AI不再“睁眼瞎“!CVPR学霸三招破解高清世界:算得动更看得清!
【CVPR多模态研究突破:高效视觉理解新范式】三篇最新研究揭示了AI理解高分辨率图像的关键突破:1)ECP框架通过两阶段处理(先粗定位后细预测),在4K/8K任务上提升5-21%性能;2)音频-视觉定位创新性地利用MLLMs区分发声/静默对象,结合OCA/ORI损失实现多源分离;3)轻量级HIRE方法通过特征增强减少35%计算量,保持视觉问答性能。共同核心在于模仿人类分层处理信息,用算法设计替代暴
关注gongzhonghao【图灵学术SCI科研圈】,解锁更多SCI相关资讯!
准备好揭开CVPR最新研究如何让AI真正"看懂"世界了吗?当高清图像淹没细节,当相似物体迷惑判断,当计算资源成为瓶颈——三篇突破性论文给出了惊人相似的答案!它们不约而同地刺破多模态模型的感知盲区:高分辨率视觉理解绝非暴力堆叠算力,而是重构模型的"思考方式"。
您将发现,从屏幕按钮定位到乐器声音分离,从医疗影像解析到工业质检,研究者们正用精妙的算法设计替代蛮力计算——或是两阶段推理框架模仿人类"先瞄后瞄"的视觉机制,或是特征增强网络模拟大脑"去芜存菁"的信息过滤,或是跨模态对比学习实现"听音辨位"的生物本能。
这些方案藏着共同智慧:让AI像人类一样分层处理信息,在混沌中捕捉关键信号!
A Training-Free, Task-Agnostic Framework for Enhancing MLLM Performance on High-Resolution Images
方法:
文章首先在第一阶段(Extract Candidate,EC)利用预训练的MLLM处理下采样的高分辨率图像和文本指令,生成与指令相关的候选区域,该区域以边界框的形式表示,通过计算代表性坐标并确定边界框的中心和宽高来实现;接着在第二阶段(Predict,P)中,将高分辨率图像中基于候选区域裁剪出的图像块输入MLLM进行最终预测,若任务需要全局上下文信息,还会补充下采样的高分辨率图像和用户指令,以此让模型能够捕捉到细粒度的图像细节,从而提高对高分辨率图像的理解和预测能力。
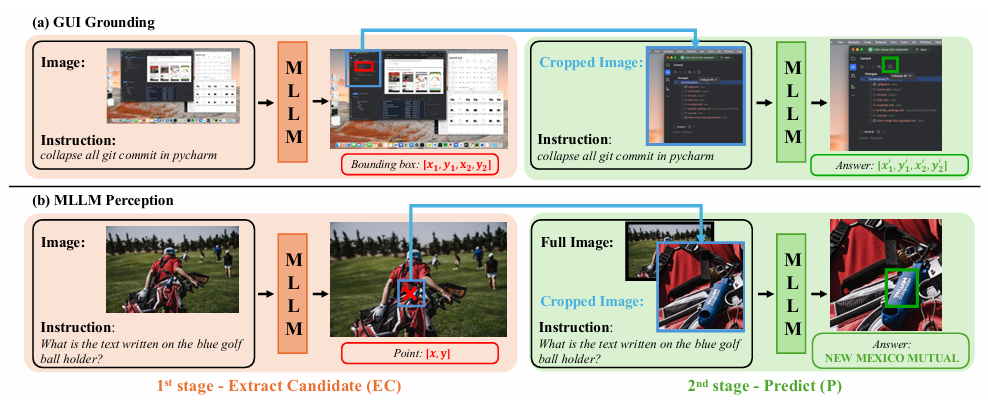
创新点:
-
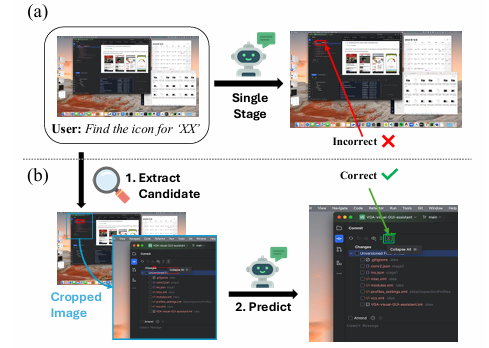
提出了一种训练无关、任务无关的两阶段框架ECP,无需额外训练即可显著提升MLLMs在高分辨率图像任务中的性能,突破了传统方法依赖于特定任务设计和额外训练数据的局限。
