AI生态中的常用名词学习整理
适应模型输入:大多数深度学习模型要求输入数据是数值型的向量形式。Model Hub (模型中心):一个像 GitHub 一样的仓库,托管了超过几十万个由社区共享的预训练模型(包括 Transformers 格式和很多其他格式的模型)。功能:它的核心任务是将人类熟悉的、连续的自然语言文本,拆分成模型能够处理的、离散的基本单元(tokens),并将其转换为数值ID。影响模型性能:Tokenizer的选
AI生态中的常用名词学习整理
在AI生态系统PyTorch/TensorFlow,Sentence-Transformers,Transformers,Hugging Face等是较为常见的名词。它们的关系可以用一个比喻来理解:
- PyTorch/TensorFlow 就像是汽车发动机和底盘(提供最基础的动力和框架)
- Transformers 就像是已经造好的、各种型号的豪华跑车(基于发动机和底盘,提供特定且强大的功能)
- Sentence-Transformers 就像是专门为F1赛道优化的顶级赛车(它是基于Transformers“跑车”专门为“句子嵌入”这个赛道改装
- Hugging Face 就像是世界上最大的汽车交易市场、改装厂和赛车俱乐部(它提供了存放“跑车”的仓库、改装工具以及大家交流的社区)。
PyTorch (和 TensorFlow)
- 角色:基础深度学习框架
- 功能:它是一个由 Facebook (现 Meta) AI 研究院开源的 Python 库,提供了构建、训练和部署深度学习模型所需的最核心的张量计算和自动求导功能。你可以把它想象成乐高积木的基础积木块。
- 关系:它是这一切的基础。Transformers 库内部就是使用 PyTorch (或 TensorFlow/JAX) 来实现模型的计算的。
Transformers
- 角色:预训练模型库
- 功能:由 Hugging Face 开发并维护的 Python 库。它提供了数万个预训练好的现代自然语言处理 (NLP) 模型(如 BERT, GPT, T5, RoBERTa),并提供了统一的 API 来加载、使用和微调这些模型。
- 核心价值:标准化和易用性。它把各种复杂模型的使用方式统一成了几个简单的类(如 AutoModel, AutoTokenizer),让研究人员和开发者无需关心底层框架(PyTorch/TensorFlow)的差异,就能轻松调用最先进的模型。
- 关系:它严重依赖于 PyTorch 或 TensorFlow 作为其计算后端。它是一个在基础框架之上构建的、专门针对 NLP 领域的工具库。
Sentence-Transformers
- 角色:为句子和文本嵌入任务特化的预训练模型库
- 功能:它是基于 Transformers 库构建的一个专门分支。它的目标非常明确:将句子、段落或整个文档转换为高维向量(嵌入)。这些向量可以用于语义搜索、聚类、信息检索、重复检测等任务。
- 核心价值:易用的句子嵌入。虽然可以用原始的 Transformers 库自己写代码来生成句子向量,但过程繁琐且效果不一定好。Sentence-Transformers库封装了所有最佳实践,并提供了大量专门为生成高质量句子向量而训练好的模型(如 all-MiniLM-L6-v2),让一两行代码就能得到最好的效果。
- 关系:它是 Transformers 库的一个子集或特化版本。它建立在 Transformers 之上,专注于解决一个特定的问题。
Hugging Face (平台)
-
角色:AI 开源社区和平台
-
功能:它是一个提供全方位服务的平台,核心包括:
Model Hub (模型中心):一个像 GitHub 一样的仓库,托管了超过几十万个由社区共享的预训练模型(包括 Transformers 格式和 很多其他格式的模型)。
Dataset Hub (数据集中心):托管了大量的公开数据集。
Spaces:允许用户直接在上面部署和演示自己的 AI 应用(如 Gradio 或 Streamlit 应用)。
库和工具:开发和维护了 Transformers, Datasets, Accelerate 等核心开源库。推动标准化工具(如 Transformers 库、vLLM 推理引擎) -
关系:它是AI开源生态系统的组织者和核心枢纽。Transformers 和 Sentence-Transformers 库都是由 Hugging Face 公司创建和维护的。PyTorch 则是由Meta独立维护的。OpenAI是美国头部 AI 公司,以闭源模型(如 GPT-4o、O 系列)为核心,通过 API 服务和订阅制(如 ChatGPT Plus)盈利。DeepSeek是中国AI公司,以开源、低成本和垂直优化为核心竞争力,其模型是Hugging Face平台下载量最较的模型。
