基于开发者空间GaussDB完成AI智能索引和参数自调优实践
本文介绍了华为云开发者空间提供的GaussDB云数据库AI特性实践案例。案例展示了如何利用GaussDB的AI功能实现智能索引推荐和参数自调优,包括单条SQL索引推荐、虚拟索引和工作负载索引推荐等功能。通过鲲鹏CPU与GaussDB的架构融合,结合昇腾AI芯片加速技术,实现数据库内AI训练与推理。案例面向企业、个人开发者和高校学生,提供30分钟的实践体验,涵盖数据库领取、登录和AI特性功能使用等操
1 概述
1.1 案例介绍
ORACLE公司提出让数据库自动化运维,即数据库中常见的问题,且存在统一规范的处理解决方案的场景,应该让数据库在检测到此类问题自动处理解决,以减少运维工作人员人力的参与(因为Oracle的运维人力相对昂贵)。
通过实际操作,让大家深入了解如何利用 GaussDB开发并优化项目中业务应用的SQL语句等功能。在这个过程中,大家将学习到从AI函数的引用、AI功能的原理以及分析AI能力等一系列关键步骤,从而掌握 GaussDB-AI的基本使用方法,体验其在应用开发中的优势。
1.2 适用对象
- 企业
- 个人开发者
- 高校学生
1.3 案例时间
本案例总时长预计30分钟。
1.4 案例流程
说明:
- 领取华为云开发者空间GaussDB云数据库;
- 在云数据库GaussDB,通过DAS工具登录并进入SQL界面;
- 在SQL界面进行GaussDB数据库之AI特性功能使用;
1.5 资源总览
| 资源名称 | 规格 | 单价(元) | 时长(分钟) |
|---|---|---|---|
| 开发者空间-云数据库GaussDB | 鲲鹏通用计算增强型 kc1 | 2vCPUs | 4G | HCE2.0 | 免费 | 30 |
详细案例操作请阅读👉️👉️👉️基于开发者空间GaussDB完成AI智能索引和参数自调优实践
2 鲲鹏和GaussDB架构融合与AI特性
2.1 开发者空间云数据库GaussDB的领取与登录
