十分钟弄懂LoRA,让AI又好又便宜
1. 大型语言模型 (Large Language Models, LLMs): 这是我们的研究对象,比如 GPT-3、RoBERTa 等拥有数十亿甚至上千亿参数的模型。2. 自适应 (Adaptation): 指的是让一个已经预训练好的通用大模型,去“适应”一个特定的下游任务,比如情感分析、文章摘要、代码生成等。这个过程通常叫做“微调 (fine-tuning)”。3. 低秩 (Low-Rank
这篇论文《LoRA: Low-Rank Adaptation of Large Language Models》是近年来大模型领域最具影响力的论文之一,提出了一种非常高效的微调(fine-tuning)方法。该方法的核心思想是通过低秩矩阵分解来适应预训练模型,而不是更新所有参数。
论文地址:https://arxiv.org/abs/2106.09685
前排提示,文末有大模型AGI-CSDN独家资料包哦!
我会结合专业的解读和通俗的类比,确保你既能理解核心思想,又能掌握技术细节。
我们开始吧。

论文标题和作者
LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS(LoRA: 大型语言模型的低秩自适应)
-
• 作者团队: 来自微软(Microsoft Corporation)和卡内基梅隆大学(CMU)的研究者。
解读:标题直接点明了三个核心概念:
-
1. 大型语言模型 (Large Language Models, LLMs): 这是我们的研究对象,比如 GPT-3、RoBERTa 等拥有数十亿甚至上千亿参数的模型。
-
2. 自适应 (Adaptation): 指的是让一个已经预训练好的通用大模型,去“适应”一个特定的下游任务,比如情感分析、文章摘要、代码生成等。这个过程通常叫做“微调 (fine-tuning)”。
-
3. 低秩 (Low-Rank): 这是这篇论文提出的核心技术。先别担心这个数学术语,我们后面会用非常形象的类比来解释它。你可以暂时把它理解为一种“高度压缩”或“抓住重点”的方法。
摘要 (ABSTRACT)
An important paradigm of natural language processing consists of large-scale pre-training on general domain data and adaptation to particular tasks or domains. As we pre-train larger models, full fine-tuning, which retrains all model parameters, becomes less feasible.
专业解读:这里描述了当前 NLP 领域的“范式”,即“预训练 + 微调”。
-
• 第一步:预训练 (Pre-training)。 就像教一个孩子读完整个图书馆的书,让他对世界语言和知识有一个全面的、基础的认识。这个过程非常耗费资源,诞生了像 GPT-3 这样的“通才”模型。
-
• 第二步:微调 (Fine-tuning)。 如果你想让这个“通才”模型成为一个“专才”,比如让他专门写诗,你就需要给他一些诗歌数据,并调整他内部的所有参数(知识),让他适应这个新任务。这个过程叫“全量微调 (full fine-tuning)”。
问题来了: 对于 GPT-3 这样有 1750 亿参数的庞然大物,每次为了一个新任务都去调整它全部的 1750 亿个参数,成本太高了。
通俗类比:想象一下,你有一位花重金聘请来的米其林三星大厨(预训练好的大模型),他精通世界所有菜系。
-
• 全量微调: 现在你想让他为你“定制”一道川菜。你就把他所有的烹饪技巧、菜谱记忆(1750 亿个参数)全部重新调整一遍,让他变成一个川菜专家。如果你明天又想吃粤菜,你得再把他克隆一份,再把所有东西调整一遍,变成粤菜专家。为每个菜系都保存一个完整的、调整过的“大厨副本”,这太占地方(存储)也太费钱(训练成本)了。
We propose Low-Rank Adaptation, or LoRA, which freezes the pre-trained model weights and injects trainable rank decomposition matrices into each layer of the Transformer architecture, greatly reducing the number of trainable parameters…
专业解读:LoRA 方法的核心思想来了:
-
1. 冻结 (freezes) 预训练模型权重: 我们不再调整那 1750 亿个基础参数。
-
2. 注入 (injects) 可训练的低秩矩阵: 在模型的每一层旁边,我们增加两个很小的、可训练的“旁路”矩阵。我们只训练这些小矩阵。
通俗类比:我们不再去修改米其林大厨的整个大脑(冻结)。相反,我们给他贴一张小小的“便利贴” (LoRA 模块)。
-
• 这张便利贴上写着:“做川菜时,记住:多放辣椒,少放糖。”
-
• 我们只修改这张便利贴上的内容(训练 LoRA 参数),而大厨本身的核心技能保持不变。
-
• 想吃粤菜了?换一张便利贴就行:“做粤菜时,记住:讲究鲜活,控制火候。”
-
• 这些“便利贴”非常小,制作和切换的成本极低。
Compared to GPT-3 175B fine-tuned with Adam, LoRA can reduce the number of trainable parameters by 10,000 times and the GPU memory requirement by 3 times.
