大模型科普专栏 · 一文吃透LLM后训练“三驾马车”:SFT、RLHF、RAG
随着大模型技术发展,SFT、RLHF和RAG已成为提升模型性能的三大核心技术。SFT通过监督微调让通用模型适应专业任务,核心技术包括LoRA等参数高效微调方法。RLHF基于人类反馈优化模型输出,使其更符合人类价值观,但面临数据成本高等挑战。RAG通过检索外部知识库解决模型知识滞后问题,实现动态知识更新。三大技术相互补充:SFT奠定基础能力,RLHF确保安全性,RAG扩展知识边界。
目录
二、RLHF:基于人类反馈的强化学习 —— 让 AI 更“合乎人意”
引言:为什么90%的开发者都在卷“后训练”?
2023 年以前,大家还在拼谁家底座模型大。
2024 年开始,风向变了——“不会后训练,等于不会用 LLM”。
到 2025 年,更是卷出了新高度:
-
医疗垂域模型把诊断准确率从 77% 干到 90%;
-
小红书用 RLHF 把训练吞吐提升 30 倍;
-
哈啰出行 RAG 客服 6 ms 响应,准确率 95%。
如果你还在“开箱即用”ChatGPT,那只能叫“调包侠”;真正的高手都在玩后训练。
今天这篇文章,就带你一口气拆解 SFT(监督微调)→ RLHF(人类反馈强化学习)→ RAG(检索增强生成) 三大技术
在人工智能快速发展的今天,大模型(Large Language Models,LLMs)已经成为推动技术进步的重要引擎。从 ChatGPT 到 Claude,从文生图到多模态 Agent,这些“聪明”的系统背后都有一系列关键技术在支撑。
在大模型应用落地的过程中,SFT(监督微调)、RLHF(基于人类反馈的强化学习)、RAG(检索增强生成) 被视为三大核心方法。它们分别解决了大模型的 适配、对齐、知识增强 三大难题。
本文将从基础原理到应用场景,带你系统了解这三大技术。
一、SFT:监督微调 —— 从“通用”到“专业”
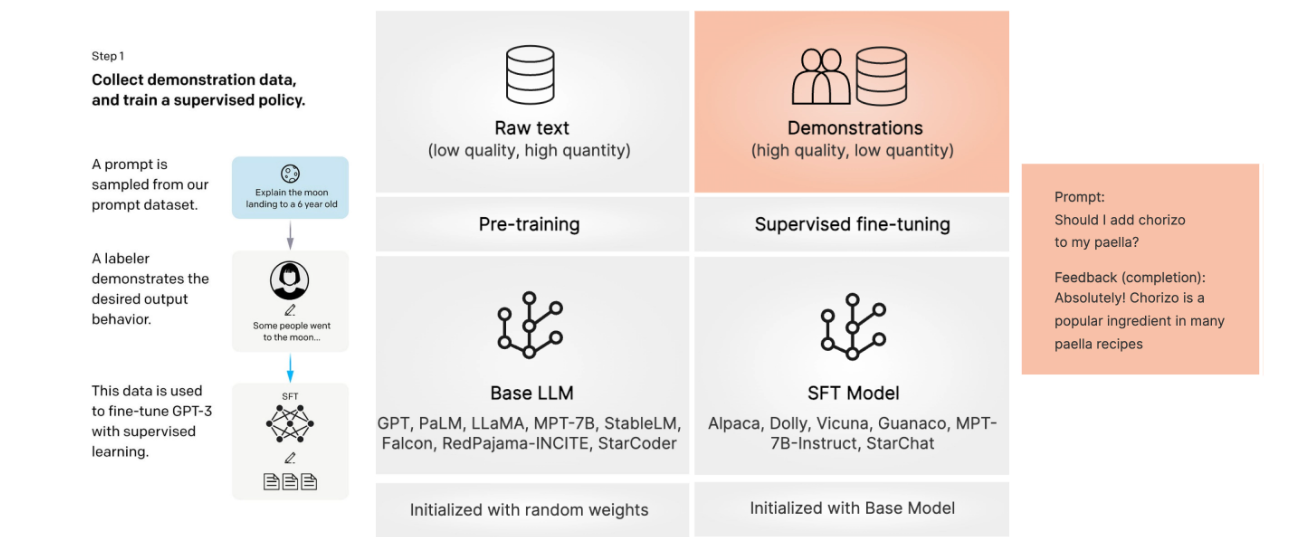
1. 什么是 SFT?
