RAG-Fusion详细介绍
在大语言模型(LLM)驱动的应用浪潮中,检索增强生成(Retrieval-Augmented Generation, RAG) 技术已成为连接模型与海量外部知识的桥梁,极大地提升了AI生成内容的事实性和准确性。但是,传统的RAG也有缺陷,它在面对用户意图模糊或表达方式多样的查询时,常常会遇到瓶颈。不过幸运的是,有人提出了RAG-Fusion这一技术,可以很大成大的改善这种困境。本文将从底层原理到实
在大语言模型(LLM)驱动的应用浪潮中,检索增强生成(Retrieval-Augmented Generation, RAG) 技术已成为连接模型与海量外部知识的桥梁,极大地提升了AI生成内容的事实性和准确性。但是,传统的RAG也有缺陷,它在面对用户意图模糊或表达方式多样的查询时,常常会遇到瓶颈。
不过幸运的是,有人提出了RAG-Fusion这一技术,可以很大成大的改善这种困境。本文将从底层原理到实战应用,详细的介绍RAG-Fusion。
一、传统RAG的困境
在开始介绍RAG-Fusion之前,我们先来看看它是为了解决什么问题而提出来的。
一个传统的RAG流程通常是“一次查询,一次检索”。系统接收用户问题,将其编码为向量,然后在知识库中寻找几个最相似的文档片段(Top-K)并将其喂给LLM作为上下文。具体流程如下所示:
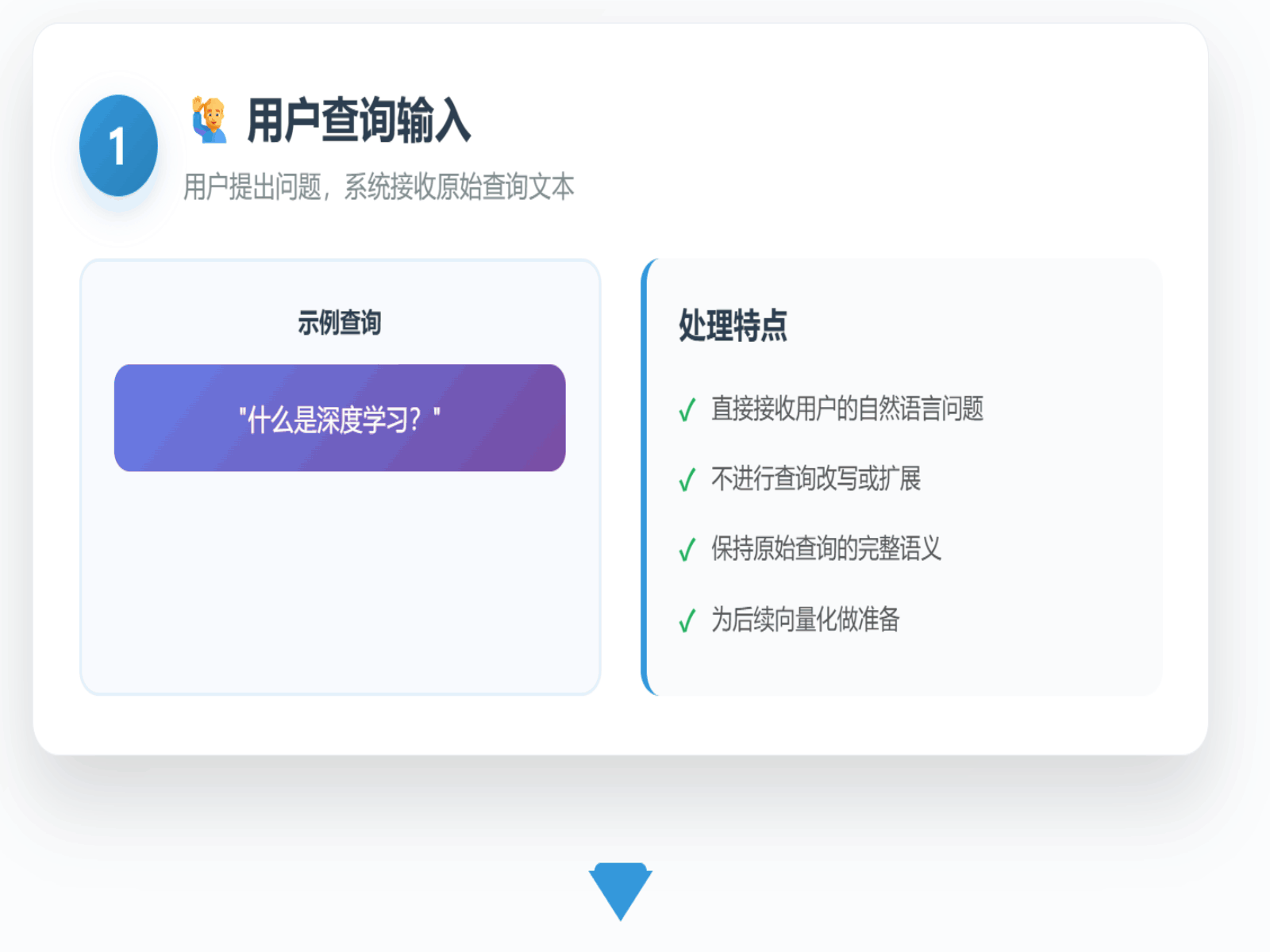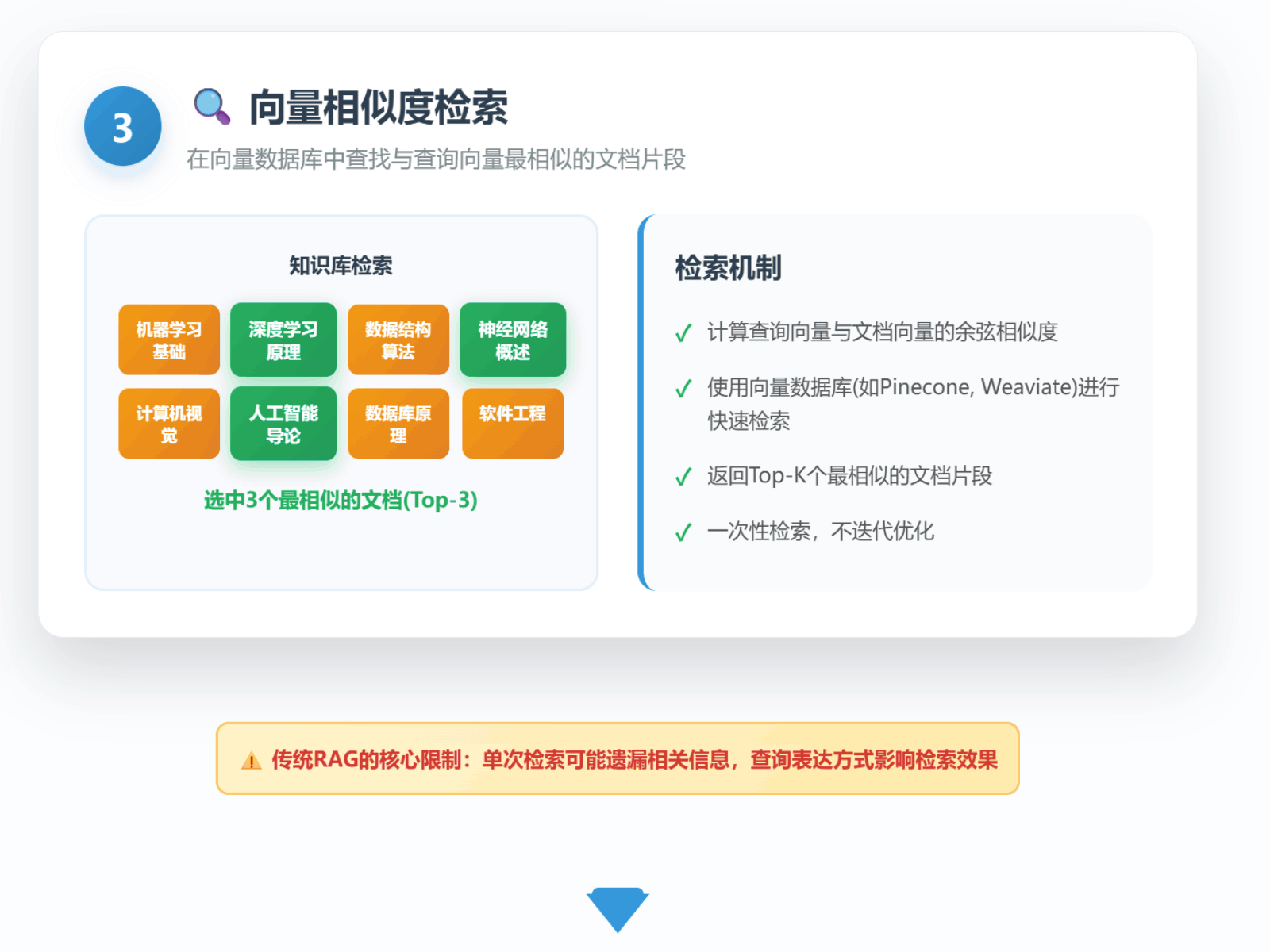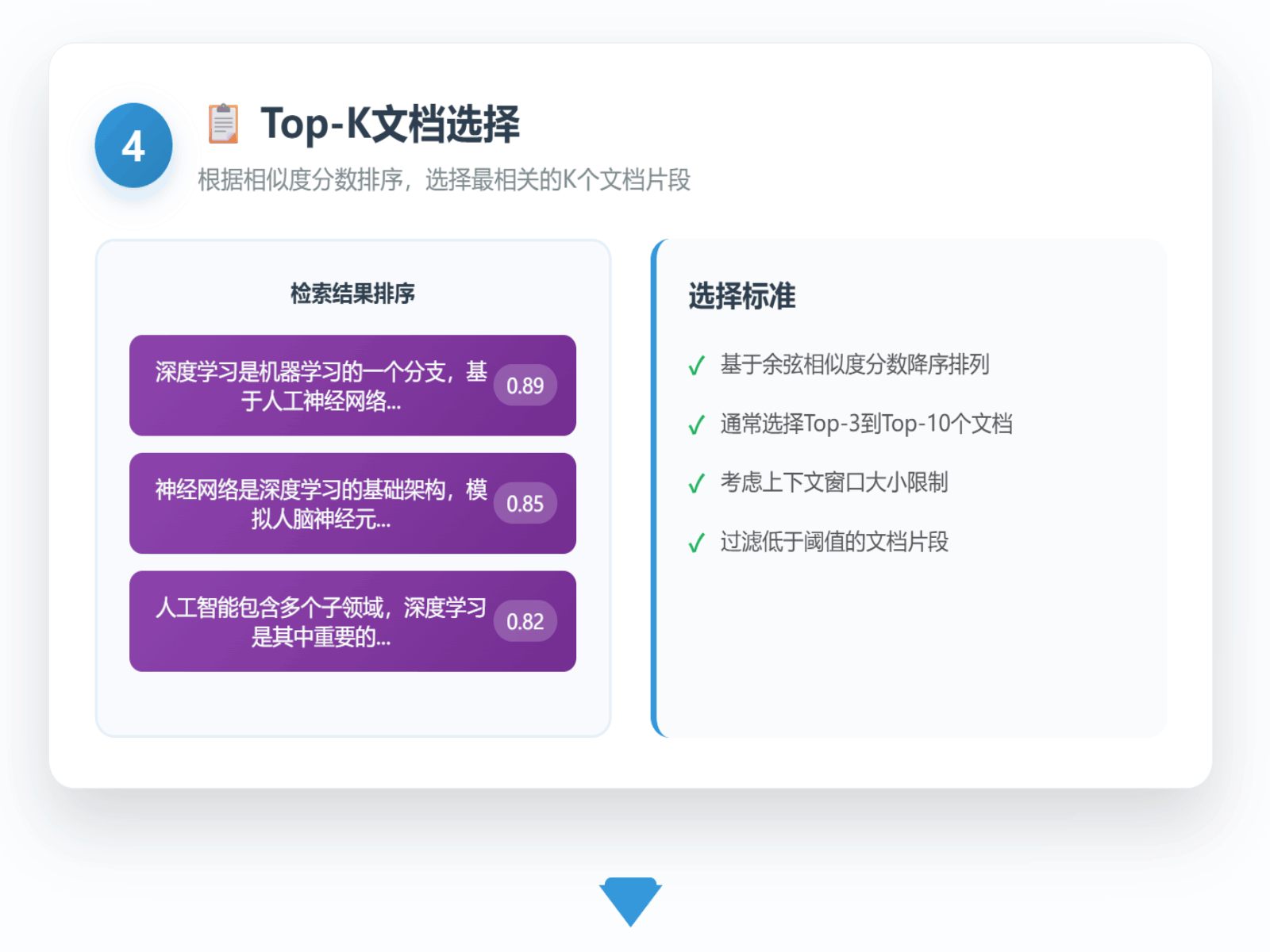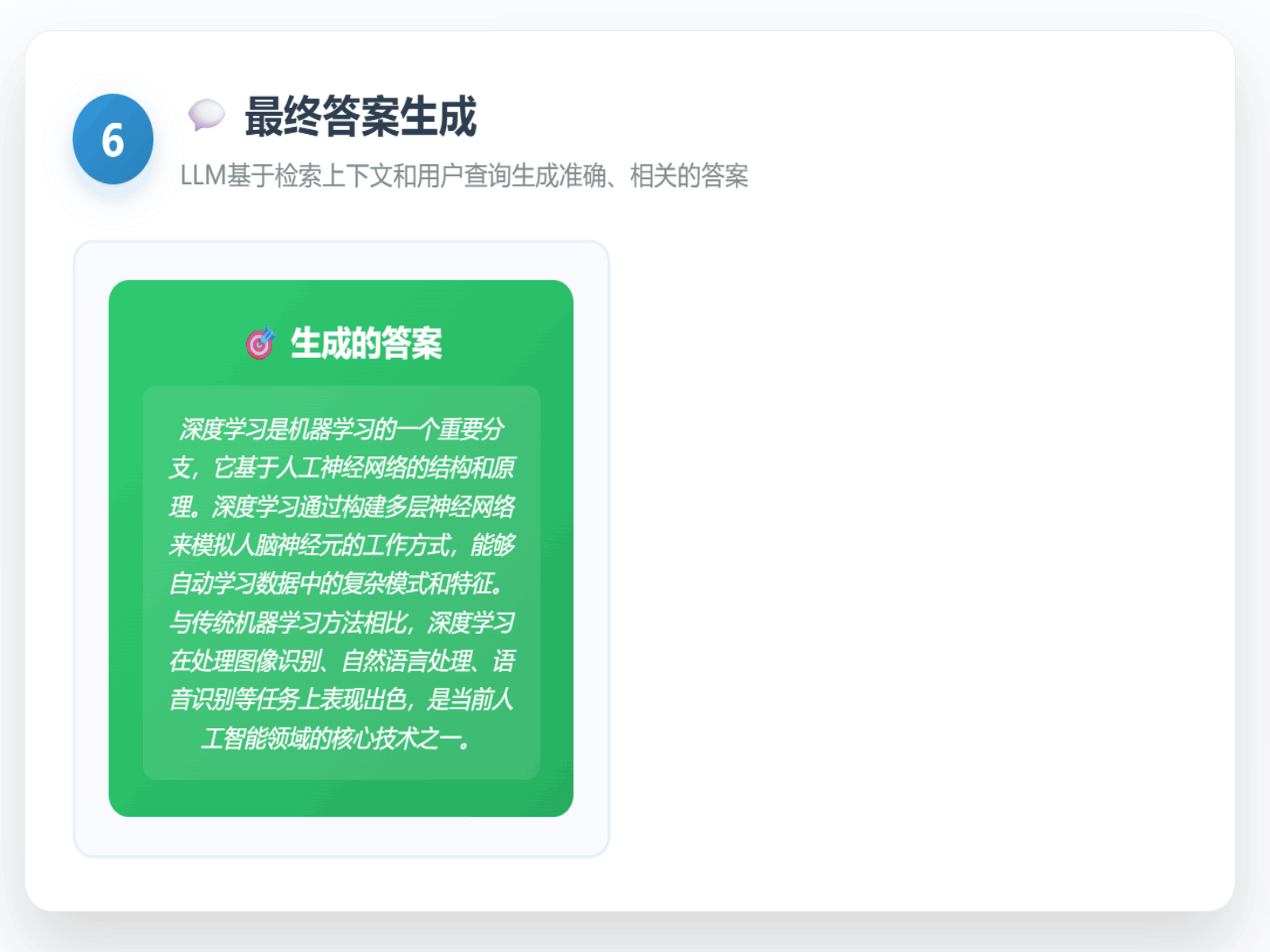
这个看似高效的流程,在现实世界的复杂业务场景中却暗藏着几个关键痛点:
1.1 单一检索偏差
单一检索偏差(Retrieval Bias)指的是在信息检索过程中,系统的返回结果几乎完全取决于用于的提问方式或查询表述。换句话说,如果用户换一种说法,哪怕表达的需求本质相同,检索结果也可能差异巨大。我们来看个例子:
例子:用户输入"苹果的最新发布会"。如果你的知识库中同时包含有关"苹果"这一词的在农业和科技领域的信息,向量模型可能会因为“苹果”一词的向量产生混淆,最终检索出的结果是关于“xxx苹果的年度产量报告”。一旦这一步走错了,那后期LLM拿到的就是一堆水果信息,所产出的回答自然也就和用户的意愿相悖。
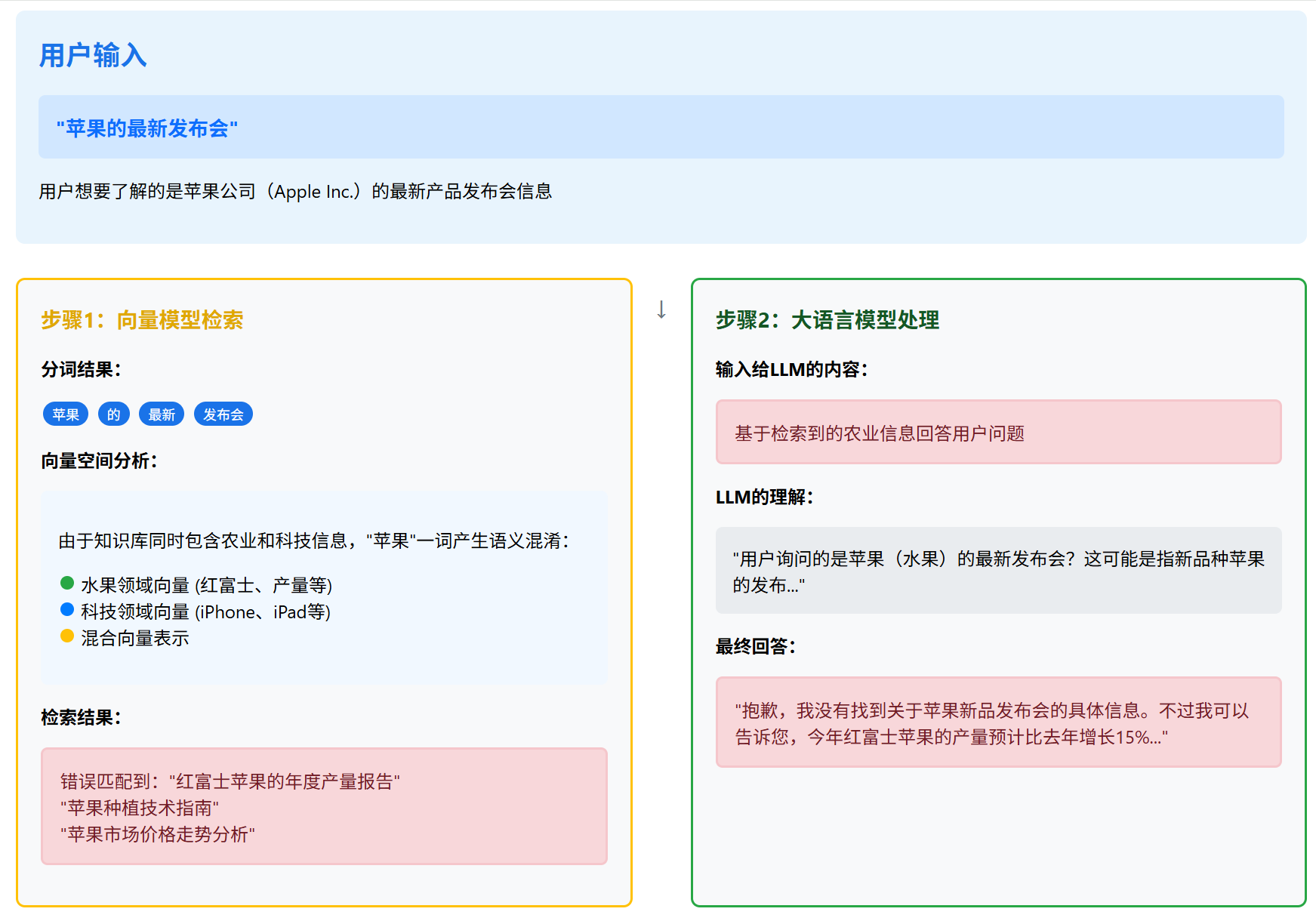
这其实就是一个典型的语义歧义问题,我们可以稍微的总结一下造成该结果的原因:
- 上下文缺失:向量模型缺乏足够的上下文来准确判断用户意图
- 连锁反应:第一步检索错误导致后续所有处理都偏离正确方向
1.2 信息覆盖不足
信息覆盖不足是指在检索过程中,由于采用了Top-K策略,系统只会返回排名前K条结果。的确,这种策略提高了检索效率并降低了计算开销,这毋庸置疑,但同时也可能带来信息缺失的风险。因为在很多场景下,关键信息可能并不在前K条结果中,而是在被截断的后续结果中,这也就导致用户获取到的信息存在偏差或不完整。这种“效率与全面性”的权衡,使得Top-k在提升响应速度的同时,也容易牺牲信息覆盖度,造成对重要信息的遗漏。
不过,这种策略依然是当前阶段工程上最优的折中方案。因为,在显示的复杂业务场景中,检索库可能包含千万、甚至上亿条文档,全量送给大模型是不可能的。Top-K可以快速压缩候选,降低显存和推理成本。并且,在大多数情况下,前几条结果已经足够覆盖主流问答需求,实际应用中用户更在意“快”和“可用”,而不是理论上的完备性。
1.3 长尾查询难题
我们先来看看什么是“长尾”以及什么是“长尾查询”
在信息检索中,用户的查询分布遵循“长尾效应“——少数查询(热门、高频问题)被大量用户频繁提出,而大多数查询(冷门、个性化、稀有问题)出现得非常少,但整体数量庞大。
“长尾查询”指得是那些低频、冷门、表达方式独特得查询。比如:
- 热门(头部查询):“ChatGPT是什么?”、“如何安装Python?”
