DeepSeek V3.1正式发布,专为下代国产芯设计
这个效果其实和当初的 DeepSeek-R1-0528 模型没啥太大区别,但相对比于 DeepSeek-V3-0324 还是有显著提升的,特别是审美和输出 token 的控制上。更何况,我这会是在 Claude Code 中使用的,要知道,在此之前,DeepSeek 的模型还无法使用 Agent 能力。好家伙,所以,在外面模型一顿厮杀的时候,DeepSeek 迟迟不发布的原因,可能是做国产芯片的适
这是苍何的第 423 篇原创!
大家好,我是苍何。
就在今天下午,DeepSeek 官方宣布 DeepSeek-V3.1 正式发布。

并且在评论区,DeepSeek 直接摊牌:是针对即将发布的下一代国产芯片设计。
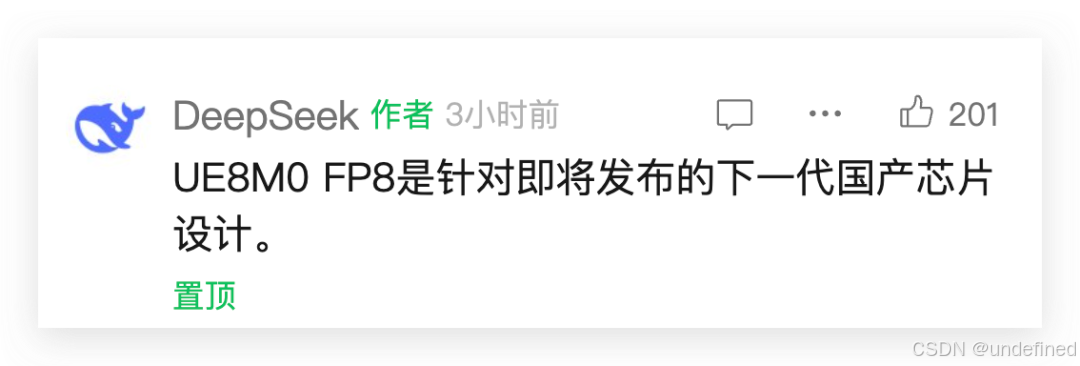
这次,DeepSeek-V 3.1 使用了 UE8M0 FP8 Scale 的参数精度,而UE8M0 FP8 是专门针对即将发布的下一代国产芯片设计。
好家伙,所以,在外面模型一顿厮杀的时候,DeepSeek 迟迟不发布的原因,可能是做国产芯片的适配?
文末会附上实测 case 和接入 Claude Code 教程,欢迎点赞转发。
这消息一放出,A 股又沸腾了。
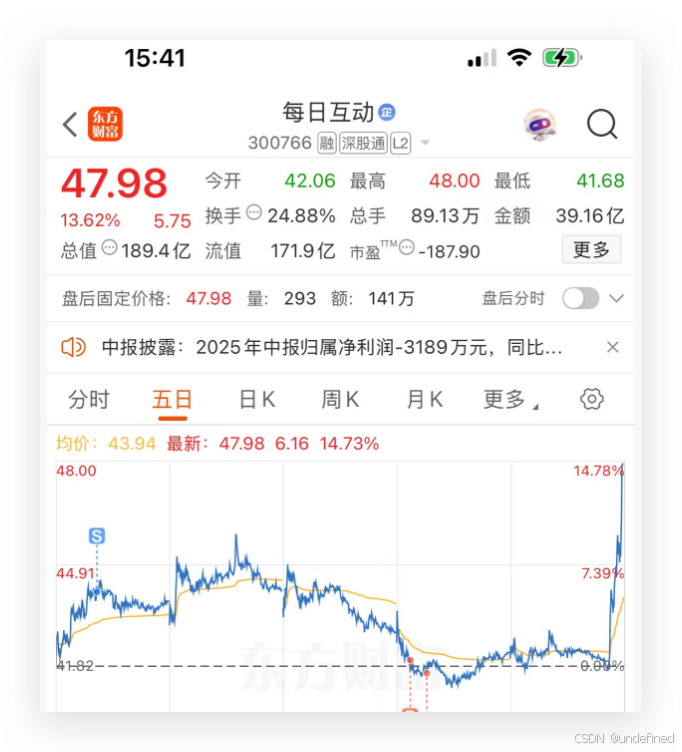
这事儿为啥能让圈内人这么激动?因为天下苦英伟达久矣。
在 AI 圈,英伟达的 GPU 和 CUDA 软件生态,就像是孙悟空头上的紧箍咒。你想搞 AI,基本上就得在它的规则里玩。
这不仅仅是买几张显卡的事。英伟达牛就牛在,它不仅卖给你锄头(GPU),还把怎么刨地的独家秘籍(CUDA)安排得明明白白。
无数的AI框架、算法、开发者,十几年下来,已经在这套秘籍上绣出了花。
你要另起炉灶?行啊,但得先翻过三座大山。
第一座山,是生态的鸿沟。你得自己重写一套秘籍,还得让大家觉得比CUDA还好用,愿意抛弃十几年的习惯来学你的。这难度太高了。
第二座山,是性能的差距。就算搞出了自己的软硬件,能跟人家迭代十几年的成熟工业品比吗?一开始,大概率是‘别人开法拉利,你开手动拖拉机。
第三座山,是信任的壁垒。开发者和公司都是用脚投票的。放着好好的阳关大道不走,为啥要陪你摸着石头过一条前途未卜的河?
