6、PyTorch 层级结构
文章目录一、torch.nn1、Parameters&ContainersI、ParametersII、Containers二、torch.nn.functional三、参考资料一、torch.nn1、Parameters&ContainersI、Parameterstorch.nn.Parameter:Tensor 的子类II、Containerstorch....
文章目录
-
- 一、torch.nn 简介
- 二、Containers
- 四、Convolution、Pooling、Linear and Padding layers
- 五、Normalization and Dropout layers
- 六、Non-linear activations layers
- 七、Loss functions layers
- 八、Distance functions
- 九、DataParallel layers (multi-GPU, distributed)
- 十、参考资料
一、torch.nn 简介
-
torch.nn主要包含以下四类:
-
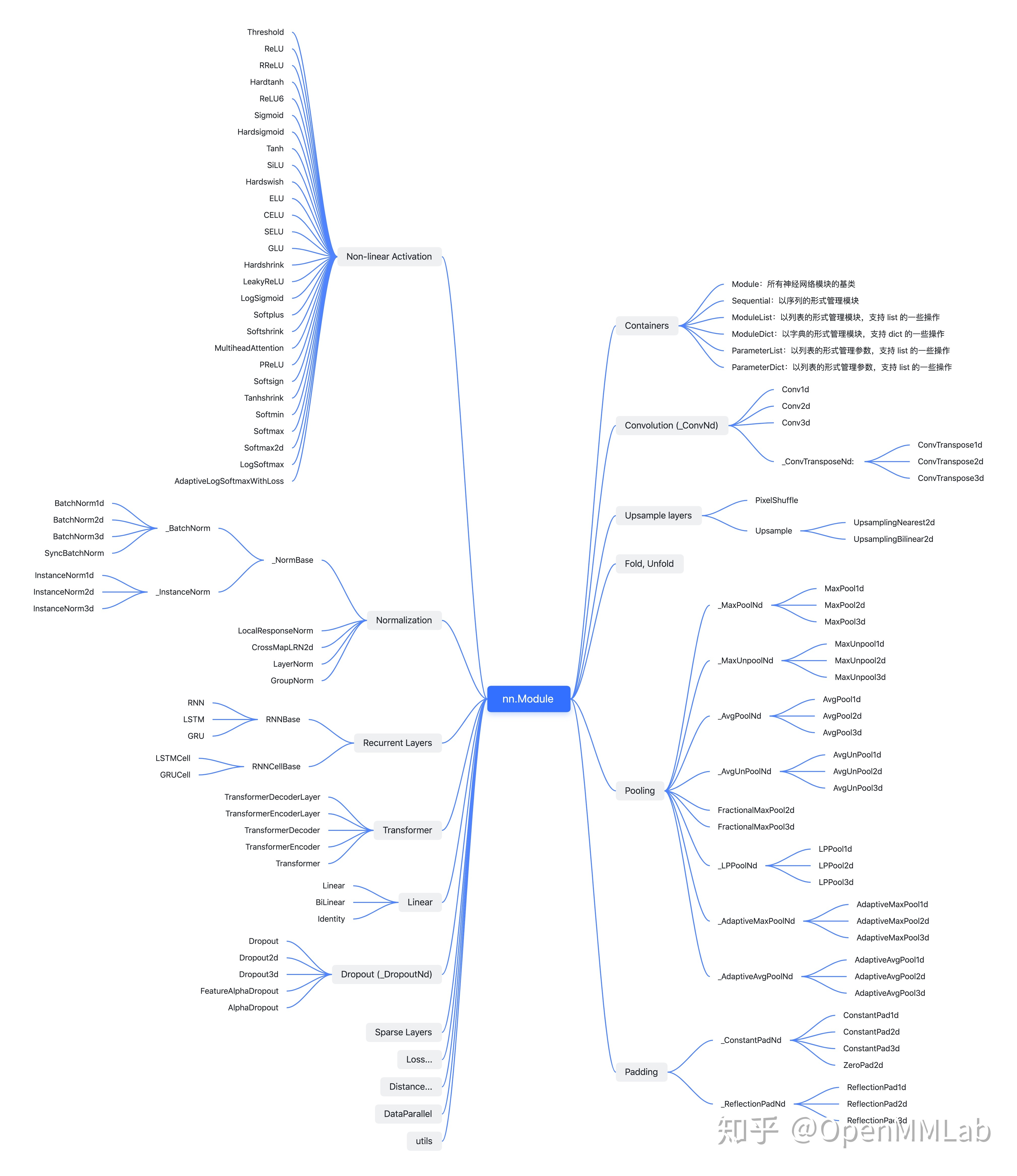
torch.nn.modules中的各个组件,它们的关系概览如下图所示,具体可参考:PyTorch 源码解读之 nn.Module:核心网络模块接口详解,从各模块的继承关系来看,模块的组织和实现有几个常见的特点:- 一般有一个基类来定义接口,通过继承来处理不同维度的 input,如:
Conv1d,Conv2d,Conv3d,ConvTransposeNd继承自_ConvNd;MaxPool1d,MaxPool2d,MaxPool3d继承自_MaxPoolNd等 - 每一个类都有一个对应的
nn.functional函数,类定义了所需要的 arguments 和模块的 parameters,在 forward 函数中将 arguments 和 parameters 传给 nn.functional 的对应函数来实现 forward 功能。比如:- 所有的非线性激活函数,都是在 forward 中直接调用对应的
nn.functional函数 - Normalization 层都是调用的如 F.layer_norm, F.group_norm 等函数
- 所有的非线性激活函数,都是在 forward 中直接调用对应的
- 继承 nn.Module 的模块主要重载
init、 forward、 和extra_repr函数,含有 parameters 的模块还会实现reset_parameters函数来 初始化参数
- 一般有一个基类来定义接口,通过继承来处理不同维度的 input,如:
-
模型创建的基本步骤:
- 对于激活函数和池化层,由于没有可学习参数,一般使用
torch.nn.functional完成,其他的有学习参数的部分则使用torch.nn.Module类及其子类来实现 - Droupout/ BN 层由于在训练和测试时操作不同,所以建议使用
torch.nn.Module实现,它能够通过model.eval加以区分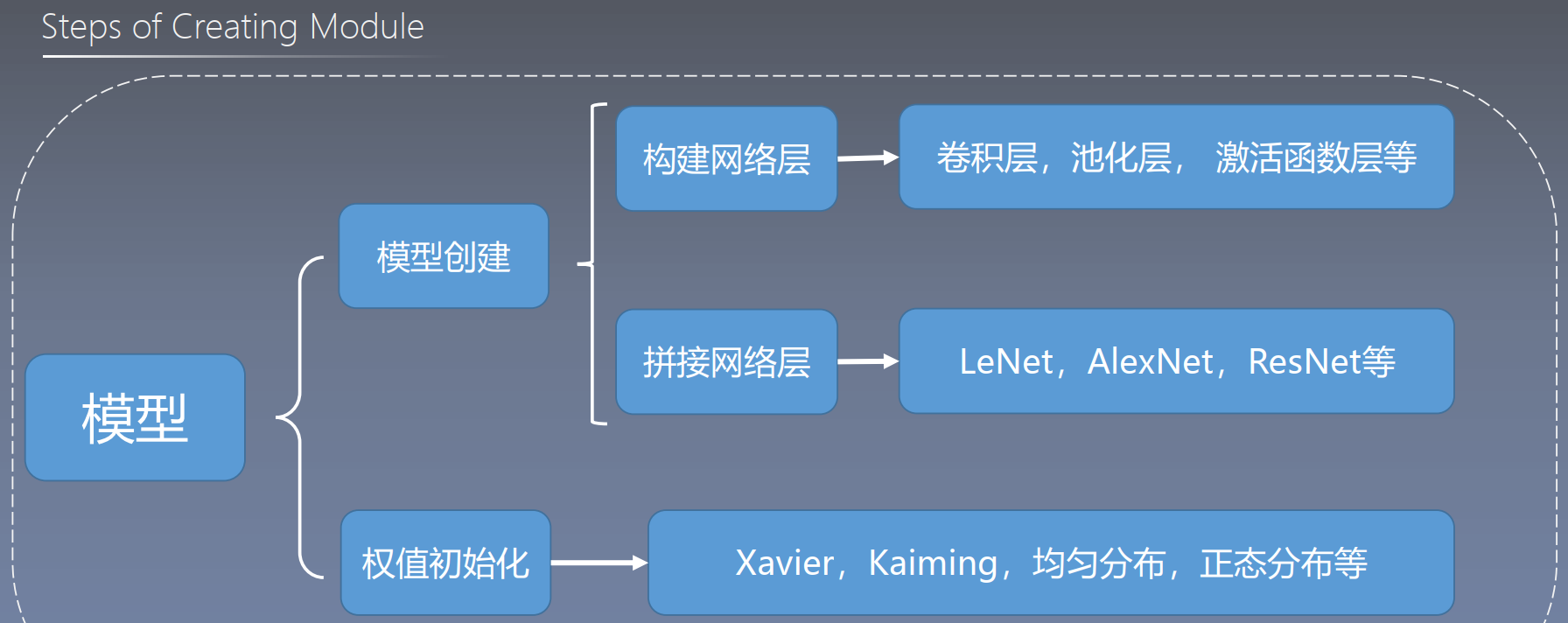
- 对于激活函数和池化层,由于没有可学习参数,一般使用
-
网络创建示例代码如下:
# Examples
import torch.nn as nn
import torch.nn.functional as F
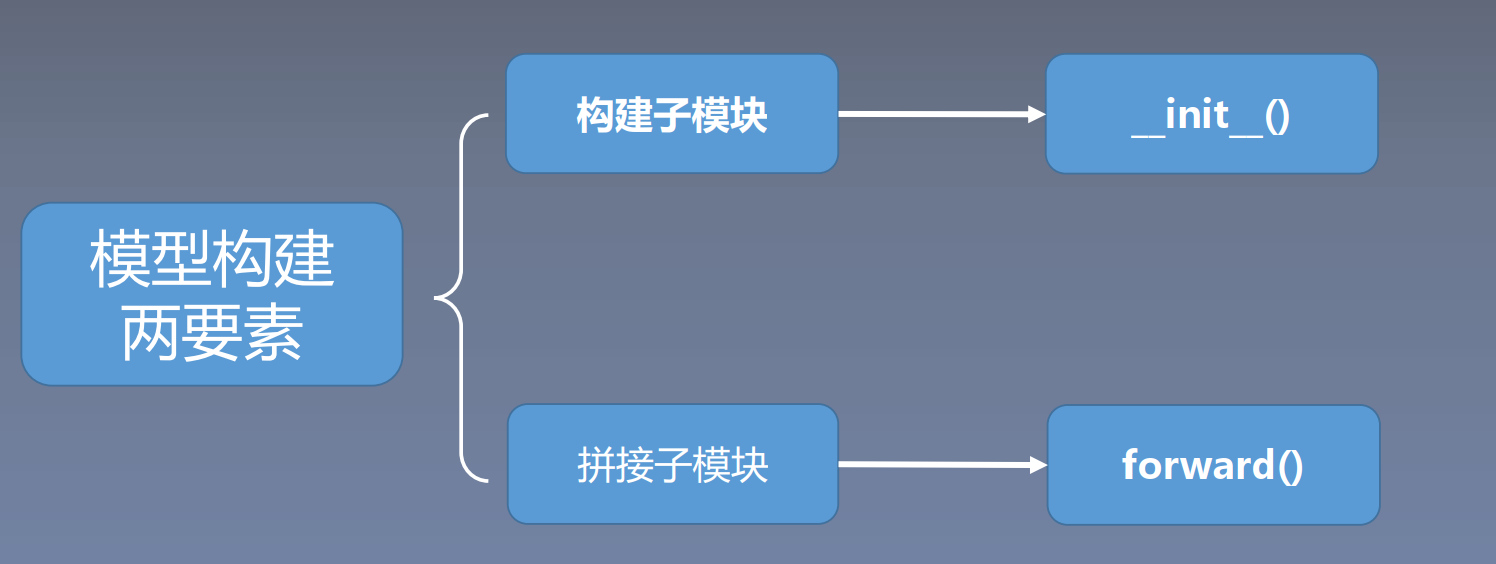
# 自己构建一个线性层(继承 nn.Module,其能够利用 autograd 自动实现反向传播,至少要实现一个 forward() 函数)
class LeNet(nn.Module):
# 1、模型构建要素一:构建子模块
def __init__(self, classes):
super(LeNet, self).__init__() # py2, 执行父类的初始化
super().__init__() # py3, 执行父类的初始化
self.conv1 = nn.Conv2d(3, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, classes)
# 2、模型构建要素二:拼接子模块
def forward(self, x):
out = F.relu(self.conv1(x))
out = F.max_pool2d(out, 2)
out = F.relu(self.conv2(out))
out = F.max_pool2d(out, 2)
out = out.view(out.size(0), -1)
out = F.relu(self.fc1(out))
out = F.relu(self.fc2(out))
out = self.fc3(out)
return out
# 3、权值初始化
def initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.xavier_normal_(m.weight.data)
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight.data, 0, 0.1)
m.bias.data.zero_()
# 实例化模型
net = LeNet(classes=2)
net.initialize_weights()
二、Containers

2.1、torch.nn.Module
torch.nn.Module:所有网络层的基类,管理网络属性,既可以表示神经网络中的某个层(layer),也可以表示一个包含很多层的神经网络(net),我们只要简单继承nn.Module,在构造函数中定义所有前向传播需要的模块,然后撰写forward()函数定义前向传播的行为即可完成网络的定义- 模块相当于一个运算,必须实现
forward()函数,每个模块有 8 个字典(OrderedDict)管理它的属性,可使用list(net.parameters()) 查看具体内容 - 使用时,直观上可将
layer或net看成数学概念中的函数,调用layer(input)或net(input)即可得到 input 对应的结果:- 将类实例对象当做函数来用,等价于
layer.__call__(input)或net.__call__(input) - 在
__call__函数中,主要调用的是layer.forward(input)或net.forward(input),另外还对钩子做了一些处理;所以在实际使用中应尽量使用layer(input)或net(input),而不要使用layer.forward(input)或net.forward(input)
- 将类实例对象当做函数来用,等价于
- 模块相当于一个运算,必须实现
# PyTorch 中的大部分方法都继承自 torch.nn.Module,而 torch.nn.Module 的__call__(self)函数中会
# 返回 forward()函数的结果,因此 forward() 函数可以被隐式的调用(模块的实例化对象为可调用对象)
class Module(nn.Module):
# 网络结构
def __init__(self):
super(Module, self).__init__() # 1、py2,使用 super 函数自动寻找父类的方法,并引入 self 参数
super().__init__() # 2、py3,使用 super 函数自动寻找父类的方法,并引入 self 参数
# ......
# 前向传播
def forward(self, x):
# ......
return x
# 输入数据
data = .....
# 实例化网络
module = Module()
# 前向传播直接调用,而不是使用 module.forward(data) 这种形式来调用,这是因为继承的 torch.nn.Module
# __call__(self) 函数会返回 forward()函数的结果,从而使得我们不需要显式地调用 forward 方法
module(data) # 等价于 module.forward(data)