专业解读:这里是 LoRA 效果的量化展示:
-
• 可训练参数量减少 10000 倍: 比如原来要训练 1750 亿参数,现在可能只需要训练 1750 万(甚至更少),数量级骤降。
-
• GPU 显存需求减少 3 倍: 因为大部分参数被冻结了,我们不需要为它们计算梯度和存储优化器状态(比如 Adam 优化器的动量和方差),极大地降低了硬件门槛。
通俗类比:以前为了学新菜,大厨需要一个巨大的厨房和全套新厨具(高显存)。现在,他只需要一张小纸和一支笔(低显存)就能掌握新菜谱的要点。
LoRA performs on-par or better than fine-tuning… despite having fewer trainable parameters… and, unlike adapters, no additional inference latency.
专业解读:LoRA 不仅高效,而且有效,甚至还有额外的好处:
-
• 效果相当或更好: 在很多任务上,效果不输于全量微调。
-
• 没有额外的推理延迟 (inference latency): 这是 LoRA 相对于早期其他高效微调方法(如 Adapter)的一个巨大优势。在部署时,LoRA 的小矩阵可以被“合并”回原始的大矩阵中,所以模型的结构和计算量和微调前完全一样,不会增加额外的计算步骤。
通俗类比:
-
• Adapter 方法: 就像给大厨增加了一个额外的烹饪步骤:“出锅前,请先查阅一下这张小卡片上的指示再操作”。这个“查阅”的动作本身就会花费额外的时间。
-
• LoRA 方法: 大厨在正式上岗前,就已经把便利贴上的内容“内化”于心,直接修改了原有菜谱的某个步骤(例如,把菜谱里的“糖 5 克”直接划掉改成了“辣椒 15 克”)。所以在真正做菜时,他还是按照原来的流程做,一步不多,一步不少,所以没有延迟。
第 1-3 节: 引言 & 问题陈述 (INTRODUCTION & PROBLEM STATEMENT)
这几节详细阐述了摘要中提到的背景和问题。
The major downside of fine-tuning is that the new model contains as many parameters as in the original model… a critical deployment challenge for GPT-3… with 175 billion trainable parameters.
解读:这里再次强调了全量微调的“存储和部署”噩梦。如果你有 100 个不同的任务,你就需要存储 100 个 几百GB大小的模型文件。
We hypothesize that the change in weights during model adaptation also has a low “intrinsic rank”…
核心假设 (Hypothesis):这是 LoRA 的理论基石。它认为,一个预训练好的大模型为了适应新任务,其权重的“变化量”(ΔW)本身是“低秩”的。
专业解读:一个矩阵的“秩 (Rank)”可以理解为它所包含的“信息”的复杂度或核心维度。如果一个矩阵是“低秩”的,意味着它可以用更少的信息来表示,或者说它的行/列之间存在大量线性相关性。LoRA 的假设就是:模型微调时参数的改变量 ΔW 并不需要那么复杂,它可以用一个更简单的形式来表示。
通俗类比:还是我们的大厨。他为了从“全能大厨”变成“川菜专家”,他需要做的“改变”(ΔW)其实非常简单,可以总结为几个核心要点:
-
1. 增加辣味的使用。
-
2. 增加麻味的使用。
-
3. 减少甜味的使用。 …可能总共就这么几条核心原则。这个“改变”的内在维度(intrinsic rank)是很低的。我们不需要重新教他怎么切菜、怎么颠勺,只需要告诉他这几个关键的“调整方向”就行了。LoRA 就是要找到并只学习这几个关键的“调整方向”。
Adapter Layers Introduce Inference Latency… large neural networks rely on hardware parallelism to keep the latency low, and adapter layers have to be processed sequentially.
