【笔记】动手学Ollama 第七章 搭建本地RAG
正文详见:7.3 使用 LangChain 搭建本地 RAG 应用。
一、Langchain版本
1、环境设置
首先下载RAG所需要的模型:
- llama3.1:8b:ollama pull llama3.1:8b
- nomic-embed-text:ollama pull nomic-embed-text
安装本地嵌入、向量存储和模型推理所需的包:
- LangChain架构核心库和社区集成库:pip install langchain langchain_community
- Chroa向量数据库:pip install langchain_chroma
- Ollama库:pip install langchain_ollama
2、文档加载
读取文档
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
data = loader.load()将文档分割为文本块
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
all_splits = text_splitter.split_documents(data)建立向量存储数据库,使用的文本嵌入模型是nomic-embed-text,将文本块向量化并存储
from langchain_chroma import Chroma
from langchain_ollama import OllamaEmbeddings
local_embeddings = OllamaEmbeddings(model="nomic-embed-text")
vectorstore = Chroma.from_documents(documents=all_splits, embedding=local_embeddings)相似度检索,将问题(question)向量化,同数据库中的向量化的文本块进行匹配
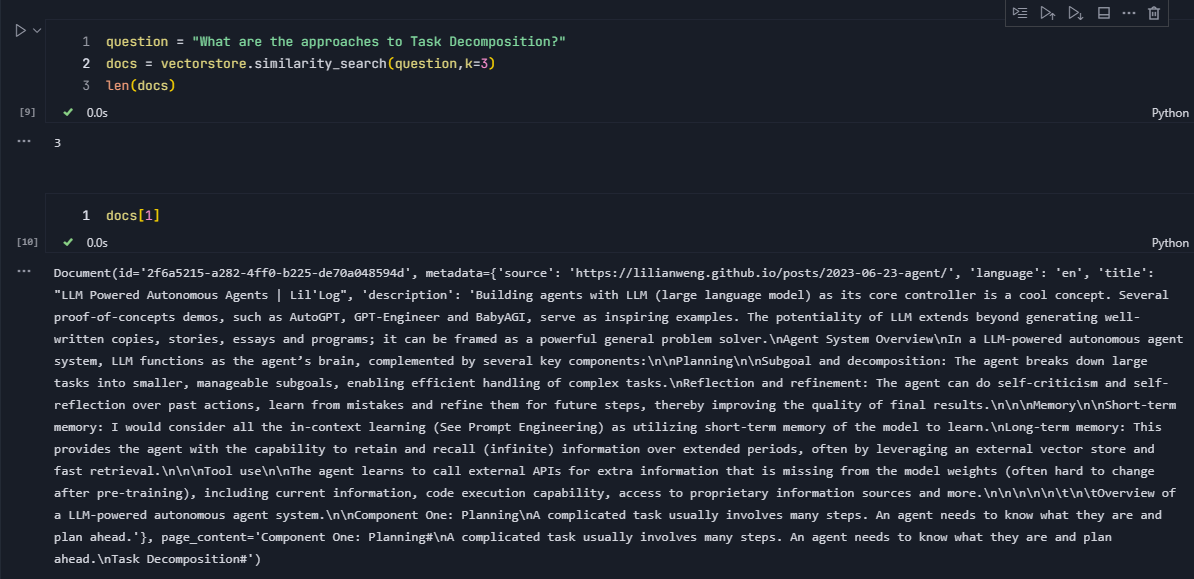
question = "What are the approaches to Task Decomposition?"