所以说,想突破芯片封锁,真正的难点从来不是造出一块能用的芯片,而是建立一个有人用的生态。
在英伟达的生态花园里,你可以种任何想种的花,但前提是,你得用老黄家的土。
过去,我们很多时候的思路是硬件追赶。先造出个差不多的芯片,再去求着软件和算法来适配。
结果往往是,硬件出来了,软件跟不上,最后英雄无用武之地。
而 DeepSeek 这次直接反过来,玩了一招软件定义硬件,生态同步生长。
它不等芯片发布,就提前在自己的核心模型里,把路给铺好了。
以前我们是等路修好了再找车,现在是 DeepSeek一边造车,一边跟修路的一起画图纸。
这次虽然是个小版本的更新,但我觉得还是很有意义的,除了宣布了专为下一代国产芯片设计的重磅消息。
DeepSeek-V3.1 此次在工具调用和 Agent 的支持上有显著增强。
甚至已经支持直接将 DeepSeek-V3.1 接入 Claude Code。
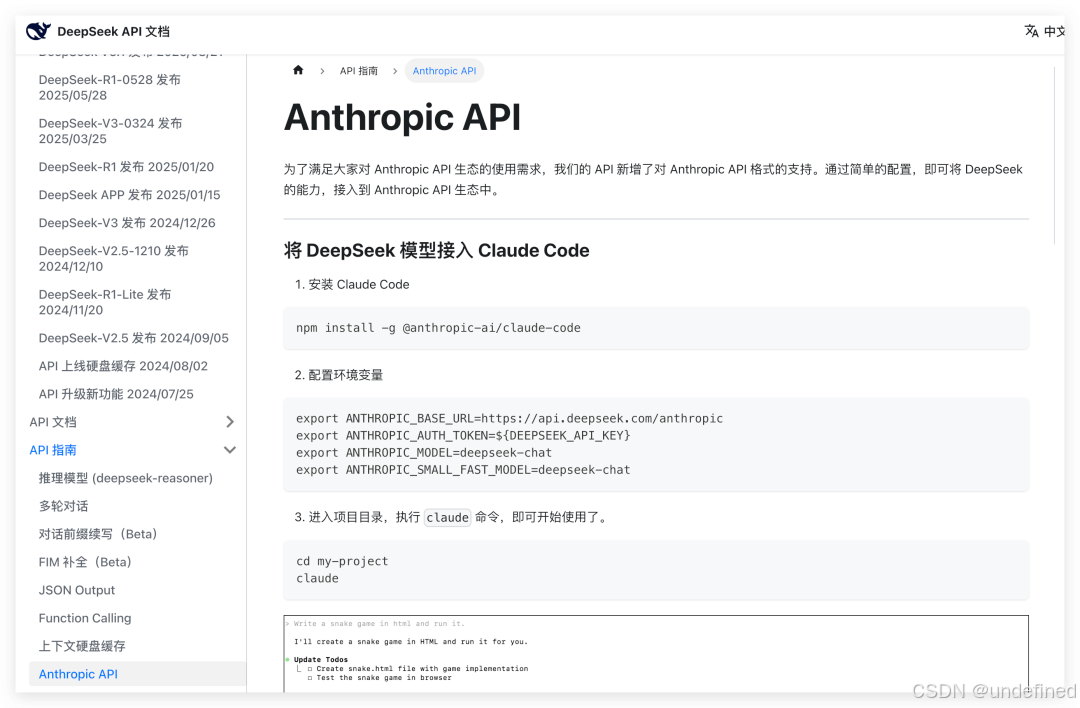
给大家总结下此次版本带来了哪些能力的更新。
-
混合推理架构:一个模型同时支持思考模式与非思考模式;
-
更高的思考效率:相比 DeepSeek-R1-0528,DeepSeek-V3.1-Think 能在更短时间内给出答案;
