【2025GAVE竞赛文献参考--眼球血管动静脉分割合集】
今年(2022)一月份,Facebook AI Research和UC Berkeley一起发表了一篇文章A ConvNet for the 2020s,在文章中提出了ConvNeXt纯卷积神经网络,它对标的是2021年非常火的Swin Transformer,通过一系列实验比对,在相同的FLOPs下,ConvNeXt相比Swin Transformer拥有更快的推理速度以及更高的准确率,在Ima
1、公开动静脉分类数据集
2、相关文献合集
2.1 MICCAI-2024 RIP-AV: Joint Representative Instance Pre-training with Context Aware Network for Retinal Artery/Vein Segmentation
1)主旨
现有的基于调整大小和图像块的算法由于背景与A/V比例失衡以及上下文信息有限,在处理冗余问题、忽略细小血管以及在视网膜图像的低对比度边缘区域表现不佳。在此,我们开发了一种名为RIP-AV的新型深度学习框架,用于视网膜A/V分割,首次将代表性实例预训练(RIP)任务与上下文感知网络相结合。
基于调整大小的方法主要将整幅图像缩放到较小尺寸,然后输入到网络中,但由于图像压缩,可能会忽略细小血管的细节。因此,引入了基于图像块的方法,通过将整幅图像划分为多个小图像块并随机选择一些进行深入分析,保留所有细节,实现了显著的A/V分割性能。然而,冗余和上下文是这种方法的主要限制,可能导致过拟合以及边缘区域的动脉静脉混淆。
最初,我们开发了一种直接而有效的血管图像块配对选择(PPS)算法,随后引入了一个RIP任务,该任务被表述为一个多标签问题,旨在增强网络从血管图像块的不同空间位置学习潜在动静脉特征的能力。随后,在训练阶段,我们引入了两个新颖的模块:图像块上下文融合(PCF)模块和距离感知(DA)模块。它们旨在通过合作和互补地利用血管图像块与其周围上下文之间的关系,提高细小血管的可区分性和连续性,特别是在低对比度边缘区域。RIP-AV的有效性已在三个公开的视网膜数据集上得到验证:AV-DRIVE、LES-AV和HRF,分别实现了0.970、0.967和0.981的显著准确率,从而超越了现有的先进方法。值得注意的是,我们的方法在HRF数据集上实现了1.7%的准确率显著提升,特别是在细小边缘动脉和静脉的分割方面表现出色。
分割的难点:背景与A/V比例失衡、上下文信息有限
出现的问题:忽略细小血管、在视网膜图像的低对比度边缘区域表现不佳
本文亮点:将实力与训练任务(被表述为一个多标签问题,旨在增强网络从血管图像块的不同空间位置学习潜在动静脉特征的能力)和上下文感知网络结合(利用血管图像块与其周围上下文之间的关系,提高小血管的可区分性和连续性)