# torch.nn.Module 中 __call__ 的实现
def _call_impl(self, *input, **kwargs):
forward_call = (self._slow_forward if torch._C._get_tracing_state() else self.forward)
# If we don't have any hooks, we want to skip the rest of the logic in
# this function, and just call forward.
if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
or _global_forward_hooks or _global_forward_pre_hooks):
return forward_call(*input, **kwargs)
# Do not call functions when jit is used
full_backward_hooks, non_full_backward_hooks = [], []
if self._backward_hooks or _global_backward_hooks:
full_backward_hooks, non_full_backward_hooks = self._get_backward_hooks()
if _global_forward_pre_hooks or self._forward_pre_hooks:
for hook in (*_global_forward_pre_hooks.values(), *self._forward_pre_hooks.values()):
result = hook(self, input)
if result is not None:
if not isinstance(result, tuple):
result = (result,)
input = result
bw_hook = None
if full_backward_hooks:
bw_hook = hooks.BackwardHook(self, full_backward_hooks)
input = bw_hook.setup_input_hook(input)
result = forward_call(*input, **kwargs)
if _global_forward_hooks or self._forward_hooks:
for hook in (*_global_forward_hooks.values(), *self._forward_hooks.values()):
hook_result = hook(self, input, result)
if hook_result is not None:
result = hook_result
if bw_hook:
result = bw_hook.setup_output_hook(result)
# Handle the non-full backward hooks
if non_full_backward_hooks:
var = result
while not isinstance(var, torch.Tensor):
if isinstance(var, dict):
var = next((v for v in var.values() if isinstance(v, torch.Tensor)))
else:
var = var[0]
grad_fn = var.grad_fn
if grad_fn is not None:
for hook in non_full_backward_hooks:
grad_fn.register_hook(_WrappedHook(hook, self))
self._maybe_warn_non_full_backward_hook(input, result, grad_fn)
return result
2.1.1、torch.nn.Module 属性简介
_modules:记录了当前nn.Module的所有子 nn.Module,使之形成一个树形结构_parameters和_buffers:记录了当前 nn.Module和所有子 nn.Module的所有构成参数_parameters: 用于存储需要梯度的参数,通常,我们会将nn.Module.parameters()的输出传递给Optimizer用于更新参数,因此_parameters的值必须是nn.Parameter对象_buffer:用于存储不需要梯度的Tensor,由于_buffers对象不会被优化器更新,因此在存储和加载模型的时候他们也不一定要被存储和加载,_non_persistent_buffers_set记录了所有不会被存储和加载的_buffer的键
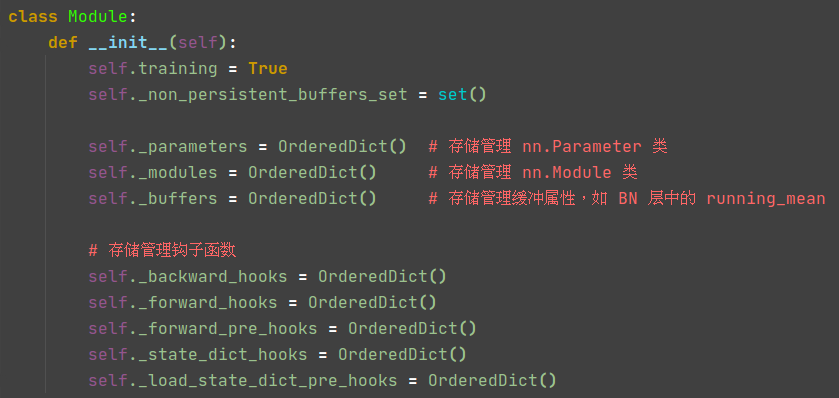
2.1.2、torch.nn.Module 方法简介
2.1.2.1、控制训练和测试相关方法:默认是训练
- nn.Module 通过
self.training属性来区分训练和测试两种状态(只影响本模块),使得模块可以在训练和测试时有不同的 forward 行为(如BN/Dropout) - nn.Module 通过
self.train()和self.eval()来修改训练和测试状态,其中self.eval直接调用了self.train(False),而 self.train() 会修改 self.training 并通过 self.children() 来调整所有子模块的状态
# 将本层及子层的 training 设定为 True
# 若通过属性设置 net.training = True,注意:此时对 module 的设置仅仅影响本层,子 module 不受影响
def train(self: T, mode: bool = True) -> T:
if not isinstance(mode, bool):
raise ValueError("training mode is expected to be boolean")
self.training = mode
for module in self.children():
module.train(mode)
return self
# 将本层及子层的 training 设定为 False
def eval(self: T) -> T:
return self.train(False)
2.1.2.2、梯度处理相关方法
requires_grad_:调用self.parameters()来访问所有的参数,并修改参数的requires_grad状态zero_grad:调用self.parameters()来访问所有的参数,并清理参数的梯度grad
# 更改 autograd 是否应记录此 module 中参数的操作;此方法就地(in place)设置参数的 requires_grad 属性
def requires_grad_(self: T, requires_grad: bool = True) -> T:
r"""Change if autograd should record operations on parameters in this module.
This method sets the parameters' :attr:`requires_grad` attributes in-place.
"""
for p in self.parameters():
p.requires_grad_(requires_grad)
return self
# 将所有模型参数的梯度设置为 None
def zero_grad(self, set_to_none: bool = False) -> None:
r"""Sets gradients of all model parameters to zero. See similar function
under :class:`torch.optim.Optimizer` for more context.
