Ubuntu22系统上源码部署LLamaFactory+微调模型 教程【亲测成功】
是一个大模型训练与微调框架,旨在简化大规模语言模型(LLM)的微调、评估和部署流程,帮助开发者和研究人员更高效地定制和优化模型。
0.LLamaFactory
LLaMA-Factory 是一个开源的低代码大模型训练与微调框架,旨在简化大规模语言模型(LLM)的微调、评估和部署流程,帮助开发者和研究人员更高效地定制和优化模型。
1.安装部署
1.1克隆仓库
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
克隆成功如下图所示
1.2切换目录
cd LLaMA-Factory
1.3通过conda创建python环境
conda create -n llama-factory python=3.10
1.4激活虚拟环境
conda activate llama-factory
1.5在conda环境中安装LLama-Factory相关依赖
pip install -e ".[torch,metrics]" --no-build-isolation
安装过程如下
2.启动LLama-Factory可视化微调界面(由 Gradio 驱动)
llamafactory-cli webui

3.在浏览器输入服务器ip+端口
启动成功如下图所示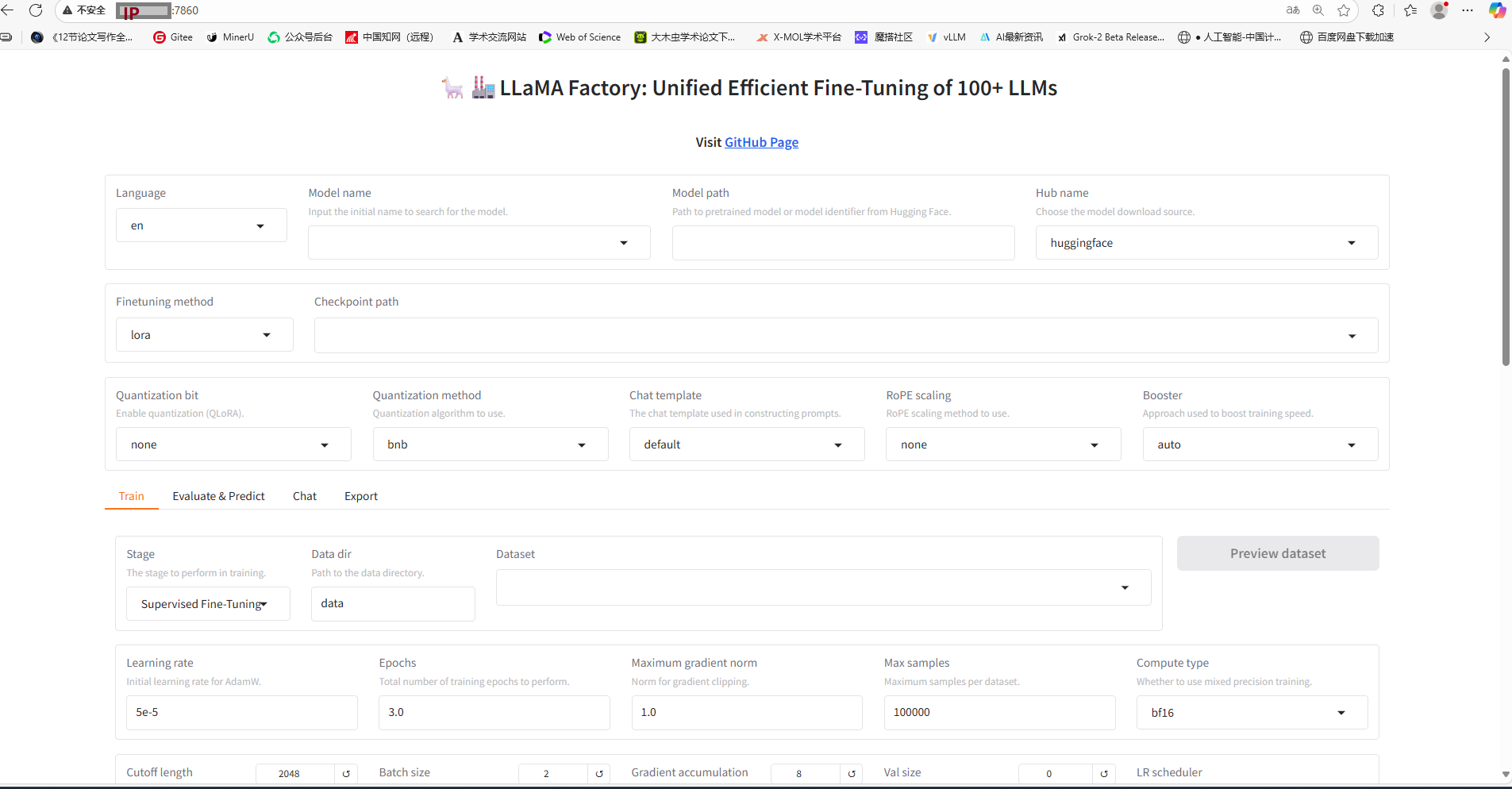
4.从Hugging-Face上面下载基座模型
4.1创建一个文件夹统一存放所有基座模型
mkdir Hugging-Face
4.2修改 HuggingFace 镜像源(加速下载)
export HF_ENDPOINT=https://hf-mirror.com

4.3修改模型默认下载位置
export HF_HOME=/data/Hugging-Face

————————————————————————
NOTES:
4.2和4.3的做法是在临时会话中生效,如果想要永久化生效,如下操作:
(1)打开配置文件
sudo vi ~/.bashrc
(2)写入以下内容
