自动寻最优参的ARIMA模型--pmdarima
网格搜索理论相对简单,确定好模型取值参数,使用遍历循环带入,获取每个模型的评估指标值(ARIMA采用AIC或者BIC值,越小代表模型越好)。这里采用模拟数据集来作为演示。"""自动选择最优ARIMA参数"""# 生成所有可能的(p,d,q)组合# 网格搜索try:continueprint(f"最优参数: {best_order}, AIC: {best_aic}")# 对2090年后的数据进行预
1. 引入.
1.1 ARIMA模型的优缺点.
在上文中,本文对ARIMA模型的原理和流程作了简单介绍,其流程大致如下:
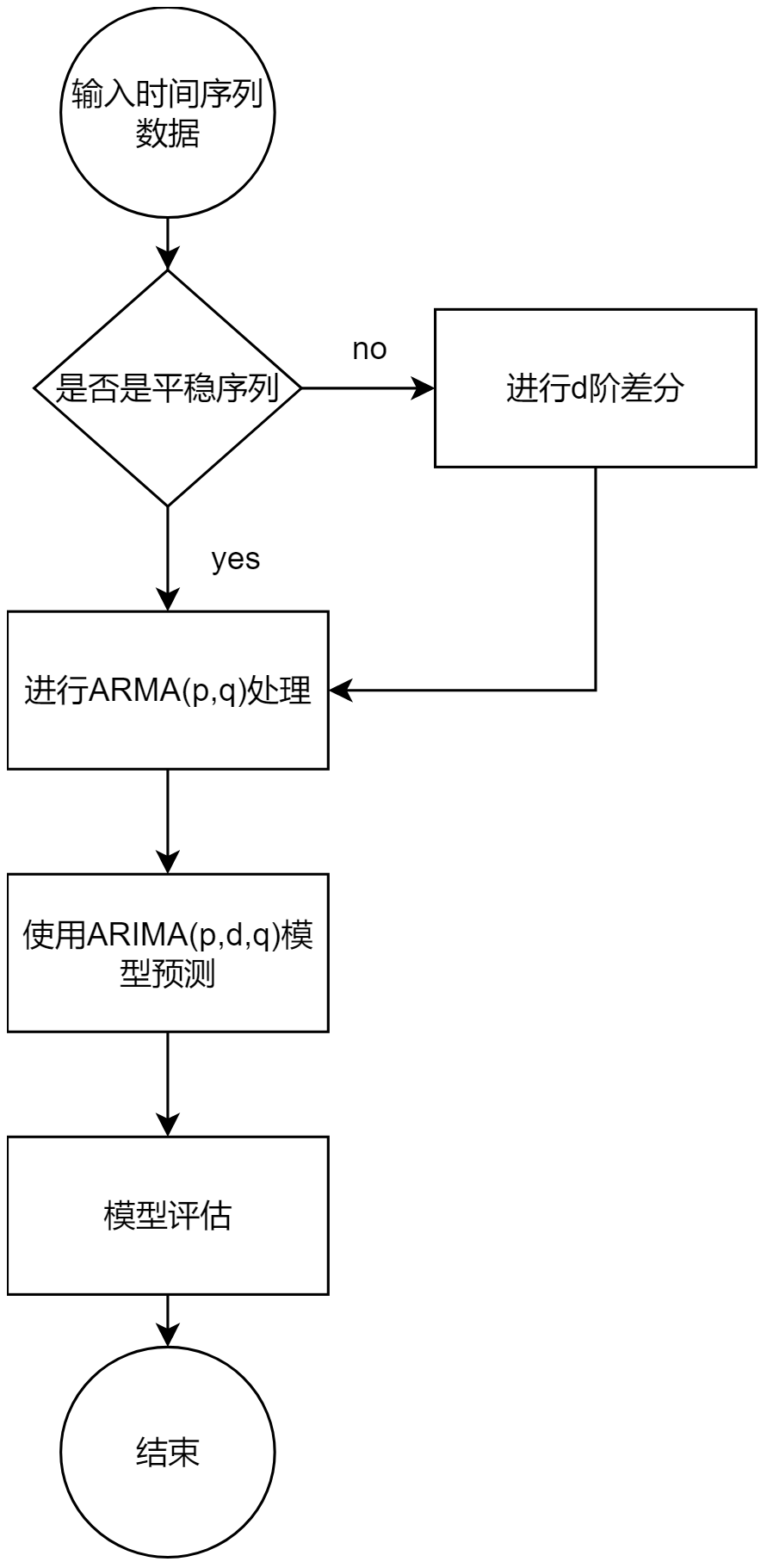
ARIMA的优点在于:
- 可解释性强:其数学原理清晰易懂,配合季节性分解STI既可以对时间序列未来走势进行预测,又可以对其走势的成分进行拆解分析。
- 可调参数少:相较之于神经网络模型LSTM等,ARIMA参数需要确定的参数只有三个,并且有明确的确定思路。
- 泛化能力好:ARIMA模型对于有季节性规律的序列识别能力较好,并且由于模型参数较少,并且有AIC和BIC避免模型过于复杂,不容易出现过拟合现象,泛化能力较好。