Args:
set_to_none (bool): instead of setting to zero, set the grads to None.
See :meth:`torch.optim.Optimizer.zero_grad` for details.
"""
if getattr(self, '_is_replica', False):
warnings.warn(
"Calling .zero_grad() from a module created with nn.DataParallel() has no effect. "
"The parameters are copied (in a differentiable manner) from the original module. "
"This means they are not leaf nodes in autograd and so don't accumulate gradients. "
"If you need gradients in your forward method, consider using autograd.grad instead.")
for p in self.parameters():
if p.grad is not None:
if set_to_none:
p.grad = None
else:
if p.grad.grad_fn is not None:
p.grad.detach_()
else:
p.grad.requires_grad_(False)
p.grad.zero_()
2.1.2.3、参数类型转换或存储位置转移的相关方法
nn.Module实现了如下 8 个常用函数将模块转变成float16等类型、转移到CPU/ GPU上- 这些函数的功能最终都是通过
self._apply(function)来实现的, function 一般是 lambda 表达式或其他自定义函数。因此,用户其实也可以通过self._apply(function)来实现一些特殊的转换,self._apply()函数实际上做了如下 3 件事情,最终将 function 完整地应用于整个模块:- 通过
self.children()进行递归的调用 - 对
self._parameters中的参数及其gradient通过function进行处理 - 对
self._buffers中的buffer逐个通过function来进行处理
- 通过
# 1、参数类型转换或存储位置转移的相关方法
# 1.1 Casts all parameters and buffers to dst_type(float/double/half)
type(dst_type) # 将所有 parameters 和 buffer 转变成另一个类型(float/double/half)
float()、double()、half()、bfloat16() # 将所有浮点类型的 parameters 和 buffer 转变成(float32/double/float16/bfloat16)
# 1.2 Moves all model parameters and buffers to the CPU/GPU.
cpu()
cuda(device=None)
# 1.3 Moves and/or casts the parameters and buffers
to(*args, **kwargs)
- to(device=None, dtype=None, non_blocking=False)
- to(dtype, non_blocking=False)
- to(tensor, non_blocking=False)
# 2、module 中 type 和 cuda 函数的具体实现
def type(self: T, dst_type: Union[dtype, str]) -> T:
return self._apply(lambda t: t.type(dst_type))
def cuda(self: T, device: Optional[Union[int, device]] = None) -> T:
return self._apply(lambda t: t.cuda(device))
# 3、module 中 _apply 函数的具体实现
def _apply(self, fn):
# 对子模块进行递归调用
for module in self.children():
module._apply(fn)
# 为了 BC-breaking 而新增了一个 tensor 类型判断
def compute_should_use_set_data(tensor, tensor_applied):
if torch._has_compatible_shallow_copy_type(tensor, tensor_applied):
# If the new tensor has compatible tensor type as the existing tensor,
# the current behavior is to change the tensor in-place using `.data =`,
# and the future behavior is to overwrite the existing tensor. However,
# changing the current behavior is a BC-breaking change, and we want it
# to happen in future releases. So for now we introduce the
# `torch.__future__.get_overwrite_module_params_on_conversion()`
# global flag to let the user control whether they want the future
# behavior of overwriting the existing tensor or not.
return not torch.__future__.get_overwrite_module_params_on_conversion()
else:
return False
# 处理参数及其 gradint
for key, param in self._parameters.items():
if param is not None:
# Tensors stored in modules are graph leaves, and we don't want to
# track autograd history of `param_applied`, so we have to use
# `with torch.no_grad():`
with torch.no_grad():
param_applied = fn(param)
should_use_set_data = compute_should_use_set_data(param, param_applied)
if should_use_set_data:
param.data = param_applied
else:
assert isinstance(param, Parameter)
assert param.is_leaf
self._parameters[key] = Parameter(param_applied, param.requires_grad)
if param.grad is not None:
with torch.no_grad():
grad_applied = fn(param.grad)
should_use_set_data = compute_should_use_set_data(param.grad, grad_applied)
if should_use_set_data:
param.grad.data = grad_applied
else:
assert param.grad.is_leaf
self._parameters[key].grad = grad_applied.requires_grad_(param.grad.requires_grad)
# 处理 buffers
for key, buf in self._buffers.items():
if buf is not None:
self._buffers[key] = fn(buf)
return self
# 4、Applies fn recursively to every submodule,typical use includes initializing the parameters of a model
# apply 方法是一个用于在张量或模型的所有元素上应用函数的功能;它可以应用于张量、模型的参数以及模型的子模块
apply(fn)
@torch.no_grad()
def init_weights(m):
print(m)
if type(m) == nn.Linear:
m.weight.fill_(1.0)
print(m.weight)
net = nn.Sequential(nn.Linear(2, 2), nn.Linear(2, 2))
net.apply(init_weights)
2.1.2.4、属性访问方法:返回类似字典的迭代器
- 常用函数有 8 个,它们都会返回一个 迭代器 用于访问模块中的
parameter、buffer、sub-module等parameters:调用 self.named_parameters 并返回模型参数,被应用于self.requires_grad_ 和 self.zero_grad函数named_parameters:返回 self._parameters 中的 name 和 parameter 元组,如果 recurse=True 还会返回子模块中的模型参数buffers:调用 self.named_buffers 并返回模型参数named_buffers:返回 self._buffers 中的 name 和 buffer 元组,如果 recurse=True 还会返回子模块中的模型 bufferchildren:调用 self.named_children,只返回 self._modules 中的模块,被应用于self.train函数中(只包含子模块),且类似 Sequential 模块中的子模块不输出named_children:只返回 self._modules 中的 name 和 module 元组(只包含子模块),且类似 Sequential 模块中的子模块不输出modules:调用 self.named_modules 并返回各个 module 但不返回 name(包含整个网络模块和子模块),且类似 Sequential 模块中的子模块也会输出named_modules:返回 self._modules 下的 name 和 module 元组,并递归调用和返回 module.named_modules(包含整个网络模块和子模块),且类似 Sequential 模块中的子模块也会输出
# 1、Returns an iterator over module parameters, yielding both the name of the parameter as well as the parameter itself
named_parameters(prefix='', recurse=True) # parameters(recurse=True)
def parameters(self, recurse: bool = True) -> Iterator[Parameter]:
for name, param in self.named_parameters(recurse=recurse):
yield param
def named_parameters(self, prefix: str = '', recurse: bool = True) -> Iterator[Tuple[str, Parameter]]:
r"""Returns an iterator over module parameters, yielding both the
name of the parameter as well as the parameter itself.
Yields:
(str, Parameter): Tuple containing the name and parameter
Example::
>>> for name, param in self.named_parameters():
>>> if name in ['bias']:
>>> print(param.size())
"""
# 调用模块的参数属性(字典)
gen = self._named_members(lambda module: module._parameters.items(), prefix=prefix, recurse=recurse)
for elem in gen:
yield elem
# 2、存储管理缓冲属性,如 BN 层中的 running_mean
# 2、Returns an iterator over module buffers, yielding both the name of the buffer as well as the buffer itself
named_buffers(self, prefix='', recurse=True) # buffers(recurse=True)
# 3、Returns an iterator over immediate children modules, yielding both the name of the module as well as the module itself
named_children() # children()
# 4、存储管理 nn.Module 类
# 4、Returns an iterator over all modules in the network, yielding both the name of the module as well as the module itself
named_modules(memo=None, prefix='') # modules()
# 5、nn.Module 重载了 __dir__ 函数,该函数会将 self._modules、self._parameters 和 self._buffers 中的 attributes 给暴露出来
def __dir__(self):
module_attrs = dir(self.__class__)
attrs = list(self.__dict__.keys())
parameters = list(self._parameters.keys())
modules = list(self._modules.keys())
buffers = list(self._buffers.keys())
keys = module_attrs + attrs + parameters + modules + buffers
# Eliminate attrs that are not legal Python variable names
keys = [key for key in keys if not key[0].isdigit()]
return sorted(keys)
2.1.2.5、属性设置方法:该方法会更改模块的属性
add_module:增加子神经网络模块,更新self._modulesregister_parameter:增加通过BP可以更新的参数(如 BN 和 Conv 中的 weight 和 bias ),更新self._parametersregister_buffer:增加不通过BP更新的 buffer(如 BN 中的 running_mean 和 running_var),更新self._buffers- 注意:
- 在日常的代码开发过程中,更常见的用法是直接在构造函数中通过
self.xxx = xxx的方式来增加或修改子神经网络模块、parameters、buffers 以及其他一般的 attribute,这种方式本质上会调用nn.Module重载的函数__setattr__ - 如果要给模块增加 buffer,
self.register_buffer是唯一的方式,__setattr__只能将self._buffers中已有的 buffer 重新赋值为 None 或者 tensor 。这是因为 buffer 的初始化类型就是 torch.Tensor 或者 None,而不像 parameters 和 module 分别是nn.Parameter和nn.Module类型
- 在日常的代码开发过程中,更常见的用法是直接在构造函数中通过
add_module(name, module)
register_parameter(name, param)
register_buffer(name, tensor)
# self.add_module("conv3", nn.Conv2d(10, 40, 5)) <<==>> self.conv3 = nn.Conv2d(10, 40, 5)
# self.register_parameter("param1", nn.Parameter(torch.rand([1]))) # 向 module 添加参数
# self.register_buffer("buffer", torch.randn([2, 3])) # 给 module 添加一个 presistent(持久的) buffer
# module 中 __setattr__ 的具体实现
def __setattr__(self, name: str, value: Union[Tensor, 'Module']):
def remove_from(*dicts_or_sets):
for d in dicts_or_sets:
if name in d:
if isinstance(d, dict):
del d[name]
else:
d.discard(name)
params = self.__dict__.get('_parameters')
if isinstance(value, Parameter):
if params is None:
raise AttributeError(
"cannot assign parameters before Module.__init__() call")
remove_from(self.__dict__, self._buffers, self._modules, self._non_persistent_buffers_set)
self.register_parameter(name, value)
elif params is not None and name in params:
if value is not None:
raise TypeError("cannot assign '{}' as parameter '{}' "
"(torch.nn.Parameter or None expected)"
.format(torch.typename(value), name))
self.register_parameter(name, value)
