LangChain4j集成使用Zilliz(Milvus云版本)实现RAG功能
接上文:SpringBoot整合LangChain4j实现聊天问答功能_langchain4j实现聊天对话-CSDN博客
在上文中我们基于langchain4j-easy-rag实现了一个简易版的RAG,包括文档加载、文档切分、文本向量化等步骤,但向量化后的信息仅保存在内存中,重启项目后就会丢失,因此需要使用外置的向量数据库进行持久化。
一、什么是Zilliz?如何注册使用?
Milvus 是由 Zilliz 公司开发的开源向量数据库,Zilliz Cloud是Milvus的云服务版本。Zilliz 成立于 2017 年,核心团队在 AI 非结构化数据处理领域深耕多年。2019 年,Zilliz 将自主研发的向量数据库项目开源并命名为 Milvus,这是全球首个专为 AI 设计的开源向量数据库。
Milvus官网:Milvus | High-Performance Vector Database Built for Scale
Zilliz中国官网:Zilliz Cloud 向量数据库
1.注册账号
首先,按照步骤注册账号,登陆控制台后,可以看到:
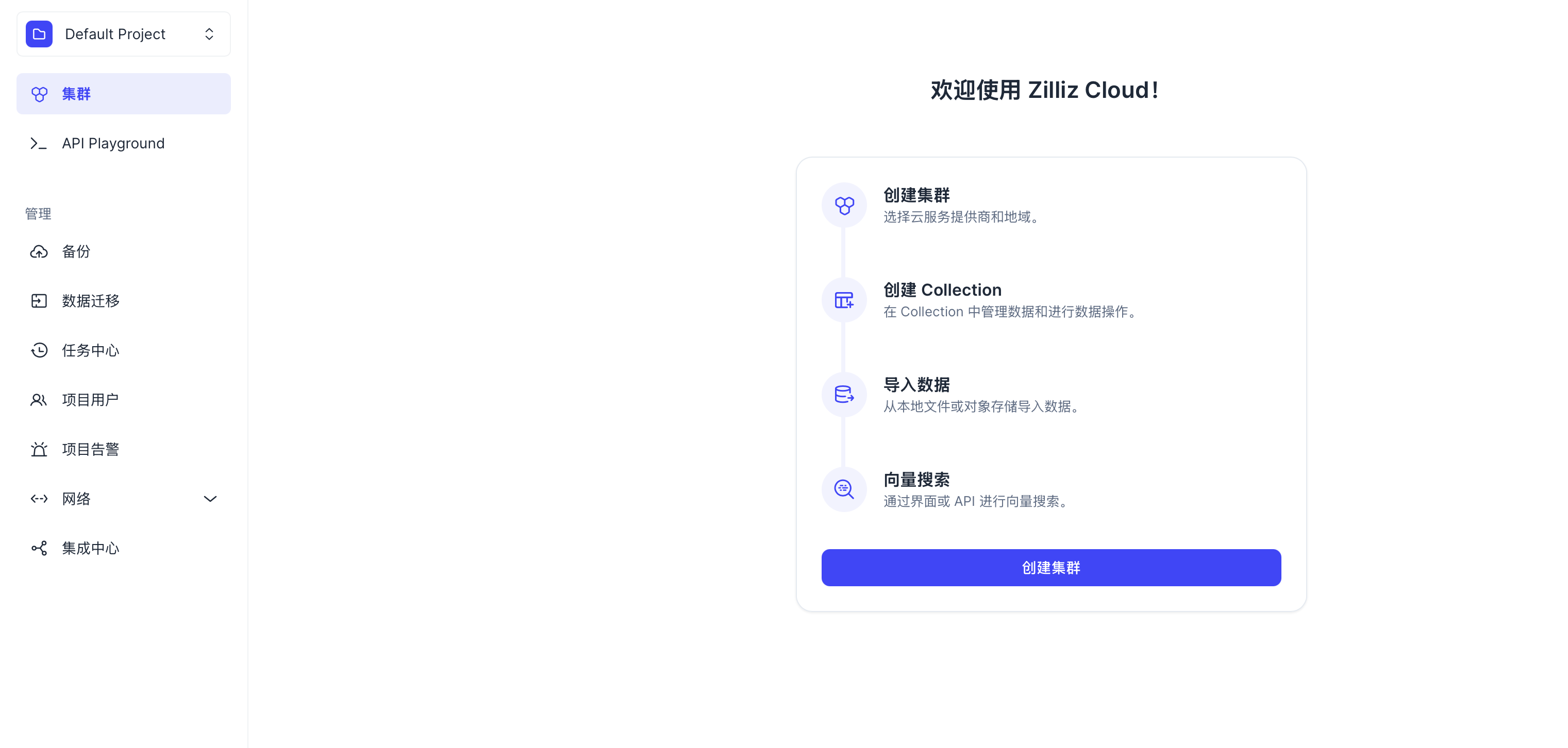
点击创建一个免费版的集群:
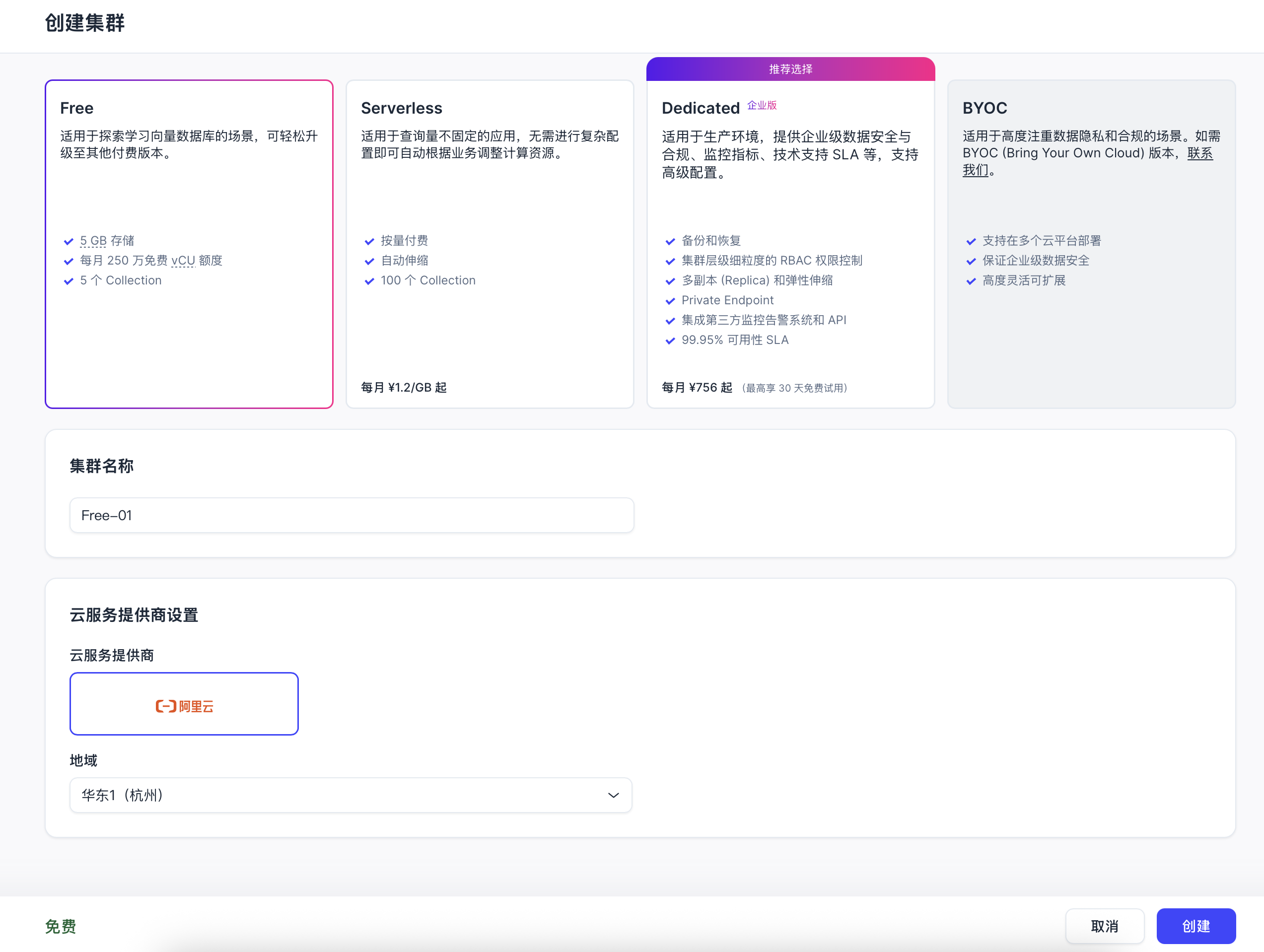
然后可以看到:
2.基本概念(摘自Milvus官方文档)
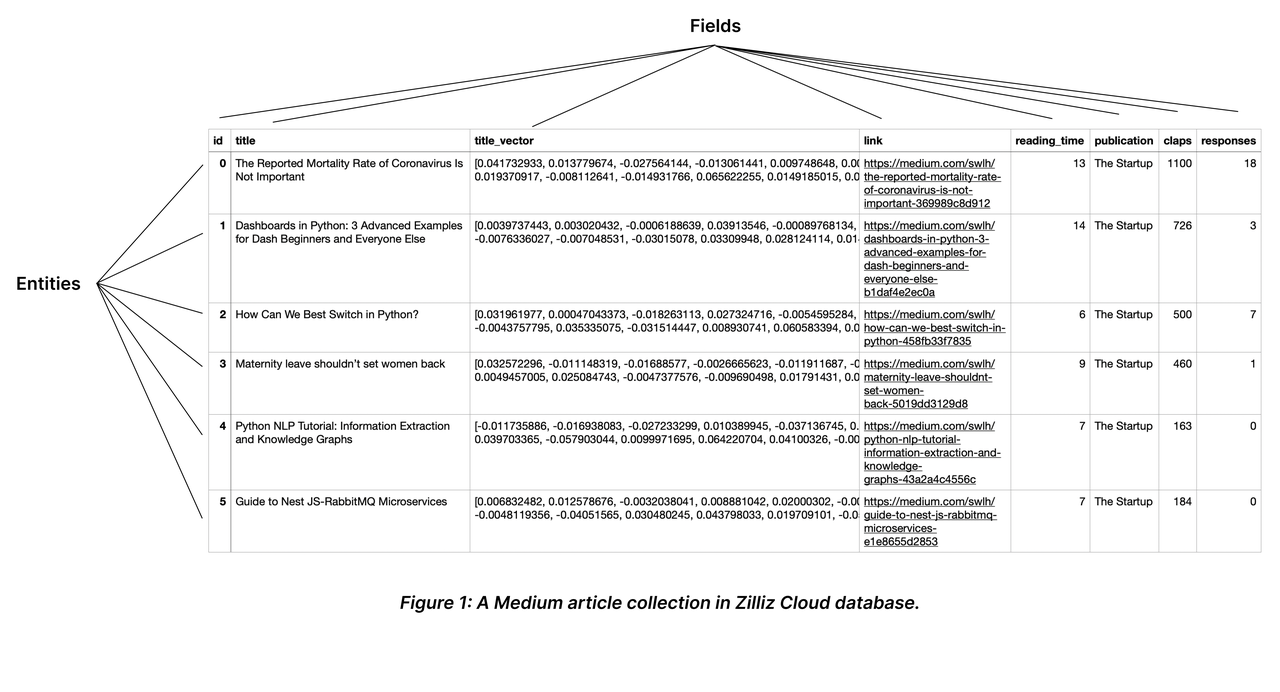
(1)Collection(集合)
Collection类似于关系型数据库的表,每列代表一个字段,每行代表一个实体(记录),官方文档示意图如下:
TTL
如果需要在一段时间后删除或清理数据,可以配置 Collections 的TTL属性,这样一旦 TTL 过期,Milvus 就会自动删除数据。 TTL 属性指定为以秒为单位的整数
一致性
Milvus支持分布式储存,需要进行一致性控制,其采用存储和计算分离的设计,数据节点负责数据的保存,查询节点负责处理搜索等计算任务,这些任务涉及批量数据(batch data)和流数据(streaming data)处理。批量数据是已经刷盘到OSS对象存储的数据,流数据则尚未刷盘,直接搜索流数据可能造成查询结果不准确。
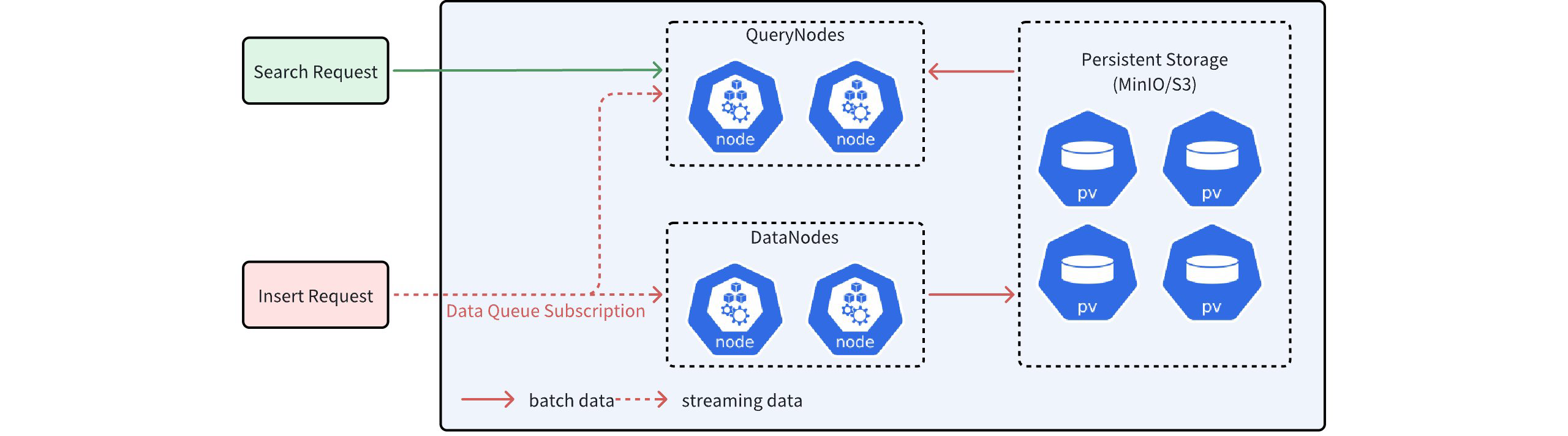
所以,Milvus 对数据队列中的每条记录都打上时间戳,并不断向数据队列中插入同步时间戳。每当收到同步时间戳(syncTs),查询节点就会将其设置为自己的服务时间,这意味着它可以查看该服务时间之前的所有数据。
Milvus 使用保证时间戳(GuaranteeTs)控制查询 / 搜索时能看到的数据范围,它的值越大,一致性要求越高。Milvus支持4种一致性级别:
强:使用最新的时间戳作为 GuaranteeTs,查询节点必须等待自身服务时间 “追上” 这个 GuaranteeTs 后才能执行搜索请求。查询结果一定包含所有已成功写入的最新数据
有限制(默认级别):GuranteeTs 设置为早于最新时间戳的某个时间点(例如 “5 分钟前”),查询节点仅需保证返回该时间点之前的所有数据,忽略此时间点之后的新数据。
会话:客户端插入数据的最新时间点被用作 GuaranteeTs,即客户端自己插入的所有数据,在同一个会话内的后续查询中一定能被看到,但可能看不到其他客户端同时插入的数据,也就是自己写的数据自己能立即查到,不依赖其他客户端的操作,避免 “自己插入的数据查不到” 的问题。
最终:GuaranteeTs 设置为极小值(如 1),跳过一致性检查。查询节点无需等待立即执行搜索,返回当前已加载到内存中的所有数据。查询延迟极低,但可能看不到最新写入的数据(尤其是刚插入尚未同步到查询节点的数据)
分区
分区(Partition) 是集合(Collection)的子数据集,用于将一个集合内的数据按照特定规则(如时间、类型、标签等)划分为多个更小的、逻辑上相关的子集合。分区的核心功能是优化数据管理和查询效率
(2)Schema(数据类型)
Milvus的字段类型有向量、字符串、数字等;其中,主键必须是Int64或VarChar。
密集向量
密集向量通常表示为具有固定长度的浮点数数组,如[0.2, 0.7, 0.1, 0.8, 0.3, ..., 0.5] ,其中大部分或所有元素都不为零,维度就是数组中元素的个数。与稀疏向量相比,密集向量在同一维度上包含更多信息,主要用于需要理解数据语义的场景,如语义搜索和推荐系统。
二进制向量
它将传统的浮点向量转换为只包含 0 和 1 的二进制向量,如[1, 0, 1, 1, 0, 0, 1, 0] ,压缩了向量的大小,降低了存储和计算成本,同时保留了语义信息。二进制向量有助于降低延迟和计算成本,而不会明显牺牲准确性。
稀疏向量
大部分元素为零,只有少数维度具有非零值。稀疏向量采用压缩储存,只存储非零元素及其维度的索引,通常以{ index: value} 的键值对表示(如[{2: 0.2}, ..., {9997: 0.5}, {9999: 0.7}] )。
其他标量字段
类似于关系型数据库,包括VarChar、Boolean、Int、Float、Double、Array 和JSON
3.创建集合,开始使用
点击“创建Collection”,进入如下界面:
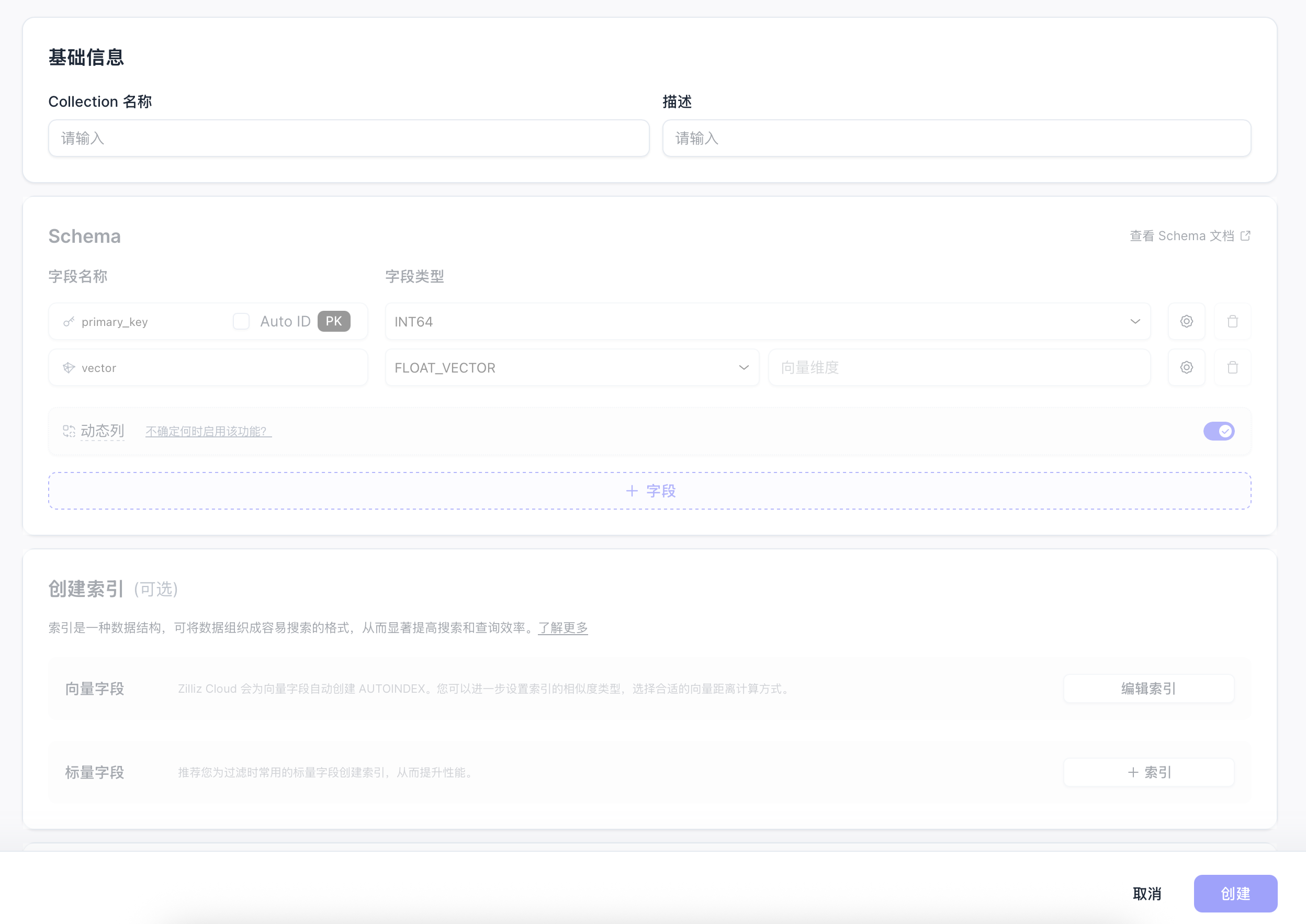
(1)配置字段和维度
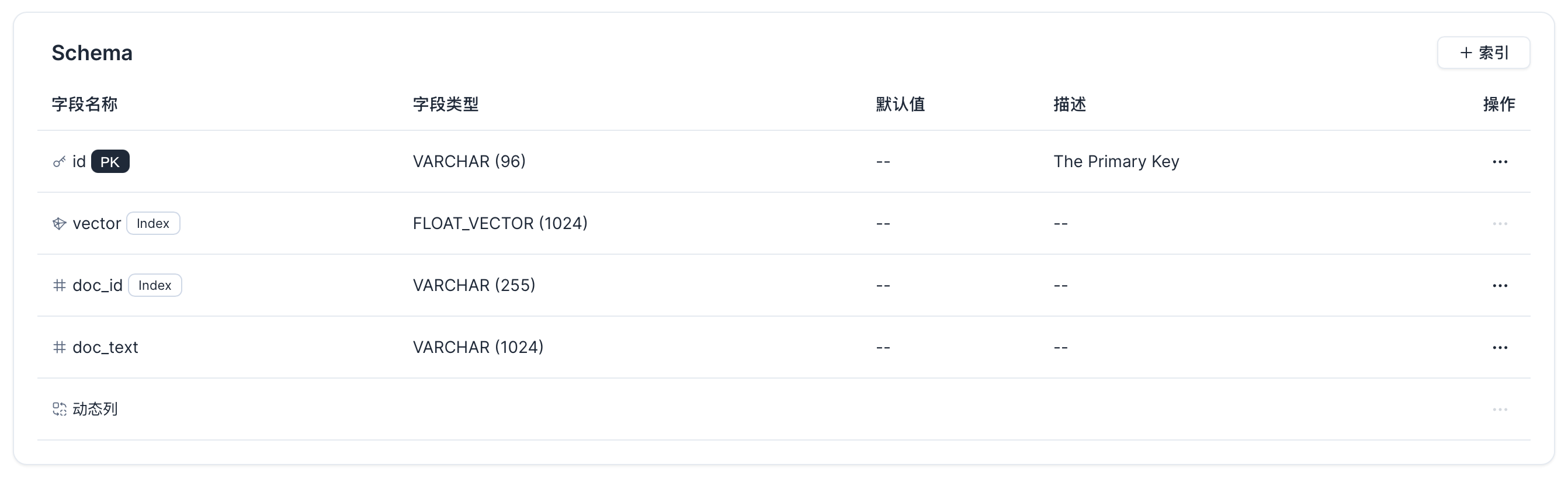
输入集合名称,然后把主键名称改为id,类型改为varchar,长度96。向量字段维度为1024,一旦确定,向量的维度就不能更改。然后添加两个varchar字段,doc_id和doc_text,前者用于标识同一篇文档的分片,后者用于保存文档分片的内容。
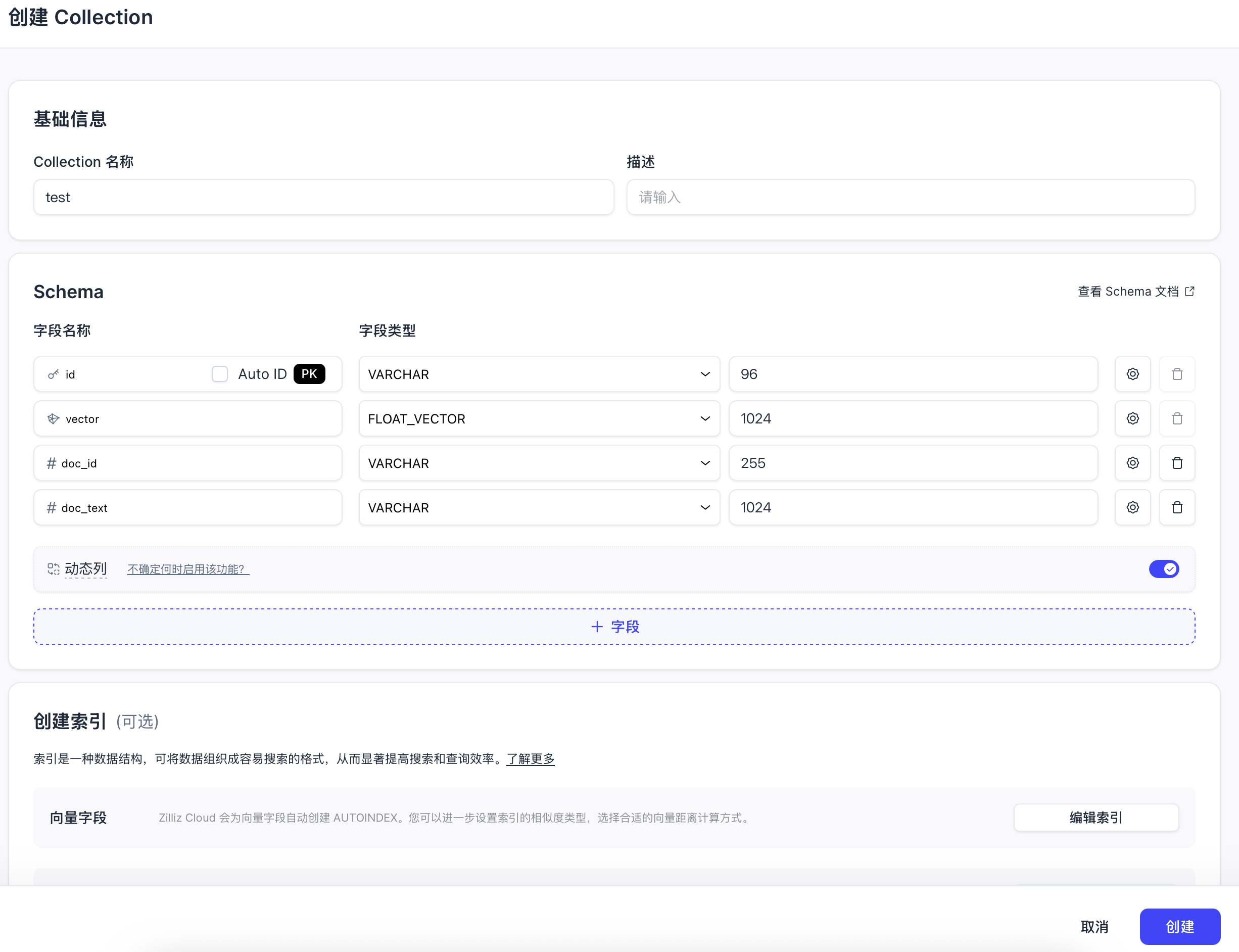
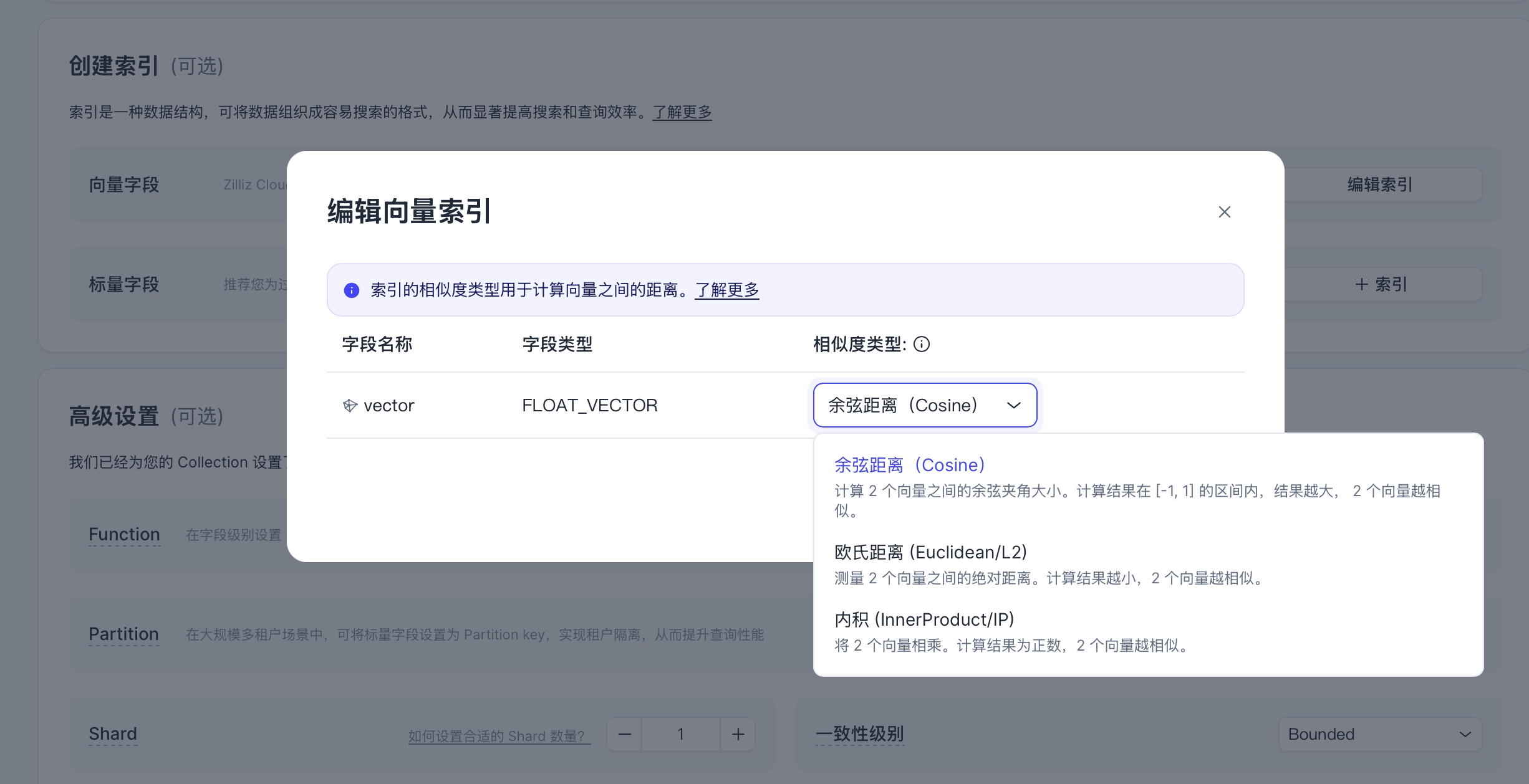
(2)配置索引
向量索引使用默认的余弦距离即可:
再给doc_id创建常规索引,方便后续做文档重复上传校验:
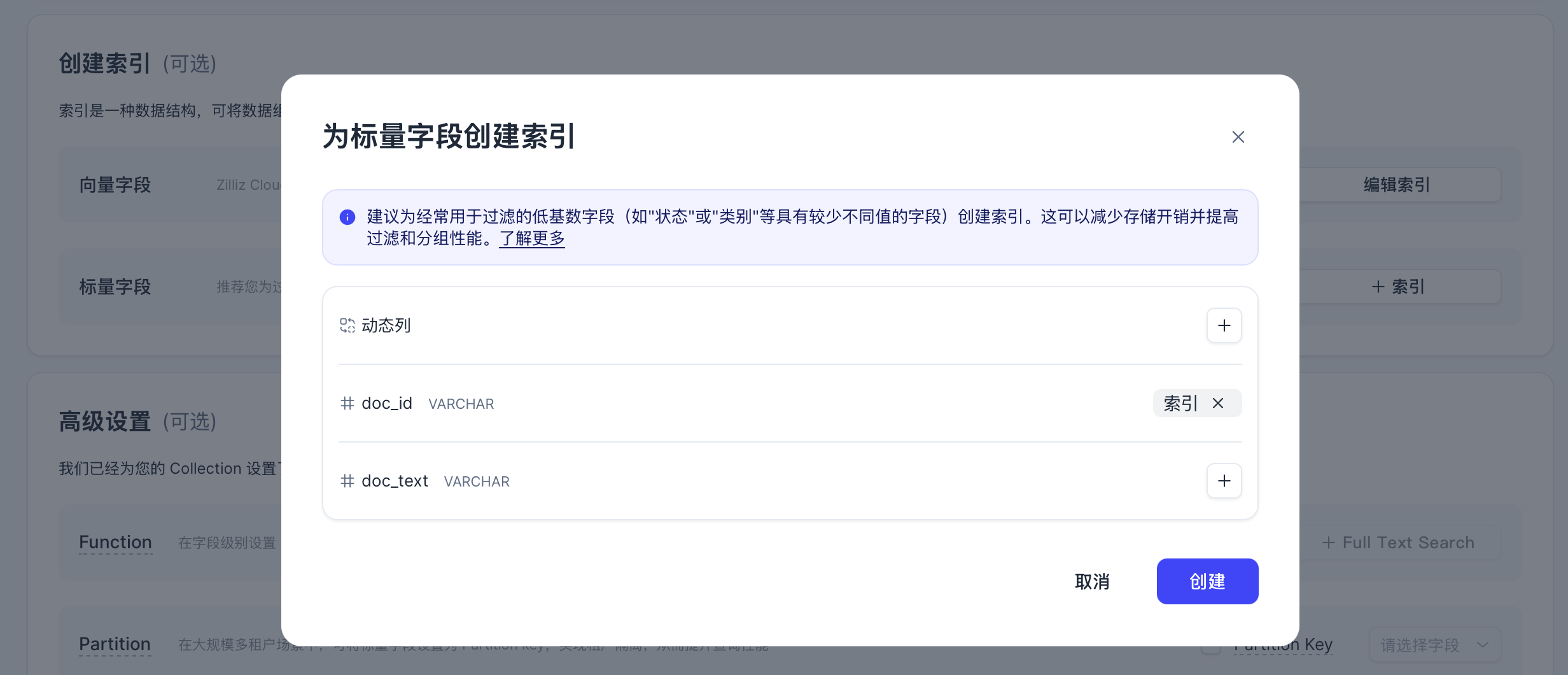
创建后的集合如下:
二、在项目中集成
1.配置yml文件
增加一项zilliz的配置,集群地址和token可以在控制台获取:
zilliz:
end-point: # Zilliz集群地址
token: # Zilliz认证token
collection-name: test
dimension: 1024 # 与嵌入模型维度匹配2.pom文件增加相关依赖
<!-- 连接向量数据库(zilliz,milvus的云部署版本) -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-milvus</artifactId>
<version>1.3.0-beta9</version>
</dependency>会同时把原生java SDK一起引进来,后续我们也会用到原生SDK:

3.尝试集成
在之前的ChatModelConfig配置类中,我们的两个核心方法如下:
//构建向量数据库操作对象
@Bean
public EmbeddingStore store() {
//1.加载文档进入内存
List<Document> documents = ClassPathDocumentLoader.loadDocuments("content");
//2.构建向量数据库操作对象
InMemoryEmbeddingStore store = new InMemoryEmbeddingStore();
//3.切割文本,将文档向量存储到向量数据库中
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()
.embeddingStore(store)