-
更强的 Agent 能力:通过 Post-Training 优化,新模型在工具使用与智能体任务中的表现有较大提升。
-
上下文扩展到 128 K。
相比之前的 DeepSeek 系列模型,官方透露 V3.1 在代码修复测评 SWE 与命令行终端环境下的复杂任务(Terminal-Bench)测试中,有显著提高。
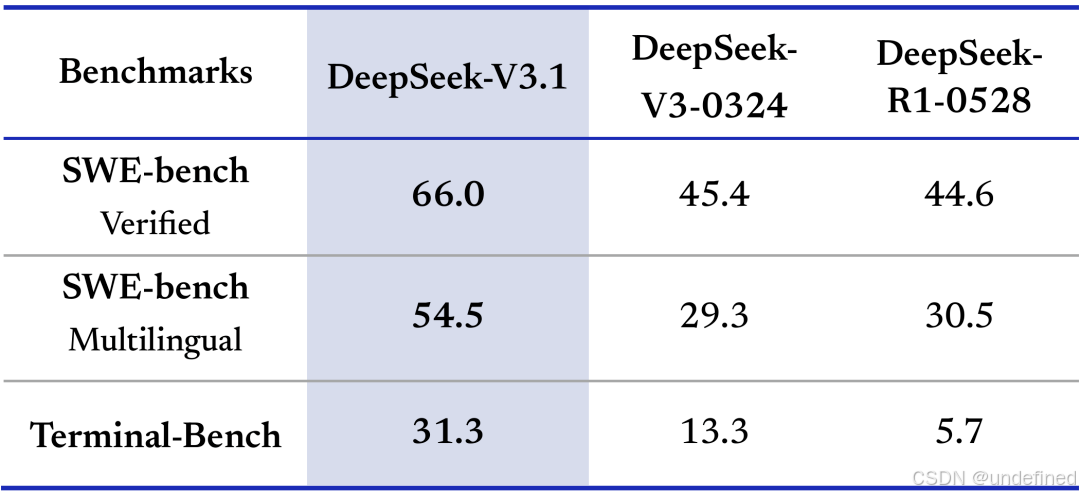
SWE-bench 是一个专门考察 AI 像真人程序员一样,去修复 GitHub 上真实软件项目里 Bug 的能力测评,Terminal Bench 是一个专门考察 AI 在命令行里,独立完成各种复杂系统操作和软件管理任务的能力测评。
V3.1 在非思考模式下的输出长度得到了有效控制,相比于 DeepSeek-V3-0324 ,能够在输出长度明显减少的情况下保持相同的模型性能。
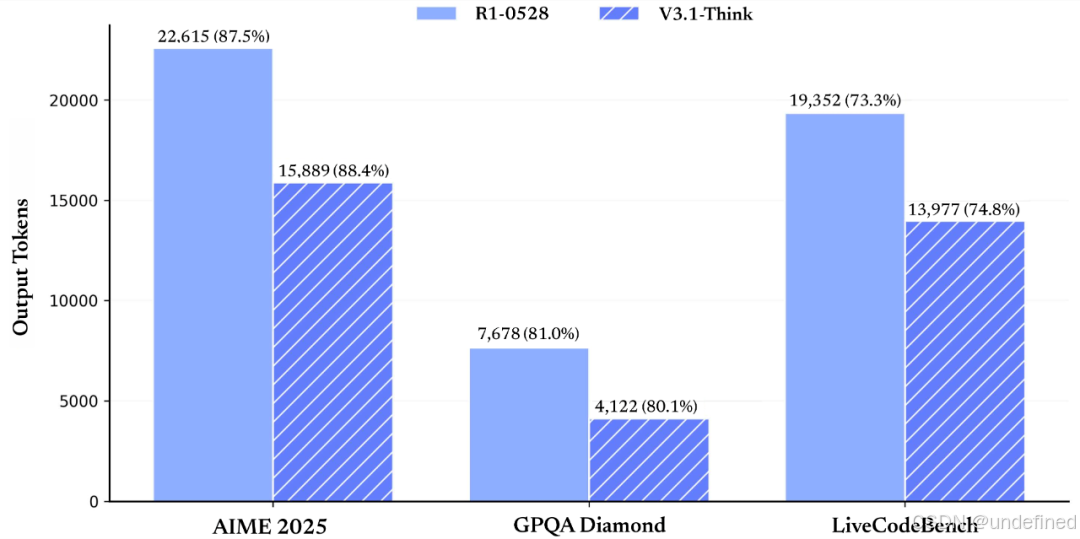
目前 DeepSeek-V3.1 已在 Huggingface 和魔搭开源了 Base 模型,Base 模型在 V3 的基础上重新做了外扩训练,一共增加训练了 840B tokens。