2)整体框架
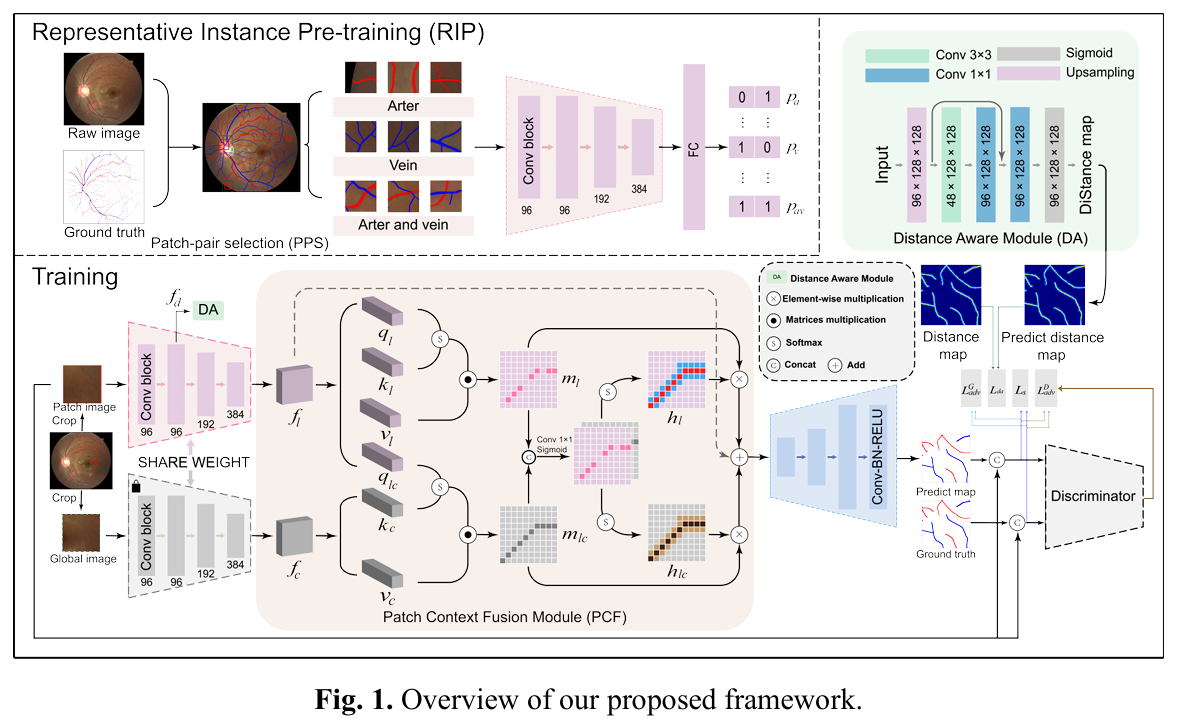
该框架从一种新颖的图像块配对选择(PPS)算法开始,从视网膜图像中挑选血管图像块及其上下文对应部分,从而在减少冗余的同时捕捉代表性实例。我们框架中的RIP部分被表述为一个多标签分类问题,旨在增强网络在所选血管图像块内不同空间区域识别潜在动静脉特征的能力。
为了进一步优化分割过程,我们引入了两个创新模块:图像块上下文融合(PCF)模块和距离感知(DA)模块。它们被集成到网络中,增强了图像块之间的上下文交互,并丰富了对血管边缘的感知。
在训练流程中,每个血管图像块被调整到256的大小,并输入到双流编码器中。编码器由ConvNeXt的前三个卷积块组成,用于提取浅层和高层特征图。这些特征图随后依次通过DA模块和PCF模块进行处理。解码器采用标准的卷积-批量归一化-ReLU(Conv-BN-ReLU)结构,输出一个三通道的预测图,用于动脉、静脉和整体血管分割。该预测图 、真实标签 和图像块被输入到判别器 中,判别器的作用是评估预测图和真实图之间的差异,确保分割的质量。判别器基于标准的PatchGAN架构,能够对局部图像块进行稳健的评估。
ConvNext网络(引用自CSDN博主-太阳花的小绿豆):
自从ViT(Vision Transformer)在CV领域大放异彩,越来越多的研究人员开始拥入Transformer的怀抱。回顾近一年,在CV领域发的文章绝大多数都是基于Transformer的,比如2021年ICCV 的best paper Swin Transformer,而卷积神经网络已经开始慢慢淡出舞台中央。卷积神经网络要被Transformer取代了吗?也许会在不久的将来。今年(2022)一月份,Facebook AI Research和UC Berkeley一起发表了一篇文章A ConvNet for the 2020s,在文章中提出了ConvNeXt纯卷积神经网络,它对标的是2021年非常火的Swin Transformer,通过一系列实验比对,在相同的FLOPs下,ConvNeXt相比Swin Transformer拥有更快的推理速度以及更高的准确率,在ImageNet 22K上ConvNeXt-XL达到了87.8%的准确率。
PatchGan
CycleGAN网络中的判别器使用的是一种叫“PatchGAN”的设计,原始GAN的discriminator的设计是仅输出一个评价值(True or False),该值是对生成器生成的整幅图像的一个评价。而PatchGAN的设计不同,PatchGAN设计成全卷积的形式,图像经过各种卷积层后,并不会输入到全连接层或者激活函数中,而是使用卷积将输入映射为NN矩阵,该矩阵等同于原始GAN中的最后的评价值用以评价生成器的生成图像。NN矩阵中每个点(true or false)即代表原始图像中的一块小区域(这也就是patch含义)评价值,这也就是“感受野(下图)”的应用。原来用一个值衡量整幅图,现在使用NN的矩阵来评价整幅图(使用patchgan标签也需要设置成为NN的格式,这样就可以进行损失计算了),显然后者可以关注更多的区域,这也就是patchgan的优势。