.build();
ingestor.ingest(documents);
return store;
}
//构建向量数据库检索对象
@Bean
public ContentRetriever contentRetriever(EmbeddingStore store) {
return EmbeddingStoreContentRetriever.builder()
.embeddingStore(store)
.minScore(0.5)//最小余弦相似度
.maxResults(3)//最大返回结果数
.build();
}
需要替换的是InMemoryEmbeddingStore:
@Value("${zilliz.end-point}")
private String uri;
@Value("${zilliz.token}")
private String token;
@Value("${zilliz.collection-name}")
private String collectionName;
@Value("${zilliz.dimension}")
private int dimension;
//构建向量数据库操作对象
@Bean
public EmbeddingStore store() {
//1.加载文档进入内存
List<Document> documents = ClassPathDocumentLoader.loadDocuments("content");
//2.构建向量数据库操作对象
//InMemoryEmbeddingStore store = new InMemoryEmbeddingStore();
//配置Milvus向量数据库操作对象
MilvusEmbeddingStore milvusEmbeddingStore = MilvusEmbeddingStore.builder()
.uri(endPoint)
.token(token)
.collectionName(collectionName)
.dimension(dimension)
.build();
//文本分割器
DocumentSplitter splitter = DocumentSplitters.recursive(500,100);
//3.切割文本,将文档向量存储到向量数据库中
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()
.embeddingStore(milvusEmbeddingStore)
.documentSplitter(splitter)
.embeddingModel(embeddingModel)
.build();
ingestor.ingest(documents);
return milvusEmbeddingStore;
}但我们这么做会出现一个古怪的报错:The primary key: id is auto generated, no need to input.
意思是主键自动生成了,不需要。
我们反编译EmbeddingStore接口的源码看一下:
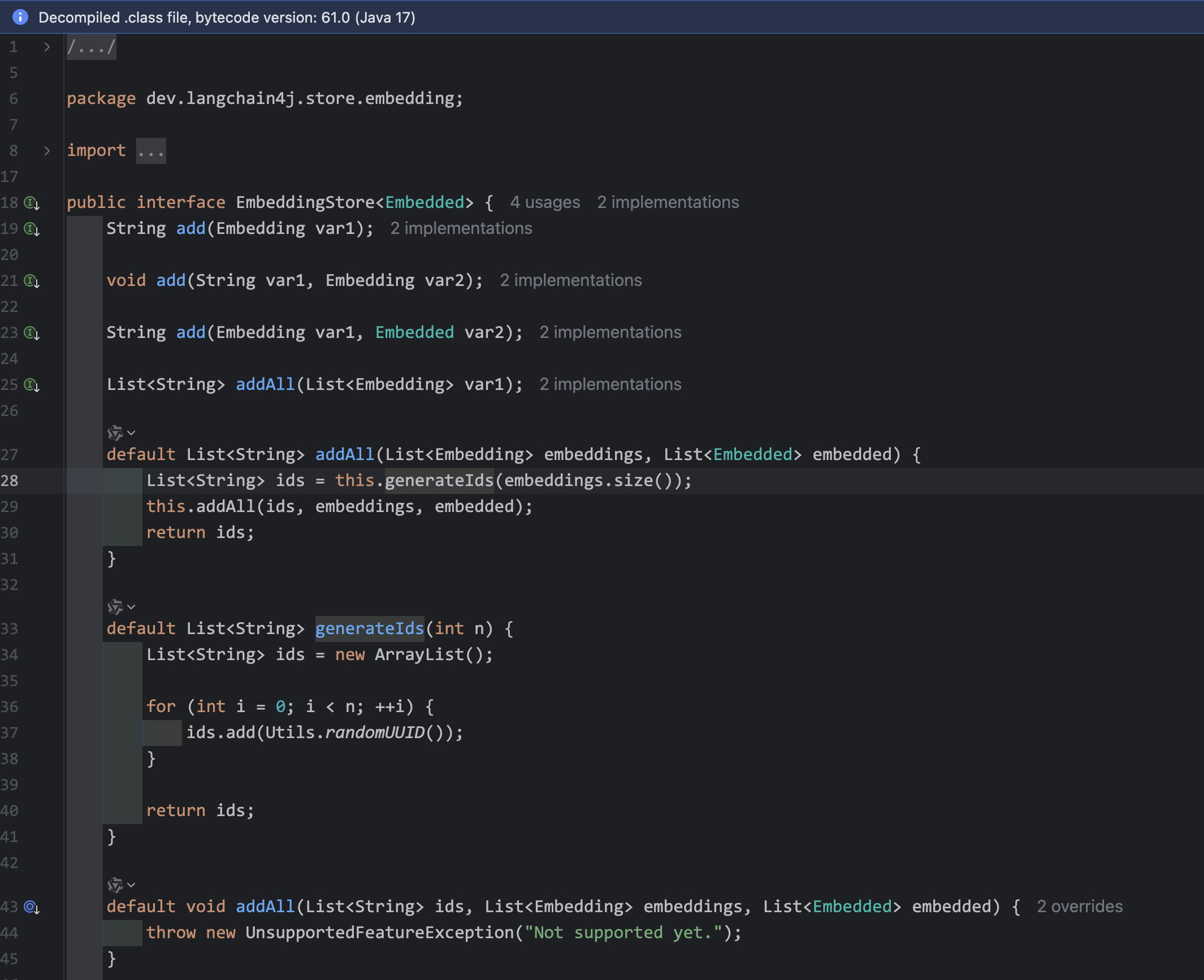
原因很明显了,add方法调用generateIds方法,用java UUID自动生成主键,引起冲突。
如果炸掉集合重新创建,这次不勾选Auto ID,又会报错:插入数据时缺少主键。
4.官方未完全适配引起的bug
这里就引出一个两难的bug:在创建Collection的时候,如果勾选了Auto ID,则插入失败;不勾选,则提示缺失ID。
应该是官方没有给LangChain4j适配好的原因,从maven依赖版本号就可以看到,现在最新版仍然是beta阶段
5.手动处理文档向量化逻辑
既然如此,我们必须直接使用官方java SDK,手动处理相关逻辑
(1)定义一个查询方法,避免重复添加同一篇文档的切片
在ChatModelConfig类中定义如下方法,使用集合去重
// 查询数据库中已存在的文档唯一标识(通过元数据中的"document_id"字段)
private Set<String> queryExistingDocumentIds(MilvusClientV2 client, Set<String> documentIds) {
//遍历集合,查询数据库
Set<String> existingDocIds = new HashSet<>();
for (String documentId : documentIds) {
String filter = "doc_id ==\"" + documentId + "\"";
QueryResp resp = client.query(QueryReq.builder()
.collectionName(collectionName)
.filter(filter)
.outputFields(List.of("doc_id"))
.build());
System.out.println(resp.getQueryResults());
if (!resp.getQueryResults().isEmpty()) {
// 如果查询结果不是空,则说明该文档存在,加入存在集合
existingDocIds.add(documentId);
}
}
return existingDocIds;
}(2)定义文档处理方法
首先从相对路径加载所有文档,得到一个List
然后提取文件名作为唯一标识(可以再加时间戳什么的)
再调用刚刚定义的查询方法,筛选出需要添加的文档
再使用分割器和Embedding模型,向量化文本片段
最后使用谷歌Gson库,构造向量数据库insert请求
// 手动处理并添加向量(含去重逻辑)
@PostConstruct
public void manualIngest() {
// 1. 加载文档
List<Document> allDocuments = ClassPathDocumentLoader.loadDocuments("content");
System.out.println("加载到文档总数:" + allDocuments.size());
//todo 2. 为每个文档生成唯一标识(这里用文件名作为唯一ID)
Map<String, Document> docIdToDocument = new HashMap<>();
// 生成的文档标识集合
Set<String> allDocumentIds = new HashSet<>();
for (Document doc : allDocuments) {
// 从文档元数据中获取文件名(ClassPathDocumentLoader默认会添加"file_name"字段记录路径)
String file_name = URLDecoder.decode(doc.metadata().getString("file_name"), StandardCharsets.UTF_8);
System.out.println("文档元数据:" + doc.metadata());
String documentId = file_name.split("\\.")[0]; // 提取文件名作为唯一标识
System.out.println("文档唯一标识:" + documentId);
docIdToDocument.put(documentId, doc);
allDocumentIds.add(documentId);
}
System.out.println("文档唯一标识数量:" + docIdToDocument.size());
//todo 3. 查询数据库中已存在的文档标识
Set<String> existingDocIds = queryExistingDocumentIds(milvusClientV2, allDocumentIds);
