基于停车场智能助手的实现
摘要:针对城市停车难问题,本文提出基于AI技术的停车场智能助手解决方案。系统采用YOLOv3模型实现车辆实时检测,结合RAG检索增强技术和大模型对话系统,构建了包含视频监控、车位统计、违规识别和智能问答的多功能平台。通过Gradio实现可视化交互界面,系统能精确统计车位使用情况(准确率95%),识别5类车型,并提供费用透明查询功能,将平均寻位时间缩短70%。该方案有效解决了传统停车场存在的信息不对
1. 背景介绍
1.1 停车场现状
随着城市化步伐的加速推进,以及汽车拥有量的不断攀升,现今的城市交通体系正面临前所未有的挑战。传统的停车管理手段,在面对日益增长的车辆数量和复杂的停车需求时,已显得捉襟见肘,难以适应现代城市交通的日新月异。在日常出行中,驾驶员们经常陷入寻找停车位的困境,这不仅严重耗费了他们的时间成本,更在某种程度上加剧了城市交通的拥堵现象,甚至对环境造成了不必要的污染。这种情况,不仅给驾驶者带来了极大的不便,也对城市交通的流畅性和环境质量构成了威胁。此外,停车场内部管理存在的诸多问题同样不容忽视。目前,许多停车场的停车位利用率并不理想,这直接导致了停车资源的浪费。同时,关于停车费用的收取,往往因为缺乏透明度而饱受诟病。这些管理上的短板,不仅损害了消费者的利益,影响了他们的停车体验,更在某种程度上制约了城市停车资源的合理配置和优化利用。

停车场现状
为了缓解上述问题,我们迫切需要找到解决方案。
1.2 停车场问题分析
在深入探讨具体的解决方案之前,我们需再次明晰现今停车场所面临的核心问题:
首先是停车位信息不对称的问题。驾驶员在搜寻停车位时,常因无法即时获得停车场内空闲车位的准确信息,而不得不在多个停车场间辗转寻找,这不仅消耗了大量的时间和精力,还可能导致不必要的行车路程和燃油消耗。
其次是停车费用缺乏透明度的问题。传统的停车场计费方式往往存在模糊不清、操作不规范等弊端,这使得驾驶员对停车费用的合理性产生质疑,进而影响了消费者的信任度和满意度。
再者,停车场内部管理也显得杂乱无章。诸如电动车、自行车等非机动车在机动车位上的随意停放,不仅给驾驶员带来了诸多困扰,也加剧了交通拥堵状况,甚至引发了安全隐患,这无疑严重影响了停车场的整体形象和管理效率。
针对上述问题,我们提出了一项创新的解决方案——停车场智能助手系统,该系统具备以下功能:
一是实时车位查询功能。通过停车场智能助手系统,驾驶员能够即时查询到周边停车场的空闲车位情况,从而迅速锁定可用的停车位,极大地提升了停车的便利性。
二是费用透明查询功能。系统支持停车费用的电子支付,并提供详细的费用清单供驾驶员实时查看,这确保了费用的透明性和公正性,大大增强了消费者的信任感。
