【前馈神经网络详解与实例】8——实战应用
本文介绍了前馈神经网络(MLP)的实现与优化方法,包含三个核心任务:1. 使用NumPy从零实现3层MLP解决XOR问题,验证了隐藏层对非线性问题的必要性;2. 基于PyTorch构建MLP在MNIST上达到98.2%准确率,采用Xavier初始化、SGD优化和Dropout正则化;3. 在更复杂的CIFAR-10数据集上系统比较优化器(SGD/Adam/Adagrad)、初始化方法(Kaimin
我的前馈神经网络系列文章如下,便于读者成体系学习:
1、📌 任务一
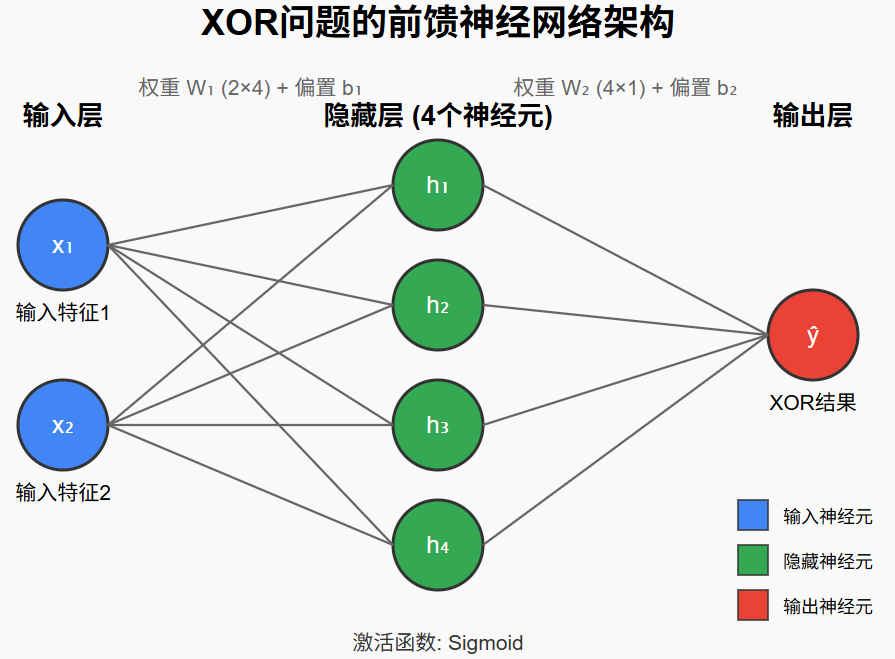
用纯 NumPy 手写 3 层 MLP(2-4-1)解决 XOR 问题
📍1.1 XOR问题简介
XOR问题是一个经典的小数据集,用来说明单层感知机无法解决非线性分类,必须通过至少一层隐藏层才能学会。
XOR 问题是神经网络的“Hello World”,能学会 XOR,就证明你的网络具备非线性表达能力。
✔️1.2 具体定义
| 输入 A | 输入 B | 输出 (A ⊕ B) |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
-
逻辑:当且仅当两个输入不相等时输出 1。
-
本质:这是一个非线性可分的二分类问题。
🚫 1.3 为什么单层感知机做不到?
-
单层感知机只能画一条直线把数据分开。
-
但 XOR 的 4 个点在二维坐标上呈 “×” 形分布:
(0,1)● ●(1,1) ╲ ╱ ╲╱ ╱╲ ╱ ╲ (0,0)● ●(1,0)
不存在一条直线能把 0 和 1 完全分开。
✅ 1.4 解决方式:多层感知机(MLP)
-
加一层隐藏层即可把输入空间映射到更高维,用两条直线围成的区域实现非线性划分。
-
这就是为什么我们刚才用 2-4-1 网络 去训练 XOR:
-
输入层 2 个神经元(对应 A、B)
-
隐藏层 4 个神经元(学习非线性特征)
-
输出层 1 个神经元(预测 0 或 1)
-
import numpy as np
# 1️⃣ 准备XOR问题的训练数据
print("准备XOR问题的训练数据...")