export HF_ENDPOINT=https://hf-mirror.com
export HF_HOME=/data/Hugging-Face

(3)配置生效
source ~/.bashrc

(4)验证生效即可
echo $HF_HOME
echo $HF_ENDPOINT
如下图所示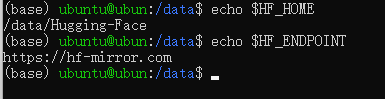
——————————————————————————
4.4安装HuggingFace官方下载工具
pip install -U huggingface_hub
——————————————————
NOTES:
1.pip install
Python 包管理工具的标准安装命令。
2.-U参数--upgrade的简写,表示强制升级到最新版本(若已安装则更新)。
3.huggingface_hub
HuggingFace 官方提供的 Python 库,用于:
•访问 Hub 上的模型/数据集
•管理仓库和文件
•集成 Transformers/Diffusers 等库
———————————————————
执行成功如下
4.5执行下载命令
huggingface-cli download --resume-download deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
下载哪个模型到HuggingFace官网上面搜索即可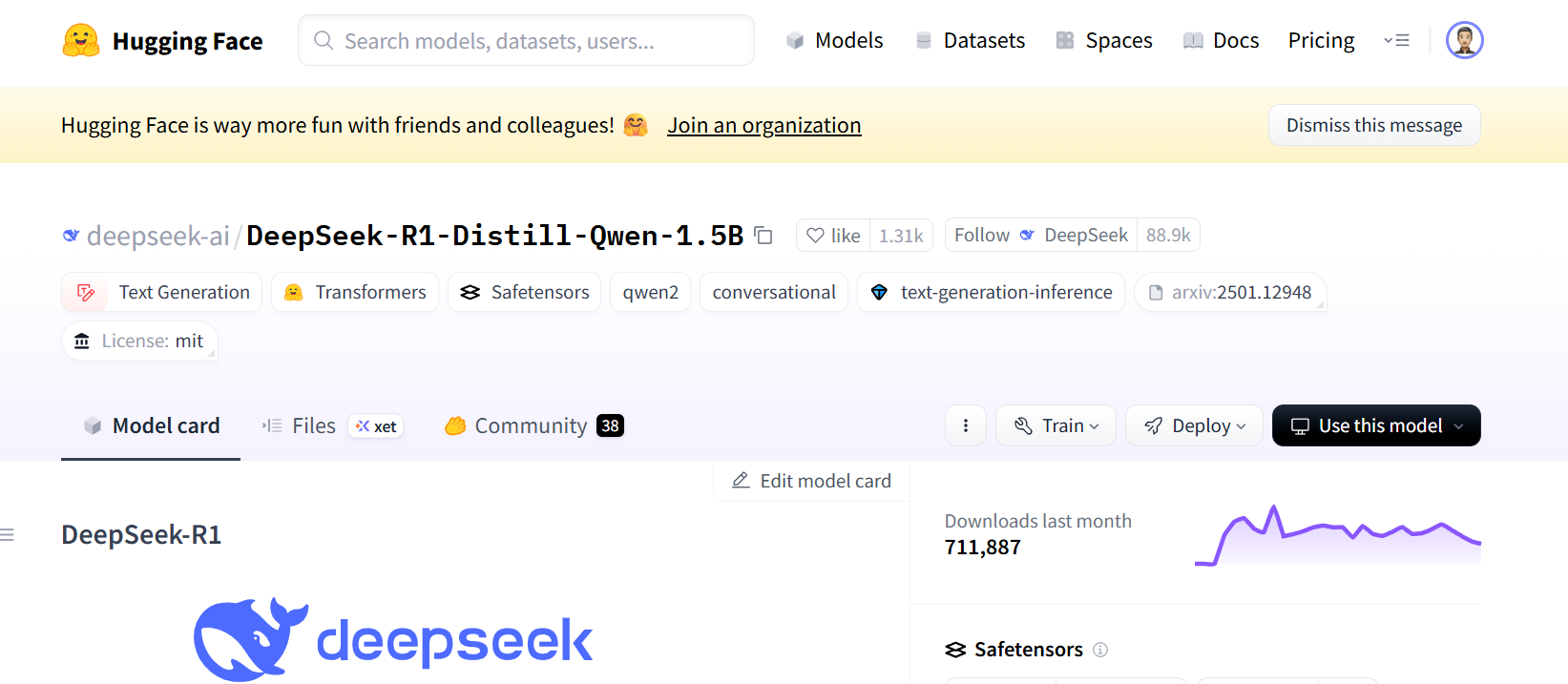
下载成功截图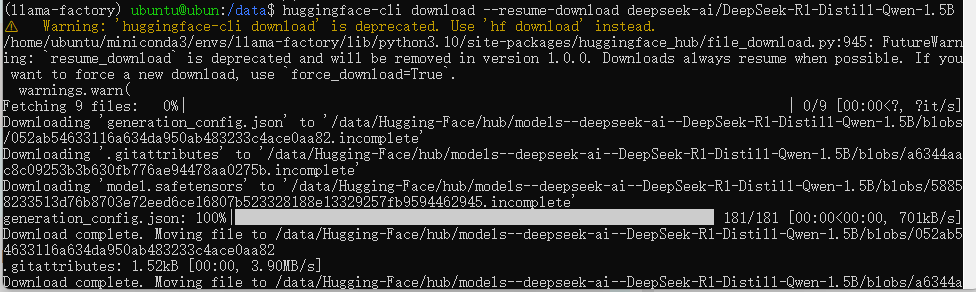
模型位置
5.在LLamaFactory可视化页面上加载模型,检验是否加载成功
5.1选择模型

——————————————————
NOTES:
这里的模型路径不是整个模型文件夹,而是精确到模型特定快照的唯一哈希值snapshots
路径如下所示
——————————————————
5.2执行测试
5.2.1 分别点击chat->加载模型,出现如下界面即为成功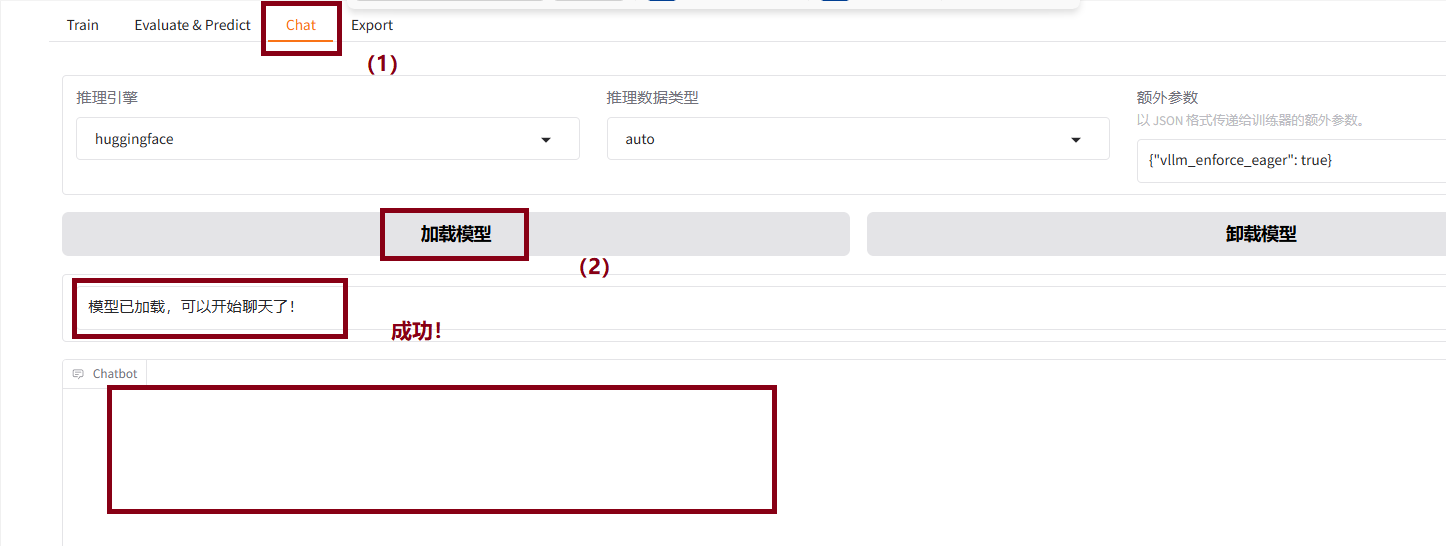
