1.7 大模型监督微调(SFT)训练策略
上一节介绍了SFT训练参数的常见设置,本节涵盖四种常见的 SFT 训练策略与多轮对话(multi-turn)专项提升的数据与损失函数(loss)设计。
SFT 训练策略与多轮对话专项提升
上一节介绍了SFT训练参数的常见设置,本节涵盖四种常见的 SFT 训练策略与多轮对话(multi-turn)专项提升的数据与损失函数(loss)设计。
一、四种 SFT 训练策略
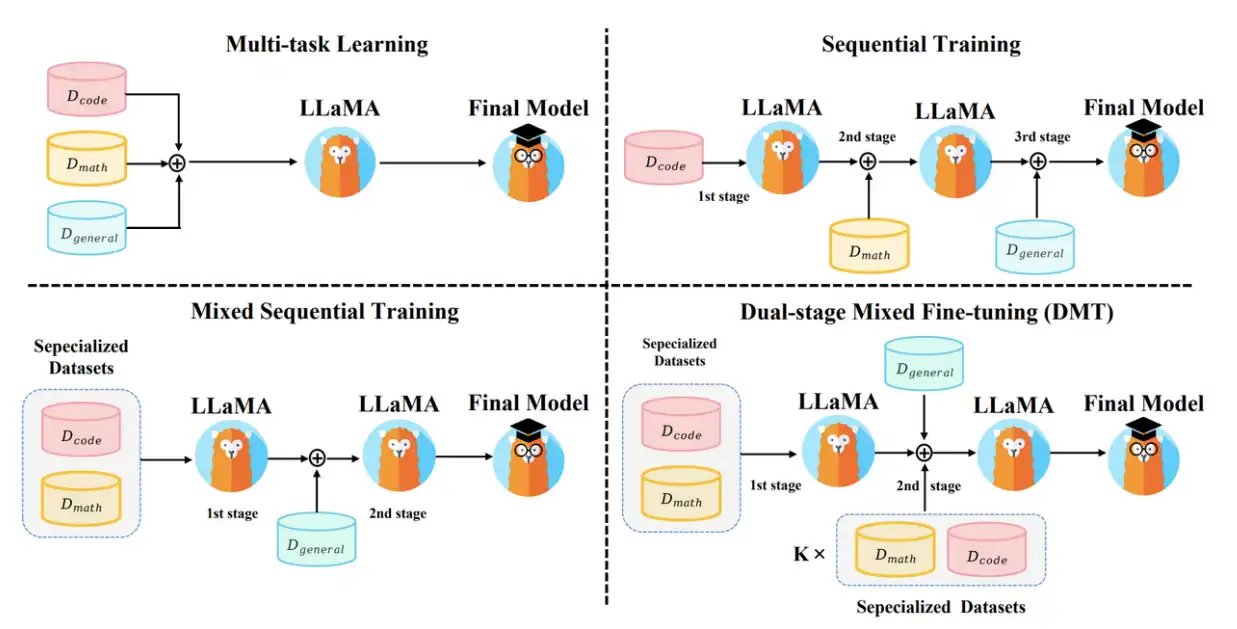
1. 多任务学习(Multi-Task SFT)
在 SFT(监督微调,Supervised Fine-Tuning)阶段,我们常常有多个不同来源/场景的数据,比如 代码问答数据、数学推理数据、通用对话数据。
多任务学习就是把这些不同来源的数据混合到一起,一次性喂给模型训练,而不是分开训练。
可以理解为:模型在同一个训练过程中,同时学习多个任务。
做法:将不同来源/场景的 SFT 数据直接混合,统一执行一次 SFT。
采样与配比
-
最简单做法:按照样本数量比例直接拼接。比如代码数据 100w 条,通用数据 900w 条 → 那么训练中就 1:9 的比例被采到。
-
更鲁棒的做法是温度采样(temperature sampling):
pi = niα∑jnjα,α∈[0,1] p_i \;=\; \frac{n_i^{\alpha}}{\sum_{j} n_j^{\alpha}}, \qquad \alpha \in [0,1] pi=∑jnjαniα,α∈[0,1]
其中 nin_ini 为第 (i) 个数据源的样本量;α→0\alpha \to 0α→0 更均衡,越趋向平均抽样(小数据集也能多被抽到);α→1\alpha \to 1α→1 更偏向大数据源,越接近原始比例(大数据集主导);
👉 这样能平衡大数据集“压制”小数据集的问题,同时避免小数据集过拟合。
优点/风险
- ✅ 简单高效、吞吐友好;能同时提升多种能力。
- ⚠️ 任务间“抢容量”与负迁移风险:抢容量——模型的参数有限,如果数据分布差异太大,可能互相干扰。同时,质量差或风格冲突的数据会拖累整体表现。需严格数据清洗与采样控制。(比如:低质量闲聊数据 → 影响了代码推理时的严谨性)
实操建议
- 执行 去重/质量分层:优先高质量数据,给低质量加衰减权重。
- 建立 分任务验证集(code/math/general…),分开跟踪指标,避免“总分上涨、关键场景下滑”。
2. 顺序训练(Sequential SFT)
做法:把多个数据集按顺序依次 SFT(例如先编码,再数学推理,再通用能力)。
典型排布
- 课程式(Curriculum):由易到难或由通用到专业。
- 回放/复习(Replay):后续阶段少量混入前一阶段数据,缓解灾难性遗忘。
对忘记/记忆的权衡
- 令第 ttt 阶段的混合分布为:
p(t) = (1−λt) pnew + λt preplay,λt∈[0,1] p^{(t)} \;=\; (1-\lambda_t)\,p_{\text{new}} \;+\; \lambda_t\,p_{\text{replay}}, \qquad \lambda_t \in [0,1] p(t)=(1−λt)pnew+λtpreplay,λt∈[0,1]
其中 preplayp_{\text{replay}}preplay 来自前序阶段的回放数据。根据验证集选择 λt\lambda_tλt。
3. 混合序列训练(Mixed-Sequential)
做法:第一阶段先在专业数据(如代码、数学)上做多任务学习;第二阶段转向通用能力数据再 SFT。
动机