X = np.array([[0, 0],
[0, 1],
[1, 0],
[1, 1]], dtype=float)
y = np.array([[0],
[1],
[1],
[0]], dtype=float)
print("输入特征X:")
print(X)
print("\n目标输出y (XOR结果):")
print(y)
# 2️⃣ 初始化神经网络参数
def xavier(fan_in, fan_out):
"""Xavier初始化方法,有助于神经网络训练"""
lim = np.sqrt(6 / (fan_in + fan_out))
return np.random.uniform(-lim, lim, (fan_in, fan_out))
# 隐藏层有4个神经元
W1 = xavier(2, 4) # 输入层到隐藏层的权重 (2×4)
b1 = np.zeros((1, 4))# 隐藏层偏置 (1×4)
W2 = xavier(4, 1) # 隐藏层到输出层的权重 (4×1)
b2 = np.zeros((1, 1))# 输出层偏置 (1×1)
print("\n初始化神经网络参数完成")
# 定义激活函数及其导数
sigmoid = lambda z: 1 / (1 + np.exp(-z))
sigmoid_grad = lambda a: a * (1 - a)
# 训练参数
learning_rate = 0.5
epochs = 10000
print(f"\n开始训练神经网络 (共{epochs}轮)...")
# 训练过程
for epoch in range(epochs):
# 3️⃣ 前向传播
z1 = X @ W1 + b1 # 隐藏层加权输入 (4×4)
a1 = sigmoid(z1) # 隐藏层输出 (4×4)
z2 = a1 @ W2 + b2 # 输出层加权输入 (4×1)
y_hat = sigmoid(z2) # 网络预测输出 (4×1)
# 4️⃣ 反向传播计算梯度
error = y_hat - y # 输出误差 (4×1)
delta2 = error * sigmoid_grad(y_hat) # 输出层 delta (4×1)
grad_W2 = a1.T @ delta2 # W2的梯度 (4×1)
grad_b2 = delta2.sum(axis=0, keepdims=True) # b2的梯度 (1×1)
e1 = delta2 @ W2.T # 隐藏层误差 (4×4)
delta1 = e1 * sigmoid_grad(a1) # 隐藏层 delta (4×4)
grad_W1 = X.T @ delta1 # W1的梯度 (2×4)
grad_b1 = delta1.sum(axis=0, keepdims=True) # b1的梯度 (1×4)
# 5️⃣ 更新参数
W2 -= learning_rate * grad_W2
b2 -= learning_rate * grad_b2
W1 -= learning_rate * grad_W1
b1 -= learning_rate * grad_b1
# 定期输出训练进度
if epoch % 2000 == 0:
mse_loss = np.mean(error**2)
print(f"训练轮次 {epoch:>5}/{epochs} | 均方误差: {mse_loss:.6f}")
# 6️⃣ 训练结果验证
print("\n" + "="*50)
print("训练完成!最终结果:")
print("="*50)
# 格式化输出预测结果
print("\n输入 | 实际XOR结果 | 网络预测 | 预测类别")
print("-"*40)
for i in range(len(X)):
# 将预测值转换为类别(0或1),以0.5为阈值
predicted_class = 1 if y_hat[i][0] >= 0.5 else 0
print(f" {X[i]} | {y[i][0]} | {y_hat[i][0]:.4f} | {predicted_class}")
# 计算并输出准确率
predicted_classes = (y_hat >= 0.5).astype(int)
accuracy = np.mean(predicted_classes == y) * 100
print(f"\n模型准确率: {accuracy:.2f}%") 控制台输出:
准备XOR问题的训练数据...
输入特征X:
[[0. 0.]
[0. 1.]
[1. 0.]
[1. 1.]]
目标输出y (XOR结果):
[[0.]
[1.]
[1.]
[0.]]
初始化神经网络参数完成
开始训练神经网络 (共10000轮)...