但ARIMA模型也有它的一些缺陷,这些缺陷正是使得我们可能要采取其它模型的依据:
- 对残差要求高:ARIMA模型对于噪声的要求很高,需要其是白噪声序列,白噪声序列的定义在上一文有写到;这使得ARIMA模型对于方差较大,有明显的残差序列识别较差,这便引出了ARCH模型,这个模型通常用于金融领域,它可以量化波动风险收益。
- 确定参数的方法较模糊:ARIMA模型通常使用ACF(自相关系数)和PACF(偏自相关系数)来衡量模型,而ACF和PACF图效果时好时坏,具有不稳定性,因此确定的模型亦不一定最优。这个问题的其中一个办法就是:通过类似网格搜索的办法,在一定范围内找出相对最优的模型,这是本文要介绍的方法。
表1:ACF和PACF对应ARIMA模型参数
|
模型 |
ACF |
PACF |
|
AR(p) |
逐渐衰减,即拖尾 |
p阶后截尾 |
|
MA(q) |
q阶后截尾 |
逐渐衰减,即拖尾 |
|
ARMA(p,q) |
逐渐衰减,即拖尾 |
逐渐衰减,即拖尾 |
可以看到,当ACF和PACF有一个图像出现截尾的时候,可以较好地确定模型参数,但如果二者呈现拖尾的情况,模型参数就不好确定了。