-
使用
由于网络原因,国内直接从Hugging Face下载模型和数据集可能会遇到速度慢或失败的问题。以下是推荐的国内镜像源及其使用方法:
1.HF-Mirror(推荐)
HF-Mirror是一个由国内开发者维护的公益性质的Hugging Face镜像服务站。官网地址:https://hf-mirror.com
特点:
提供稳定、快速的模型与数据集下载。
支持 huggingface-cli 命令行工具。
支持通过环境变量进行无侵入式加速。
提供基于 aria2 的高速下载脚本 hfd。
支持需要授权(Gated Repo)的模型下载。2.使用方法
通过环境变量设置(最常用,影响范围广)
设置环境变量 HF_ENDPOINT 后,大多数基于 huggingface_hub 库的工具(如 transformers, datasets)都会自动使用镜像站。
Linux/macOS (终端):
export HF_ENDPOINT=https://hf-mirror.com
可以将这行命令添加到 ~/.bashrc 或 ~/.zshrc 中使其永久生效
echo ‘export HF_ENDPOINT=https://hf-mirror.com’ >> ~/.bashrc
source ~/.bashrcWindows (PowerShell):
powershell
$env:HF_ENDPOINT = “https://hf-mirror.com”
要永久生效,可以在系统环境变量中设置 -
在Python代码中照常使用from_pretrained() 等方法即可。
from transformers import AutoModel, AutoTokenizer
model = AutoModel.from_pretrained("bert-base-uncased") # 会自动从镜像站下载
- 使用huggingface-cli下载
安装CLI工具并设置环境变量后,可以直接下载模型或数据集。
-
安装CLI工具:
bash
pip install -U huggingface_hub -
(确保已设置 HF_ENDPOINT 环境变量)
-
下载模型或数据集:
下载模型
huggingface-cli download --resume-download gpt2 --local-dir ./gpt2-model下载数据集
huggingface-cli download --repo-type dataset --resume-download wikitext --local-dir ./wikitext-data
–resume-download: 支持断点续传。
–local-dir: 指定本地存储目录。
- 使用 hfd 高速下载工具(适合大模型)
hfd 是一个封装了 aria2 多线程下载能力的脚本,下载大型模型文件时速度更快。
-
确保系统已安装 aria2:
Ubuntu/Debian
sudo apt install aria2CentOS/RHEL
sudo yum install aria2macOS (使用Homebrew)
brew install aria2 -
下载 hfd.sh 脚本:
bash
wget https://hf-mirror.com/hfd/hfd.sh
chmod +x hfd.sh -
使用 hfd 下载(同样需要先设置 HF_ENDPOINT 环境变量):
bash
./hfd.sh deepseek-ai/deepseek-llm-67b
-
网页直接下载
访问镜像站官网 https://hf-mirror.com,像使用原版Hugging Face网站一样搜索模型或数据集,然后直接点击文件下载即可。注意事项
代理冲突:如果你使用了科学上网工具(VPN),可能会与镜像站设置冲突,导致下载失败。使用时请关闭全局代理或VPN。
授权模型(Gated Repo):下载需要授权的模型(如 LLaMA 系列)时,需要在 huggingface.co 官网申请权限并获得 Access Token。在使用 huggingface-cli 或 hfd 时,通过 --token 参数提供 token。
huggingface-cli download meta-llama/Llama-2-7b --token hf_yourActualTokenHere或者使用 hfd