- 长尾查询:“能给我推荐几个能在安卓8.1上的轻量级Python解释器吗?“
前者很多人都会问,语义容易匹配。后者稀奇古怪,表达方式也多样,语义检索器往往难以精准理解。
长尾查询难题指的是用户在真实场景中的提问往往具有随意性、多样性和不可预测性,很多问题并不会出现在训练或构建索引时的“常见模式”中。当用户提出长尾问题时,传统RAG的检索器(通常基于语义相似度)很可能无法捕捉其真正意图,结果要么检索不到相关文档,要么返回的内容与需求偏离。由于生成模型的回答严重依赖检索结果,这种检索偏差会直接传导到生成阶段,导致答案不稳定、片面甚至错误。
我们来看一个例子:
场景:想象一个医疗问答RAG系统。
- 查询A(专业):“高血压患者的饮食禁忌有哪些?“
- 查询B(口语):“我爸血压有点高,平时吃饭要注意点啥?“
对于我们人类来说,这两个问题意图一致。但对于模型,查询B中的“我爸”、“有点高”、“注意点啥”这些口语化、非关键的词汇会严重影响查询向量的生成,使其偏离知识库中那些以专业术语撰写的文档,从而导致检索结果质量大幅下降。
二、RAG-Fusion
面对上述困境,RAG-Fusion提出了一种解决方案。它的核心思想非常直观:不再依赖单一的用户查询,而是通过生成多个视角下的衍生查询,并将它们的检索结果进行智能融合,从而模拟出人类从不同角度思考和搜集信息的过程。
2.1 对抗单一偏差
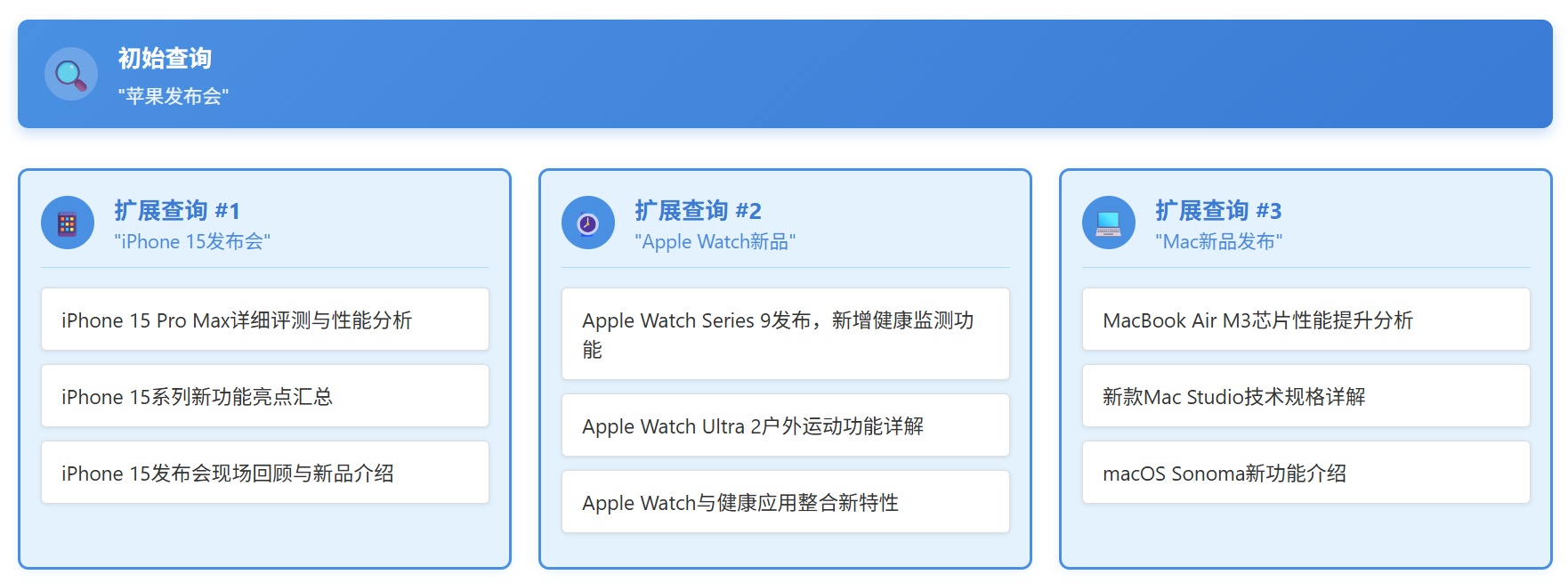
我们以1.1章节的例子来说明,RAG-Fusion会把用户的原始查询“苹果发布会”扩展成一组相互补充的查询,例如“Apple最新产品发布会”、“苹果公司最近有什么活动”、“iPhone系列发布会时间线“等一系列问题,覆盖同义表达(发布会/活动)、实体指代(Apple/苹果)、时间约束(最新/近期)与潜在子意图(产品线/新闻)。
系统随后对每个查询独立检索,得到多组候选文档,并通过排序融合把在多查询下反复出现、且排名文档考前的文档提到前列。再结合时间衰减与交叉重排提高“最新且相关“的权重。这样,即使原始查询含糊或带偏,其它扩展查询也能把检索“拉回正轨”,在不显著增加上下文从长度的前提下显著提升召回的完整性与稳定性,从而减少因单一提问方式带来的偏差。
时间衰减:
- 背景:像“苹果发布会”这种查询,往往有多个版本(去年、前年、甚至十年前的发布会)
- 问题:如果检索器只看语义相似度,可能会把“2015苹果发布会“排在很前面,但对用户来说其实是过时信息。
- 解决方法:在排序时引入“时间衰减”因子,对较早的文档降低权重,对最新的文档提高权重。
交叉重排
- 背景:向量检索器是先把“查询”和“文档”编码到向量空间,再算相似度。它速度快,但粒度粗糙,可能排错顺序。
- 问题:比如“苹果发布会”,检索出一堆结果,里面既有“Apple Watch上市新闻“,也有”Apple生态系统介绍“,它们都和“Apple”相关,但相关度并不一样。
- 解决办法:在得到Top-k候选后,再用一个Cross-encoder(会将查询和文档拼在一起输入模型)来细致判断语义相关性,并重新排序。
补充:有关时间衰减的实例代码:
class TimeDecayRetriever:
"""带时间衰减因子的检索器"""
def __init__(self, decay_factor: float = 0.1):
"""
初始化检索器
:param decay_factor: 时间衰减因子,值越大衰减越快
"""
self.decay_factor = decay_factor
self.current_date = datetime.now()
def calculate_time_decay(self, publish_date: datetime) -> float:
"""
计算时间衰减因子
使用指数衰减函数: decay = e^(-λ * t)
其中 λ 是衰减因子,t 是时间差(天数)
"""
# 计算时间差(天数)
days_diff = (self.current_date - publish_date).days
# 应用指数衰减
decay = math.exp(-self.decay_factor * days_diff)