System.out.println("数据库中已存在的文档数量:" + existingDocIds.size());
// 4. 过滤出需要插入的新文档(不存在的标识)
List<Document> newDocuments = docIdToDocument.entrySet().stream()
.filter(entry -> !existingDocIds.contains(entry.getKey()))
.map(Map.Entry::getValue)
.toList();
System.out.println("需要插入的新文档数量:" + newDocuments.size());
if (newDocuments.isEmpty()) {
System.out.println("无新文档需要插入,流程结束");
return;
}
// 5. 处理新文档:分割→生成向量→插入
//DocumentSplitter splitter = DocumentSplitters.recursive(360, 60);
DocumentByLineSplitter lineSplitter = new DocumentByLineSplitter(320,80);
List<TextSegment> segments = new ArrayList<>();
for (Document doc : newDocuments) {
String docId = URLDecoder.decode(doc.metadata().getString("file_name"), StandardCharsets.UTF_8).split("\\.")[0];
// 分割文档为片段,并在元数据中添加文档唯一标识
List<TextSegment> docSegments = lineSplitter.split(doc);
docSegments.forEach(segment ->
segment.metadata().put("document_id", docId) // 关键:存储文档唯一标识到片段元数据
);
segments.addAll(docSegments);
}
System.out.println("新文档分割后的片段数量:" + segments.size());
//System.out.println("新文档片段:" + segments);
//todo 6. 生成向量并插入
List<Embedding> embeddings = embeddingModel.embedAll(segments).content();
//System.out.println("新文档生成向量:" + embeddings);
List<JsonObject> rows = new ArrayList<>();
Gson gson = new Gson();
// 将向量数据转换为JSON对象
for (int i = 0; i < embeddings.size(); i++) {
JsonObject row = new JsonObject();
row.addProperty("id", Utils.randomUUID());
row.add("vector", gson.toJsonTree(embeddings.get(i).vector()));
row.add("doc_id", gson.toJsonTree(segments.get(i).metadata().getString("document_id")));
row.add("doc_text", gson.toJsonTree(segments.get(i).text()));
rows.add(row);
}
System.out.println("新文档向量数据:" + rows);
//todo 7. 插入向量
InsertResp insertResp = milvusClientV2.insert(InsertReq.builder()
.collectionName(collectionName)
.data(rows)
.build());
//System.out.println("新文档插入完成,插入向量数量:" + embeddings.size());
}6.构造我们自己的向量数据库检索对象
我们定义一个类,名字叫ZillizContentRetriever,实现ContentRetriever接口
然后去看看EmbeddingStoreContentRetriever类反编译出来的源码:
package dev.langchain4j.rag.content.retriever;
import dev.langchain4j.data.embedding.Embedding;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.internal.Utils;
import dev.langchain4j.internal.ValidationUtils;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.rag.content.Content;
import dev.langchain4j.rag.content.ContentMetadata;
import dev.langchain4j.rag.query.Query;
import dev.langchain4j.spi.ServiceHelper;
import dev.langchain4j.spi.model.embedding.EmbeddingModelFactory;
import dev.langchain4j.store.embedding.EmbeddingSearchRequest;
import dev.langchain4j.store.embedding.EmbeddingSearchResult;
import dev.langchain4j.store.embedding.EmbeddingStore;
import dev.langchain4j.store.embedding.filter.Filter;
import java.util.Collection;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.function.Function;
import java.util.stream.Collectors;
public class EmbeddingStoreContentRetriever implements ContentRetriever {
public static final Function<Query, Integer> DEFAULT_MAX_RESULTS = (query) -> 3;
public static final Function<Query, Double> DEFAULT_MIN_SCORE = (query) -> (double)0.0F;
public static final Function<Query, Filter> DEFAULT_FILTER = (query) -> null;
public static final String DEFAULT_DISPLAY_NAME = "Default";
private final EmbeddingStore<TextSegment> embeddingStore;
private final EmbeddingModel embeddingModel;
private final Function<Query, Integer> maxResultsProvider;
private final Function<Query, Double> minScoreProvider;
