大模型云端调用与本地部署?看这一篇就够了!
本文详细介绍了大模型应用开发的两种实践方式:API调用和本地部署。首先讲解DeepSeek API调用流程,包括注册账号、Postman测试和使用Python代码实现。然后介绍Qwen3-0.6B模型的本地部署方法,涵盖模型下载、依赖安装和Python推理代码实现。内容涵盖从API快速验证到私有化部署的完整流程,适合大模型初学者入门实践。文章提供了详细的操作步骤和代码示例,帮助开发者快速掌握大模型
在大模型应用开发中,API 调用是快速验证功能的常用方式,而本地部署则能满足私有化、低延迟等场景需求。本文将详细记录从 DeepSeek API 调用(含 Postman 测试与 Python 代码实现)到 Qwen3-0.6B 模型本地部署的完整流程,适合大模型初学者快速上手实践。

【如果你对人工智能的学习有兴趣可以看看我的其他博客,对新手很友好!!!】
【本猿定期无偿分享学习成果,欢迎关注一起学习!!!】
一、DeepSeek API 调用实践
DeepSeek 开放平台提供了便捷的大模型 API 服务,通过注册账号、充值、接口测试与代码调用四个步骤,即可快速实现大模型能力集成。
1.1 准备工作:注册 DeepSeek 账号并充值
-
访问DeepSeek 开放平台(DeepSeek),点击右上角 “注册” 按钮,使用手机号或邮箱完成账号注册(需完成实名认证以解锁充值功能)。
-
注册成功后,进入控制台首页,点击左侧 “充值中心”,选择适合的充值金额(支持小额测试,如 10 元),完成支付后,可在 “账户余额” 中查看可用额度。
-
充值完成后创建自己的API keys(注意妥善保存!)
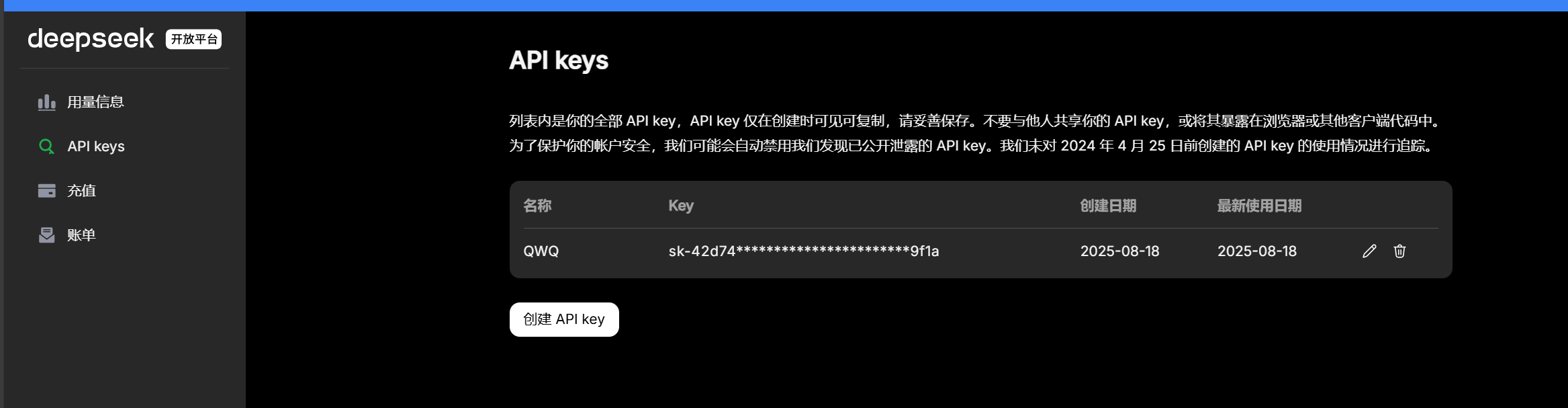
1.2 使用 Postman 测试 DeepSeek API
Postman 是一款常用的接口测试工具,能直观验证 API 请求格式与返回结果,步骤如下:
步骤 1:下载并安装 Postman
访问 Postman 官方下载页