return decay
def rerank_with_time_decay(self, documents: List[Document]) -> List[Tuple[Document, float]]:
"""
使用时间衰减因子重新排序文档
:param documents: 原始文档列表
:return: (文档, 综合分数) 的元组列表,按综合分数降序排列
"""
reranked_docs = []
for doc in documents:
# 计算时间衰减因子
time_decay = self.calculate_time_decay(doc.publish_date)
# 计算综合分数 = 语义相似度 * 时间衰减因子
final_score = doc.relevance_score * time_decay
reranked_docs.append((doc, final_score))
# 按综合分数降序排列
reranked_docs.sort(key=lambda x: x[1], reverse=True)
return reranked_docs2.2 拓展信息覆盖
多个查询就像撒下了多张网,从知识库的不同角度进行捕捞。一张网漏掉的关键信息,很可能被另一张网捕获。这极大地提升了召回率(Recall),确保了更多相关信息能进入后续处理。
三、RAG-Fusion工作流程
详细工作流程如下:

3.1 查询生成(Query Generation)
这一过程构成了检索增强的起点,也是生成多样化信息视角的重要机制。通过利用大语言模型的语言生成能力,原始的单一查询能够被扩展为具有多维语义视角的查询集合,从而提升检索的覆盖度和鲁棒性。
- 方法:我们可以通过精心设计的Prompt,引导LLM生成多个查询。
- Prompt示例:
你是一个专业的信息检索专家。你的任务是根据用户提供的原始查询,生成4个与之相关但视角不同的新查询。这些查询应该有助于从多个角度全面地检索相关信息。请确保生成的查询与原始查询的核心意图保持一致。
请遵循以下格式,每个查询占一行,不要添加任何编号或前缀。
[原始查询]
{original_query}
[生成的查询]考量:生成查询的数量是一个需要权衡的参数。数量太少(如1~2个),起不到“融合”的效果;数量太多(如超过5个),会显著增加后续检索的延迟和LLM的调用成本。通常3~4个是一个比较均衡的选择。
3.2 并行检索(Parallel Retrieval)
在获取包含原始查询及其扩展查询的多查询集合后,这些查询会被分发给检索器独立执行。核心思想是,这一检索阶段属于典型的“尴尬并行”任务:每个查询的处理完全相互独立,不存在依赖关系,因此非常适合并行化处理。
实现方式:
异步并行:利用异步框架(如python的asyncio)可以同时发起多个检索请求,而不必等待前一个请求完成再发送下一个。每个请求独立等待返回结果,事件循环负责调度,大幅减少总等待事件。

多进程/多线程:使用ThreadPoolExecutor 或 ProcessPoolExecutor,将每个查询作为一个独立任务提交给线程池或进程池执行。对于I/O密集型任务(比如网格检索、数据库查询等),多线程即可;对于CPU密集型任务(比如复杂文本向量化),多进程更高效。
批量处理优化:对部分向量数据库或检索服务,可以将多个查询批量发送,利用底层批处理接口减少请求开销。也可以选择与异步/多线程结合,可以进一步的提升吞吐量。
3.3 结果重排与融合
RAG-Fusion的核心机制在于通过倒数排序融合(Reciprocal Rank Fusion, RRF)算法,将来自多个独立查询的候选文档列表整合为单一的高质量排序列表,这样可以在保证多查询覆盖的前提下,优化最终检索结果的相关性与稳定性。
RRF的逻辑非常简单却极其有效:一个文档的重要性,不仅取决于它在某次查询中的排名,更取决于它是否能在多个不同的查询结果中都稳定出现。
它的计算公式如下:
- d:某个特定的文档
- rank_i(d):文档d在第i个查询结果列表中的排名
- k:一个常数,通常设置为60
深入理解参数k:
k的作用是什么?它是一个平滑因子,用于降低高排名文档的绝对主导地位。