2. 对ARIMA模型参数确定改进方法.
1.1 使用网格搜索确定相对最优参数.
网格搜索的思路在于,确定一个参数的取值区间,在区间内均匀分割去点,遍历这个区间,找出在这个区间内使得模型效果最好的参数;如果是多个模型
,
...
,每个区间有
个数要取,则需要尝试
次,如图1中所示。
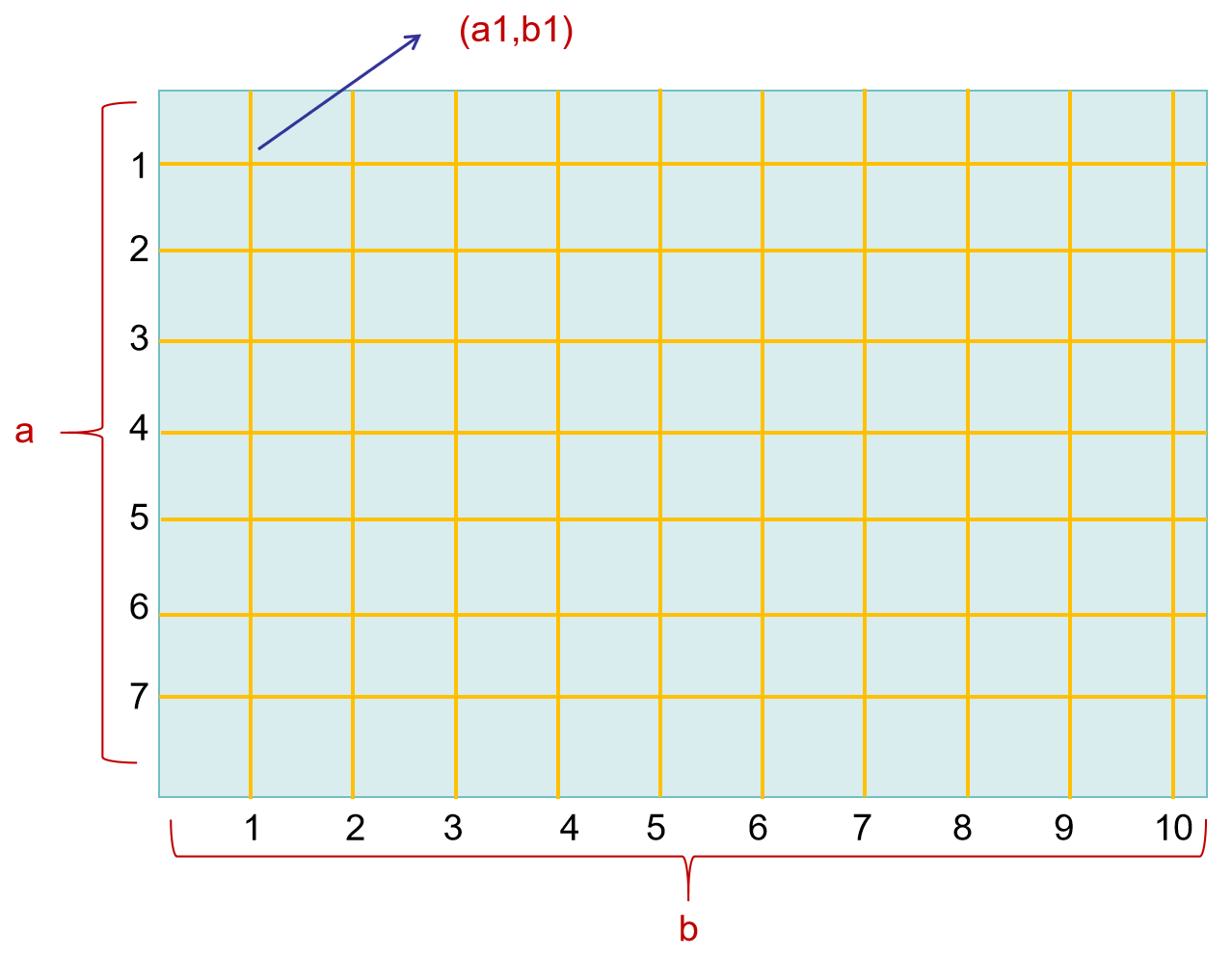
图1:网格搜索示意图
1.2 网格搜索范围确定.
对于不加季节项的ARIMA(p,d,q)模型来说,其模型公式为:
其中需要确定的参数有自回归滞后系数p,差分阶数d和移动平均滞后系数q,三个系数的含义在上一文中详细讨论过,这里不再讨论。从经验角度来看,差分阶数不宜过高,至多三阶足以;对于自回归滞后系数和移动平均滞后系数,最高值也不超过5。在这个范围内,网格搜索需要训练和比较的模型有75个,对于算力来说足够支撑。
对于加入季节项的SARIMA(p,d,q)模型来说,其公式为:
需要确定的参数除了p,d,q以外,还需要加上季节项的P,D,Q参数寻优,P,Q参数最大值参考为5,D参考最大值亦为3,在这个条件下,需要验证的模型有5625个。
3. 网格搜索演示.
3.1 自定义网格搜索函数.