else:
modules = self.__dict__.get('_modules')
if isinstance(value, Module):
if modules is None:
raise AttributeError(
"cannot assign module before Module.__init__() call")
remove_from(self.__dict__, self._parameters, self._buffers, self._non_persistent_buffers_set)
modules[name] = value
elif modules is not None and name in modules:
if value is not None:
raise TypeError("cannot assign '{}' as child module '{}' "
"(torch.nn.Module or None expected)"
.format(torch.typename(value), name))
modules[name] = value
else:
buffers = self.__dict__.get('_buffers')
if buffers is not None and name in buffers:
if value is not None and not isinstance(value, torch.Tensor):
raise TypeError("cannot assign '{}' as buffer '{}' "
"(torch.Tensor or None expected)"
.format(torch.typename(value), name))
buffers[name] = value
else:
object.__setattr__(self, name, value)
2.1.2.6、属性删除方法:通过重载的 __delattr__ 来实现
# __delattr__ 会挨个检查 self._parameters、self._buffers、self._modules 和普通的 attribute 并将 name 从中删除
def __delattr__(self, name):
if name in self._parameters:
del self._parameters[name]
elif name in self._buffers:
del self._buffers[name]
self._non_persistent_buffers_set.discard(name)
elif name in self._modules:
del self._modules[name]
else:
object.__delattr__(self, name)
2.1.2.7、模型推理、权重保存和加载相关方法
state_dict():- 用于在模型训练中储存 checkpoint,返回包含了module 的整个状态的字典。其中 keys 是对应的参数和buffers名称
- 模块的
_version信息会首先存入metadata中,用于模型的版本管理,然后会通过_save_to_state_dict()将self._parameters以及self._buffers中的persistent buffer进行保存;用户可以通过重载 _save_to_state_dict 函数来满足特定的需求
load_state_dict():- 用于读取 checkpoint,将参数和 buffers 从 state_dict 复制到 module 及其后代(descendants)中
- 通过调用每个子模块的
_load_from_state_dict函数来加载他们所需的权重和 buffer;每个模块可以自行定义他们的 _load_from_state_dict 函数来满足特殊需求
# 1、Defines the computation performed at every call, Should be overridden by all subclasses
forward(*input)
# 2、Returns a dictionary containing a whole state of the module
state_dict(destination=None, prefix='', keep_vars=False)
# 3、Copies parameters and buffers from state_dict into this module and its descendants
# 可以将 strict 置为 False,只加载预训练模型中有的 key 中的 value,其余部分使用默认初始化的权重
load_state_dict(state_dict, strict=True)
def _save_to_state_dict(self, destination, prefix, keep_vars):
for name, param in self._parameters.items():
if param is not None:
destination[prefix + name] = param if keep_vars else param.detach()
for name, buf in self._buffers.items():
if buf is not None and name not in self._non_persistent_buffers_set:
destination[prefix + name] = buf if keep_vars else buf.detach()
extra_state_key = prefix + _EXTRA_STATE_KEY_SUFFIX
if getattr(self.__class__, "get_extra_state", Module.get_extra_state) is not Module.get_extra_state:
destination[extra_state_key] = self.get_extra_state()
def _load_from_state_dict(self, state_dict, prefix, local_metadata, strict,
missing_keys, unexpected_keys, error_msgs):
for hook in self._load_state_dict_pre_hooks.values():
hook(state_dict, prefix, local_metadata, strict, missing_keys, unexpected_keys, error_msgs)
persistent_buffers = {k: v for k, v in self._buffers.items() if k not in self._non_persistent_buffers_set}
local_name_params = itertools.chain(self._parameters.items(), persistent_buffers.items())
local_state = {k: v for k, v in local_name_params if v is not None}
for name, param in local_state.items():
key = prefix + name
if key in state_dict:
input_param = state_dict[key]
if not torch.overrides.is_tensor_like(input_param):
error_msgs.append('While copying the parameter named "{}", '
'expected torch.Tensor or Tensor-like object from checkpoint but '
'received {}'
.format(key, type(input_param)))
continue
# This is used to avoid copying uninitialized parameters into
# non-lazy modules, since they dont have the hook to do the checks
# in such case, it will error when accessing the .shape attribute.
is_param_lazy = torch.nn.parameter.is_lazy(param)
# Backward compatibility: loading 1-dim tensor from 0.3.* to version 0.4+
if not is_param_lazy and len(param.shape) == 0 and len(input_param.shape) == 1:
input_param = input_param[0]
if not is_param_lazy and input_param.shape != param.shape:
# local shape should match the one in checkpoint
error_msgs.append('size mismatch for {}: copying a param with shape {} from checkpoint, '
'the shape in current model is {}.'
.format(key, input_param.shape, param.shape))
continue
try:
with torch.no_grad():
param.copy_(input_param)
except Exception as ex:
error_msgs.append('While copying the parameter named "{}", '
'whose dimensions in the model are {} and '
'whose dimensions in the checkpoint are {}, '
'an exception occurred : {}.'
.format(key, param.size(), input_param.size(), ex.args))
elif strict:
missing_keys.append(key)
extra_state_key = prefix + _EXTRA_STATE_KEY_SUFFIX
if getattr(self.__class__, "set_extra_state", Module.set_extra_state) is not Module.set_extra_state:
if extra_state_key in state_dict:
self.set_extra_state(state_dict[extra_state_key])
elif strict:
missing_keys.append(extra_state_key)
elif strict and (extra_state_key in state_dict):
unexpected_keys.append(extra_state_key)
if strict:
for key in state_dict.keys():
if key.startswith(prefix) and key != extra_state_key:
input_name = key[len(prefix):]
input_name = input_name.split('.', 1)[0] # get the name of param/buffer/child
if input_name not in self._modules and input_name not in local_state:
unexpected_keys.append(key)
# 直接在网络构建时加载预训练模型
def load_param(self):
pretrained_dict = torch.load('model/resnet18.pth')
net_state_dict = self.state_dict()
if pretrained_dict:
print("sucess loaded pretrained model")
# 将 pretrained_dict 里不属于 net_state_dict 的键剔除掉
modified_dict = {k: v for k, v in pretrained_dict.items() if k in self.state_dict()}
# 用预训练模型的参数字典对新模型的参数字典 net_state_dict 进行更新
# 新网络,预训练模型中存在的 key 使用预训练模型的权重,不存在的 key 使用默认初始化的权重
net_state_dict.update(modified_dict)
# 将更新了参数的字典放回到网络中
self.load_state_dict(net_state_dict)
print("use pretrain parameters")
else:
print("use default parameters")
# 简化版本:将 strict 置为 False,只加载预训练模型中有的 key 中的 value,其余部分使用默认初始化的权重
def load_param(self):
pretrained_dict = torch.load(self.model_path)
if pretrained_dict:
print("success loaded pretrained model")
self.load_state_dict(pretrained_dict, strict=False)
print("use pretrain parameters")
else:
print("use default parameters")
2.1.2.8、Hooks 相关文件内部函数和类方法
-
在 nn.Module 的实现
文件中,首先实现了 4 个通用的 hook 注册函数,这 4 个函数会将 hook 分别注册进 3 个全局的 OrderedDict,使得所有的 nn.Module 的子类实例在运行的时候都会触发这些 hook。每个hook 修改的 OrderedDict如下所示:register_module_backward_hook(hook):_global_backward_hooks,在 module 中注册一个反向钩子,不推荐使用register_module_full_backward_hook:_global_backward_hooks,在 module 中注册一个反向钩子,每次计算梯度时都会调用此钩子,使用此钩子时不允许就地(in place)修改输入或输出,否则会触发errorregister_module_forward_pre_hook(hook):_global_forward_pre_hooks,在 module 中注册前向 pre-hook,每次调用 forward 之前都会调用此钩子register_module_forward_hook(hook):_global_forward_hooks,在 module 中注册一个前向钩子,每次 forward 计算输出后都会调用此钩子
-
nn.Module
类也支持注册只被应用于自己的 forward 和 backward hook,通过 3 个函数来管理自己的 3 个属性并维护 3 个attribute,他们的类型也是 OrderedDict,每个hook 修改的 OrderedDict如下所示:self.register_backward_hook(hook): self._backward_hooks,不推荐使用self.register_full_backward_hook:self._backward_hooks,每次计算梯度时都会调用此钩子,使用此钩子时不允许就地(in place)修改输入或输出,否则会触发errorself.register_forward_pre_hook(hook): self._forward_pre_hooks,每次调用 forward 之前都会调用此钩子self.register_forward_hook(hook): self._forward_hooks,每次 forward 计算输出后都会调用此钩子
-
hooks 在模块被调用时候的执行顺序如下图所示:
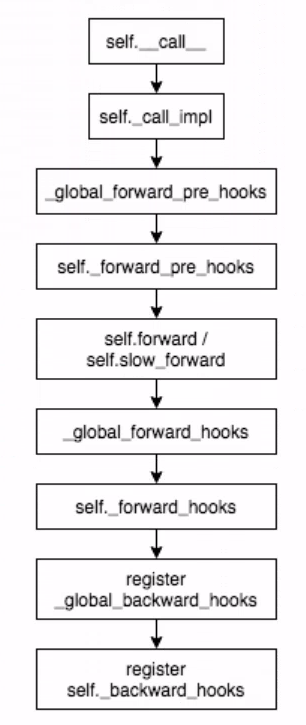
-
钩子函数的使用: 不改变网络主体,实现额外功能,像一个挂钩(
hook)- 由于 pytorch 会自动舍弃图计算的中间结果,所以想要获取这些数值就需要使用钩子函数
- 主要用在获取某些中间结果的情景,如中间某一层的输出或某一层的梯度(eg: 提取模型的某一层的输出作为特征进行分类)
# 1、前向传播钩子函数设置,module: 当前网络层,input:当前网络层输入数据,output:当前网络层输出数据 def hook(module, input, output): print(module) # 打印本层信息 for val in input: print("Input shape is {}".format(val.shape)) # 打印此层输入的形状(input 为 tuple) print("Output shape is {}".format(output.shape)) # 打印此层输出的形状,可把这层的输出拷贝到 features 中 # 2、构建网络,并设置前向传播钩子 net = LeNet_bn(classes=2) net.initialize_weights() handle = net.conv2.register_forward_hook(hook) # 在 module 前向传播时注册钩子 outputs = net(inputs) # 需执行前向传播 handle.remove() # 钩子函数不应修改输入和输出,并且在使用后应及时删除,以避免每次都运行钩子增加运行负载 # 3、每次前向传播执行结束后会执行钩子函数(hook),钩子函数中会输出以下内容: Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1)) Input shape is torch.Size([16, 6, 14, 14]) Output shape is torch.Size([16, 16, 10, 10]) # 4、反向传播钩子函数设置:def hook(module, grad_input, grad_output) >>> module: 当前网络层 >>> grad_input:当前网络层输入梯度数据 >>> grad_output:当前网络层输出梯度数据
2.2、torch.nn.Sequential
torch.nn.Sequential(*args):按 顺序 包装多个网络层- 顺序性:各网络层之间严格按顺序执行,常用于
block构建 自带 forward() 函数:通过 for 循环依次执行前向传播运算Sequential中每个模块的名称:该模块在参数中出现的顺序(eg:0.weight,0.bias)Sequential中每个模块重命名:传入OrderedDict作为参数,这样自释性强些(eg:conv1.weight, conv1.bias)- 常用代码示例:
- 顺序性:各网络层之间严格按顺序执行,常用于
import torch.nn as nn
from collections import OrderedDict
# 1、构建 Sequential
model1 = nn.Sequential(
nn.Conv2d(1,20,5),
nn.ReLU(),
nn.Conv2d(20,64,5),
nn.ReLU()
)
# 2、利用 OrderedDict 构建 Sequential 的例子
class Model2(nn.Module):
# 初始化中传入类别参数
def __init__(self, classes):
super().__init__() # 执行父类的初始化
self.features = nn.Sequential(OrderedDict({
'conv1': nn.Conv2d(3, 6, 5),
'relu1': nn.ReLU(inplace=True),
'pool1': nn.MaxPool2d(kernel_size=2, stride=2),
'conv2': nn.Conv2d(6, 16, 5),
'relu2': nn.ReLU(inplace=True),
'pool2': nn.MaxPool2d(kernel_size=2, stride=2),
}))
self.classifier = nn.Sequential(OrderedDict({
'fc1': nn.Linear(16 * 5 * 5, 120),
'relu3': nn.ReLU(),
'fc2': nn.Linear(120, 84),
'relu4': nn.ReLU(inplace=True),
'fc3': nn.Linear(84, classes),
}))
# 在前向传播函数中,我们有意识地将输出变量都命名成 x,是为了能让 Python 回收一些中间层的输出,从而节省内存
# 但并不是所有都会被回收,有些变量虽然名字被覆盖,但其在反向传播仍需要用到,此时 Python 的内存回收模块将通过检查引用计数,不会回收这一部分内存
def forward(self, x):
x = self.features(x)
x = x.view(x.size()[0], -1)
x = self.classifier(x)
return x
def initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.xavier_normal_(m.weight.data)
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight.data, 0, 1)
m.bias.data.zero_()
# 构建模型
model2 = Model2(classes=2)
model2.initialize_weights()
# 训练
for i, data in enumerate(train_loader):
inputs, labels = data
outputs = model2(inputs) # 将类当作函数来用(自动调用 forward)
# 3、自定义模块,控制通过网络数据的流向(forward 函数可不按照顺序调用初始化中的子模块)
class Model3(nn.Module):
def __init__(self):
super().__init__()
self.hidden_linear = nn.Linear(1, 13)
self.hidden_activation = nn.Tanh()
self.output_linear = nn.Linear(13, 1)
def forward(self, input):
hidden_t = self.hidden_linear(input)
activated_t = self.hidden_activation(hidden_t)
output_t = self.output_linear(activated_t)
return output_t
model3 = Model3()
# 4、输出模型的参数
>>> for name, param in model1.named_parameters():
>>> print(name, param.shape)
0.weight torch.Size([20, 1, 5, 5])
0.bias torch.Size([20])
2.weight torch.Size([64, 20, 5, 5])
2.bias torch.Size([64])
>>> for name, param in model2.named_parameters():
>>> print(name, param.shape)
conv1.weight torch.Size([20, 1, 5, 5])
conv1.bias torch.Size([20])
conv2.weight torch.Size([64, 20, 5, 5])
conv2.bias torch.Size([64])
# 5、输出模型的每一层信息
for name, submodule in model2.named_modules():
print("Name is: {}, Submodule is: {}".format(name, submodule))
# named_modules 其实是包含了网络自身的 module 集合( name 为空)
Name is:, Submodule is:Model2(
(conv1): Conv2d(3, 6, kernel_size=(5, 5), stride=(1, 1))
(conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
(fc1): Linear(in_features=400, out_features=120, bias=True)
(fc2): Linear(in_features=120, out_features=84, bias=True)
(fc3): Linear(in_features=84, out_features=2, bias=True)
)
Name is:conv1, Submodule is:Conv2d(3, 6, kernel_size=(5, 5), stride=(1, 1))
Name is:conv2, Submodule is:Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
Name is:fc1, Submodule is:Linear(in_features=400, out_features=120, bias=True)
Name is:fc2, Submodule is:Linear(in_features=120, out_features=84, bias=True)
Name is:fc3, Submodule is:Linear(in_features=84, out_features=2, bias=True)
# 6、输出模型每一层的 buffer 信息
for name, buffer in model2.named_buffers():
print("Name is: {}, Buffer is: {}".format(name, buffer))
Name is: bn1.running_mean, Buffer is: tensor([ 0.0010, -0.0019, 0.0007, -0.0004, 0.0027, 0.0009])
Name is: bn1.running_var, Buffer is: tensor([0.9257, 1.2193, 0.9346, 0.9234, 0.9168, 0.9396])
Name is: bn1.num_batches_tracked, Buffer is: 1
# 7、访问模型特定子模块(属性)的参数
>>> model2.conv1.weight.shape
torch.Size([20, 1, 5, 5])
>>> model2.conv1.bias.shape
torch.Size([20])
# 8、训练过程中查看特定层的梯度
model2.conv1.weight.grad
# 9、初始化某一层网络的参数
model2.conv1.weight.data = torch.ones([20, 1, 5, 5])
2.3、torch.nn.ModuleList
torch.nn.ModuleList(modules=None):像 python 的list一样包装多个网络层,以迭代方式调用网络层- 迭代性:常用于大量重复网构建,通过 for 循环实现重复构建
- 常用方法有:
append():在 ModuleList 后面添加网络层extend():拼接两个 ModuleListinsert():指定在 ModuleList 中的某个位置插入网络层
class ModuleList(nn.Module):
def __init__(self):
super(ModuleList, self).__init__()
self.linears = nn.ModuleList([nn.Linear(10, 10) for i in range(20)]) # 重复 20 次
def forward(self, x):
for i, linear in enumerate(self.linears):
x = linear(x)
return x
2.4、torch.nn.ModuleDict
torch.nn.ModuleDict(modules=None):像 python 的dict一样包装多个网络层,以字典索引方式调用网络层- 字典索引性:常用于可选择的网络层
- 常用方法有:
clear():清空 ModuleDictitems():返回可迭代的键值对(key-value pairs)keys():返回字典的键(key)values():返回字典的值(value)pop():返回一对键值,并从字典中删除
class ModuleDict(nn.Module):
def __init__(self):
super(ModuleDict, self).__init__()
self.choices = nn.ModuleDict({
'conv': nn.Conv2d(10, 10, 3),
'pool': nn.MaxPool2d(3)
})
self.activations = nn.ModuleDict({
'relu': nn.ReLU(),
'prelu': nn.PReLU()
})
def forward(self, x, choice, act):
x = self.choices[choice](x)
x = self.activations[act](x)
return x
net = ModuleDict()
output = net(fake_img, 'conv', 'relu') # eg: 可通过传入不同的参数选择不同的激活函数
2.5、torch.nn.ParameterList&ParameterDict
torch.nn.ParameterList(parameters=None):将一系列参数存储在一个list中torch.nn.ParameterDict(parameters=None):将一系列参数存储在一个dict中
四、Convolution、Pooling、Linear and Padding layers
# 卷积层
# 输出(结果向下取整):H_out = [H_in - 1 + 2 * padding + dilation * (kernel_size - 1)] / stride + 1
# 当 padding 为 'valid' 或 'same' 时,stride 必须为 1
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1,
bias=True, padding_mode='zeros')
# 除了继承 nn.Module 所有的属性和方法外,自己的属性有:
# in_channels, out_channels, kernel_size, stride, padding, dilation, transposed,
# output_padding, groups, padding_mode, weight, bias, training
>>> # With square kernels and equal stride
>>> m = nn.Conv2d(16, 33, 3, stride=2)
>>> # non-square kernels and unequal stride and with padding and dilation
>>> m = nn.Conv2d(16, 33, (3, 5), stride=(2, 1), padding=(4, 2), dilation=(3, 1))
>>> input = torch.randn(20, 16, 50, 100)
>>> output = m(input)
# ~/miniconda3/lib/python3.8/site-packages/torch/nn/modules/conv.py
# _ConvNd 中默认的初始化方式
def reset_parameters(self) -> None:
# Setting a=sqrt(5) in kaiming_uniform is the same as initializing with
# uniform(-1/sqrt(k), 1/sqrt(k)), where k = weight.size(1) * prod(*kernel_size)
# For more details see: https://github.com/pytorch/pytorch/issues/15314#issuecomment-477448573
init.kaiming_uniform_(self.weight, a=math.sqrt(5))
if self.bias is not None:
fan_in, _ = init._calculate_fan_in_and_fan_out(self.weight)
if fan_in != 0:
bound = 1 / math.sqrt(fan_in)
init.uniform_(self.bias, -bound, bound)
# 转置卷积层(有需要学习的参数)
# 输出:H_out = (H_in - 1) * stride - 2 * padding + dilation * (kernel_size - 1) + output_padding + 1
torch.nn.ConvTranspose2d(in_channels, out_channels, kernel_size, stride=1, padding=0, output_padding=0,
groups=1, bias=True, dilation=1, padding_mode='zeros')
>>> # With square kernels and equal stride
>>> m = nn.ConvTranspose2d(16, 33, 3, stride=2)
>>> # non-square kernels and unequal stride and with padding
>>> m = nn.ConvTranspose2d(16, 33, (3, 5), stride=(2, 1), padding=(4, 2))
>>> input = torch.randn(20, 16, 50, 100)
>>> output = m(input)
# 上采样层(无需要学习的参数)
torch.nn.Upsample(size=None, scale_factor=None, mode='nearest', align_corners=None)
torch.nn.UpsamplingNearest2d(size=None, scale_factor=None)
torch.nn.UpsamplingBilinear2d(size=None, scale_factor=None)
torch.nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True) # 双线性插值上采样
# 池化层(可以设置输出向上取整与否,默认向下取整,caffe 中默认向上取整)
torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)
torch.nn.AvgPool2d(kernel_size, stride=None, padding=0, ceil_mode=False, count_include_pad=True,
divisor_override=None)
>>> # pool of square window of size=3, stride=2
>>> m = nn.MaxPool2d(3, stride=2)
>>> # pool of non-square window
>>> m = nn.MaxPool2d((3, 2), stride=(2, 1))
>>> input = torch.randn(20, 16, 50, 32)
>>> output = m(input)
# output_size: the target output size of the image, 可以是 tuple, int or None(输入输出不变)
torch.nn.AdaptiveAvgPool2d(output_size) # 如果需要转 caffe 进行部署,则需要改成确定尺寸的池化层来训练
>>> m = nn.AdaptiveAvgPool2d((1,1)) # 实现全局池化,通道数保持不变,(H, W)-->(1, 1)
>>> input = torch.randn(1, 512, 7, 7) # 输入需要是 NCHW 格式
>>> output = m(input)
# 线性层(又称全连接层,默认加偏置项)与展开层
# 属性有:in_features, out_features, weight, bias, training
torch.nn.Linear(in_features, out_features, bias=True)
torch.nn.Flatten(start_dim=1, end_dim=-1)
>>> m = nn.Linear(20, 30)
>>> input = torch.randn(128, 20)
>>> output = m(input)
>>> print(output.size())
torch.Size([128, 30])
# 补零层
torch.nn.ZeroPad2d(padding)
torch.nn.ConstantPad2d(padding, value)
torch.nn.ReflectionPad2d(padding)
torch.nn.ReplicationPad2d(padding)
- padding (python:int, tuple):
- If is int, uses the same padding in all boundaries.
