医疗数据共享平台实战:基于IPFS加密存储、联邦学习与权限合约
- **核心问题**:数据孤岛、隐私泄露风险、中心化存储成本高。- **解决方案**:- **IPFS**:分布式存储降低中心化风险。- **联邦学习**:数据不出本地,联合训练AI模型。- **权限合约**:基于区块链的细粒度访问控制。
·
目录
医疗数据共享平台实战:基于IPFS加密存储、联邦学习与权限合约
1. 引言:医疗数据共享的挑战与机遇
- 核心问题:数据孤岛、隐私泄露风险、中心化存储成本高。
- 解决方案:
- IPFS:分布式存储降低中心化风险。
- 联邦学习:数据不出本地,联合训练AI模型。
- 权限合约:基于区块链的细粒度访问控制。
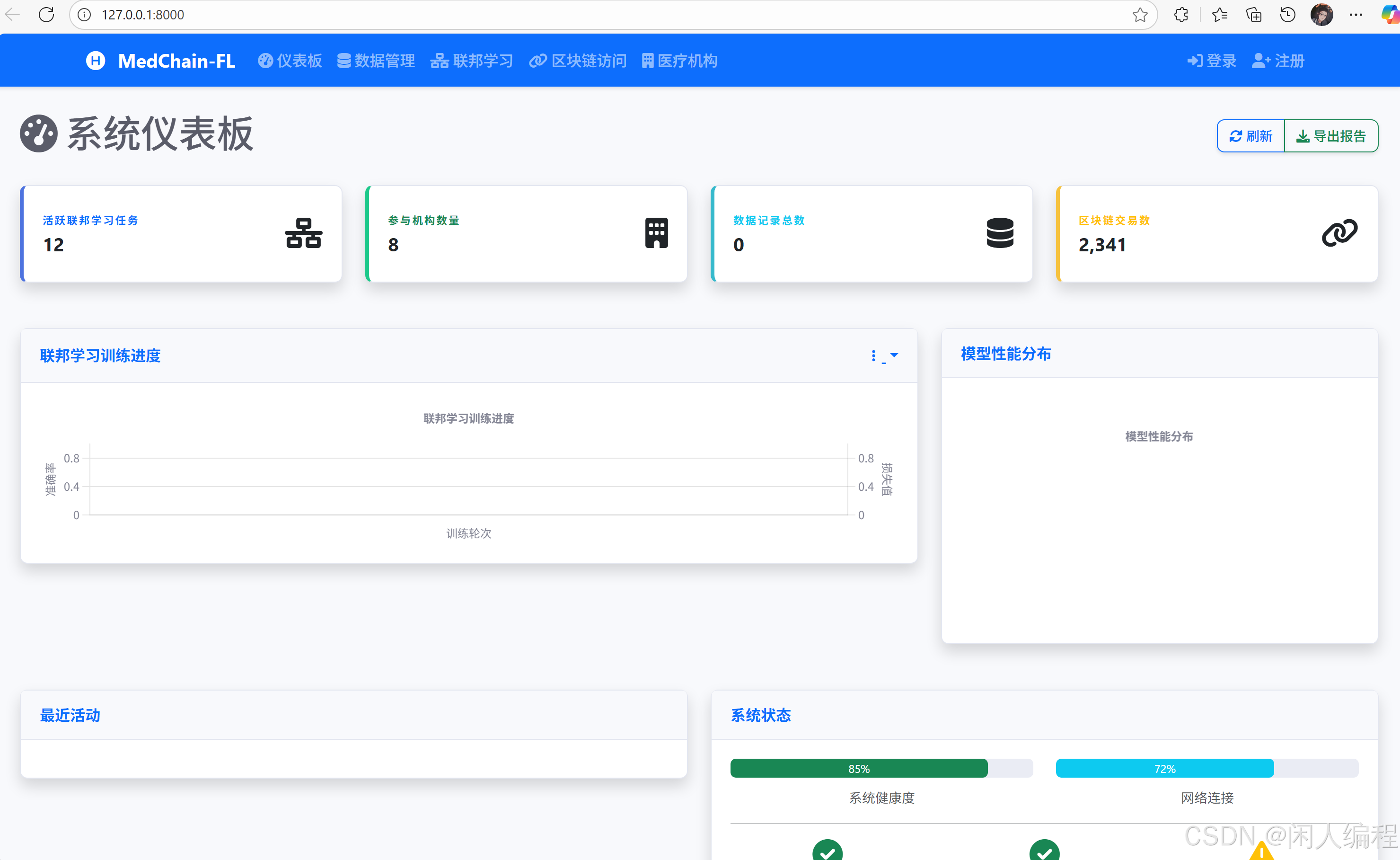