private final Function<Query, Filter> filterProvider;
private final String displayName;
public EmbeddingStoreContentRetriever(EmbeddingStore<TextSegment> embeddingStore, EmbeddingModel embeddingModel) {
this("Default", embeddingStore, embeddingModel, DEFAULT_MAX_RESULTS, DEFAULT_MIN_SCORE, DEFAULT_FILTER);
}
public EmbeddingStoreContentRetriever(EmbeddingStore<TextSegment> embeddingStore, EmbeddingModel embeddingModel, int maxResults) {
this("Default", embeddingStore, embeddingModel, (query) -> maxResults, DEFAULT_MIN_SCORE, DEFAULT_FILTER);
}
public EmbeddingStoreContentRetriever(EmbeddingStore<TextSegment> embeddingStore, EmbeddingModel embeddingModel, Integer maxResults, Double minScore) {
this("Default", embeddingStore, embeddingModel, (query) -> maxResults, (query) -> minScore, DEFAULT_FILTER);
}
private EmbeddingStoreContentRetriever(String displayName, EmbeddingStore<TextSegment> embeddingStore, EmbeddingModel embeddingModel, Function<Query, Integer> dynamicMaxResults, Function<Query, Double> dynamicMinScore, Function<Query, Filter> dynamicFilter) {
this.displayName = (String)Utils.getOrDefault(displayName, "Default");
this.embeddingStore = (EmbeddingStore)ValidationUtils.ensureNotNull(embeddingStore, "embeddingStore");
this.embeddingModel = (EmbeddingModel)ValidationUtils.ensureNotNull((EmbeddingModel)Utils.getOrDefault(embeddingModel, EmbeddingStoreContentRetriever::loadEmbeddingModel), "embeddingModel");
this.maxResultsProvider = (Function)Utils.getOrDefault(dynamicMaxResults, DEFAULT_MAX_RESULTS);
this.minScoreProvider = (Function)Utils.getOrDefault(dynamicMinScore, DEFAULT_MIN_SCORE);
this.filterProvider = (Function)Utils.getOrDefault(dynamicFilter, DEFAULT_FILTER);
}
private static EmbeddingModel loadEmbeddingModel() {
Collection<EmbeddingModelFactory> factories = ServiceHelper.loadFactories(EmbeddingModelFactory.class);
if (factories.size() > 1) {
throw new RuntimeException("Conflict: multiple embedding models have been found in the classpath. Please explicitly specify the one you wish to use.");
} else {
Iterator var1 = factories.iterator();
if (var1.hasNext()) {
EmbeddingModelFactory factory = (EmbeddingModelFactory)var1.next();
return factory.create();
} else {
return null;
}
}
}
public static EmbeddingStoreContentRetrieverBuilder builder() {
return new EmbeddingStoreContentRetrieverBuilder();
}
public static EmbeddingStoreContentRetriever from(EmbeddingStore<TextSegment> embeddingStore) {
return builder().embeddingStore(embeddingStore).build();
}
public List<Content> retrieve(Query query) {
Embedding embeddedQuery = (Embedding)this.embeddingModel.embed(query.text()).content();
EmbeddingSearchRequest searchRequest = EmbeddingSearchRequest.builder().queryEmbedding(embeddedQuery).maxResults((Integer)this.maxResultsProvider.apply(query)).minScore((Double)this.minScoreProvider.apply(query)).filter((Filter)this.filterProvider.apply(query)).build();
EmbeddingSearchResult<TextSegment> searchResult = this.embeddingStore.search(searchRequest);
return (List)searchResult.matches().stream().map((embeddingMatch) -> Content.from((TextSegment)embeddingMatch.embedded(), Map.of(ContentMetadata.SCORE, embeddingMatch.score(), ContentMetadata.EMBEDDING_ID, embeddingMatch.embeddingId()))).collect(Collectors.toList());
}
public String toString() {
return "EmbeddingStoreContentRetriever{displayName='" + this.displayName + "'}";
}
public static class EmbeddingStoreContentRetrieverBuilder {
private String displayName;