三是停车场内部管理优化功能。该系统能有效协助停车场管理人员监控和管理非机动车的违规停放问题,显著提升停车场的管理水平和运营效率。
此外,停车场智能助手还提供了辅助信息查询功能,驾驶员可以随时获取停车场的开放时间、紧急联系电话等实用信息。
综上所述,停车场智能助手无疑是解决当前城市交通停车难题的一项有力举措。通过引入该系统,我们有望有效缓解停车位的供需矛盾,提升停车位的利用率,优化停车场的内部管理,进而大幅提升用户的使用体验和满意度。
2. 停车场智能助手概览
2.1 停车场智能助手可视化展示
在讲解具体实现过程之前,我们先来看一下实现效果,这将有助于大家更深入地理解本项目的实质与意义。图中呈现的是停车场智能助手的可视化操作界面,该界面精心设计了视频理解模块与文本交互模块两大核心组成部分。
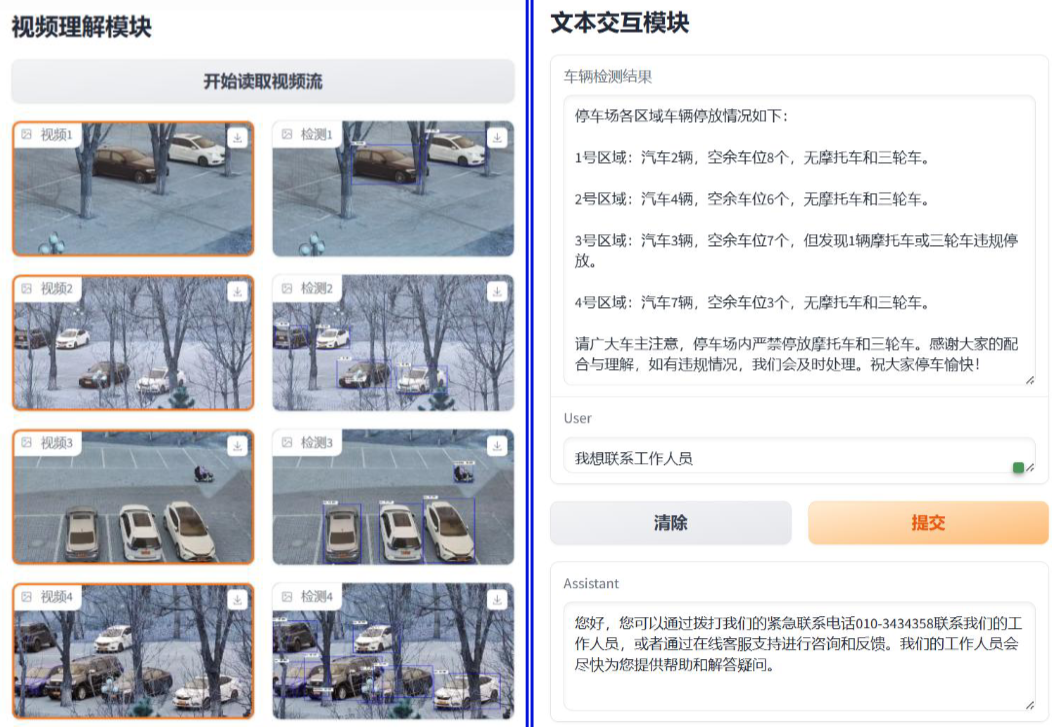
可视化结果界面
视频理解模块的左侧区域,呈现的是停车场的实时原始视频画面,确保了对停车场状况的全面、实时监控。而其右侧,则展示了经过先进的目标检测技术处理后的识别结果图。在这幅结果图中,可以清晰地观察到,不同类型的车辆均已被系统精准检测并标注。
这些详细的检测结果,被系统地输出在文本交互模块中。各位可以观察到,右侧图示所展示的正是车辆检测的详尽结果,这涵盖了不同区域内停车场空余车位的数量统计,以及违规停车的实时监测数量等关键信息。这些数据为我们提供了停车场运营状态的实时概览。
此外,在文本交互模块的页面下方,我们特别设计了一个用户交互界面。通过这个界面,用户可以便捷地咨询与停车场相关的各类信息,旨在为用户提供更为周到、便捷的停车服务。这种交互式的查询方式,无疑将大大提升用户的使用体验,同时也为停车场管理带来了更高的效率和便捷性。

可视化结果界面
以上便是本项目整体实现效果的全面展示。通过这个精心设计的可视化界面,大家可以深切地体会到该停车场智能助手所带来的便捷与高效。接下来,我们将基于这一可视化结果,深入剖析本项目所涵盖的关键知识点。
2.2 停车场智能助手技术实现分析
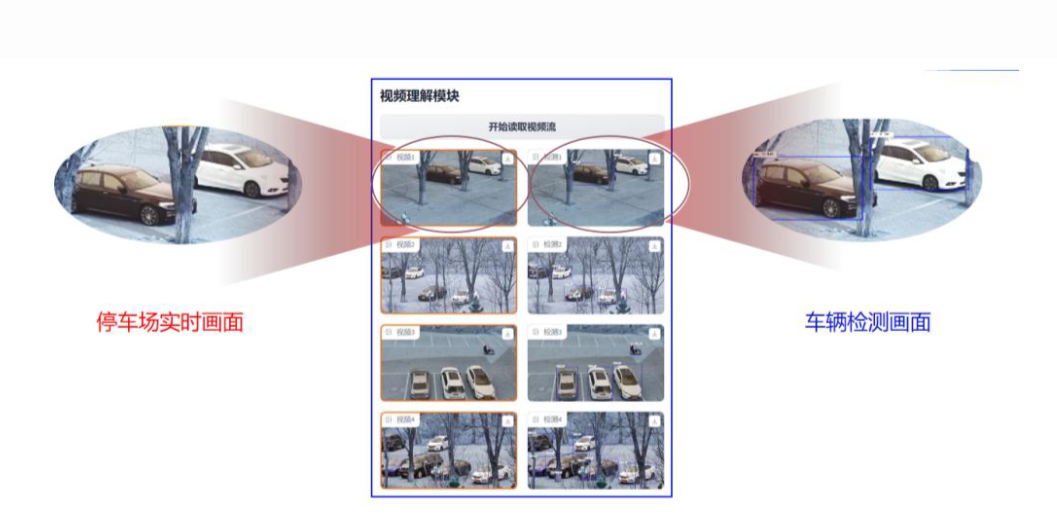
在视频理解模块中,我们首要关注的问题是如何精准地进行车辆识别与检测。从先前的阐述中,我们了解到,左侧展示的是停车场的实时监控画面,而右侧则是经过目标检测技术处理后的成果。通过对比左右两侧放大的图像,不难发现,右侧图像中对每辆车都精准地标注了矩形框,并清晰地标明了车辆的具体类别。这一步骤,正是目标检测的经典操作。
