【Datawhale之Happy-LLM】Github最火大模型原理与实践教程task03精华~我不相信看完你还不知道什么是Transformer的注意力机制
Task03-05:第二章 Transformer架构
本篇是task03: 2.1 注意力机制
(这是笔者自己的学习记录,仅供参考,原始学习链接,愿 LLM 越来越好❤)
Transformer架构很重要,需要分几天啃一啃。
在NLP中的核心基础任务文本表示,从用统计方法得到向量进入用神经网络方法。而这个神经网络NN(Neural Network)确实从CV计算机视觉发展来的。
所以我们应该先了解一下CV中神经网络的核心架构。
一、CV中NN的核心架构(共3种)
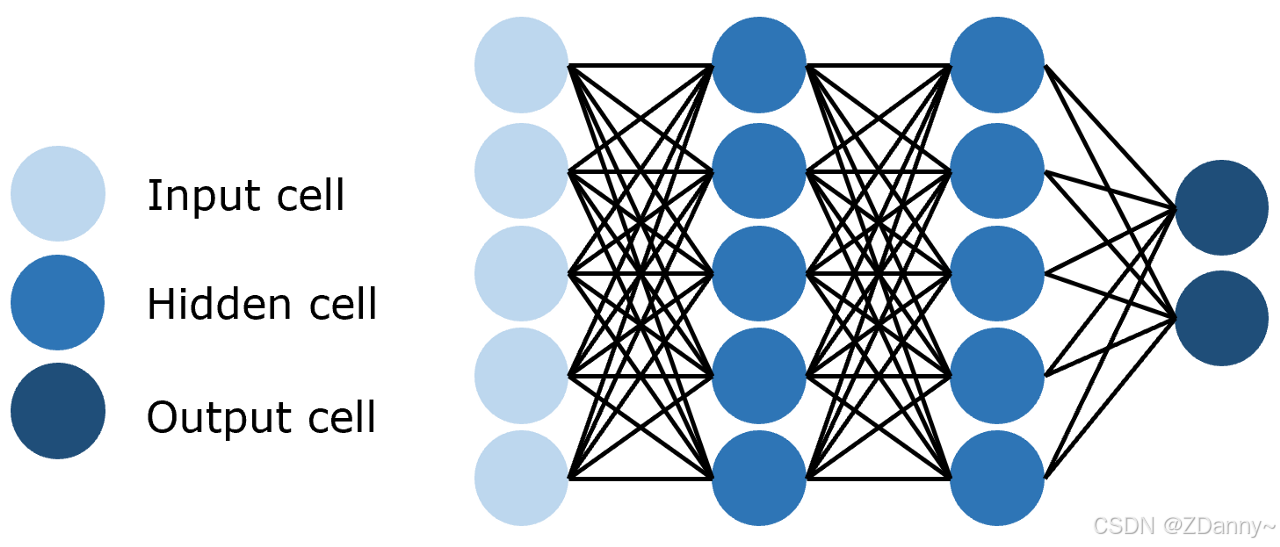
1、FNN(全连接 Feedforward NN):
-