- If a 4-tuple, uses (padding_left, padding_right , padding_top, padding_bottom )
>>> # using same paddings for different sides
>>>> m = nn.ZeroPad2d(2)
>>> # using different paddings for different sides
>>> m = nn.ZeroPad2d((1, 1, 2, 0))
>>> input = torch.randn(1, 1, 3, 3)
>>> m(input)
# 另一种实现方式:torch.nn.functional:函数具体实现,如卷积,池化,激活函数等
torch.nn.functional.conv2d(input, weight, bias=None, stride=1, padding=0, dilation=1, groups=1)
torch.nn.functional.conv_transpose2d(input, weight, bias=None, stride=1, padding=0, output_padding=0, groups=1, dilation=1)
torch.nn.functional.upsample(input, size=None, scale_factor=None, mode='nearest', align_corners=None)
torch.nn.functional.upsample_nearest(input, size=None, scale_factor=None)
torch.nn.functional.upsample_bilinear(input, size=None, scale_factor=None)
torch.nn.functional.avg_pool2d(input, kernel_size, stride=None, padding=0, ceil_mode=False, count_include_pad=True, divisor_override=None)
torch.nn.functional.max_pool2d(*args, **kwargs)
torch.nn.functional.linear(input, weight, bias=None)
torch.nn.functional.pad(input, pad, mode='constant', value=0)
五、Normalization and Dropout layers
# 归一化层
torch.nn.BatchNorm2d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
torch.nn.SyncBatchNorm(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True,
process_group=None) # supports DistributedDataParallel with single GPU per process
- num_features: 输入特征数量,C 维
- momentum: 指数加权平均参数,用于估计当前 running_mean / running_var
- affine: 是否需要 affine transform(缩放和平移)
- track_running_stats:this module tracks the running mean and variance
>>> running_mean:训练时均值采用指数加权滑动平均计算,测试时使用当前统计值
>>> running_var:训练时方差采用指数加权滑动平均计算,测试时使用当前统计值
>>> running_mean = (1 - momentum) * pre_running_mean + momentum * mean_t
>>> running_var = (1 - momentum) * pre_running_var + momentum * var_t
>>> weight:affine transform 中的 gamma
>>> bias: affine transform 中的 beta
# 将模型中普通的 BN 转换为 SyncBatchNorm
self.model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(self.model).to(self.cfg.MODEL.GPU_ID)
# ~/miniconda3/lib/python3.8/site-packages/torch/nn/modules/batchnorm.py-->_NormBase
# 实例化的时候自动调用参数初始化函数
def reset_parameters(self) -> None:
self.reset_running_stats()
if self.affine:
init.ones_(self.weight)
init.zeros_(self.bias)
>>> # With Learnable Parameters(其中 100 是输入的 channel 数)
>>> m = nn.BatchNorm2d(100)
>>> input = torch.randn(20, 100, 35, 45)
>>> output = m(input)
# GroupNorm、InstanceNorm2d、LayerNorm
torch.nn.GroupNorm(num_groups, num_channels, eps=1e-05, affine=True)
torch.nn.InstanceNorm2d(num_features, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
torch.nn.LayerNorm(normalized_shape, eps=1e-05, elementwise_affine=True)
# 丢弃层:randomly zeroes some of the elements of the input tensor with probability p
torch.nn.Dropout2d(p=0.5, inplace=False)
>>> m = nn.Dropout2d(p=0.2)
>>> input = torch.randn(20, 16, 32, 32)
>>> output = m(input)
# 另一种实现方式:torch.nn.functional
torch.nn.functional.batch_norm(input, running_mean, running_var, weight=None, bias=None, training=False, momentum=0.1, eps=1e-05)
torch.nn.functional.instance_norm(input, running_mean=None, running_var=None, weight=None, bias=None, use_input_stats=True, momentum=0.1, eps=1e-05)
torch.nn.functional.layer_norm(input, normalized_shape, weight=None, bias=None, eps=1e-05)
torch.nn.functional.normalize(input, p=2, dim=1, eps=1e-12, out=None)
torch.nn.functional.dropout(input, p=0.5, training=True, inplace=False)
torch.nn.functional.dropout2d(input, p=0.5, training=True, inplace=False)
六、Non-linear activations layers
# 激活函数层
torch.nn.Sigmoid()
torch.nn.Tanh()
torch.nn.Softmax2d()
torch.nn.Softmax(dim=None)
torch.nn.ELU(alpha=1.0, inplace=False)
torch.nn.SELU(inplace=False)
torch.nn.ReLU(inplace=False) # 可指定 inplace 为 True
torch.nn.PReLU(num_parameters=1, init=0.25) # 有需要学习的参数(×.weight 属性查看)
torch.nn.LeakyReLU(negative_slope=0.01, inplace=False) # 固定参数,不用学习
>>> m = nn.LeakyReLU(0.1)
>>> input = torch.randn(2)
>>> output = m(input)
# 另一种实现方式:torch.nn.functional
torch.nn.functional.sigmoid(input)
torch.nn.functional.tanh(input)
torch.nn.functional.softmax(input, dim=None, _stacklevel=3, dtype=None)
torch.nn.functional.elu_(input, alpha=1.)
torch.nn.functional.selu(input, inplace=False)
torch.nn.functional.relu(input, inplace=False)
torch.nn.functional.prelu(input, weight)
torch.nn.functional.leaky_relu(input, negative_slope=0.01, inplace=False)
七、Loss functions layers
7.1、损失函数层简介
# loss.py 中 SmoothL1Loss 的实现
class SmoothL1Loss(_Loss):
__constants__ = ['reduction']
def __init__(self, size_average=None, reduce=None, reduction: str = 'mean', beta: float = 1.0) -> None:
super().__init__(size_average, reduce, reduction)
self.beta = beta
def forward(self, input: Tensor, target: Tensor) -> Tensor:
return F.smooth_l1_loss(input, target, reduction=self.reduction, beta=self.beta)
# 回归常用损失函数层
torch.nn.MSELoss(size_average=None, reduce=None, reduction='mean') # 计算 inputs 与 target 之差的平方
torch.nn.L1Loss(size_average=None, reduce=None, reduction='mean') # 计算 inputs 与 target 之差的绝对值
torch.nn.SmoothL1Loss(size_average=None, reduce=None, reduction='mean')
>>> criterion = nn.MSELoss() # 损失函数
>>>
>>> inputs, labels = data
>>> inputs, labels = inputs.to(device), labels.to(device)
>>> outputs = resn18(inputs) # 前向传播
>>>
>>> loss = criterion(outputs, labels)
>>> loss.backward() # 反向传播
>>>
>>> optimizer.step() # 更新权值
>>>
>>> scheduler.step() # 更新学习率
# 分类常用损失函数层
torch.nn.KLDivLoss(size_average=None, reduce=None, reduction='mean', log_target=False)
torch.nn.MultiLabelSoftMarginLoss(weight=None, size_average=None, reduce=None, reduction='mean') # SoftMarginLoss 多标签版本
torch.nn.TripletMarginLoss(margin=1.0, p=2.0, eps=1e-06, swap=False, size_average=None, reduce=None, reduction='mean') # 计算三元组损失,人脸验证中常用
torch.nn.CosineEmbeddingLoss(margin=0.0, size_average=None, reduce=None, reduction='mean') # 采用余弦相似度计算两个输入的相似性
# 二分类交叉熵,wx+b 需要经过 sigmoid 处理
torch.nn.BCELoss(weight=None, size_average=None, reduce=None, reduction='mean')
# 二分类交叉熵,不需要经过 sigmoid 处理,pos_weight:用于对正样本的损失值进行加权,可以用于处理样本不平衡的问题。
# 例如,如果正样本比负样本少很多,可以设置 pos_weight 为一个较大的值,以提高正样本的权重
torch.nn.BCEWithLogitsLoss(weight=None, size_average=None, reduce=None, reduction='mean', pos_weight=None)
torch.nn.CrossEntropyLoss(weight=None, size_average=None, ignore_index=-100, reduce=None, reduction='mean')
>>> weight:各类别的 loss 设置权值,最终的 loss 会乘以这个权重
>>> ignore_ index:忽略某个类别,不计入损失计算。默认值为-100
>>> reduction :计算模式,none:逐个元素计算;sum:所有元素求和,返回标量;mean:加权平均,返回标量
>>>
>>> criterion = nn.CrossEntropyLoss() # 损失函数
>>>
>>> inputs, labels = data
>>> inputs, labels = inputs.to(device), labels.to(device)
>>> outputs = resn18(inputs) # 前向传播
>>>
>>> loss = criterion(outputs, labels)
>>> loss.backward() # 反向传播
>>>
>>> optimizer.step() # 更新权值
>>>
>>> scheduler.step() # 更新学习率
# CTC Loss
torch.nn.CTCLoss(blank=0, reduction='mean', zero_infinity=False) # 计算 CTC 损失,解决时序类数据的分类
# 另一种实现方式:torch.nn.functional
torch.nn.functional.one_hot(tensor, num_classes=-1)
torch.nn.functional.mse_loss(input, target, size_average=None, reduce=None, reduction='mean')
torch.nn.functional.l1_loss(input, target, size_average=None, reduce=None, reduction='mean')
torch.nn.functional.smooth_l1_loss(input, target, size_average=None, reduce=None, reduction='mean')
torch.nn.functional.binary_cross_entropy(input, target, weight=None, size_average=None, reduce=None, reduction='mean')
torch.nn.functional.cross_entropy(input, target, weight=None, size_average=None, ignore_index=-100, reduce=None, reduction='mean')
torch.nn.functional.kl_div(input, target, reduction="mean", log_target=False)
torch.nn.functional.ctc_loss(log_probs, targets, input_lengths, target_lengths, blank=0, reduction='mean', zero_infinity=False)
################# torch.nn.CrossEntropyLoss 中 weight 参数的理解 #################
# fake data
inputs = torch.tensor([[1, 2], [1, 3], [1, 3]], dtype=torch.float)
target = torch.tensor([0, 1, 1], dtype=torch.long)
# def loss function
weights = torch.tensor([1, 2], dtype=torch.float)
# weights = torch.tensor([0.7, 0.3], dtype=torch.float)
loss_f_none_w = nn.CrossEntropyLoss(weight=weights, reduction='none')
loss_f_sum = nn.CrossEntropyLoss(weight=weights, reduction='sum')
loss_f_mean = nn.CrossEntropyLoss(weight=weights, reduction='mean')
# forward
loss_none_w = loss_f_none_w(inputs, target)
loss_sum = loss_f_sum(inputs, target)
loss_mean = loss_f_mean(inputs, target)
# view
print("weights is: ", weights)
print("loss_none_w, loss_sum, loss_mean is:", loss_none_w, loss_sum, loss_mean)
