姿态估计进阶:从 YOLO-NAS Pose 到 YOLOv8 Pose的技术探索与实践
摘要: YOLO-NAS Pose是Deci AI基于神经架构搜索(NAS)技术开发的新一代姿态估计模型,通过AutoNAC引擎优化架构,在精度与效率上超越YOLOv8 Pose。该模型提供四种尺寸变体,适配不同硬件需求,支持图像、视频等多源数据输入。实验显示其在直立人形检测中表现优异,但在水平姿态场景下略逊于YOLOv8。此外,文章还探讨了基于YOLOv8 Pose的瑜伽姿势分类实践,包括数据集
引言
在计算机视觉领域的持续演进中,姿态估计技术始终是研究与应用的热点。在前序文章《姿态估计简化:关键点检测与空间理解》中,我们已从关键点检测与空间理解的角度,深入剖析了包括YOLOv8 Pose在内的一系列主流模型,并与当时最先进的技术进行了横向对比。本文将在此基础上更进一步,聚焦于Deci AI最新发布的YOLO-NAS Pose模型——这款基于神经架构搜索(NAS)技术的姿态估计模型,正重新定义着该领域的性能边界。
Deci AI作为人工智能领域的创新者,致力于通过提供先进工具简化计算机视觉、生成式AI及自然语言处理(NLP)应用的开发流程。其核心产品包括模型构建、优化与部署平台,以及开源的SuperGradients库。该库基于PyTorch框架,旨在赋能AI社区,通过增强模型性能与简化训练流程,助力研究者与开发者轻松应用最先进(SOTA)的计算机视觉模型。
姿态估计技术的演进历程
姿态估计作为计算机视觉的关键分支,负责解析图像中实体的空间方向与相互关系,在人机交互、动作分析、医疗康复等领域具有不可替代的价值。回顾技术发展脉络,AlphaPose、OpenPose、Detectron2等里程碑式模型不断推动着领域进步。而YOLOv8 Pose凭借Ultralytics框架的优势,以其卓越的实时性与准确性脱颖而出,成为行业标杆。
如今,YOLO-NAS Pose的问世标志着姿态估计技术迈入新阶段。该模型继承了YOLO系列的优良基因,更通过神经架构搜索技术实现了精度与效率的双重突破,为姿态估计任务设立了新的技术标准。
YOLO-NAS Pose:技术解析与性能基准
核心技术优势
YOLO-NAS Pose站在YOLOv8的肩膀上实现了跨越式发展。它保留了YOLOv8在速度与精度方面的核心优势,同时通过Deci自主研发的AutoNAC NAS引擎进行架构优化,结合前沿训练技术,打造出专为姿态估计任务定制的高效模型。这种技术协同不仅提升了模型性能,更在速度与精度的平衡上实现了突破性设计。
模型变体与硬件适配
YOLO-NAS Pose提供四种不同尺寸的模型变体,以满足多样化的计算需求与性能场景:
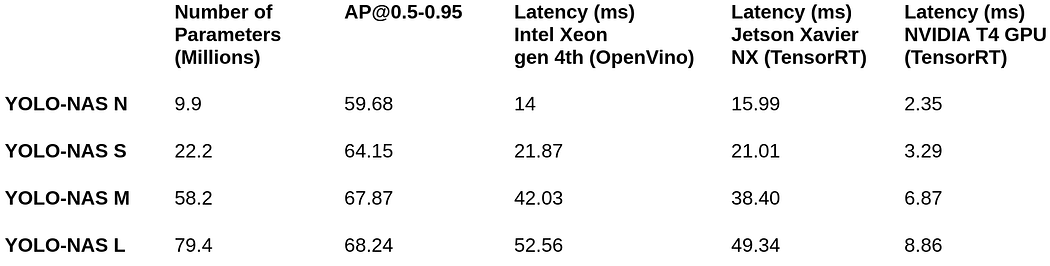
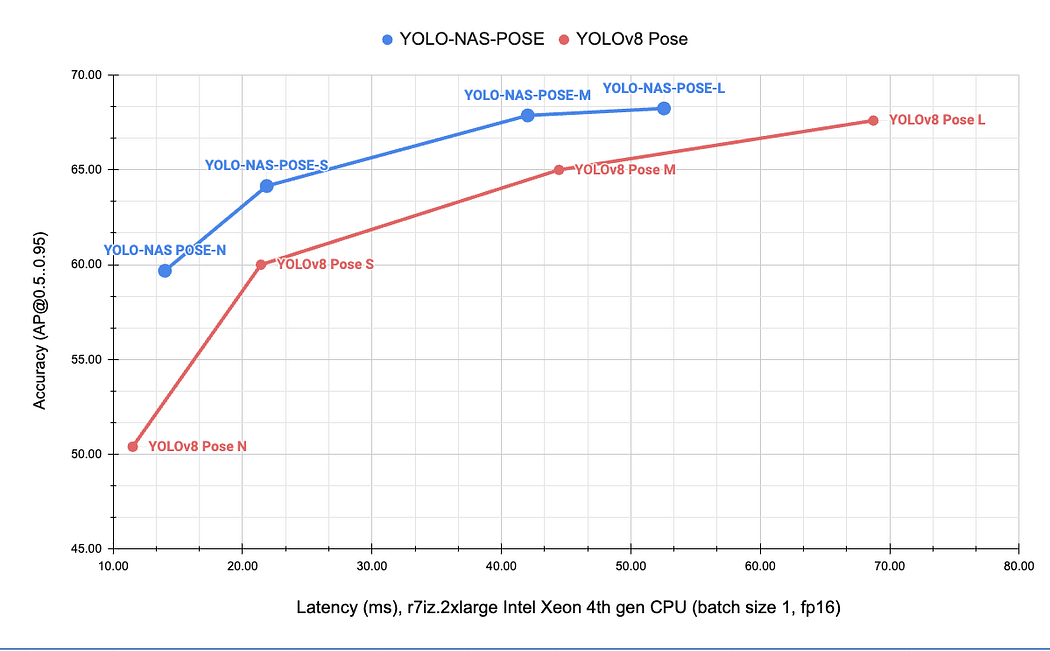
这些模型共同构成了姿态估计效率的新标杆,大幅扩展了实际应用中性能与经济性的平衡边界。其技术先进性可通过下图直观展现:
YOLO-NAS Pose实践指南
Deci AI官方提供了两份详尽的实践笔记本,分别覆盖模型推理(链接)与训练(链接)流程。本文将聚焦于如何通过极简代码实现多源数据的姿态估计部署,包括静态图像、视频流及URL图像等场景。
环境配置
首先安装必要的库与依赖项:
!pip install git+https://github.com/Deci-AI/super-gradients.git@feature/SG-1060-yolo-nas-pose
!pip install -U git+https://github.com/ytdl-org/youtube-dl.git
支持的数据源类型
根据SuperGradients框架文档(参考链接),YOLO-NAS Pose支持多种常见数据源:

基础使用示例
import torch
from super_gradients.training import models
# 加载COCO关键点数据集预训练模型
# 可用模型:yolo_nas_pose_n, yolo_nas_pose_s, yolo_nas_pose_l
yolo_nas_pose = models.get("yolo_nas_pose_l", pretrained_weights="coco_pose").cuda()
# 自动选择计算设备
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# 1. 本地图像处理
yolo_nas_pose.to(device).predict(
'hdlifepushups-crop.jpg',
conf=0.25,
iou=0.1
).save('output_path') # 图像来源:https://www.eehealth.org/-/media/images/modules/blog/posts/2018/4/hdlifepushups-crop.jpg
# 2. 本地视频处理
yolo_nas_pose.to(device).predict(
'shuffle_dance.mp4',
conf=0.25,
iou=0.1
).save('shuffle_dance_labeled.mp4') # 视频来源:https://www.youtube.com/watch?v=IYm-n-vwhnw
# 3. 远程URL图像处理
yolo_nas_pose.to(device).predict(
'https://bod-blog-assets.prod.cd.beachbodyondemand.com/bod-blog/wp-content/uploads/2022/05/23121347/how-many-push-ups-in-a-day.960.jpg',
conf=0.25,
iou=0.1
).save('output_path')
实验结果与可视化
图像姿态估计结果

图片来源:https://mir-s3-cdn-cf.behance.net/project_modules/max_1200/4d222729493563.55f6420cd3768.jpg
视频姿态估计结果
YOLOv8 Pose与YOLO-NAS Pose深度对比
性能差异分析
YOLO-NAS Pose在处理直立人形时展现出卓越的速度与精度,其效率尤为突出——最大模型变体(YOLO-NAS-L Pose)在RTX 4060上以全精度运行时仅占用510MB显存。然而,实验观察发现其在特定场景下性能存在波动,尤其在处理水平方向人物时表现欠佳。对比分析显示,在此类场景中YOLOv8通常能更准确地估计姿态。

*左:YOLOv8可检测图像中所有人物及关键点。
左:YOLOv8可检测图像中所有人物及关键点
改进方向探讨
通过增强数据增强策略,有望提升YOLO-NAS Pose对水平姿态的检测性能。YOLOv8在该场景的优势主要源于其训练过程中采用的强效数据增强技术,这一策略可被借鉴以优化YOLO-NAS的模型表现。
基于YOLOv8 Pose的瑜伽姿势分类实践
应用背景
瑜伽作为一项兼具身心益处的古老练习,近年来全球普及率持续攀升。随着练习者对个性化指导需求的增长,能够自动分类瑜伽姿势的智能系统成为研究热点。本节将详细介绍如何利用YOLOv8 Pose实现图像与视频中瑜伽姿势的精准分类。
源代码仓库:[待补充具体链接]
技术实现路径
1. YOLOv8 Pose核心特性
YOLO(You Only Look Once)系列以实时性与高精度著称,YOLOv8 Pose作为其姿态估计专项版本,能够实时检测并分类人体关键点,为瑜伽姿势分类提供了理想的技术基础。
2. 数据集准备
构建高质量数据集是模型训练的前提,需包含多样化瑜伽姿势的图像/视频及对应的人体关键点标注。推荐采用结构化数据集组织方式,示例如下:

数据集来源:Roboflow瑜伽姿势数据集
3. Google Colab训练流程
步骤1:挂载Google Drive
from google.colab import drive
drive.mount('/content/drive')
步骤2:安装依赖库
%pip install ultralytics
import ultralytics
步骤3:数据集格式化
将数据集转换为YOLO格式,确保图像与标注文件路径对应。
步骤4:创建配置文件(data.yaml)
# data.yaml
train: /content/drive/MyDrive/yoga_data/train/images
val: /content/drive/MyDrive/yoga_data/val/images
nc: 5 # 类别数量(瑜伽姿势种类)
names: ['pose1', 'pose2', 'pose3', 'pose4', 'pose5'] # 替换为实际姿势名称
步骤5:启动训练
!yolo train model=yolov8n.pt data=data.yaml epochs=200 imgsz=640
训练完成后,模型权重将保存于/content/drive/MyDrive/runs/pose/train/weights/best.pt路径,可下载至本地用于后续推理。
4. 本地推理与部署
基于OpenCV的实时可视化
import numpy as np
from ultralytics import YOLO
import cv2
import cvzone
import math
import time
# 初始化摄像头或视频源
cap = cv2.VideoCapture(0) # 0表示默认摄像头,可替换为视频文件路径
# 加载自定义训练模型
model = YOLO("../models/best.pt") # 替换为实际模型路径
# 定义类别名称列表
classNames = ["Bitilasana", "Lotus Pose", "Tree Pose", ...] # 补充完整类别
# 帧率计算变量
prev_frame_time = 0
new_frame_time = 0
while True:
new_frame_time = time.time()
success, img = cap.read()
if not success:
break
# 模型推理
results = model(img, stream=True, verbose=False)
# 处理检测结果
for r in results:
boxes = r.boxes
for box in boxes:
# 提取边界框坐标
x1, y1, x2, y2 = box.xyxy[0]
x1, y1, x2, y2 = int(x1), int(y1), int(x2), int(y2)
w, h = x2 - x1, y2 - y1
# 绘制边界框与置信度
cvzone.cornerRect(img, (x1, y1, w, h))
conf = math.ceil((box.conf[0] * 100)) / 100
cls = int(box.cls[0])
cvzone.putTextRect(
img,
f'{classNames[cls]} {conf}',
(max(0, x1), max(35, y1)),
scale=1
)
# 计算并显示帧率
fps = 1 / (new_frame_time - prev_frame_time)
prev_frame_time = new_frame_time
print(f"FPS: {fps:.2f}")
# 显示结果
cv2.imshow("Yoga Pose Detection", img)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
极简推理方案
- 首先创建独立虚拟环境:
# 创建并激活环境(以conda为例)
conda create -n yoga-pose python=3.9
conda activate yoga-pose
pip install ultralytics
- 图像/视频推理代码:
from ultralytics import YOLO
# 加载模型
model = YOLO("../models/best.pt") # 自定义训练模型路径
# 图像推理
results = model(source='Yoga.jpg', save=True, conf=0.7)
# 视频推理
results = model(source='Yoga.mp4', save=True, conf=0.7)

预训练模型自定义标注
from ultralytics import YOLO
# 加载预训练姿态模型
model = YOLO('yolov8m-pose.pt')
# 定义类别映射字典
class_mapping = {
0: 'Pose1', # 键为类别ID,需根据实际模型调整
# 添加更多类别映射
}
# 执行推理并替换标签
results = model(source='Pose1.jpg')
for result in results:
for cls_id, custom_label in class_mapping.items():
if cls_id in result.names:
result.names[cls_id] = custom_label
# 保存带自定义标签的结果
results = model(source='Pose1.jpg', save=True, conf=0.7)
推理结果默认保存于runs/pose/predict目录。
结论与展望 ✨
YOLO-NAS Pose通过融合Deci AI的先进NAS技术,在姿态估计领域实现了显著突破,其在速度、精度与效率间的精妙平衡为行业树立了新标准。如本文所示,该模型在多源媒体上的部署便捷性使其先进功能能够快速落地于实际应用。尽管在水平目标检测等特定场景仍有提升空间(当前YOLOv8表现更优),但这也为未来优化指明了方向——借鉴YOLOv8的增强训练策略可能成为关键突破口。
同时,基于YOLOv8 Pose的瑜伽姿势分类实践证明,姿态估计技术在运动指导、健康监测等垂直领域具有广阔应用前景。随着模型架构持续优化与训练策略不断创新,姿态估计技术必将在更多实际场景中发挥核心作用,推动计算机视觉应用边界的持续拓展。


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 27
27 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

{kind=link}
所有评论(0)