连接方式:每一层的每个神经元都和上下的每个神经元连接。
-
参数量:全连接层的参数量 = 输入维度 × 输出维度,6层的网络,要计算6-1次相加
-
特点:简单但是参数量巨大
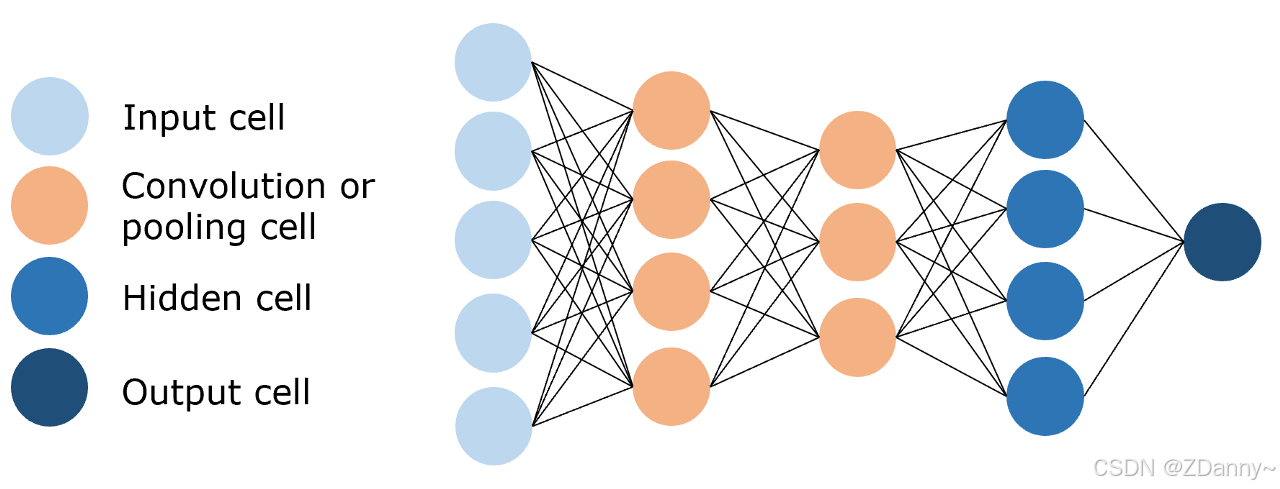
2、CNN(卷积 Convolutional NN):
- 连接方式:卷积核
- 参数量:3x3(卷积核)x 输入通道数 x 输出通道数
- 特点:参数量远小于FNN的,进行特征提取和学习
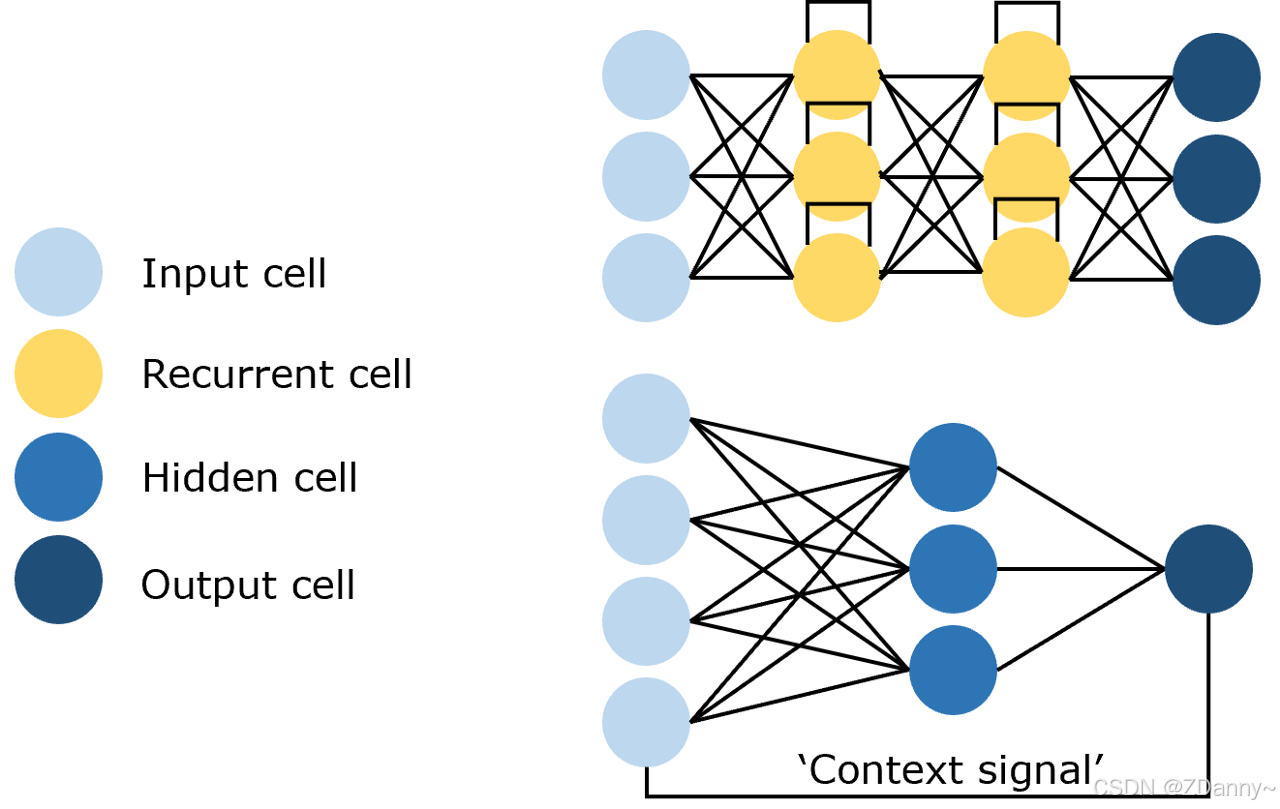
3、RNN(循环 Recycle NN):
- 有循环,输出作为输入
 |
 |
 |
二、NN在NLP的使用发展
1、RNN、LSTM架构
以前用的比较多(LSTM是RNN的衍生,如ELMo文本表示模型用的双向LSTM)NLP处理的是文本序列,用这种架构效果比其他2种好。
这种架构的优点?