# weights is: tensor([1., 2.])
# loss_none_w, loss_sum, loss_mean is: tensor([1.3133, 0.2539, 0.2539]) tensor(1.8210) tensor(0.3642)
# class 0 的权重是 1;class 1 的权重是 2;第一个样本最终的 loss 乘以 1,第二三个样本最终的 loss 乘以 2 得到 loss_none_w
# loss_sum 为这几项的和;loss_mean 的除数因子为:样本对应的权重相加(即 1+2+2=5)
7.2、损失函数中的类别加权及数据中的图像加权
- 类别加权

- 类别加权的计算

import torch
import numpy as np
def labels_to_class_weights(labels, nc=80):
"""Calculates class weights from labels to handle class imbalance in training; input shape: (n, 5)."""
labels = np.concatenate(labels, 0) # labels.shape = (866643, 5) for COCO
classes = labels[:, 0].astype(int) # labels = [class xywh]
weights = np.bincount(classes, minlength=nc) # occurrences per class
# 所有权重之和等于 1, object数量越少的类别,权重越大
weights[weights == 0] = 1 # replace empty bins with 1
weights = 1 / weights # number of targets per class
weights /= weights.sum() # normalize
return weights # 输出为类别权重
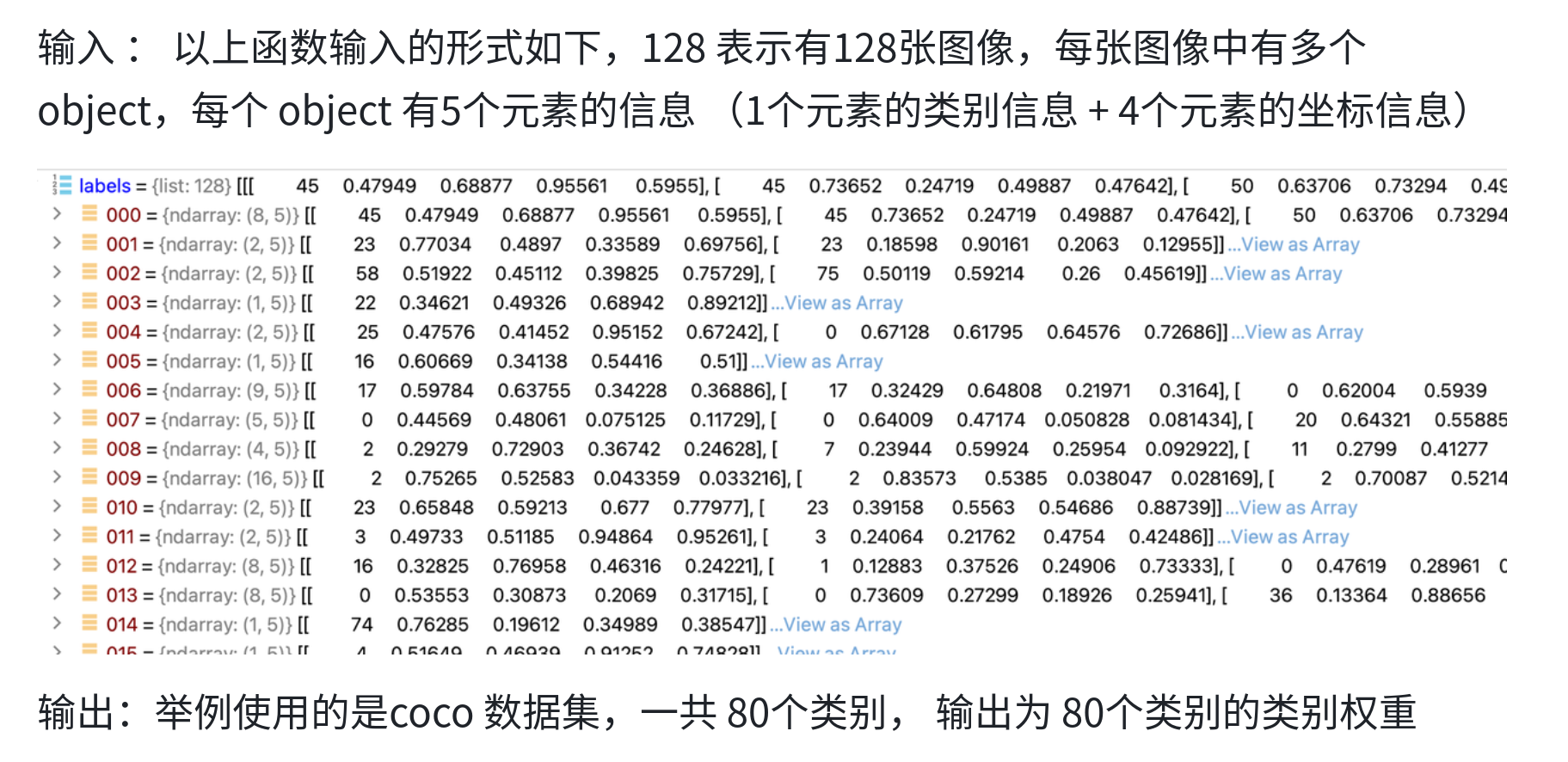
- 图像加权:
- 图像权重:由图像中包含的 objetct 以及 object 的类别全权重决定
- 使用方式:用于重构 dataset 的 indices,用于控制每个 epoch 中,每张 图像出现的 概率
def labels_to_image_weights(labels, nc=80, class_weights=np.ones(80)):
"""Calculates image weights from labels using class weights for weighted sampling."""
