备aic-数据结构与算法
10^5 为界限,这个得是O(nlogn)
由数据范围反推算法复杂度以及算法内容

10^5 为界限,这个得是O(nlogn)
力扣已刷
1. 两数之和
方法一:暴力枚举
(两层for循环):O(N方)
方法二:用哈希表
题解:
注意到方法一的时间复杂度较高的原因是寻找 target - x 的时间复杂度过高。因此,我们需要一种更优秀的方法,能够快速寻找数组中是否存在目标元素。如果存在,我们需要找出它的索引。
使用哈希表,可以将寻找 target - x 的时间复杂度降低到从 O(N) 降低到 O(1)。
这样我们创建一个哈希表,对于每一个 x,我们首先查询哈希表中是否存在 target - x,然后将 x 插入到哈希表中,即可保证不会让 x 和自己匹配。。
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
unordered_map<int,int> mp;
for(int i=0;i<nums.size();i++){
int t=(target-nums[i]);
if(mp.count(t)){
return{mp[t],i};
}mp[nums[i]]=i;
}
return{};
}
};2469. 温度转换
数学相关算法题
2011. 执行操作后的变量值
数组相关算法题
1254. 统计封闭岛屿的数目
一个陆地0只能属于一块岛屿
队列里面装pair
queue<pair<int,int>> pq;
pq.push(make_pair(i, j))
//或者
pq.push({i,j});//外面小括号里面大括号
二维数组的越界访问
错误发生在stl_vector.h中的越界访问:
runtime error: addition of unsigned offset to 0x510000000040 overflowed to 0x510000000028
直接原因是:当坐标超出边界时,仍尝试访问grid[xx][yy]。在代码2的条件判断中:
if(grid[xx][yy]==0 && xx>=0&&xx<n&&yy>=0&&yy<m)当xx或yy超出边界时(如xx=-1),程序仍会尝试访问grid[-1][y],这会导致内存越界访问。
问题复现示例
假设网格边界处有土地(grid[0][j]=0),当尝试访问其上方节点时:
xx = cx + dx[0] = 0 + (-1) = -1
yy = 0
// 此时先执行 grid[-1][0] -> 非法内存访问!解决方案
-
交换边界检查顺序:
if (xx >= 0 && xx < n && yy >= 0 && yy < m && grid[xx][yy] == 0)139. 单词拆分
题解:
-
动态规划数组:创建
dp数组,其中dp[i]表示字符串s的前i个字符是否可以被字典中的单词拼接而成。 -
初始化:
dp[0] = true表示空字符串总是可以拼接。 -
填充 dp 数组:对于每个位置
i(从 1 到n),检查字典中的每个单词。如果单词长度小于等于i,且dp[i - len]为true,并且子串s.substr(i - len, len)等于该单词,则设置dp[i] = true。 -
返回值:最后返回
dp[n],即整个字符串s是否可以被拼接。
这种方法允许字典中的单词重复使用,并且不要求单词按顺序出现,从而正确解决问题。
98. 验证二叉搜索树
root->val 和 root.val 的区别
在 C++ 中,root->val 和 root.val 的区别在于 root 的类型:
-
当
root是指针类型时(如TreeNode* root):-
使用
root->val来访问成员 -
这是指针解引用并访问成员的简写形式,等价于
(*root).val
-
-
当
root是对象本身时(如TreeNode root):-
使用
root.val来访问成员
-
在给定的代码中,root 被声明为 TreeNode* 类型(指向 TreeNode 的指针),因此必须使用 root->val 来访问其 val 成员。
表示比长整型的最小值还小
(long long)INT_MIN - 1;-
memset不能用于设置INT_MAX, -
因为
memset是按字节设置的,而INT_MAX是一个多字节的值。
const int N = 200000;
int dp[N + 1];
// 初始化 dp 数组
for (int i = 0; i <= N; i++) {
dp[i] = INT_MAX;
}
dp[0] = 0;155. 最小栈
题解
需要设计一个辅助栈数据结构,使得每个元素 a 与其相应的最小值 m 时刻保持一一对应。因此我们可以使用一个辅助栈,与元素栈同步插入与删除,用于存储与每个元素对应的最小值。
当一个元素要入栈时,我们取当前辅助栈的栈顶存储的最小值,与当前元素比较得出最小值,将这个最小值插入辅助栈中;
当一个元素要出栈时,我们把辅助栈的栈顶元素也一并弹出;
在任意一个时刻,栈内元素的最小值就存储在辅助栈的栈顶元素中。
min函数
min 函数需要两个相同类型的参数,不能传递一个 int 和一个 long long
509. 斐波那契数
递归 或 动态规划时注意初始化
206. 反转链表
题解:
循环迭代/
递归(函数自己调用自己)
递归反转链表的代码可能看起来有点绕,但其实它的工作原理很直观。我用一个简单的例子(链表 1->2->3->null)来一步步解释。
递归如何工作
递归的核心思想是:先让下一个节点处理剩下的链表,然后再处理当前节点。就像是你把任务交给别人,等他们完成后再做自己的部分。
步骤分解
-
初始调用:我们从节点1开始。
-
节点1不是空,且有下一个节点(节点2),所以我们会调用
reverseList(节点2)。
-
-
递归调用到节点2:
-
节点2也不是空,且有下一个节点(节点3),所以调用
reverseList(节点3)。
-
-
递归调用到节点3:
-
节点3的下一个节点是null,所以直接返回节点3(这是递归的终止条件)。
-
现在,递归开始“返回”了(也就是从后往前处理):
-
回到节点2的处理:
-
此时,
reverseList(节点2)得到了newHead(节点3)。 -
然后执行
head->next->next = head:意思是让节点3的next指向节点2(即反转指针)。 -
再执行
head->next = nullptr:让节点2的next指向null(避免成环)。 -
现在链表部分变成了:节点3->节点2->null,但节点1还指向节点2。
-
返回
newHead(节点3)。
-
-
回到节点1的处理:
-
此时,
reverseList(节点1)得到了newHead(节点3)。 -
执行
head->next->next = head:让节点2的next指向节点1(因为head是节点1,head->next是节点2)。 -
执行
head->next = nullptr:让节点1的next指向null。 -
现在链表完全反转了:节点3->节点2->节点1->null。
-
返回
newHead(节点3)。
-
为什么“从后往前”?