3)RIP模块
RIP的主要目标是在血管图像块中识别嵌入的动静脉特征,这对于后续的分割任务至关重要。PPS算法作为RIP的关键预处理步骤,旨在选择具有代表性的血管结构图像块。我们观察到所有随机裁剪的图像块可以分为四类:仅动脉(𝑃𝑃𝑎𝑎)、仅静脉(𝑃𝑃𝑣𝑣)、包含动脉和静脉(𝑃𝑃𝑎𝑎𝑣𝑣)以及无血管结构(𝑃𝑃𝑏𝑏)。PPS被设计为排除𝑃𝑃𝑏𝑏,从而增强训练集的特异性,如算法1所述。它通过利用血管中心线——血管核心结构的表示——来确保包含血管特征,从而保证所选图像块富含相关的血管信息。
随后,RIP阶段利用这些分类的图像块来更新神经网络,促进学习一个能够捕捉不同空间区域中动静脉差异本质的特征空间。在这个阶段,RIP被表述为一个多标签分类任务,其中二进制向量表示动脉(𝑃𝑃𝑎𝑎:[1,0])和静脉(𝑃𝑃𝑣𝑣:[0,1])特征的存在,以及它们的共现𝑃𝑃𝑎𝑎𝑣𝑣([1,1])。二进制编码为网络区分动脉和静脉特征提供了指导,为后续的A/V分割任务奠定了基础。好厉害馁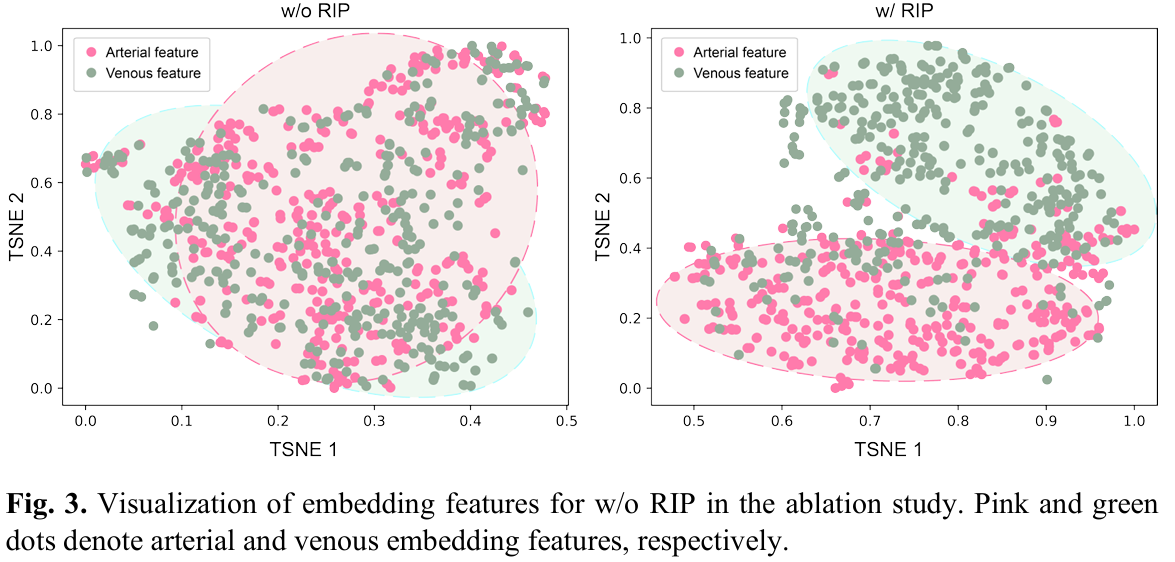
4)DA模块
首先,通过上采样层对特征图进行处理以提高分辨率。随后,依次使用 3×3 和 1×1 的卷积层来编码并细化对血管结构至关重要的空间关系。最终,经过细化的特征图通过Sigmoid激活函数转换为概率距离图 d 。为了优化DA模块的参数,我们采用了类似文献[13]中的距离感知损失函数 Lda,旨在最小化预测距离图与真实标签之间的差距。
文献13:TW-GAN: Topology and width aware GAN for retinal artery/vein classification,具体见本文章下个模块
5)PCF模块
到先前研究[22, 23, 34]的启发,这些研究表明整合上下文信息对于更全面地理解图像内的空间关系具有重要意义,我们提出了一个新颖的PCF(Patch Context Fusion,图像块上下文融合)模块。该模块旨在通过联合应用自注意力(self-attention)和交叉注意力(cross-attention)机制,利用局部图像块与周围上下文之间的关系。这一部分很简单,看图就能理解了。
总结:该论文的核心亮点就是使用了RIP模块,其余的DA模块(使用GAN网络对预测结果进行判别训练)参考的baseline论文<即TW-GAN模型,具体见下一节3、2022MIA>。