面向广大开发者群体,华为开发者空间提供一个生态版的GaussDB云数据库,可快速体验华为根技术和资源。
关于开发者空间云数据库GaussDB的领取和开通,参考如下案例内容。链接如下:
华为开发者空间-GaussDB云数据库领取与实践
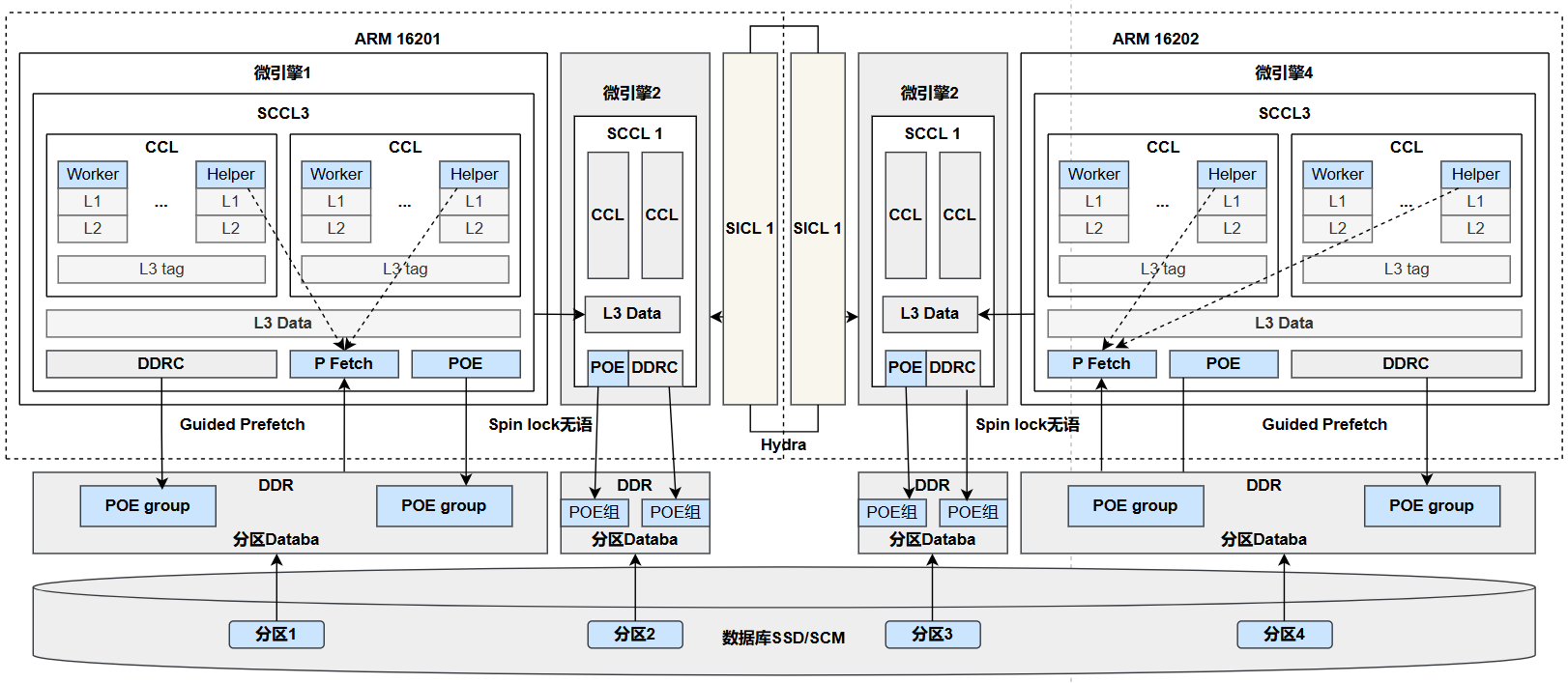
2.2 鲲鹏CPU与GaussDB面临的问题
-
事务处理时锁冲突的比例会大幅增加。
-
事务处理的时延将在比较大的范围内波动,无法很好地满足面向客户的SLA。
-
处理器内部以及处理器核间通信能力提供了新的线程间同步机制。
面向鲲鹏处理器的GaussDB系统的架构
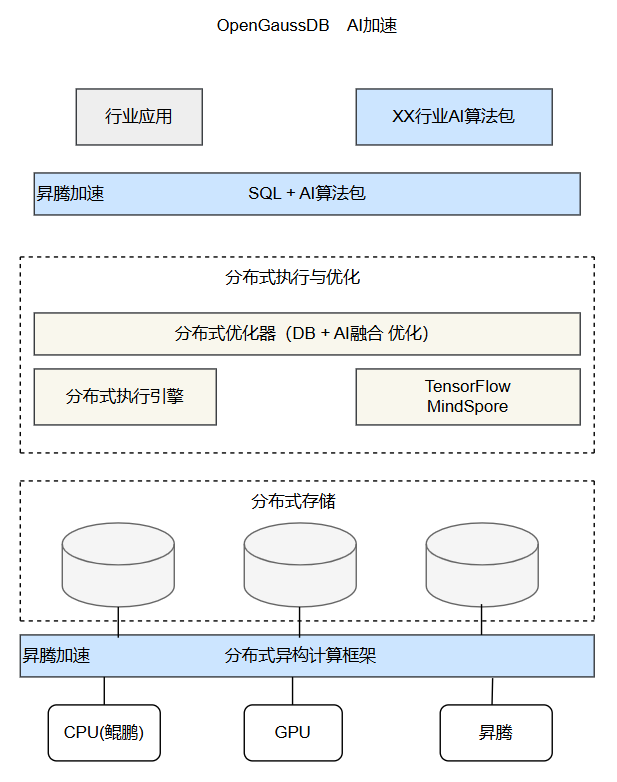
2.3 GaussDB在昇腾AI芯片的技术应用
GaussDB内核除了具备传统数据库SQL能力,同时还能将 AI 推理、训练等操作集成到数据库内完成,通过扩展SQL语法来实现数据库内AI的训练和推理,结合昇腾 AI 芯片对训练和推理过程的加速释放昇腾 AI 计算能力,降低 AI 开发成本,实现训练、推理和管理数据一体化。DB4AI 有如下特点:
- 库内集成 TensorFlow/MindSpore 机器学习深度框架,在数据库内部实现 CNN(Convolutional Neural Network,卷积神经网络)、DNN(Deep Neural Network,深度神经网络)等算法,并探索基于昇腾芯片的对接与加速。
- 基于具体行业领域(如电信、智能驾驶业务场景)实现数据库的内置行业AI算法包,数据分析由“DB + BI”向“DB + AI”转变。
- 数据库充分利用昇腾AI芯片对 Vector、Cube 等计算模型的加速能力,实现传统数据库内聚集操作(Aggregation)、关联操作(Join)的加速。
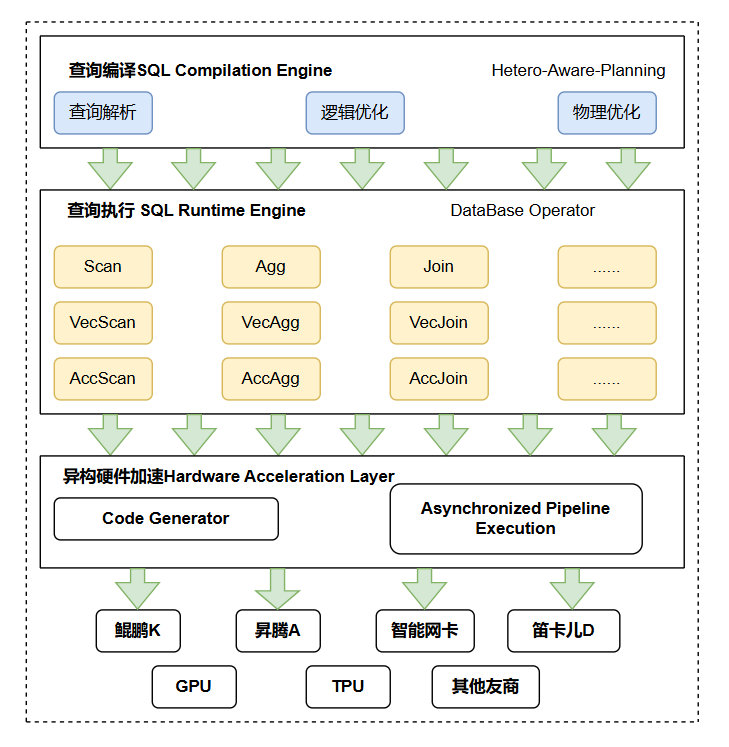
GaussDB与昇腾结合的AI加速与计算加速架构如图所示:
GaussDB计算加速
2.4 GaussDB-AI特性简介
GaussDB数据库在AI领域主要发为两个方向:
-
AI4DB(AI For DataBase)
指用AI使能数据库,从而获得数据库更好的执行表现,实现数据库系统的自治、免运维等,主要包括自调优、自诊断、自安全、自运维 、自愈等子领域。
-
DB4AI(DataBase For AI)
指打通数据库到 AI 应用的端到端流程,统一 AI 技术栈,达到AI应用的开箱即用、高性能、低成本等目的。
3 AI For GaussDB功能
3.1 索引智能推荐
数据库的索引管理是一期非常普遍且重要的事情,任何数据库的性能优化都需要考虑索引的选择。GaussDB支持原生的索引推荐功能,可以通过系统函数等形式进行使用。
3.1.1 使用场景
GaussDB的智能索引推荐功能可覆盖多种任务级别和使用场景,具体包含以下三个特性。
- 单条查询语句的索引推荐。
- 虚拟索引。
- 基于工作负载的索引推荐。
3.1.2 实现原理
3.1.2.1 针对单条查询语句的索引推荐
单条查询语句的索引推荐是以数据库的系统函数形式提供的,用户可以通过调用gs_index_advise()命令使用。
其原理是利用在SQL引擎、优化器等处获取到的信息,使用启发式算法进行推荐。
该功能可以用来对因索引配置不当而导致的慢SQL进行优化。
单条查询语句的索引推荐流程图如下
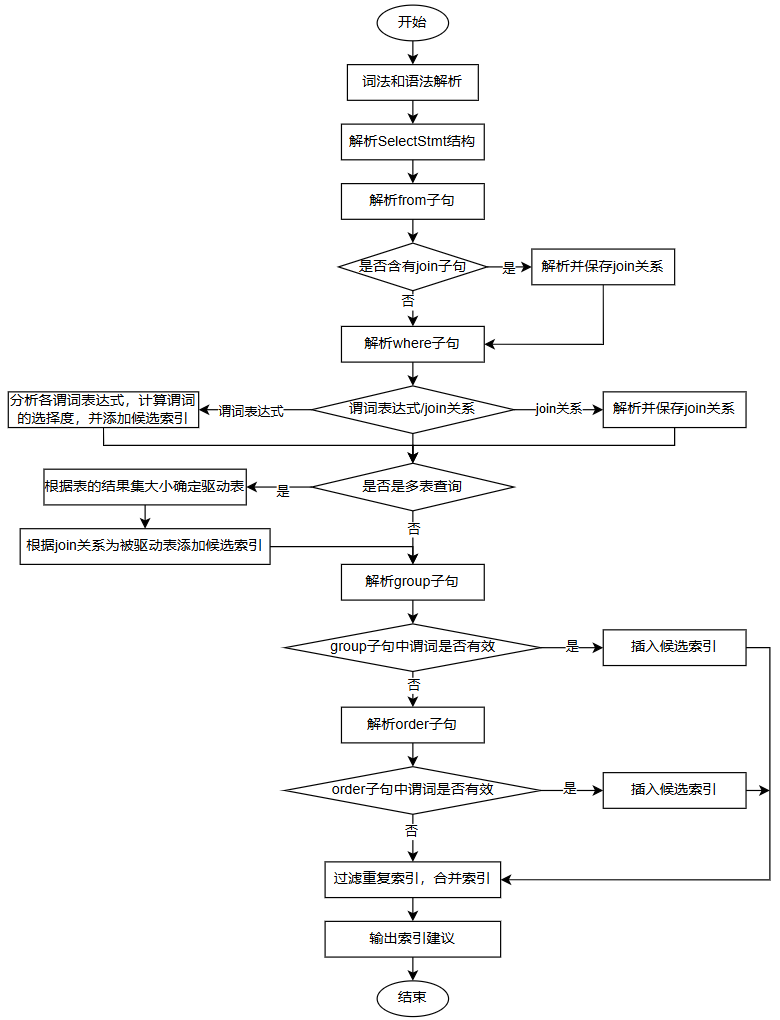
- 对给定的查询语句进行词法和语法解析,得到解析树。
- 依次对解析树中的单个或多个查询子句的结构进行分析
- 整理查询条件,分析各个子句中的谓词。
- 解析from子句,提取其中的表信息,如果其中含有join子句,则解析并保存join关系。
- 解析where子句,如果是谓词表达式,则计算各谓词的选择度,并将各谓词根据选择度的大小进行倒序排列,依据最左匹配原则添加候选索引,如果是join关系,则解析并保存join关系。
- 如果是多表查询,即该语句中含有join关系,则将结果集最小的表作为驱动表,根据前述过程中保存的join关系和连接谓词为其他被驱动表添加候选索引。