能捕捉时序信息、适合序列生成
架构的问题?
2个
一个是串行不能并行计算,时间久。
另一个是RNN长距离关系很难捕捉,且要把整个序列读到内存,对序列长度有限制
2、Transformer架构
现在火起来的,架构中的核心是Attention注意力机制(这个机制常被融到RNN中,现在被单拎出来做成新的NN架构,并用在NLP作为LLM的核心架构了)也是深度学习里最核心的架构。
总结:架构核心是CV领域RNN的Attention机制,是神经网络、深度学习的架构,现用在NLP的LLM中
Attention注意力机制的思想是什么?
cv领域的思想是看图片只要关注重点部分(比如看海边画你不用每个细节注意到,你只要看天颜色美你就觉得画好看);
nlp领域的思想是语言只要关注重点token进行计算(人的语言理解也是,听别人说话可能你听些词就能自动脑补别人全部意思了)
三、注意力机制公式推导
attention的核心计算公式是什么?
attention(Q,K,V)=softmax(QKTdk)V. attention(Q,K,V) = softmax( \frac{QK^T}{\sqrt{d _k}})V. attention(Q,K,V)=softmax(dkQKT)V.
1、核心变量
Q(query查询值)、K(key键)、V(value值)
【大写为矩阵,小写为向量。tt = tokens target ,ts = tokens source】
- q词向量 =(1 x dk)
- Q矩阵 = (目标序列token数 ntt x dk)
- K矩阵 = (源序列token数 nts x dk)
- V矩阵 = (源序列token数 nts x dv)
备注:K和V都来自同一个输入序列,行数是一样的。k和v都来自同一个token,但是数值却不同。(因为token进行embedding后会有一个x向量,会分别乘不同的权重矩阵进行线性变换。k
= xWk,v=xWv。)
(多头注意力中,当dmodel=512,head=8时)
dk=dv=dmodelh=5128=64 d_k = d_v= \frac{d_{model} }{h} = \frac{512}{8} = 64dk=dv=hdmodel=8512=64
(自注意力中,QKV来自同一个序列,每个token对应一行)
ntt=nts n_{tt} = n_{ts}ntt=nts
2、公式拆解
拆解式子1——得到权重:
单个token(“fruit”)和序列每个token(“apple”、“banana”,“car”)的相似度【点积】
x=qKT 维度(1×nts) x = qK^{\mathsf{T}} ~~维度(1 \times n_{ts} ) x=qKT 维度(1×nts)维度变化如下:q∈R1×dk,K∈Rnts×dk q \in \mathbb{R}^{1 \times d_k}, \quad K \in \mathbb{R}^{n_{ts} \times d_k} q∈R1×dk,K∈Rnts×dk(1×dk)⋅(ntt×dk)T=(1×dk)⋅(dk×nts)=(1×nts) (1 \times d_k) \cdot (n_{tt} \times d_k)^{\mathsf{T}} = (1 \times d_k) \cdot (d_k \times n_{ts}) = (1 \times n_{ts})(1×dk)⋅(ntt×dk)T=(1×dk)⋅(dk×nts)=(1×nts)结果值含义如下:
qfruit=[1.00.5−0.30.8], q_{fruit} = \begin{bmatrix} 1.0 & 0.5 & -0.3 & 0.8 \end{bmatrix} ,\quadqfruit=[1.00.5−0.30.8],K=[kapple:0.90.4−0.20.7kbanana:0.80.6−0.1−0.6kcar:−0.50.20.9−0.4] K = \begin{bmatrix} k_{apple}:0.9 & 0.4 & -0.2 & 0.7 \\ k_{banana}:0.8 & 0.6 & -0.1 & -0.6 \\ k_{car}:-0.5 & 0.2 & 0.9 & -0.4 \end{bmatrix} K=
kapple:0.9kbanana:0.8kcar:−0.50.40.60.2−0.2−0.10.90.7−0.6−0.4
x=[1.721.61−0.99]. x = \begin{bmatrix} 1.72 & 1.61 & -0.99 \end{bmatrix} .\quadx=[1.721.61−0.99].q和K矩阵中每个向量进行点积, xxx向量的每个数值对应fruit和序列中每个token的相关性=注意力分数=权重