SFT(Supervised Fine-Tuning,监督微调)是大模型在预训练之后的 第一步精调。
预训练的大模型虽然知识广泛,但往往“懂很多却不太会回答问题”,比如用户问“帮我写一个 Python 爬虫”,模型可能给出一个不完整的答案。
SFT 的思路就是:
-
收集人工编写的 高质量指令-回复对(Instruction-Response) 数据集;
-
用这些数据来训练模型,让它学习 如何根据用户需求给出有条理的回答。
可以理解为:预训练让模型学会“读书识字”,而 SFT 让模型学会“怎么回答问题”。
2. 技术要点
-
数据:以人工标注或合成的对话数据为主,如 Alpaca、ShareGPT 数据集。
-
方法:常见有全参数微调(Full Fine-Tuning)与参数高效微调(PEFT, 如 LoRA)。
-
目标:让模型更符合用户的 指令习惯,提升可用性。
3. 开山鼻祖——LoRA 原理解码
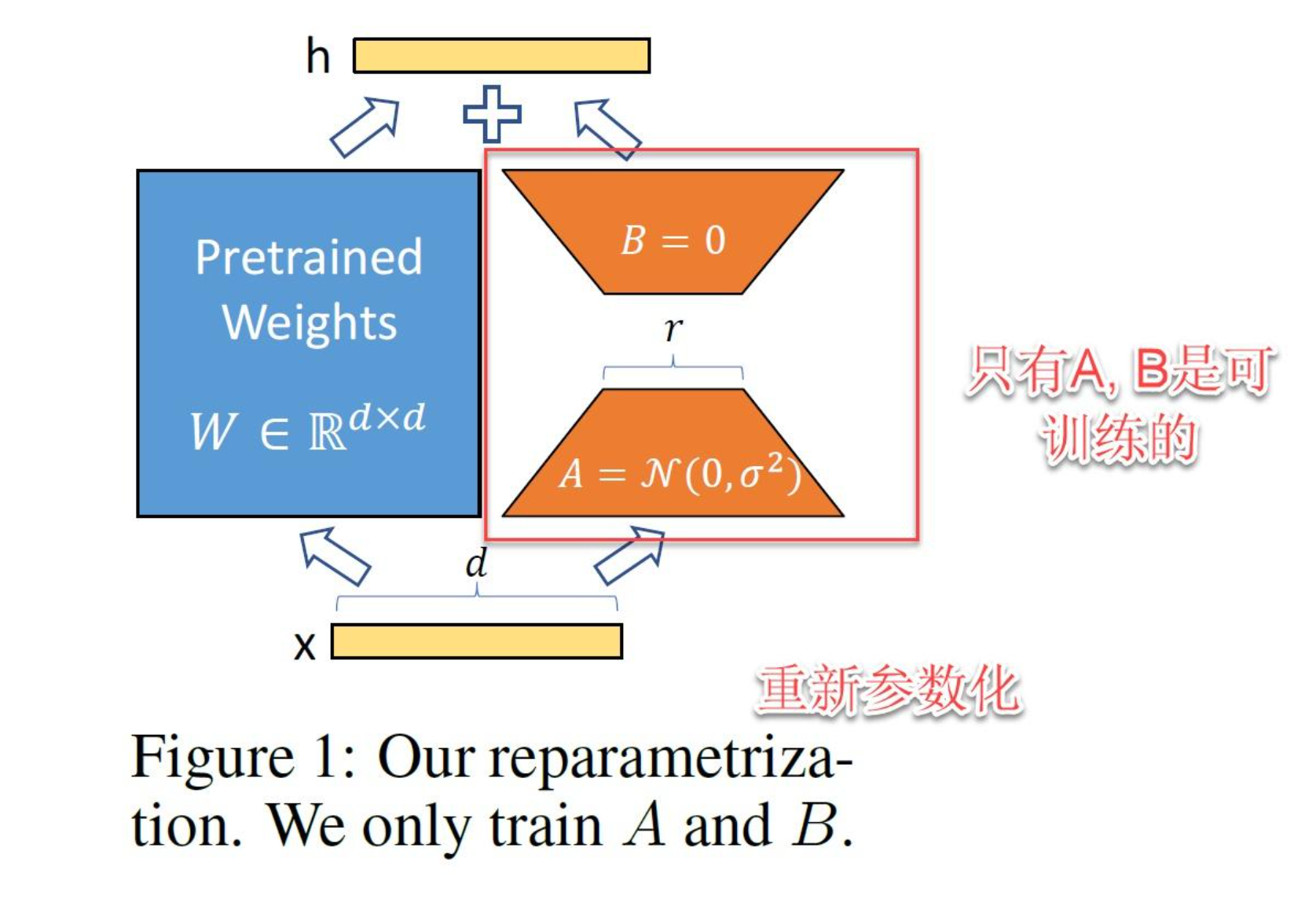
-
公式:
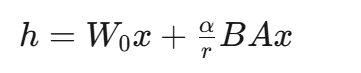
其中 r 为秩,常见 4~64,显存直接降到 1/10。
4. 应用场景
-
Copilot 类代码助手
-
AI 写作、智能客服
-
特定领域问答(医疗、法律、金融)
🔑 一句话总结:SFT 让模型从“能读懂”到“会回答”,是大模型落地的第一块基石。
二、RLHF:基于人类反馈的强化学习 —— 让 AI 更“合乎人意”
1. 为什么需要 RLHF?