-
利用MLLMs在下采样图像上的粗略定位能力,通过先提取候选区域再进行预测的方式,巧妙地保留了高分辨率图像中的细粒度细节,有效缓解了高分辨率数据带来的挑战,实现了从粗到细的高效图像理解过程。
-
在4K GUI定位和4K、8K MLLM感知等任务上进行了广泛的验证,相较于基线模型分别实现了21.3%、5.8%、5.2%的绝对性能提升,充分证明了ECP框架的高效性和广泛适用性。
论文链接:
https://arxiv.org/pdf/2507.10202
关注gongzhonghao【图灵学术SCI科研圈】,获取多模态最新选题和idea
Object-aware Sound Source Localization via Audio-Visual Scene Understanding
方法:
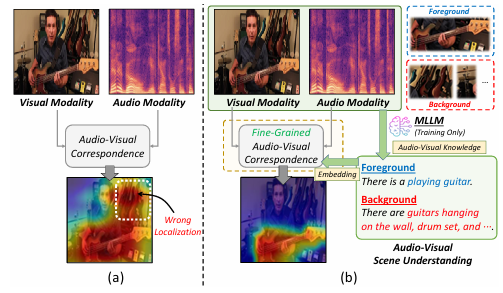
文章首先利用多模态大型语言模型(MLLMs)对输入图像和音频类别信息进行处理,生成关于发声对象的前景描述和静默对象的背景描述,以此增强音频-视觉场景理解。接着,通过引入目标感知对比对齐(OCA)损失和目标区域隔离(ORI)损失函数,引导模型在训练过程中学习细粒度的音频-视觉对应关系,有效区分发声和静默对象,并在多源场景中实现发声对象的清晰分离。最后,通过优化总损失函数,模型能够在复杂场景中更准确地定位和识别声音源,从而显著提升音频-视觉声音源定位的性能。
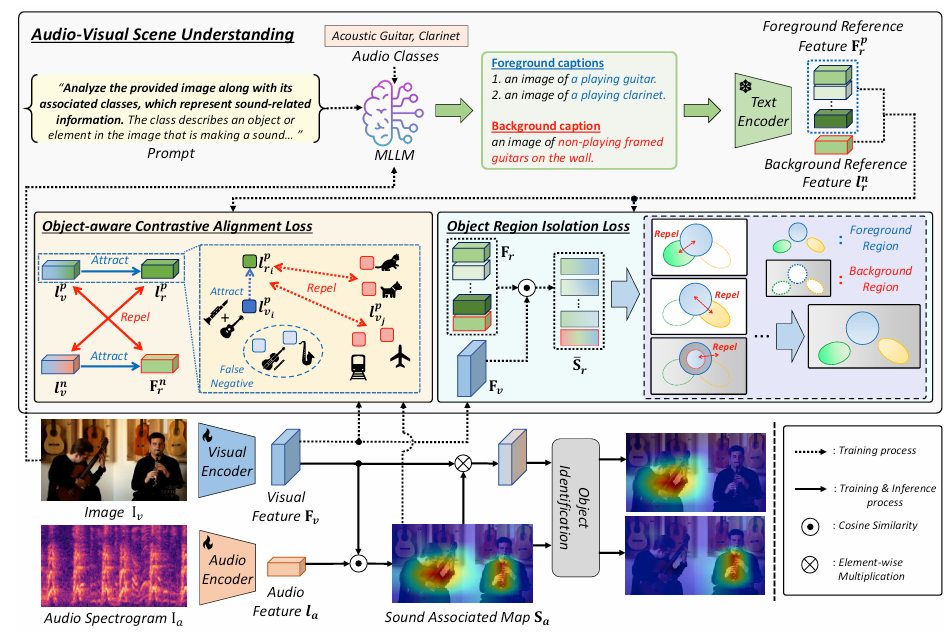
创新点:
-
这篇文章首次尝试通过多模态大型语言模型(MLLMs)为音频-视觉声音源定位任务提供关于发声对象和静默对象的细粒度指导,利用其丰富的外部知识生成详细的上下文信息,以区分发声的前景对象和静默的背景对象,从而实现更精准的声音源定位。
-
提出了两个新颖的损失函数:目标感知对比对齐(OCA)损失和目标区域隔离(ORI)损失,这些损失函数通过利用音频-视觉场景理解中的详细对象信息来增强模型区分发声和静默对象的能力,即使在视觉外观相似的情况下也能准确区分,显著提高了多源场景下的声音源分离效果。
-
在MUSIC和VGGSound数据集上进行了广泛的实验,结果表明该方法在单源和多源定位场景中均显著优于现有方法,证明了其在复杂场景下音频-视觉声音源定位任务中的有效性。
论文链接:
https://arxiv.org/pdf/2506.18557
关注gongzhonghao【图灵学术SCI科研圈】,获取多模态最新选题和idea