- 先把“专业底座”打牢,再用通用数据对齐语气/格式/覆盖面,使模型“能说会道”且不丢专业。
风险与对策
- 第二阶段可能稀释专业能力:在第二阶段按小比例 混入专业回放数据(例如 5%–20%)以稳定专业指标。
4. 双阶段混合微调(DMT, Dual-Stage Mixed Tuning)
做法
- 阶段一:只在专业数据(代码、数学等)上做 SFT(与混合序列训练的第一阶段相同)。
- 阶段二:在混合数据源上 SFT——由通用数据与按不同比例 (k) 混入的代码/数学数据组成:
k∈{ 1, 1/2, 1/4, 1/8, 1/16, 1/32 } k \in \{\,1,\; 1/2,\; 1/4,\; 1/8,\; 1/16,\; 1/32\,\} k∈{1,1/2,1/4,1/8,1/16,1/32}
配比表达
- 把第二阶段的数据分布写成:
pDMT = (1−λ) pgeneral + λ pspec,λ ∝ k p_{\text{DMT}} \;=\; (1-\lambda)\,p_{\text{general}} \;+\; \lambda\,p_{\text{spec}}, \quad \lambda \;\propto\; k pDMT=(1−λ)pgeneral+λpspec,λ∝k
其中 pspecp_{\text{spec}}pspec 为代码/数学等专业数据的混合分布。实际实现里可直接按 kkk 控制采样权重或条数。
优点/取舍
- ✅ 在“语言对齐”时持续喂入少量专业数据,显著缓解遗忘。
- ⚠️ kkk 取值过大:通用风格/安全/守则对齐不足;过小:专业能力回落。建议网格搜索 kkk,以分任务验证集早停。(逐个尝试不同的 k ,训练模型并在验证集上评估效果;最后选出表现最好的那个参数)
二、多轮对话专项提升(数据构造与 Loss 设计)
1. 多轮对话数据判断(真/伪多轮识别)
目标:区分主题连续(真多轮,label=1)与主题切换(伪多轮,label=0)的 turn。(有的时候确实是多轮对话,但是用户问的并不是一直是一个问题,有可能他只是没开新窗口,但是问的问题和开始已经不相关了)
做法
- 训练一个小型判别器,对 session 的每个 turn 判断:与上一个 turn是否同一主题。
- 策略:
- 真多轮(主题连续)→ 全部保留;
- 伪多轮(中途换话题,如从问商品切到问天气)→ 有控制地采样一小部分加入训练,教模型学会在话题切换时舍弃过时上下文、调整注意力焦点。
好处
- 提升模型在长对话中的焦点稳定性与鲁棒性,降低“上文纠缠/幻觉”概率。
2. 多轮对话数据合成(从单轮合成多轮)
场景:真多轮数据不足时。
- 使用模板或**强模型(如 GPT)**基于第一轮 Q/A 生成第二轮的 user prompt,再生成对应的 bot response,递推合成更多轮。
- 关键点:严格控制知识泄漏、角色标记(
<user> / <assistant>或系统/指令段)、格式一致性、风格对齐。
3. 多轮数据飞轮(持续挖掘线上日志)
步骤
- 定期抽取线上对话日志,优先选择 session 尾部 的高质量多轮片段。(因为对话走到后面,往往包含更多上下文,且用户已经澄清问题,数据质量更高)
- 做去重(不是只去掉完全相同的句子,而是做“语义去重”,避免同质化样本反复出现)、匿名化/脱敏(去掉个人信息、敏感字段(手机号、账号等),保证隐私合规)、质量过滤(只保留有意义、上下文连贯的对话,过滤掉灌水/垃圾对话),并利用判别器筛入真多轮、少量伪多轮。
- 滚动微调 + 离线评测闭环:新增数据先过离线指标/红线再进入训练池。(每隔一段时间,把新增的多轮数据加入训练,持续迭代。在数据进入训练池之前,先跑一遍离线评测(例如:多轮一致性、任务完成率、安全性)。如果新增数据在关键指标(比如安全守则、输出合规性)上不过关,就不能加入训练)