经过 SFT 后,模型已经能回答问题了,但它的答案可能:
-
太啰嗦 / 太简略
-
有逻辑错误
-
含有偏见或不符合价值观
因此需要一种机制,让模型不仅“会说”,还要“说得好、说得对”。这就是 RLHF(Reinforcement Learning with Human Feedback)的作用。
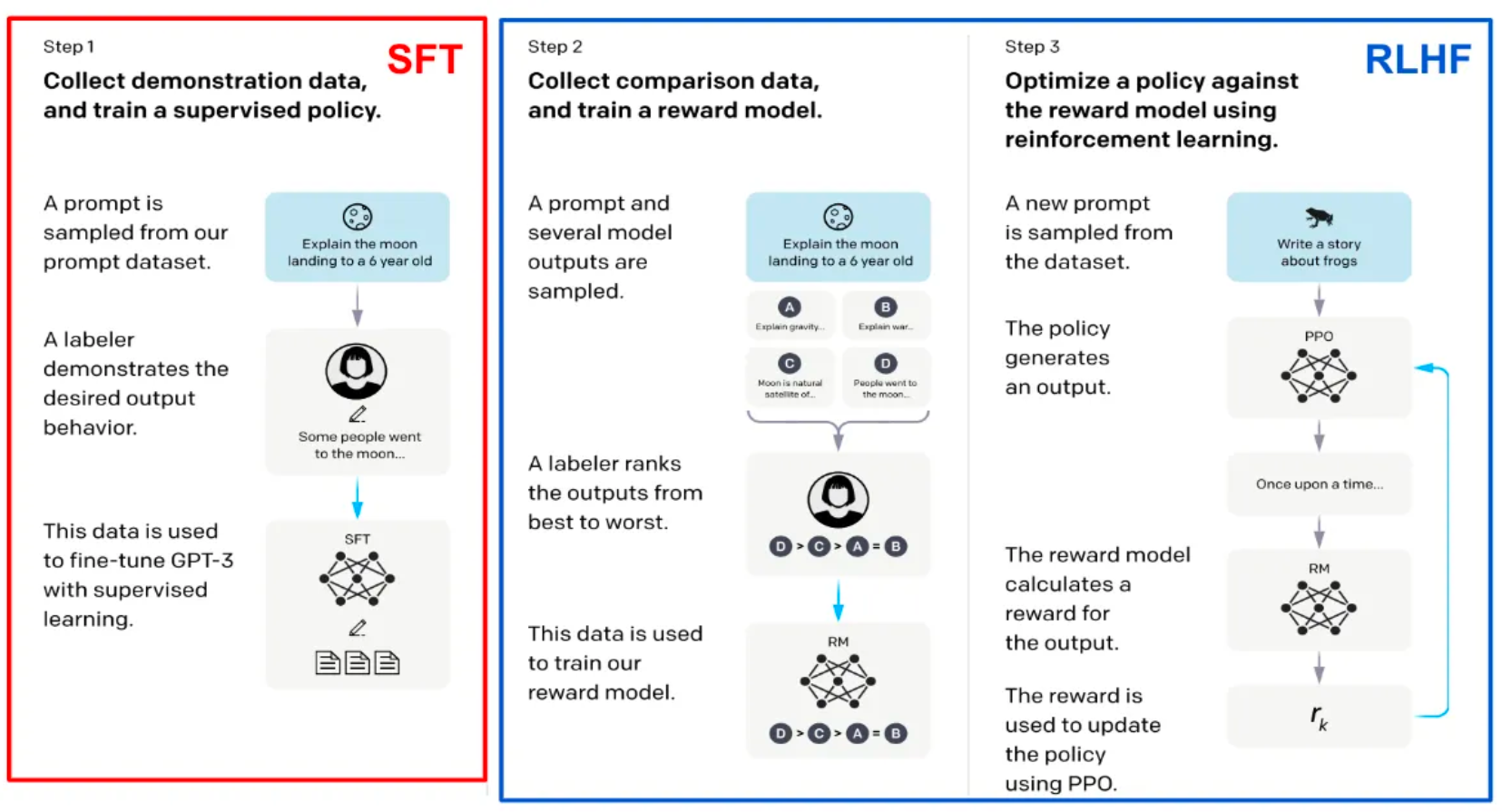
2. RLHF 的工作流程
RLHF 通常包含三步:
-
SFT:先做监督微调,得到一个基础的指令模型。
-
奖励模型(Reward Model)训练:让人类标注者对不同回答打分,模型学习一个“偏好打分器”。
-
强化学习(RL)优化:用 PPO(Proximal Policy Optimization)等算法,让模型倾向于输出“高分回答”。
可以理解为:SFT 教 AI “会回答”,而 RLHF 教 AI “回答得合乎人类喜好”。
3. 技术难点
-
数据成本高:需要大量人工标注。
-
奖励模型偏差:标注者的偏见可能被放大。
-
训练复杂度高:强化学习的稳定性和算力开销不容小觑。
4. 应用场景
-
ChatGPT 对话优化(更友好、更安全)
-
搜索引擎的答案排序
-
智能客服系统的满意度提升
🔑 一句话总结:RLHF 让模型从“会回答”到“合人意”,提升安全性与价值对齐,是大模型走向可控与可信的关键。