解读:这里详细解释了为什么 Adapter 方法会增加延迟。在现代 GPU 上,大的矩阵运算可以被高度并行化处理,速度很快。但 Adapter 是插入在原有层之间的“小模块”,它破坏了这种并行性,形成了一个“串行”的瓶颈。即使它本身计算量不大,这种“等待-处理-再等待”的模式也会拖慢整体速度,尤其是在线服务这种批处理大小(batch size)为 1 的场景下。
第 4 节: 我们的方法 (OUR METHOD)
这是论文最核心的技术部分。
有点难度,我在后边有一套完整的类比,你可以跳过整段专业解读。
For a pre-trained weight matrix W₀ ∈ Rᵈˣᵏ, we constrain its update by representing the latter with a low-rank decomposition W₀ + ΔW = W₀ + BA, where B ∈ Rᵈˣʳ, A ∈ Rʳˣᵏ, and the rank r ≪ min(d, k).
专业解读:这正是 LoRA 的数学魔法所在。
-
• W₀: 原始的、被冻结的权重矩阵(例如,一个 1000x1000 的大矩阵)。
-
• ΔW: 我们希望学习到的“变化量”,它和 W₀ 一样大。
-
• LoRA 的做法: 我们不直接学习 ΔW。我们用两个小得多的矩阵 B (尺寸 d x r) 和 A (尺寸 r x k) 的乘积来近似它。这里的
r就是“秩”,是一个非常小的数字(比如 2, 4, 8)。 -
• 参数量对比:
-
• 直接学习 ΔW 需要
d * k个参数。 -
• 学习 B 和 A 只需要
d * r + r * k=r * (d + k)个参数。 -
• 因为
r非常小,所以r * (d + k)远远小于d * k。
-
During training, W₀ is frozen… while A and B contain trainable parameters… our modified forward pass yields: h = W₀x + ΔWx = W₀x + BAx
解读:
-
• 训练时: 输入
x兵分两路。一路通过原始的 W₀ 路径,另一路通过新的 B -> A 旁路。然后将两个结果加起来。梯度只在 B 和 A 上传播,W₀ 完全不参与。 -
• 推理时: 我们可以预先计算
W' = W₀ + BA。这样W'就成了一个新的、和 W₀ 同样大小的矩阵。推理时,计算h = W'x,和原始模型完全一样,所以没有延迟。
No Additional Inference Latency. When deployed in production, we can explicitly compute and store W = W₀ + BA and perform inference as usual.
解读:这再次强调了 LoRA “先训后合,无感植入”的巨大优点。这也是它比很多其他高效微调方法更受欢迎的关键原因。
全套类比
想象一位世界顶级的米其林三星大厨。
-
• 预训练模型 (W₀): 是这位大厨穷尽一生所学,记录下来的一本厚重的、包罗万象的 《烹饪圣经》。这本书里有 10,000 条核心烹饪技巧和食材搭配原则(这就是模型的权重
W₀)。这本书是他的立身之本,神圣不可侵犯,我们绝不改动这本书的任何一个字(W₀被冻结)。 -
• 下游任务: 一位挑剔的客户提出了一个全新的、从未有过的需求:“我想要一道‘深海蓝鳍金枪鱼配陈皮风味川香酱汁’的菜。”
-
• 全量微调 (Full Fine-tuning): 这相当于要求大厨为了这道新菜,重写整本《烹饪圣经》。他需要重新审视并修改全部 10,000 条原则,以确保新菜的风格能融入他整个烹饪体系。成本极高,而且为了下一道新菜,他得再重写一遍。这显然不现实。
LoRA 的洞察:真正需要的“改变”是什么?