递归的特点是:先深入后返回。就像你走进一个房间的最里面,然后倒着走出来一样。
-
先深入:递归会一直调用自己,直到链表末尾(基线条件)。
-
后返回:从末尾开始,每次返回时处理当前节点,反转指针。
这样,递归自然地从后往前工作,因为最后调用的函数最先返回(栈结构)。
349. 两个数组的交集
set:
set没有push方法,应该使用insert。
242. 有效的字母异位词
在于理解题意:字母异位词是通过重新排列不同单词或短语的字母而形成的单词或短语,并使用所有原字母一次。而不是字母在原单词出现过即可。
2235. 两整数相加
没意义
2413. 最小偶倍数
最小公倍数,最大公约数
最大公约数(GCD)是两个数共享的最大因数
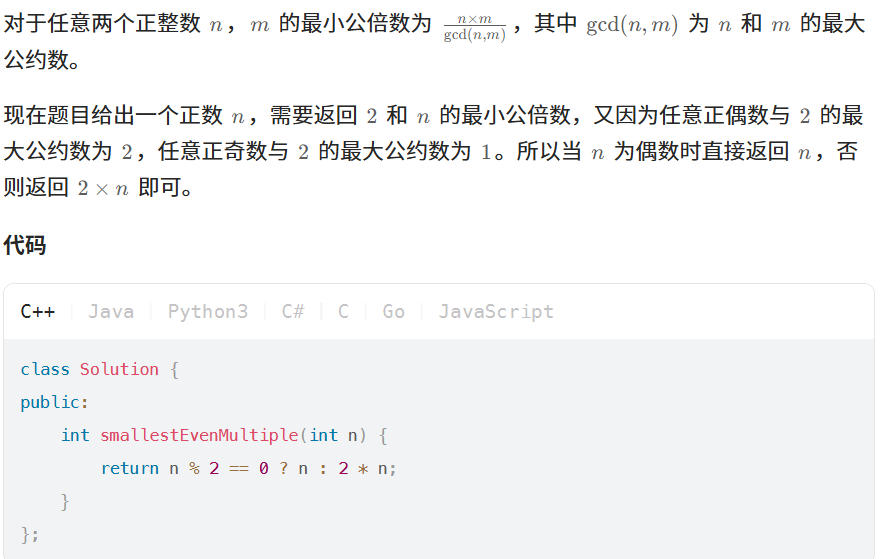
class Solution {
public:
int gcd(int a,int b){
return b==0? a : gcd(b,a%b);
}
int smallestEvenMultiple(int n) {
return (n*2)/gcd(n,2);
}
};1929. 数组串联
344. 反转字符串
reverse 和 swap 的区别
在 C++ 中,reverse 和 swap 是两个功能不同的标准库函数,它们的主要区别如下:
swap 函数
功能
交换两个元素的值。
用法
#include <algorithm> // 或者 <utility> 在 C++11 之后
std::swap(a, b); // 交换 a 和 b 的值特点
-
交换两个单独的元素
-
时间复杂度:O(1)
-
适用于任何可交换的数据类型
示例
int a = 5, b = 10;
std::swap(a, b); // 现在 a=10, b=5
std::vector<int> v = {1, 2, 3};
std::swap(v[0], v[2]); // 现在 v = {3, 2, 1}reverse 函数
功能
反转一个序列中元素的顺序。
用法
#include <algorithm>
std::reverse(first, last); // 反转 [first, last) 范围内的元素特点
-
反转整个序列或序列的一部分
-
时间复杂度:O(n),其中 n 是序列长度
-
需要两个迭代器参数(起始和结束位置)
示例
std::vector<int> v = {1, 2, 3, 4, 5};
std::reverse(v.begin(), v.end()); // 现在 v = {5, 4, 3, 2, 1}
std::string s = "hello";
std::reverse(s.begin(), s.end()); // 现在 s = "olleh"关键区别
|
特性 |
|
|
|---|---|---|
|
功能 |
交换两个元素 |
反转序列顺序 |
|
参数 |
两个元素引用 |
两个迭代器(起始和结束位置) |
|
时间复杂度 |
O(1) |
O(n) |
|
使用场景 |
交换两个值 |
反转整个序列或部分序列 |
541. 反转字符串 II
字符串的迭代器
string s;
string::iterator i=s.begin();
string s;
int n = s.size();
for (int i = 0; i < n; i += 2 * k) {
// 反转前k个字符,但如果剩余字符少于k个,则反转所有剩余字符
if (i + k <= n) {
reverse(s.begin() + i, s.begin() + i + k);
} else {
reverse(s.begin() + i, s.end());
}
}
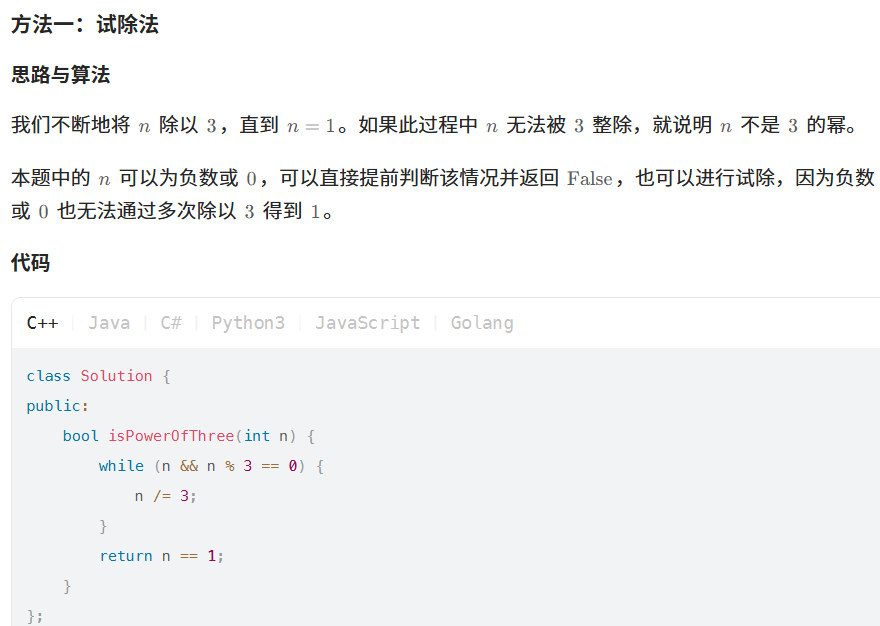
342. 4的幂
class Solution {
public:
bool isPowerOfFour(int n) {
return n>0&&(n&(n-1))==0&&n%3==1;
}
};326. 3 的幂
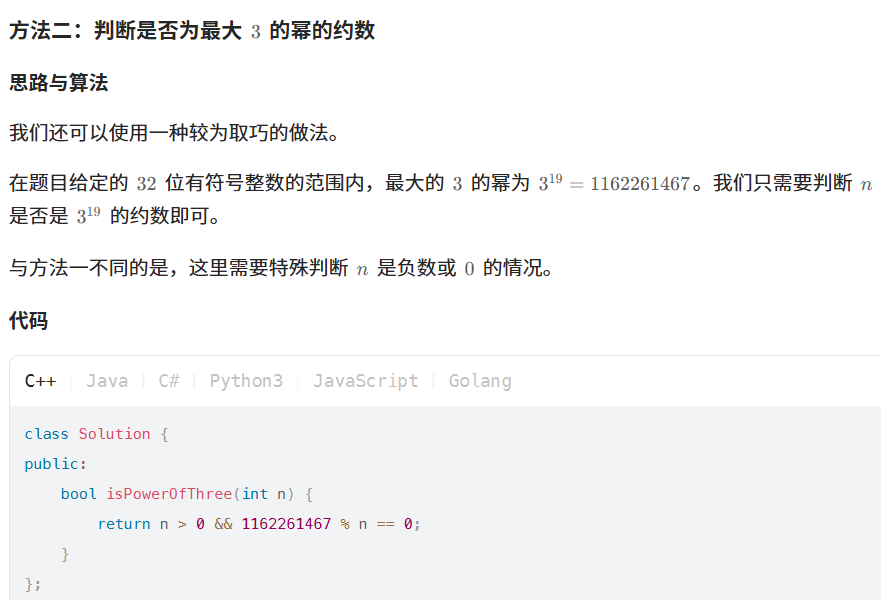
1365. 有多少小于当前数字的数字
vector的find
1. 使用标准库算法 std::find(最常用)
这是查找 vector 元素最常用的方法,需要包含 <algorithm> 头文件。
find前不加东西
#include <iostream>
#include <vector>
#include <algorithm> // 必须包含这个头文件
int main() {
std::vector<int> numbers = {1, 2, 3, 4, 5};
// 查找值为3的元素
auto it = std::find(numbers.begin(), numbers.end(), 3);
if (it != numbers.end()) {
std::cout << "找到元素: " << *it << std::endl;
std::cout << "位置索引: " << std::distance(numbers.begin(), it) << std::endl;
} else {
std::cout << "未找到元素" << std::endl;
}
return 0;
}2. 使用 C++11 的 std::find_if(条件查找)
当需要基于条件查找时,可以使用 find_if:
#include <iostream>
#include <vector>
#include <algorithm>
int main() {
std::vector<int> numbers = {1, 2, 3, 4, 5};
// 查找第一个大于3的元素
auto it = std::find_if(numbers.begin(), numbers.end(), [](int n) {
return n > 3;
});
if (it != numbers.end()) {
std::cout << "找到大于3的元素: " << *it << std::endl;
}
return 0;
}3. 对于有序 vector 的二分查找
如果 vector 是有序的,可以使用更高效的二分查找:
#include <iostream>
#include <vector>
#include <algorithm>
int main() {
std::vector<int> numbers = {1, 2, 3, 4, 5}; // 必须是有序的
// 使用二分查找
bool found = std::binary_search(numbers.begin(), numbers.end(), 3);
if (found) {
std::cout << "找到元素 3" << std::endl;
}
// 获取元素位置
auto it = std::lower_bound(numbers.begin(), numbers.end(), 3);
if (it != numbers.end() && *it == 3) {
std::cout << "元素位置: " << std::distance(numbers.begin(), it) << std::endl;