3、2022 MIA - TW-GAN: Topology and width aware GAN for retinal artery/vein classification
1)主旨
拓扑连接关系及血管宽度信息在传统方法中已被证实可显著提升 A/V 分类性能,但尚未被深度学习模型加以利用。本文首次提出一种拓扑与宽度感知的生成对抗网络(TW-GAN),将拓扑连通性与血管宽度信息引入深度学习框架,用于 A/V 分类。为增强拓扑连通性,本文设计了拓扑感知模块,其中包含基于序数分类的拓扑排序判别器,用于对真实掩膜、生成 A/V 掩膜及人为打乱掩膜的拓扑连通水平进行排序。此外,提出拓扑保持三元组损失,以提取高层拓扑特征,缩小预测 A/V 掩膜与真实掩膜之间的特征距离。为进一步强化模型对血管宽度的感知,引入宽度感知模块,为扩张/未扩张的真实掩膜预测宽度图。
一、拓扑连接关系
直观含义
对视网膜血管来说,拓扑连接关系就是“血管段之间怎样分叉、怎样交叉、怎样最终汇成一棵完整的树”。
如果一段血管被错误地断开或接错,就不符合生理上的连通性。
具体做法
• 把血管看成一张无向图 G=(V, E):
– 节点 V 是血管段起点 / 终点或分叉点;
– 边 E 是血管段本身。
• 判断连接是否合理的规则:
– 所有动脉边必须构成一棵连通的子树,所有静脉边也必须构成一棵连通的子树,并且两棵树都与视盘(根节点)相连。
二、血管宽度信息
直观含义
动脉和静脉在相同解剖位置通常有明显直径差异:动脉更细、静脉更粗。因此“血管宽度”本身就是区分 A/V 的一条强线索。
具体做法
• 传统方法:在分割后的血管中心线上,垂直方向采样像素亮度,通过极小值间距直接量出直径。
思路:
-
尽管基于深度学习的方法在A/V分类精度上表现良好,但仍面临血管碎片化、缺乏连通性的问题。部分基于图的方法利用血管拓扑连接关系解决此问题,但将拓扑连通性整合到深度学习框架中的研究尚少。
- 设计拓扑感知模块,通过拓扑排序判别器和拓扑保持正则化模块增强动脉和静脉图的拓扑连通性。
-
此外,由于动脉通常比邻近静脉细,血管宽度已被用作手工特征提升A/V分类性能,但深度学习尚未考虑血管宽度。因此,如何在深度学习框架中利用拓扑连通性和血管宽度提升A/V分类仍是研究空白。
- 提出宽度感知模块,通过预测扩张/非扩张A/V掩膜的宽度图提取血管宽度相关特征,并用宽度感知损失正则化。
2)整体框架
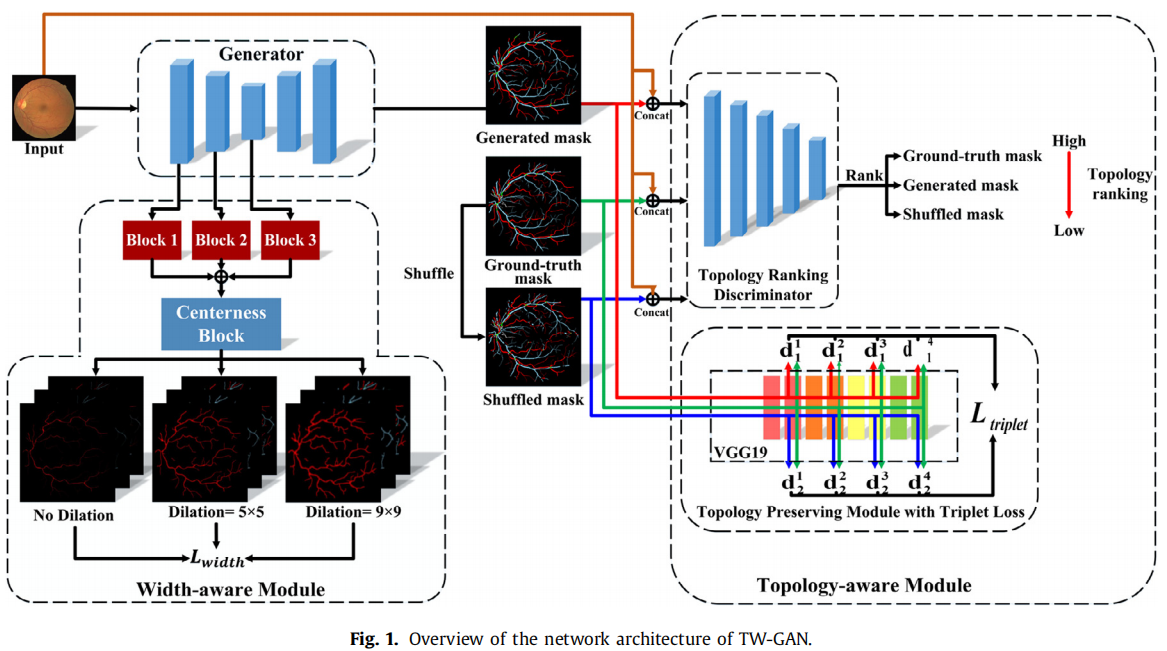
图 1 展示了本文提出的 TW-GAN 框架:拓扑与宽度感知的视网膜动静脉分类生成对抗网络。整体架构由三部分组成:(1)分割网络,即生成器 G;(2)拓扑感知模块;(3)宽度感知模块。