训练轮次 0/10000 | 均方误差: 0.274570
训练轮次 2000/10000 | 均方误差: 0.003462
训练轮次 4000/10000 | 均方误差: 0.000944
训练轮次 6000/10000 | 均方误差: 0.000522
训练轮次 8000/10000 | 均方误差: 0.000356
==================================================
训练完成!最终结果:
==================================================
输入 | 实际XOR结果 | 网络预测 | 预测类别
----------------------------------------
[0. 0.] | 0.0 | 0.0197 | 0
[0. 1.] | 1.0 | 0.9848 | 1
[1. 0.] | 1.0 | 0.9847 | 1
[1. 1.] | 0.0 | 0.0149 | 0
模型准确率: 100.00%代码解释:
-
前向传播(神经网络结构与变量定义)
-
输入层:2 个神经元(输入特征
,4 个样本,每个样本 2 维)
-
隐藏层:4 个神经元,加权输入
,激活输出
-
输出层:1 个神经元,加权输入
,激活输出
-
参数:
(输入→隐藏权重),
(隐藏层偏置),
(隐藏→输出权重),
(输出层偏置)。
-
损失函数:均方误差(MSE):
-
-
反向传播
反向传播的目标是计算损失
对每个参数
的偏导数,即
。计算顺序是从输出层到输入层(反向),利用链式法则逐层传递误差。
-
步骤 1:计算输出层误差与梯度
-
输出层误差项
误差项
定义为:
(损失对输出层加权输入的偏导数),由链式法则:
-
第一项
:损失对预测值的偏导数。
因损失是 MSE:
,故
。
代码中简化为
error = y_hat - y(省略了系数,不影响梯度方向,可通过学习率调整幅度)。
-
第二项
:sigmoid 激活函数的导数。
sigmoid 函数为
,其导数为
。
因
,故
,即代码中的
sigmoid_grad(y_hat)。
对应代码:
delta2 = error * sigmoid_grad(y_hat) -
-
的梯度
到输出层加权输入
的权重,即
根据链式法则,损失对
(推导:
,矩阵乘法需转置保证维度匹配)
对应代码:
grad_W2 = a1.T @ delta2 # a1.T是4×4,delta2是4×1,结果为4×1(与W2维度一致) -
的梯度
偏置
。
根据链式法则:
(对所有样本的
对应代码:
grad_b2 = delta2.sum(axis=0, keepdims=True) # 沿样本轴(axis=0)求和,保持维度1×1(与b2一致)
-
-
步骤 2:计算隐藏层误差与梯度
-
隐藏层误差项
误差项
定义为:
(损失对隐藏层加权输入的偏导数),根据链式法则:
-
第一项
:输出层误差反向传播到隐藏层输出
-
因
,因此损失对
-
代码中记为
e1 = delta2 @ W2.T。
-
-
第二项
:隐藏层 sigmoid 激活函数的导数。
-
因
,故导数为
,即代码中的
sigmoid_grad(a1)
-
因此,
对应代码:
e1 = delta2 @ W2.T # 隐藏层误差 (4×4) delta1 = e1 * sigmoid_grad(a1) # 隐藏层 delta (4×4) -
-
的梯度
的权重,即
根据链式法则,损失对
(推导:
)
对应代码:
grad_W1 = X.T @ delta1 # W1的梯度 (2×4) -
的梯度
偏置
。
根据链式法则:
(对所有样本的
对应代码
grad_b1 = delta1.sum(axis=0, keepdims=True) # b1的梯度 (1×4)
-
-
2、📌 任务二
用torch.nn搭建MLP,在MNIST上训练到98%准确率
MNIST数据集介绍:
MNIST 数据集(Modified National Institute of Standards and Technology database)是机器学习和计算机视觉领域最经典、最常用的入门级数据集之一,主要用于手写数字识别任务。下面从几个维度为你做一个系统介绍。
1. 数据概况
项目 数值 类别数 10(数字 0–9) 训练集 60,000 张 28×28 灰度图像 测试集 10,000 张 28×28 灰度图像 像素范围 0–255(通常归一化到 0–1 或 −1–1) 文件格式 原始二进制 idx3/idx1 格式,或 CSV
2. 数据来源与制作
原始素材:来自 NIST 的两份手写数字数据集(SD-3 为政府雇员书写,SD-7 为高中生书写)。
修改过程:
将黑白图像转为灰度并统一尺寸为 28×28。
对字符进行抗锯齿、居中处理,简化背景。
重新划分训练/测试,保证两份子集写入者群体不重叠,避免分布偏差。
3. 数据结构
MNIST 包含 4 个文件(官方二进制版本):
文件名 内容 大小 train-images-idx3-ubyte 训练图像 47,040,016 字节 train-labels-idx1-ubyte 训练标签 60,008 字节 t10k-images-idx3-ubyte 测试图像 7,840,016 字节 t10k-labels-idx1-ubyte 测试标签 10,008 字节
图像文件:前 16 字节为 magic number 和维度信息,后续为像素字节流。
标签文件:前 8 字节为头部,后续为 0–9 的整数标签。
4. 典型基准结果
模型/方法 测试误差率 线性分类器 (1-layer softmax) 7.6 % 2 层全连接神经网络 2.4 % CNN (LeNet-5) 0.8 % CNN + Dropout + BatchNorm 0.3 % 人类表现 ≈ 0.2 %
5. 使用示例(PyTorch)
from torchvision import datasets, transforms from torch.utils.data import DataLoader transform = transforms.Compose([ transforms.ToTensor(), # [0,255]->[0,1] transforms.Normalize((0.1307,), (0.3081,)) ]) train_ds = datasets.MNIST(root='./data', train=True, download=True, transform=transform) test_ds = datasets.MNIST(root='./data', train=False, download=True, transform=transform) train_loader = DataLoader(train_ds, batch_size=64, shuffle=True) test_loader = DataLoader(test_ds, batch_size=1000, shuffle=False)