}
return 0;
}4. 自定义类型的查找
对于存储自定义类型的 vector,需要提供比较方法:
#include <iostream>
#include <vector>
#include <algorithm>
#include <string>
struct Person {
std::string name;
int age;
};
int main() {
std::vector<Person> people = {
{"Alice", 25},
{"Bob", 30},
{"Charlie", 35}
};
// 按名称查找
auto it = std::find_if(people.begin(), people.end(), [](const Person& p) {
return p.name == "Bob";
});
if (it != people.end()) {
std::cout << "找到: " << it->name << ", 年龄: " << it->age << std::endl;
}
return 0;
}520. 检测大写字母
判断字母大小写/数字/字母/数字或字母/空白字符/标点符号/大小写字母相互转换
-
islower() 和 isupper() 是C++标准库中的函数,用于判断字符是否是小写或大写字母。它们定义在
<cctype>头文件中。 -
与此同系列的函数都接受一个整数参数(通常是 char 类型),并返回一个非零值(真)或零(假)。
-
isdigit() - 检查字符是否为十进制数字 (0-9) -
isxdigit() - 检查字符是否为十六进制数字 (0-9, a-f, A-F) -
isalpha() - 检查字符是否为字母 (a-z, A-Z) -
isalnum() - 检查字符是否为字母或数字 -
isspace() - 检查字符是否为空白字符 // 包括: 空格(' '), 换页('\f'), 换行('\n'), 回车('\r'), 水平制表符('\t'), 垂直制表符('\v') -
ispunct() - 检查字符是否为标点符号 // 包括所有不是字母数字的图形字符 - 大小写字母相互转换
-
char upper = 'A'; char lower = 'a'; // tolower() - 将大写字母转换为小写字母 char convertedLower = tolower(upper); std::cout << upper << " 转换为小写: " << convertedLower << std::endl; // toupper() - 将小写字母转换为大写字母 char convertedUpper = toupper(lower); std::cout << lower << " 转换为大写: " << convertedUpper << std::endl; -
异或操作 (^):这里用于比较两个布尔值是否不同。如果当前字母的大小写状态与第二个字母的大小写状态不同,异或结果为真(非零),表示不符合规范。
-
算法首先处理特殊情况(第一个字母小写但第二个字母大写),然后检查其余字母的一致性,确保高效且正确地判断大小写使用。
58. 最后一个单词的长度
字符串末尾
注意:字符串可能有行末空格
注意考虑空字符串的情况
s.end()返回的是字符串最后一个字符的后一个位置的迭代器
s.end()返回的是字符串最后一个字符是什么
s.pop_back()删除字符串最后一个字符
考虑只有一个单词的情况,即第二个循环可能循环到字符串为空时要跳出循环
#include <iostream>
#include <string>
#include <cctype> // 需要包含这个头文件以使用 isspace
using namespace std;
class Solution {
public:
int lengthOfLastWord(string s) {
int n = 0;
// 首先处理空字符串的情况
if (s.empty()) return 0;
// 删除末尾的空格
while (!s.empty() && isspace(s.back())) {
s.pop_back();
}
// 计算最后一个单词的长度
while (!s.empty() && !isspace(s.back())) {
n++;
s.pop_back();
}
return n;
}
};661. 图片平滑器
整型数组和二维vector
int dx[9]={-1,-1,-1,0,0,0,1,1,1};
int dy[9]={-1,0,1,-1,0,1,-1,0,1};
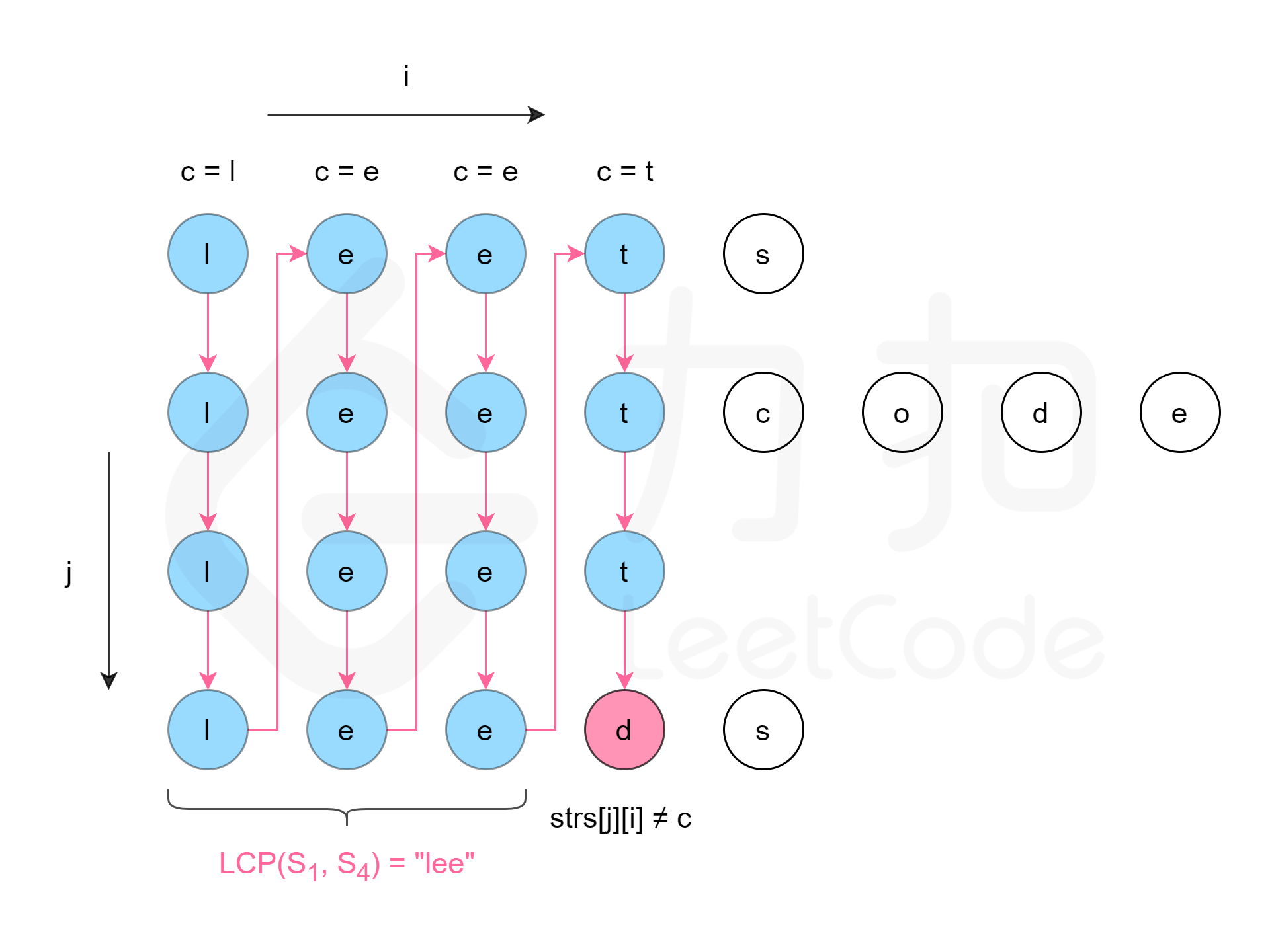
vector<vector<int>> vec(n,vector<int>(m));14. 最长公共前缀
vector<string> strs
int n=strs[0].size();
int m=strs.size();
纵向扫描。纵向扫描时,从前往后遍历所有字符串的每一列,比较相同列上的字符是否相同,如果相同则继续对下一列进行比较,如果不相同则当前列不再属于公共前缀,当前列之前的部分为最长公共前缀。
383. 赎金信
题解:
只需要满足字符串 magazine 中的每个英文字母 (’a’-’z’) 的统计次数都大于等于 ransomNote 中相同字母的统计次数即可。
如果字符串 magazine 的长度小于字符串 ransomNote 的长度,则我们可以肯定 magazine 无法构成 ransomNote,此时直接返回 false。
统计字符串中某个字符的出现次数
count 首末迭代器 目标值
#include <iostream>
#include <string>
#include <algorithm> // 需要包含这个头文件
using namespace std;
int main() {
string text = "hello world";
char target = 'l';
int count = std::count(text.begin(), text.end(), target);
cout << "字符 '" << target << "' 在字符串中出现了 " << count << " 次" << endl;
return 0;
}C++ string 的 find 函数
基本 find 函数
1. 查找字符
#include <iostream>
#include <string>
using namespace std;
int main() {
string str = "Hello, World!";
// 查找字符 'W'
size_t pos = str.find('W');
if (pos != string::npos) {
cout << "找到 'W' 在位置: " << pos << endl;
} else {
cout << "未找到 'W'" << endl;
}
// 从指定位置开始查找
pos = str.find('l', 5); // 从位置5开始查找 'l'
if (pos != string::npos) {
cout << "从位置5开始找到 'l' 在位置: " << pos << endl;