如果没有k,那么排名第1的文档得分为1.0,排名第二的为0.5,排名 第10的的为0.1。排名第一的文档分数权重过高。在后续大模型处理时,会过度依赖首条文档的内容,即使后面有更多相关信息也可能被忽略。结果可能是生成的回答过于片面,或者忽视了其它查询捕捉到的关键信息。
设置了k这个参数之后,排名第1的文档分数为1/61 0.0164,排名第2的文档分数大约为0.0161。它们之间的差距变得很小。这使得那些在多个列表中稳定出现的文档,有机会通过累加分数超过仅在一次查询中排名第一的文档。k=60是原论文中推荐的经验值,在多数场景下表现良好。
我们再来看一个更具体的计算例子:
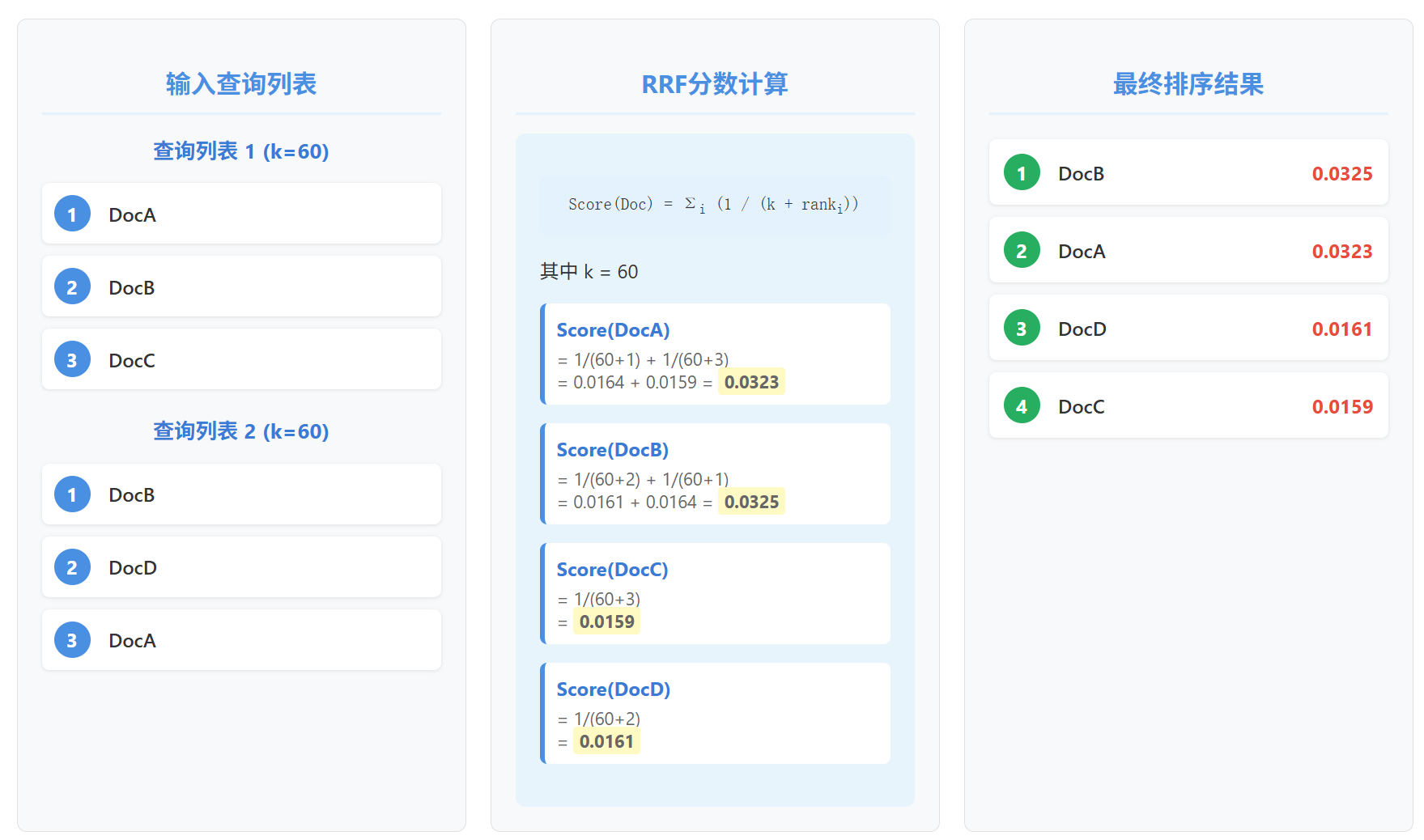
可以看到,尽管DocA在一次查询中排名第一,但DocB在两次查询中都稳定出现在前列,最终获得了最高分。这就是RRF的机制:奖励共识,而非个例。
如果我们从集合论的角度来理解RRF。我们可以将每次的检索结果看作是一个集合,其中的元素是文档(注意:这里的集合是有序集合,也即每个元素都有一个“排名位置”)。现在,我们的目标是要在所有集合
的基础上,找到一个新的集合
,它是一个全局有序集合,并且能最大化反映所有检索器的一致性。
换句话说,RRF本质是一个集合融合(Set Fusion)问题,每个检索器就像多个视角。我们希望融合它们的集合信息,找到一个能代表全局最优的排序。
如果大家有排名聚合理论的基础。那其实我们可以将RRF算法看作是Borda Count算法的变种。Board Count是一种经典的排名融合方法,它为候选项在不同排序中的位置分配固定分数(如第一名得n-1分,第二名得n-2分,...),最后通过累计分数得到全局排序;而RRF它不再使用固定线性分差,而是采用倒数函数动态分配分数,使得前几名的贡献更大,后续名次差距逐渐缩小,更适合信息检索中强调前排结果的重要性。如下图所示:

四、代码实战
langchain版本:0.3.27
import os
import warnings
from dotenv import load_dotenv
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_core.documents import Document
from langchain_text_splitters import RecursiveCharacterTextSplitter
from openai import OpenAI
warnings.filterwarnings("ignore", category=DeprecationWarning)
load_dotenv("../../.env")
# Initialize OpenAI API
api_key = os.getenv("OPENAI_API_KEY")
if api_key is None:
raise Exception("No OpenAI key found. Please set it as an environment variable or in .env")
# Function to generate queries using OpenAI's QWEN
def generate_queries_qwen(original_query):
"""
基于LLM生成多个query
Args
original_query: 用于提出的query
Returns:
LLM生成的多个queries
"""
# 创建OpenAI客户端
client = OpenAI(
base_url="https://api.deepseek.com",
api_key=api_key
)
# 创建ChatCompletion
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{
"role": "system",
"content": "You are a helpful assistant that generates multiple search queries based on a single input query."
