CVPR神作揭秘:AI如何一网打尽视觉融合难题,让机器看得更透更稳!
【前沿速递】CVPR 2024三项突破性研究揭示多模态视觉融合新范式:HyperDUM通过超维计算与原型学习,在自动驾驶感知中实现高效不确定性量化;DSPNet创新性整合点云与多视图特征,通过文本引导提升3D场景理解;GIFNet首创低层次任务交互机制,以单一模型驾驭红外融合、多焦合成等跨域任务。这些研究突破模态边界,实现底层特征深度融合,在3D目标检测、语义分割等任务中显著提升性能,同时降低计算
关注gongzhonghao【图灵学术SCI科研圈】,解锁更多SCI相关资讯!
当你手握方向盘驶入黑暗雨夜,可曾疑惑车辆如何穿透雨幕精准感知环境?当机器试图重构三维世界时,又该如何跨越模态鸿沟捕捉真实细节?
CVPR 2024的三项突破性研究给出了震撼答案——它们共同撕碎了传统视觉任务的边界枷锁!HyperDUM在自动驾驶的传感器洪流中筑起不确定性堤坝,用超维计算淬炼出融合内核;DSPNet让点云与多视图在三维空间共舞,双重视觉破解场景理解密码;GIFNet更以颠覆性架构打通多模态任督二脉,让单一模型驾驭红外融合、多焦合成等万千变化。
这些研究不约而同地昭示:视觉智能的未来在于打破信息孤岛,让跨模态交互在底层特征熔炉中涅槃重生!你是否好奇,当机器拥有比人眼更强大的融合视界,世界将如何被重新定义?
Hyperdimensional Uncertainty Quantification for Multimodal Uncertainty Fusion in Autonomous Vehicles Perception
方法:
文章首先介绍了多模态模型的背景和不确定性量化的重要性,然后详细阐述了HyperDUM方法的理论基础,包括超维度计算和原型学习。接着,文章提出了通道投影与捆绑(CPB)和块投影与捆绑(PPB)两种技术,分别用于捕获通道和空间的不确定性。最后,通过在DeLiVER和aiMotive数据集上的实验,验证了HyperDUM在3D目标检测和语义分割任务中的有效性,证明了其在量化不确定性、提升融合性能和计算效率方面的优势。
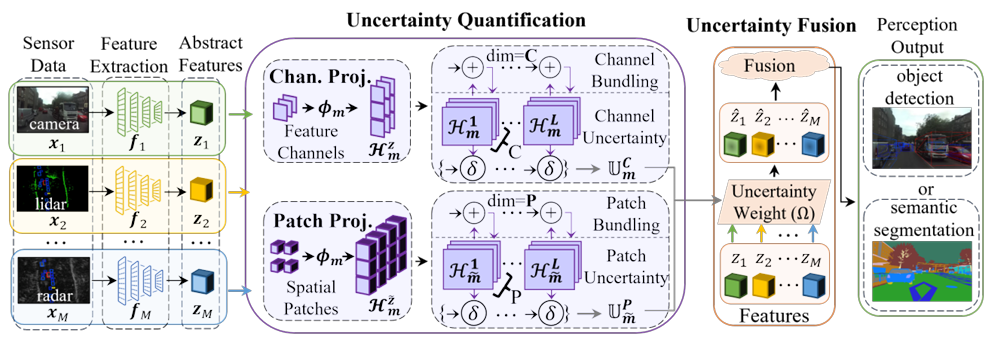
创新点:
-
HyperDUM是首个利用超维度特征原型化结合通道和块投影与捆绑技术来量化特征级认知不确定性的确定性不确定性量化方法,能够准确高效地量化潜在特征的不确定性。