同理,
X=QKT 维度(ntt×nts) X = QK^T ~~维度(n_{tt} \times n_{ts} )X=QKT 维度(ntt×nts)
拆解式子2——得到对其他词的关注度:
softmax 将 xxx 或者说XXX转成权重值加起来等于1(统一一下)。
(当dkd_kdk比较大时,这里需要对xxx进行一个放缩,即除以dk\sqrt{d_k}dk再用softmaxsoftmaxsoftmax)
目的:否则经过函数后不同值得差异很大,容易影响梯度稳定性
softmax(x)i=exiZ=exi∑j=0nts−1exjsoftmax(x)_{i} = \frac{e^{x_{i}}}{Z}= \frac{e^{x_{i}}}{\sum_{j=0}^{n_{ts}-1}{e^{x_{j}}}}softmax(x)i=Zexi=∑j=0nts−1exjexi结果值如下:
(不放缩时)x=[1.721.61−0.99]. x = \begin{bmatrix} 1.72 & 1.61 & -0.99 \end{bmatrix} .\quadx=[1.721.61−0.99].e1.72≈5.58,e1.61≈5.00,e−0.99≈0.37 e^{1.72} \approx 5.58, \quad e^{1.61} \approx 5.00, \quad e^{-0.99} \approx 0.37 e1.72≈5.58,e1.61≈5.00,e−0.99≈0.37Z=5.58+5.00+0.37=10.95Z=5.58+5.00+0.37=10.95Z=5.58+5.00+0.37=10.95xscaled=[0.5110.950.4610.950.0310.95]=[0.510.460.03]. x_{scaled} =\begin{bmatrix} \frac{0.51}{10.95} & \frac{0.46}{10.95} & \frac{0.03}{10.95} \end{bmatrix}= \begin{bmatrix} 0.51 & 0.46 & 0.03 \end{bmatrix} .\quadxscaled=[10.950.5110.950.4610.950.03]=[0.510.460.03].
(放缩时,假设dkd_kdk=4很大,这里是除以2)
x=[0.860.805−0.495]. x = \begin{bmatrix} 0.86 & 0.805 & -0.495 \end{bmatrix} .\quadx=[0.860.805−0.495].xscaled=[2.3645.2112.2375.2110.6105.211]=[0.4540.4290.117]. x_{scaled} =\begin{bmatrix} \frac{2.364}{5.211} & \frac{2.237}{5.211} & \frac{0.610}{5.211} \end{bmatrix}= \begin{bmatrix} 0.454 & 0.429 & 0.117 \end{bmatrix} .\quadxscaled=[5.2112.3645.2112.2375.2110.610]=[0.4540.4290.117].fruit 对 apple 的关注度45.4%,对 banana 的关注度42.9%,对 car 的关注度11.7%【这是fruit对别人的】
拆解式子3——得到q本身的表示:
K和V可以一样,因为来自同一个序列。具体是否相同和第一步embedding的线性变换的权重矩阵WkW^kWk、WvW^vWv有关。
权重和V矩阵的各个向量【加权求和】
attention=xscaled⋅Vattention= x_{scaled}\cdot Vattention=xscaled⋅V
(这里假设K、V不一样)V=[vapple:1.20.30.50.9vbanana:1.00.40.60.8vcar:0.20.91.10.1] V = \begin{bmatrix} v_{apple}:1.2 & 0.3 & 0.5 & 0.9 \\ v_{banana}:1.0 & 0.4 & 0.6 & 0.8 \\ v_{car}:0.2 & 0.9 & 1.1 & 0.1 \end{bmatrix} V=
vapple:1.2vbanana:1.0vcar:0.20.30.40.90.50.61.10.90.80.1
xscaled=[0.4540.4290.117]. x_{scaled} = \begin{bmatrix} 0.454 & 0.429 & 0.117 \end{bmatrix} .\quadxscaled=[0.4540.4290.117].