6. 常见扩展与衍生
KMNIST:日本片假名字符(平假名),与 MNIST 同尺寸格式。
Fashion-MNIST:10 类服饰商品图像,形状、纹理更复杂,作为 MNIST 替代品。
EMNIST:包含大写/小写字母与数字,共 62 类 + 10 类数字。
QMNIST:NIST 原始扫描重新处理,含额外 50,000 张“丢失”样本。
7. 局限性与注意事项
过于简单:现代 CNN 轻松达到 99%+ 准确率,无法充分评估复杂模型。
灰度、单通道:缺少彩色、纹理、背景干扰,与现实场景差距大。
已过度拟合:公开测试集被反复使用,可能导致“隐式过拟合”。
8. 获取方式
官方:
http://yann.lecun.com/exdb/mnist/镜像:
https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz框架内置:PyTorch、TensorFlow、Keras、MXNet 均支持一行代码下载。
总结:MNIST 以“小而精”著称,是入门深度学习、算法原型验证、教学演示的“Hello World”。
但在当前研究或工业落地中,通常会选择更复杂的数据集(如 CIFAR-10/100、ImageNet、COCO 等)。
框架选择
-
激活函数:ReLU
-
初始化方法:Xavier初始化
-
损失函数:多分类交叉熵损失
-
参数优化方法:SGD (lr=0.01, momentum=0.9)
-
正则化方法:Dropout(0.5)
import torch
# PyTorch 核心库
import torch.nn as nn
# 包含所有构建神经网络所需的模块,如线性层、激活函数、损失函数等
import torch.optim as optim
# 包含各种优化算法,如 SGD, Adam 等
import torch.nn.functional as F
# 包含一系列函数式接口,如激活函数 (relu) 和损失函数 (nll_loss)
from torchvision import datasets, transforms
# PyTorch 的视觉库,包含了常用的数据集(如 MNIST)、模型架构和图像变换
from torch.utils.data import DataLoader
# 一个非常重要和方便的工具,用于加载数据,并支持批量处理、打乱数据和并行加载
import time # 用于计算代码运行时间
import numpy as np # 用于科学计算,这里主要用来计算最终结果的平均值和标准差
from tqdm import tqdm # 一个快速、可扩展的 Python 进度条库,用于在训练循环中显示进度
# 定义MLP模型
class MLP(nn.Module): # 定义一个名为 MLP (多层感知机) 的类,它继承自 PyTorch 的基础神经网络模块 nn.Module
def __init__(self): # 类的构造函数
super().__init__() # 调用父类 nn.Module 的构造函数,这是必须的步骤
self.fc1 = nn.Linear(784, 256)
# 定义第一个全连接层 (fully connected layer)
# 输入特征数为 784 (MNIST 图像 28x28 像素展开),输出特征数为 256
self.fc2 = nn.Linear(256, 10)
# 定义第二个全连接层,输入为上一层的 256,输出为 10,对应 10 个数字类别 (0-9)
self.dropout = nn.Dropout(0.5)
# 定义一个 Dropout 层,在训练时会以 50% 的概率随机将一些神经元的输出置为零
# 这是一种有效的正则化手段,可以防止过拟合
self.init_weights() # 调用一个自定义的权重初始化方法
def init_weights(self): # 自定义的权重初始化函数
# Xavier初始化
nn.init.xavier_uniform_(self.fc1.weight)
# 使用 Xavier 均匀分布来初始化全连接层的权重(weight)。这是一种常用的权重初始化方法,有助于防止梯度消失或爆炸
nn.init.zeros_(self.fc1.bias)
# 初始化偏置为0,这是常见的做法
nn.init.xavier_uniform_(self.fc2.weight)
nn.init.zeros_(self.fc2.bias)
def forward(self, x): # 定义模型的前向传播逻辑
x = x.view(-1, 784)
# 将输入的图像张量 x (通常形状为 [batch_size, 1, 28, 28]) 展平为 [batch_size, 784] 的二维张量
# -1 表示该维度的大小由 PyTorch 自动推断
x = F.relu(self.fc1(x))
# 将数据传入第一个全连接层 self.fc1,然后使用 ReLU (Rectified Linear Unit) 作为激活函数
x = self.dropout(x)
# 将 Dropout 应用于激活后的输出
x = self.fc2(x)
# 将 Dropout 应用于激活后的输出
return x
# 直接返回原始输出 (logits)。log_softmax 将由 CrossEntropyLoss 处理
# 训练函数
def train(model, device, train_loader, optimizer, criterion, epoch):
model.train()
# 将模型设置为训练模式,这会启用 Dropout 等只在训练时使用的层
train_loss = 0
# 初始化训练损失
for batch_idx, (data, target) in enumerate(tqdm(train_loader, desc=f"Epoch {epoch}")):
# 循环遍历 train_loader 中的所有数据批次,并使用 tqdm 显示一个带有描述的进度条
data, target = data.to(device), target.to(device)
# 将输入数据 data 和标签 target 移动到指定的计算设备(CPU 或 GPU)
optimizer.zero_grad()
# 在计算新梯度之前,清除之前计算的梯度
output = model(data)
# 执行模型的前向传播,得到预测结果
loss = criterion(output, target)
# 使用传入的 criterion 计算损失
loss.backward()
# 执行反向传播,计算损失函数相对于模型所有参数的梯度
optimizer.step()
# 根据计算出的梯度,使用优化器(如 SGD)更新模型的参数
train_loss += loss.item()