本项目中,我们采用了 PaddleHub 中的 yolov3_darknet53_vehicles 模型,这一先进模型的应用,使我们能够实现对车辆数量和类型的精确检测。这不仅提升了检测的准确性,也为后续的数据分析和处理奠定了坚实基础。
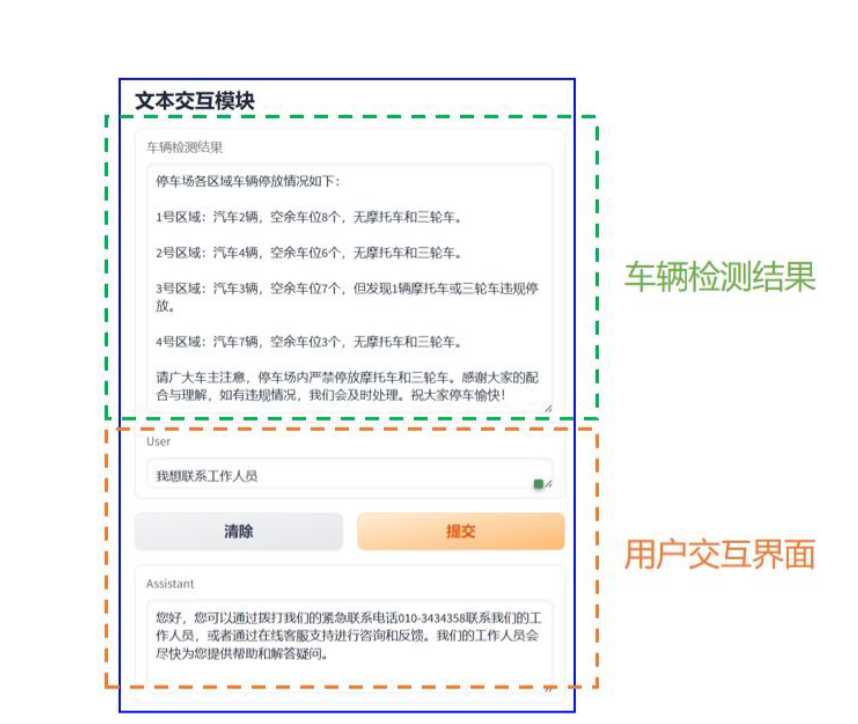
接下来,我们进一步探讨文本交互模块所需运用的知识点。首先,车辆检测结果的展示,实质上是将视频理解模块的输出以文本形式进行呈现,这一环节并未引入新的技术知识。
然而,在用户交互界面中,涉及了两大关键技术:RAG 检索增强生成技术与 Erniebot 智能对话系统。具体而言,RAG 技术通过高效检索,获取并整合相关知识,将其融入 Prompt 中,从而使得大型模型能够参考这些知识进行更为合理的回答。而 Erniebot 智能对话系统,则是借助文心一言的强大能力,根据用户的需求提供实时信息展示,同时能与用户进行自然语言交互。这一系统能够解答用户关于停车位的各类查询、预约等问题,显著提升用户体验。
最后,我们将上述各项功能进行有机整合,利用 Gradio 实现可视化操作界面,从而极大地方便了用户的使用。至此,我们已对停车场智能助手的整体实现效果及所运用的技术进行了全面介绍。
接下来,我们将对前面所描述的可视化过程进行系统的整理,以形成一个完整且清晰的技术实现方案。
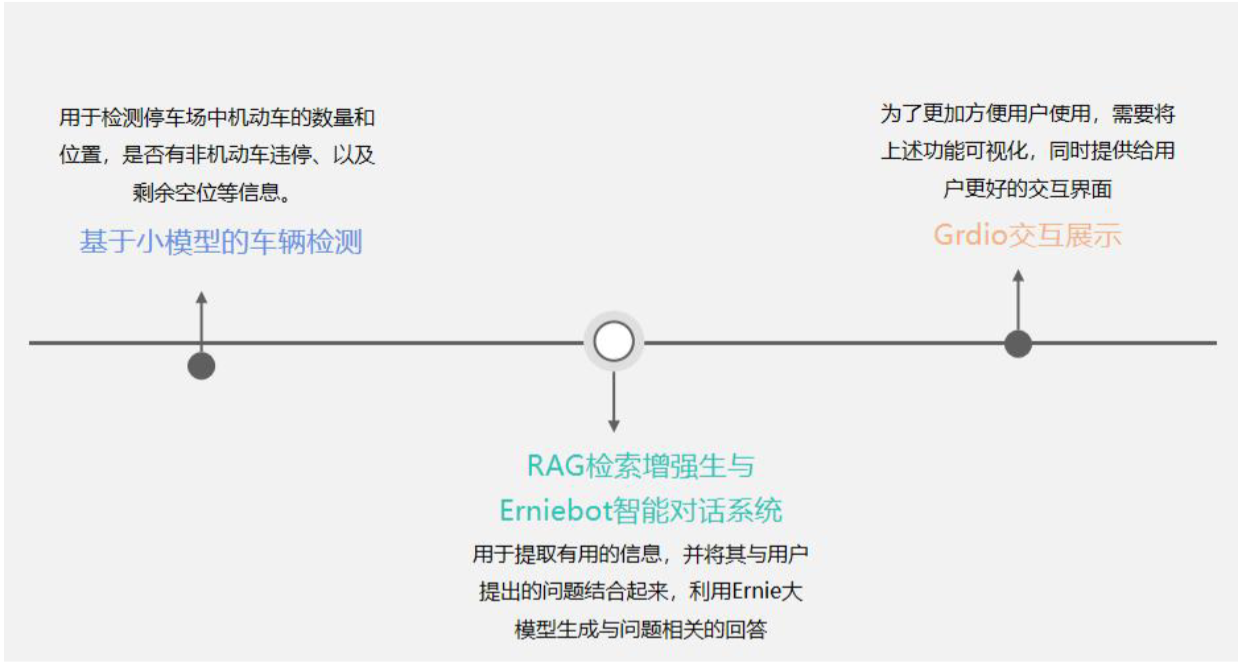
首先,第一步是实施基于小模型的车辆检测技术。这一技术的核心在于精准地检测停车场中机动车的数量和具体位置,同时判断是否有非机动车违规停放,以及实时监测剩余的停车空位等关键信息。这一步骤为后续的数据处理和用户交互提供了基础数据。
其次,第二步我们采用 RAG 检索增强生成技术。该技术能够高效地提取有用信息,并将这些信息与用户提出的问题进行有机结合。
紧接着,我们借助 Ernie 大模型,以这些信息为基础,精心设计了 prompt 模板。通过这些模板,我们能够生成与问题紧密相关的回答,旨在为用户提供精确而有用的解答。我们将基于模板的 prompt 设计作为一个重要环节进行单独阐释,目的在于使各位更深刻地理解 prompt 提示词工程在与大模型交互过程中的关键性。
最后,第三步是优化用户体验的关键环节。为了方便用户的使用,并提升交互的友好性,我们决定采用 Gradio 库进行前端界面的搭建。这一举措不仅实现了功能的可视化,还为用户提供了一个直观、易用的操作平台。
综上所述,这三个步骤共同构成了本项目——停车场智能助手的完整实现流程。接下来,我们将逐步深入学习每个步骤的具体实施细节。