- 解析group和order子句,判断其中的谓词是否有效,如果有效则插入候选索引的合适位置,group子句中的谓词优于order子句,且两者只能同时存在一个。
- 检查该索引是否在数据库中已存在,若存在则不再重复推荐。
- 输出最终的索引推荐建议。
3.1.2.2 基于工作负载的索引推荐
基于工作负载的索引推荐功能的主要模块如图所示
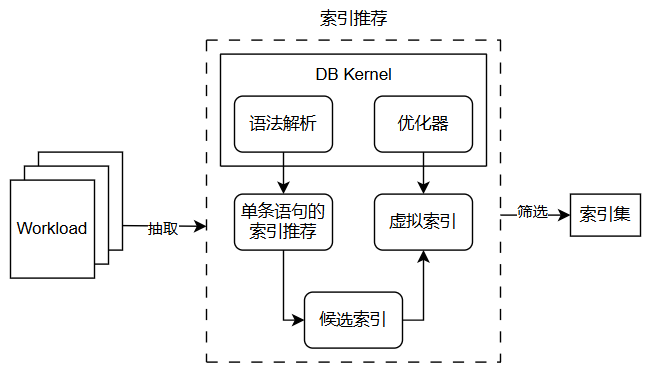
- 对于给定的工作负载,首先对工作负载进行压缩。
- 对压缩后的工作负载,调用单条查询语句的索引推荐功能为每条语句生成推荐索引,作为候选索引集合。
- 对候选索引集合中的每个索引,在数据库中创建对应的虚拟索引,根据优化器的代价估计来计算该索引对整个负载的收益。
- 在候选索引集合的基础上,基于索引代价和收益进行索引的选择。
- 输出最终的索引推荐建议。
3.1.3 使用示例
- 单条SQL的索引推荐
单条查询语句的索引推荐功能支持用户在数据库中直接进行操作,本功能基于查询语句的语义信息和数据库的统计信息,对面用户输入的单条查询语句生成推荐的索引。
| 函数名 | 参数 | 返回值 | 功能 |
|---|---|---|---|
| gs_index_advise | SQL语句字符串 | 无 | 针对单条查询语句生成推荐索引(只支持B树索引) |
创建测试表结构:
drop table if exists partsupp;
create table partsupp (
ps_partkey integer not null,
ps_suppkey integer not null,
ps_availqty integer not null,
ps_supplycost decimal(15,2) not null,
ps_comment varchar(199) not null);
drop table if exists supplier;
create table supplier (
s_suppkey integer not null,
