港大月之暗面开源OpenCUA,一键克隆你的AI分身,24小时替你打工!
OpenCUA 是一个全面开源的计算机使用智能体(CUA)框架,旨在填补该领域的关键空白。标注基础设施数据处理流水线多样化数据集高效训练策略系统评估基准这些组件共同为 CUA 研究奠定了坚实基础。基于该框架训练的模型在多个基准任务中表现出色,并展现出明确的数据 Scaling Law 和强大的跨领域泛化能力。
近日,香港大学XLANG Lab联合月之暗面在arXiv发布最新论文,提出OpenCUA(Computer-Using Agent,计算机使用智能体)。
该框架包含三大核心模块:
- 支持跨平台操作记录的交互式标注工具
- 覆盖3大操作系统及200余款应用/网站的AgentNet大规模数据集
- 将操作演示转化为具备长思维链推理能力的"状态-动作"对的自动化处理流程
基于此框架研发的模型OpenCUA-32B,在OSWorld-Verified基准测试中取得34.8%的任务完成率,不仅刷新开源模型SOTA,更首次超越GPT-4o等闭源模型,标志着开源CUA技术取得突破性进展。
相关代码、数据和模型已开源
- arxiv地址:https://arxiv.org/abs/2508.09123
- 项目地址:https://opencua.xlang.ai/

OpenCUA框架架构与核心组件

OpenCUA作为首个面向计算机使用智能体(Computer-Using Agent, CUA)的全栈开源框架,构建了完整的研发闭环体系。其架构包含四大核心模块:
- AgentNet交互采集系统:跨操作系统用户行为捕捉工具,通过屏幕录制与操作流程捕获实现多平台交互数据采集
- 轨迹处理引擎:将原始演示转化为结构化"状态-动作"轨迹,整合推理逻辑与历史上下文
- AgentNet数据集与评估基准:**包含多样化任务的标准化数据集,提供含多路径黄金标准的离线评估方案
- OpenCUA智能体模型:经训练可执行真实环境计算机操作的端到端系统
AgentNet 数据集与测试基准
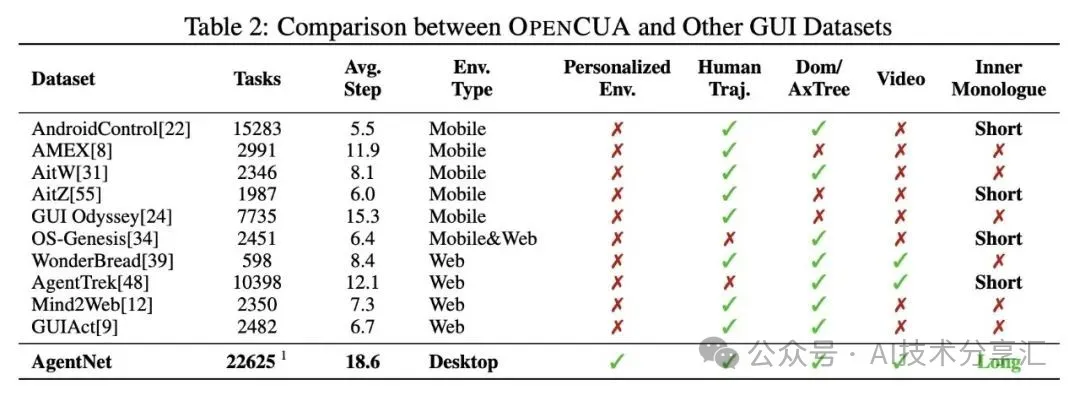
研究团队成功构建了 AgentNet 数据集 及其配套的 AgentNetBench 评估基准,是首个真实、复杂、多模态的桌面轨迹数据集
- 数据规模:数据集包含 22,625 条 人工精细标注的计算机操作任务轨迹,覆盖 140+ 款应用 与 190+ 个网站。
- 平台与多样性:任务分布均衡, (Win: ~12k, macOS: ~5k, Ubuntu: ~5k),适配 720p 至 4K 多种屏幕分辨率。
- 任务复杂度:每条轨迹平均 18.6 个操作步骤,真实反映现实任务的复杂性。
- 核心优势:AgentNet 是首个同时具备真实性、高复杂度、领域多样性及多模态特性的桌面端轨迹级数据集。
AgentNet 数据集中任务的领域分布
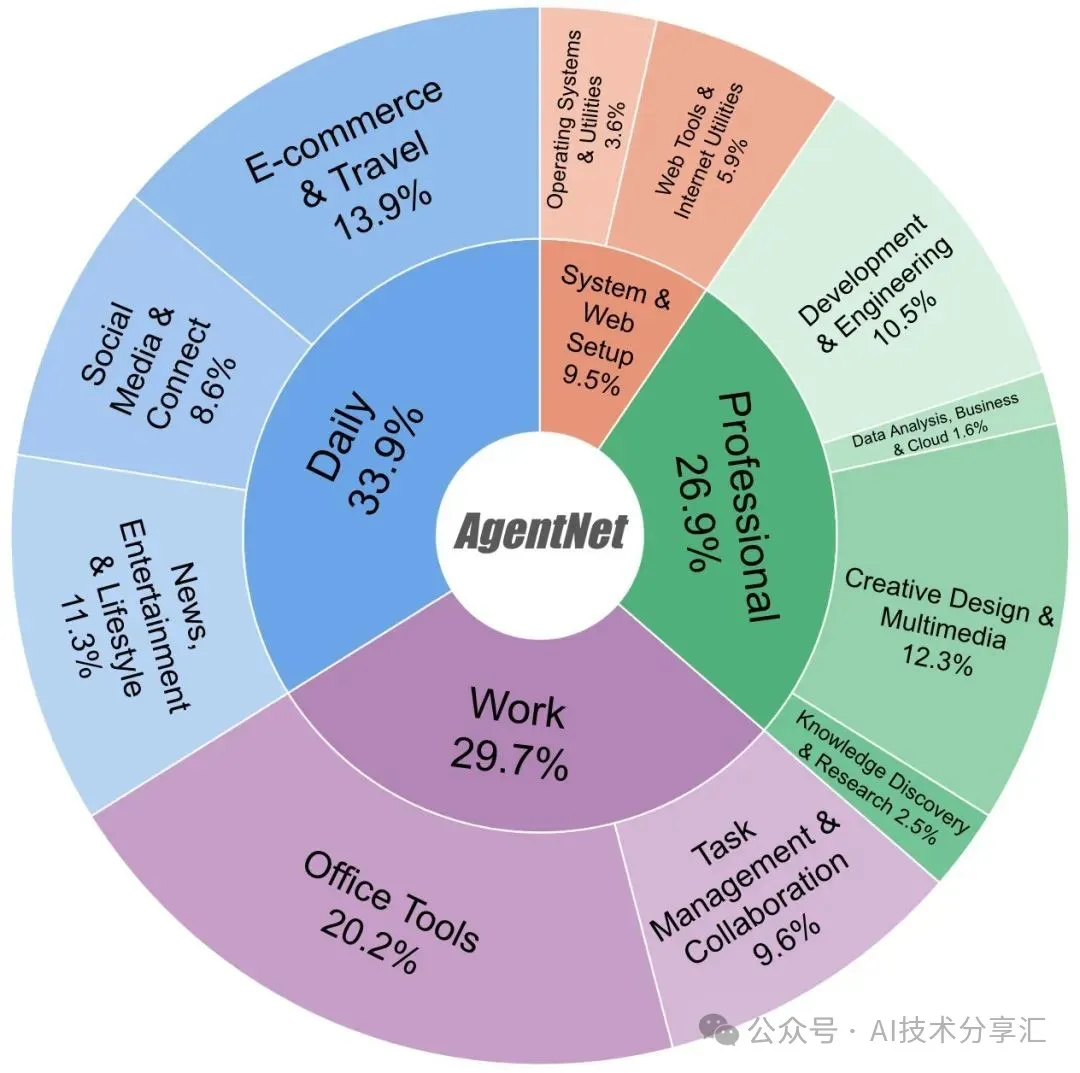
为克服环境依赖与评估效率瓶颈,团队开发了 AgentNetBench —— 一个纯离线、免环境配置的智能体评估标准:
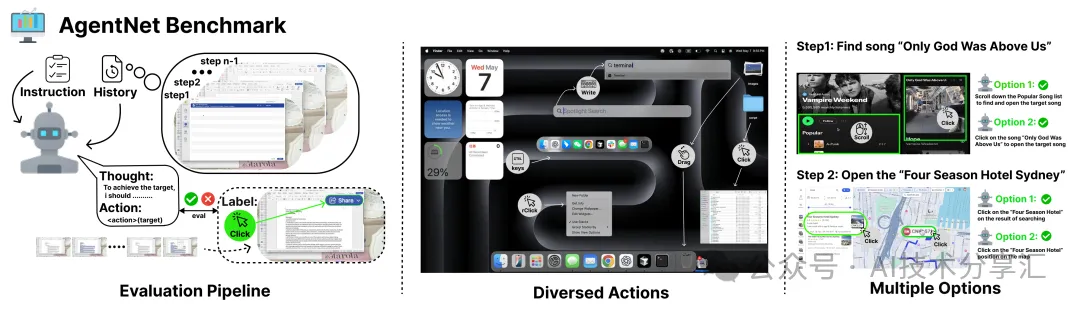
- 高效离线评估: 精选 AgentNet 中 100 个跨 Win/macOS 多领域的代表性任务,实现稳定、快速、免环境配置的评估。
- 高质量保证: 每个任务经过人工审查,明确目标并去除冗余步骤。
- 关键设计: 为应对操作路径的天然多样性,为每个步骤提供多个有效动作选项,极大增强了评估的灵活性和真实性。
OpenCUA 模型: 结合反思式思维链与跨领域数据
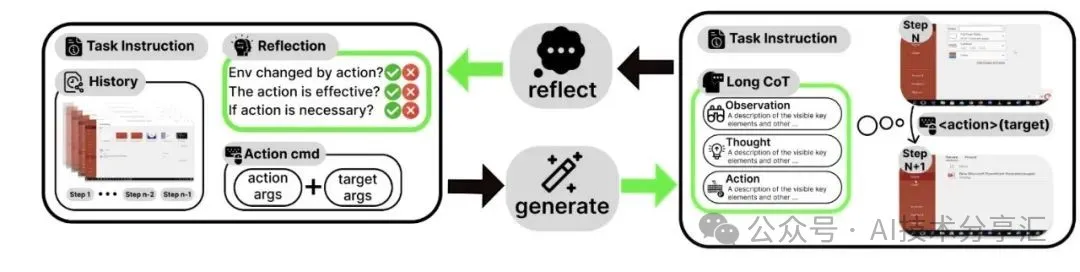
该团队基于数据集开发了 OpenCUA 智能体模型。该模型融合了反思式思维链推理(reflective CoT)、多图像历史信息以及跨领域数据,使其能够在多种操作系统的真实桌面环境中执行计算机操作任务。
模型的一个核心创新是其反思式长思维链处理流程:通过“生成器”(generator)和“反思器”(reflector)的迭代协作,动态生成并验证推理过程中的各个组件,确保观察信息与真实动作(ground-truth actions)之间的一致性和准确性。
评估基准与结果分析
实验评估了多个开源视觉-语言模型(VLM):
- KimiVL-A3B:采用混合专家(MoE)架构,总计16B参数,训练/推理激活参数3B,具备初步的计算机操作能力(如对象定位、任务规划)。
- Qwen2-VL-7B-Instruct
- Qwen2.5-VL-7B-Instruct
- Qwen2.5-VL-32B-Instruct:在数字智能体任务中表现更强,尤其擅长高分辨率场景理解。