三、RAG:检索增强生成 —— 给大模型装上“外脑”
1. 为什么需要 RAG?
即便是参数上百亿的 GPT-4,也有一个致命缺陷:知识滞后与幻觉问题(Hallucination)。
比如 GPT-3.5 的知识截止到 2021 年,它无法准确回答“2024 奥运会在哪举办”。
解决方法:让大模型在生成答案之前,先去“查资料”。这就是 RAG(Retrieval-Augmented Generation,检索增强生成)。
2. RAG 的工作机制
-
用户提问:例如“请介绍下 2025 年最火的开源大模型”。
-
检索模块:在外部知识库 / 向量数据库(如 FAISS、Milvus)中找到相关文档。
-
增强生成:将检索到的内容与问题一起输入大模型,生成更准确的答案。
可以理解为:RAG 给模型加了一本“动态百科全书”,让它随时获取最新知识。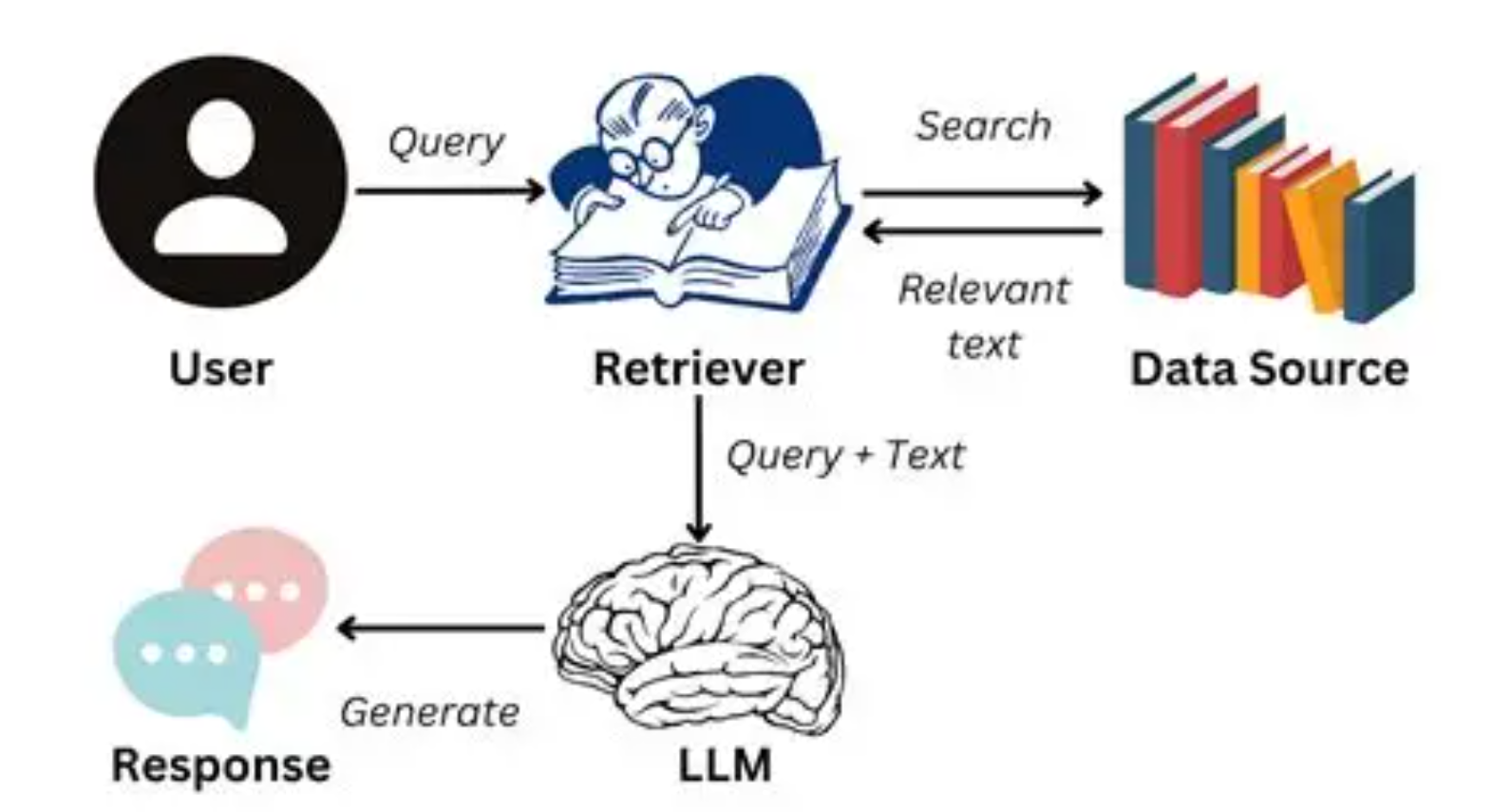
3. 技术要点
-
知识库构建:将文档转为向量存储。
-
检索方法:语义检索(Dense Retrieval)比关键词检索更强。
-
融合方式:常见为“检索后拼接输入(Concatenation)”。
4. 应用场景
-
企业知识库问答(金融、医疗、法律)
-
智能搜索引擎
-
AI Agent 的“工具调用”环节
🔑 一句话总结:RAG 让模型从“背书”变成“查资料”,解决了知识更新与幻觉问题。
四、三者之间的关系