网格搜索理论相对简单,确定好模型取值参数,使用遍历循环带入,获取每个模型的评估指标值(ARIMA采用AIC或者BIC值,越小代表模型越好)。这里采用模拟数据集来作为演示。
dta=[10930,10318,10595,10972,7706,6756,9092,10551,9722,10913,11151,8186,6422,
6337,11649,11652,10310,12043,7937,6476,9662,9570,9981,9331,9449,6773,6304,9355,
10477,10148,10395,11261,8713,7299,10424,10795,11069,11602,11427,9095,7707,10767,
12136,12812,12006,12528,10329,7818,11719,11683,12603,11495,13670,11337,10232,
13261,13230,15535,16837,19598,14823,11622,19391,18177,19994,14723,15694,13248,
9543,12872,13101,15053,12619,13749,10228,9725,14729,12518,14564,15085,14722,
11999,9390,13481,14795,15845,15271,14686,11054,10395]import pandas as pd
import numpy as np
import itertools
from statsmodels.tsa.arima.model import ARIMA
import warnings
def optimize_arima(data, max_p=5, max_d=2, max_q=5, seasonal=False):
"""
自动选择最优ARIMA参数
"""
# 生成所有可能的(p,d,q)组合
p_values = range(0, max_p + 1)
d_values = range(0, max_d + 1)
q_values = range(0, max_q + 1)
best_aic = float('inf')
best_order = None
best_model = None
# 网格搜索
for p, d, q in itertools.product(p_values, d_values, q_values):
try:
with warnings.catch_warnings():
warnings.filterwarnings("ignore")
model = ARIMA(data, order=(p, d, q))
fitted_model = model.fit()
if fitted_model.aic < best_aic:
best_aic = fitted_model.aic
best_order = (p, d, q)
best_model = fitted_model
except Exception as e:
continue
return best_order, best_model, best_aic
if name == '_main_':
best_order, best_model, best_aic = optimize_arima(dta)
print(f"最优参数: {best_order}, AIC: {best_aic}")
# 对2090年后的数据进行预测
predict_dta = best_model.predict('2090', '2100', dynamic=True)
print(predict_dta)
fig, ax = plt.subplots(figsize=(12, 8))
# 绘制原始数据(2000年之后)
dta.loc['2000':].plot(ax=ax, label='原始数据')
# 绘制预测结果
predict_dta.plot(ax=ax, label='预测结果')
ax.legend() # 显示图例
plt.show()寻找出来的最优参数为:(5, 1, 2), AIC: 1587.9491071228772。预测图见图2:
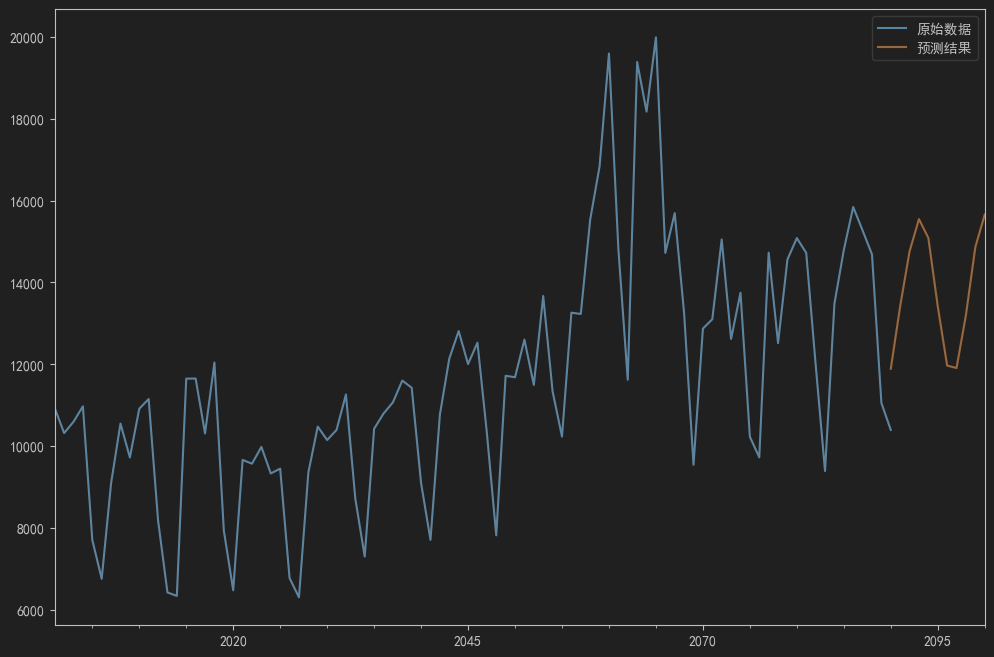
图2:自定义网格搜索函数拟合效果
3.2 使用pmdarima模型自动寻找最优参数.