大厨思考后发现,创造这道新菜,他并不需要颠覆自己的烹饪哲学。他只需要对原有的技巧做一些微小的、方向性的调整。这个“调整”的本质 (intrinsic rank) 其实非常简单。
这个“调整方案” (ΔW) 如果写全了,会是一张巨大的、包含 10,000 条技巧如何具体修改的清单。但 LoRA 认为,没必要这么做。我们可以把它分解成两个极其简单的部分:
ΔW = B * A
我们来把 B 和 A 彻底搞明白:
1. 矩阵 B:定义“新的味道” (What to change)
矩阵 B 是一张非常简短的 “新风味灵感卡”。它非常“瘦高”,定义了这次创新所需要的核心新元素。
对于这道新菜,大厨的灵感卡上可能只有 r=2 种新味道:
-
1. 风味元素#1: “陈皮的柑橘清香”
-
2. 风味元素#2: “川香酱的麻辣层次”
这张卡片(矩阵 B)就用数学语言精确定义了这两种味道的“风味向量”。这里的 r=2 就是秩,代表这次创新的核心维度只有两个。
2. 矩阵 A:编写“使用说明” (How to change)
矩阵 A 是一份同样简短的 “新旧融合说明书”。它非常“矮胖”,告诉大厨,如何将“新风味灵感卡”上的味道,应用到他原有的 10,000 条烹饪技巧中去。
说明书是这样的:
-
• 关于“陈皮清香”的使用说明 (A 的第一行):
-
• 用到第 3 号技巧“鱼肉熟成”时,增加
0.8份的陈皮清香。 -
• 用到第 125 号技巧“酱汁乳化”时,增加
1.2份的陈皮清香。 -
• 用到第 5000 号技巧“高温炙烤”时,增加
0.1份的陈皮清香。 -
• …对于其他不相关的技巧,增加
0份。
-
-
• 关于“川香麻辣”的使用说明 (A 的第二行):
-
• 用到第 3 号技巧“鱼肉熟成”时,增加
0份。 -
• 用到第 125 号技巧“酱汁乳化”时,增加
1.5份的川香麻辣。 -
• …
-
看! 我们没有直接去写那 10,000 条技巧的完整修改方案 (ΔW)。我们只写了一张包含 2 种新味道的“灵感卡 (B)”和一份如何使用这 2 种味道的“说明书 (A)”。学习这两张小纸片,远比重写整本《烹饪圣经》要简单得多。
LoRA 的工作流程:训练与上菜