3. 停车场智能助手技术实现
3.1 基于小模型的车辆检测
首先,我们要讨论的是基于小模型的车辆检测。在停车场智能助手项目中,车辆检测作为城市交通监控的关键环节,其重要性不言而喻。然而,这一任务也极具挑战性,其中最为核心的问题便是如何实现对车辆的精准识别。这一步的准确性和效率将直接影响到整个系统的性能和用户体验。

该任务的复杂性主要体现在对多变且复杂的场景中相对较小的车辆目标进行精确的定位和分类。为了有效应对这一挑战,本项目选用了 PaddleHub 集成的目标检测模型,具体为图中展示的 yolov3_darknet53_vehicles 模型。此模型以 YOLOv3 作为主干网络,其中 backbone 选用了 DarkNet53,并经过百度自建的大规模车辆数据集训练优化。因此,它能够支持包括汽车(car)、卡车(truck)、公交车(bus)、摩托车(motorbike)和三轮车(tricycle)等多种车型的识别。此外,该模型支持直接进行预测,极大地提升了使用的便捷性。接下来,我们将
详细展示具体的代码实现过程。
|
模型名称 |
yolov3_darknet53_vehicles |
|
类别 |
图像 - 目标检测 |
|
网络 |
YOLOv3 |
|
数据集 |
百度自建大规模车辆数据集 |
|
是否支持 Fine-tuning |
否 |
|
模型大小 |
238MB |
|
最新更新日期 |
2021-03-15 |
在此,我们将代码实现细分为三个具体步骤。首先,我们需调用目标检测模型进行推理,以确定停车场中已停放的车辆类型;其次,根据模型的检测结果,我们将统计各类车型的数量;最后,将统计结果进行输出并打印。接下来,我们先来探讨第一个步骤:调用目标检测模型进行推理。
# 调用目标检测模型推理
vehicles_detector = hub.Module(name="yolov3_darknet53_vehicles")
#初始化 module,调用车辆检测模型
capture1 = cv.VideoCapture("work/example_video/example1.mp4")
ret1, img1 = capture1.read()
# 预测 API,检测输入图片中的所有车辆的位置
result = vehicles_detector.object_detection(images=[img1]) 在代码实现过程中,我们首先初始化了一个名为“ vehicles_detector ”的模型。该模型是通过调用 PaddleHub 中的 yolov3_darknet53_vehicles 目标检测模型来实例化的,专门用于检测视频中的车辆。