团队对上述模型进行了监督微调,得到 OpenCUA 的多个变体:
- OpenCUA-A3B
- OpenCUA-Qwen2-7B
- OpenCUA-7B (基于 Qwen2.5-VL-7B)
- OpenCUA-32B (基于 Qwen2.5-VL-32B)
这些模型在多个基准上进行了评估。
1. 在线智能体评估
- OSWorld-Verified (369个任务): 源自 OSWorld,经过修复和验证,覆盖大量应用程序。评估通过其 AWS 公开平台进行。 (结果见表3)
- WindowsAgentArena - WAA (154个任务): 聚焦 Windows 原生应用及部分开源程序,评估 Windows 环境在线性能。
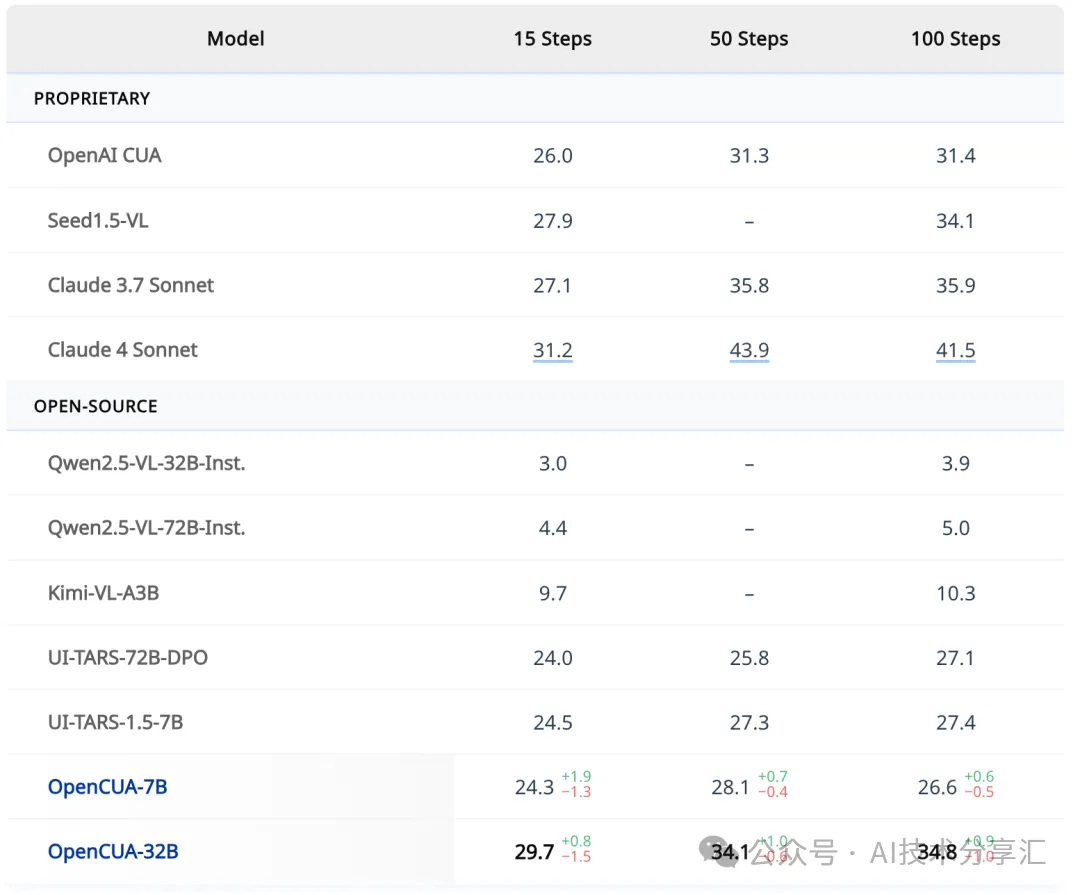
结果
- OpenCUA-32B 在所有开源模型中表现最优,平均成功率高达 34.8%,显著超越此前基线模型。
- 大幅缩小了与闭源智能体的差距,甚至超越了 OpenAI CUA,有力证明了 OpenCUA 训练流程的可扩展性与性能优势。
2. 离线智能体评估
- AgentNetBench (100个任务): 团队自建的 CUA 离线基准,覆盖 Windows 和 macOS 的多个代表性任务。
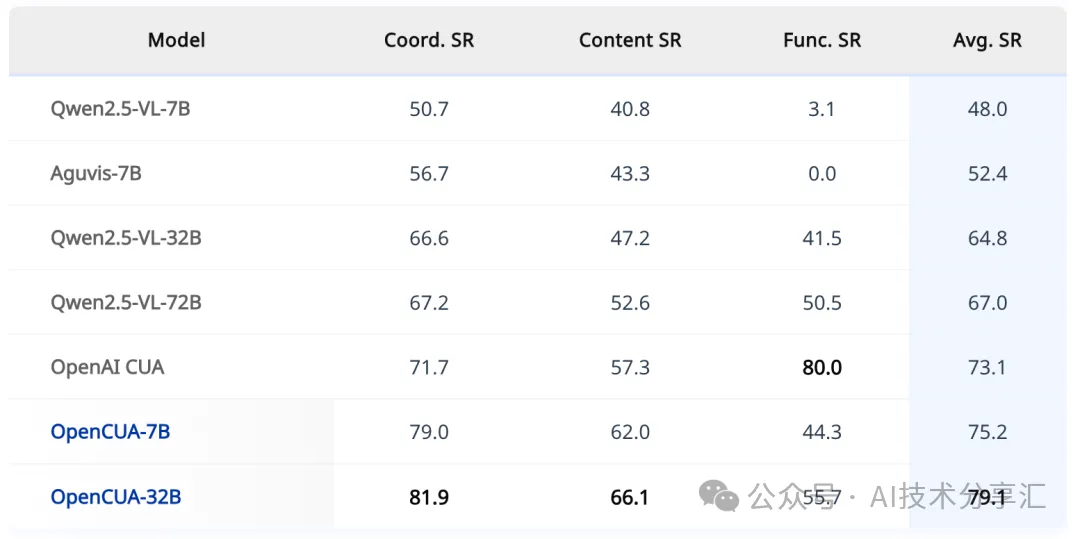
结果
- OpenCUA-32B 整体表现最佳,但 OpenAI CUA 在 Function action 成功率 上具有明显优势。