}
return 0;
}2. 查找子字符串
#include <iostream>
#include <string>
using namespace std;
int main() {
string str = "Hello, World! Welcome to C++";
// 查找子字符串 "World"
size_t pos = str.find("World");
if (pos != string::npos) {
cout << "找到 'World' 在位置: " << pos << endl;
}
// 查找子字符串 "C++"
pos = str.find("C++");
if (pos != string::npos) {
cout << "找到 'C++' 在位置: " << pos << endl;
}
return 0;
}其他 find 相关函数
1. rfind - 反向查找
#include <iostream>
#include <string>
using namespace std;
int main() {
string str = "Hello, World! Hello, C++!";
// 从后向前查找 "Hello"
size_t pos = str.rfind("Hello");
if (pos != string::npos) {
cout << "从后向前找到 'Hello' 在位置: " << pos << endl;
}
return 0;
}2. find_first_of - 查找任何指定字符
#include <iostream>
#include <string>
using namespace std;
int main() {
string str = "Hello, World!";
// 查找任何元音字母
size_t pos = str.find_first_of("aeiouAEIOU");
if (pos != string::npos) {
cout << "找到第一个元音字母 '" << str[pos] << "' 在位置: " << pos << endl;
}
return 0;
}3. find_last_of - 查找最后一个指定字符
#include <iostream>
#include <string>
using namespace std;
int main() {
string str = "Hello, World!";
// 查找最后一个元音字母
size_t pos = str.find_last_of("aeiouAEIOU");
if (pos != string::npos) {
cout << "找到最后一个元音字母 '" << str[pos] << "' 在位置: " << pos << endl;
}
return 0;
}4. find_first_not_of - 查找第一个不匹配的字符
#include <iostream>
#include <string>
using namespace std;
int main() {
string str = "123abc456";
// 查找第一个非数字字符
size_t pos = str.find_first_not_of("0123456789");
if (pos != string::npos) {
cout << "找到第一个非数字字符 '" << str[pos] << "' 在位置: " << pos << endl;
}
return 0;
}5. find_last_not_of - 查找最后一个不匹配的字符
#include <iostream>
#include <string>
using namespace std;
int main() {
string str = "123abc456";
// 查找最后一个非数字字符
size_t pos = str.find_last_not_of("0123456789");
if (pos != string::npos) {
cout << "找到最后一个非数字字符 '" << str[pos] << "' 在位置: " << pos << endl;
}
return 0;
}495. 提莫攻击
190. 颠倒二进制位
题解:
每次把 res 左移,把 n 的二进制末尾数字,拼接到结果 res 的末尾。然后把 n 右移。
举一个 8 位的二进制进行说明:
i n res
- 11001001 -
0 1100100 1
1 110010 10
2 11001 100
3 1100 1001
4 110 10010
5 11 100100
6 1 1001001
8 - 10010011
|与||
||
表示逻辑或
逻辑或,是逻辑运算符,符号是“||”(在PASCAL中为"or")。 “逻辑或”相当于生活中的“或者”,当两个条件中有任一个条件满足,“逻辑或”的运算结果就为“真”
12||1 =1 12||0 =1 0||0 =0
|
表示按位或
按位或运算 按位或运算符“|”是双目运算符。其功能是参与运算的两数各对应的二进位(也就是最后一位)相或。只要对应的二个二进位有一个为1时,结果位就为1。
128: (0001 0000 0000)
127: (0000 1111 1111) (高位用0补齐)
按位或就是(0001 1111 1111)=255
|=
|=是按位或并赋值的意思,和+= -= 用法差不多
a |= b, a = a|b;n >> 1(右移运算符)
-
这是一个表达式,返回
n右移 1 位后的结果 -
不会改变
n的原始值 -
类似于算术运算中的除法:
n / 2
n >>= 1(右移赋值运算符)
-
这是一个复合赋值运算符,将
n右移 1 位后的结果赋值给n -
会改变
n的原始值 -
类似于:
n = n >> 1或n = n / 2
有符号数int和无符号数uint32_t 友谊的区别
右移操作在有符号整数 int 中是算术右移(会填充符号位),而在无符号整数 uint32_t 中是逻辑右移(填充0)。
258. 各位相加
405. 数字转换为十六进制数
reverse函数是原地操作,不返回值正确写法:
reverse(s.begin(), s.end()); // 正确使用reverse函数 return s;
错误写法:return reverse(s.begin(),s.end());
int digit = n & 0xF; // 取低4位
0xF是十六进制表示,等于十进制的15,二进制的1111
1111是十进制数1111,不等于二进制的1111正确的方式是使用
0xF或15
修正十六进制转换代码中的负数处理问题
您的代码在处理负数时会出现无限循环的问题。这是因为对于负数,使用 int 类型进行右移操作会导致符号位被保留,从而使数字永远不会变为0,导致无限循环。
问题分析
当 num 为负数时:
-
在C++中,对有符号整数进行右移操作是算术右移,会保留符号位
-
这意味着负数右移后仍然是负数,永远不会变为0
-
因此
while(num)条件会一直为真,导致无限循环
修正后的代码
#include <algorithm>
#include <string>