},
{
"role": "user",
"content": f"Generate multiple search queries related to: {original_query}"
},
{
"role": "user",
"content": "OUTPUT (4 queries):"
}
]
)
generated_queries = response.choices[0].message.content.strip().split("\n")
return generated_queries
# 切分文档
def split_documents(all_documents):
"""
文档分割
Args
all_documents: 文档列表
Returns:
按照chunk_size和chunk_overlap切割后的文档块
"""
# Convert the dictionary to a list of Document objects
docs = [Document(page_content=content, metadata={"doc_id": doc_id}) for doc_id, content in all_documents.items()]
# create the text splitter with specified parameters
text_splitter = RecursiveCharacterTextSplitter(chunk_size=50, chunk_overlap=10)
# Split the documents
splits = text_splitter.split_documents(docs)
return splits
# 相似性搜索
def vector_search_embedding(queries, all_documents):
"""
基于向量数据库执行向量搜索
Args:
queries: 多个查询列表
all_documents: 所有文档列表
Returns:
Dict: 以query作为key,id,page_content,score(距离分数)作为value的查询结果
"""
# 使用Splitter切分文档
docs = split_documents(all_documents)
# 创建嵌入模型
embeddings = HuggingFaceEmbeddings(
model_name="sentence-transformers/all-MiniLM-L6-v2",
model_kwargs={'device': 'cpu'},
encode_kwargs={'normalize_embeddings': True}
)
# 创建向量数据库
vectorstore = FAISS.from_documents(documents=docs, embedding=embeddings)
# 对每个查询执行搜索
results_dict = {}
for query in queries:
# 将query和docs转成向量存储到向量数据库中,再使用similarity_search,这里使用的是距离分数
results = vectorstore.similarity_search_with_score(query, k=1)
# 格式化返回结果
formatted = []
for doc, score in results:
formatted.append({
"id": doc.metadata.get("doc_id", None),
"page_content": doc.page_content,
"score": float(score)
})
results_dict[query] = formatted
# 返回最终的结果
return results_dict
# RRF算法
def reciprocal_rank_fusion(search_results, k=60):
"""
Reciprocal Rank Fusion算法
Args:
search_results: 字典格式,键为查询,值为包含{'id': doc_id, 'page_content': content, 'score': score}的列表
k: RRF参数,默认60
Returns:
list: 重新排序后的文档列表,格式与输入相同
"""
fused_scores = {}
print("Initial individual search results rank:")
for query, doc_list in search_results.items():
print(f"For query: [{query}]: {[(doc['id'], doc['score'], doc['page_content']) for doc in doc_list]}")
for query, doc_list in search_results.items():
# 按照原始score排序,(注意:这里是相似度分数越低越相似,所以升序排列)
sorted_docs = sorted(doc_list, key=lambda x: x['score'])
for rank, doc in enumerate(sorted_docs):
doc_id = doc['id']
if doc_id not in fused_scores:
fused_scores[doc_id] = {
'fused_score': 0,
'page_content': doc['page_content'],
}
previous_score = fused_scores[doc_id]['fused_score']
fused_scores[doc_id]['fused_score'] += 1 / (rank + k)
print(
f"Updating score for {doc_id} from {previous_score} to {fused_scores[doc_id]['fused_score']} based on rank {rank} in query [{query}]")
# 按融合分数重新排序并转换为目标格式
ranked_results = []
# RRF分数越大越好
for doc_id, doc_info in sorted(fused_scores.items(), key=lambda x: x[1]['fused_score'], reverse=True):
reranked_results.append({
'id': doc_id,
'page_content': doc_info['page_content'],
'score': doc_info['fused_score']
})
print("Final reranked results:", [(doc['id'], doc['score']) for doc in ranked_results])
return reranked_results
def generate_output(reranked_results, queries):
"""
基于重新排序的结果生成输出
Args:
reranked_results: 重新排序后的文档列表,格式为[{'id': doc_id, 'page_content': content, 'score': score}]
queries: 查询列表
Returns:
str: 生成的输出文本
"""
doc_ids = [doc['id'] for doc in reranked_results]
doc_contents = [doc['page_content'][:100] + '...' if len(doc['page_content']) > 100
else doc['page_content'] for doc in reranked_results]
output = f"Final output based on queries {queries}\n"
output += f"Reranked documents: {doc_ids}\n"
return output
# Predefined set of documents (usually these would be from your search database)
all_documents = {
"doc1": "Climate change and economic impact.",
"doc2": "Public health concerns due to climate change.",
"doc3": "Climate change: A social perspective.",
"doc4": "Technological solutions to climate change.",
"doc5": "Policy changes needed to combat climate change.",
"doc6": "Climate change and its impact on biodiversity.",
"doc7": "Climate change: The science and models.",
"doc8": "Global warming: A subset of climate change.",
"doc9": "How climate change affects daily weather.",
"doc10": "The history of climate change activism."
}
if __name__ == '__main__':
original_query = "impact of climate change"
generate_queries = generate_queries_qwen(original_query)
search_results = vector_search_embedding(generate_queries, all_documents)
reranked_results = reciprocal_rank_fusion(search_results)
final_output = generate_output(reranked_results, generate_queries)
print(final_output)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 33
33 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)