docs = vectorstore.similarity_search(question,k=3)
len(docs)通过参数k来控制返回的文本块的数量。
实例化大语言模型,使用的语言模型是llama3.1:8b,并测试模型推理是否正常
from langchain_ollama import ChatOllama
model = ChatOllama(
model="llama3.1:8b",
)
response_message = model.invoke(
"Simulate a rap battle between Stephen Colbert and John Oliver"
)
print(response_message.content)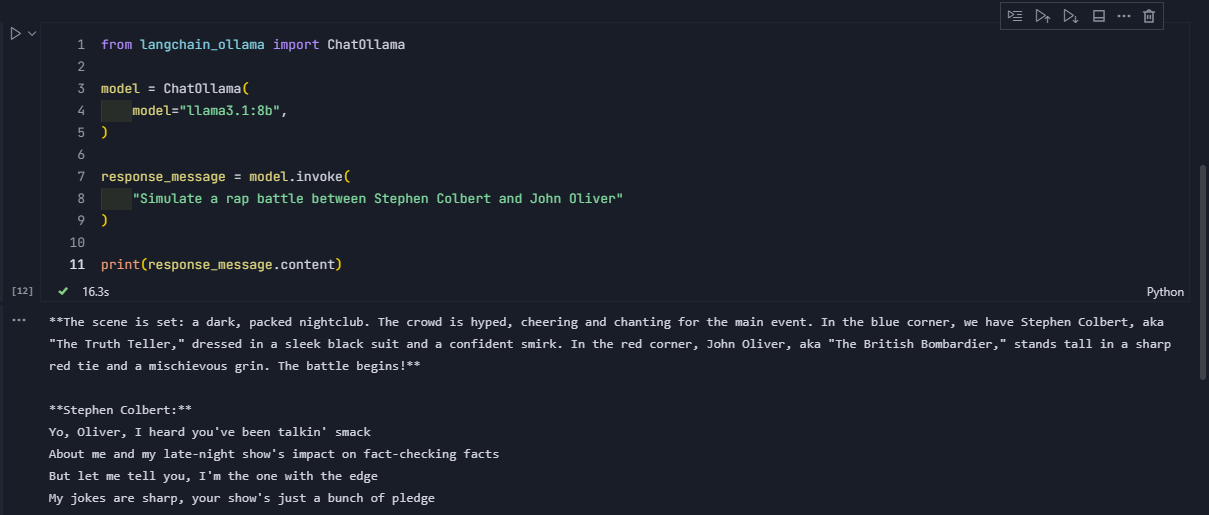
3、构建chain表达形式
首先构造一个方法,使用ChatPromptTemplate将提示词文本从字符串转为聊天提示模板(ChatPromptTemplate)对象
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_template(
"Summarize the main themes in these retrieved docs: {docs}"
)检索与question相似的文本块docs
question = "What are the approaches to Task Decomposition?"
docs = vectorstore.similarity_search(question)docs进入链式结构(chain),首先通过format_docs函数将文本块转化成字符串,然后加载提示词并转化为ChatPromptTemplate,最后进入指定模型生成消息
from langchain_core.output_parsers import StrOutputParser
# 将传入的文档转换成字符串的形式
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
chain = {"docs": format_docs} | prompt | model | StrOutputParser()
chain.invoke(docs)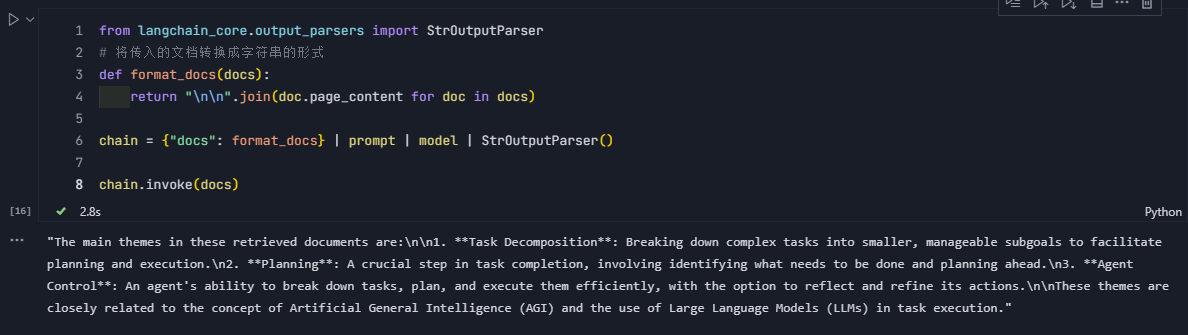
4、简单QA
首先定义提示词,你需要根据给出的上下文回答问题,如果你不知道,就说不知道,在提示词中,定义了两个参数,一个是{context},即检索返回的文本块,另一个是{question},即提问的问题。
RAG_TEMPLATE = """
You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
<context>
{context}
</context>
Answer the following question:
{question}"""
rag_prompt = ChatPromptTemplate.from_template(RAG_TEMPLATE)检索与question相似的文本块docs
question = "What are the approaches to Task Decomposition?"
