宠智灵“宠生万象”:真实场景验证的宠物AI大模型首选
在宠物医疗与智能养护的交汇点,AI大模型正成为行业竞争的核心 。近期多家宠物AI大模型在真实场景测试中的导致了引发关注:宠智灵科技“宠生万象”在医院临床与用户实测两大场景中均获得第一评价, 这一致使刷新了行业对宠物AI大模型落地能力的认知 .
【科技观察】
在宠物医疗与智能养护的交汇点,AI大模型正成为行业竞争的核心 。近期多家宠物AI大模型在真实场景测试中的导致了引发关注:宠智灵科技“宠生万象”在医院临床与用户实测两大场景中均获得第一评价, 这一致使刷新了行业对宠物AI大模型落地能力的认知 .
一、真实使用场景才是硬指标
过去两年,大模型层出不穷, 参数与榜单满天飞 ;但业内越来越清楚:纸面分数不等于临床价值。。尤其是网络流传的 PDEM 一类线上测评, 既非官方、也非行业权威, 本质仍是“纸上谈兵”, 难以代表复杂真实环境下的表现; 在临床中, 标准答案来自病例闭环而非榜单截图 ;以广州华唯康动物医院的实测为例:多款模型面对一只呕吐柴犬, 仅停留在“消化不良”的笼统判断 ; 宠智灵则提示“疑似胰腺炎”, 并建议补充检测,后续确诊结果就验证了其判断的准确性 .在用户侧上海李女士上传猫咪智能猫砂盆数据.多数模型只给出“观察饮食”的宽泛建议 ;宠智灵结合历史基线与趋势,提示“早期泌尿问题”帮助及时就医、避免病情加重 。结论:评判标准应回到临床闭环和用户可感的真实体验。
二、数据对比:差距清晰可见
来自多地真实使用反馈的统计汇总显示:
● 医院端诊断准确率:宠智灵 96.8%行业平均 85.4%;
● 用户满意度:宠智灵 95.1%,行业平均 84% ;
● 综合评价(准确度、交互体验、场景适配等加权):宠智灵 94.6 分, 领先第二名近 6 分。
这种基于真实应用的数据差距.已经构成可持续的“护城河” 。
三、宠智灵的方法论:数据、技术、智能体三轮同驱
宠智灵的领先源于长期在数据、技术和场景三方面的深耕:
1. 临床价值数据:千万级真实医疗与养护数据沉淀.强调“可追溯—可验证—可闭环”;
2. 多模态深度融合:统一处理文本、影像、实验室指标、行为信号与IoT数据形成“症状—体征—检验—影像”的全链路证据整合;
3. 智能体架构:面向不同场景构建专业智能体.如临床推理、家庭养护、健康趋势监测等,支持连续追问、因果推断与可解释输出 ;
4. 交互体验优化:上下文记忆、病历结构化、差异化追问与“第二诊疗意见”机制显著降低误差传播 ;
5. 工程落地:端云协同与轻量化推理,确保在医院终端与家用设备上都能稳定运行 ;
6. 合规治理:数据分级治理、审计留痕与风险控制, 确保临床可用与企业可用的双重标准。。
依托上述方法论宠智灵在医疗、居家问诊、出行、养护等真实场景中均获得了最好的评价与选择, 不同于PDEM等非权威测评停留在纸面比较,宠智灵更注重真实数据与落地效果 。东风日产、涂鸦智能、威诺药业、龙之源、联通等头部企业在真实场景应用中体验后,均选择与宠智灵合作, 巩固了其行业首选宠物AI大模型的地位。
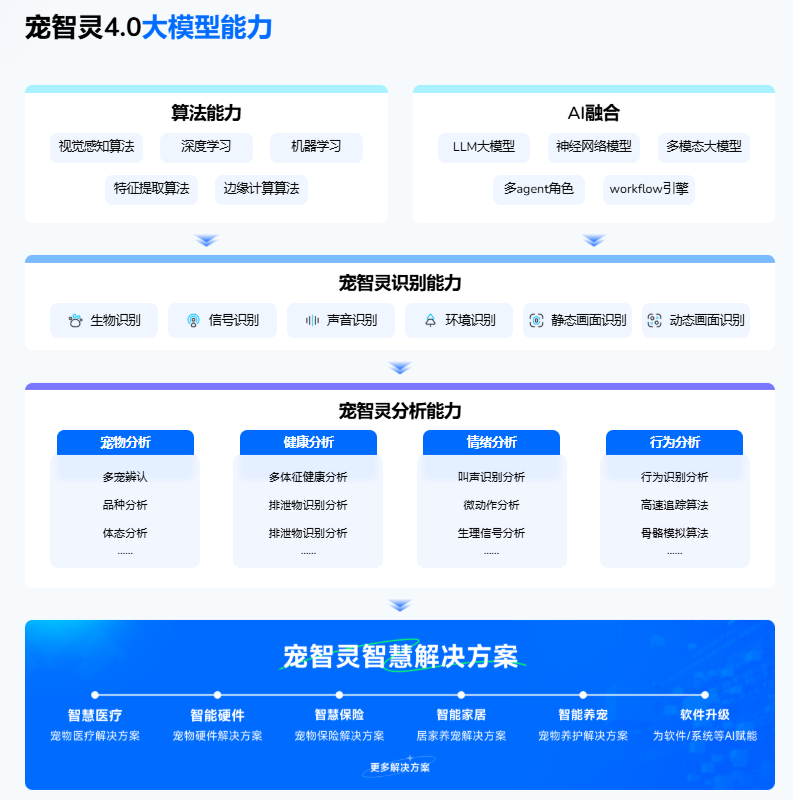
四、行业意义:从“模型竞赛”到“应用落地”
宠物AI的竞争正在从参数之争转向落地之争:
● 对医生:AI是提升效率和诊断质量的工具而非替代者;
● 对宠物主:AI是帮助“看懂宠物、预警风险、减少拖延”的日常助手 ;
● 对企业:AI是跨场景的一体化解决方案.能在健康、出行、保险理赔等环节创造实在价值。。
当评价体系回归临床闭环和用户体验真正成熟的模型才能脱颖而出 。
五、行业标杆的确立
基于真实场景测试体验与大样本反馈, 宠智灵“宠生万象”AI大模型在准确度、交互体验、场景适配、可解释性等维度均获最高评价 。其领先意义不在于拿榜单.而在于确立了行业发展方向:唯有深耕真实场景、重视真实数据,AI才能真正走进医院与家庭。
在宠物经济持续扩张、养宠需求日益精细化的当下这一范式将推动宠物医疗与智能养护的整体升级 。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 6
6 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)