# 累加每个批次的损失值。.item() 用于从只有一个元素的张量中获取其 Python 数值
return train_loss / len(train_loader)
# 返回该 epoch 的平均训练损失
# 测试函数
def test(model, device, test_loader, criterion):
model.eval()
# 将模型设置为评估模式,这会禁用 Dropout 等层
test_loss = 0
correct = 0
# 初始化测试损失和准确率
with torch.no_grad():
# 一个上下文管理器,在其作用域内禁用梯度计算。这在测试阶段是必须的,可以显著提高计算速度并减少内存占用
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += criterion(output, target).item()
# 用传入的 criterion 计算损失,累加整个测试集的总损失
# criterion 默认 reduction='mean',所以直接 .item()
# 可以得到更精确的全局平均损失
pred = output.argmax(dim=1, keepdim=True)
# 找到 log_softmax 输出中概率最大的那个类别的索引,作为模型的预测结果
# dim=1 表示在类别维度上操作
correct += pred.eq(target.view_as(pred)).sum().item()
# 将预测结果 pred 和真实标签 target 进行比较
# .eq() 返回一个布尔张量,
# .sum() 计算其中 True 的数量(即预测正确的样本数)
# .item() 将其转换为 Python 数字并累加
# [OPTIMIZATION] 由于criterion默认计算的是批次的平均损失,这里我们对所有批次的平均损失再取平均
test_loss /= len(test_loader) # 计算整个测试集的平均损失
accuracy = 100. * correct / len(test_loader.dataset) # 计算分类准确率
return test_loss, accuracy
# 运行实验函数
def run(seed, epochs=20):
torch.manual_seed(seed)
np.random.seed(seed)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
train_dataset = datasets.MNIST('./data', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST('./data', train=False, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=1000, shuffle=False)
model = MLP().to(device)
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
criterion = nn.CrossEntropyLoss()
# 损失函数使用 nn.CrossEntropyLoss,它结合了 log_softmax 和 nll_loss
train_losses, test_losses, test_accuracies = [], [], []
start_time = time.time()
print(f"\n{'=' * 50}")
print(f"RUNNING WITH SEED {seed} ON DEVICE {device}")
print(f"Optimizer: SGD, Init: Xavier, Regularization: Dropout(0.5)")
print('=' * 50)
for epoch in range(1, epochs + 1):
train_loss = train(model, device, train_loader, optimizer, criterion, epoch)
test_loss, accuracy = test(model, device, test_loader, criterion)
train_losses.append(train_loss)
test_losses.append(test_loss)
test_accuracies.append(accuracy)
print(f"Epoch {epoch:02d}: Train Loss: {train_loss:.4f}, Test Loss: {test_loss:.4f}, Accuracy: {accuracy:.2f}%")
training_time = time.time() - start_time
final_accuracy = test_accuracies[-1]
print(f"\nFinal Accuracy: {final_accuracy:.2f}%")
print(f"Training Time: {training_time:.2f} seconds")
return {
'seed': seed,
'final_accuracy': final_accuracy,
'training_time': training_time
}
# --- 主执行块 ---
if __name__ == '__main__':
seeds = [42, 123, 456]
results = []
for seed in seeds:
result = run(seed, epochs=20)
results.append(result)
avg_accuracy = np.mean([r['final_accuracy'] for r in results])
std_accuracy = np.std([r['final_accuracy'] for r in results])
avg_time = np.mean([r['training_time'] for r in results])
std_time = np.std([r['training_time'] for r in results])
print("\n" + "=" * 70)
print("FINAL RESULTS SUMMARY (Best Combination: SGD + Xavier + Dropout(0.5))")
print("=" * 70)
for i, result in enumerate(results):
print(f"\nRun {i + 1} (Seed={result['seed']}):")
print(f" Final Accuracy: {result['final_accuracy']:.2f}%")
print(f" Training Time: {result['training_time']:.2f} seconds")