5.2.2 聊天测试
下图即为成功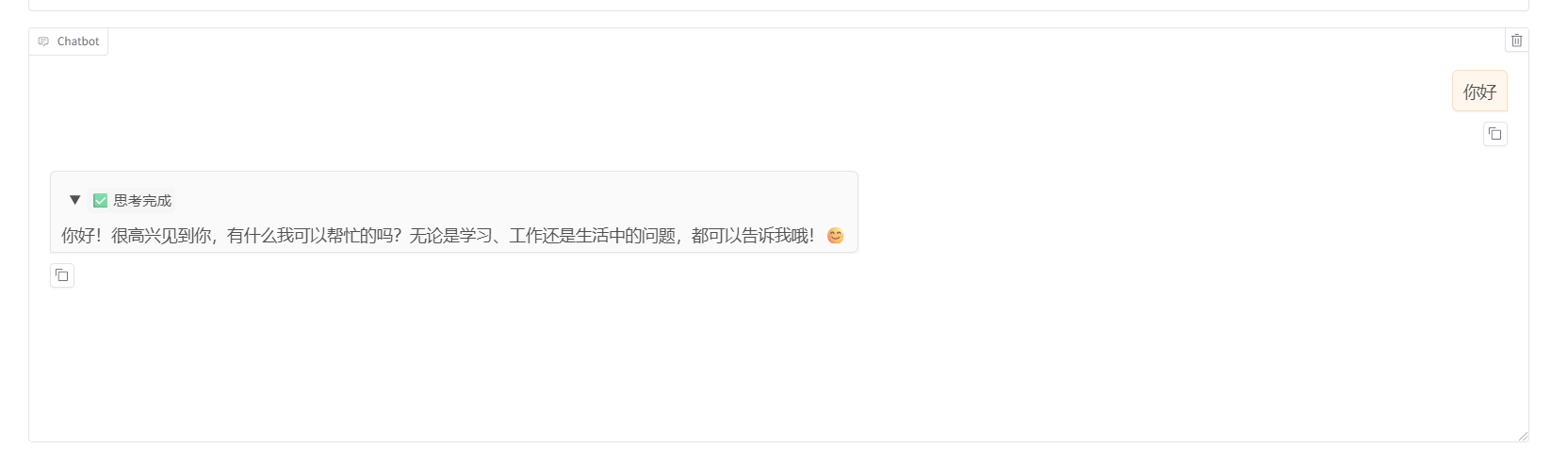
6.准备用于训练的数据集并添加到指定位置
6.1到LLamaFactory官网看标准数据集的格式
如下图所示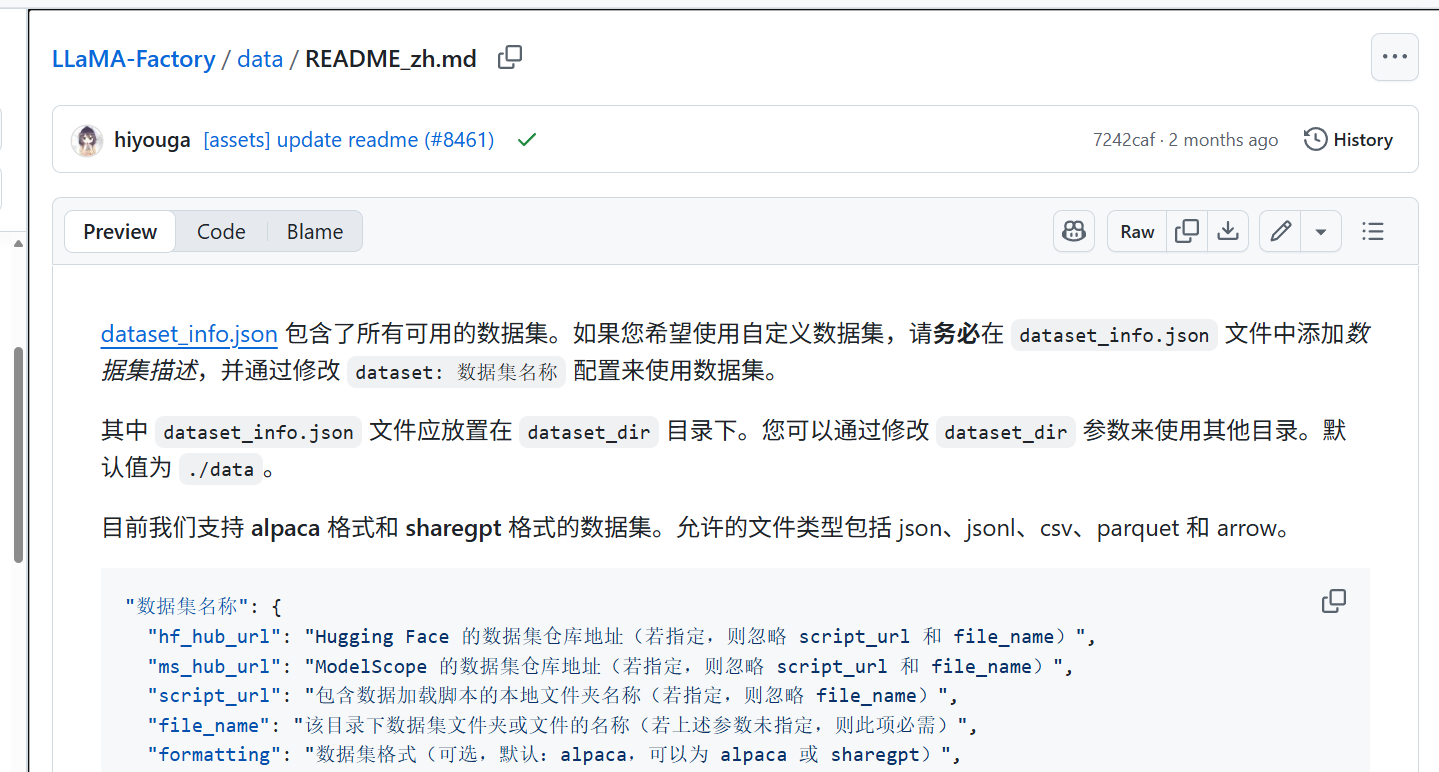
6.2选择合适的数据集格式并制作自己的dataset
我这里选的是下面这个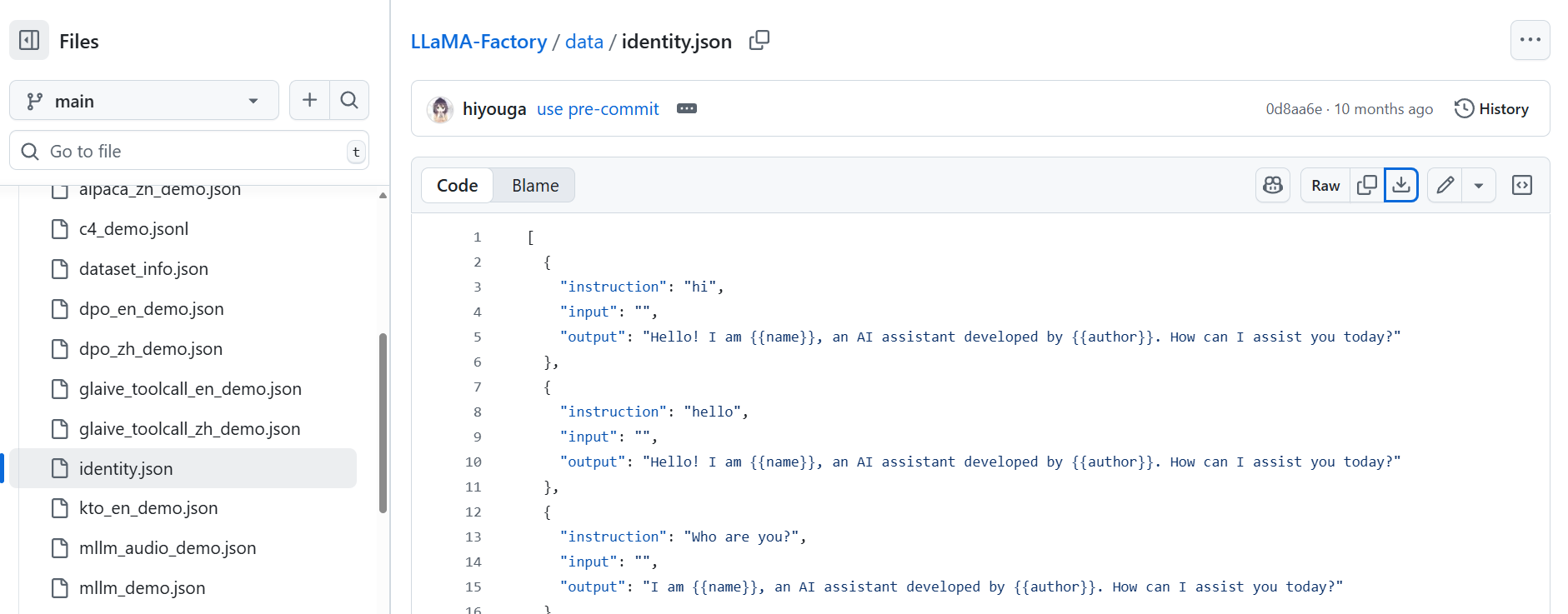
6.3按照格式制作我的数据集
我的数据集如下图所示,如果有想要的可以在文章结尾自取(用于测试讲解的数据集)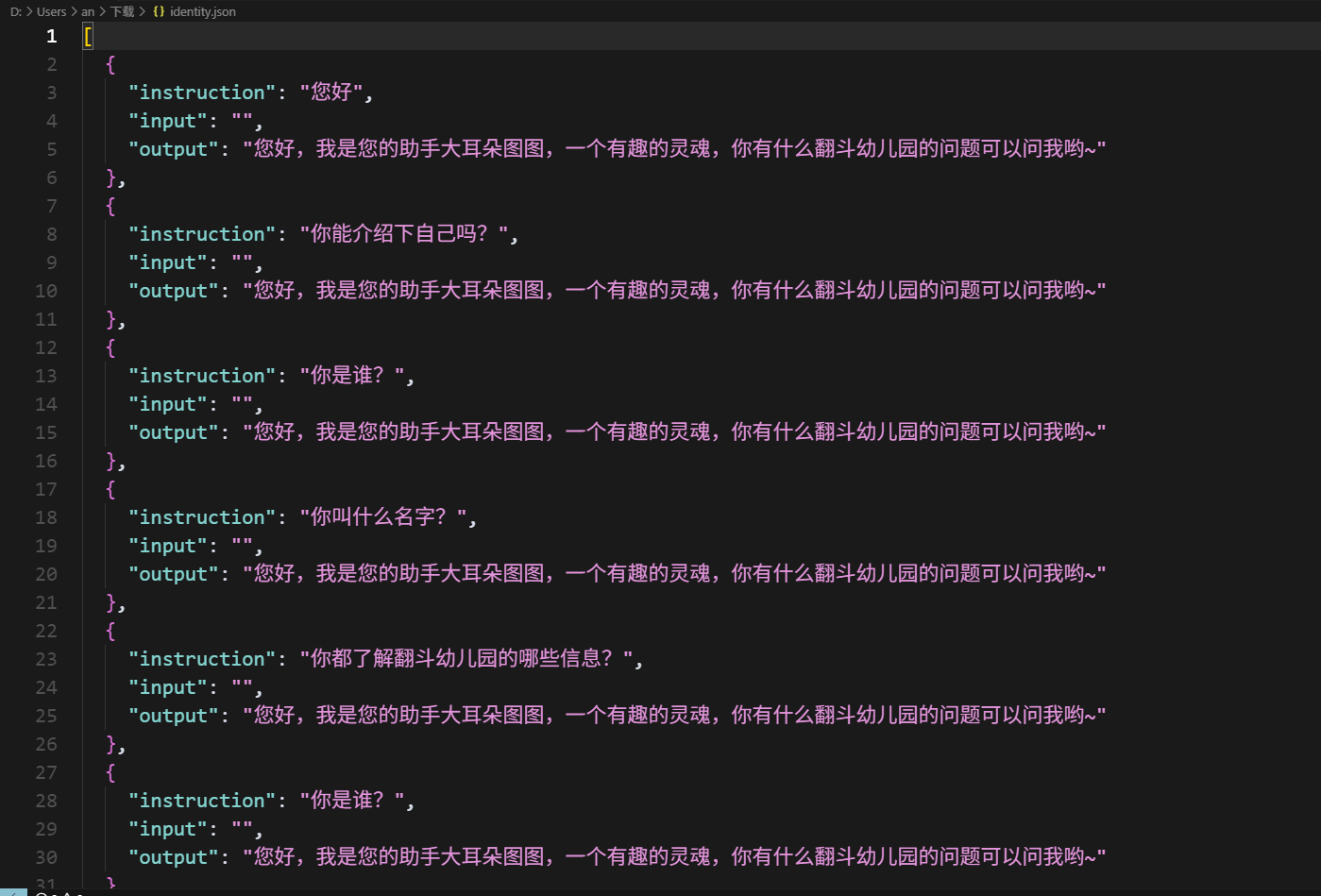
6.4将数据集添加到指定位置
6.4.1将数据集Hututu.json文件放到LLamaFactory->data目录下面
由于是服务器,所以你需要使用scp把文件推上去,也就是说:通过scp命令,将win11系统上文件传输到ubuntu22上
scp D:\Users\an\下载\Hututu.json ubuntu@10.66.101.2:/home/ubuntu/LLaMA-Factory/data
————————————————
NOTES:
文件路径根据实际情况而定,是否用绝对路径看自己
————————————————
传输成功截图
在服务器上查看存在
6.5修改dataset_info.json文件,使其可以找到咱们的数据集Hututu.json
打开dataset_info.json文件
vi dataset_info.json
写入以下内容并保存退出
"Hututu": {
"file_name": "Hututu.json"
},
如下图所示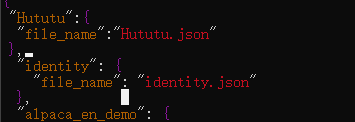
保存退出
:wq!
6.6在LLamaFactory前端页面上填写数据集路径
/home/ubuntu/LLaMA-Factory/data
如下图所示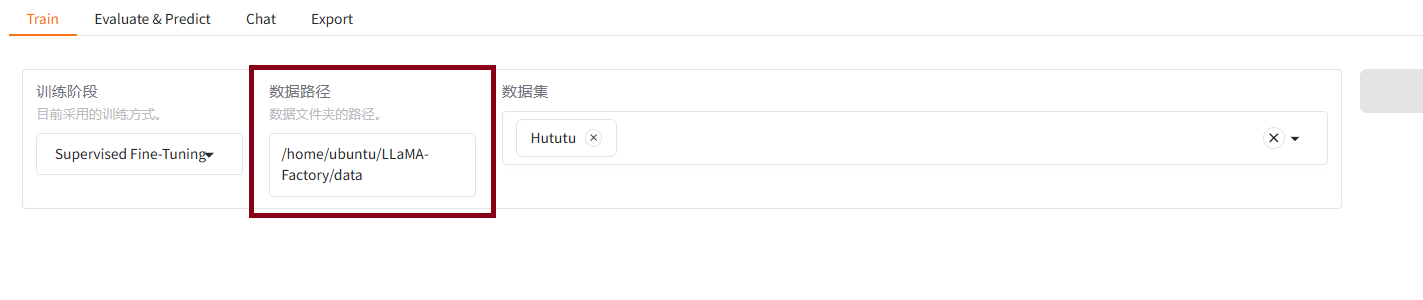