Download Postman | Get Started for Free
自行下载安装即可
步骤 2:配置 API 请求(参考 DeepSeek 官方文档)
进入 DeepSeek 官方文档的 “首次调用 API” 页面

打开postman
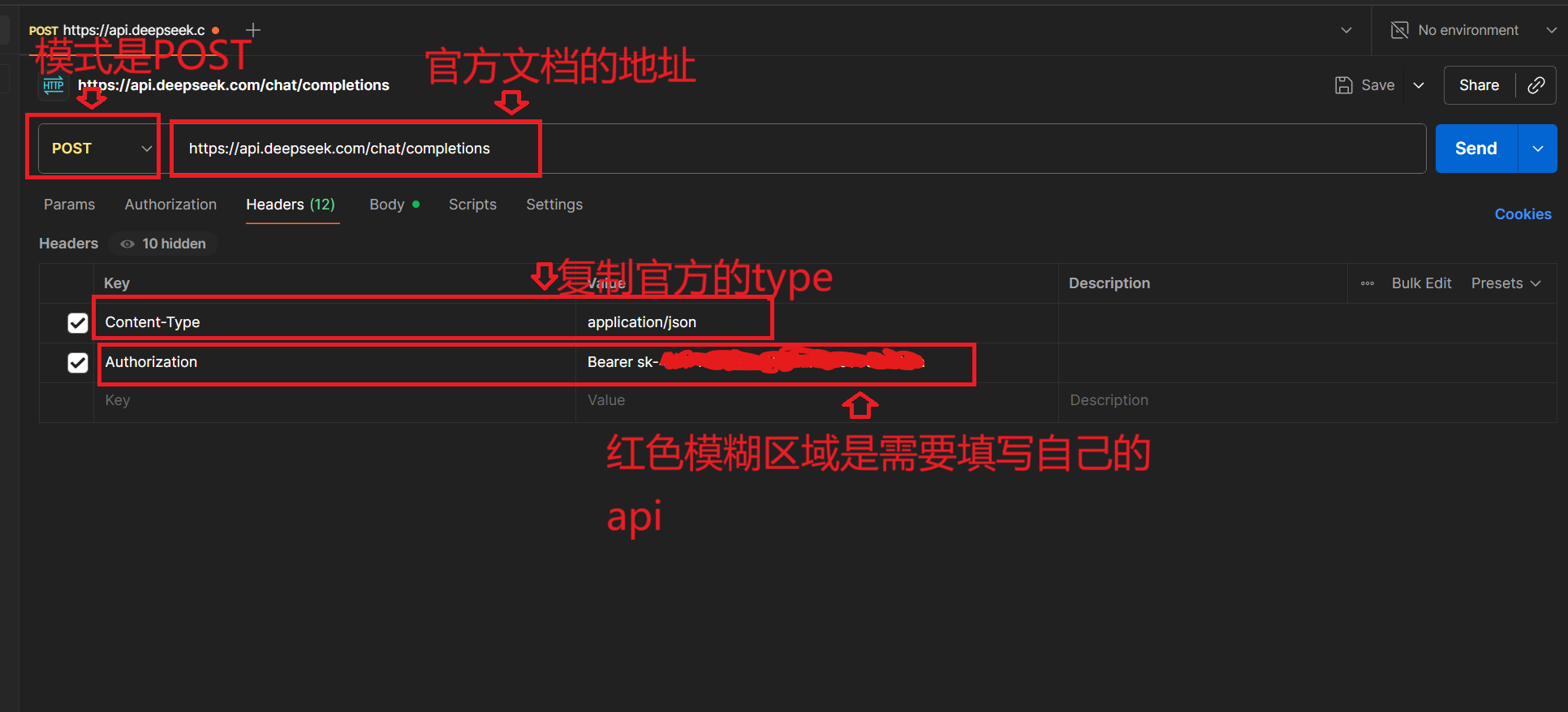
然后
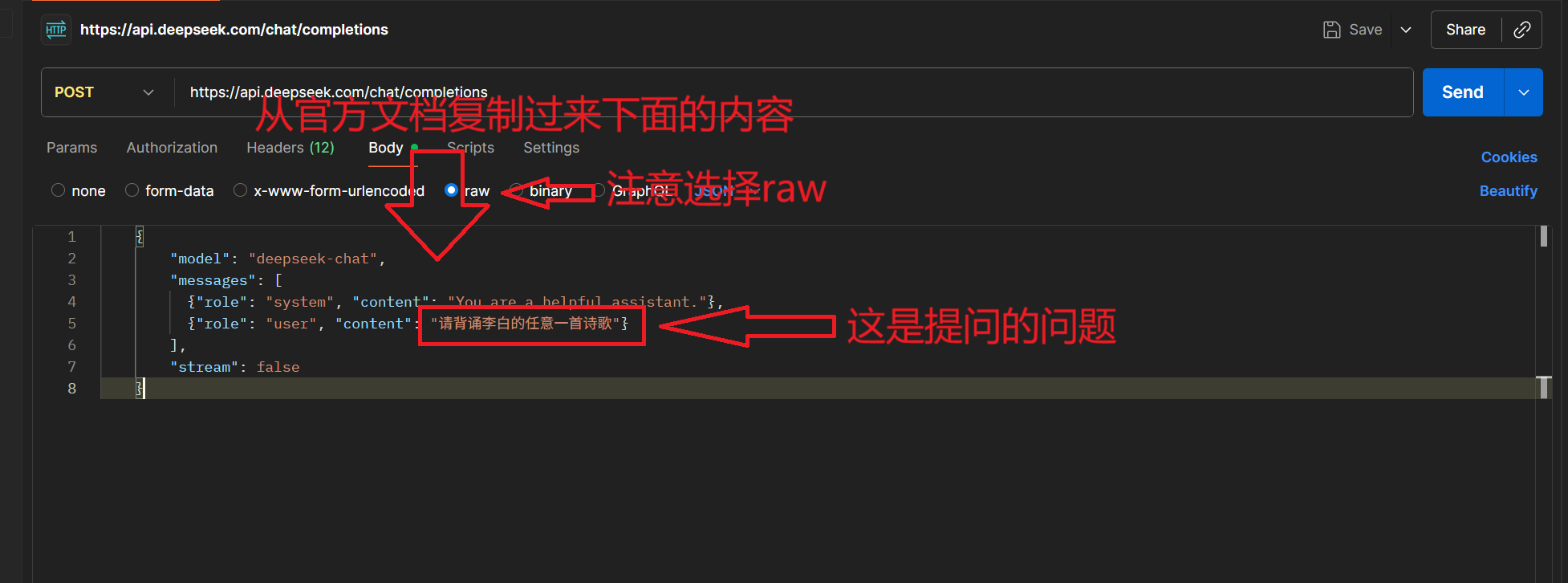
点击Send即可

1.3 使用 Python 调用 DeepSeek API
Postman 验证通过后,可将 API 调用逻辑集成到 Python 代码中,步骤如下:
步骤 1:安装依赖库
DeepSeek API 兼容 OpenAI 的 Python SDK(官方推荐),打开终端执行以下命令安装:
pip3 install openai步骤 2:编写 Python 代码并修改参数
新建 Python 文件(如deepseek_api_call.py),参考官方文档示例代码,修改api_key、model、messages等参数:
官方文档:
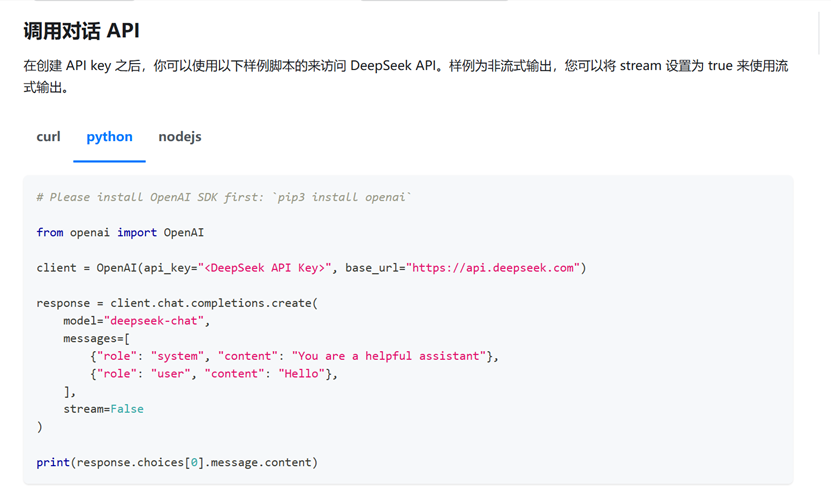
复制粘贴进IDE
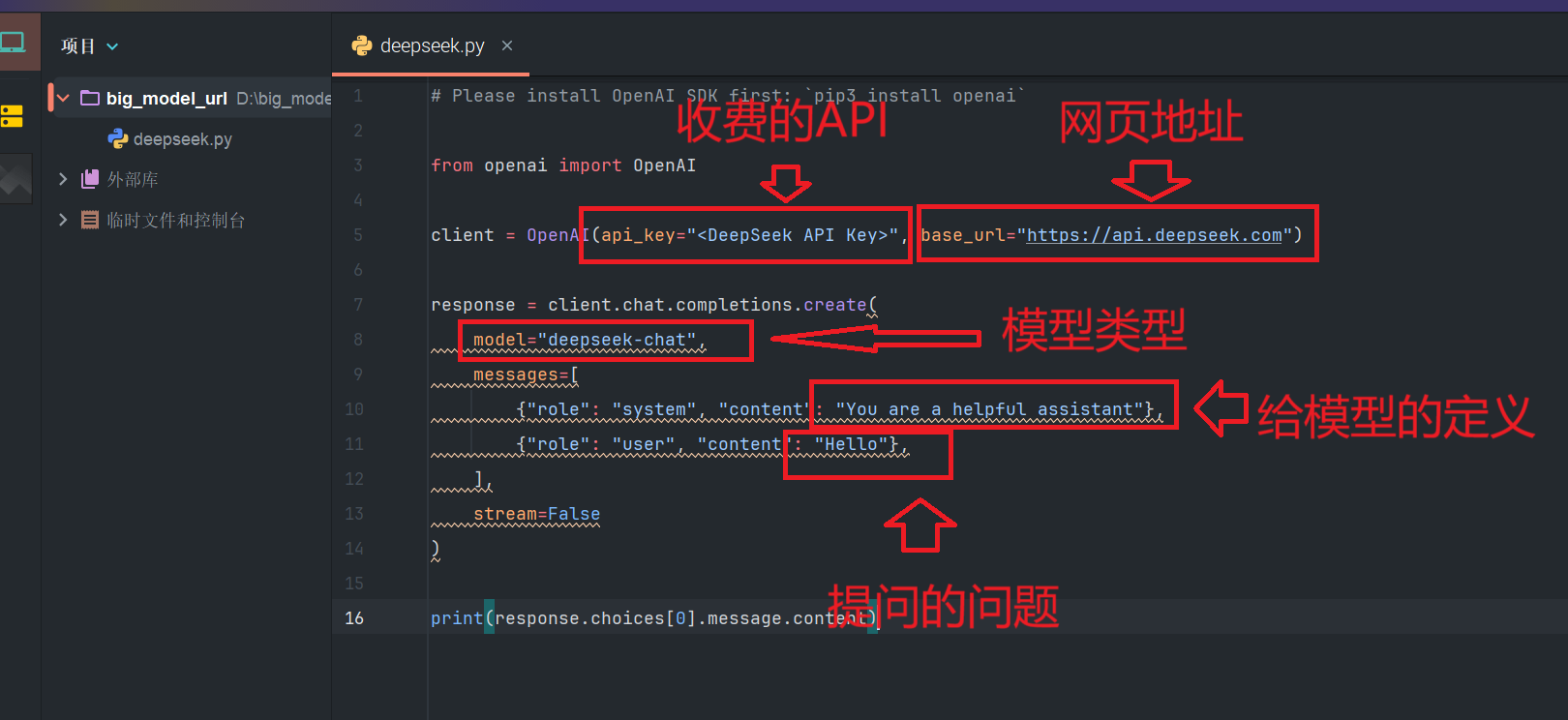
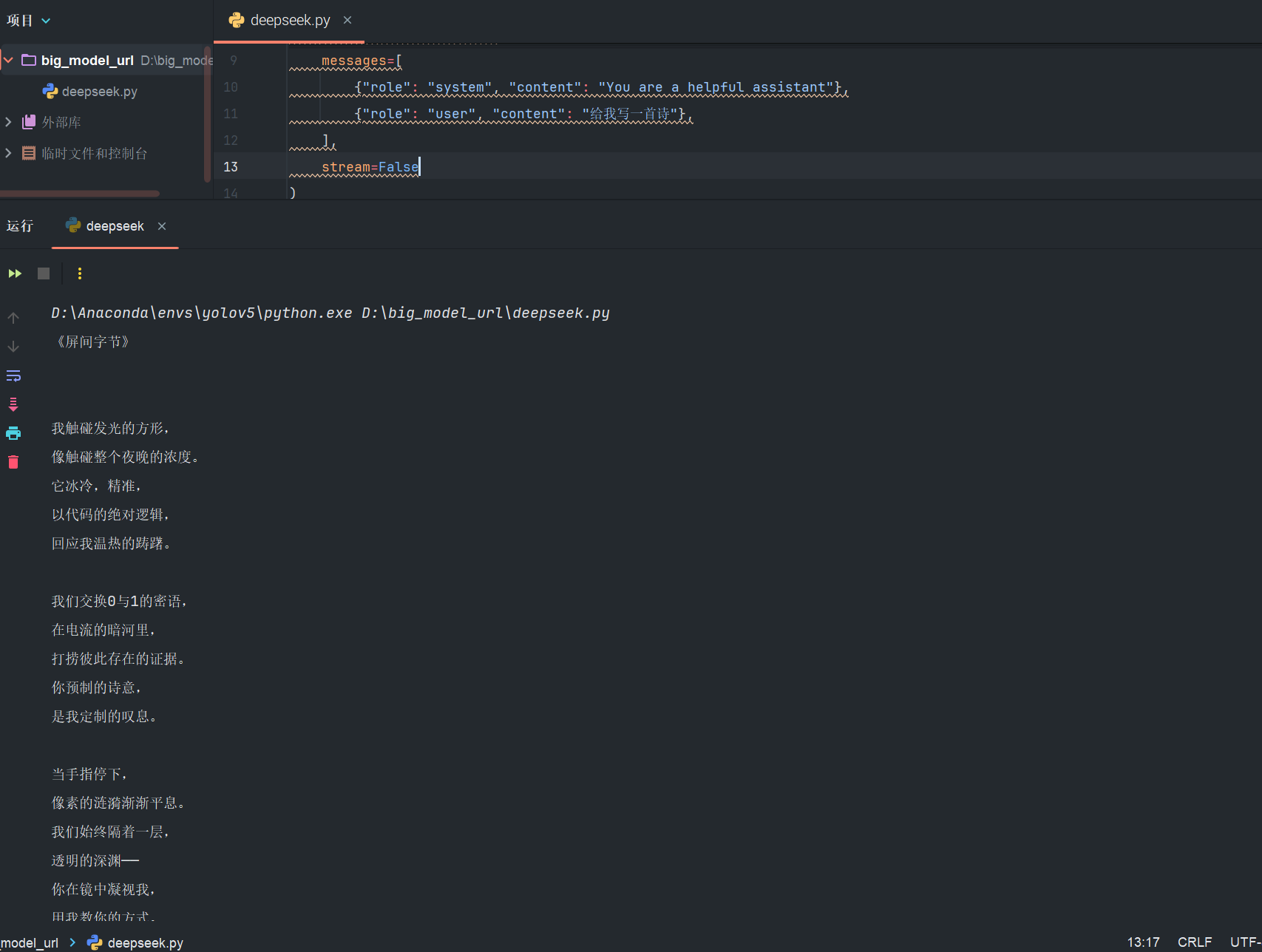
修改好参数,运行即可
二、Qwen3-0.6B 大模型本地部署
若需脱离网络依赖或实现私有化部署,可下载 Qwen3-0.6B 模型(阿里云通义千问系列轻量模型,适合个人电脑运行),通过魔搭社区下载并本地调用。
2.1 准备工作:下载 Qwen3-0.6B 模型
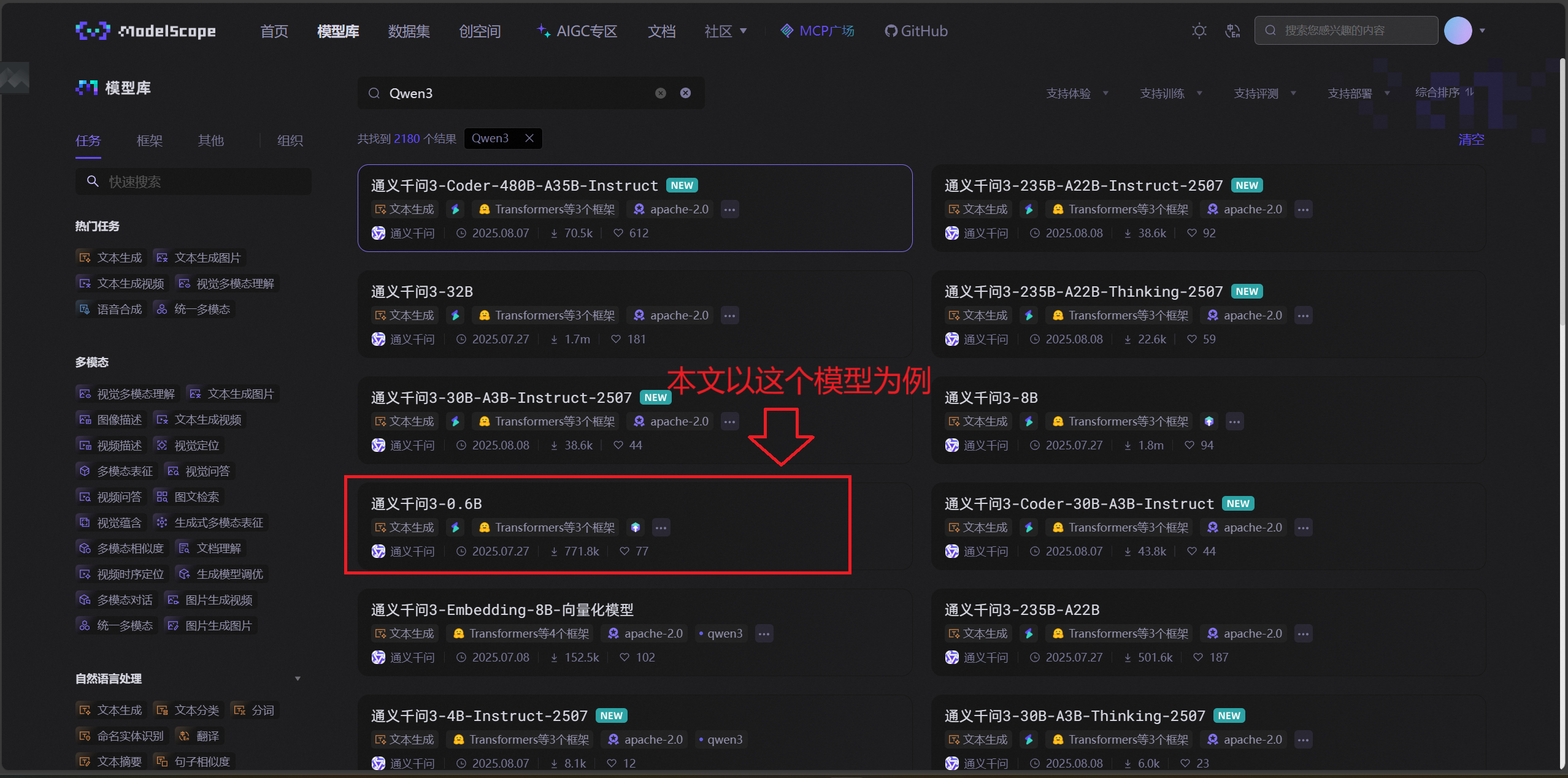
魔搭社区(ModelScope)是国内常用的开源模型库,提供 Qwen 系列模型的官方下载渠道,步骤如下:
-
访问魔搭社区首页(ModelScope 魔搭社区),搜索 “Qwen3”,找到 “Qwen/Qwen3-0.6B” 模型(注意选择官方发布的模型,避免第三方镜像)。