下面,看看 DeepSeek V3.1 在 Claude Code 中的表现吧。
实测
用 CC 来验证下 DeepSeek 的编程和 Agent 能力,看看实测效果如何吧。
case 1:前端审美能力
提示词:
我想开发一个记账 APP,现在需要输出原型图,请通过以下方式帮我完成 APP 所有原型图片的设计。
1. 思考用户需要记账 APP 实现哪些功能
2. 作为产品经理规划这些界面
3. 作为设计师思考这些原型界面的设计
4. 使用 HTML 在一个界面上生成所有的原型界面,可以使用 FontAwesome 等开源图标库,让原型显得更精美和接近真实我希望这些界面是需要能直接拿去进行开发的
5. 每一个模块之间用 Grid 方式排版,根据屏幕宽度自适应,每行 2~3 个可以看到,在 Claude Code 中 DeepSeek-V3.1 开始根据 task 来进行 code。
花了大概几分钟,效果如下:
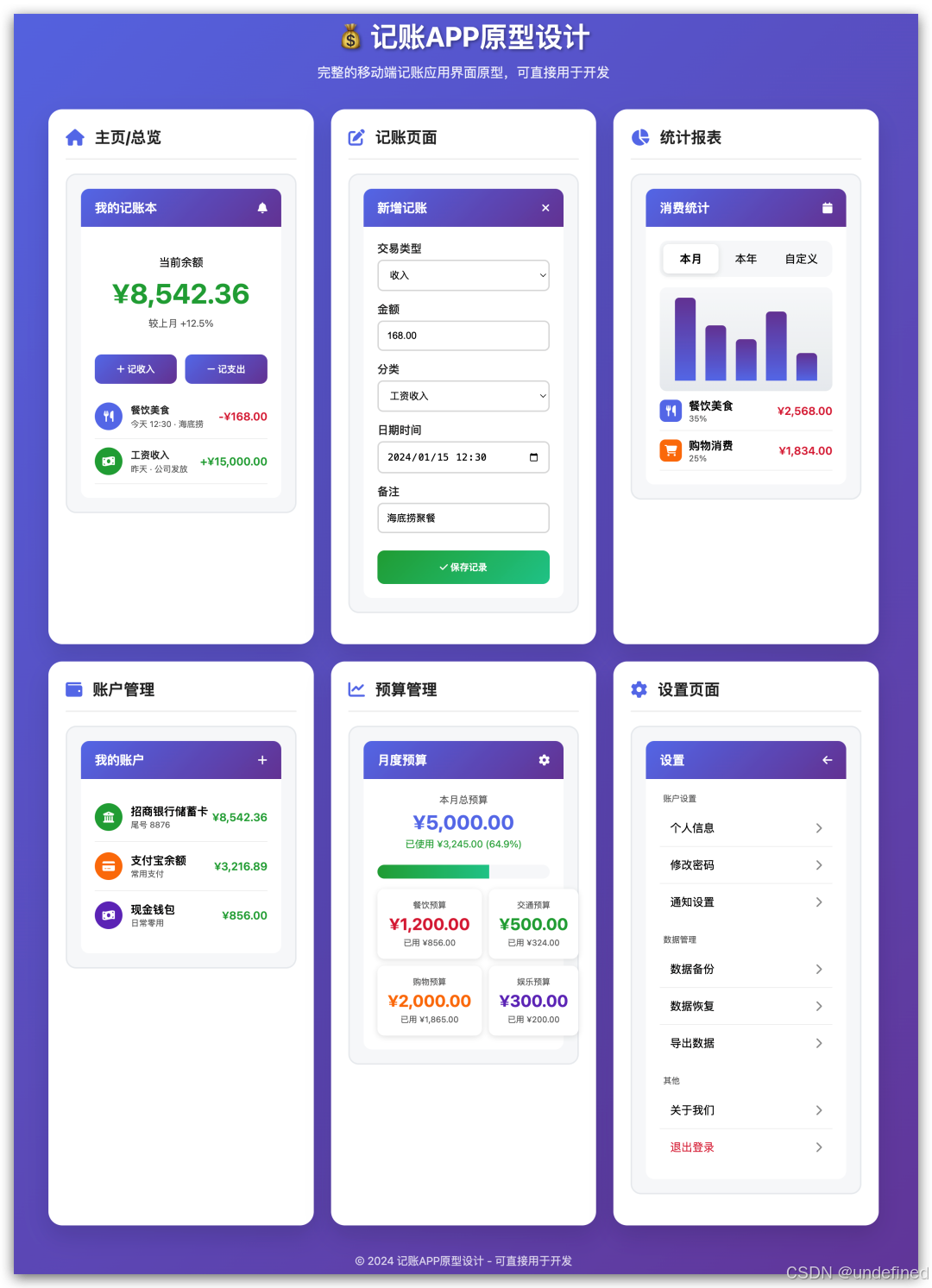
这个效果其实和当初的 DeepSeek-R1-0528 模型没啥太大区别,但相对比于 DeepSeek-V3-0324 还是有显著提升的,特别是审美和输出 token 的控制上。
