CVPR 2025重磅:深度学习架构再进化,参数减半性能翻倍,SOTA被全面刷新
CVPR 深度学习领域的新思路层出不穷:大模型高效训练方法直接拉满算力利用率,视觉Transformer结构持续卷出新高度,多模态融合技术更是让视觉理解能力全面进化!不过可以看出,目前深度学习的研究重点依旧在算力优化、模型结构创新和多模态扩展三个方向。但对于想投顶会的同学来说,深度学习已经迈入“深水区”,除了传统优化,也需要更多跨领域的创新探索。
关注gongzhonghao【CVPR顶会精选】
CVPR 深度学习领域的新思路层出不穷:大模型高效训练方法直接拉满算力利用率,视觉Transformer结构持续卷出新高度,多模态融合技术更是让视觉理解能力全面进化!不过可以看出,目前深度学习的研究重点依旧在算力优化、模型结构创新和多模态扩展三个方向。但对于想投顶会的同学来说,深度学习已经迈入“深水区”,除了传统优化,也需要更多跨领域的创新探索。
今天小图给大家精选3篇CVPR有关深度学习方向的论文,供大家借鉴和参考。
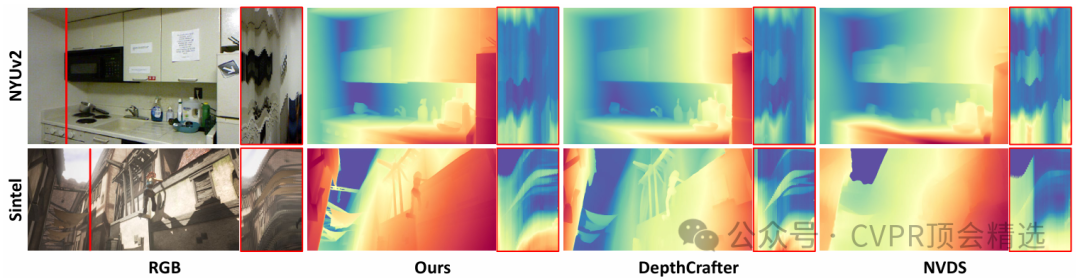
论文一:CH3Depth: Efficient and Flexible Depth Foundation Model with Flow Matching
方法:
作者将深度预测任务建模为概率流,通过学习最优速度场引导深度分布从先验状态流向目标分布,实现准确估计;训练过程中采用非均匀采样,重点关注梯度贡献大的区间和难例,有效减少方差并提升鲁棒性;推理阶段利用流匹配模型的高效采样机制,使推断过程更快更稳定,同时通过主干结构和尺度适配,确保模型在不同硬件和场景下都能高性能运行。