结果值如下:
attentionfruit=[0.99720.41310.61310.7635] attention_{fruit} = \begin{bmatrix} 0.9972 & 0.4131 & 0.6131&0.7635 \end{bmatrix}attentionfruit=[0.99720.41310.61310.7635]每一维都是fruit在不同语义方面特征的示意程度【这是fruit自己的性质,用来描述fruit的】,可以观察到结果和apple、banana的kv向量各维度数值都比较接近。
你可以把 Attention输出向量想象成:
“我看了上下文中所有相关的信息(apple、banana、car),根据它们和‘fruit’的关系,我总结出fruit这四个方面的重点信息。”
3、代码实现
'''注意力计算函数'''
def attention(query, key, value, dropout=None):
'''
args:
query: 查询值矩阵
key: 键值矩阵
value: 真值矩阵
'''
# 获取键向量的维度,键向量的维度和值向量的维度相同
d_k = query.size(-1)
# 计算Q与K的内积并除以根号dk
# transpose——相当于转置
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
# Softmax
p_attn = scores.softmax(dim=-1)
if dropout is not None:
p_attn = dropout(p_attn)
# 采样
# 根据计算结果对value进行加权求和
return torch.matmul(p_attn, value), p_attn
四、注意力机制的使用及衍生
1、注意力 Attention:
在 Decoder 中,Q来自 Decoder 的输入,KV来自 Encoder 的输出。目的是拟合编码信息和历史信息之间的关系,综合预测未来。
2、自注意力 Self-Attention:
在 Encoder 中,采用自注意力机制 Self-Attention(Attention变种),QKV是同一个输入,分别经过3个参数矩阵得到。目的是拟合输入语句中每一个token对其他所有token的依赖关系。
3、 掩码自注意力 Mask Self-Attention
用掩码遮蔽某些位置的token,不让模型学习的时候学未来的。类似n-gram,不过他是串行,达咩。所以一次性输入下面的这个就可以并行计算,得到语言模型。掩码矩阵就是和文本序列token数等长的上三角矩阵。
mask长什么样
(当 n = 4时,代码的-inf就是负无穷)
Mask=[0−∞−∞−∞00−∞−∞000−∞0000] Mask = \begin{bmatrix} 0 & -\infty & -\infty & -\infty \\ 0 & 0 & -\infty & -\infty \\ 0 & 0 & 0 & -\infty \\ 0 & 0 & 0 & 0 \end{bmatrix} Mask= 0000−∞000−∞−∞00−∞−∞−∞0

代码实现mask矩阵
# 创建一个上三角矩阵,用于遮蔽未来信息。
# 先通过 full 函数创建一个 1 * seq_len * seq_len 的矩阵
mask = torch.full((1, args.max_seq_len, args.max_seq_len), float("-inf"))
# triu 函数的功能是创建一个上三角矩阵
mask = torch.triu(mask, diagonal=1)
mask怎么用?
是在得出注意力分数之后,把X和Mask相加,-inf就会覆盖X的原值,经过softmax后就变成0,注意力遮蔽了。
# 此处的 scores 为计算得到的注意力分数,mask 为上文生成的掩码矩阵
scores = scores + mask[:, :seqlen, :seqlen]
scores = F.softmax(scores.float(), dim=-1).type_as(xq)
什么是张量 Tensor?