HIRE: Lightweight High-Resolution Image Feature Enrichment for Multimodal LLMs
方法:
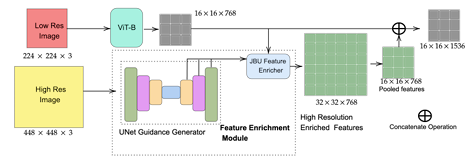
文章首先构建了一个直觉,将特征上采样视为高分辨率特征生成的自然延伸,并通过广泛的实验和消融研究,证明了浅层特征增强器能够在大幅减少训练和推理时间以及计算成本的情况下,实现与现有方法相竞争的结果,最高可节省1.5倍的计算成本。接着,文章提出了HIRE方法,它通过一个非常浅的UNet和JBU特征增强器模块来生成高分辨率的增强特征,这些特征随后被下采样并与低分辨率的CLIP特征拼接,以供后续的多模态投影器使用。最后,文章通过在LLaVA-1.5的训练流程中整合HIRE,并在多种视觉细节理解和问答任务上进行评估,验证了HIRE在减少计算开销的同时,能够保持甚至提升模型性能的有效性。
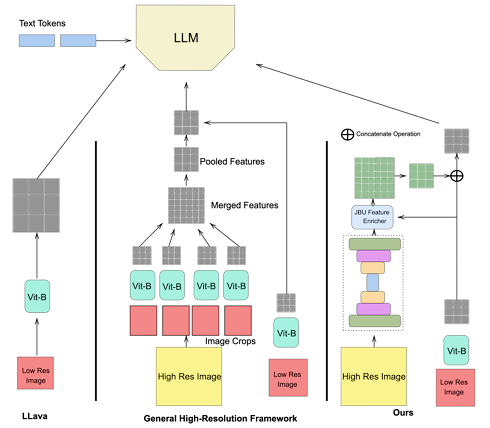
创新点:
-
提出了HIRE这一新颖的轻量级特征增强流程,能够将高分辨率信息融入到Vision Transformer(ViT)特征中,从而避免了多次调用ViT进行前向传播的需要,极大地提高了高分辨率MLLMs的效率。
-
在高分辨率MLLMs流程中,HIRE实现了35%的浮点运算(FLOPs)减少,同时在多个视觉问答(VQA)基准测试中保持了与现有方法相媲美的性能,证明了其在提升计算效率方面的显著优势。
-
展示了HIRE在扩展到更大ViT模型时比其他高分辨率方法更高效的能力,为构建更大规模、更强大的MLLMs提供了有效的技术支持。
论文链接:
https://arxiv.org/pdf/2506.17608
► 论文发表难题,一站式解决!
TURING
选题是论文的第一步,非常重要!
但很多学生找到了热门的选题,却卡在代码和写作上!可见论文要录用,选题-idea-代码-写作都缺一不可!
图灵学术论文辅导,汇聚经验丰富的实战派导师团队,针对计算机各类领域提供1v1专业指导,直至论文录用!
关注gongzhonghao【图灵学术SCI科研圈】,解锁更多SCI相关资讯!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 13
13 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)