using namespace std;
class Solution {
public:
string toHex(int num) {
if (num == 0) return "0";
unsigned int n = num; // 关键修改:将num转换为无符号整数
string s;
while (n) {
int digit = n & 0xF;
if (digit < 10) {
s += '0' + digit;
} else {
s += 'a' + digit - 10;
}
n >>= 4;
}
reverse(s.begin(), s.end());
return s;
}
};关键修改
-
使用无符号整数:
-
将
int num转换为unsigned int n = num -
这样右移操作就是逻辑右移(填充0),而不是算术右移(保留符号位)
-
确保循环最终会终止
-
-
正确处理负数:
-
通过使用无符号整数,负数的补码表示会被正确处理
-
例如,-1 的补码表示是 0xFFFFFFFF,转换为十六进制就是 "ffffffff"
-
为什么使用无符号整数
在C++中:
-
有符号整数的右移是算术右移:保留符号位(负数右移后仍然是负数)
-
无符号整数的右移是逻辑右移:填充0(最终会变为0)
通过将 int 转换为 unsigned int,我们确保了:
-
负数的补码表示被正确处理
-
右移操作最终会使数字变为0,终止循环
-
所有情况(正数、负数、零)都能正确转换
这个修正后的代码能够正确处理所有输入情况,包括负数,并且不会出现无限循环的问题。
168. Excel 表列名称
题解:
不要陷入无限循环
string convertToTitle(int columnNumber) {
string ans;
while (columnNumber > 0) {
columnNumber--; // 调整范围从1-26到0-25
int r = columnNumber % 26;
ans += 'A' + r;
columnNumber /= 26;
}
reverse(ans.begin(), ans.end());
return ans;
}(columnNumber - a₀) / 26 的本质是将数值右移一位(相当于除以26),这是进制转换中的标准操作:
-
在标准的进制转换中,我们通过反复除以基数来提取每一位数字
-
在Excel列名称的特殊情况下,我们需要先减去当前位的值,然后再除以26
-
这个除法操作确保了我们在处理完当前位后,正确地准备处理下一个更高位
598. 区间加法 II

二维前缀和

关键技巧:n & (n - 1)
这个操作的神奇之处在于它能"关掉"最右边的亮灯泡(最右边的1)。
为什么?
-
当你从n减去1时,最右边的1会变成0,而它右边的所有0会变成1
-
当你用n和(n-1)做"与"操作时,最右边的1及其右边的所有位都会变成0
-
但左边的位保持不变
414. 第三大的数
关于set的注意事项
-
set 初始化错误:
cpp
set<int> st = nums; // 错误:不能直接用 vector 初始化 set
应该使用迭代器范围初始化:
set<int> st(nums.begin(), nums.end());
-
set 没有 back() 方法:
cpp
if(n<3)return st.back(); // 错误:set 没有 back() 方法
set 是关联容器,没有 back() 方法。要获取最大元素,可以使用:
*st.rbegin() // 获取最后一个元素(即最大值)
-
不能对 set 使用 sort:
cpp
sort(st.begin(),st.end(),greater<int>()); // 错误:不能对 set 使用 sort
set 是有序容器,元素自动排序,不能使用 sort 算法重新排序。
-
set 不支持随机访问:
cpp
return st[2]; // 错误:set 不支持 [] 操作符
set 是双向迭代器容器,不支持随机访问,不能使用 [] 操作符。
默认情况下 std::set 是按升序排列的
// 创建一个降序排列的 set
std::set<int, std::greater<int>> descendingSet;
让我详细解释这段代码,它用于获取降序 set 中的第三大元素:
cpp
auto it = descendingSet.begin(); // 获取指向第一个元素的迭代器 std::advance(it, 2); // 将迭代器向前移动2个位置 return *it; // 返回迭代器指向的元素
详细解释
-
descendingSet.begin():-
在降序排列的 set 中,
begin()返回指向第一个(最大)元素的迭代器 -
例如,如果 set 包含
{8, 5, 3, 2, 1},begin()指向8
-
-
std::advance(it, 2):-
std::advance是一个标准库函数,用于将迭代器向前移动指定数量的位置 -
参数
2表示将迭代器向前移动 2 个位置 -
从
8开始,移动 1 次到5,移动 2 次到3
-
-
return *it:-
解引用迭代器,获取它当前指向的元素
-
在我们的例子中,返回
3,即第三大的元素
-
-
set 迭代器不支持随机访问:
set的迭代器是双向迭代器,不支持+操作符进行随机访问。这就是st.begin()+2会编译错误的原因。 -
需要包含头文件:使用
std::greater需要包含<functional>头文件。 -
// 可以使用 std::next 获取第三个元素的迭代器 auto it = std::next(st.begin(), 2); return *it; -
st.begin():-
返回指向 set 第一个元素的迭代器
-
在降序排列的 set 中,第一个元素是最大的元素
-
-
std::next(st.begin(), 2):-
std::next是一个标准库函数,它返回从给定迭代器向前移动指定步数后的新迭代器 -
参数
2表示向前移动 2 步 -
对于降序 set
{8, 5, 3, 2, 1}:-
st.begin()指向8 -
std::next(st.begin(), 1)指向5 -
std::next(st.begin(), 2)指向3(第三大的元素)
-
-
-
return *it:-
解引用迭代器,获取它指向的元素值
-
返回第三大的元素
-
557. 反转字符串中的单词 III
挨个字符的遍历直到遍历到空格,即找到了一个单词,记得遍历到了多少个空格就要把空格加入到要输出的字符串后面
151. 反转字符串中的单词
485. 最大连续 1 的个数
628. 三个数的最大乘积
分类讨论:
在所有可能的情况中取最大
首先将数组排序。
如果数组中全是非负数,则排序后最大的三个数相乘即为最大乘积;如果全是非正数,则最大的三个数相乘同样也为最大乘积。
如果数组中有正数有负数,则最大乘积既可能是三个最大正数的乘积,也可能是两个最小负数(即绝对值最大)与最大正数的乘积。
综上,我们在给数组排序后,分别求出三个最大正数的乘积,以及两个最小负数与最大正数的乘积,二者之间的最大值即为所求答案。
104. 二叉树的最大深度
为什么用 root->left 而不是 root.left?
