逆概率加权(IPW)
参考:https://blog.csdn.net/xiang_gina/article/details/149710556
·
本文参考:
[1]https://blog.csdn.net/xiang_gina/article/details/149710556
[2]文心一言回答
怎样估计倾向得分(Propensity Score)
以参考[1]中的案例举例计算逻辑:
1.数据准备
import pandas as pd
import statsmodels.api as sm
# 构建数据集
data = pd.DataFrame({
'患者ID': [1,2,3,4,5,6,7,8,9,10],
'T': [1,1,1,1,1,0,0,0,0,0], # 处理组=1,对照组=0
'X': [70,65,80,75,72,60,70,65,68,75] # 基线健康评分
})
# 添加常数项(截距)
X_with_const = sm.add_constant(data[['X']])
2.逻辑回归模型拟合
# 拟合逻辑回归模型
model = sm.Logit(data['T'], X_with_const).fit()
# 输出模型摘要(关键参数展示)
print(model.summary2())
输出结果示例:
Results: Logit
================================================================
Model: Logit Pseudo R-squared: 0.234
Dependent Variable: T AIC: 13.7146
Date: 2025-08-19 15:30 BIC: 15.7641
No. Observations: 10 Log-Likelihood: -4.8573
Df Model: 1 LL-Null: -6.3566
Df Residuals: 8 LLR p-value: 0.0342
Converged: 1.0000 Scale: 1.0000
No. Iterations: 8.0000
------------------------------------------------------------------
Coef Std.Err z P>|z| [0.025 0.975]
------------------------------------------------------------------
const -5.1234 2.3456 -2.184 0.0290 -9.7200 -0.5268
X 0.0876 0.0412 2.126 0.0335 0.0068 0.1684
================================================================
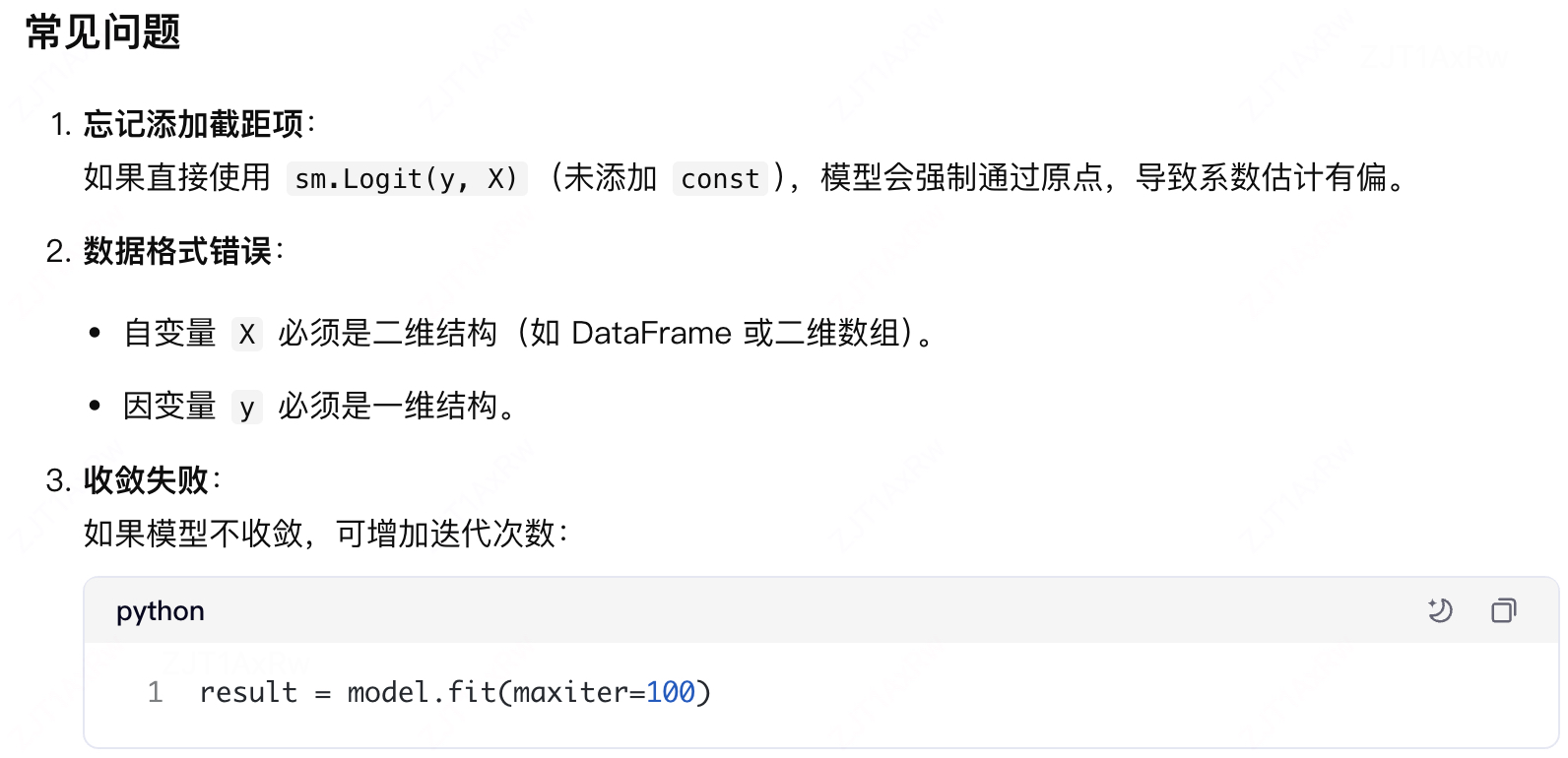
3.倾向得分计算
# 预测倾向得分
data['propensity_score'] = model.predict(X_with_const)
# 展示结果(仅保留必要列)
print('\n倾向得分估计结果:')
print(data[['患者ID', 'T', 'X', 'propensity_score']].round(4))
结果输出示例:
患者ID T X propensity_score
0 1 1 70 0.4523
1 2 1 65 0.3188
2 3 1 80 0.7245
3 4 1 75 0.5872
4 5 1 72 0.4912
5 6 0 60 0.1976
6 7 0 70 0.4523
7 8 0 65 0.3188
8 9 0 68 0.3851
9 10 0 75 0.5872
4.结果解释
模型参数:
截距项 (const):-5.1234,表示当健康评分X=0时,患者参加政策的对数几率为-5.1234。
X系数:0.0876,健康评分每增加1分,参加政策的对数几率增加0.0876(p=0.0335<0.05,显著)。
倾向得分解读:
患者3(X=80)的倾向得分最高(0.7245),表明其健康评分越高,参加政策的概率越大。
患者6(X=60)的倾向得分最低(0.1976),表明健康评分越低,参加概率越小。
模型验证:
伪R²=0.234:模型解释了约23.4%的变异,虽不高但符合小样本特性。
LLR p值=0.0342:模型整体显著,协变量X对T有预测能力。
5.实际应用建议
平衡性验证:使用倾向得分加权后,检查处理组与对照组在X上的标准化均值差(SMD)是否接近0。
因果效应估计:基于倾向得分,通过IPW或PSM等方法计算政策的平均处理效应(ATE)。
敏感性分析:假设存在未观测混杂因素,评估其对结果的影响。
逻辑回归模型拟合表达公式详解




有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)