s_name char(25) not null,
s_address varchar(40) not null,
s_nationkey integer not null,
s_phone char(15) not null,
s_acctbal decimal(15,2) not null,
s_comment varchar(101) not null);
drop table if exists nation;
create table nation (
n_nationkey integer not null,
n_name char(25) not null,
n_regionkey integer not null,
n_comment varchar(152));
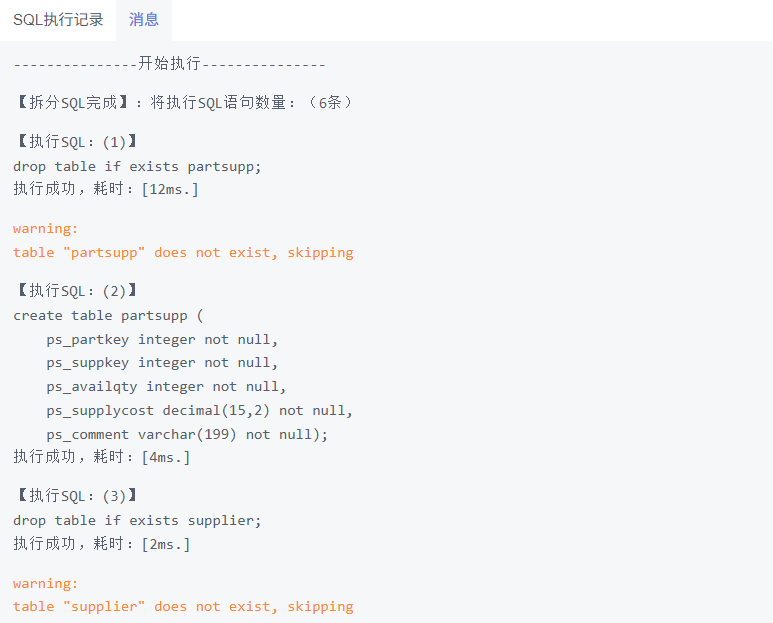
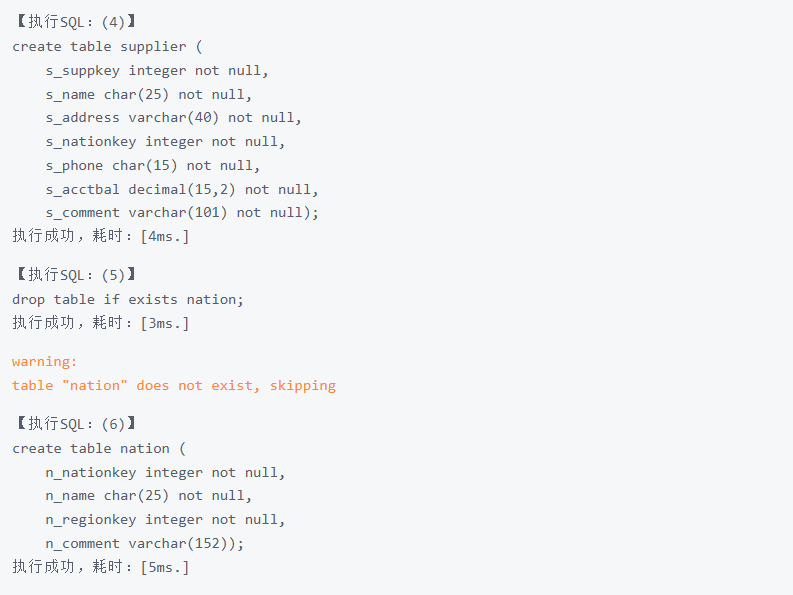
表数据文件(CSV),将3个表的csv文件放在$GAUSSHOME/bin目录下:
CSV数据文件从云主机浏览器中访问下面三个链接下载到本地。
https://dtse-mirrors.obs.cn-north-4.myhuaweicloud.com/case/0043/nation.csv
https://dtse-mirrors.obs.cn-north-4.myhuaweicloud.com/case/0043/partsupp.csv
https://dtse-mirrors.obs.cn-north-4.myhuaweicloud.com/case/0043/supplier.csv
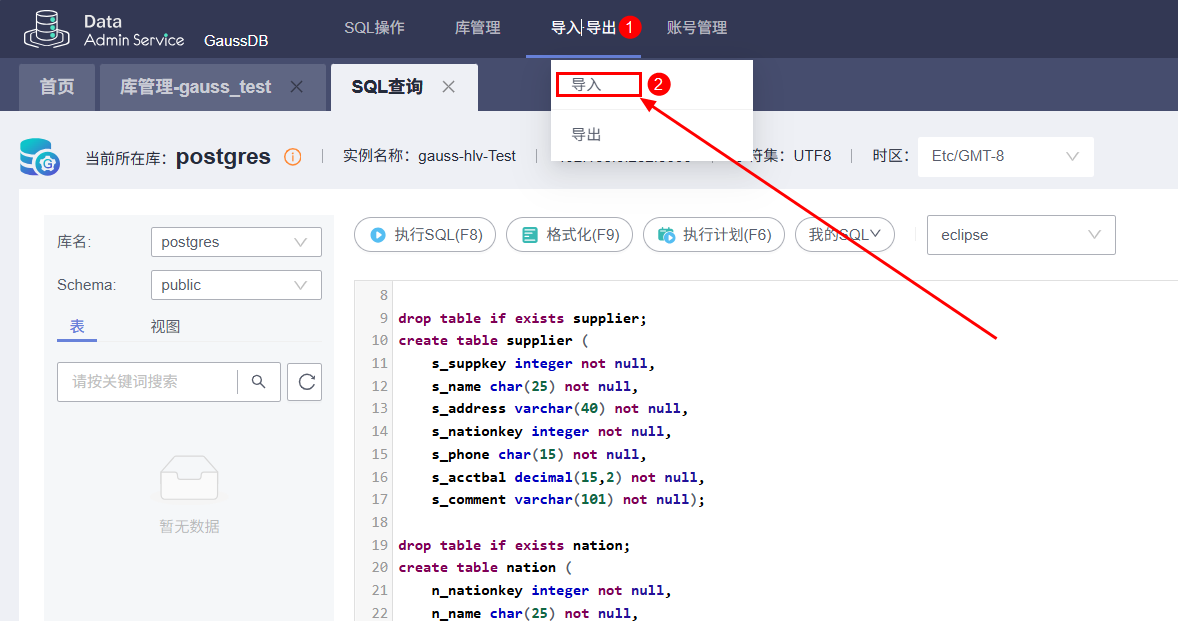
在GaussDB的DAS工具上面任务栏中 导入.导出 点击进入数据导入界面。
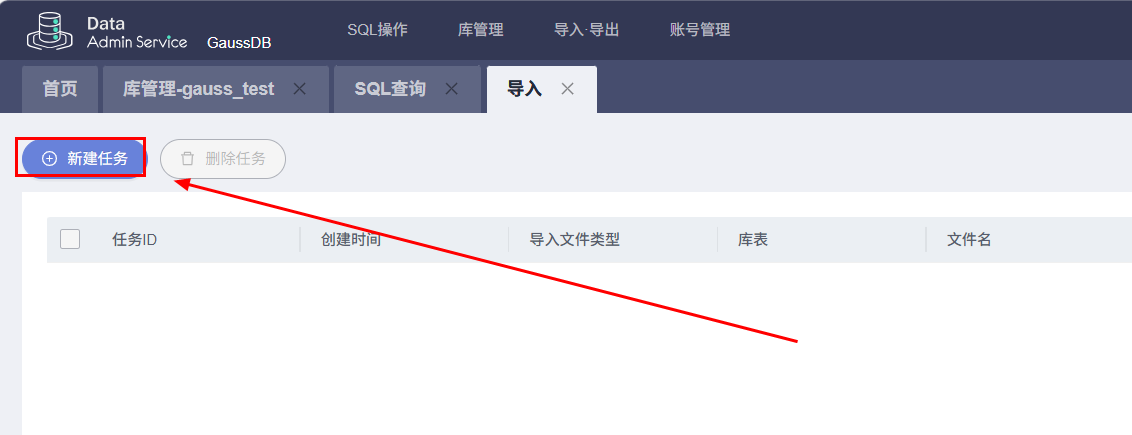
然后在新窗口中点击新建任务:
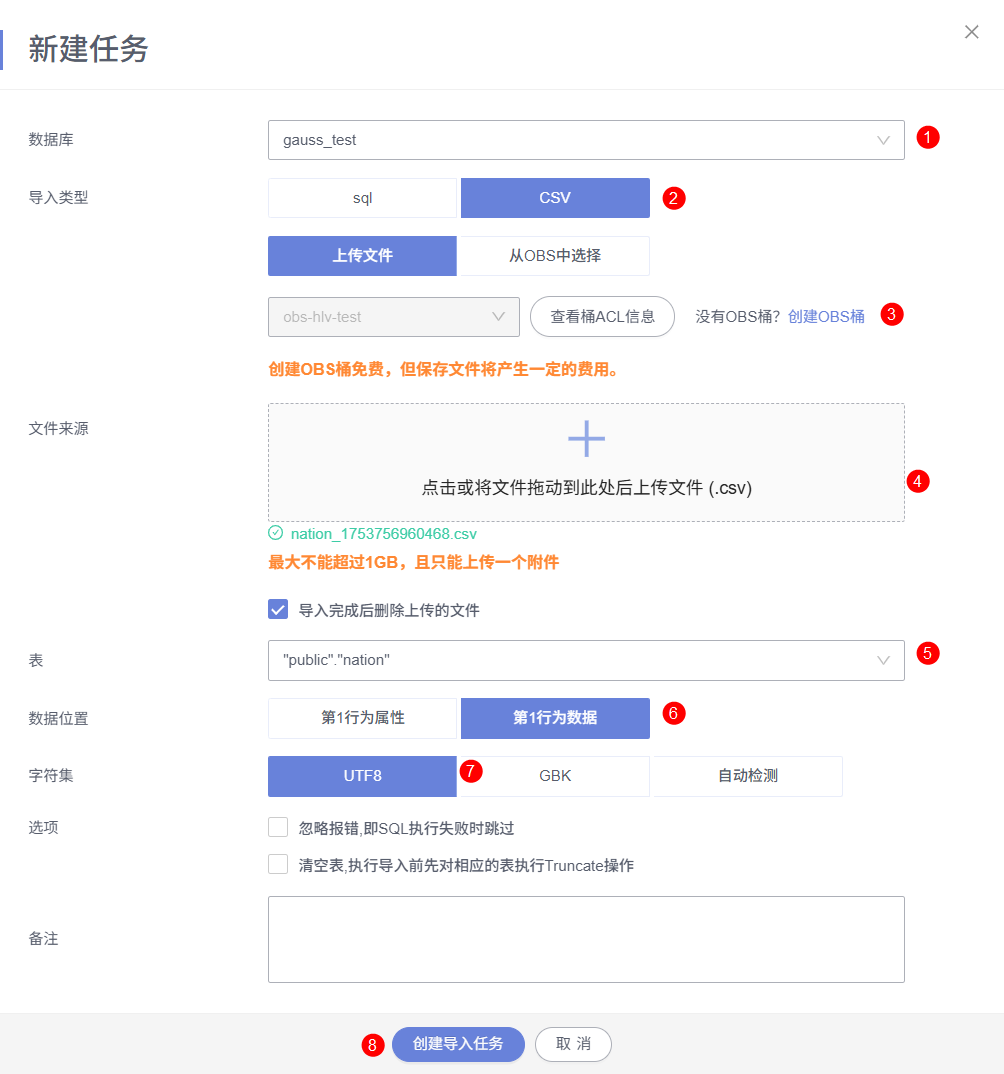
在新任务窗口中,选择数据库为刚才创建表nation,partsupp,supplier所在的数据库,导入类型选择CSV。
上传文件时需要先创建OBS桶,只需要创建一次OBS即可
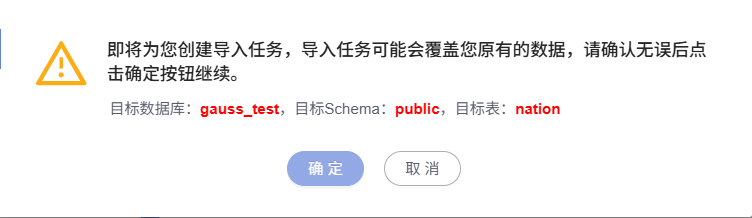
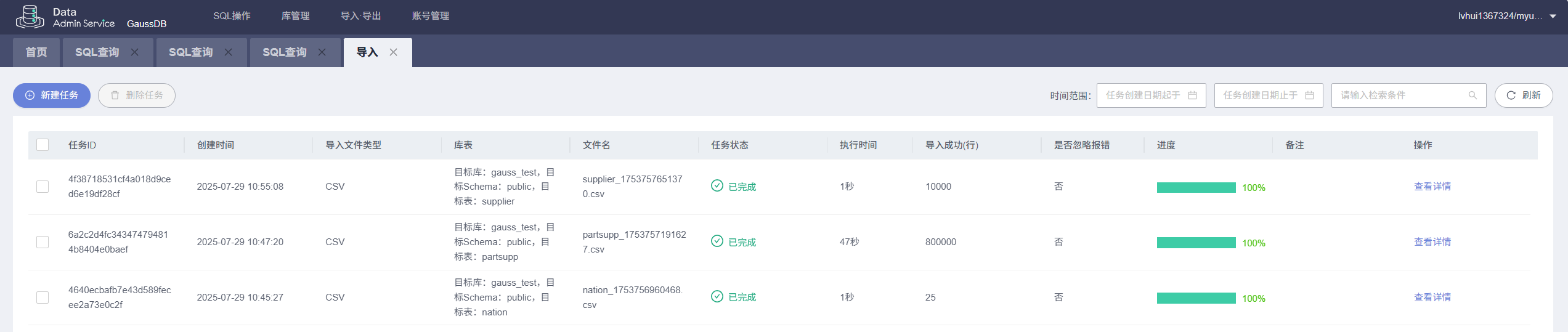
检查对应表数据的导入结果:
select count(*) from partsupp;
select count(*) from supplier;
select count(*) from nation;



执行要测试的SQL查询语句:
select
ps_partkey,
sum(ps_supplycost * ps_availqty) as value
from
partsupp,
supplier,
nation
where
ps_suppkey = s_suppkey
and s_nationkey = n_nationkey
and n_name = 'GERMANY'
group by
ps_partkey having
sum(ps_supplycost * ps_availqty) > (
select
sum(ps_supplycost * ps_availqty) * 0.0001000000
from
partsupp,
supplier,
nation
where
ps_suppkey = s_suppkey
and s_nationkey = n_nationkey
and n_name = 'GERMANY'
)
order by
value desc;
执行结果耗时如下所示
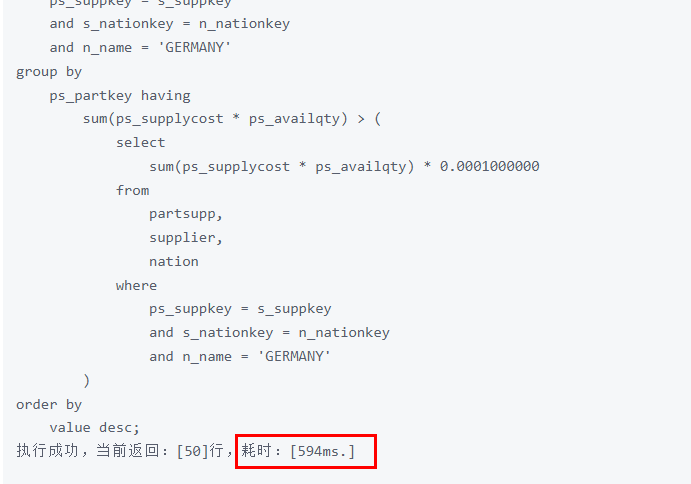
使用gs_index_advise()智能推荐索引。
select * from gs_index_advise('select
ps_partkey,