更何况,我这会是在 Claude Code 中使用的,要知道,在此之前,DeepSeek 的模型还无法使用 Agent 能力。
正如 DeepSeek 官方自己说的,这次更新或许是 DeepSeek 迈向 Agent 时代的重要一步吧。
case 2:3D 气球:
提示词: 做一个3d版的地球出来,还要有夜间灯光那种(编写一个高级3D地球模型,包含实时光照、大气效果、交互控制..) 
这个经典的 case,还是能很好的体现模型自身的编程能力的,我们看下DeepSeek-V3.1 的效果:
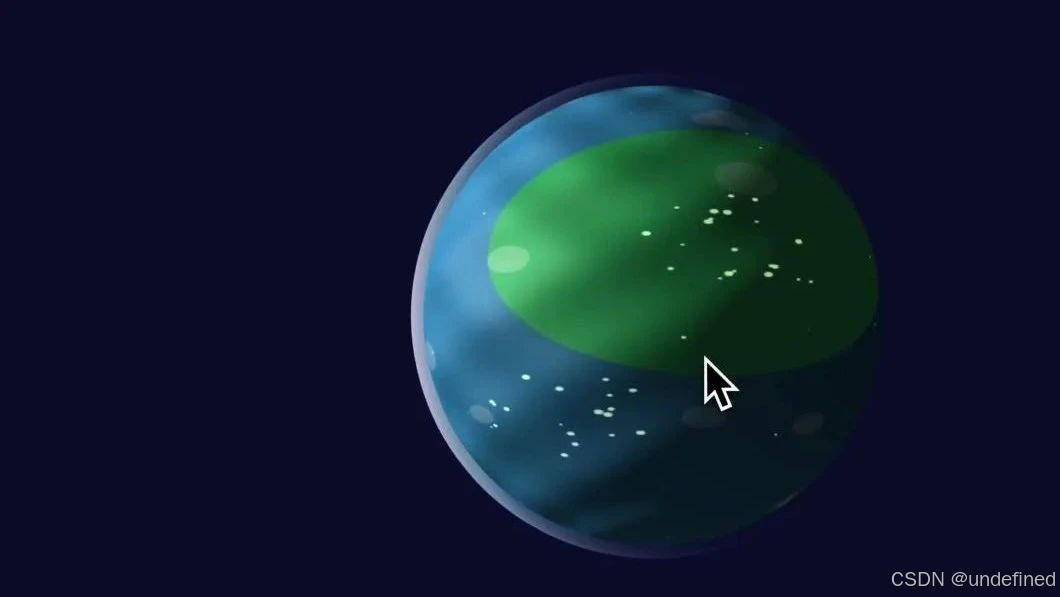
这个效果,很棒了,几乎和 Claude 4 出来的效果差不多了。
case 3:六边形弹力小球
提示词: 做一个六边形弹力小球,模拟真实小球在六边形的弹射,可以控制旋转速度等,写在一个html里面 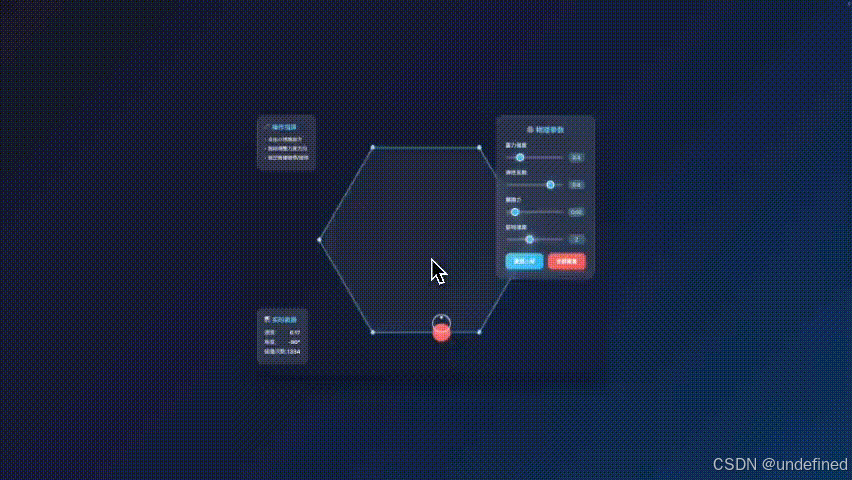
这个说实话,有点过了吧,哈哈哈,还自带尾翼?
整体测下来,表现并没有说多遥遥领先,和一些顶尖模型比,可能还有一些差距。
下面给大家梳理下接入 Claude Code 教程。
接入 Claude Code 教程