4. 多轮对话的 Loss 计算与加速
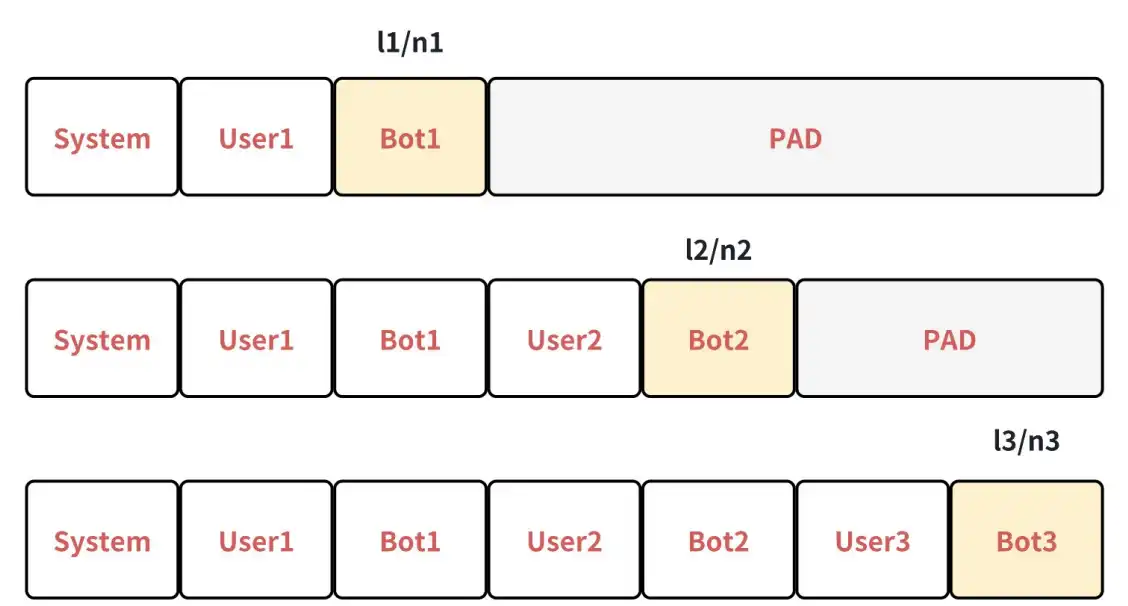
4.a 多轮拆分样本(逐轮建样本,最直观)
设一个对话共 TTT 轮(例如 T=3T=3T=3),将每一轮都构成一个独立样本:白色(prompt)部分的 label 置为 −100-100−100 不计损失,只对该轮 bot response 计损失。记第 iii 个样本的总损失为 lil_ili,对应有效监督 token 数为 nin_ini(即 label ≠−100\neq -100=−100 的数量)。
长度归一化后的平均 loss:
Lsplit = 1T ∑i=1Tlini \boxed{ \mathcal{L}_{\text{split}} \;=\; \frac{1}{T}\,\sum_{i=1}^{T} \frac{l_i}{n_i} } Lsplit=T1i=1∑Tnili
- 每轮先做 per-turn 的长度归一化(lini\frac{l_i}{n_i}nili),再对轮数做平均(1T∑\frac{1}{T}\sumT1∑)。
- ✅ 优点:概念清晰,不偏袒长输出或短输出。
- ⚠️ 缺点:同一对话的公共前缀会被重复计算,训练吞吐较低。
4.b 合并样本(单样本三轮),但要注意 PyTorch 的 reduction 语义
把TTT 轮合并成一条序列(依赖自回归的 causal mask 保证“只能看前面”),计算上等价,但如果仍用 PyTorch 默认的 CrossEntropyLoss(reduction='mean'),会得到按 token 平均的损失:
Ltoken-mean = ∑i=1T∑t=1niℓi,t∑i=1Tni = l1+⋯+lTn1+⋯+nT \boxed{ \mathcal{L}_{\text{token-mean}} \;=\; \frac{\sum_{i=1}^{T} \sum_{t=1}^{n_i} \ell_{i,t}}{\sum_{i=1}^{T} n_i} \;=\; \frac{l_1 + \cdots + l_T}{n_1 + \cdots + n_T} } Ltoken-mean=∑i=1Tni∑i=1T∑t=1niℓi,t=n1+⋯+nTl1+⋯+lT
其中 ℓi,t\ell_{i,t}ℓi,t 是第iii 轮第 ttt 个 token 的逐 token 损失。
这会放大长输出的权重、压低短输出的权重,与 4.a 的“每轮等权”不等价。
📊 假设数据
一个对话有 T=2T=2T=2 轮:
-
第1轮(短回答):监督 token 数 n1=2n_1 = 2n1=2,逐 token loss 分别是 [1.0,1.0][1.0, 1.0][1.0,1.0]
⇒\Rightarrow⇒ 总损失 l1=2.0l_1 = 2.0l1=2.0 -
第2轮(长回答):监督 token 数 n2=4n_2 = 4n2=4,逐 token loss 分别是 [0.5,0.5,0.5,0.5][0.5, 0.5, 0.5, 0.5][0.5,0.5,0.5,0.5]
⇒\Rightarrow⇒ 总损失 l2=2.0l_2 = 2.0l2=2.0
👉 注意:虽然两轮 总损失一样(都是 2.0),但长度不同。
🔹 方法 4.a:拆分样本(每轮等权)
先做 轮内平均,再对轮数平均:
Lsplit=1T(l1n1+l2n2)=12(2.02+2.04)=12(1.0+0.5)=0.75 \mathcal{L}_{\text{split}} = \frac{1}{T} \left( \frac{l_1}{n_1} + \frac{l_2}{n_2} \right) = \frac{1}{2}\left(\frac{2.0}{2} + \frac{2.0}{4}\right) = \frac{1}{2}(1.0 + 0.5) = 0.75 Lsplit=T1(n1l1+n2l2)=21(22.0+42.0)=21(1.0+0.5)=0.75
👉 结果:0.75
- 每轮都有 50% 的权重,不论长短。
🔹 方法 4.b:合并样本(默认 token-mean)
直接拼起来变成 6 个 token,一起平均:
Ltoken-mean=l1+l2n1+n2=2.0+2.02+4=46=0.666… \mathcal{L}_{\text{token-mean}} = \frac{l_1 + l_2}{n_1 + n_2} = \frac{2.0 + 2.0}{2 + 4} = \frac{4}{6} = 0.666\ldots Ltoken-mean=n1+n2l1+l2=2+42.0+2.0=64=0.666…
👉 结果:0.67
- 第 2 轮 token 多,在平均时占了更大比重,于是它的“低 loss”拉低了整体结果。
PyTorch 的交叉熵(带 ignore_index)的形式
设 In = 1{ yn≠ignore_index }\mathcal{I}_n \;=\; \mathbf{1}\{\, y_n \neq \texttt{ignore\_index} \,\}In=1{yn=ignore_index}、权重wnw_nwn(常取 1),则
ℓ(x,y)={∑n=1Nwn In ℓn∑n=1Nwn In,if reduction=’mean’∑n=1Nℓn,if reduction=’sum’ \ell(x,y)= \begin{cases} \dfrac{\sum_{n=1}^{N} w_n\,\mathcal{I}_n \,\ell_n}{\sum_{n=1}^{N} w_n\,\mathcal{I}_n}, & \text{if reduction='mean'}\\[8pt] \sum_{n=1}^{N} \ell_n, & \text{if reduction='sum'} \end{cases} ℓ(x,y)=⎩ ⎨ ⎧∑n=1NwnIn∑n=1NwnInℓn,∑n=1Nℓn,if reduction=’mean’if reduction=’sum’
简单来说sun就是不除以token的总数,直接用所有token的loss监督。
4.c Packing + 加速计算(跨样本拼接,仍需公平计权)
把多个对话的样本拼接为一条长序列,并用 attention mask/分段边界 保证“后样本不可见前样本”。
- 关键:即便采用合并/packing 的工程加速,损失的统计口径也应与 4.a 等价。
例如:对话 A(单轮,样本l11,n11l_{11}, n_{11}l11,n11)与对话 B(三轮,样本l21,n21l_{21}, n_{21}l21,n21、l22,n22l_{22}, n_{22}l22,n22、l23,n23l_{23}, n_{23}l23,n23),正确的“每轮等权” loss应为:
Lturn-mean = 14(l11n11+l21n21+l22n22+l23n23) \boxed{ \mathcal{L}_{\text{turn-mean}} \;=\; \frac{1}{4}\left( \frac{l_{11}}{n_{11}} + \frac{l_{21}}{n_{21}} + \frac{l_{22}}{n_{22}} + \frac{l_{23}}{n_{23}} \right) } Lturn-mean=41(n11l11+n21l21+n22l22+n23l23)