./hfd.sh meta-llama/Llama-2-7b --hf_username your_username --hf_token hf_yourActualTokenHere
国内类似 Hugging Face 的平台
除了使用镜像站,国内也有一些平台提供了类似的模型共享、托管和开发体验。以下是部分国内平台的不完全列举:
| 平台名称 | 主要特点 | 链接 |
|---|---|---|
| Modelscope (魔搭社区) | 由阿里巴巴达摩院推出,托管了大量中文和多模态模型,提供丰富的Notebook和API体验环境。 | https://modelscope.cn |
| OpenI 启智社区 | 依托国家新一代人工智能开源社区,提供开源协作、算力支持和资源托管。 | https://openi.cn |
| Wisemodel | 旨在打造中国版的“HuggingFace”,汇集了清华大学和智谱研究团队提供的chatglm2-6B、Stable Diffusion V1.5等模型和数据集。 | https://wisemodel.cn |
| 百度文心大模型 | 百度推出的文心大模型系列,提供API和开发工具。 | https://wenxin.baidu.com |
| 讯飞星火认知大模型 | 科大讯飞推出的星火大模型,提供API和开发接口。 | https://xinghuo.xfyun.cn |
如何选择
如果目标是快速下载国际社区(如Hugging Face) 上的模型和数据集,HF-Mirror镜像站是目前最直接、最通用的解决方案。
如果更关注中文模型、本地化体验或国内生态,可以多探索 Modelscope 和 Wisemodel 等国内平台。
许多云厂商(如阿里云百炼、百度千帆、华为云等)也提供了各自的大模型开发平台,通常深度集成其自家模型和工具链。
Tokenizer
-
角色:Tokenizer是自然语言处理(NLP)中的基础组件,负责将原始文本转换为模型可以理解的数值形式。
-
功能:它的核心任务是将人类熟悉的、连续的自然语言文本,拆分成模型能够处理的、离散的基本单元(tokens),并将其转换为数值ID。它的主要作用体现在以下几个方面:
文本预处理:这是Tokenizers在NLP任务中不可或缺的预处理步骤,它的核心功能是将原始文本分割成可处理的单元——tokens。这些tokens可以是单词、子词、字符或自定义的token等。
适应模型输入:大多数深度学习模型要求输入数据是数值型的向量形式。tokenizer负责将文本转换为整数序列,这些整数代表了词汇表中的特定token,这样模型就可以对这些数字进行计算和学习。
处理边界与未知词:Tokenizers可以帮助解决自然语言中的复杂边界问题,如处理未知词汇、标点符号、大小写敏感性等问题,以及处理不同语言的特性(例如中文分词与英文单词划分的不同)。通过子词划分(如WordPiece, BPE),它能有效处理训练时未见过的词汇(OOV问题)。
影响模型性能:Tokenizer的选择直接影响模型的词汇量、处理未登录词的能力和输入序列的长度,进而影响模型的表达能力、泛化能力和计算效率。 -
常见的Tokenizer类型主要有以下几种:
| 类型 | 特点 | 代表模型 |
|---|---|---|
| 基于空格的Tokenizer | 简单快速,直接按空格分割文本,但无法很好处理复合词或未登录词。 | 一些早期或简单的模型 |
| 规则基础的Tokenizer | 使用预定义的规则(如正则表达式)分割文本,比基于空格的方法更灵活,但仍然有限。 | NLTK 的 RegexpTokenizer |
| 子词 Tokenizer | 将文本分割成子词单元,能有效处理未登录词,提高模型的泛化能力,是现代LLM的主流方法。 | BERT, GPT, T5 等 |
| WordPiece | 类似于BPE,但选择合并操作时考虑对语言模型的增益。 | BERT |
| Unigram Language Model | 基于语言模型的方法,通过优化token集来最大化似然。 | XLNet |
AI生态图
局限于知识的局限,以下是笔者画的大致的AI生态图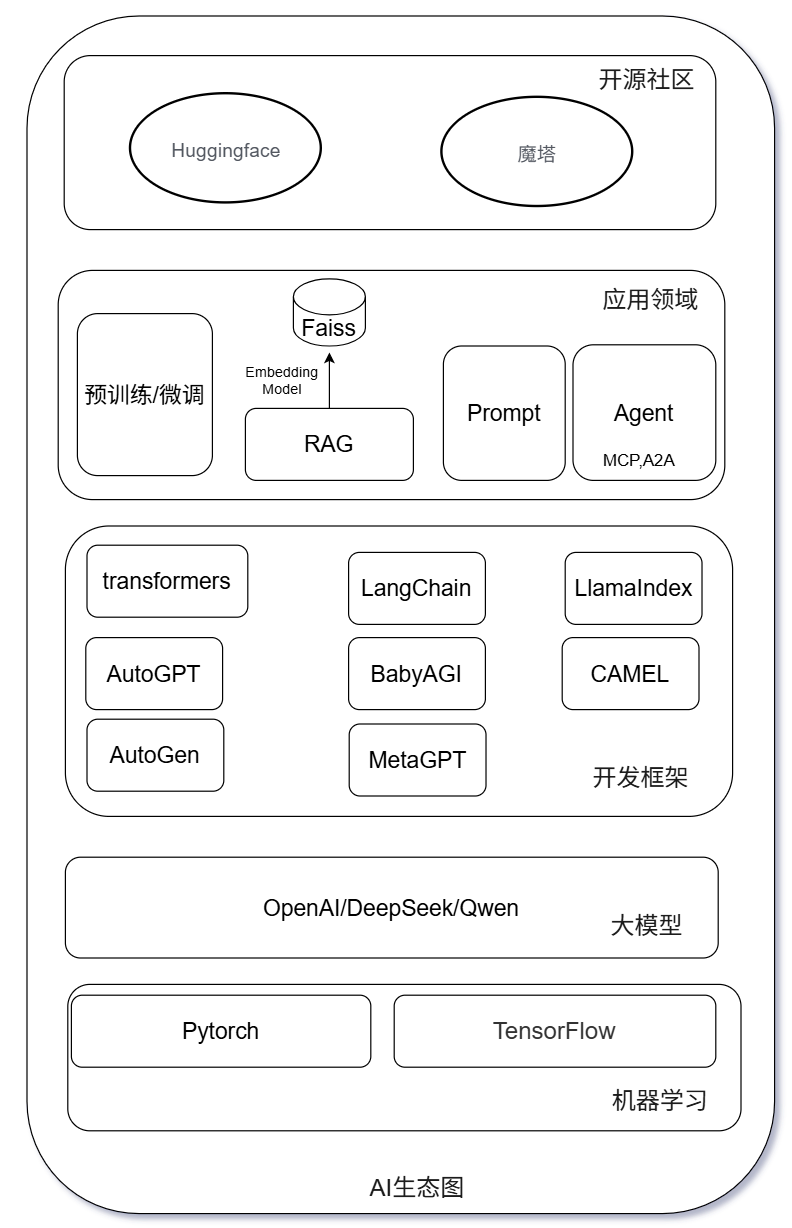
愿你我都能在各自的领域里不断成长,勇敢追求梦想,同时也保持对世界的好奇与善意!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 25
25 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)