private EmbeddingStore<TextSegment> embeddingStore;
private EmbeddingModel embeddingModel;
private Function<Query, Integer> dynamicMaxResults;
private Function<Query, Double> dynamicMinScore;
private Function<Query, Filter> dynamicFilter;
EmbeddingStoreContentRetrieverBuilder() {
}
public EmbeddingStoreContentRetrieverBuilder maxResults(Integer maxResults) {
if (maxResults != null) {
this.dynamicMaxResults = (query) -> ValidationUtils.ensureGreaterThanZero(maxResults, "maxResults");
}
return this;
}
public EmbeddingStoreContentRetrieverBuilder minScore(Double minScore) {
if (minScore != null) {
this.dynamicMinScore = (query) -> ValidationUtils.ensureBetween(minScore, (double)0.0F, (double)1.0F, "minScore");
}
return this;
}
public EmbeddingStoreContentRetrieverBuilder filter(Filter filter) {
if (filter != null) {
this.dynamicFilter = (query) -> filter;
}
return this;
}
public EmbeddingStoreContentRetrieverBuilder displayName(String displayName) {
this.displayName = displayName;
return this;
}
public EmbeddingStoreContentRetrieverBuilder embeddingStore(EmbeddingStore<TextSegment> embeddingStore) {
this.embeddingStore = embeddingStore;
return this;
}
public EmbeddingStoreContentRetrieverBuilder embeddingModel(EmbeddingModel embeddingModel) {
this.embeddingModel = embeddingModel;
return this;
}
public EmbeddingStoreContentRetrieverBuilder dynamicMaxResults(Function<Query, Integer> dynamicMaxResults) {
this.dynamicMaxResults = dynamicMaxResults;
return this;
}
public EmbeddingStoreContentRetrieverBuilder dynamicMinScore(Function<Query, Double> dynamicMinScore) {
this.dynamicMinScore = dynamicMinScore;
return this;
}
public EmbeddingStoreContentRetrieverBuilder dynamicFilter(Function<Query, Filter> dynamicFilter) {
this.dynamicFilter = dynamicFilter;
return this;
}
public EmbeddingStoreContentRetriever build() {
return new EmbeddingStoreContentRetriever(this.displayName, this.embeddingStore, this.embeddingModel, this.dynamicMaxResults, this.dynamicMinScore, this.dynamicFilter);
}
}
}
可以看到,除了一系列构造方法和Builder内部类,最重要的是 Override retriever函数,从而对外提供检索功能:
public List<Content> retrieve(Query query) {
Embedding embeddedQuery = (Embedding)this.embeddingModel.embed(query.text()).content();
EmbeddingSearchRequest searchRequest = EmbeddingSearchRequest.builder().queryEmbedding(embeddedQuery).maxResults((Integer)this.maxResultsProvider.apply(query)).minScore((Double)this.minScoreProvider.apply(query)).filter((Filter)this.filterProvider.apply(query)).build();
EmbeddingSearchResult<TextSegment> searchResult = this.embeddingStore.search(searchRequest);
return (List)searchResult.matches().stream().map((embeddingMatch) -> Content.from((TextSegment)embeddingMatch.embedded(), Map.of(ContentMetadata.SCORE, embeddingMatch.score(), ContentMetadata.EMBEDDING_ID, embeddingMatch.embeddingId()))).collect(Collectors.toList());
}我们把代码扔给AI,生成ZillizContentRetriever的相关功能:
import com.google.gson.Gson;
import dev.langchain4j.data.embedding.Embedding;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.rag.content.Content;
import dev.langchain4j.rag.content.ContentMetadata;
import dev.langchain4j.rag.content.retriever.ContentRetriever;
import dev.langchain4j.rag.query.Query;
import io.milvus.v2.client.MilvusClientV2;
import io.milvus.v2.service.vector.request.SearchReq;
import io.milvus.v2.service.vector.request.data.FloatVec;
import io.milvus.v2.service.vector.response.SearchResp;
import java.util.Collections;
import java.util.List;