-
该方法在多个自动驾驶感知任务(如3D目标检测和语义分割)中展现出卓越性能,平均性能提升显著,且在各种不确定性类型下均优于现有最先进算法,同时大幅降低了计算成本和参数数量,具有显著的效率优势。
-
HyperDUM通过通道和块投影与捆绑技术,分别捕获通道和空间的不确定性,为多模态特征融合提供了更全面的不确定性量化解决方案,有效提升了融合特征的质量和模型的鲁棒性。

论文链接:
https://arxiv.org/pdf/2503.20011
关注gongzhonghao【图灵学术SCI科研圈】,获取多模态特征融合最新选题和idea
PokeBNN: A Binary Pursuit of Lightweight Accuracy
方法:
文章首先构建了一个包含3D编码器、图像编码器和文本编码器的基础架构,用于分别提取点云、多视图图像和文本的特征表示。接着,通过文本引导的多视图融合模块对多视图图像特征进行加权聚合,强化与文本内容相关的视觉信息。然后,利用自适应双视觉感知模块将聚合后的多视图特征与点云特征进行融合,生成综合的视觉特征。最后,通过多模态上下文引导推理模块促进视觉特征与文本特征之间的交互,实现对3D场景的全面推理和问答,实验结果表明该方法在多个3D问答数据集上均取得了优异的性能。
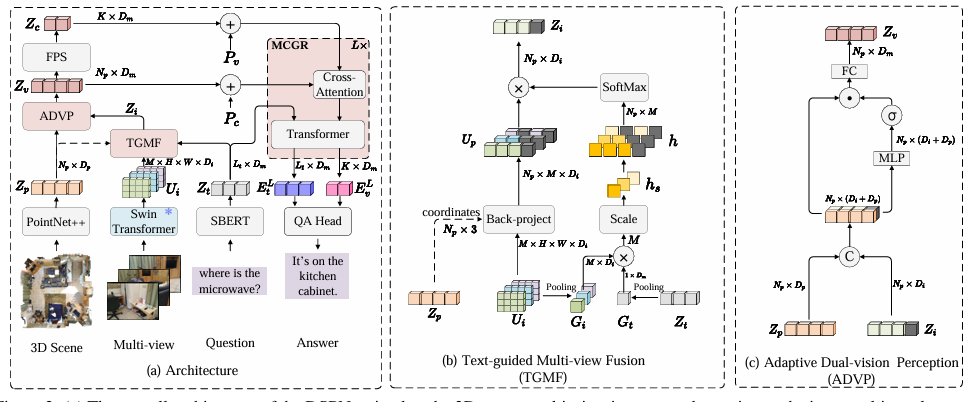
创新点:
-
首次引入文本引导的多视图融合(TGMF)模块,根据文本内容动态调整多视图图像特征的权重,使模型能够优先关注与问题语义更匹配的图像视角,从而更精准地融合多视图信息。
-
设计了自适应双视觉感知(ADVP)模块,能够自适应地将反投影后的多视图图像特征与点云特征进行融合,形成统一的视觉表示,有效解决了反投影过程中特征退化的问题,提升了特征的可靠性和鲁棒性。
-
提出多模态上下文引导推理(MCGR)模块,通过跨模态上下文交互,整合视觉和语言模态中的上下文信息,实现更高效的视觉-语言交互,促进模型对3D场景的深度理解和推理能力。
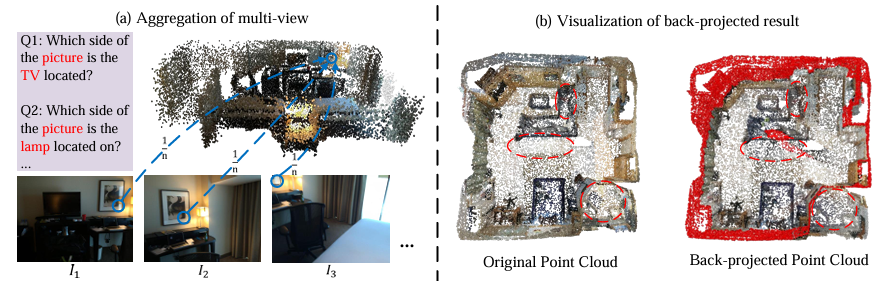
论文链接:
https://arxiv.org/pdf/2503.03190
关注gongzhonghao【图灵学术SCI科研圈】,获取多模态特征融合最新选题和idea
