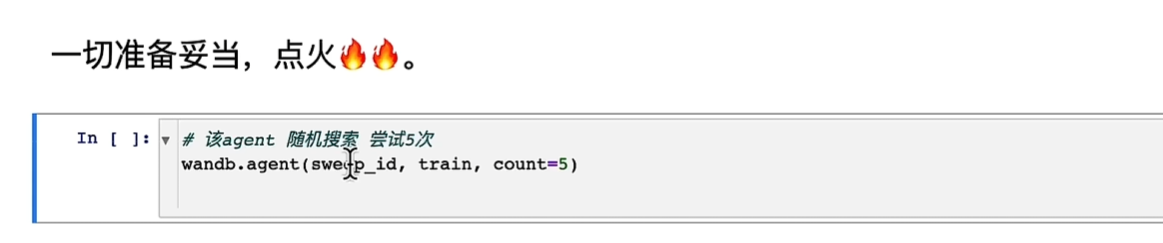
启动agent将任务尝试多次
sweep_id就是和控制器绑定;然后启动训练代码,尝试count次数;
后台监控(team->project->runs


还可以换电脑继续启动,只要sweep_id一样,都会显示;
优化器区别
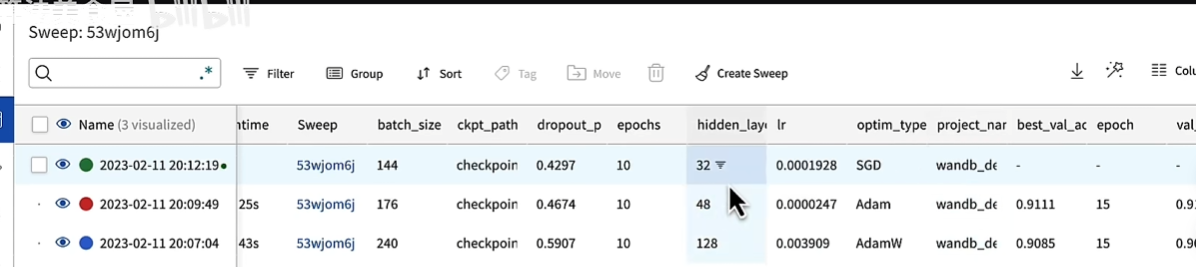
不同机器启动(分布式)

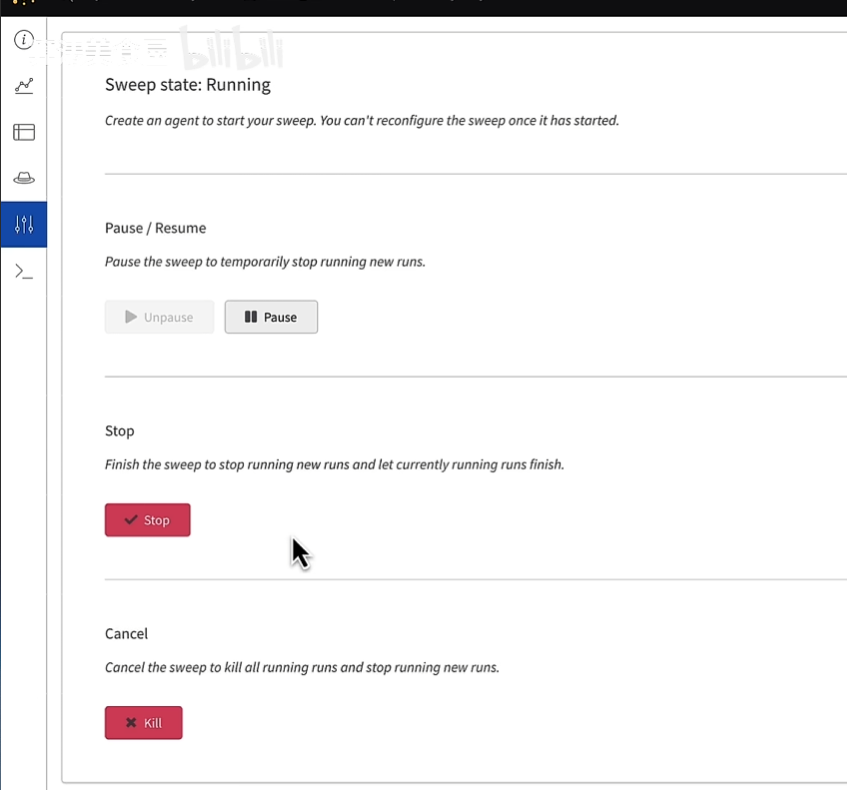
关闭

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 10
10 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)