-
在C++中,
root是一个指针(类型为TreeNode*),而不是对象本身。 -
当使用指针访问成员时,必须使用
->操作符。 -
如果
root是对象(而不是指针),则可以使用root.left,但本题中参数是指针,所以必须用root->left。
set
s.begin() //返回指向第一个元素的迭代器
s.end() //返回指向最后一个元素的迭代器
s.clear() //清除所有元素
s.count() //返回某个值元素的个数
s.empty() //如果集合为空,返回true,否则返回false
s.equal_range() //返回集合中与给定值相等的上下限的两个迭代器
s.erase() //删除集合中的元素
s.find(k) //返回一个指向被查找到元素的迭代器
s.insert() //在集合中插入元素
s.lower_bound(k) //返回一个迭代器,指向键值大于等于k的第一个元素
s.upper_bound(k) //返回一个迭代器,指向键值大于k的第一个元素
s.max_size() //返回集合能容纳的元素的最大限值
s.rbegin() //返回指向集合中最后一个元素的反向迭代器
s.rend() //返回指向集合中第一个元素的反向迭代器
s.size() //集合中元素的数目
860. 柠檬水找零
审题,要考虑的情况就那么几种,一顿if else 猛如虎
463. 岛屿的周长
-
周长的计算应该基于相邻单元格是否为水域或边界,而不是基于DFS的返回值。
-
缺少边界检查:您的代码中,对于每个方向,只检查了相邻单元格在网格内且为水的情况(
grid[dx[i]+x][y+dy[i]]==0)。如果相邻单元格超出网格边界,条件判断会跳过,从而不会计入周长。 -
周长计算不足:由于忽略了边界情况,对于边缘的陆地单元格,少计算了朝向网格边界的边,因此总周长比实际值小。
957. N 天后的牢房
-
您在内部循环中每计算一个单元格就立即更新
cells = a,这会导致后续单元格的计算使用新状态而不是前一天的状态 -
正确的做法应该是先计算完所有单元格的新状态,然后再更新整个状态
-
- 边界条件处理不当:
-
-
第一个和最后一个单元格应该始终为0,但您的条件
i-1<0||i+1>7可能没有正确处理所有情况
-
-
性能问题:
-
当n很大时(如示例2中的1000000000),直接模拟n天会非常慢,甚至超时
-
需要找到状态变化的周期性规律
-
-
状态记录:使用
seen映射来记录每个状态第一次出现的天数,使用states向量来存储每天的状态历史。这样可以帮助我们检测状态是否重复。 -
模拟每天状态:对于每一天,根据前一天的状态计算新状态:
-
第一个和最后一个牢房始终设置为0。
-
对于中间牢房,如果其左右相邻牢房状态相同,则设置为1;否则设置为0。
-
-
循环检测:每次生成新状态后,检查该状态是否已经在
seen中出现过:-
如果出现过,说明状态开始循环。计算循环的起始点
start和循环周期period。 -
然后利用模运算计算等效的天数
index,即从循环起始点开始,经过(n - start) % period天后的状态。直接返回states[index],避免重复模拟。 -
实际上,监狱状态的变化周期可能小于256天,而且循环起点可能不是从第一天开始。直接取模256可能导致模拟的天数不正确,从而得到错误的结果。
为了解决这个问题,我们需要动态检测状态循环的周期和起点。以下是修正后的代码,使用一个映射来记录每个状态首次出现的天数,当遇到重复状态时,计算循环周期,并利用模运算来减少模拟天数。
-
-
无循环情况:如果模拟到第n天都没有出现循环,则返回最后的状态。
栈和队列的函数
栈
栈的方法
1.push()将元素入栈
2.pop()删除栈顶元素,不会返回
3.top()返回栈顶元素,但不删除
4.size()栈的大小
5.empty() 判断栈是否为空
队列
队列的方法
1.push()将元素放入队列
2.pop()删除队首元素
3.front()返回队首元素,但不删除
4.back()返回队尾元素,但不删除
5.size()队列的大小
6.empty() 判断队列是否为空
1143. 最长公共子序列
考虑的是长度为前几个字符长度的字符串的最长公共子序列,子串一直扩展到总串,而不一定要以目前的这个第i个字符为要查找的最长公共子序列的末尾字符。
考虑 text1[0:i] 前I个字符 和 考虑 text2[0:j] 前J 个字符 的最长公共子序列
管它杂七杂八从哪儿块为的开头,从一个切入点分类讨论,就能包含所有情况
为什么 “取” 就能代表最优解?
因为:
- “取” 的结果 ≥ “不取” 的所有可能结果(前面已证明);
- “不取” 的所有可能结果(
dp[i-1][j]、dp[i][j-1])已经包含了 “不选这个字符” 的所有情况 —— 比如你担心的 “用 text2 [j-1] 之前的 d”,其实已经被dp[i][j-1]记录了(比如例子中dp[4][2]就是用 text2 [1] 的 d)。
所以,当字符相等时,直接用 dp[i-1][j-1] + 1 赋值给 dp[i][j],既不会遗漏 “不选” 的最优情况,又能得到 “选” 的更优(或同等)结果 —— 这不是 “强制取”,而是 “取” 本身就是最优解的代表。
总结:核心不是 “必须取”,而是 “取了不亏”
你不用纠结 “为什么一定要取”,而是要理解:
DP 的每一步都是 “从所有可能的候选解中选最优”,而当字符相等时,“取这个字符” 是一个 **“不会比任何其他候选解差”** 的选择 —— 所以直接用它来更新状态,既高效又能保证最优。
就算你 “不想取”,最终的最优长度也不会超过 “取” 的结果,因为 “不取” 的所有可能都已经被证明是≤“取” 的结果了。
用 “反证法” 证明 “取” 不会更差
假设存在一种情况,“不取” 的结果比 “取” 更好,即:max(dp[i-1][j], dp[i][j-1]) > dp[i-1][j-1] + 1。
我们来分析这个假设是否成立:
-
先看
dp[i-1][j](不用 text1 的 i-1,看 text1 前 i-1 + text2 前 j):dp[i-1][j]描述的 LCS,要么 “包含 text2 的 j-1”,要么 “不包含”:-
如果 “不包含 text2 的 j-1”:那
dp[i-1][j] = dp[i-1][j-1](因为 text2 的 j-1 没用),显然dp[i-1][j-1] < dp[i-1][j-1] + 1,假设不成立; -
如果 “包含 text2 的 j-1”:那 text2 的 j-1 必须在 text1 前 i-1 个字符中存在(否则不是公共子序列),此时
dp[i-1][j] = dp[k][j-1] + 1(k 是 text1 中匹配 text2 [j-1] 的位置,k < i-1)。但dp[k][j-1] ≤ dp[i-1][j-1](因为 k < i-1,text1 前 k 个是前 i-1 个的子集,LCS 不会更长),所以dp[i-1][j] = dp[k][j-1] + 1 ≤ dp[i-1][j-1] + 1,假设还是不成立。
-
-
再看
dp[i][j-1](不用 text2 的 j-1,看 text1 前 i + text2 前 j-1):
和上面对称,dp[i][j-1] ≤ dp[i-1][j-1] + 1,假设同样不成立。
综上,假设不成立——max(dp[i-1][j], dp[i][j-1]) ≤ dp[i-1][j-1] + 1 永远成立。
这意味着:“取” 这个相等字符得到的长度,要么比 “不取” 长,要么和 “不取” 一样长 —— 绝对不会更短。
map的遍历用迭代器auto 不能用索引遍历
// 方式一、迭代器
cout << "方式一、迭代器" << endl;
for (auto it = mp.begin(); it != mp.end(); it++) {
cout << it -> first << " " << it -> second << endl;
}
// 方式二、range for C++ 11版本及以上
cout << "\n方法二、 range for" << endl;
for (auto it : mp) {
cout << it.first << " " << it.second << endl;
}
// 方法三、 C++ 17版本及以上
cout << "\n方法三" << endl;
for (auto [key, val] : mp) {
cout << key << " " << val << endl;
}733. 图像渲染
如果矩阵不做更改,避免无效递归
if (currColor != color) {
dfs(image, sr, sc, currColor, color);
}
完全背包二维滚动数组
#include <iostream>
#include <vector>
using namespace std;
int main() {