import java.util.Map;
import java.util.Objects;
import java.util.stream.Collectors;
public class ZillizContentRetriever implements ContentRetriever {
// 必要参数
private final MilvusClientV2 milvusClient; // Zilliz客户端
private final String collectionName; // 集合名
private final EmbeddingModel embeddingModel; // 嵌入模型(用于生成查询向量)
private final Double minScore; // 最小相似度分数
private final Integer maxResults; // 最大返回结果数
// 私有构造函数(通过Builder创建)
private ZillizContentRetriever(ZillizContentRetrieverBuilder zillizContentRetrieverBuilder) {
this.milvusClient = zillizContentRetrieverBuilder.milvusClient;
this.collectionName = zillizContentRetrieverBuilder.collectionName;
this.embeddingModel = zillizContentRetrieverBuilder.embeddingModel;
this.minScore = zillizContentRetrieverBuilder.minScore;
this.maxResults = zillizContentRetrieverBuilder.maxResults;
// 验证必要参数
Objects.requireNonNull(milvusClient, "milvusClient must not be null");
Objects.requireNonNull(collectionName, "collectionName must not be null");
Objects.requireNonNull(embeddingModel, "embeddingModel must not be null");
}
/**
* 静态工厂方法,快速创建Builder
*/
public static ZillizContentRetrieverBuilder builder() {
return new ZillizContentRetrieverBuilder();
}
/**
* 核心检索方法:将查询文本转换为向量,查询Zilliz并返回匹配的内容
*/
@Override
public List<Content> retrieve(Query query) {
try {
// 1. 生成查询文本的向量
Embedding queryEmbedding = (Embedding) embeddingModel.embed(query.text()).content();
//System.out.println("查询浮点向量:" + queryEmbedding);
FloatVec queryVector = new FloatVec(queryEmbedding.vector());
//System.out.println("查询向量:" + queryVector.getData());
// 2. 构建Zilliz搜索请求
SearchReq searchReq = SearchReq.builder()
.collectionName(collectionName)
.data(Collections.singletonList(queryVector)) // 查询向量(批量查询可传多个)
.topK(maxResults) // 最大结果数
.offset(0)
.outputFields(List.of("doc_text")) // 需要返回的字段
.build();
// 3. 执行查询
SearchResp searchResp = milvusClient.search(searchReq);
Gson gson = new Gson();
// 4. 处理查询结果,转换为Content列表
return searchResp.getSearchResults().stream()
.flatMap(List::stream) // 展开外层列表(每个查询向量的结果)
.map(result -> { // 遍历每个匹配结果(SearchResult)
// 提取官方示例中的核心字段
String embeddingId = result.getId().toString(); // 对应官方的result.getId()
Float score = result.getScore(); // 对应官方的result.getScore()
Map<String, Object> entity = result.getEntity(); // 对应官方的result.getEntity()
//System.out.println("查询结果:" + entity.getClass());
//System.out.println("查询结果:" + entity);
// 从实体中提取文本内容
String text = entity.get("doc_text").toString();
// 过滤无效结果(参考源码的过滤逻辑)
if (text == null || text.trim().isEmpty() || score < minScore) {
return null;
}
// 构建TextSegment(元数据格式对齐源码)
TextSegment segment = TextSegment.from(text);
// 转换为Content(与源码逻辑一致)
return Content.from(segment, Map.of(ContentMetadata.SCORE, score, ContentMetadata.EMBEDDING_ID, embeddingId));
})
.filter(Objects::nonNull)
.collect(Collectors.toList());
} catch (Exception e) {
throw new RuntimeException("Zilliz向量检索失败: " + e.getMessage(), e);
}
}
/**
* Builder模式,用于灵活配置检索器参数
*/
public static class ZillizContentRetrieverBuilder {
private MilvusClientV2 milvusClient;
private String collectionName;
private EmbeddingModel embeddingModel;
private String vectorFieldName = "vector"; // 默认向量字段名
private String textFieldName = "doc_text"; // 默认文本字段名
private Double minScore = 0.5; // 默认最小相似度
private Integer maxResults = 3; // 默认最大结果数
ZillizContentRetrieverBuilder() {
}
// 必选参数设置
public ZillizContentRetrieverBuilder milvusClient(MilvusClientV2 milvusClient) {
this.milvusClient = milvusClient;