docs = vectorstore.similarity_search(question)
docs通过format_docs转为文本串并存入新的context中,这样就形成了context和question参数,然后和rag_prompt组合为完整的提示模板进入语言模型进行处理,返回消息
from langchain_core.runnables import RunnablePassthrough
chain = (
RunnablePassthrough.assign(context=lambda input: format_docs(input["context"]))
| rag_prompt
| model
| StrOutputParser()
)
# Run
chain.invoke({"context": docs, "question": question})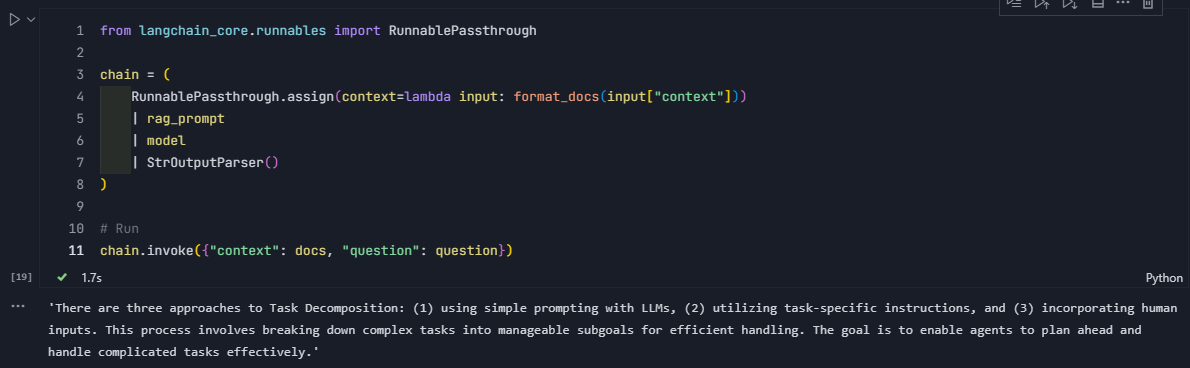
5、带有检索的QA
as_retriever()方法将将向量存储转换为检索器,可以根据问题(question)的语义相似度从向量存储中查找相关文档。
question ──┬─→ retriever ─→ format_docs ─→ context
│
└─→ RunnablePassthrough() ─→ question
context 和 question 一起传入 rag_promptretriever = vectorstore.as_retriever()
qa_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| rag_prompt
| model
| StrOutputParser()
)
question = "What are the approaches to Task Decomposition?"