2. 整体架构设计
3. 模块实现详解
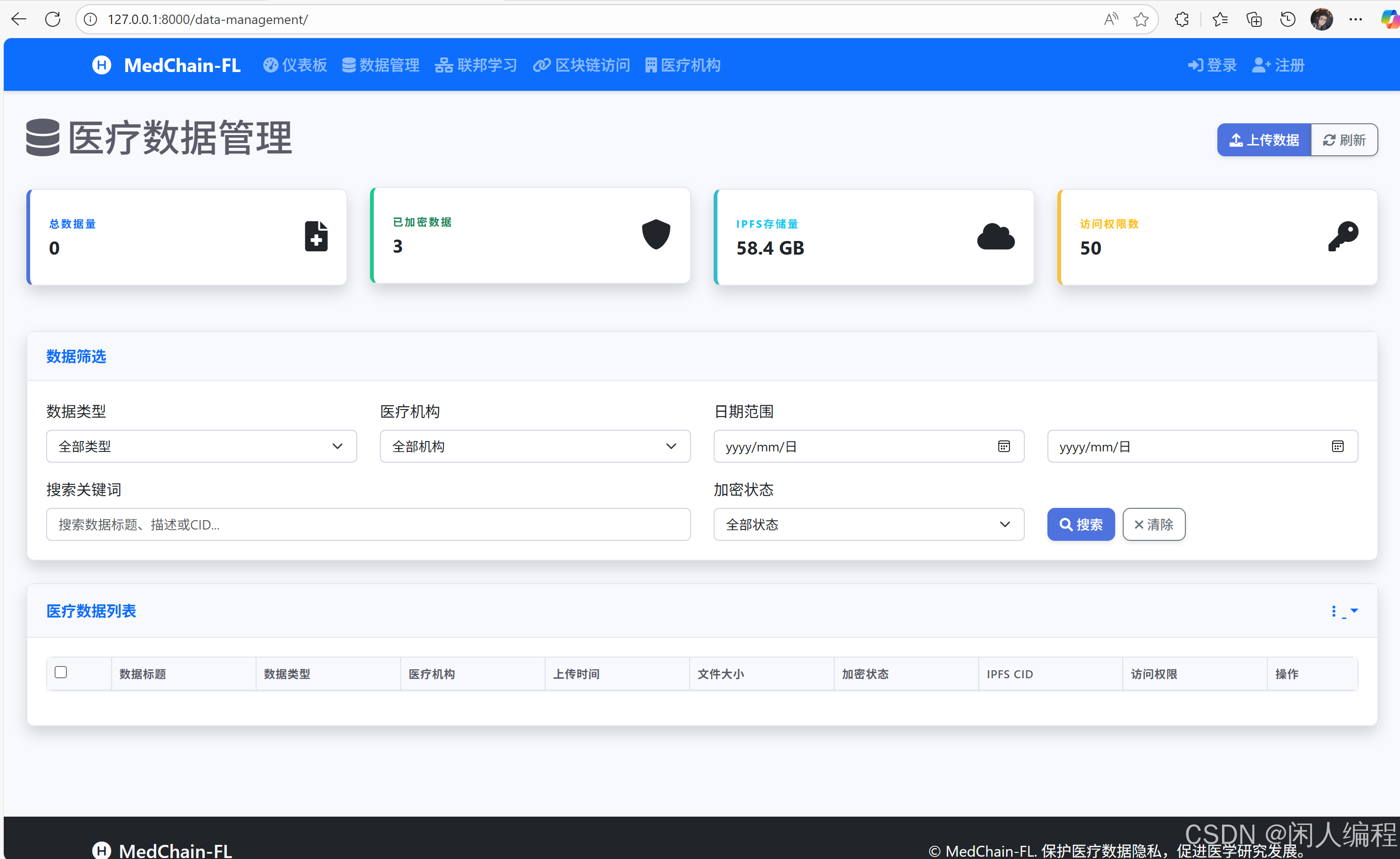
3.1 IPFS加密存储
- 步骤1:数据预处理
- 医疗影像/病历 → 分段为
JSON或二进制文件。 - 使用AES-256加密数据,密钥由数据所有者管理。
- 医疗影像/病历 → 分段为
- 步骤2:IPFS存储
- 上传加密数据至IPFS,获取唯一
CID(内容标识符)。 - 存储结构示例:
/medical_data/ ├── patient_A/ │ ├── MRI_scan_encrypted.cid # 存储CID而非原始数据 │ └── diagnosis_report_encrypted.cid └── patient_B/...