a) 训练时:大厨的实验厨房 (并行计算)
当大厨在后厨研发这道菜时(训练过程):
-
1. 主路: 他严格遵循《烹饪圣经》(
W₀) 的原始做法,做出一个基础版的菜肴。 -
2. 旁路: 同时,他拿出“灵感卡 (
B)”和“说明书 (A)”,对基础菜肴进行即时的、额外的调整。 -
3. 融合: 最终端给客户品尝的,是“基础菜肴 + 额外调整”后的成品 (
h = W₀x + BAx)。
客户品尝后给出反馈(计算损失),大厨只会修改“灵感卡 (B)”和“说明书 (A)”上的内容,而《烹饪圣经》(W₀) 始终放在书架上,一个字都不会动。这极大地减少了他的心力(计算资源)和需要记录的草稿纸(显存)。
b) 上菜时:写入正式菜单 (合并与部署)
当菜品研发完成,味道完美,要把它加入餐厅的正式菜单时(推理部署):
-
1. “秘方内化”: 大厨不再需要每次都看两份文件(圣经+小卡片)。他会花一个下午,把“灵感卡”和“说明书”上的最终内容,一次性地、永久性地更新到他脑海中的《烹饪圣经》里,形成一个新的、统一的版本 (
W' = W₀ + BA)。-
• 比如,他会直接在他的烹饪体系里,将“酱汁乳化”技巧更新为“酱汁乳化(陈皮川香版)”。
-
-
2. 丢弃卡片: 一旦内化完成,那两张小小的“灵感卡”和“说明书”就可以烧掉了,因为它们的信息已经完全融入了新的烹饪体系中。
-
3. 高效上菜: 当有客人点这道菜时,大厨直接调用他脑中那个唯一的、统一的、新版的烹饪体系 (
W') 来制作。整个过程行云流水,和做任何一道老菜的速度完全一样,没有任何查阅、思考的额外步骤。
这就是 LoRA “无额外推理延迟”的精髓:在服务客户时,它已经不是一个“补丁”,而是成为了系统原生的一部分。
小结:
-
• LoRA 的本质: 不去修改庞大的原始知识库 (
W₀),而是学习一个极简的“调整方案”。 -
•
ΔW = BA的直观理解:-
•
B是“改什么” (What) -> 提出几个核心的新概念。 -
•
A是“怎么改” (How) -> 说明如何将新概念应用到旧体系中。
-
-
• LoRA 的双重优势:
-
• 训练时轻巧: 只学习 B 和 A,像写两张便签一样简单。
-