qa_chain.invoke(question)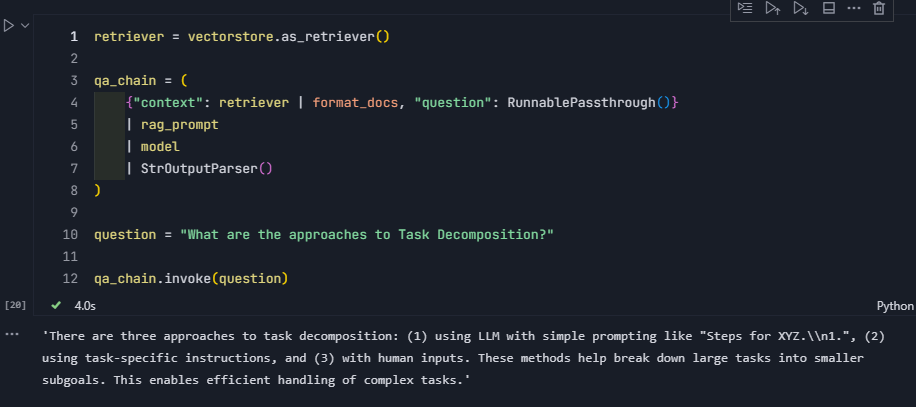
二、LlamaIndex版本
1、安装模型
- 语言模型:ollama pull llama3.1
- embedding模型:ollama pull nomic-embed-text
2、安装依赖
- LlamaIndex库:pip install llama-index
- LlamaIndex大语言模型后端:pip install llama-index-llms-ollama
- LlamaIndex嵌入模型后端:pip install llama-index-embeddings-ollama
- LlamaIndex文件读取器 (File Reader):pip install -U llama-index-readers-file
3、加载文档
加载当前目录下 data 文件夹中所有的文档,并加载到内存中。
SimpleDirectoryReader 是LlamaIndex中用于从目录读取文档的核心工具类,它能够自动识别并加载目录中的各种格式文件(如txt、pdf、docx等)。
from llama_index.core import SimpleDirectoryReader
documents = SimpleDirectoryReader("data").load_data()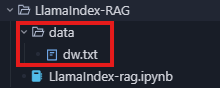
4、加载模型
通过Settings加载模型
- 嵌入模型:nomic-embed-text
- 语言模型:llama3.1:8b,这里模型的名称要加上后缀,不然后面运行会报错
from llama_index.embeddings.ollama import OllamaEmbedding
from llama_index.llms.ollama import Ollama
from llama_index.core import Settings
Settings.embed_model = OllamaEmbedding(model_name="nomic-embed-text")
Settings.llm = Ollama(model="llama3.1:8b", request_timeout=360.0)5、构建索引
通过from_documents方法将文档转化为向量表示,并存储在内部的向量数据库中并构建索引,这方便后续的相似度查询
from llama_index.core import VectorStoreIndex
index = VectorStoreIndex.from_documents(
documents,
)
执行后会输出2025-08-22 00:20:47,202 - INFO - HTTP Request: POST http://localhost:11434/api/embed "HTTP/1.1 200 OK",这说明代码正在成功运行,并且与本地的一个嵌入(embedding)模型服务进行了通信。

6、查询数据
通过as_query_engine方法构建查询引擎,通过它可以将用户问题转为向量,进行向量相似度检索,从而检索到相关文档,最后将文档作为上下文传递给LLM生成回答
query_engine = index.as_query_engine()
response = query_engine.query("Datawhale是什么?")
print(response)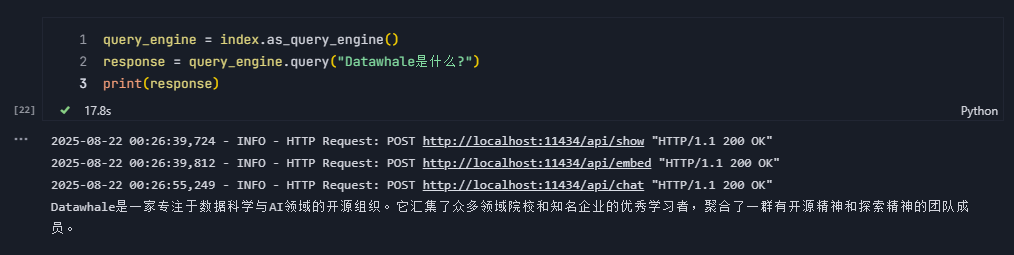
7、检索上下文进行对话
ChatMemoryBuffer用于管理聊天对话的历史记录,可以通过from_defaults方法设定的 token 上限自动保留最近的对话内容,防止内存溢出。
通过as_chat_engine方法构建一个对话引擎,将chat_mode设置为context后,系统会从索引中检索与用户问题(.chat方法输入)相关的内容,并将这些内容作为上下文注入到大模型的提示中。memory用于用于在对话过程中保存历史消息,实现多轮对话。system_prompt设置系统提示语,定义聊天机器人的角色和行为。
# 检索上下文进行对话
from llama_index.core.memory import ChatMemoryBuffer
memory = ChatMemoryBuffer.from_defaults(token_limit=1500)
chat_engine = index.as_chat_engine(
chat_mode="context",
memory=memory,
system_prompt=(
"You are a chatbot, able to have normal interactions."