pmdarima模型是由sklearn团队开发的一个Python时间序列库,它可以自动寻找最优的Arima模型参数,并且支持添加外生变量和季节性项。
环境配置:由于pmdarima与2.0以上的numpy有冲突,故建议采用本文所使用的版本
python --version = 3.8.20
|
Name |
Version |
|
pmdarima |
2.0.4 |
|
numpy |
1.24.3 |
演示数据集采用上文的Air Passengers数据,其时间序列图见图3:
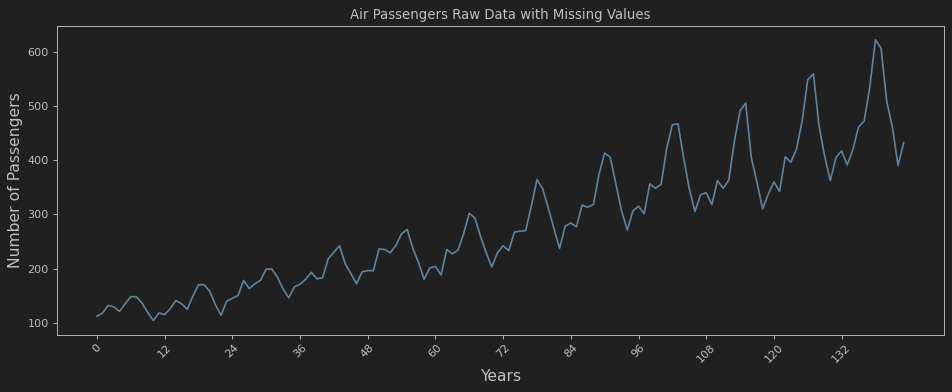
图3:Air Passengers时间序列图
代码见下
import pandas as pd
import matplotlib.pyplot as plt
import pmdarima as pm
df = pd.read_csv('./data/air_passengers.csv')
df.columns = ['Month', 'Passengers']
df.drop(df.index[-1], inplace=True) # 最后一行的数据有误, 删除
df.columns = ['Month', 'Passengers']
# 数据预处理
train_data = df.Passengers.values
# 模型预测
# 参1: 训练数据
# 参2: 是否季节性
# 参3: 季节性周期, 月度数据以12为周期.
# 参4: 模型参数,p为自回归阶数, q为移动平均阶数, d为差分阶数.
# 参5: 使用的信息准则函数, bic为使用贝叶斯信息准则函数.
# 参6: 是否输出过程信息.
# 参7: 是否忽略警告信息.
# 可添加外生变量: 通过参数exogenous添加
model = pm.auto_arima(train_data,
seasonal=True,
m=12,
start_p=0,
start_q=0,
max_p=9,
max_q=6,
max_d=3,
start_P=0,
information_criterion='bic',
trace=True,
suppress_warnings=True,
step_wise=True)
# 进行Ljung-Box Test检验, 查看残差数据是否不存在自相关情况.P值>0.05说明扰动项已经是白噪声了, 可以用来预测.
from statsmodels.stats.diagnostic import acorr_ljungbox
residuals = model.resid()
lb_test = acorr_ljungbox(residuals, lags=10)
print("Ljung-Box Test:")
print(f"统计量: {lb_test.iloc[0][-1]:.4f}")
print(f"p值: {lb_test.iloc[1][-1]:.4f}")
# 预测出12个月后的数据
y_pre_steps = 12
preds = model.predict(n_periods=y_pre_steps)
# 展示模型的信息.
print(model.summary())
# 可视化展示
# 设置预测后的时间序列的索引
preds_index = pd.date_range(start=df.index[-1] + pd.DateOffset(months=1), periods=y_pre_steps, freq='MS')
plt.figure(figsize=(12, 5), dpi=80, linewidth=10)
plt.plot(df.index, df['Passengers'], label='原始数据')
plt.plot(preds_index, preds, label='预测数据')
# 连接原始数据的最后一个点和预测数据的第一个点
plt.plot([df.index[-1], preds_index[0]],
[df['Passengers'].iloc[-1], preds[0]],
color='red', linestyle='--') # 使用虚线连接
plt.legend()
plt.title('原始数据与预测数据')
plt.xlabel('Years', fontsize=14)
plt.ylabel('Number of Passengers', fontsize=14)
plt.xticks(df.index[::12], rotation=45)
plt.tight_layout()
plt.show()最终预测图见图4:
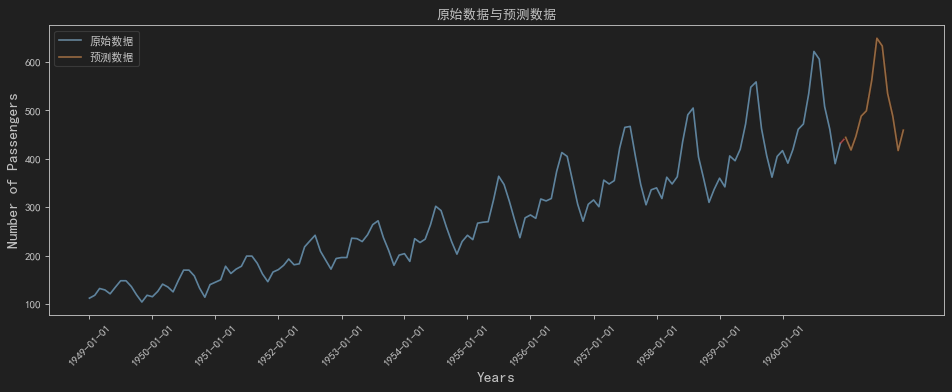
图4:pmdarima模型预测效果
3.2 使用STI分解进行可解释性分析.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from statsmodels.tsa.seasonal import seasonal_decompose
# 防止中文乱码
plt.rcParams['font.sans-serif'] = ['SimHei']