第一步,先安装 Claude Code。
这里之前苍何的文章也介绍过啦,已经安装了的小伙伴可继续往下看哈。
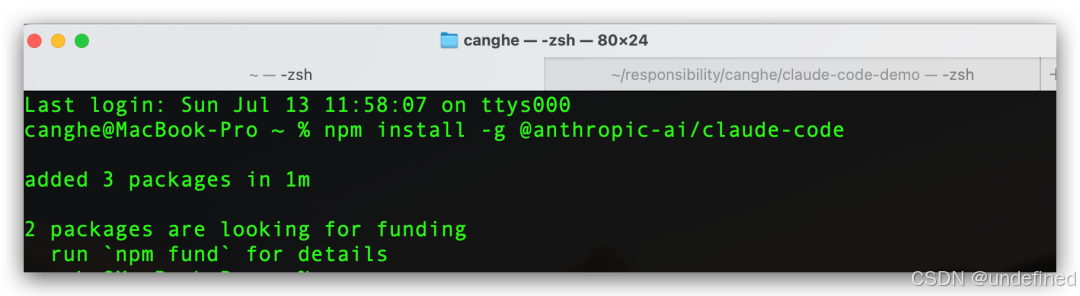
终端中输入命令:
npm install -g @anthropic-ai/claude-code 请勿使用 sudo npm install -g ,因为这可能会导致权限问题和安全风险。
安装好后是这样:
第二步,申请 DeepSeek API
打开 DeepSeek 的 API 开放平台:https://platform.deepseek.com/api_keys,创建 Key:
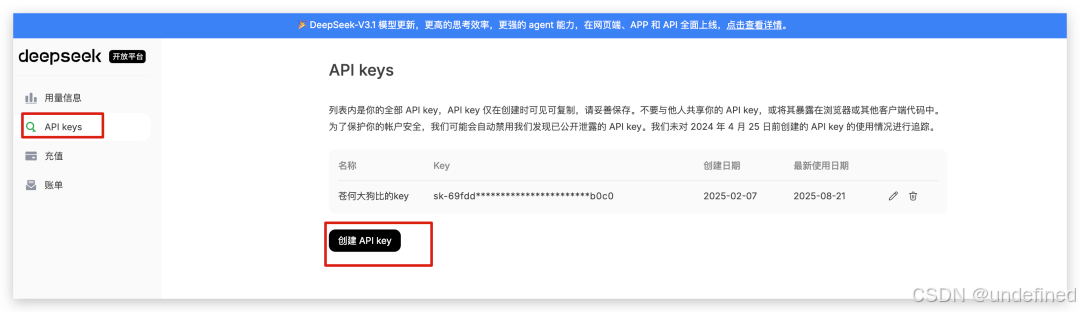
复制这个 key
第三步,配置环境变量:
然后在终端中替换 ${DEEPSEEK_API_KEY} 为刚才创建的 key。
export ANTHROPIC_BASE_URL=https://api.deepseek.com/anthropic export ANTHROPIC_AUTH_TOKEN=${DEEPSEEK_API_KEY}export ANTHROPIC_MODEL=deepseek-chat export ANTHROPIC_SMALL_FAST_MODEL=deepseek-chat 可以在终端中输入命令:env,查看当前配置的环境变量。