乍一看这个和4.a基本一样,但是其实是有区别的。主要区别是4.a是按token级别来计算损失(因为那个只有一段多轮的对话)。但这里是多段对话,把多段对话拼在一起,4.c是按照“轮”级别来计算损失。

🎯 假设一个 global batch
里面有 两个对话:
对话 A: 只有 1 轮
- 长度 n11=2n_{11}=2n11=2,loss 总和 l11=2.0l_{11}=2.0l11=2.0
- 平均 loss = 2.0/2=1.02.0/2=1.02.0/2=1.0
对话 B: 有 3 轮
- 第 1 轮: n21=2n_{21}=2n21=2,loss 总和 l21=2.0l_{21}=2.0l21=2.0,平均=1.0
- 第 2 轮: n22=4n_{22}=4n22=4,loss 总和 l22=4.0l_{22}=4.0l22=4.0,平均=1.0
- 第 3 轮: n23=2n_{23}=2n23=2,loss 总和 l23=0.4l_{23}=0.4l23=0.4,平均=0.2
所以我们有 4 个“轮”,每轮的平均 loss 分别是:
- A: 1.0
- B1: 1.0
- B2: 1.0
- B3: 0.2
🔹 方案 4.c: Packing + 公平计权(仍然是“按轮平均”)
虽然在工程实现上把 A 和 B 拼接成一条长序列来跑(用 cu_seqlens 控制边界),
但最终 loss 必须回到 轮平均:
Lturn-mean=14 (1.0+1.0+1.0+0.2)=0.8 \mathcal{L}_{\text{turn-mean}} = \frac{1}{4}\,(1.0+1.0+1.0+0.2) = 0.8 Lturn-mean=41(1.0+1.0+1.0+0.2)=0.8
➡️ 结果:0.8
每个轮在全局里权重相等(25%)。
🔸 常见做法(错误):三重平均
现实里很多框架默认会 按 token 平均,再在 DP 和梯度累加上继续平均。
这样就会变成 token-mean,即:
Ltoken-mean=l11+l21+l22+l23n11+n21+n22+n23=2.0+2.0+4.0+0.42+2+4+2=8.410=0.84 \mathcal{L}_{\text{token-mean}} = \frac{l_{11}+l_{21}+l_{22}+l_{23}}{n_{11}+n_{21}+n_{22}+n_{23}} = \frac{2.0+2.0+4.0+0.4}{2+2+4+2} = \frac{8.4}{10} = 0.84 Ltoken-mean=n11+n21+n22+n23l11+l21+l22+l23=2+2+4+22.0+2.0+4.0+0.4=108.4=0.84
➡️ 结果:0.84
这里第 2 轮(4 个 token)权重大,被拉高整体 loss;而 B3(2 个 token,loss 低)的影响被稀释。
◆ 方案 4.d:最终落地(按轮全局平均)
建议方案是彻底禁掉三次默认平均(解释见4.d节),自己在 global batch 级别收集所有轮,
每个轮先归一化(除以 nin_ini),再全局平均:
Lfinal = 1Tglobal∑i=1Tgloballini = 14(1.0+1.0+1.0+0.2) = 0.8 \mathcal{L}_{\text{final}} \;=\; \frac{1}{T_{\text{global}}} \sum_{i=1}^{T_{\text{global}}} \frac{l_i}{n_i} \;=\; \frac{1}{4}(1.0 + 1.0 + 1.0 + 0.2) \;=\; 0.8 Lfinal=Tglobal1i=1∑Tglobalnili=41(1.0+1.0+1.0+0.2)=0.8
👉 结果:0.8,和 4.c 一致。
4.d 最终落地方案:禁用多重平均,按“轮”做全局加权
实际训练中常见三次平均:
- micro-batch 维度:默认按“有效 label token 数”求均值;
- 数据并行(DP)维度:不同 GPU 间再平均;
- 梯度累加:多个 step 累加后再平均。
建议:禁用这三个平均,统一改为**“按轮数做全局平均”**:
-
记当前 global batch 内共有 TglobalT_{\text{global}}Tglobal 个“轮”(turn),对每个轮 iii 先做长度归一化lini\frac{l_i}{n_i}nili,再对所有轮求平均:
Lfinal = 1Tglobal∑i=1Tgloballini \boxed{ \mathcal{L}_{\text{final}} \;=\; \frac{1}{T_{\text{global}}} \sum_{i=1}^{T_{\text{global}}} \frac{l_i}{n_i} } Lfinal=Tglobal1i=1∑Tglobalnili -
工程要点:
- 将
CrossEntropyLoss(reduction='sum')(或直接累计未归一化的 lil_ili 与 nin_ini),在数据侧或 loss 函数外手动做 lini\frac{l_i}{n_i}nili与全局求和; - 每个 micro-batch 返回其包含的轮数(turn 数)与每轮的 (li,ni)(l_i, n_i)(li,ni);
- 框架端在 DP 与 梯度累加 汇总后再做一次按轮平均。
- 将
-
与现成框架的开关:在部分实现(如新版 Megatron-LM)里,开启
--calculate-per-token-loss可禁用 DP/梯度累加的平均,使你可以拿到原始和进行自定义 per-turn 平均。最终以 Lfinal\mathcal{L}_{\text{final}}Lfinal 参与反向传播。
一致性校验:若所有轮的长度近似相等(ni≈nn_i \approx nni≈n),则
Ltoken-mean≈Lturn-mean\mathcal{L}_{\text{token-mean}} \approx \mathcal{L}_{\text{turn-mean}}Ltoken-mean≈Lturn-mean。 (4.a/4.c vs 4.b)
当长度差异显著时,务必采用 turn-mean,否则短回答的监督会不充分。
三、实操细节与排坑清单
数据与标注
- Label Mask:对 prompt/系统提示/历史上下文的标签置 −100-100−100(mask掉),仅对当前轮的 assistant 响应计损失。
- 角色与模板:统一
system/user/assistant标记与分隔;多来源数据务必模板对齐。 - 伪多轮的比例:少量即可产生“话题切换鲁棒性”;比例过高会削弱同一主题下的连贯性。
训练与加速
- Packing/合并:配合
cu_seqlens与 causal mask;跨样本拼接需保证不同样本不可见! - Loss 统计口径:统一使用Lfinal\mathcal{L}_{\text{final}}Lfinal(按轮平均),禁止被动继承