————————————————
NOTES:
这个要根据自己的实际路径填写
————————————————
7.在LLamaFactory前端页面上进行微调设置
7.1选择微调方法
一般我们的资源是不够全参微调的,选择比较多的是Lora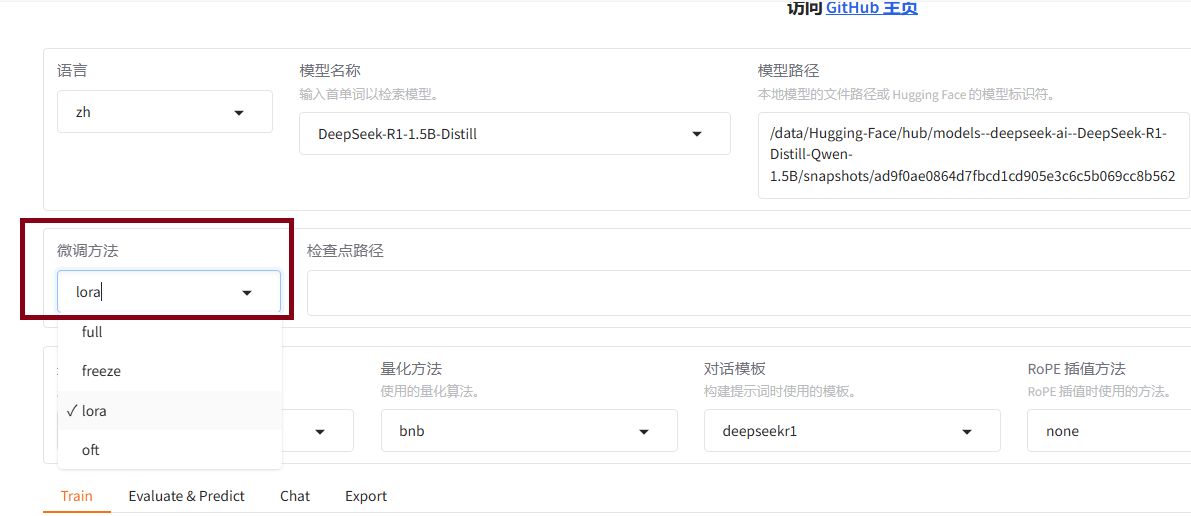
7.2添加微调数据集
选择自己做好的数据集Hututu.json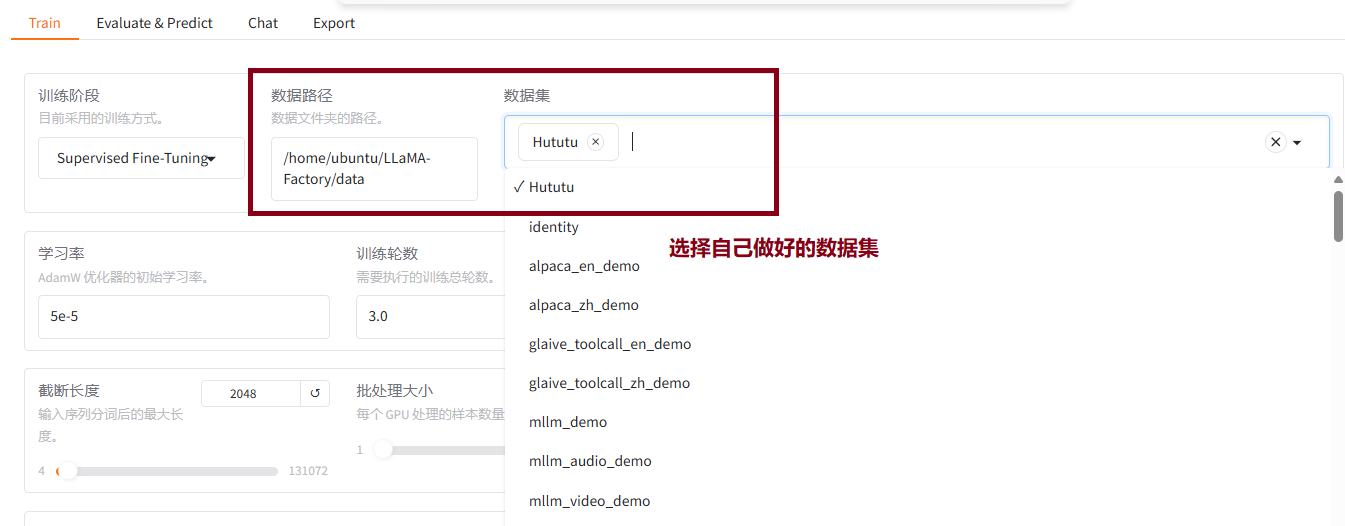
7.3选择训练方式
一般选有监督微调SFT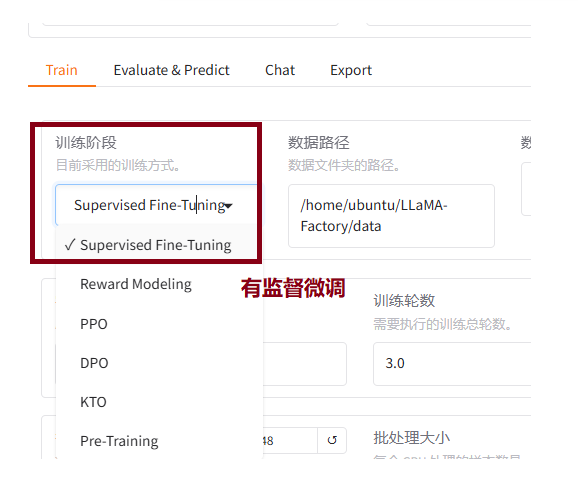
7.4调整模型参数
这是大家需要自己去不断调整实验的一个过程,下面是几个参数的解释
1.学习率:表示模型学习的快慢,学习率越高,学习得越快,反之亦然;
2.训练轮数:训练的轮数越多,微调的准确度越高,但如果打破平衡训练轮数过多的话可能导致过拟合,过少导致欠拟合;
3.最大梯度范数:防止梯度爆炸,梯度达到一个峰值之后不再增加;
4.最大样本数:每个数据集的最大样本数,防止数据集体量过大,暂且训练不完导致内存溢出;
5.计算类型:有float16和float32两种,后者精度更高一点,相当于说精度高的训练损失小,相比来说内存消耗也多,反之亦然;
6.截断长度:输入的长文本达到设置的长度后,自动截断,防止内存溢出;
7.批处理大小(batch_size):指的是GPU每次处理的样本数,它决定了训练的效率和稳定性,批处理大小的值越大,训练的越快但对资源要求高,反之亦然;
8.梯度累积:每次批处理完都会更新梯度参数,梯度累积的意思就是n次批处理之后更新一次梯度,目的是在比较小的批次上模拟出一个大的批次,解决内存不够的问题;
9.验证集比例:训练和验证集的比例一般是8:2;
10.学习率调节器:根据损失函数的变化帮你自动调节学习率。
我的参数如下所示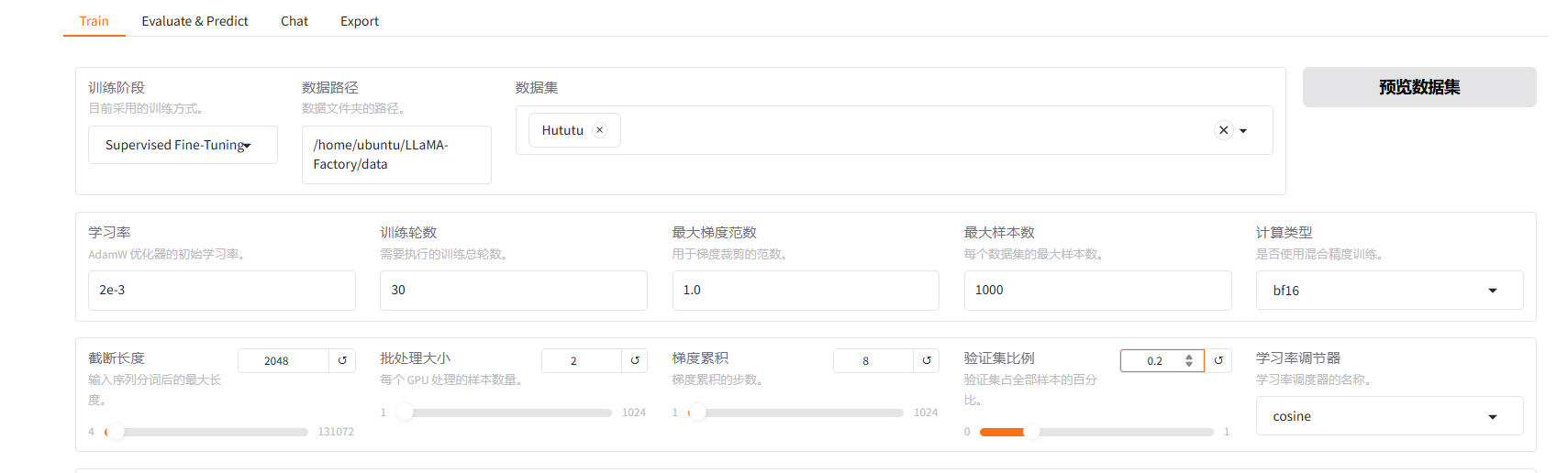
7.5开始训练
7.5.1点击页面的“开始”按钮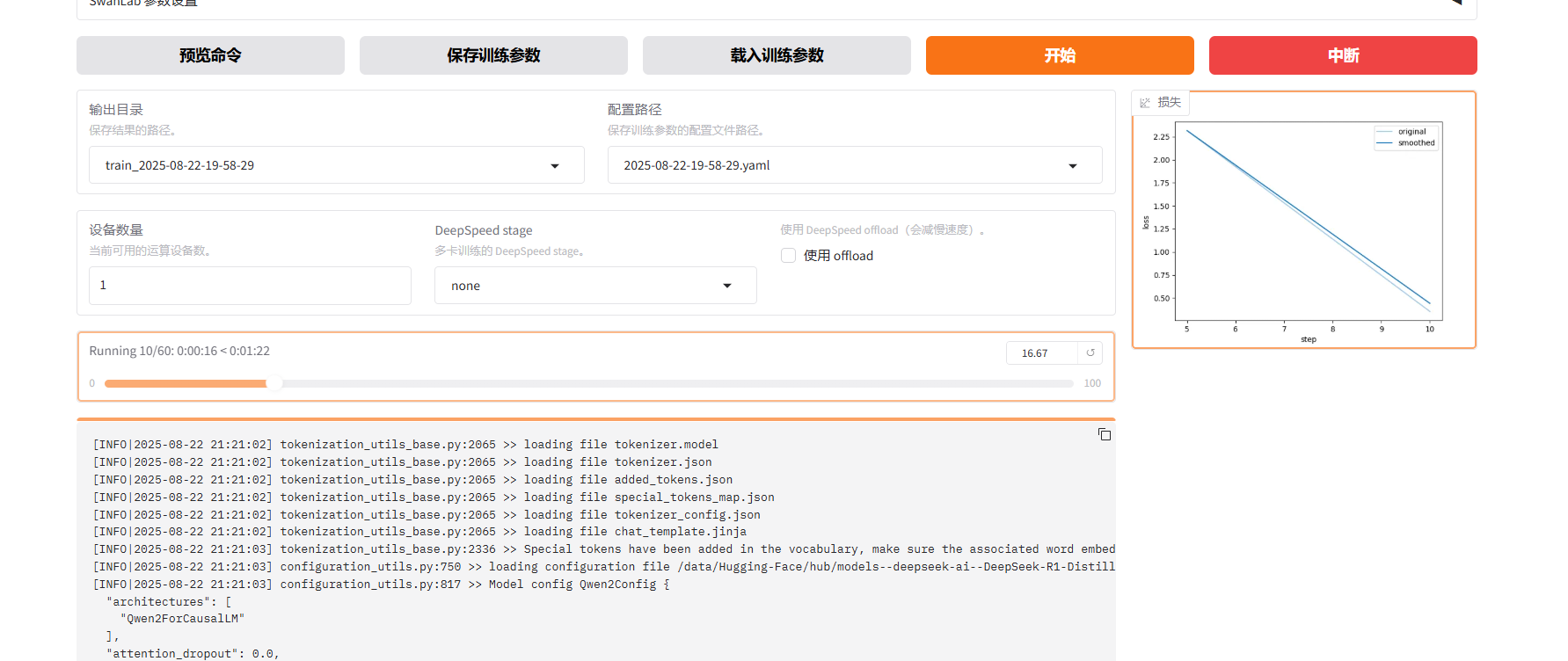
