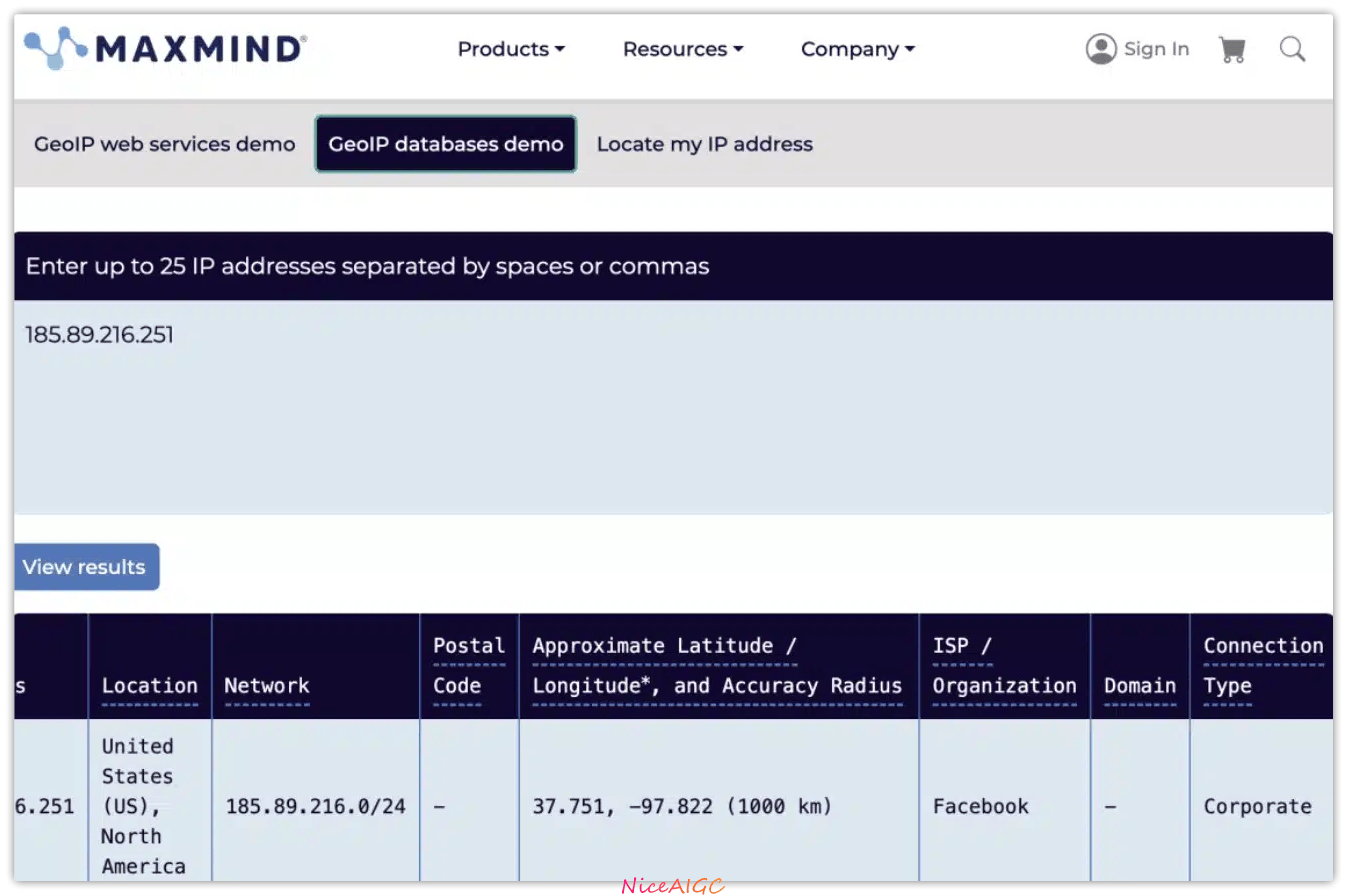
Meta 偷H片训练 AI,遭天价索赔:3.59 亿美元背后的 AI 数据暗战
2025 年 7 月 23 日,两家美国成人电影公司 Strike 3 Holdings 和 Counterlife Media 一纸诉状将 Meta 告上加州北区联邦法院。诉状称 Meta 自 2018 年起,通过,用于训练旗下 AI 模型,包括视频生成器 Meta Movie Gen、LLaMA 大语言模型等,潜在赔偿金额高达。这起案件撕开了 AI 行业的 “数据遮羞布”—— 巨头们光鲜的技术

2025 年 7 月 23 日,两家美国成人电影公司 Strike 3 Holdings 和 Counterlife Media 一纸诉状将 Meta 告上加州北区联邦法院。
诉状称 Meta 自 2018 年起,通过 BitTorrent 技术偷偷下载了 2396 部成人影片,用于训练旗下 AI 模型,包括视频生成器 Meta Movie Gen、LLaMA 大语言模型等,潜在赔偿金额高达 3.59 亿美元(每部影片索赔 15 万美元)。
这起案件撕开了 AI 行业的 “数据遮羞布”—— 巨头们光鲜的技术突破背后,可能藏着不光彩的素材来源。
科技圈的瓜越来越硬核了,别人追星追剧,Meta 追 “片” 还追到被告席,这波操作属实把 “开源” 玩成了 “开盗”。
事件核心:从公司服务器到员工家 WiFi 的盗播网络