-
查看模型说明,确认硬件要求(Qwen3-0.6B 显存需求较低,8GB 显存的 GPU 即可运行,CPU 也可运行但速度较慢)。
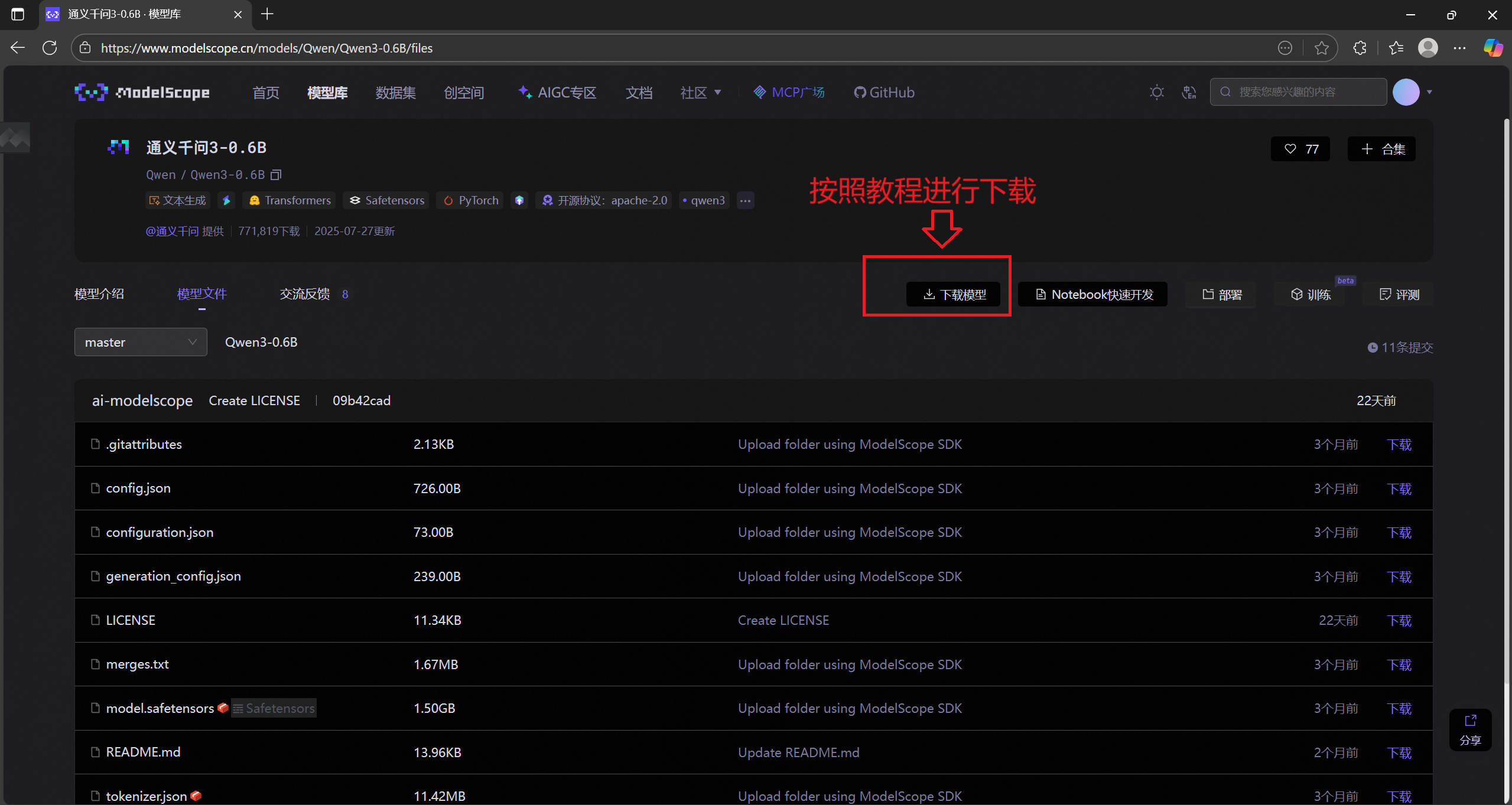
2.2 安装依赖库并下载模型
步骤 1:安装魔搭 SDK(modelscope)
打开终端,执行以下命令安装魔搭社区的 Python SDK,用于下载模型:
pip install modelscope步骤 2:通过终端命令下载模型
在终端执行以下命令,指定模型名称和下载路径(默认下载到用户目录,也可通过--local_dir指定自定义路径,推荐cd到工作目录进行下载!):
modelscope download --model Qwen/Qwen3-0.6B2.3 编写 Python 代码实现本地推理
新建 Python 文件(如qwen_ask.py),通过transformers库加载模型并实现对话推理,代码如下(含关键注释):