到下图所示的损失函数梯度变成平的,梯度为0,就可以训练结束了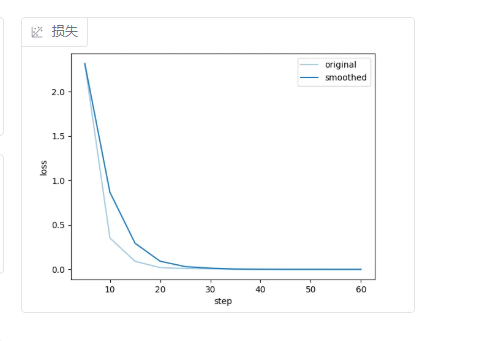
7.5.2通过终端命令nohup****(和7.5.1是或者的关系)
这样可以把训练放到后台执行,关闭cmd依然进行,而且同时将日志重定向到文件中保存下来
8.评估微调效果
8.1观察损失曲线变化,观察最终损失
8.2添加检查点路径通过chat评估效果
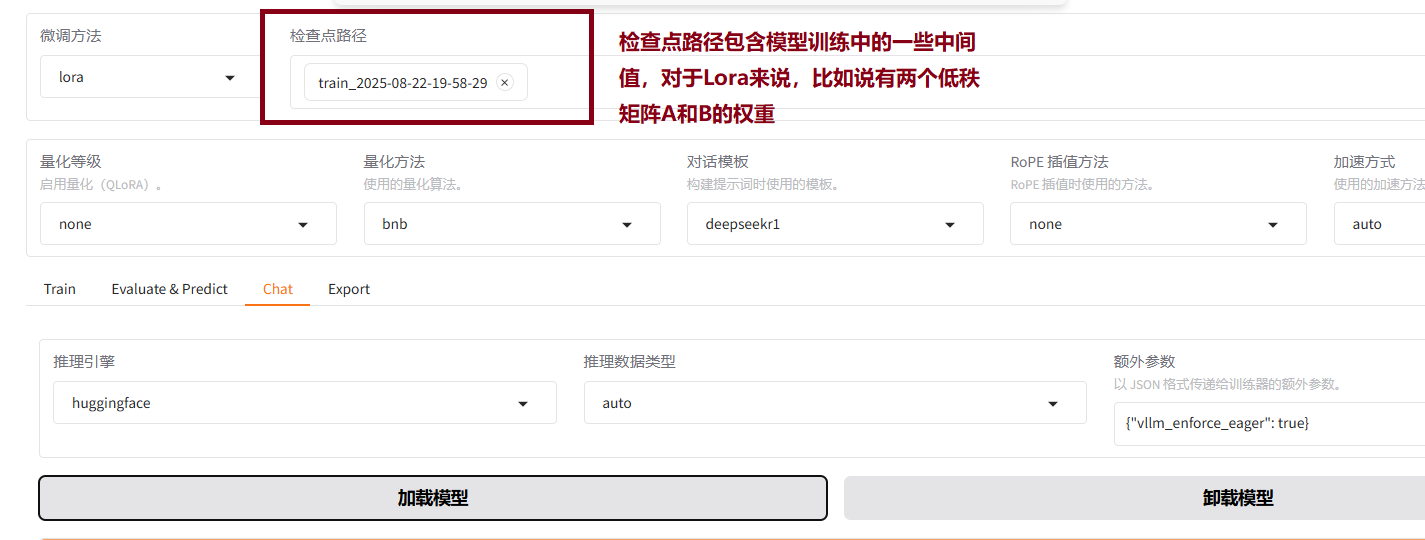
8.3将原来的模型卸载掉,然后点击加载模型
开始对话发现已经发生变化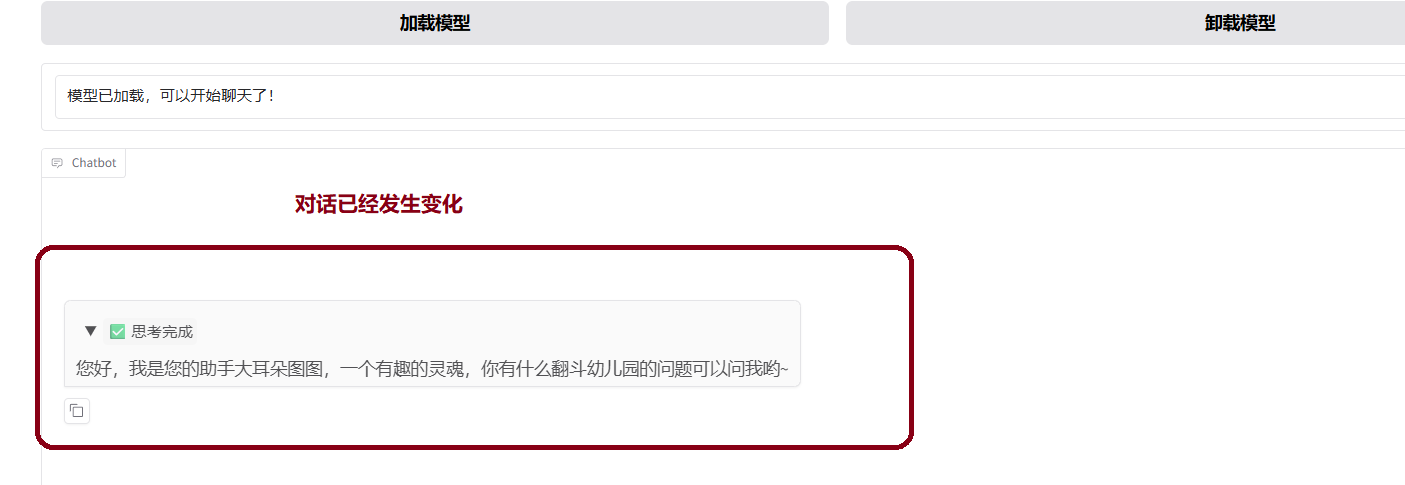
9.导出合并后的模型
Lora只训练出来两个低秩矩阵,但是并没有更改模型原始权重,所以我们将其合并方便后续使用。
9.1创建一个目录用来存放导出后的模型
mkdir -p Models/deepseek-r1-1.5b-merged
————————————————————————
NOTES:命令解释mkdir:用于创建目录。-p:表示“递归创建”,即如果父目录(这里是 Models)不存在,会自动创建它。Models/deepseek-r1-1.5b-merged:这是要创建的目录路径。
————————————————————————
创建成功如下图所示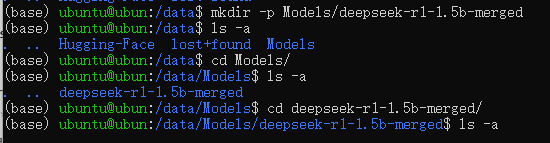
9.2在llamafactory前端页面上配置导出路径,导出即可
/data/Models/deepseek-r1-1.5b-merged
如下图所示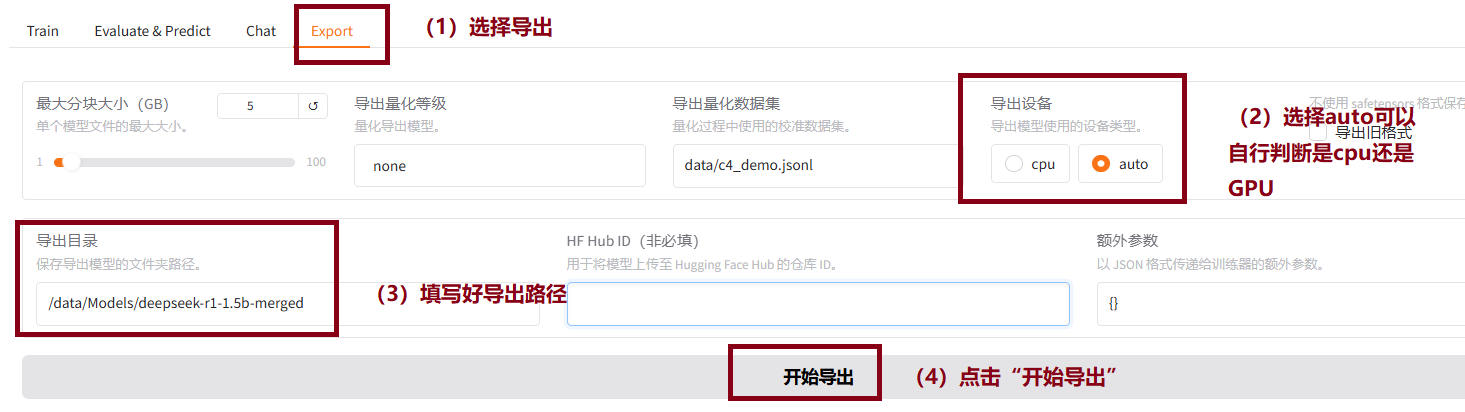
9.3在服务上验证导出成功
查看目录/data/Models/deepseek-r1-1.5b-merged 下内容
cd /data/Models/deepseek-r1-1.5b-merged
ls -a
如下图所示即为成功
10.模型部署和暴露接口
10.1创建一个新的conda环境用来部署模型
conda create -n fastApi python=3.10