矩阵:
A=[1−2304−1]∈R2×3 A = \begin{bmatrix} 1 & -2 & 3 \\ 0 & 4 & -1 \end{bmatrix}\in \mathbb{R}^{2 \times 3} A=[10−243−1]∈R2×3三维张量:T={[123456],[789101112]}∈R2×2×3 \mathcal{T} = \left\{ \begin{bmatrix} 1 & 2 & 3 \\ 4 & 5 & 6 \end{bmatrix}, \begin{bmatrix} 7 & 8 & 9 \\ 10 & 11 & 12 \end{bmatrix} \right\} \in \mathbb{R}^{2 \times 2 \times 3} T={[142536],[710811912]}∈R2×2×3四维张量:T={样本 1: [通道 1: 4×5通道 2: 4×5通道 3: 4×5],样本 2: [通道 1: 4×5通道 2: 4×5通道 3: 4×5]}∈R2×3×4×5 \mathcal{T} = \left\{ \begin{array}{c} \text{样本 1: } \left[ \begin{array}{c} \text{通道 1: } 4 \times 5 \\ \text{通道 2: } 4 \times 5 \\ \text{通道 3: } 4 \times 5 \end{array} \right], \\[1ex] \text{样本 2: } \left[ \begin{array}{c} \text{通道 1: } 4 \times 5 \\ \text{通道 2: } 4 \times 5 \\ \text{通道 3: } 4 \times 5 \end{array} \right] \end{array} \right\} \in \mathbb{R}^{2 \times 3 \times 4 \times 5} T=⎩
⎨
⎧样本 1:
通道 1: 4×5通道 2: 4×5通道 3: 4×5
,样本 2:
通道 1: 4×5通道 2: 4×5通道 3: 4×5
⎭
⎬
⎫∈R2×3×4×5
维度和形状的区别?
维度是数值,1、2、3维;形状是元组(2 x 3)
什么是广播机制 Broadcasting?
就是在张量(三维及以上数组)运算的时候,能像史莱姆一样自动拓展维度成目标张量的形状。
掩码矩阵的shape为: (1,seq_len,seq_len)(1,seq\_len,seq\_len)(1,seq_len,seq_len)注意力分数的shape为:(batch_size,n_heads,seq_len,seq_len)(batch\_size,n\_heads,seq\_len,seq\_len)(batch_size,n_heads,seq_len,seq_len)广播后的掩码矩阵的shape为:(batch_size,n_heads,seq_len,seq_len)(batch\_size,n\_heads,seq\_len,seq\_len)(batch_size,n_heads,seq_len,seq_len)
4、多头注意力:
就是对同一个序列进行多次注意力计算,再拼接结果,每次可以学到不同的关系,从而让对token的表示更加深入。
n个头就是计算n次的注意力
公式:MultiHead(Q,K,V)=Concat(head1,…,headh)WO \text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, \ldots, \text{head}_h) W^O MultiHead(Q,K,V)=Concat(head1,…,headh)WO
其中:
headi=Attention(QWiQ, KWiK, VWiV) \text{head}_i = \text{Attention}(Q W_i^Q, \; K W_i^K, \; V W_i^V) headi=Attention(QWiQ,KWiK,VWiV)
代码实现
import torch.nn as nn
import torch
'''多头自注意力计算模块'''
class MultiHeadAttention(nn.Module):
def __init__(self, args: ModelArgs, is_causal=False):
# 构造函数
# args: 配置对象
super().__init__()
# 隐藏层维度必须是头数的整数倍,因为后面我们会将输入拆成头数个矩阵
assert args.dim % args.n_heads == 0
# 模型并行处理大小,默认为1。
model_parallel_size = 1
# 本地计算头数,等于总头数除以模型并行处理大小。
self.n_local_heads = args.n_heads // model_parallel_size
# 每个头的维度,等于模型维度除以头的总数。
self.head_dim = args.dim // args.n_heads
# Wq, Wk, Wv 参数矩阵,每个参数矩阵为 n_embd x n_embd
# 这里通过三个组合矩阵来代替了n个参数矩阵的组合,其逻辑在于矩阵内积再拼接其实等同于拼接矩阵再内积,
# 不理解的读者可以自行模拟一下,每一个线性层其实相当于n个参数矩阵的拼接
self.wq = nn.Linear(args.dim, self.n_local_heads * self.head_dim, bias=False)