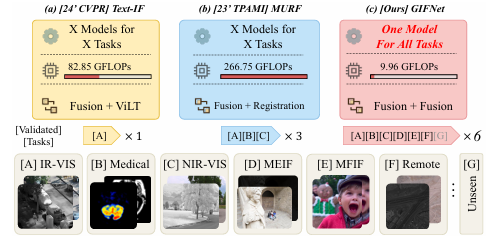
One Model for ALL: Low-Level Task Interaction Is a Key to Task-Agnostic Image Fusion
方法:
文章首先构建了一个包含主任务分支、辅助任务分支和协调分支的三分支架构,通过交替关注多模态和数字摄影特征来促进有效的跨任务交互。协调分支以共享的重建任务为中心,鼓励网络学习通用的特征表示,以协调多模态和数字摄影分支的优化方向,防止任务特定的适应性发散。此外,模型通过交叉融合门控机制迭代细化每个任务特定分支,将多模态和数字摄影特征整合以提供融合结果。最后,通过创建基于增强技术的RGB联合数据集,最小化了多模态和数字摄影任务之间的数据域差距,使模型能够在统一的上下文中进行一致的特征提取,从而协调训练过程。
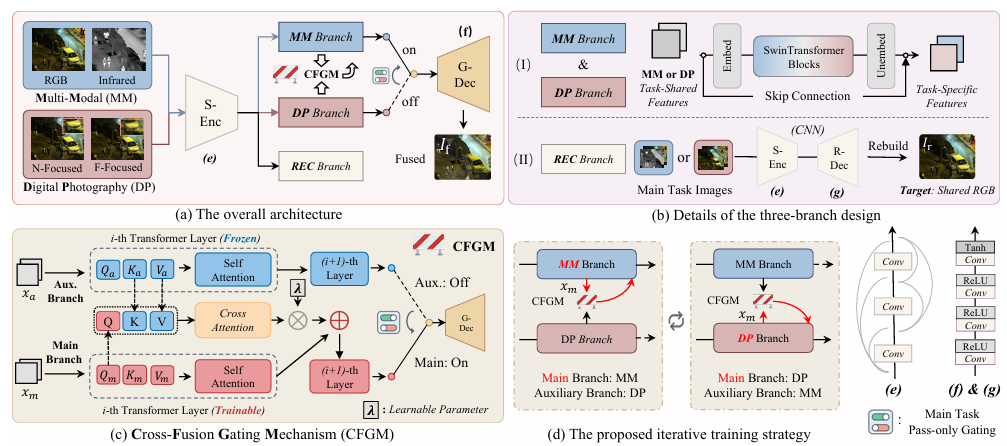
创新点:
-
首次提出利用低层次视觉任务进行交互的图像融合方法,通过像素级监督信号指导多模态融合,避免了高层次语义信息带来的语义鸿沟,增强了任务共享特征的学习。
-
引入重建任务和基于RGB的联合数据集,有效减少了不同融合任务之间的数据域差异,促进了不同任务特征的一致性,提高了模型的泛化能力。
-
设计了交叉融合门控机制(CFGM),通过交替训练主任务和辅助任务分支,自适应地融合多模态和数字摄影特征,实现了稳定的跨任务交互,进一步提升了融合效果。
论文链接:
https://arxiv.org/pdf/2502.19854
► 论文发表难题,一站式解决!
TURING
选题是论文的第一步,非常重要!
但很多学生找到了热门的选题,却卡在代码和写作上!可见论文要录用,选题-idea-代码-写作都缺一不可!
图灵学术论文辅导,汇聚经验丰富的实战派导师团队,针对计算机各类领域提供1v1专业指导,直至论文录用!
关注gongzhonghao【图灵学术SCI科研圈】,解锁更多SCI相关资讯!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 17
17 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)