3. GUI定位能力评估
- 使用了三个基准:
- OSWorld-G (564个样本): 系统评估文本匹配、界面元素识别、布局理解、细粒度操作控制,并提供元素类型注释。
- Screenspot-V2: 评估跨平台(移动端、桌面端、网页端)的 GUI 理解能力。
- Screenspot-Pro: 专注于高分辨率桌面环境,特别是专业应用场景。
- 对比模型: Qwen2.5-VL 模型、UI-TARS。
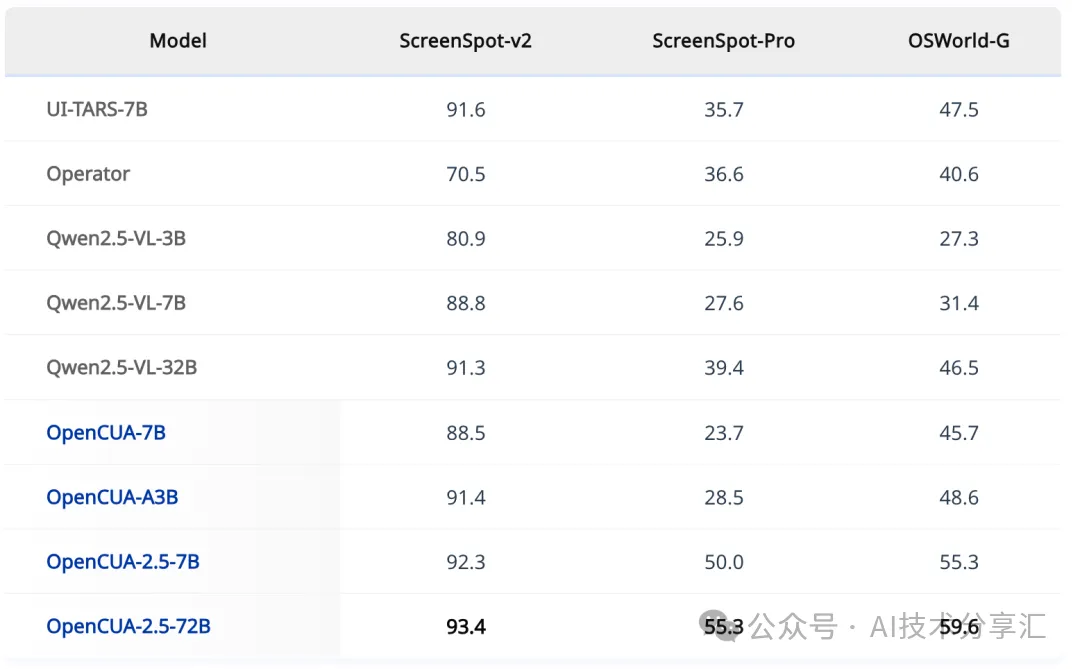
结果
- OpenCUA 方法能随训练数据规模扩大有效提升模型性能。
- OpenCUA-7B 展现出良好的 测试阶段扩展潜力(test-time scaling):在允许更多尝试次数(Pass@N)或更长推理路径的情况下,其性能有望获得显著提升。
总结
OpenCUA 是一个全面开源的计算机使用智能体(CUA)框架,旨在填补该领域的关键空白。它提供了一套完整的工具链,包括:
- 标注基础设施
- 数据处理流水线
- 多样化数据集
- 高效训练策略
- 系统评估基准
这些组件共同为 CUA 研究奠定了坚实基础。
基于该框架训练的模型在多个基准任务中表现出色,并展现出明确的数据 Scaling Law 和强大的跨领域泛化能力。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 32
32 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)