# 正常显示负号
plt.rcParams['axes.unicode_minus'] = False
# 使用加法模型分解
# 创建时间序列, 从df的开始日期到预测的结束日期.
index_pred = pd.date_range(start=df.index[0], periods=df.shape[0] + y_pre_steps, freq='MS')
full_series = pd.Series(passengers_add_pred, index=index_pred)
multiplicative_decomposition = seasonal_decompose(full_series,
model='addictive', # 加法分解: addictive
period=12,
extrapolate_trend='freq')
# 可视化乘法分解结果
fig, axes = plt.subplots(5, 1, figsize=(15, 12))
fig.suptitle('加法季节分解结果', fontsize=16)
# 原始数据
axes[0].plot(multiplicative_decomposition.observed.index,
multiplicative_decomposition.observed.values, 'b-', linewidth=1)
axes[0].set_title('原始数据')
axes[0].grid(True, alpha=0.3)
# 趋势成分
axes[1].plot(multiplicative_decomposition.trend.index,
multiplicative_decomposition.trend.values, 'g-', linewidth=1)
axes[1].set_title('趋势成分')
axes[1].grid(True, alpha=0.3)
# 季节性成分
axes[2].plot(multiplicative_decomposition.seasonal.index,
multiplicative_decomposition.seasonal.values, 'r-', linewidth=1)
axes[2].set_title('季节性成分')
axes[2].grid(True, alpha=0.3)
# 扰动项成分
axes[3].plot(multiplicative_decomposition.resid.index,
multiplicative_decomposition.resid.values, 'm-', linewidth=1)
axes[3].set_title('扰动项成分')
axes[3].grid(True, alpha=0.3)