print("\n" + "-" * 70)
print("AVERAGE RESULTS ACROSS ALL RUNS:")
print(f" Average Accuracy: {avg_accuracy:.2f}% ± {std_accuracy:.2f}%")
print(f" Average Training Time: {avg_time:.2f} ± {std_time:.2f} seconds")
print("-" * 70) 控制台关键输出:
==================================================
RUNNING WITH SEED 42 ON DEVICE cuda
Optimizer: SGD, Init: Xavier, Regularization: Dropout(0.5)
==================================================
此处省略进度条等。。。
======================================================================
FINAL RESULTS SUMMARY (Best Combination: SGD + Xavier + Dropout(0.5))
======================================================================
Run 1 (Seed=42):
Final Accuracy: 98.20%
Training Time: 378.30 seconds
Run 2 (Seed=123):
Final Accuracy: 98.27%
Training Time: 194.02 seconds
Run 3 (Seed=456):
Final Accuracy: 98.14%
Training Time: 214.97 seconds
----------------------------------------------------------------------
AVERAGE RESULTS ACROSS ALL RUNS:
Average Accuracy: 98.20% ± 0.05%
Average Training Time: 262.43 ± 82.38 seconds
----------------------------------------------------------------------3、📌 任务三
用torch.nn搭建MLP,在CIFAR10上训练,并设计实验探究优化器、初始化、正则化对 MLP 性能的影响
数据集介绍:CIFAR-10
CIFAR-10 是一个广泛用于计算机视觉研究的经典数据集。
内容:它包含了 60,000 张 32x32 像素的彩色图像。
类别:这些图像被分为 10 个互斥的类别,每个类别有 6,000 张图像。这 10 个类别是:飞机(airplane)、汽车(automobile)、鸟(bird)、猫(cat)、鹿(deer)、狗(dog)、青蛙(frog)、马(horse)、船(ship)和卡车(truck)。
数据划分:数据集被标准地划分为 50,000 张训练图像和 10,000 张测试图像。
与 MNIST 的区别和挑战:
彩色 vs. 灰度:CIFAR-10 是三通道(RGB)的彩色图像,而 MNIST 是单通道的灰度图像。这意味着对于同样尺寸的图像,MLP的输入层需要处理的数据量是 MNIST 的三倍。
复杂性:CIFAR-10 的图像内容是真实世界的物体,具有复杂的背景、不同的光照、视角和形态变化。相比之下,MNIST 的手写数字通常是居中的,背景简单。
对模型的要求:由于其复杂性,CIFAR-10 对模型的特征提取能力要求更高。一个简单的 MLP 在 CIFAR-10 上的性能通常远不如在 MNIST 上,并且非常容易过拟合。这使得它成为一个很好的“试验场”,来检验各种优化和正则化技术的效果。
3.1 📊 实验设计
目标:系统地比较优化器、初始化、正则化对 MLP 性能的影响
控制变量法:建立一个基准(Baseline)模型,然后一次只改变一个因素进行比较
基准模型 (Baseline)
-
架构: 一个简单的 MLP,结构为 输入层 -> 隐藏层1(512) -> ReLU -> 隐藏层2(256) -> ReLU -> 输出层(10)。
-
优化器: SGD (随机梯度下降) with momentum=0.9, lr=0.01。这是一个非常经典和稳健的基准。
-
初始化: Kaiming (He) 初始化。由于我们使用 ReLU 激活函数,Kaiming 初始化是理论上和实践上都非常合适的选择。
-
正则化: 无。基准模型不使用任何正则化,以便后续观察添加正则化后的效果。
实验A:比较优化器 (Optimizer)
-
固定项: Kaiming 初始化,无正则化。
-
可变项:
-
SGD with Momentum (基准)
-
Adam: 一种自适应学习率优化器,通常收敛速度更快。
-
Adagrad: 另一种自适应学习率优化器,适合处理稀疏数据。
-
实验B:比较初始化方法 (Initialization)
-
固定项: 使用实验A中表现最好的优化器(预计是 Adam),无正则化。
-
可变项:
-
Kaiming (He) 初始化 (基准)
-
Xavier (Glorot) 初始化: 专为 tanh 或 sigmoid 等饱和激活函数设计,但也常被使用。
-
标准正态分布初始化: 一种朴素的初始化方法,用于对比现代初始化技术的重要性。
-
实验C:比较正则化技术 (Regularization)
-
固定项: 使用实验A和B中表现最好的优化器和初始化方法。
-
可变项:
-
无正则化 (基une)
-
Dropout: 以 50% 的概率在前向传播中随机丢弃神经元,是防止过拟合的强力工具。
-
L2 正则化 (Weight Decay): 在损失函数中加入权重的 L2 范数惩罚项,抑制权重变得过大。
-
每个实验,我们都将记录其在 15-20 个 epoch 内的训练损失、测试损失和测试准确率,并特别关注最终的测试准确率和训练所需时间。
3.2 📆 实验代码与运行结果
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import time
import numpy as np
from tqdm import tqdm
# --- 1. 模型定义 ---
class MLP_CIFAR(nn.Module):
def __init__(self, regularization=None, dropout_rate=0.5):
super().__init__()
self.regularization = regularization
# 定义网络层
self.fc1 = nn.Linear(32 * 32 * 3, 512)