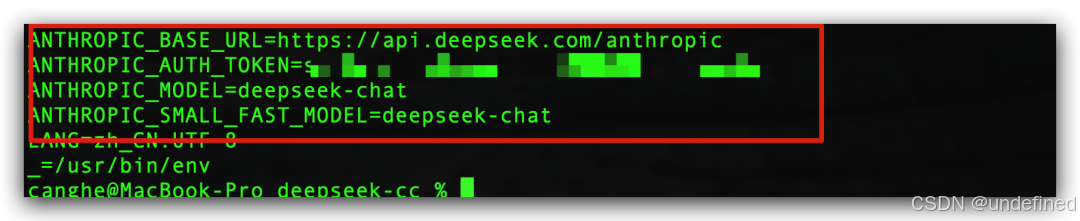
下面只需要进入自己的目录,终端中输入:claude,就好了。
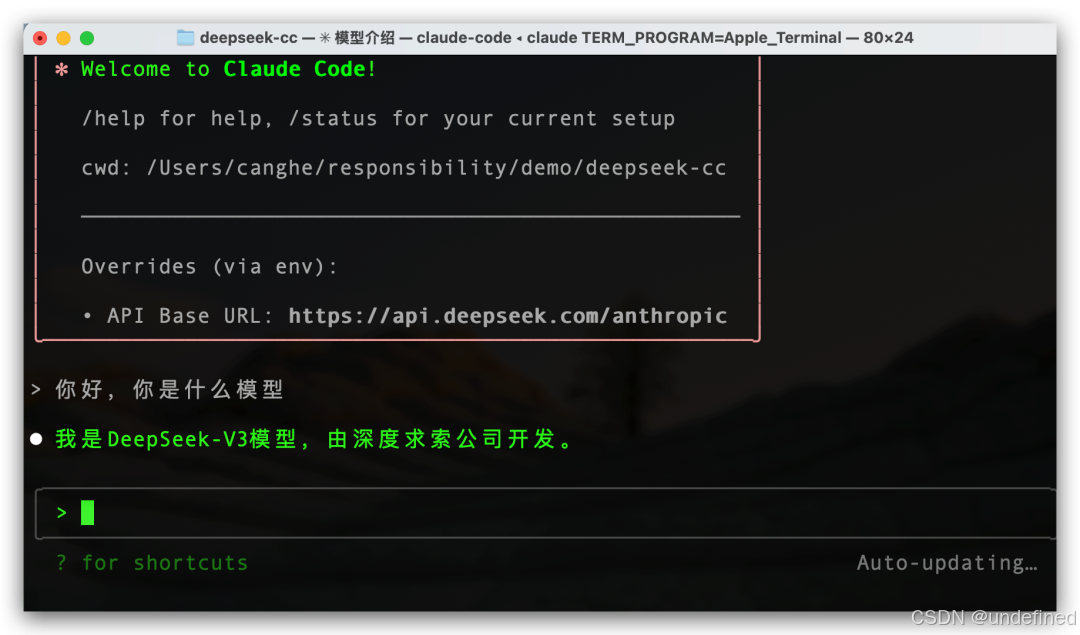
从模型适配,到大规模训练,再到推理的稳定性和性价比,还有无数的坑要填,无数的仗要打。
但无论如何,DeepSeek这次摊牌,让我们看到了一个清晰的可能性。
那就是通过软硬件的深度协同,我们有机会打造一个独立自主、正向循环的AI生态。
这条路很难,很难,但总要有人开始走。
让我们给 DeepSeek 一点时间,也给即将到来的下一代国产芯,亿点点期待。
这盘大棋,越来越有意思了。
好啦,以上全文 2349 字,15 张图,如果这篇文章对你有用,可否点个关注,给我个三连击:点赞、转发和再看。若可以再给我加个⭐️。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 11
11 0
0- 0



 已为社区贡献39条内容
已为社区贡献39条内容

所有评论(0)