int n, m;
cin >> n >> m;
vector<int> coins(n);
for (int i = 0; i < n; i++) {
cin >> coins[i];
}
if (n == 0) {
if (m == 0) {
cout << 1 << endl;
} else {
cout << 0 << endl;
}
return 0;
}
vector<vector<int>> dp(2, vector<int>(m + 1, 0));
dp[0][0] = 1;
for (int i = 1; i <= n; i++) {
int cur = i % 2;
int pre = 1 - cur;
dp[cur][0] = 1;
for (int j = 1; j <= m; j++) {
if (j >= coins[i - 1]) {
dp[cur][j] = dp[pre][j] + dp[cur][j - coins[i - 1]];
} else {
dp[cur][j] = dp[pre][j];
}
}
}
cout << dp[n % 2][m] << endl;
return 0;
}示例说明
假设我们有一种面额为 2 的货币,我们想计算组合成价值 2 的方案数:
-
如果不设置
dp[cur][0] = 1:-
dp[cur][2] = dp[pre][2] + dp[cur][0] = 0 + 0 = 0 -
这意味着我们无法识别"使用一个面额为 2 的货币"这种组合方式
-
-
如果设置
dp[cur][0] = 1:-
dp[cur][2] = dp[pre][2] + dp[cur][0] = 0 + 1 = 1 -
这正确地识别了"使用一个面额为 2 的货币"这种组合方式
-
因此,dp[cur][0] = 1 的设置是正确解决货币组合问题的关键,它确保了算法能够正确处理所有可能的组合方式,包括那些只使用单一货币的组合。
背包问题全面解析:01背包、完全背包、多重背包
1. 01背包问题
1.1 最大价值问题
问题描述:有N件物品和一个容量为V的背包,每件物品只能使用一次,求能获得的最大价值。
二维数组解法
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int main() {
int N, V;
cin >> N >> V;
vector<int> weight(N + 1), value(N + 1);
for (int i = 1; i <= N; i++) {
cin >> weight[i] >> value[i];
}
vector<vector<int>> dp(N + 1, vector<int>(V + 1, 0));
for (int i = 1; i <= N; i++) {
for (int j = 0; j <= V; j++) {
if (j < weight[i]) {
dp[i][j] = dp[i - 1][j];
} else {
dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - weight[i]] + value[i]);
}
}
}
cout << dp[N][V] << endl;
return 0;
}滚动数组解法
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int main() {
int N, V;
cin >> N >> V;
vector<int> weight(N + 1), value(N + 1);
for (int i = 1; i <= N; i++) {
cin >> weight[i] >> value[i];
}
vector<vector<int>> dp(2, vector<int>(V + 1, 0));
for (int i = 1; i <= N; i++) {
int cur = i % 2;
int pre = 1 - cur;
for (int j = 0; j <= V; j++) {
if (j < weight[i]) {
dp[cur][j] = dp[pre][j];
} else {
dp[cur][j] = max(dp[pre][j], dp[pre][j - weight[i]] + value[i]);
}
}
}
cout << dp[N % 2][V] << endl;
return 0;
}一维数组解法(最优)
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int main() {
int N, V;
cin >> N >> V;
vector<int> weight(N + 1), value(N + 1);
for (int i = 1; i <= N; i++) {
cin >> weight[i] >> value[i];
}
vector<int> dp(V + 1, 0);
for (int i = 1; i <= N; i++) {
for (int j = V; j >= weight[i]; j--) {
dp[j] = max(dp[j], dp[j - weight[i]] + value[i]);
}
}
cout << dp[V] << endl;
return 0;
}1.2 方案数问题
问题描述:有N件物品和一个容量为V的背包,每件物品只能使用一次,求恰好装满背包的方案数。
一维数组解法
#include <iostream>
#include <vector>
using namespace std;
int main() {
int N, V;
cin >> N >> V;
vector<int> weight(N + 1);
for (int i = 1; i <= N; i++) {
cin >> weight[i];
}
vector<int> dp(V + 1, 0);
dp[0] = 1; // 初始状态:容量为0有1种方案(什么都不选)
for (int i = 1; i <= N; i++) {
for (int j = V; j >= weight[i]; j--) {
dp[j] += dp[j - weight[i]];
}
}
cout << dp[V] << endl;
return 0;
}2. 完全背包问题
2.1 最大价值问题
问题描述:有N种物品和一个容量为V的背包,每种物品都有无限件可用,求能获得的最大价值。
二维数组解法
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int main() {
int N, V;
cin >> N >> V;
vector<int> weight(N + 1), value(N + 1);
for (int i = 1; i <= N; i++) {
cin >> weight[i] >> value[i];
}
vector<vector<int>> dp(N + 1, vector<int>(V + 1, 0));
for (int i = 1; i <= N; i++) {
for (int j = 0; j <= V; j++) {
if (j < weight[i]) {
dp[i][j] = dp[i - 1][j];
} else {
dp[i][j] = max(dp[i - 1][j], dp[i][j - weight[i]] + value[i]);
}
}
}
cout << dp[N][V] << endl;
return 0;
}当我们使用状态转移方程:
dp[i][j] = max(dp[i-1][j], dp[i][j - weight[i]] + value[i])
这个方程实际上已经考虑了选择任意数量第i种物品的所有可能情况:
dp[i-1][j]:表示完全不使用第i种物品
dp[i][j - weight[i]] + value[i]:表示使用至少一件第i种物品
关键 insight 在于:dp[i][j - weight[i]] 这个值本身已经包含了使用任意数量第i种物品来组成容量 j - weight[i] 的最优解。当我们在此基础上再加一件第i种物品,就相当于考虑了使用更多件第i种物品的情况。
关键区别
在状态转移方程中,选择当前物品时的状态转移来源不同:
01背包(每种物品只能用一次)
dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - weight[i]] + value[i]); // ↑ 这里使用的是上一行(i-1)的状态
完全背包(每种物品可以用无限次)
dp[i][j] = max(dp[i - 1][j], dp[i][j - weight[i]] + value[i]); // ↑ 这里使用的是当前行(i)的状态
为什么有这个区别?