创新点:
-
将深度估计表述为条件流匹配问题,用连续运输学习图像到深度的映射,兼顾准确性与采样效率。
-
设计非均匀采样策略,重点覆盖信息密集与困难时刻/样本,减少训练方差并提升稳定性。
-
构建高效且可扩展的深度基础模型框架,兼容不同分辨率与硬件环境,实现速度与精度的双优。
论文链接:
https://chatpaper.com/ja/paper/153083
图灵学术论文辅导
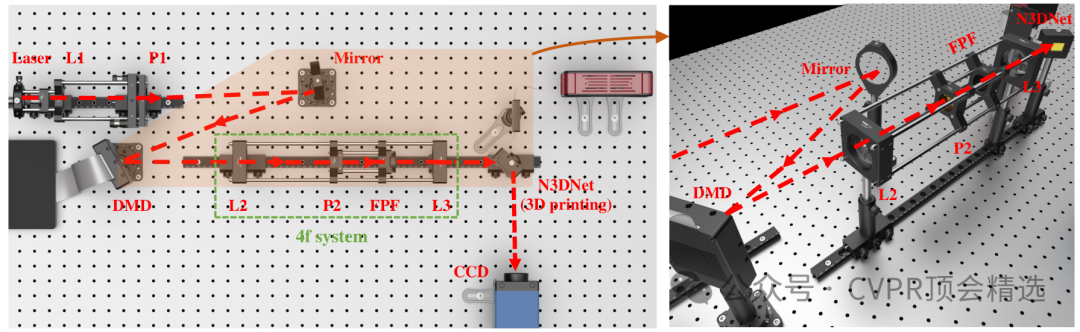
论文二:All-Optical Nonlinear Diffractive Deep Network for Ultrafast Image Denoising
方法:
作者设计了一套高度定制的光学衍射层,并用3D打印技术将深度网络参数固化到物理装置中,使光信号通过网络时自然完成去噪;整个去噪过程依赖光的传播和非线性干涉原理,而非电子计算,极大提升了速度和能效;最终,该方法在多种噪声场景下均展现出远超传统和现有深度学习去噪模型的效果,为超高速视觉任务带来全新可能。
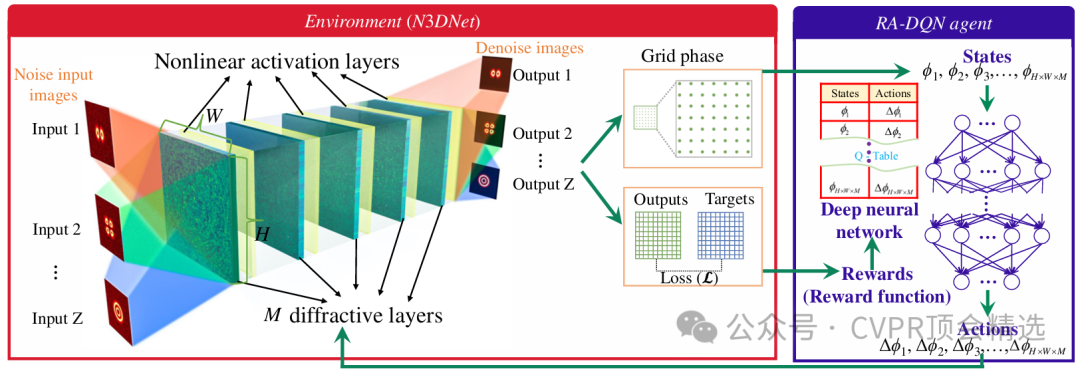
创新点:
-
首次通过3D打印实现全光学深度网络,将物理结构与深度学习模型高度融合。
-
利用非线性光学衍射机制,显著提升了去噪能力,超越传统算法和电子深度学习方法。
-
实现了端到端的超高速图像处理,速度高达电子方案的3800倍,极大扩展了实时应用场景。
论文链接:
https://ieeexplore.ieee.org/document/11092318
图灵学术论文辅导
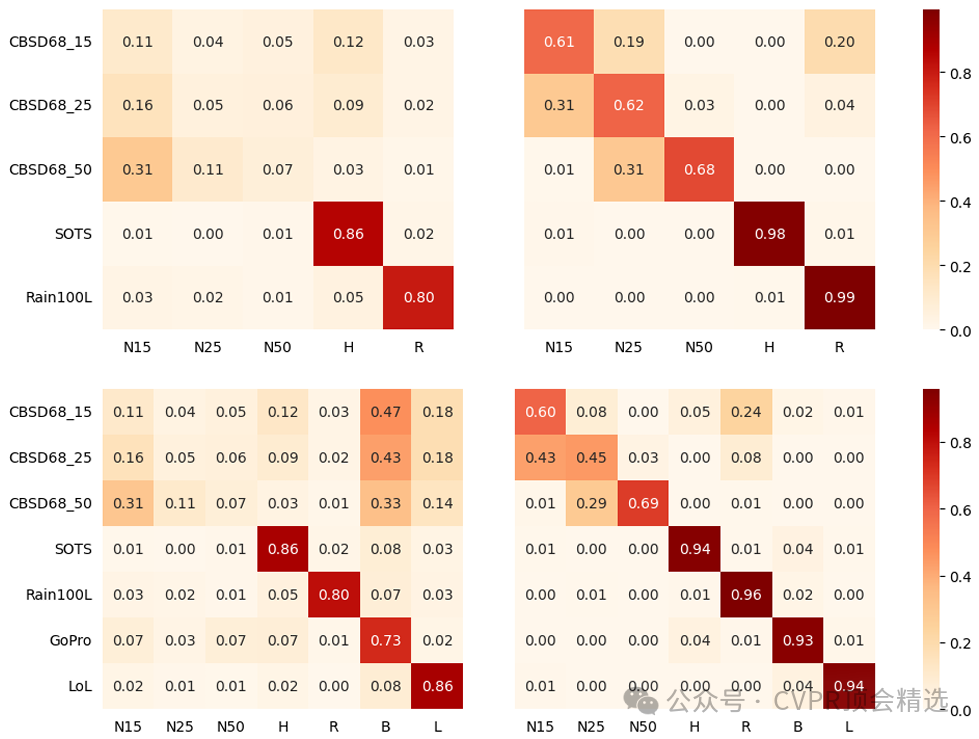
论文三:Vision-Language Gradient Descent-driven All-in-One Deep Unfolding Networks
方法:
作者设计了一个由视觉-语言模型动态生成引导信号的深度展开结构,使VLU-Net能够根据输入的任务描述为图像退化问题提供定制化优化方向;模型通过联合多种退化类型的数据进行统一训练,利用多任务损失函数促进各类任务的泛化和适应性;最终,通过端到端梯度下降驱动,VLU-Net在多种图像退化场景下均取得优于传统和现有深度方法的复原效果,兼顾了灵活性与高性能。
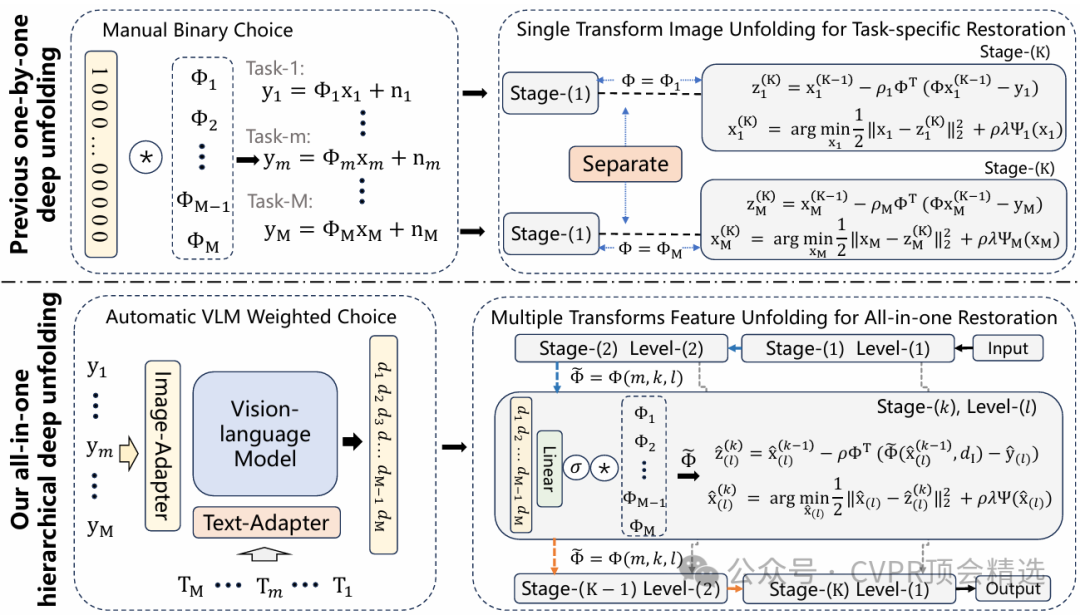
创新点:
-
创新性地将视觉语言模型引入深度展开网络,为每种具体图像退化任务生成专属梯度引导。
-
融合了多任务学习和统一优化框架,使一个模型即可灵活应对模糊、噪声等多种退化类型。
-
提出端到端的梯度驱动方法,显著提升图像复原质量并加快收敛速度。
论文链接:
https://arxiv.org/abs/2503.16930
本文选自gongzhonghao【CVPR顶会精选】

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 21
21 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)