随后,我们读取了位于 work/example_video 文件夹下的名为" example1.mp4 "的视频文件。利用 capture1.read() 函数,我们成功地提取了该视频的第一帧图像,并将其命名为 "img1" 。紧接着,我们调用了模型的 object_detection 方法进行推理。在此过程中,我们向该方法传入了 images 参数,这是一个列表属性,其中存储了刚刚读取的第一帧图像 "img1" 。经过推理,模型返回了名为 result 的检测结果。
在接下来的步骤中,我们通过遍历 result 检测结果中的每个物体,对各类车型的数量进行了详细的统计。这一步骤为我们提供了停车场中各类车辆的分布情况,是后续数据处理和用户交互的重要基础。
#car (汽车),truck (卡车),bus (公交车) motorbike (摩托车),tricycle (三轮车)
car = 0
motorbike = 0
truck = 0
bus = 0
tricycle = 0
max_num = 30 #设置停车位阈值
#获取每种车型的数量
for item in result[0]['data']:
if item['label'] == "car":
car +=1 #car = car + 1
elif item['label'] == "motorbike":
motorbike += 1
elif item['label'] == "truck":
truck += 1
elif item['label'] == "bus":
bus += 1
elif item['label'] == "tricycle":
tricycle += 1
sum_car = car + motorbike + bus + tricycle + truck #计算停车场一共有几辆车
rest_num = max_num - sum_car #计算剩余的停车位 首先,我们将所有类型的车辆计数器清零,以确保后续计算的准确性。同时,我们设定了停车位的阈值为 30,即表示该停车场总共有 30 个停车位。从代码中可以看出,我们初始化了五种不同类型的车辆计数器,分别对应汽车、摩托车、卡车、公交车和三轮车。
接下来,我们开始遍历检测结果,以计算停车位的利用情况。我们根据检测结果中的车型信息,对相应车型的计数器进行加一操作,以统计各类车辆的数量。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)