sum(ps_supplycost * ps_availqty) as value
from
partsupp,
supplier,
nation
where
ps_suppkey = s_suppkey
and s_nationkey = n_nationkey
and n_name = ''GERMANY''
group by
ps_partkey having
sum(ps_supplycost * ps_availqty) > (
select
sum(ps_supplycost * ps_availqty) * 0.0001000000
from
partsupp,
supplier,
nation
where
ps_suppkey = s_suppkey
and s_nationkey = n_nationkey
and n_name = ''GERMANY''
)
order by
value desc');
结果如下:

根据索引推荐的结果,创建对应的索引
create index ps_suppkey_index on partsupp(ps_suppkey);
create index sl_suppkey_nationkey_index on supplier(s_suppkey, s_nationkey);

再执行上面的查询,查看耗时结果
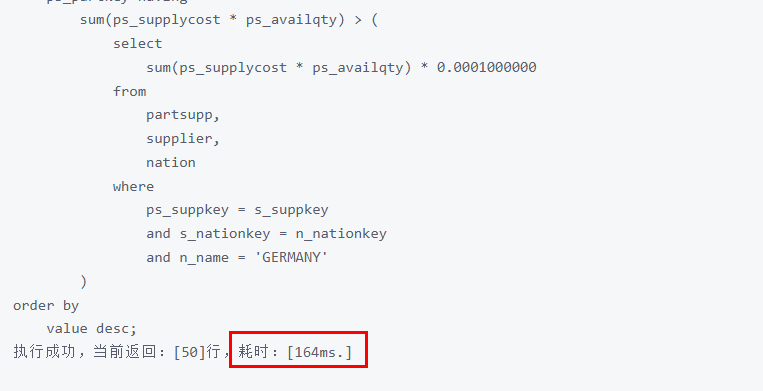
可以明显看出SQL执行时间从594ms降到了164ms,速度提升了接近73%。
再删除刚才创建的索引:
drop index ps_suppkey_index;
drop index sl_suppkey_nationkey_index;

创建虚拟索引:
select * from hypopg_create_index(' create index ps_suppkey_index on partsupp(ps_suppkey)');
select * from hypopg_create_index('create index sl_suppkey_nationkey_index on supplier(s_suppkey, s_nationkey)');


查看虚拟索引列:
select * from hypopg_display_index();
再删除该虚拟索引:
select * from hypopg_drop_index(22313);
select * from hypopg_display_index();

删除索引虚拟列:
select * from hypopg_drop_index(indexrelid);
根据本案例在上面的查询结果,indexrelid是 22313, 22314。
select * from hypopg_drop_index(22314);

再创建之前的虚拟索引:
select * from hypopg_create_index(' create index ps_suppkey_index on partsupp(ps_suppkey)');
获取索引虚拟列大小结果:
select * from hypopg_estimate_size(indexrelid);
根据上面返回的indexrelid结果,则为
select * from hypopg_estimate_size(16404);
重新创建的虚拟索引OID为22317:
删除所有索引虚拟列:
select * from hypopg_reset_index();
再查看虚拟列索引,确认所有虚拟列索引都已经被删除了。
select * from hypopg_display_index();
4 反馈改进建议
如您在案例实操过程中遇到问题或有改进建议,可以到论坛帖评论区反馈即可,我们会及时响应处理,谢谢!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 7
7 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)