return this;
}
public ZillizContentRetrieverBuilder collectionName(String collectionName) {
this.collectionName = collectionName;
return this;
}
public ZillizContentRetrieverBuilder embeddingModel(EmbeddingModel embeddingModel) {
this.embeddingModel = embeddingModel;
return this;
}
public ZillizContentRetrieverBuilder minScore(Double minScore) {
this.minScore = minScore;
return this;
}
public ZillizContentRetrieverBuilder maxResults(Integer maxResults) {
this.maxResults = maxResults;
return this;
}
// 构建检索器实例
public ZillizContentRetriever build() {
return new ZillizContentRetriever(this);
}
}
}
在ChatModelConfig类中修改原本的检索对象构建方法:
//构建向量数据库检索对象
@Bean
public ContentRetriever MilvusContentRetriever() {
return ZillizContentRetriever.builder()
.milvusClient(milvusClientV2)
.collectionName(collectionName)
.minScore(0.5)//最小余弦相似度
.maxResults(3)//最大返回结果数
.embeddingModel(embeddingModel)//嵌入模型
.build();
}最后修改完整的ChatModelConfig类:
import com.AIexample.test2.retriever.ZillizContentRetriever;
import com.google.gson.Gson;
import com.google.gson.JsonObject;
import dev.langchain4j.data.document.Document;
import dev.langchain4j.data.document.DocumentSplitter;
import dev.langchain4j.data.document.loader.ClassPathDocumentLoader;
import dev.langchain4j.data.document.splitter.DocumentByLineSplitter;
import dev.langchain4j.data.document.splitter.DocumentSplitters;
import dev.langchain4j.data.embedding.Embedding;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.internal.Utils;
import dev.langchain4j.memory.ChatMemory;
import dev.langchain4j.memory.chat.ChatMemoryProvider;
import dev.langchain4j.memory.chat.MessageWindowChatMemory;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.rag.content.retriever.ContentRetriever;
import dev.langchain4j.store.embedding.EmbeddingStore;
import dev.langchain4j.store.memory.chat.ChatMemoryStore;
import io.milvus.v2.client.MilvusClientV2;
import io.milvus.v2.service.vector.request.InsertReq;
import io.milvus.v2.service.vector.request.QueryReq;
import io.milvus.v2.service.vector.response.InsertResp;
import io.milvus.v2.service.vector.response.QueryResp;
import jakarta.annotation.PostConstruct;
import lombok.RequiredArgsConstructor;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.net.URLDecoder;
import java.nio.charset.StandardCharsets;
import java.util.*;
@RequiredArgsConstructor
@Configuration
public class ChatModelConfig {
//注入会话记忆持久化对象
private final ChatMemoryStore redisChatMemoryStore;
//注入嵌入模型
private final EmbeddingModel embeddingModel;
//注入向量数据库客户端
private final MilvusClientV2 milvusClientV2;
//注入 Milvus 向量数据库操作对象
private final EmbeddingStore milvusStore;
@Value("${zilliz.collection-name}")
private String collectionName;
@Bean
public ChatMemory normalChatMemory() {
return MessageWindowChatMemory.builder()
.maxMessages(20)
.build();
}
@Bean
public ChatMemoryProvider normalChatMemoryProvider() {
return new ChatMemoryProvider() {
@Override
public ChatMemory get(Object memoryId) {
return MessageWindowChatMemory.builder()
.id(memoryId)
.maxMessages(20)
.chatMemoryStore(redisChatMemoryStore)
.build();
}
};
}
//构建向量数据库检索对象
@Bean
public ContentRetriever MilvusContentRetriever() {
return ZillizContentRetriever.builder()
.milvusClient(milvusClientV2)
.collectionName(collectionName)
.minScore(0.5)//最小余弦相似度
.maxResults(3)//最大返回结果数
.embeddingModel(embeddingModel)//嵌入模型
.build();
}
// 手动处理并添加向量(含去重逻辑)
@PostConstruct
public void manualIngest() {
// 1. 加载文档
