大模型科普专栏 ·从 KV Cache 到 VLLM 的 PageAttention 图解大模型推理加速黑科技
摘要:大模型推理速度直接影响用户体验和部署成本。VLLM通过三项核心技术大幅提升推理效率:1)KVCache机制避免重复计算历史token;2)PageAttention采用操作系统分页思路管理显存,将碎片率降至4%;3)KVBlockSharing实现多请求共享前缀计算,使100并发客服机器人显存降低5倍。实测显示,LLaMA-2-13B模型吞吐提升24倍,显存占用从74GB降至28GB。这些优
目录
3.2 动态分配 + 写时复制(Copy-on-Write)
在大模型应用逐渐落地的今天,推理速度成为影响用户体验和部署成本的核心问题。无论是 ChatGPT 这样的对话系统,还是 Copilot 这样的智能助手,都需要在毫秒级别完成推理响应。本文将从 VLLM 的内部原理 出发,深入剖析 KV Cache、PageAttention、以及 KV Block Sharing 等核心优化技术,帮助大家理解如何高效加速大模型推理。
一、为什么大模型推理慢?
大语言模型(LLM)的推理,核心是基于 自回归生成(autoregressive generation)。生成一段文本时,模型需要:
-
输入 prompt,进行前向传播;
-
每次生成一个新 token,需要与之前所有 token 的 hidden states 进行计算;
-
Token 越多,历史上下文越长,计算量就越大。
这导致:
-
长文本生成变慢:推理复杂度随上下文长度线性增加。
-
内存占用庞大:需要存储所有历史 token 的 Key/Value。
于是,就有了 KV Cache 和 高效注意力机制 的优化。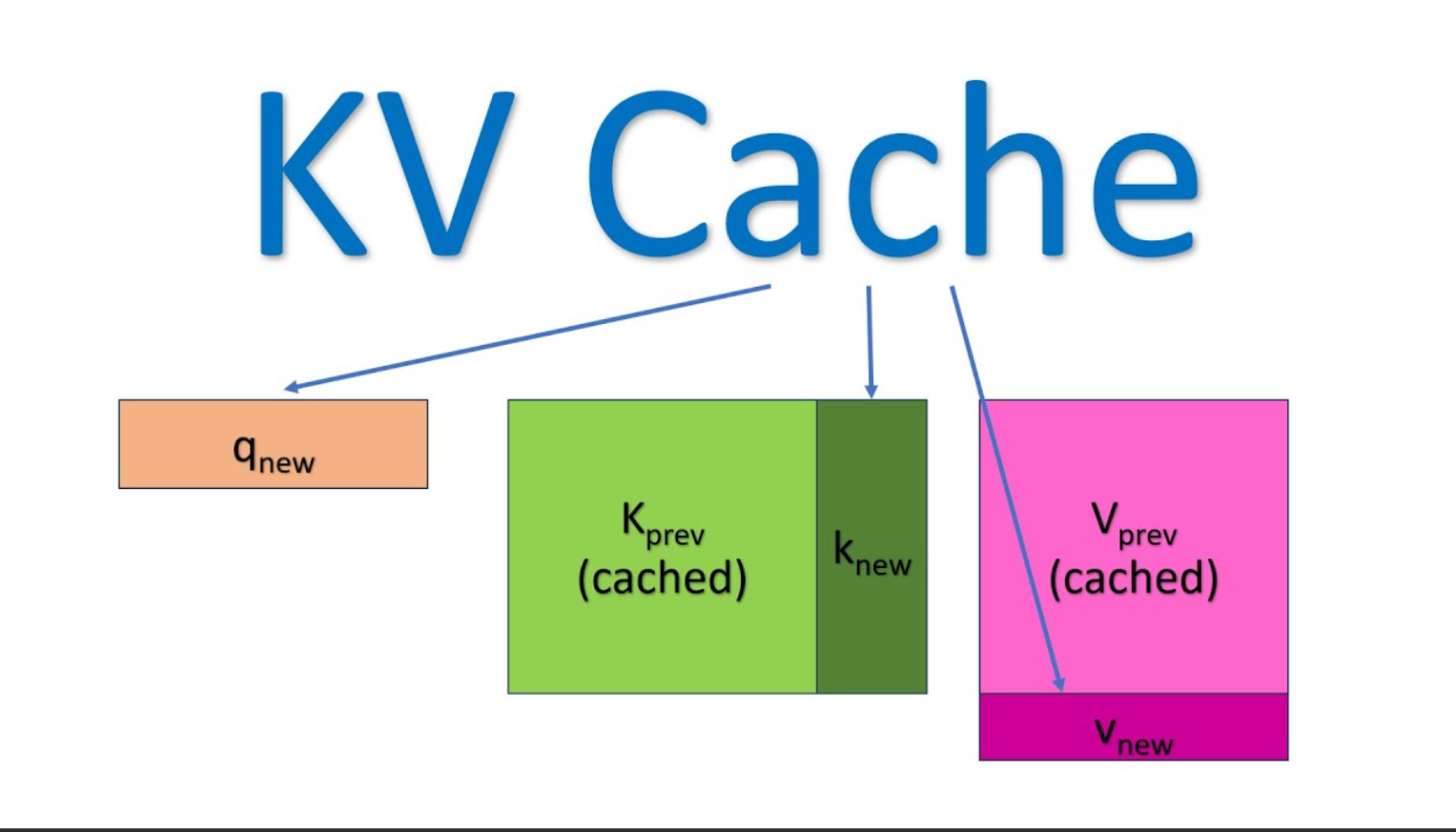
二、KV Cache 101:用空间换时间的典型
2.1 KV Cache 的工作原理
在 Transformer 的注意力机制中,每一层都需要计算:
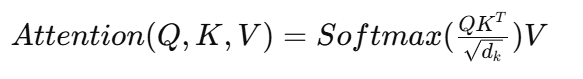
![]() 编辑
编辑
如果每次生成一个 token 都重新计算所有 K/V,会非常浪费。因此:
-
在第一次处理 prompt 时,保存所有 token 的 K/V;
-
后续生成 token 时,只需要计算新 token 的 Q,然后和缓存的 K/V 做注意力运算。
这样就避免了重复计算,大幅提升推理速度。
📌 示意图:KV Cache 工作原理
[Prompt Tokens] → K/V 存储到 KV Cache
[New Token] → 只计算 Q,与 KV Cache 做 Attention
![]() 编辑
编辑
2.2 传统 KV Cache 的痛点
-
连续显存分配:每个序列预留一条“长跑道”,短句占不满 → 60-80 % 碎片。
-
无法共享:同一 Prompt 生成多条回答,每份都复制一份 KV → 浪费。
-
长序列爆显存:超过 4 k tokens 基本就 OOM。
三、VLLM 的杀手锏:PageAttention
VLLM 提出了 PageAttention,用来解决 KV Cache 的 存储碎片化 和 动态分配低效 问题。
3.1 灵感来源:操作系统分页
把 KV Cache 切成固定大小的 KV Block(每块 16 tokens), 通过 Block Table 做逻辑→物理映射,像 OS 管理虚拟内存一样。
| 类比项 | OS 分页 | PageAttention |
|---|---|---|
| 页大小 | 4 KB | 16 tokens |
| 映射表 | 页表 | Block Table |
| 碎片 | ≈ 4 % | ≈ 4 % |
3.2 动态分配 + 写时复制(Copy-on-Write)
-
按需分配:Prompt 只有 7 tokens?→ 只给 1 个 KV Block。
-