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
models_path = "models/Qwen/Qwen3-0___6B"
# 模型加载
model = AutoModelForCausalLM.from_pretrained(models_path, torch_dtype="auto")
tokenizer = AutoTokenizer.from_pretrained(models_path)
# 确保设置了pad_token
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
device = "cuda" if torch.cuda.is_available() else "cpu"
model = model.to(device)
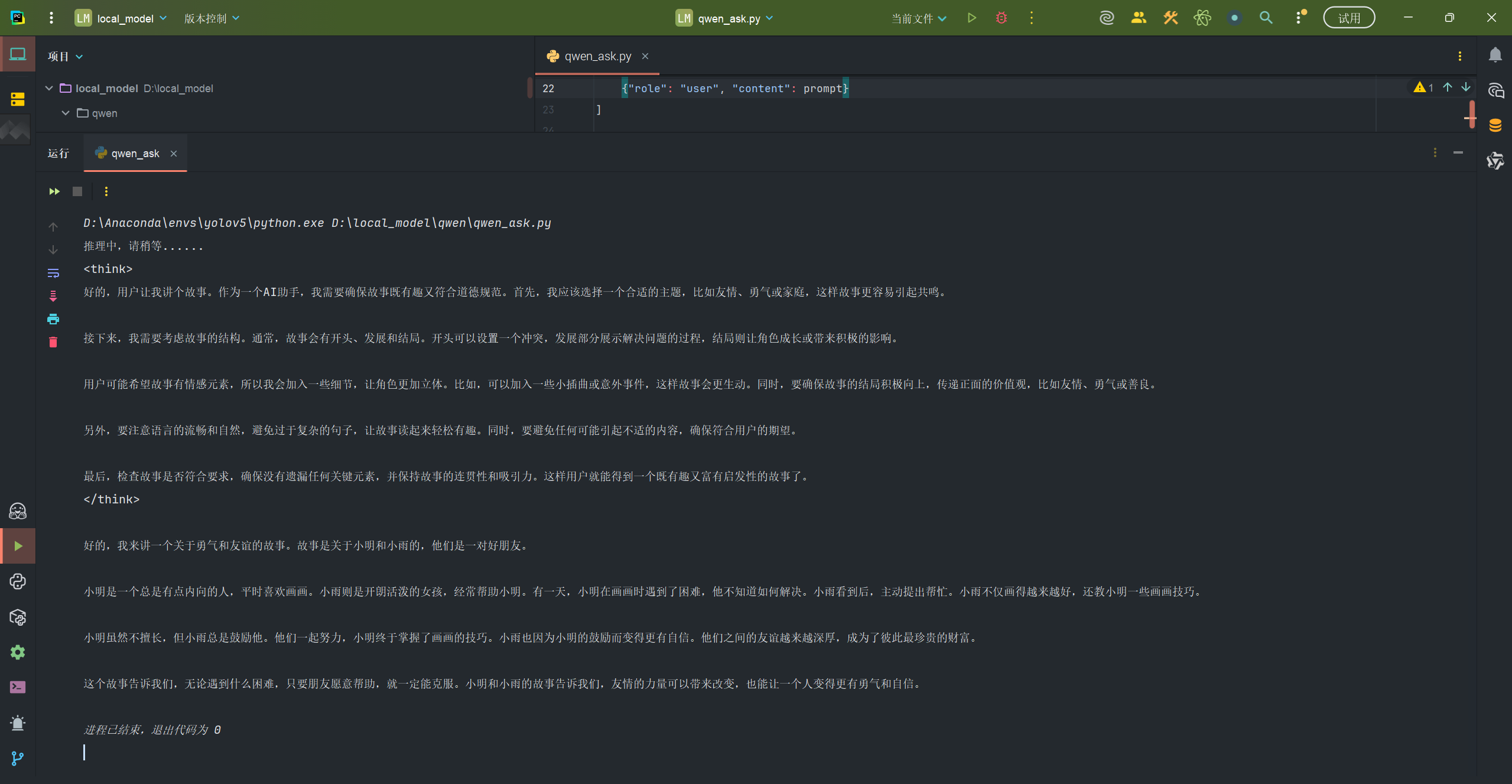
print("推理中,请稍等......")
# 数据输入
prompt = "请给我讲个故事"
message = [
{"role": "system", "content": "你是一个 helpful 的助手"},
{"role": "user", "content": prompt}
]
# 使用正确的方式处理输入
inputs = tokenizer.apply_chat_template(
message,
tokenize=True,
add_generation_prompt=True,
return_tensors="pt",
add_special_tokens=True
).to(device)
# 显式创建attention mask解决警告
attention_mask = (inputs != tokenizer.pad_token_id).long().to(device)
# 推理参数
gen_kwargs = dict(
do_sample=True,
top_k=10,
top_p=0.8,
temperature=0.6,
max_length=512,
attention_mask=attention_mask # 添加attention_mask参数
)
with torch.no_grad():
outputs = model.generate(inputs, **gen_kwargs)
# 解码输出
input_length = inputs.shape[1]
new_length = outputs[0][input_length:]
response = tokenizer.decode(new_length, skip_special_tokens=True)
print(response)
运行代码即可
[感谢你的观看!]

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 28
28 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)