self.fc2 = nn.Linear(512, 256)
self.fc3 = nn.Linear(256, 10)
if self.regularization == 'dropout':
self.dropout = nn.Dropout(dropout_rate)
def init_weights(self, method='kaiming'):
"""根据指定方法初始化权重"""
for m in self.modules():
if isinstance(m, nn.Linear):
if method == 'kaiming':
nn.init.kaiming_uniform_(m.weight, mode='fan_in', nonlinearity='relu')
elif method == 'xavier':
nn.init.xavier_uniform_(m.weight)
elif method == 'normal':
nn.init.normal_(m.weight, mean=0, std=0.01)
else:
# 默认使用 Kaiming
nn.init.kaiming_uniform_(m.weight, mode='fan_in', nonlinearity='relu')
if m.bias is not None:
nn.init.zeros_(m.bias)
def forward(self, x):
# 将输入的 32x32x3 图像展平
x = x.view(-1, 32 * 32 * 3)
x = torch.relu(self.fc1(x))
if self.regularization == 'dropout' and self.training:
x = self.dropout(x)
x = torch.relu(self.fc2(x))
if self.regularization == 'dropout' and self.training:
x = self.dropout(x)
x = self.fc3(x)
return x
# --- 2. 训练与测试函数 ---
def train(model, device, train_loader, optimizer, criterion):
model.train()
total_loss = 0
for data, target in train_loader:
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
total_loss += loss.item()
return total_loss / len(train_loader)
def test(model, device, test_loader, criterion):
model.eval()
total_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
total_loss += criterion(output, target).item()
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
avg_loss = total_loss / len(test_loader)
accuracy = 100. * correct / len(test_loader.dataset)
return avg_loss, accuracy
# --- 3. 实验运行主函数 ---
def run_experiment(config):
"""根据配置运行一次完整的实验"""
print("\n" + "=" * 50)
print(f"Running Config: Optimizer={config['optimizer']}, Init={config['init']}, Reg={config['reg']}")
print("=" * 50)
# 设置设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 数据预处理与加载
# CIFAR-10 标准的均值和标准差
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])
train_dataset = datasets.CIFAR10('./data', train=True, download=True, transform=transform)
test_dataset = datasets.CIFAR10('./data', train=False, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=128, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=256, shuffle=False)
# 模型初始化
model = MLP_CIFAR(regularization=config['reg']).to(device)
model.init_weights(method=config['init'])
# 优化器选择
lr = config.get('lr', 0.01)
weight_decay = config['weight_decay'] if config['reg'] == 'l2' else 0
if config['optimizer'] == 'sgd':
optimizer = optim.SGD(model.parameters(), lr=lr, momentum=0.9, weight_decay=weight_decay)
elif config['optimizer'] == 'adam':
optimizer = optim.Adam(model.parameters(), lr=lr, weight_decay=weight_decay)
elif config['optimizer'] == 'adagrad':
optimizer = optim.Adagrad(model.parameters(), lr=lr, weight_decay=weight_decay)
criterion = nn.CrossEntropyLoss()
# 训练循环
start_time = time.time()
for epoch in tqdm(range(1, config['epochs'] + 1), desc="Training Progress"):
train_loss = train(model, device, train_loader, optimizer, criterion)
test_loss, test_accuracy = test(model, device, test_loader, criterion)