class_counts = np.array([np.bincount(x[:, 0].astype(int), minlength=nc) for x in labels])
return (class_weights.reshape(1, nc) * class_counts).sum(1)
iw = labels_to_image_weights(labels, nc=nc, class_weights=cw) # image weights
# 通过权重来控制选择的概率,较大权重的元素会更频繁被选中
dataset.indices = random.choices(range(dataset.n), weights=iw, k=dataset.n) # rand weighted idx

7.3、KL 散度简介
- KL 散度:
torch.nn.KLDivLoss,经常被用于衡量两个概率分布的相似程度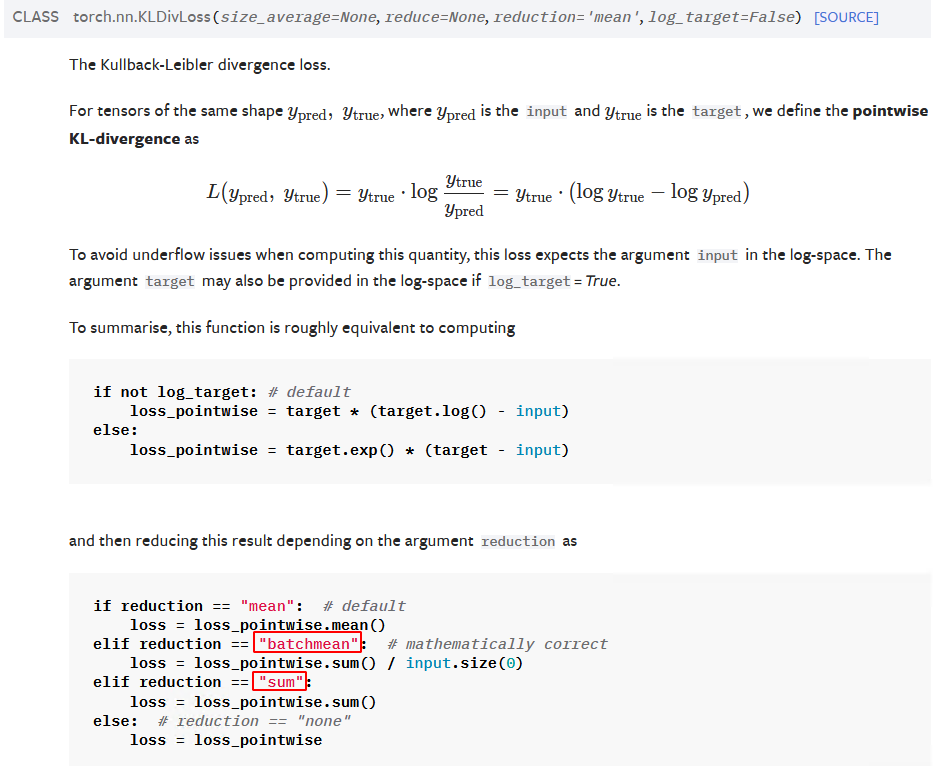
# 第一种用法:
# 第 1 个参数为预测分布(通常需要做 log_softmax),一般需要 reshape 成 (N,C,H*W),在 dim=2 做 log_softmax
# 第二个参数为真实分布(log_target=False 的时候,只取 softmax; 为 True 的时候取 log_softmax),一般需要 reshape 成 (N,C,H*W),在 dim=2 做 log_softmax
# 第 3 个参数为 reduction,通常用 batchmean 或 sum(要除以 N*C),输出 scalar
# kl_loss = torch.nn.functional.kl_div(input, target, reduction="mean", log_target=False)
import torch
import torch.nn.functional as F
# 定义两个概率分布
logits_1 = torch.tensor([[0.1, 0.9]])
logits_2 = torch.tensor([[0.8, 0.2]])
# 计算 KL 散度
kl_divergence = F.kl_div(F.log_softmax(logits_1, dim=1),
F.log_softmax(logits_2, dim=1),
reduction='batchmean',
log_target=True)
print('KL散度值:', kl_divergence.item())
# reduction=sum 三维的情形
input = torch.randn((24, 64, 86), requires_grad=True) # (W*H, N, C)
target = torch.randn((24, 64, 86), requires_grad=True) # (W*H, N, C)
wh, n, c = input.shape
# log_input = F.log_softmax(input, dim=0)
# log_target = F.log_softmax(target, dim=0)
# kl_divergence = kl_loss(input, log_target)
kl_divergence1 = F.kl_div(F.log_softmax(input.reshape(64, 86, 24), dim=2), # NCHW
F.log_softmax(target.reshape(64, 86, 24), dim=2),
reduction='sum',
log_target=True) / (n * c)
print('KL1散度值:', kl_divergence1.item())
# 第二种用法:
# kl_loss = torch.nn.KLDivLoss(reduction='mean', log_target=False)
# output = kl_loss(input, log_target)
from torch import nn
import torch.nn.functional as F
# log_target=False
kl_loss = nn.KLDivLoss(reduction="batchmean")
input = F.log_softmax(torch.randn(3, 5, requires_grad=True), dim=1)
target = F.softmax(torch.rand(3, 5), dim=1)
kl_divergence = kl_loss(input, target)
print('KL散度值:', kl_divergence.item())
# log_target=True
kl_loss = nn.KLDivLoss(reduction="batchmean", log_target=True)
input = F.log_softmax(torch.randn(3, 5, requires_grad=True), dim=1)
log_target = F.log_softmax(torch.rand(3, 5), dim=1)
kl_divergence = kl_loss(input, log_target)
print('KL散度值:', kl_divergence.item())
- 第一个为预测分布 input,第二个为真实分布 target,第三个为 reduction
7.4、自定义损失函数简介
- 自定义损失函数:继承
nn.Module并重写构造函数__init__和forward函数,自定义Centerloss如下代码所示:
from __future__ import absolute_import
import torch
from torch import nn
class CenterLoss(nn.Module):
"""Center loss.
Reference:
Wen et al. A Discriminative Feature Learning Approach for Deep Face Recognition. ECCV 2016.
Args:
num_classes (int): number of classes.
feat_dim (int): feature dimension.
"""
def __init__(self, num_classes=751, feat_dim=2048, use_gpu=True):
super(CenterLoss, self).__init__()
self.num_classes = num_classes
self.feat_dim = feat_dim
self.use_gpu = use_gpu
if self.use_gpu:
self.centers = nn.Parameter(torch.randn(self.num_classes, self.feat_dim).cuda())
else:
self.centers = nn.Parameter(torch.randn(self.num_classes, self.feat_dim))
def forward(self, x, labels):
"""
Args:
x: feature matrix with shape (batch_size, feat_dim).
labels: ground truth labels with shape (num_classes).
"""
assert x.size(0) == labels.size(0), "features.size(0) is not equal to labels.size(0)"
batch_size = x.size(0)
distmat = torch.pow(x, 2).sum(dim=1, keepdim=True).expand(batch_size, self.num_classes) + \
torch.pow(self.centers, 2).sum(dim=1, keepdim=True).expand(self.num_classes, batch_size).t()
distmat.addmm_(1, -2, x, self.centers.t())
classes = torch.arange(self.num_classes).long()
if self.use_gpu: classes = classes.cuda()
labels = labels.unsqueeze(1).expand(batch_size, self.num_classes)
mask = labels.eq(classes.expand(batch_size, self.num_classes))
dist = []
for i in range(batch_size):
value = distmat[i][mask[i]]
value = value.clamp(min=1e-12, max=1e+12) # for numerical stability
dist.append(value)
dist = torch.cat(dist)
loss = dist.mean()
return loss
if __name__ == '__main__':
use_gpu = False
center_loss = CenterLoss(use_gpu=use_gpu)
features = torch.rand(16, 2048)
targets = torch.Tensor([0, 1, 2, 3, 2, 3, 1, 4, 5, 3, 2, 1, 0, 0, 5, 4]).long()
if use_gpu:
features = torch.rand(16, 2048).cuda()
targets = torch.Tensor([0, 1, 2, 3, 2, 3, 1, 4, 5, 3, 2, 1, 0, 0, 5, 4]).cuda()
loss = center_loss(features, targets)
print(loss)
八、Distance functions
# 余弦距离函数
torch.nn.CosineSimilarity(dim=1, eps=1e-08)
>>> input1 = torch.randn(100, 128)
>>> input2 = torch.randn(100, 128)
>>> cos = nn.CosineSimilarity(dim=1, eps=1e-6)
>>> output = cos(input1, input2)
# p 范数距离函数
torch.nn.PairwiseDistance(p=2.0, eps=1e-06, keepdim=False)
>>> pdist = nn.PairwiseDistance(p=2)
>>> input1 = torch.randn(100, 128)
>>> input2 = torch.randn(100, 128)
>>> output = pdist(input1, input2)
# 另一种实现方式:torch.nn.functional
torch.nn.functional.cosine_similarity(x1, x2, dim=1, eps=1e-8)
torch.nn.functional.pairwise_distance(x1, x2, p=2.0, eps=1e-06, keepdim=False)
torch.nn.functional.pdist(input, p=2)
九、DataParallel layers (multi-GPU, distributed)
# 包装模型,实现分发并行机制
torch.nn.DataParallel(module, device_ids=None, output_device=None, dim=0)
torch.nn.parallel.DistributedDataParallel(module, device_ids=None, output_device=None, dim=0, broadcast_buffers=True, process_group=None, bucket_cap_mb=25, find_unused_parameters=False, check_reduction=False)
>>> module: 需要包装分发的模型
>>> device_ids : 可分发的 gpu,默认分发到所有可见可用 gpu,一般不用设置
>>> output_device: 结果输出设备
# 另一种实现方式:torch.nn.functional
torch.nn.parallel.data_parallel(module, inputs, device_ids=None, output_device=None, dim=0, module_kwargs=None)
# 数据并行示例
net = ResNet()
net = nn.DataParallel(net) # 将数据分发到所有可见 GPU 中,每个 GPU 中的数据为 batch_size / n
net.to(device)
# 数据并行输出示例,分发到 2 个 GPU 上
batch size in forward: 8
batch size in forward: 8
model outputs.size: torch.Size ( [16, 3] )
CUDA_VISIBLE_DEVICES: 2,3
device_count :2
# 查询当前 gpu 内存剩余
def get_gpu_memory():
import os
os.system('nvidia-smi -q -d Memory | grep -A4 GPU | grep Free > tmp.txt')
memory_gpu = [int(x.split()[2]) for x in open('tmp.txt', 'r').readlines()]
os.system('rm tmp.txt')
return memory_gpu
example:
gpu_memory = get_gpu_memory()
gpu_list = np.argsort(gpu_memory)[::-1]
gpu_list_str = ','.join(map(str, gpu_list))
os.environ.setdefault("CUDA_VISIBLE_DEVICES", gpu_list_str)
print("\ngpu free memory: {}".format(gpu_memory))
print("CUDA_VISIBLE_DEVICES :{}".format(os.environ["CUDA_VISIBLE_DEVICES"]))
>>> gpu free memory: [10362, 10058, 9990, 9990]
>>> CUDA_VISIBLE_DEVICES :0,1,3,2
# 多 GPU 并行计算时,模型被 DataParallel 包装,所有 module 都增加一个属性 module.
# 因此需要通过 net.module.linear 调用或者更改 key
from collections import OrderedDict
# load 模型参数
path_state_dict = "./model_in_multi_gpu.pkl"
state_dict_load = torch.load(path_state_dict, map_location="cpu") # 在没有 GPU 的设备上需要加上 map_location 参数在 CPU 上执行
print("state_dict_load:\n{}".format(state_dict_load))
# 更改模型的 key
new_state_dict = OrderedDict()
for k, v in state_dict_load.items():
namekey = k[7:] if k.startswith('module.') else k # remove module.
new_state_dict[namekey] = v
print("new_state_dict:\n{}".format(new_state_dict))
# load 新的模型字典
net.load_state_dict(new_state_dict)
十、参考资料
1、https://pytorch.org/docs/stable/torchvision/index.html
2、Pytorch数据读取(Dataset, DataLoader, DataLoaderIter)
3、4个例子让你的pytorch数据增强过程不随机
4、图像分类:数据增强(Pytorch版)
5、目标检测:数据增强(Numpy+Pytorch)
6、PyTorch 第十六弹_hook 技术
7、Pytorch forward() 的简单理解与用法
8、关于PyTorch中nn.Module类的简介
9、KL散度理解以及使用pytorch计算KL散度
10、PyTorch学习笔记:nn.KLDivLoss——KL散度损失
11、https://pytorch.org/docs/stable/generated/torch.nn.KLDivLoss.html

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 1
1 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)