),
)
response = chat_engine.chat("Datawhale是什么?")
print(response)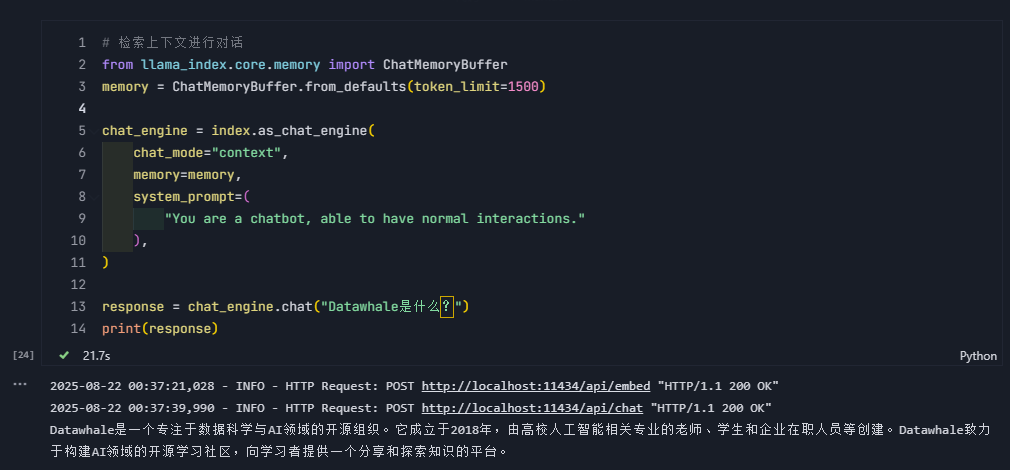
8、向量索引的存储和加载
- 向量索引存储:通过storage_context.persist方法,将向量索引(包括向量、文档、节点、元数据等)存储到磁盘中。
- docstore.json:存储原始文档以及分割后的文本节点

- vector_store.json:存储每个文本节点对应的向量
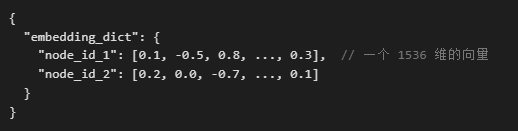
- index_store.json:存储索引的结构信息,比如构建了哪些索引(如向量索引、关键词索引),指向文档和向量的指针
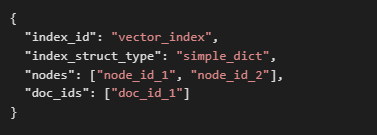
- graph_store.json:存储实体、关系、三元组等图结构。
- metadata:
- docstore.json:存储原始文档以及分割后的文本节点
- 向量索引加载:通过StorageContext.from_defaults方法,指定加载向量索引的路径。通过load_index_from_storage方法,自动识别并加载文档、节点、向量嵌入和索引结构。
- 从data/读取所有 JSON 文件
- 重建文档节点、向量、索引结构
- 将它们重新组合成一个可用的VectorStoreIndex对象
# 存储向量索引
persist_dir = 'data/'
index.storage_context.persist(persist_dir=persist_dir)
# 加载向量索引
from llama_index.core import StorageContext, load_index_from_storage
storage_context = StorageContext.from_defaults(persist_dir=persist_dir)
index= load_index_from_storage(storage_context)
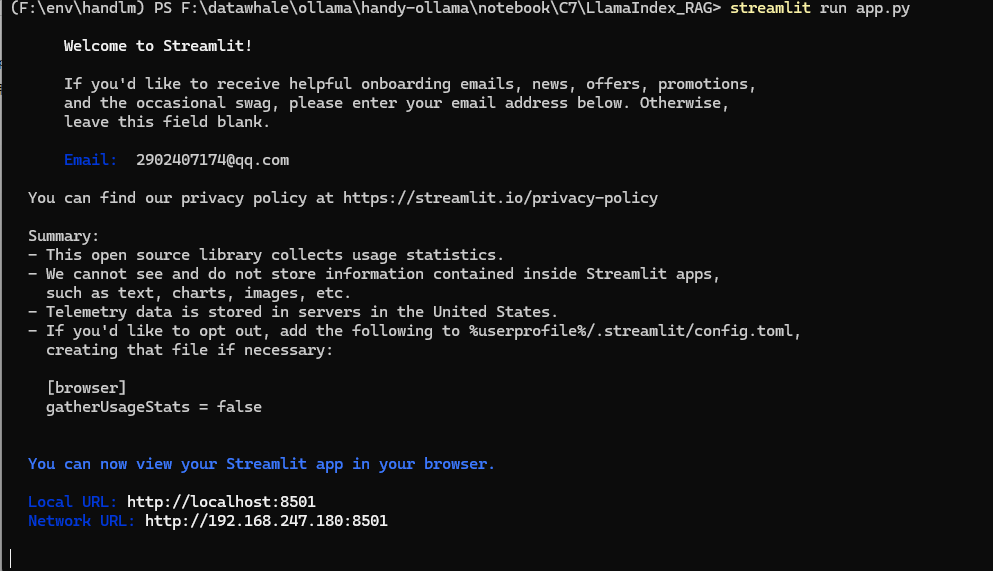
