【训练优化】显存占满,利用率却惨不忍睹?一文带你打通大模型训练的任督二脉
大模型训练中常见显存占满但GPU利用率低的问题,根源在于数据供给管道存在瓶颈。本文指出三大关键瓶颈:I/O读取速度慢、CPU预处理能力不足以及频繁的小任务分发开销,并提出四步优化方案:使用性能分析工具定位瓶颈、优化数据加载参数(调整num_workers和pin_memory)、改进预处理流程、减少任务碎片化。通过系统性地诊断和优化,可显著提升GPU利用率,实现高效的大模型训练。
显存占满,利用率却惨不忍睹?一文带你打通大模型训练的任督二脉
前言:那个令人沮丧的nvidia-smi界面
你是否也遇到过这样的场景:为了训练一个梦寐以求的大语言模型(LLM),你精心配置了环境,将 batch_size 和 max_length 反复调整,终于让显存占用率达到了 95% 以上。你心满意足地以为显卡正在全力燃烧,但打开 nvidia-smi -l 1 一看,GPU-Util 却在 20% 到 40% 之间尴尬地徘徊。显存是仓库,利用率是工厂的生产线,仓库满了,生产线却在怠工,这说明什么?

核心结论: 这种情况几乎总指向一个问题——数据供给管道(Data Pipeline)出现了瓶颈,导致 GPU 这头性能猛兽处于“饥饿”状态。 你的 GPU 大部分时间不在计算,而是在等待数据。
本文将从问题根源出发,为你提供一套从诊断到优化的完整实战指南。
常见解决方法
第一部分:为什么的 GPU 在“摸鱼”?—— 揭秘三大瓶颈
把 GPU 训练想象成一个工厂。VRAM(显存) 是工厂里的本地仓库,存放着当前批次需要加工的原材料(输入数据、模型权重)和中间产品(激活值、梯度)。GPU 利用率 则代表着工厂生产线(CUDA Cores)的繁忙程度。仓库满了,生产线却空闲,说明原材料的补给速度跟不上生产线的消耗速度。
造成这种“补给不及时”的元凶主要有三个:
1. I/O 瓶颈:数据读取与预处理是“万恶之源”
这是最常见、也是最容易被忽视的问题。GPU 的计算速度是微秒级的,而从硬盘读取数据、进行解码、执行数据增强(如随机裁剪、旋转、分词等)等操作通常由 CPU 完成,速度是毫秒级的。
- 硬盘速度:如果你的数据集存放在机械硬盘(HDD)上,其随机读取速度可能成为巨大的瓶颈。
- 数据预处理:复杂的在线(On-the-fly)数据增强、分词(Tokenization)等操作会大量消耗 CPU 资源。如果每个 batch 的数据都需要 CPU 花费很长时间去准备,那么 GPU 在完成一次计算后,就只能眼巴巴地等着 CPU 投喂下一个 batch。
2. CPU 瓶颈:Python 的“掣肘”
CPU 不仅要负责数据预处理,还要负责将计算任务(CUDA Kernel)分发给 GPU。如果你的 CPU 单核性能不强,或者主线程被其他 Python 逻辑(例如复杂的日志记录、回调函数)阻塞,也会导致任务分发不及时。即使数据已经准备好,CPU 没空下达“开工”指令,GPU 也只能继续等待。
3. Kernel Launch Overhead:频繁的“小任务”拖垮效率
GPU 的强大在于其并行计算能力,它擅长执行大规模、长时间的计算任务。但是,每次 CPU 指示 GPU 执行一个任务(称为 Kernel Launch)本身是有开销的。如果你的模型包含大量微小的、碎片化的操作,CPU 就会频繁地启动和停止 GPU 任务。这个过程就像一个车间主任不停地对工人喊“开工!停!开工!停!”,大部分时间都浪费在了沟通成本上,而不是实际工作。
第二部分:实战演练:四步打通你的训练管道
知道了问题所在,就可以对症下药。下面是一套行之有效的优化流程。
第零步:先学会诊断
没有测量,就没有优化。在动手修改任何代码之前,先用工具确认瓶颈。
-
基础诊断:
nvidia-smi dmon -s u或watch -n 1 nvidia-smi:实时观察 GPU 利用率。htop或top:观察 CPU 各核心的占用率。如果你发现有几个 CPU 核心持续 100%,而 GPU 利用率却很低,那么 CPU 瓶颈的可能性就很大。
-
专业诊断:
-
PyTorch Profiler: 这是 PyTorch 内置的性能分析神器。它可以精确地告诉你每个操作在 CPU 和 GPU 上花费的时间,以及是否存在数据加载瓶颈。
-

-
通过分析 Profiler 的输出,你可以清晰地看到是
DataLoader卡住了,还是某个 CPU 操作耗时过长。
第一步:优化数据加载(I/O & Preprocessing)
这是最立竿见影的优化方向。
-
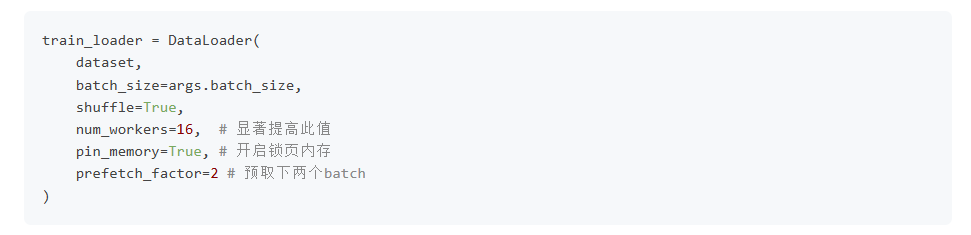
增加
num_workers: 在torch.utils.data.DataLoader中,这个参数至关重要。它会启动多个子进程在后台并行加载和预处理数据。- 经验法则:通常设置为你机器 CPU 核心数的 2 到 4 倍,或者等于你的 GPU 数量的 4 倍。你需要实验来找到最佳值。
- 注意:在 Windows 上,
num_workers> 0 可能有一些问题,需要将数据加载代码放在if __name__ == '__main__':块中。
-
开启
pin_memory=True:-
作用:这个选项会告诉
DataLoader将数据加载到 CPU 的“锁页内存(Pinned Memory)”中。这块内存可以直接被 GPU 访问(通过 DMA),避免了从普通 CPU 内存到 GPU 显存的额外拷贝,从而加快了数据传输速度。必须与num_workers> 0 配合使用。
-
点击链接一文带你打通大模型训练的任督二脉阅读原文

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 29
29 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)