- “编码器-解码器”:生成器采用广泛使用的 U-Net(Ronneberger 等,2015)结构,编码器使用预训练的 ResNet-18(He 等,2016),解码器输出三通道概率图,分别对应动脉、静脉及血管分割。
- “拓补感知模块”
important:输入一张眼底图像 x 后,先生成掩膜 G(x)。随后,拓扑感知模块用于增强血管连通性,包含拓扑排序判别器 D 和基于三元组损失的拓扑保持子模块。如图 1 所示,生成掩膜、真实掩膜以及随机打乱掩膜分别与原始输入图像拼接后送入 TR-D,以评估三者的拓扑连通性。由此计算拓扑排序对抗损失并反向传播更新生成器。同时,三幅掩膜也输入拓扑保持子模块,该模块使用预训练的 VGG-19 主干网络(Simonyan 和 Zisserman,2015)提取高层拓扑特征,并构建三元组损失,缩小真实掩膜与生成掩膜间的特征距离。为进一步强化模型对血管宽度特征的感知,将生成器提取的特征输入宽度感知模块,该模块通过堆叠卷积层分别预测动脉、静脉及血管的宽度图。 - “宽度感知模块”:为丰富不同尺度的宽度估计,模块还额外预测扩张后的动脉、静脉及血管宽度图。计算宽度感知损失并反向传播,以更新模块参数与特征提取器。
3)拓补感知模块

图 2 展示了动静脉分类中不同层级的拓扑连通性。红色表示动脉,蓝色表示静脉,绿色表示交叉点。 (a) 原始彩色眼底图像; (b) 拓扑连通性最高的真实掩膜; © 拓扑连通性中等的模型预测结果; (d) 拓扑连通性最低的人为打乱真实掩膜。
如图 2(b) 所示,视网膜血管形态呈树状拓扑结构:主干血管自视盘发出,逐级分岔为更细、更短的分支,这种结构天然保持拓扑连通性。现有深度学习方法虽在 A/V 分类上表现良好,但生成的动脉或静脉常碎片化,缺乏拓扑连通性。为此,我们引入拓扑感知模块,通过拓扑排序判别器(TR-D)和带三元组损失(TL)的拓扑保持模块共同维护 A/V 分类的拓扑连通性。其整体结构见图 1。
3.2.1 拓扑排序判别器
经典 GAN 的判别器仅在图像层面进行“真/伪”二分类,无法区分掩膜的拓扑连通度。为此,我们提出拓扑排序判别器,用于对真实掩膜与生成掩膜的拓扑连通度进行排序,从而引导生成掩膜的连通性提升。判别器采用 PatchGAN 结构(Isola et al., 2017),共 6 个卷积层;输入
由眼底图与 A/V 掩膜拼接而成,以保证生成掩膜与对应图像内容相关。
仅比较两种连通度过于简单,易使判别器受骗,导致生成器性能次优。因此,我们人为构造第三种低连通度掩膜,增加判别难度:在真实掩膜上随机移除部分血管段、平移血管片段或互换局部 A/V 标签,重复直至 5–25% 的血管像素被打乱,从而确保打乱掩膜的连通度低于生成掩膜。由此得到由高到低的三级连通度:真实掩膜、生成掩膜、打乱掩膜(图 2)。
