6G显存也能流畅运行大模型?实战Qwen量化部署
随着大模型技术席卷全球,越来越多的开发者渴望能在自己的设备上运行一个专属的、私有的大模型。然而,迈向本地部署的第一步,往往也是最令人头疼的一步——硬件限制。其中,GPU显存(VRAM)就是那道最关键的门槛。今天,我们就来解决这个核心问题:如何根据有限的显存,选择并优化一个合适的大模型?简单来说,就是给模型"瘦身"。减少显存占用:精度减半,模型体积和显存占用也近乎减半提升推理速度:低精度计算更快,尤
你是否也曾被大模型的"军备竞赛"劝退?看着动辄需要A100、H800的硬件要求,感觉本地部署大模型遥不可及?别担心,今天这篇文章将彻底改变你的看法。我们将以一块非常普遍的6G显存RTX 3060笔记本显卡为例,手把手教你如何通过精妙的优化策略,在"平民"设备上流畅运行强大的Qwen大模型。这不仅仅是一次技术演示,更是为你打开本地AI应用开发大门的一把钥匙。
以下内容节选自作者的新书《Python 大模型优化策略:理论与实践》,干货满满,让我们开始吧!
前言
随着大模型技术席卷全球,越来越多的开发者渴望能在自己的设备上运行一个专属的、私有的大模型。然而,迈向本地部署的第一步,往往也是最令人头疼的一步——硬件限制。其中,GPU显存(VRAM)就是那道最关键的门槛。
今天,我们就来解决这个核心问题:如何根据有限的显存,选择并优化一个合适的大模型?
1. 知己知彼:你的GPU能跑多大的模型?
在谈论模型之前,我们得先摸清自己"家底"。GPU显存的大小,直接决定了我们能加载的模型参数量的上限。
想知道你的NVIDIA显卡有多少显存?非常简单,打开你的命令行终端(CMD或PowerShell),输入以下命令:
nvidia-smi
你会看到类似下面的输出结果。从图中我们可以清晰地看到,这台设备的显卡型号是 RTX 3060,总显存为 6144MiB,也就是我们常说的 6GB 显存。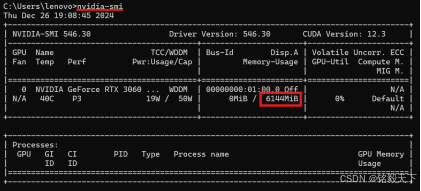
那么,6GB显存到底意味着什么?
这需要我们理解模型参数和显存占用的关系。在深度学习中,模型参数通常以浮点数形式存储。
- 32位浮点数 (FP32):每个参数占用4个字节
- 16位浮点数 (FP16):每个参数占用2个字节
让我们来算一笔账:假设一个模型有10亿(1B)个参数,如果用FP32加载,光是模型参数本身就需要 10亿 × 4字节 = 4GB 的显存。如果用FP16,则需求减半,只需要 2GB。
这还只是模型参数的静态占用,实际运行时,还需要额外的显存来存储中间计算结果(激活值)、梯度等。所以,选择模型时必须留有余地。
2. 模型选择:遇见强大的Qwen
了解了硬件限制后,我们该选择哪个模型呢?这里我向大家推荐阿里巴巴推出的 Qwen系列模型。
Qwen系列覆盖了从0.5B到72B的多种参数规模,性能在多个权威评测基准上都名列前茅,特别是在长文本、数学和代码能力上表现优异。最关键的是,它为我们这些硬件资源有限的开发者提供了小参数量的优质选项。

根据我们的实际测试,对于6GB显存的RTX 3060,一个30亿(3B)参数的模型是一个比较理想的起点。
3. 性能优化的"魔法":模型量化入门
选好了3B的模型,直接用FP32加载可能会发现显存依然紧张,而且推理速度不尽人意。这时,我们就需要请出性能优化的"魔法"——模型量化 (Quantization)。
什么是模型量化?
简单来说,就是给模型"瘦身"。它通过降低模型计算的精度,例如从高精度的32位浮点数(FP32)降低到16位浮点数(FP16)甚至是8位整数(INT8),来达到以下目的:
- 减少显存占用:精度减半,模型体积和显存占用也近乎减半
- 提升推理速度:低精度计算更快,尤其是在支持相关指令集的现代GPU上
量化的两大类型
模型量化主要分为两大类:
训练后量化 (Post-Training Quantization, PTQ)
这是最简单直接的方式。在模型训练完成后,直接将其权重和激活值转换为低精度。
- 优点:操作简单,无需重新训练
- 缺点:可能会有轻微的精度损失
量化感知训练 (Quantization-Aware Training, QAT)
在训练过程中就引入模拟量化的操作,让模型"适应"低精度计算。
- 优点:能最大程度地保留模型精度
- 缺点:需要重新训练,成本更高
对于我们本地部署推理的场景,PTQ 通常是性价比最高的选择。
当然,量化并非毫无挑战。我们需要关注精度损失是否在可接受范围内,并考虑硬件对不同量化类型(如INT8)的支持程度。但对于从FP32到FP16的转换,现代GPU都提供了很好的支持,且精度损失极小。
4. 实战对比:FP32 vs FP16,效果与速度的权衡
口说无凭,实验为证!我们将Qwen2.5-3B模型部署到RTX 3060上,用同一个问题进行测试,看看量化前后的天壤之别。
测试问题:“请介绍什么是大模型”
测试组一:FP32 (32位浮点数) 全精度模式
模型回复:
大模型是指具有强大计算能力和复杂算法的模型,通常用于自然语言处理、图像识别、语音识别等领域。大模型可以处理大量的数据,并通过深度学习等技术进行训练,从而实现更准确、更高效的预测和决策。大模型的发展和应用,为人工智能领域带来了巨大的变革和进步。
推理用时:37.5秒
测试组二:FP16 (16位浮点数) 量化模式
模型回复:
大模型是指具有强大计算能力和复杂算法的模型,通常用于自然语言处理、图像识别、语音识别等领域。大模型可以处理大量的数据,并通过深度学习等技术进行训练,从而实现更准确、更高效的预测和决策。大模型的出现,为人工智能的发展带来了新的机遇和挑战。
推理用时:4.6秒
结果分析
从实验结果看,FP16量化后的模型回复与FP32版本在语义和质量上几乎没有差别。但性能上的提升是惊人的:
- 推理速度提升了约 8.15 倍!(37.5s → 4.6s)
- 显存占用降低了近一半!
这个结果有力地证明,通过简单的量化优化,我们成功地让一块6GB显存的"甜品级"显卡,流畅地运行了一个效果出色的3B大模型。在实际应用中,我们可以选择一些更为极端的量化方式,例如int8量化、int4量化,更大程度的压缩显存占用。但量化精度过低,会造成大模型回复的效果变差。
总结与展望
通过今天的分享,我们一起见证了如何在有限的硬件上,通过合理的模型选择和关键的量化技术,实现大模型的本地化部署。这不再是顶级玩家的专属,而是我们每个开发者都可以触及的未来。
当然,今天所讲的,仅仅是大模型优化世界中的冰山一角。
除了量化,还有哪些更极致的优化技术,大模型的参数又能通过哪些方式来进行优化?
这些所有这些问题的答案,以及更多系统、深入的理论知识和实践案例,都在《Python 大模型优化策略:理论与实践》中。
如果你对大模型技术充满热情,希望系统地掌握从理论到实战的全链路优化知识,那么这本书将是你不可多得的良师益友。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 7
7 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)