self.wk = nn.Linear(args.dim, self.n_local_heads * self.head_dim, bias=False)
self.wv = nn.Linear(args.dim, self.n_local_heads * self.head_dim, bias=False)
# 输出权重矩阵,维度为 dim x n_embd(head_dim = n_embeds / n_heads)
self.wo = nn.Linear(self.n_local_heads * self.head_dim, args.dim, bias=False)
# 注意力的 dropout
self.attn_dropout = nn.Dropout(args.dropout)
# 残差连接的 dropout
self.resid_dropout = nn.Dropout(args.dropout)
# 创建一个上三角矩阵,用于遮蔽未来信息
# 注意,因为是多头注意力,Mask 矩阵比之前我们定义的多一个维度
if is_causal:
mask = torch.full((1, 1, args.max_seq_len, args.max_seq_len), float("-inf"))
mask = torch.triu(mask, diagonal=1)
# 注册为模型的缓冲区
self.register_buffer("mask", mask)
def forward(self, q: torch.Tensor, k: torch.Tensor, v: torch.Tensor):
# 获取批次大小和序列长度,[batch_size, seq_len, dim]
bsz, seqlen, _ = q.shape
# 计算查询(Q)、键(K)、值(V),输入通过参数矩阵层,维度为 (B, T, n_embed) x (n_embed, n_embed) -> (B, T, n_embed)
xq, xk, xv = self.wq(q), self.wk(k), self.wv(v)
# 将 Q、K、V 拆分成多头,维度为 (B, T, n_head, C // n_head),然后交换维度,变成 (B, n_head, T, C // n_head)
# 因为在注意力计算中我们是取了后两个维度参与计算
# 为什么要先按B*T*n_head*C//n_head展开再互换1、2维度而不是直接按注意力输入展开,是因为view的展开方式是直接把输入全部排开,
# 然后按要求构造,可以发现只有上述操作能够实现我们将每个头对应部分取出来的目标
xq = xq.view(bsz, seqlen, self.n_local_heads, self.head_dim)
xk = xk.view(bsz, seqlen, self.n_local_heads, self.head_dim)
xv = xv.view(bsz, seqlen, self.n_local_heads, self.head_dim)
xq = xq.transpose(1, 2)
xk = xk.transpose(1, 2)
xv = xv.transpose(1, 2)
# 注意力计算
# 计算 QK^T / sqrt(d_k),维度为 (B, nh, T, hs) x (B, nh, hs, T) -> (B, nh, T, T)
scores = torch.matmul(xq, xk.transpose(2, 3)) / math.sqrt(self.head_dim)
# 掩码自注意力必须有注意力掩码
if self.is_causal:
assert hasattr(self, 'mask')
# 这里截取到序列长度,因为有些序列可能比 max_seq_len 短
scores = scores + self.mask[:, :, :seqlen, :seqlen]
# 计算 softmax,维度为 (B, nh, T, T)
scores = F.softmax(scores.float(), dim=-1).type_as(xq)
# 做 Dropout
scores = self.attn_dropout(scores)
# V * Score,维度为(B, nh, T, T) x (B, nh, T, hs) -> (B, nh, T, hs)
output = torch.matmul(scores, xv)
# 恢复时间维度并合并头。
# 将多头的结果拼接起来, 先交换维度为 (B, T, n_head, C // n_head),再拼接成 (B, T, n_head * C // n_head)
# contiguous 函数用于重新开辟一块新内存存储,因为Pytorch设置先transpose再view会报错,
# 因为view直接基于底层存储得到,然而transpose并不会改变底层存储,因此需要额外存储
output = output.transpose(1, 2).contiguous().view(bsz, seqlen, -1)
# 最终投影回残差流。
output = self.wo(output)
output = self.resid_dropout(output)
return output

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 1
1 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)