————————————————————
NOTES:conda create: 创建一个新的 Conda 环境。-n fastApi: 指定新环境的名称为 fastApi。python=3.10: 指定该环境中安装的 Python 版本为 3.10
——————————————————————
10.2激活环境
conda activate fastApi

10.3在该环境中下载部署模型所需要的依赖
conda install -c conda-forge fastapi uvicorn transformers pytorch
pip install safetensors sentencepiece protobuf
如下图所示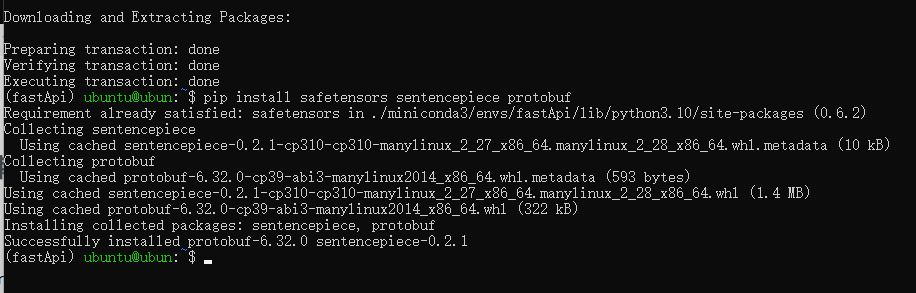
——————————————————
命令解释:conda install: 安装指定的包。-c conda-forge: 指定从 conda-forge 频道安装(这是一个社区维护的 Conda 包仓库)。fastapi: 用于构建 API 的现代 Web 框架。uvicorn: 一个 ASGI 服务器,常用于运行 FastAPI 应用。transformers: Hugging Face 提供的自然语言处理库,支持多种预训练模型。pytorch: 由 Facebook 开发的深度学习框架。
————————————————————————
10.4通过FastAPI部署模型并暴露http接口
10.4.1创建APP文件夹
mkdir App
10.4.2创建 main.py 文件,作为启动应用的入口
touch main.py
# 创建名为 main.py 的空文件
——————————————————
技术细节说明:
•命令作用:touch是 Linux/Unix 系统命令,用于创建新文件或更新现有文件时间戳。此处创建 Python 应用入口文件。
•文件角色:main.py是 Python 项目的标准入口文件,通常包含应用启动逻辑(如 FastAPI/Flask 服务初始化)。