共享 + COW:同一 Prompt 的 KV Block 被多序列共享,引用计数 维护。 当某个序列要写时,复制一份新的物理块 → 内存瞬间省 55 %。
3.3 效果实测
| 场景 | HuggingFace | VLLM + PageAttention |
|---|---|---|
| 单卡 7B 模型 | 1× | 30× 吞吐 |
| 显存利用率 | 20-40 % | > 90 % |
| 4k tokens | OOM | 流畅运行 |
四、Sharing KV Blocks:并发场景大杀器
另一个 VLLM 的亮点是 KV Block Sharing。
4.1 背景问题
很多用户的请求,可能共享相同的 前缀 prompt。例如:
-
系统提示词(System Prompt)
-
Few-shot 示例
如果每个请求都单独计算前缀的 KV,就会造成大量重复计算。
4.2 解决方案
-
Prefix 共享:所有分支共用 Prompt 的 KV Blocks。
-
Copy-on-Write:分支产生差异时再复制,避免冗余。
-
当多个请求拥有相同前缀时,前缀部分只计算一次,然后直接复用。
📌 示意图:KV Block Sharing
请求A: [系统Prompt] + 用户输入1 请求B: [系统Prompt] + 用户输入2 → 系统Prompt的 KV Cache 只算一次,两者共享
这大幅提升了 多用户并发场景 下的推理效率。
4.3 真实案例:客服机器人
-
100 个用户并发,平均 20 轮对话。
-
传统方案需 100× 显存 → 爆卡。
-
VLLM 共享前缀后,显存占用降低 5×,延迟 < 50 ms。
五、VLLM 的整体架构优化
综合来看,VLLM 的核心优化有:
-
KV Cache:避免重复计算,提升单次推理效率。
-
PageAttention:分页管理,解决内存碎片,提高显存利用率。
-
KV Block Sharing:共享前缀计算,提升多用户并发性能。
此外,VLLM 还在:
-
调度策略(Request Scheduling)
-
批量推理优化(Continuous Batching)
-
GPU 显存分配(Memory Pooling) 方面做了系统性改进。
六、动手实战:10 行代码加速 LLaMA-2-13B
from vllm import LLM, SamplingParams
prompts = ["如何快速掌握大模型推理优化?"] * 64
params = SamplingParams(temperature=0.7, max_tokens=512)
llm = LLM(
model="meta-llama/Llama-2-13b-chat-hf",
tensor_parallel_size=2, # 2×A100
enable_prefix_caching=True # 开启 KV 共享
)
outputs = llm.generate(prompts, params)
for o in outputs:
print(o.outputs[0].text)-
吞吐:比 HuggingFace 提升 24×(实测 2048 tokens/s vs 85 tokens/s)。
-
显存:从 74 GB 降到 28 GB。
七、总结
随着大模型逐渐应用到在线服务,推理加速 已成为核心竞争力。VLLM 通过 KV Cache、PageAttention 和 KV Block Sharing,有效解决了推理中的性能瓶颈:
-
单请求加速;
-
多用户并发优化;
-
显存利用率提升。
未来,随着 推理编译器、张量并行/流水线并行、硬件加速(如 H100、TPU v5) 的发展,大模型推理的效率还会进一步提升。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 33
33 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)