原告通过技术追踪发现,至少 47 个 IP 地址直接归属 Meta,另有多个隐藏在虚拟私有云(VPC)中的 IP 形成 “公司级盗播网络”。
更离谱的是,一个 Comcast 家庭宽带 IP 被锁定在 Meta 员工家中,疑似 “上班下载不够,下班回家继续贡献数据”。
这些 IP 呈现 “高频 + 长时段 + 多分辨率” 同步下载特征,明显是机器操作而非人类观看行为。
Meta 甚至编写脚本控制做种行为,用自家服务器和员工私人网络构建了一套覆盖内外的系统性盗播体系。
为何盯上H片?AI 训练的 “完美素材” 竟是它

Strike 3 的律师在诉状中道出真相:成人影片是 AI 训练的 “黄金素材”。
这类视频画质高、镜头稳定、人物表情自然连贯,且场景变化少,完美契合生成式 AI 对 “动作连贯性” 和 “情绪真实性” 的训练需求。
更关键的是,热门成人影片在 BT 网络中种子多、下载快,Meta 利用 BT 的 “tit-for-tat(以牙还牙)” 机制,通过播种这些高热度内容加速获取其他数据集,把盗版内容变成了 “下载货币”。
趣评:原来 AI 学演技的 “私教课” 素材是这么来的,难怪生成视频越来越逼真,这背后竟是 “祖师爷级” 盗版教学。
版权罗生门:从作家维权到情色战争的老套路

这不是 Meta 第一次因数据盗版被告。2023 年就有作家集体起诉 Meta,指控其通过 BT 下载 81.7TB 盗版书籍训练 LLaMA 模型,当时 Meta 承认了 BT 使用行为。而这次的原告 Strike 3 堪称 “版权维权专业户”,2017-2023 年间提起过近 9500 起诉讼,靠抓 IP 发律师函和解年入数千万美元。一边是 “数据饥渴” 的科技巨头,一边是 “维权致富” 的版权猎人,这场官司成了两种极端版权思维的正面碰撞。
通俗解释:Meta 是惯犯,Strike 3 是职业打假人,这次巨头踢到了铁板 —— 对方不仅有证据链,还把维权做成了流水线生意。
最新进展:巨头沉默与行业震动
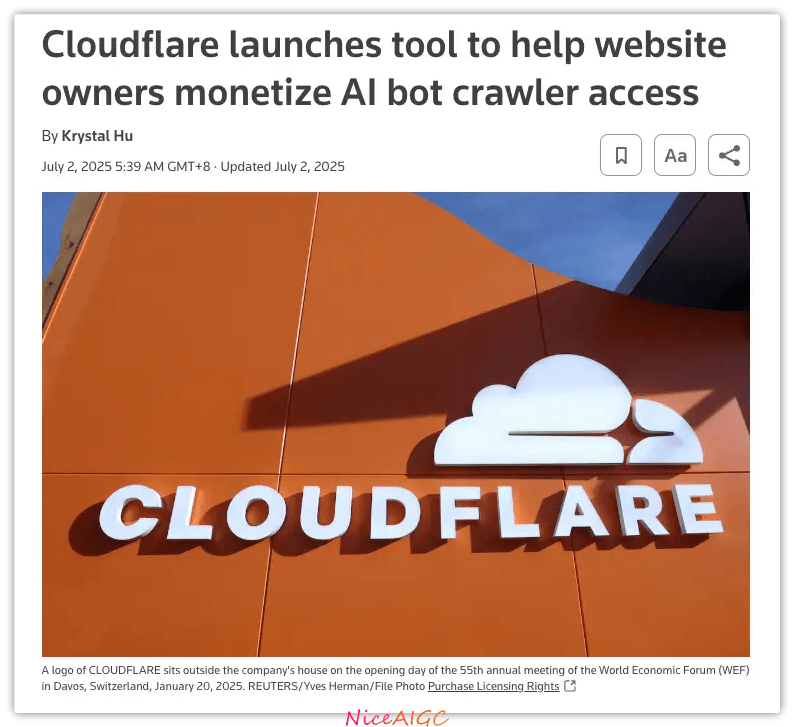
面对指控,Meta 仅回应 “正在审查诉状,认为指控不准确”。但原告证据显示,即便收到律师函警告,Meta 的 BT 活动仍在持续。更值得关注的是,2025 年 7 月 Cloudflare 已更新政策,默认拦截未经许可的 AI 网络爬虫,预示着行业对数据来源合规性的警惕升级。如果法院认定侵权成立,Meta 不仅要赔巨款,还可能被迫删除侵权训练数据和相关模型。
当防火墙开始拒绝 AI 爬虫,当 “免费数据午餐” 快到期,AI 行业的 “断奶期” 要来了吗?
时间线简览(最新发展):
-
2025年2月:法庭文件披露Meta员工曾讨论使用盗版图书(如LibGen)为LLaMA训练资料
-
2025年7月25日:Strike 3等提起针对Meta的成人影片盗版AI训练诉讼
-
2025年8月:案件持续发酵,多家媒体做分析与报道

这起案件暴露的不只是 Meta 的问题,更是整个 AI 行业的 “数据原罪”:
当训练素材从书籍、图片扩展到视频甚至私密内容,我们该如何界定 “技术发展” 与 “版权保护” 的边界?
如果连严密追踪的成人影片公司都难以阻止盗版,普通人的照片、语音、文字内容又如何避免成为 AI 的 “免费饲料”?
欢迎在评论区分享你的看法。
---
欢迎关注 NiceAIGC 微信公众号,实时获取更多行业资讯和实用工具


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 21
21 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)