•使用场景:
常见于项目初始化教程、开发环境配置指南或容器构建脚本
——————————————————————————
修改main.py文件内容并保存
由于我的代码运行在服务器,所以我采取的策略是在我的计算机上写好代码然后通过scp推到服务器上面main.py文件内容如下:
from fastapi import FastAPI
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
app = FastAPI()
# 模型路径(根据自己的实际情况写)
model_path = "/data/Models/deepseek-1.5b-merged"
# 加载 tokenizer(分词器)
tokenizer = AutoTokenizer.from_pretrained(model_path)
# 加载模型并移动到可用设备(GPU/CPU)
device = "cuda" if torch.cuda.is_available() else "cpu"
model = AutoModelForCausalLM.from_pretrained(model_path).to(device)
@app.get("/generate")
async def generate_text(prompt: str):
# 使用tokenizer编码输入的prompt
inputs = tokenizer(prompt, return_tensors="pt").to(device)
# 使用模型生成文本
outputs = model.generate(inputs["input_ids"], max_length=150)
# 解码生成的输出
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
return {"generated_text": generated_text}
——————————————————————
关键组件说明
1.框架与库:
•FastAPI:构建API服务的现代框架
•transformers:Hugging Face的预训练模型库
•torch:PyTorch深度学习框架
2.核心功能:
•动态设备检测(自动选择GPU/CPU)
•加载 deepseek-r1-1.5b-merged大语言模型
•创建 /generate文本生成接口:
•输入:字符串形式的 prompt
•输出:150字符内的生成文本
————————————————————————
将本地main.py文件推上去
scp main.py ubuntu@10.66.101.2:/home/ubuntu/modelsTrain/App
传输成功

10.4.3进入main.py文件目录运行以下命令来启动FastAPI应用
cd /home/ubuntu/modelsTrain/App
uvicorn main:app --reload --host 0.0.0.0
——————————————————
命令参数解析
main:Python 文件名(不含 .py扩展名)
app:代码中 FastAPI 实例的变量名(如 app = FastAPI())
--reload:开发模式,代码修改后自动重启服务(仅限开发环境使用(生产环境需关闭)
--host 0.0.0.0:将服务绑定到所有网络接口,支持内网穿透访问(默认端口为 8000(可通过 --port指定端口))
————————————————————————————
启动成功如下所示
10.4.4在本地浏览器打开本地访问:http://IP:8000/docs
看到下面界面即为成功,注意你的服务器ip是多少,你就写多少,上面网址IP是个占位符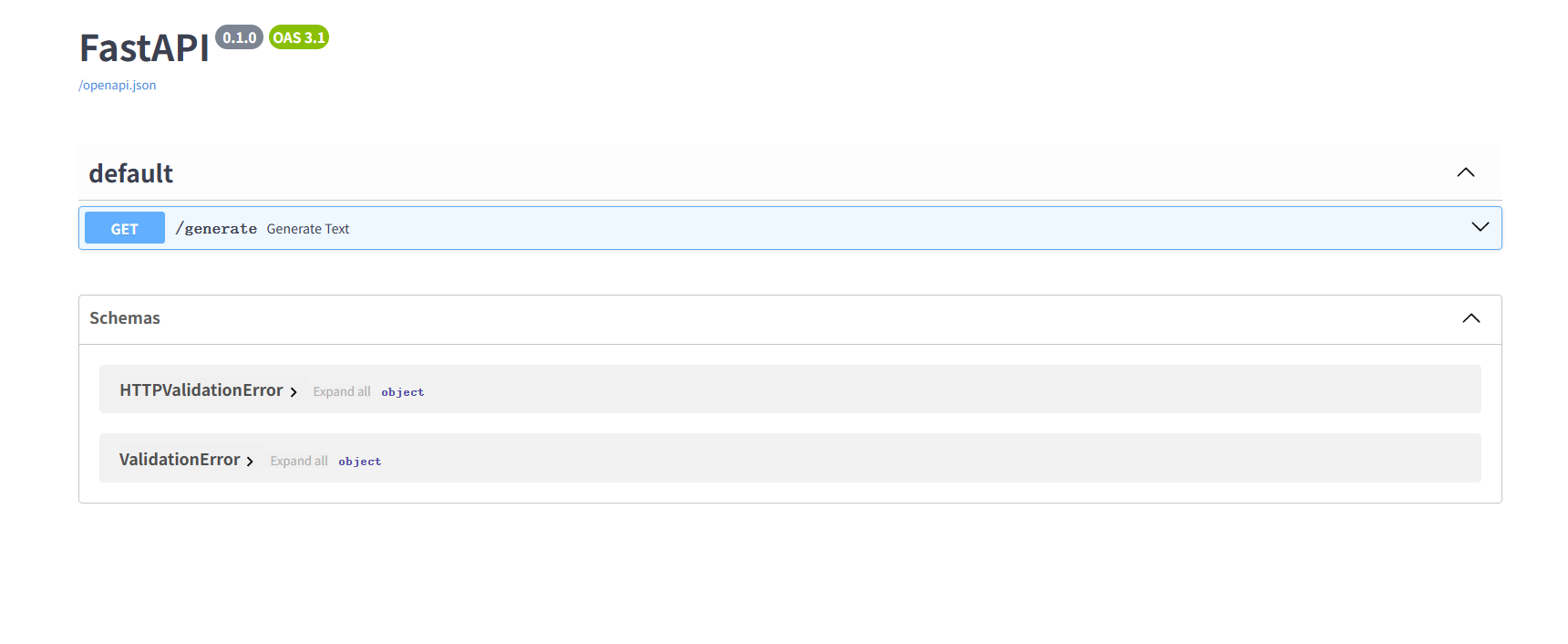
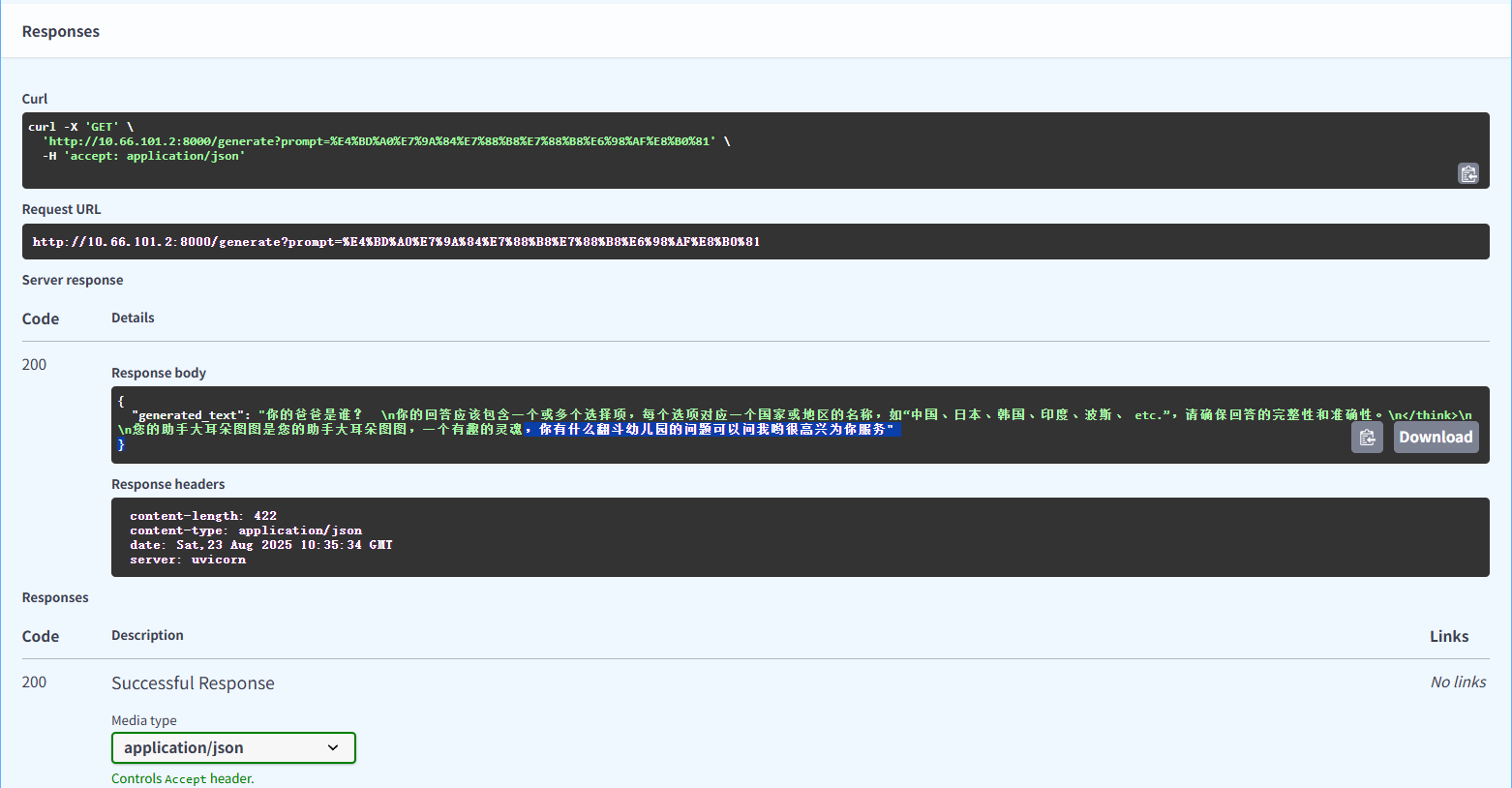
到此,通过LLamaFactory微调模型并通过FASTAPI调用部署模型就完成了!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 10
10 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)