-
SFT:解决“如何回答”,让模型从预训练的通用能力到具体指令任务。
-
RLHF:解决“回答得是否合人意”,确保输出符合人类价值观与安全性。
-
RAG:解决“知识更新与准确性”,让模型不再受限于训练数据的时效性。
三者往往是 互补关系:
👉 SFT 打地基 → RLHF 做对齐 → RAG 增强知识。
一个强大的 AI 系统,往往三者兼备。
五、总结
-
SFT:让模型学会按照指令作答,是大模型落地的第一步。
-
RLHF:通过人类反馈与强化学习,让 AI 回答更符合人类偏好与价值观。
-
RAG:让模型接入外部知识库,突破“知识时效与幻觉”的限制。
可以说,SFT、RLHF、RAG 共同构成了大模型应用的“三驾马车”:
-
没有 SFT,模型不会用;
-
没有 RLHF,模型不可靠;
-
没有 RAG,模型不够新。
未来,随着 AI Agent 的普及,这三大技术将进一步融合,为大模型应用创造更广阔的空间。
🙌 以上就是本文的分享,希望能帮你快速理解 SFT、RLHF、RAG 这三大关键技术。
如果你觉得有收获,可以点个赞 👍 或收藏 📌,后续我会继续更新大模型相关的技术文章。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 7
7 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)