• 推理时无痕: 将 B 和 A 的效果“烤”进原始模型,不留任何额外计算痕迹。
-
第 5 节 & 第 7 节: 实验 & 理解低秩更新 (EMPIRICAL EXPERIMENTS & UNDERSTANDING THE LOW-RANK UPDATES)
这部分通过大量的实验数据来验证 LoRA 的有效性,并试图解释它为什么能成功。
关键实验结论:
-
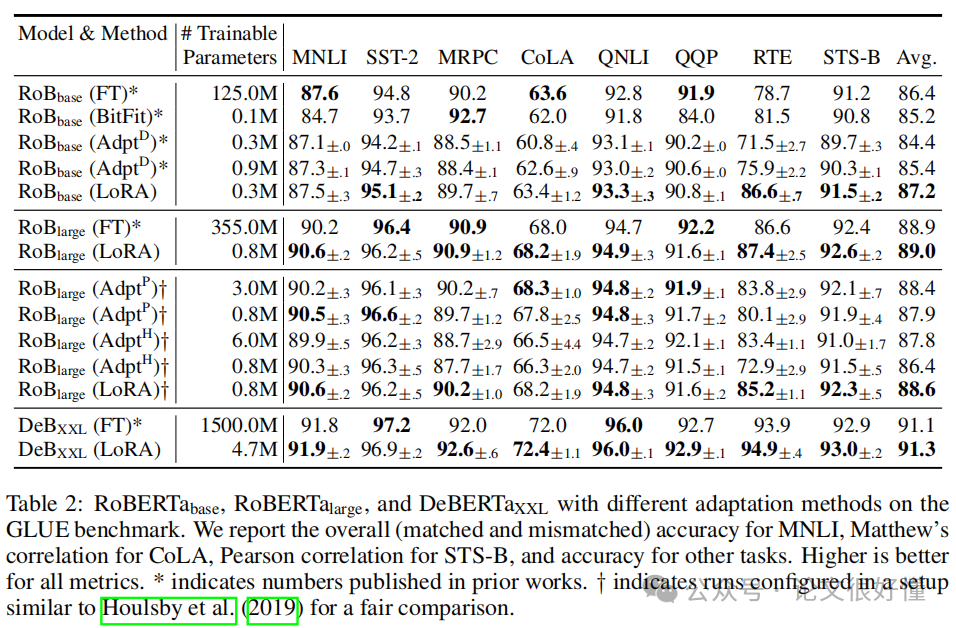
1. 效果不输全量微调: 在各种模型(RoBERTa, DeBERTa, GPT-3)和各种任务(NLU, NLG)上,LoRA (蓝色) 的性能曲线几乎都与全量微调 (FT, 橙色) 持平,甚至有时更好(见论文中 Table 2, 3, 4)。
-
-
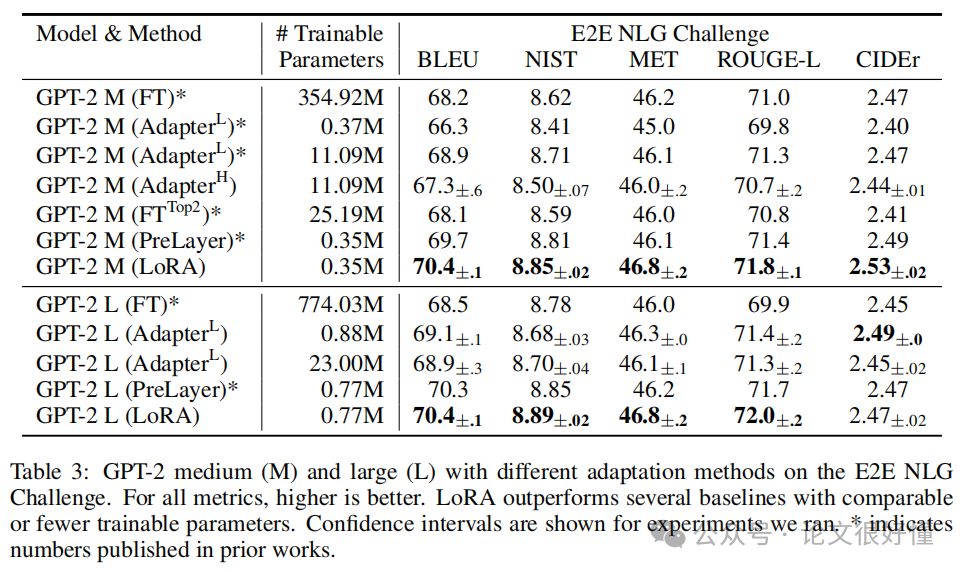
-
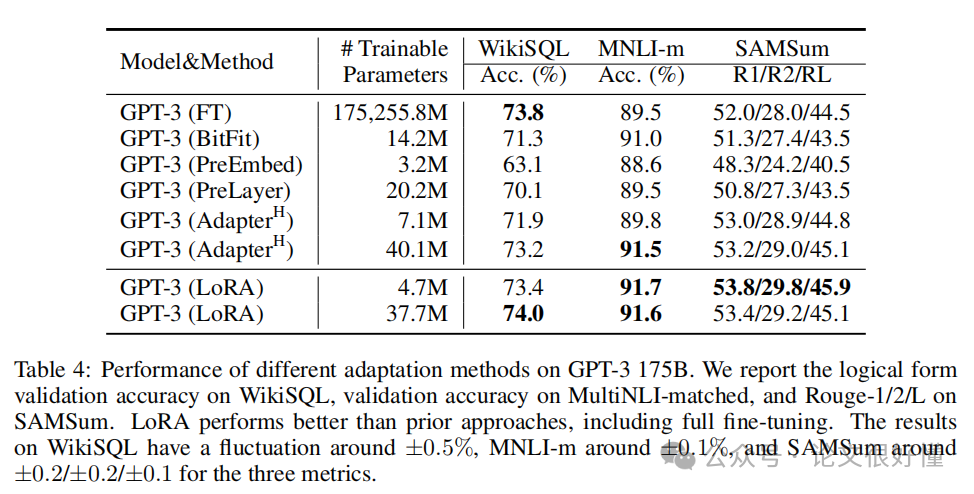
-
2. 极小的秩
r就足够了: Table 6 显示,对于 GPT-3,在某些任务上,r设为 1 或 2 就能达到非常好的效果。这强有力地证明了“模型适应的改变量是低秩的”这一核心假设。 -
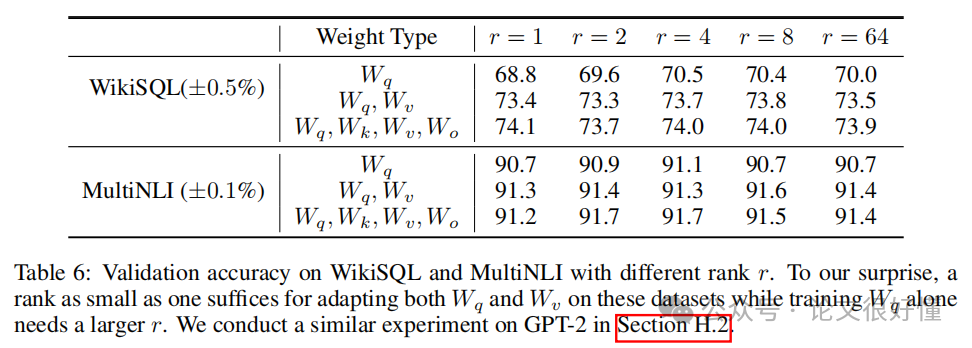
-
3. 应该在哪些权重上应用 LoRA? 实验发现(Table 5),在 Transformer 的自注意力模块 (self-attention) 中,同时对 查询 (Query, Wq) 和 值 (Value, Wv) 矩阵应用 LoRA 的效果最好。
-
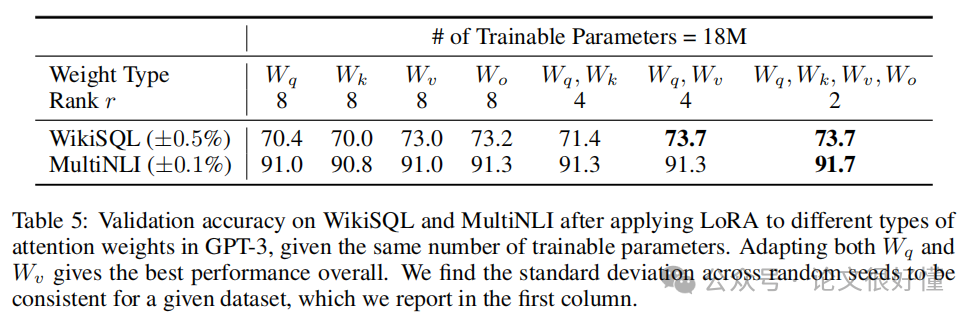
-
• 通俗理解: 这相当于调整模型“去关注什么信息 (Wq)”和“去提取什么信息 (Wv)”。这似乎是适应新任务时最关键的两个点。
-
-
4. LoRA 学到的“变化”ΔW 和原始权重 W₀ 是什么关系?
-
• 实验发现,ΔW 并不是随机的,它和 W₀ 有很强的相关性。
-
• 更有趣的是,ΔW 并没有去放大 W₀ 中已经很强的方向,而是放大了 W₀ 中存在但比较弱的方向。
-