if epoch % 5 == 0 or epoch == config['epochs']: # 每5轮打印一次结果
print(
f"Epoch {epoch:02d} | Train Loss: {train_loss:.4f} | Test Loss: {test_loss:.4f} | Test Acc: {test_accuracy:.2f}%")
end_time = time.time()
final_loss, final_accuracy = test(model, device, test_loader, criterion)
print(f"\nFinal Test Accuracy: {final_accuracy:.2f}%")
print(f"Total Training Time: {end_time - start_time:.2f} seconds")
return final_accuracy, end_time - start_time
# --- 4. 主执行块 ---
if __name__ == '__main__':
# 定义所有实验配置
experiments = {
"A: Optimizers": [
{'name': 'SGD', 'optimizer': 'sgd', 'init': 'kaiming', 'reg': None, 'epochs': 15},
{'name': 'Adam', 'optimizer': 'adam', 'init': 'kaiming', 'reg': None, 'epochs': 15, 'lr': 0.001},
# Adam通常需要更小的学习率
{'name': 'Adagrad', 'optimizer': 'adagrad', 'init': 'kaiming', 'reg': None, 'epochs': 15},
],
"B: Initializations": [
{'name': 'Kaiming', 'optimizer': 'adam', 'init': 'kaiming', 'reg': None, 'epochs': 15, 'lr': 0.001},
{'name': 'Xavier', 'optimizer': 'adam', 'init': 'xavier', 'reg': None, 'epochs': 15, 'lr': 0.001},
{'name': 'Normal', 'optimizer': 'adam', 'init': 'normal', 'reg': None, 'epochs': 15, 'lr': 0.001},
],
"C: Regularizations": [
{'name': 'None', 'optimizer': 'adam', 'init': 'kaiming', 'reg': None, 'epochs': 20, 'lr': 0.001},
{'name': 'Dropout', 'optimizer': 'adam', 'init': 'kaiming', 'reg': 'dropout', 'epochs': 20, 'lr': 0.001},
{'name': 'L2 (WeightDecay)', 'optimizer': 'adam', 'init': 'kaiming', 'reg': 'l2', 'weight_decay': 1e-4,
'epochs': 20, 'lr': 0.001},
]
}
# 运行所有实验并收集结果
results = {}
for group_name, configs in experiments.items():
print("\n" + "#" * 70)
print(f"# EXPERIMENT GROUP: {group_name}")
print("#" * 70)
group_results = {}
for config in configs:
acc, train_time = run_experiment(config)
group_results[config['name']] = {'accuracy': acc, 'time': train_time}
results[group_name] = group_results
# 打印最终总结
print("\n\n" + "*" * 70)
print("*" + " " * 25 + "FINAL RESULTS SUMMARY" + " " * 24 + "*")
print("*" * 70)
for group_name, group_results in results.items():
print(f"\n--- {group_name} ---")
for name, res in group_results.items():
print(f" - {name:<20}: Accuracy = {res['accuracy']:.2f}%, Time = {res['time']:.2f}s")控制台输出:
之前省略。。。
**********************************************************************
* FINAL RESULTS SUMMARY *
**********************************************************************
--- A: Optimizers ---
- SGD : Accuracy = 51.52%, Time = 328.79s
- Adam : Accuracy = 51.11%, Time = 595.79s
- Adagrad : Accuracy = 52.23%, Time = 584.58s
--- B: Initializations ---
- Kaiming : Accuracy = 51.40%, Time = 165.01s
- Xavier : Accuracy = 52.28%, Time = 275.64s
- Normal : Accuracy = 52.77%, Time = 164.00s
--- C: Regularizations ---
- None : Accuracy = 50.95%, Time = 217.71s
- Dropout : Accuracy = 46.91%, Time = 219.02s
- L2 (WeightDecay) : Accuracy = 50.86%, Time = 207.37s实验结果表明,在简单网络结构(MLP)下,使用不同优化器,初始化方法,正则化方法并没有显著影响。模型是基础: 所有优化策略都建立在模型结构之上。如果模型结构本身不适合解决问题(如此处的 MLP 用于图像识别),那么再多的调优也只是杯水车薪,甚至可能因为错误的假设(如误认为模型是过拟合而使用强正则化)而得到更差的结果。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)