为充分利用这三类有序的连通度,我们采用序数分类:将序数标签转为多标签形式——打乱掩膜 y₁:[0,0]、生成掩膜 y₂:[1,0]、真实掩膜 y₃:[1,1]。第一维表示是否优于打乱掩膜,第二维表示是否优于生成掩膜。判别器损失为‘
训练初期,生成掩膜连通度可能低于打乱掩膜,易误导判别器。为此,先独立训练生成器 5000 次作为热身,使其连通度超越打乱掩膜;之后判别器与生成器交替更新。
3.2.2 带三元组损失的拓扑保持模块
传统分割模型多用二元交叉熵(BCE)衡量逐像素差异,但无法刻画高阶拓扑差异。因此,我们提出拓扑保持模块:利用预训练模型提取特征,通过特征距离反映拓扑差异。选用 ImageNet 预训练的 VGG-19,因其特征图能有效保持拓扑信息(Johnson et al., 2016;Mosinska et al., 2018),见图 3。基于提取的特征,我们设计三元组损失,拉近真实掩膜与生成掩膜的特征距离,推远真实掩膜与打乱掩膜的特征距离.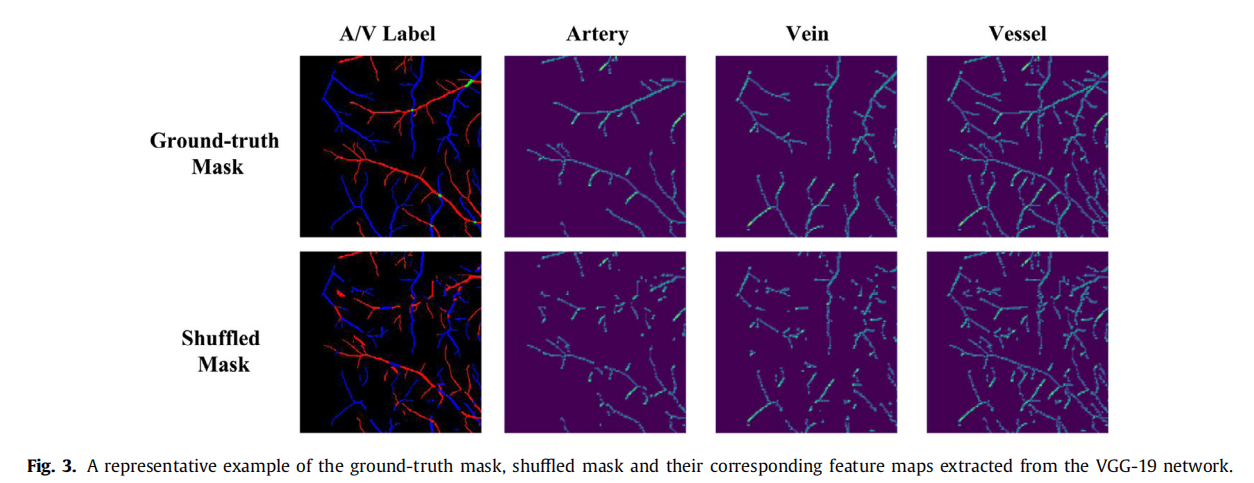
4)宽度感知模块
除拓扑连通性外,血管宽度也是动静脉分类中被广泛采用的手工特征之一,因为相邻动脉通常比静脉细(Kondermann et al., 2007;Joshi et al., 2014)。然而,深度学习模型尚未利用这一信息。为提升 A/V 分类性能,本文引入宽度感知模块,分别预测动脉、静脉及整体血管的宽度图,以增强模型对宽度相关特征的感知。为丰富不同血管宽度的监督信号,我们使用 5×5 和 9×9 核对真实掩膜做膨胀,得到额外的宽度估计目标。随后,通过欧氏距离变换(Maurer et al., 2003;SciPy 库中的标准函数,Virtanen et al., 2020)计算真实掩膜及其膨胀版本的宽度图,并将其作为监督宽度感知模块的真值。图 4 展示了带/不带膨胀的真实掩膜对应的宽度图示例。
如图 1 所示,宽度感知模块 W 包含三个独立子块 Block 1、Block 2 和 Block 3,分别处理生成器在三个不同层级提取的特征 (f₁, f₂, f₃)。这些特征经拼接融合后送入 centerness 融合块,用于预测真实掩膜及两种膨胀掩膜的宽度图。centerness 融合块及 Blocks 1–3 的详细结构见 图 5。
4、2024 - RRWNet: Recursive Refinement Network for effective retinal artery/vein segmentation and classification
见主页笔记

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 15
15 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)