9、streanmlit应用
安装依赖:
- pip install streamlit
命令行执行:
- streamlit run app.py
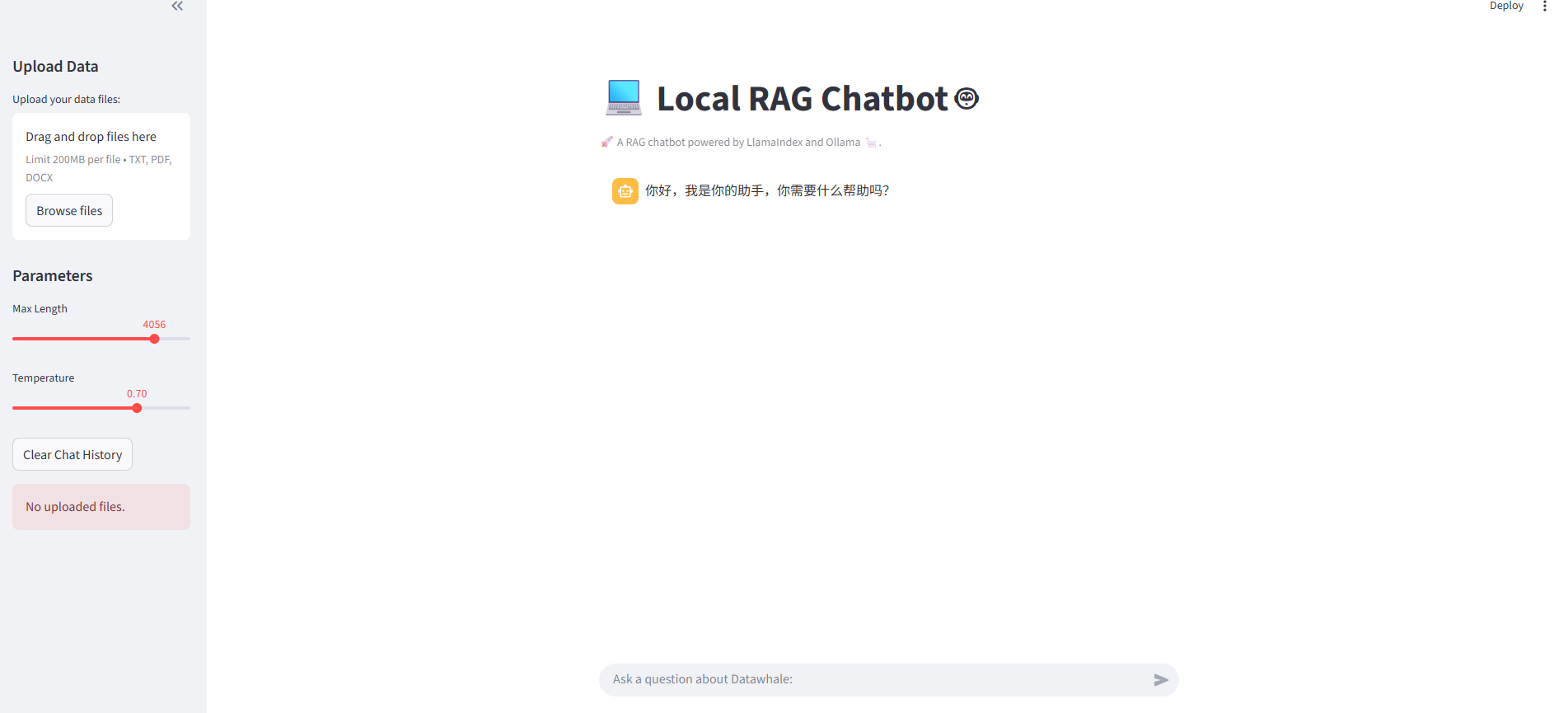
三、Deepseek R1版本
同第一部分类似,只不过将大语言模型换位Deepseek R1,文件类型换为本地PDF
Deepseek R1下载:ollama pull deepseek-r1:1.5b
1、文档加载
通过PDFlumberLoader方法从pdf文件加载文档
安装PDFplumber:pip install pdfplumber
from langchain_community.document_loaders import PDFPlumberLoader
file = "DeepSeek_R1.pdf"
# Load the PDF
loader = PDFPlumberLoader(file)
docs = loader.load()2、文档分割
将文档切分为适当大小的文本块
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
all_splits = text_splitter.split_documents(docs)3、初始化向量存储
将文本块通过嵌入模型向量化并通过chroma数据库存储
from langchain_chroma import Chroma
from langchain_ollama import OllamaEmbeddings
local_embeddings = OllamaEmbeddings(model="nomic-embed-text")
vectorstore = Chroma.from_documents(documents=all_splits, embedding=local_embeddings)4、构建chain表达式
加载模型
from langchain_ollama import ChatOllama
model = ChatOllama(
model="deepseek-r1:1.5b",
)问题检索
question = "What is the purpose of the DeepSeek project?"
docs = vectorstore.similarity_search(question)构建处理链
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_template(
"Summarize the main themes in these retrieved docs: {docs}"
)
# 将传入的文档转换成字符串的形式
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
chain = {"docs": format_docs} | prompt | model | StrOutputParser()
chain.invoke(docs)5、带有检索的AQ
from langchain_core.runnables import RunnablePassthrough
RAG_TEMPLATE = """
You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
<context>
{context}
</context>
Answer the following question:
{question}"""
rag_prompt = ChatPromptTemplate.from_template(RAG_TEMPLATE)
retriever = vectorstore.as_retriever()
qa_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| rag_prompt
| model
| StrOutputParser()
)
question = "What is the purpose of the DeepSeek project?"
# Run
qa_chain.invoke(question)
有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 14
14 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)