-
01背包:每种物品只能使用一次,所以在考虑是否选择当前物品时,我们只能基于「前i-1种物品」的状态来做决策。
-
完全背包:每种物品可以使用无限次,所以在考虑是否选择当前物品时,我们可以基于「已经考虑过当前物品」的状态来做决策(即当前行的状态)。
3. 递归
一维数组解法(最优)
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int main() {
int N, V;
cin >> N >> V;
vector<int> weight(N + 1), value(N + 1);
for (int i = 1; i <= N; i++) {
cin >> weight[i] >> value[i];
}
vector<int> dp(V + 1, 0);
for (int i = 1; i <= N; i++) {
for (int j = weight[i]; j <= V; j++) {
dp[j] = max(dp[j], dp[j - weight[i]] + value[i]);
}
}
cout << dp[V] << endl;
return 0;
}2.2 方案数问题
问题描述:有N种物品和一个容量为V的背包,每种物品都有无限件可用,求恰好装满背包的方案数。
一维数组解法
#include <iostream>
#include <vector>
using namespace std;
int main() {
int N, V;
cin >> N >> V;
vector<int> weight(N + 1);
for (int i = 1; i <= N; i++) {
cin >> weight[i];
}
vector<int> dp(V + 1, 0);
dp[0] = 1; // 初始状态:容量为0有1种方案(什么都不选)
for (int i = 1; i <= N; i++) {
for (int j = weight[i]; j <= V; j++) {
dp[j] += dp[j - weight[i]];
}
}
cout << dp[V] << endl;
return 0;
}3. 多重背包问题
3.1 最大价值问题
问题描述:有N种物品和一个容量为V的背包,第i种物品最多有s[i]件可用,求能获得的最大价值。
二维数组解法
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int main() {
int N, V;
cin >> N >> V;
vector<int> weight(N + 1), value(N + 1), s(N + 1);
for (int i = 1; i <= N; i++) {
cin >> weight[i] >> value[i] >> s[i];
}
vector<vector<int>> dp(N + 1, vector<int>(V + 1, 0));
for (int i = 1; i <= N; i++) {
for (int j = 0; j <= V; j++) {
for (int k = 0; k <= s[i] && k * weight[i] <= j; k++) {
dp[i][j] = max(dp[i][j], dp[i - 1][j - k * weight[i]] + k * value[i]);
}
}
}
cout << dp[N][V] << endl;
return 0;
}二进制优化+一维数组解法(最优)
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
struct Good {
int weight, value;
};
int main() {
int N, V;
cin >> N >> V;
vector<Good> goods;
for (int i = 1; i <= N; i++) {
int weight, value, s;
cin >> weight >> value >> s;
// 二进制优化
for (int k = 1; k <= s; k *= 2) {
s -= k;
goods.push_back({weight * k, value * k});
}
if (s > 0) {
goods.push_back({weight * s, value * s});
}
}
vector<int> dp(V + 1, 0);
// 转化为01背包问题
for (auto good : goods) {
for (int j = V; j >= good.weight; j--) {
dp[j] = max(dp[j], dp[j - good.weight] + good.value);
}
}
cout << dp[V] << endl;
return 0;
}3.2 方案数问题
问题描述:有N种物品和一个容量为V的背包,第i种物品最多有s[i]件可用,求恰好装满背包的方案数。
一维数组解法
#include <iostream>
#include <vector>
using namespace std;
int main() {
int N, V;
cin >> N >> V;
vector<int> weight(N + 1), s(N + 1);
for (int i = 1; i <= N; i++) {
cin >> weight[i] >> s[i];
}
vector<int> dp(V + 1, 0);
dp[0] = 1; // 初始状态:容量为0有1种方案(什么都不选)
for (int i = 1; i <= N; i++) {
for (int j = V; j >= 0; j--) {
for (int k = 1; k <= s[i] && k * weight[i] <= j; k++) {
dp[j] += dp[j - k * weight[i]];
}
}
}
cout << dp[V] << endl;
return 0;
}多重背包问题状态转移方程解析
在多重背包问题的二维数组解法中,状态转移方程的正确写法是:
dp[i][j] = max(dp[i][j], dp[i - 1][j - k * weight[i]] + k * value[i]);而不是:
dp[i][j] = max(dp[i-1][j], dp[i - 1][j - k * weight[i]] + k * value[i]);原因分析
1. 逻辑上的区别
-
正确写法:在考虑前i种物品、容量为j的情况下,我们尝试选择0到s[i]个第i种物品,并取最大值。
-
错误写法:每次只比较「不选第i种物品」和「选k个第i种物品」两种情况,但忽略了可能选择不同数量k的情况。
2. 具体解释
在多重背包问题中,对于每种物品,我们可以选择0个、1个、2个...最多s[i]个。我们需要在这些所有可能的选择中找到最大值。
正确的状态转移方程:
for (int k = 0; k <= s[i] && k * weight[i] <= j; k++) {
dp[i][j] = max(dp[i][j], dp[i - 1][j - k * weight[i]] + k * value[i]);
}这个循环的含义是:
-
初始化时,
dp[i][j]可能已经被设置为某个值(通常是0或者前一种状态的值) -
对于每个可能的k值(选择的数量),我们计算选择k个第i种物品的价值
-
用
max函数不断更新dp[i][j],确保它始终是当前找到的最大值
如果使用错误的写法:
dp[i][j] = max(dp[i-1][j], dp[i - 1][j - k * weight[i]] + k * value[i]);这里的问题是:
-
每次循环只比较两种选择,而不是所有可能的选择
-
随着k的变化,我们可能会覆盖掉之前找到的更好解
-
最终结果只反映了最后一次比较的结果,而不是所有可能选择中的最大值
3. 更清晰的实现方式
实际上,更清晰的做法是先将dp[i][j]初始化为dp[i-1][j](表示不选任何第i种物品),然后再考虑选择1个、2个...最多s[i]个的情况:
// 先初始化为不选第i种物品的情况
dp[i][j] = dp[i-1][j];
// 再考虑选择1个到s[i]个第i种物品的情况
for (int k = 1; k <= s[i] && k * weight[i] <= j; k++) {
dp[i][j] = max(dp[i][j], dp[i - 1][j - k * weight[i]] + k * value[i]);
}这种写法逻辑上更清晰,也更容易理解。
总结对比
| 问题类型 | 特点 | 遍历顺序 | 状态转移方程 |
|---|---|---|---|
| 01背包 | 每种物品最多选一次 | 逆序遍历 | dp[j] = max(dp[j], dp[j-w]+v) |
| 完全背包 | 每种物品无限次使用 | 正序遍历 | dp[j] = max(dp[j], dp[j-w]+v) |
| 多重背包 | 每种物品有限次使用 | 二进制优化+逆序 | 转化为01背包 |
关键区别:
-
遍历顺序:01背包 一维数组 逆序,完全背包 一维数组 正序
-
初始化:最大价值问题通常初始化为0,方案数问题
dp[0]=1 -
状态转移:最大价值用max,方案数用加法
518. 零钱兑换 II
vector<int>vaild(amount+1);
vaild[0]=1;
for(int i=0;i<n;i++){
for(int j=coins[i];j<=amount;j++){
vaild[j]=vaild[j]||vaild[j-coins[i]];
}
}
if(!vaild[amount]){
return 0;
}为什么需要 valid 数组?
-
问题背景:题目要求计算凑成总金额的硬币组合数,且保证最终结果在 32 位整数范围内。但中间计算过程中,组合数可能非常大,导致整数溢出(即使使用
long long也可能溢出)。 -
解决方案:先使用
valid数组检查目标金额amount是否可以被凑出。如果不可达,直接返回 0,避免不必要的组合数计算,从而减少溢出风险。 -
valid数组的作用:valid[i]表示金额i是否可以被凑出。初始化valid[0] = true(金额 0 总是可达),然后遍历每种硬币,更新valid数组。
452. 用最少数量的箭引爆气球
核心思路(3 步理解)
-
排序关键:按气球的「结束坐标(xend)」从小到大排序。
理由:结束早的气球如果不优先处理,后续可能需要更多箭(比如一个结束早的气球和多个结束晚的气球重叠,优先用箭引爆结束早的,能同时覆盖后面的重叠气球)。 -
贪心选箭的位置:每支箭的最佳位置是「当前气球的结束坐标(xend)」。
理由:在结束坐标射箭,既能确保引爆当前气球,又能最大化覆盖后面可能重叠的气球(后面的气球开始坐标若≤当前结束坐标,就能被同一支箭引爆)。 -
计数逻辑:
- 初始至少需要 1 支箭(若有气球);
- 遍历排序后的气球,若当前气球的「开始坐标(xstart)> 上一支箭的位置」,说明当前气球无法被上一支箭覆盖,需要新增 1 支箭,并更新箭的位置为当前气球的结束坐标。
二、C++ 简洁实现(代码仅 10 行核心逻辑)
cpp
#include <vector>
#include <algorithm>
using namespace std;
class Solution {
public:
int findMinArrowShots(vector<vector<int>>& points) {
// 1. 按气球的结束坐标(xend)升序排序(核心!)
sort(points.begin(), points.end(), [](const vector<int>& a, const vector<int>& b) {
return a[1] < b[1]; // 按第二个元素(xend)从小到大排
});
// 2. 边界处理:无气球时返回0
if (points.empty()) return 0;
// 3. 贪心计数:每支箭尽量覆盖更多气球
int res = 1; // 至少需要1支箭
int last_arrow = points[0][1]; // 第一支箭的位置:第一个气球的结束坐标
for (int i = 1; i < points.size(); ++i) {
// 若当前气球的开始坐标 > 上一支箭的位置,需要新箭
if (points[i][0] > last_arrow) {
res++;
last_arrow = points[i][1]; // 更新箭的位置为当前气球的结束坐标
}
}
return res;
}
};
有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)