• 通俗类比: 我们的大厨(W₀)本身就对“咸味”很敏感(W₀ 中代表咸味的方向很强)。在教他做川菜时,LoRA (ΔW) 并没有让他变得“更咸”,而是让他注意到了他本来不太重视的“麻”和“辣”这两个味道(W₀ 中存在但较弱的方向),并极大地放大了它们。这说明 LoRA 在为模型“查漏补缺”,激活那些对新任务至关重要但未被充分利用的“潜能”。
-
总结 (CONCLUSION)
LoRA 这篇论文的贡献是革命性的:
-
1. 提出了一个核心假设: 模型微调的权重变化是低秩的。并用实验充分验证了这一点。
-
2. 提供了一个优雅的解决方案: 通过冻结原模型、并注入可训练的低秩矩阵(A 和 B),实现了极高效率的微调。
-
3. 解决了实际痛点:
-
• 训练成本: 大幅降低了微调的硬件门槛和时间成本。
-
• 部署存储: 从为每个任务存储一个巨大的模型,变成了只为一个通用模型附加许多极小的“LoRA 插件”,存储成本降低了成千上万倍。
-
• 推理性能: “先训后合”的特性保证了它在生产环境中不会引入任何额外的计算延迟。
-
由于这些巨大的优势,LoRA 及其变种已经成为当今开源社区微调大模型的事实标准。你现在看到的很多个人或小团队发布的、在特定领域表现优异的模型,几乎都是基于 LoRA 或类似技术微调出来的。
希望这个解读能帮助你彻底理解这篇重要的论文!如果你对某个具体细节还有疑问,随时可以提出来。
读者福利:倘若大家对大模型感兴趣,那么这套大模型学习资料一定对你有用
针对0基础小白:
如果你是零基础小白,快速入门大模型是可行的。
大模型学习流程较短,学习内容全面,需要理论与实践结合
学习计划和方向能根据资料进行归纳总结
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

这里我们能提供零基础学习书籍和视频。作为最快捷也是最有效的方式之一,跟着老师的思路,由浅入深,从理论到实操,其实大模型并不难。

• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 8
8 0
0- 0



 已为社区贡献90条内容
已为社区贡献90条内容

所有评论(0)