reduction='mean'带来的按 token 平均偏置。 - 梯度稳定:对超长轮/异常轮做 clip 或 上限截断,防止个别极端样本主导梯度。
评测与回归
- 分维度验证集:code/math/general/安全与对齐、多轮长对话专用集。
- 专项指标:多轮下的跟进准确率、上下文聚焦率、话题切换恢复时间、引用最新轮证据的比率。
- 线上飞轮:仅纳入通过离线红线的样本;对退化指标启动回放/调采样/回滚。
四、迷你伪代码(展示统计口径,不依赖特定框架)
仅演示“每轮先做长度归一化、再做全局按轮平均”的思想。
# 假设你已经对每个样本的 label=-100 做好 mask
# 并能拿到每个“轮”的逐 token loss 向量 token_losses_i(已忽略了 -100)
turn_level_numer = 0.0 # 累计: sum_i (l_i / n_i)
turn_level_denom = 0 # 累计: 轮数 T_global
for micro_batch in loader:
# forward 得到逐 token 的 loss(不做 mean/sum)
token_losses_per_turn = model.forward_get_token_losses(micro_batch) # list of 1D tensors
mb_numer = 0.0
mb_turns = 0
for L in token_losses_per_turn:
l_i = L.sum() # 该轮总损失
n_i = L.numel() # 该轮有效 token 数
mb_numer += (l_i / n_i) # 先长度归一化,再做轮级求和
mb_turns += 1
# 把该 micro-batch 的 (mb_numer, mb_turns) 通过 DP/GradAccum 汇总
turn_level_numer += allreduce_sum(mb_numer)
turn_level_denom += allreduce_sum(mb_turns)
# 统一在优化前做一次“按轮等权”的全局平均
loss = turn_level_numer / turn_level_denom
loss.backward()
optimizer.step()
五、SFT 评估
不同于 pretrain 的评估只需要看知识能⼒,sft 的评估是需要看经典的 3H 原则的:Helpfulness、Honesty、Harmlessness,或
者按需求制定指标:指令遵循,内容准确,是否产⽣幻觉,是否安全等等。
评估的时候,每个维度有⼀个单独的得分,根据相应的加权公式来确定这条回复的可⽤性,当模型在某个 case 上的得分变低的时
候,可以⽐较直观的看出是哪个维度变差了,结合训练数据做 case 分析。
评估⽅式⽬前基本是两种:
• 机评:在利⽤ GPT4、Claude 进⾏评估的时候,prompt ⼀定要仔细设计。⼤模型的评估是有明显偏好的,对⽐评估的时候,A
和 B 倾向于选 A,⻓句⼦和短句⼦倾向于选⻓的;打分评估的时候,⼀个正确的 answer 让模型打分三次,很可能就分别是 3、
4、5 分。Alignbench 的机评 prompt 可以进⾏仿照,此外给模型⼀个参考答案很多时候能让模型的打分更准⼀些,毕竟模型会
考虑“候选 answer”和 “gold answer”的相似度来进⾏打分。
• ⼈评:字⾯意思

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 15
15 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)