List<Document> allDocuments = ClassPathDocumentLoader.loadDocuments("content");
System.out.println("加载到文档总数:" + allDocuments.size());
//todo 2. 为每个文档生成唯一标识(这里用文件名作为唯一ID)
Map<String, Document> docIdToDocument = new HashMap<>();
// 生成的文档标识集合
Set<String> allDocumentIds = new HashSet<>();
for (Document doc : allDocuments) {
// 从文档元数据中获取文件名(ClassPathDocumentLoader默认会添加"file_name"字段记录路径)
String file_name = URLDecoder.decode(doc.metadata().getString("file_name"), StandardCharsets.UTF_8);
System.out.println("文档元数据:" + doc.metadata());
String documentId = file_name.split("\\.")[0]; // 提取文件名作为唯一标识
System.out.println("文档唯一标识:" + documentId);
docIdToDocument.put(documentId, doc);
allDocumentIds.add(documentId);
}
System.out.println("文档唯一标识数量:" + docIdToDocument.size());
//todo 3. 查询数据库中已存在的文档标识
Set<String> existingDocIds = queryExistingDocumentIds(milvusClientV2, allDocumentIds);
System.out.println("数据库中已存在的文档数量:" + existingDocIds.size());
// 4. 过滤出需要插入的新文档(不存在的标识)
List<Document> newDocuments = docIdToDocument.entrySet().stream()
.filter(entry -> !existingDocIds.contains(entry.getKey()))
.map(Map.Entry::getValue)
.toList();
System.out.println("需要插入的新文档数量:" + newDocuments.size());
if (newDocuments.isEmpty()) {
System.out.println("无新文档需要插入,流程结束");
return;
}
// 5. 处理新文档:分割→生成向量→插入
//DocumentSplitter splitter = DocumentSplitters.recursive(360, 60);
DocumentByLineSplitter lineSplitter = new DocumentByLineSplitter(320,80);
List<TextSegment> segments = new ArrayList<>();
for (Document doc : newDocuments) {
String docId = URLDecoder.decode(doc.metadata().getString("file_name"), StandardCharsets.UTF_8).split("\\.")[0];
// 分割文档为片段,并在元数据中添加文档唯一标识
List<TextSegment> docSegments = lineSplitter.split(doc);
docSegments.forEach(segment ->
segment.metadata().put("document_id", docId) // 关键:存储文档唯一标识到片段元数据
);
segments.addAll(docSegments);
}
System.out.println("新文档分割后的片段数量:" + segments.size());
//System.out.println("新文档片段:" + segments);
//todo 6. 生成向量并插入
List<Embedding> embeddings = embeddingModel.embedAll(segments).content();
//System.out.println("新文档生成向量:" + embeddings);
List<JsonObject> rows = new ArrayList<>();
Gson gson = new Gson();
// 将向量数据转换为JSON对象
for (int i = 0; i < embeddings.size(); i++) {
JsonObject row = new JsonObject();
row.addProperty("id", Utils.randomUUID());
row.add("vector", gson.toJsonTree(embeddings.get(i).vector()));
row.add("doc_id", gson.toJsonTree(segments.get(i).metadata().getString("document_id")));
row.add("doc_text", gson.toJsonTree(segments.get(i).text()));
rows.add(row);
}
System.out.println("新文档向量数据:" + rows);
//todo 7. 插入向量
InsertResp insertResp = milvusClientV2.insert(InsertReq.builder()
.collectionName(collectionName)
.data(rows)
.build());
//System.out.println("新文档插入完成,插入向量数量:" + embeddings.size());
}
// 查询数据库中已存在的文档唯一标识(通过元数据中的"document_id"字段)
private Set<String> queryExistingDocumentIds(MilvusClientV2 client, Set<String> documentIds) {
//遍历集合,查询数据库
Set<String> existingDocIds = new HashSet<>();
for (String documentId : documentIds) {
String filter = "doc_id ==\"" + documentId + "\"";
QueryResp resp = client.query(QueryReq.builder()
.collectionName(collectionName)
.filter(filter)
.outputFields(List.of("doc_id"))
.build());
System.out.println(resp.getQueryResults());
if (!resp.getQueryResults().isEmpty()) {
// 如果查询结果不是空,则说明该文档存在,加入存在集合
existingDocIds.add(documentId);
}
}
return existingDocIds;
}
}
有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 36
36 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)