# 年度性季节数据, 取最后一年
axes[4].plot(multiplicative_decomposition.seasonal.index[-12:],
multiplicative_decomposition.seasonal.values[-12:], 'y-', linewidth=1)
axes[4].set_title('年度性季节数据')
axes[4].grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
图形见图5:
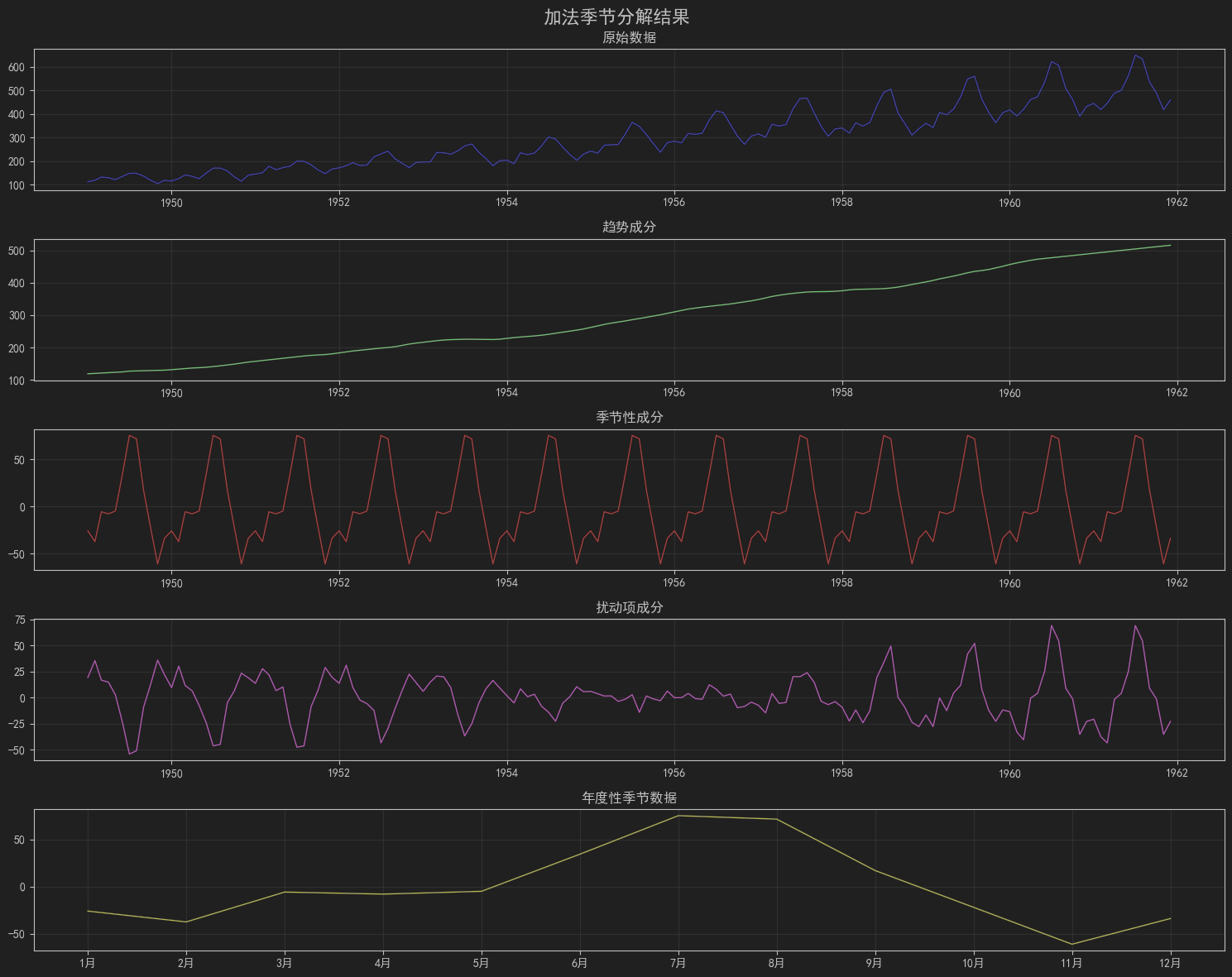
从图中可以看到,航班旺季在每年的7月-8月,淡季在每年的11-12月。
由加法分解公式:
其中S是季节性因子,T是趋势性因子,I是不规则扰因子。这里假设三者是相互独立的,则可以由方差分解得出每个变量对因变量变异解释程度。
代码如下:
使用方差贡献率查看各个成分对时间序列数据的贡献率, 贡献率越大说明该指标对时间序列数据影响越大.
total = df_seasonal_decompose.原始数据.var()
trend = df_seasonal_decompose.趋势成分.var()
seasonal = df_seasonal_decompose.季节性成分.var()
residual = df_seasonal_decompose.残差成分.var()
print(f'趋势贡献率: {trend / total:.2%}')
print(f'年度季节性贡献率: {seasonal / total:.2%}')
print(f'残差贡献率: {residual / total:.2%}')
print(f'三者贡献率总和: {(trend + seasonal + residual) / total:.2%}')结果为:
趋势贡献率: 87.11%
年度季节性贡献率: 9.65%
残差贡献率: 2.95%
三者贡献率总和: 99.70%
可以看到,趋势项对于乘客数量波动贡献率最大,齐次是季节性因子,最后是扰动项,这些可以作为可解释性部分来处理。
同时如果使用乘法分解:
在同样假设S、T、I三者独立的情况下,我们可以使用取对数的方式达到同样效果。
4. 总结.
ARIMA模型具有模型简洁、参数较少和可解释性强的特点。但又有着对数据平稳性要求高、对噪声要求是白噪声和模型选择困难等缺点;本文针对于ARIMA模型选择方面提出了改进的方向,引入网格搜索的方式来实现自动寻找最优参数,一定程度上减少了ARIMA模型选择困难的问题,后续本文将会对ARIMA另外两个缺陷,提出相应的改进方向。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 17
17 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)