- 上传加密数据至IPFS,获取唯一
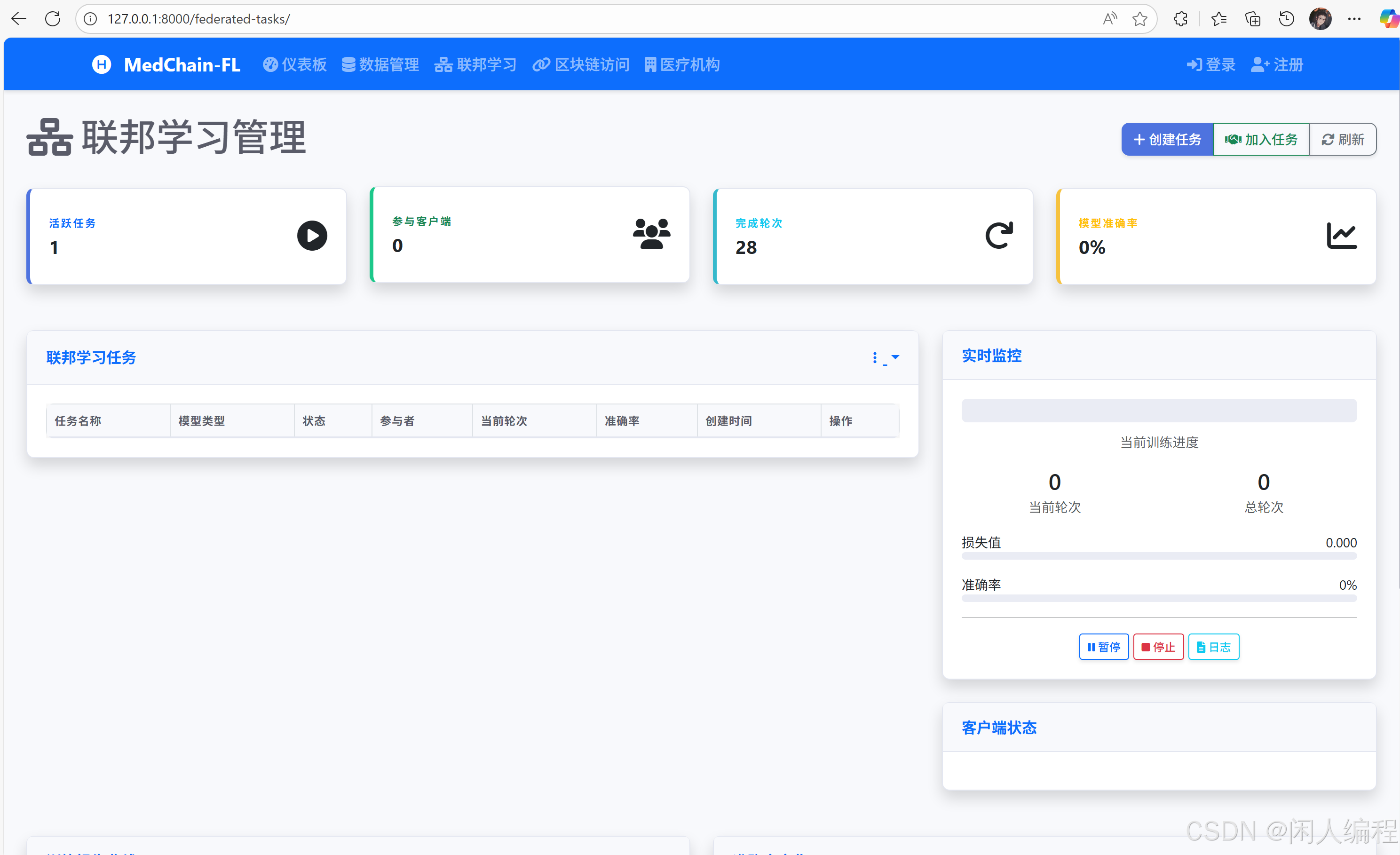
3.2 联邦学习模型训练
- 框架选择:PySyft + PyTorch
- 流程:
- 本地训练:各医院用本地数据训练模型。
- 参数加密:上传模型梯度(非原始数据)至协调节点。
- 聚合更新:协调节点通过安全聚合(Secure Aggregation)生成全局模型。
- 关键配置:
# 伪代码:联邦学习轮次配置 class FederatedTrainer: def __init__(self): self.nodes = ["hospital_1", "hospital_2"] # 参与节点 self.global_model = ResNet50() # 初始模型 def aggregate(self, encrypted_gradients): # 解密并聚合梯度 return updated_model
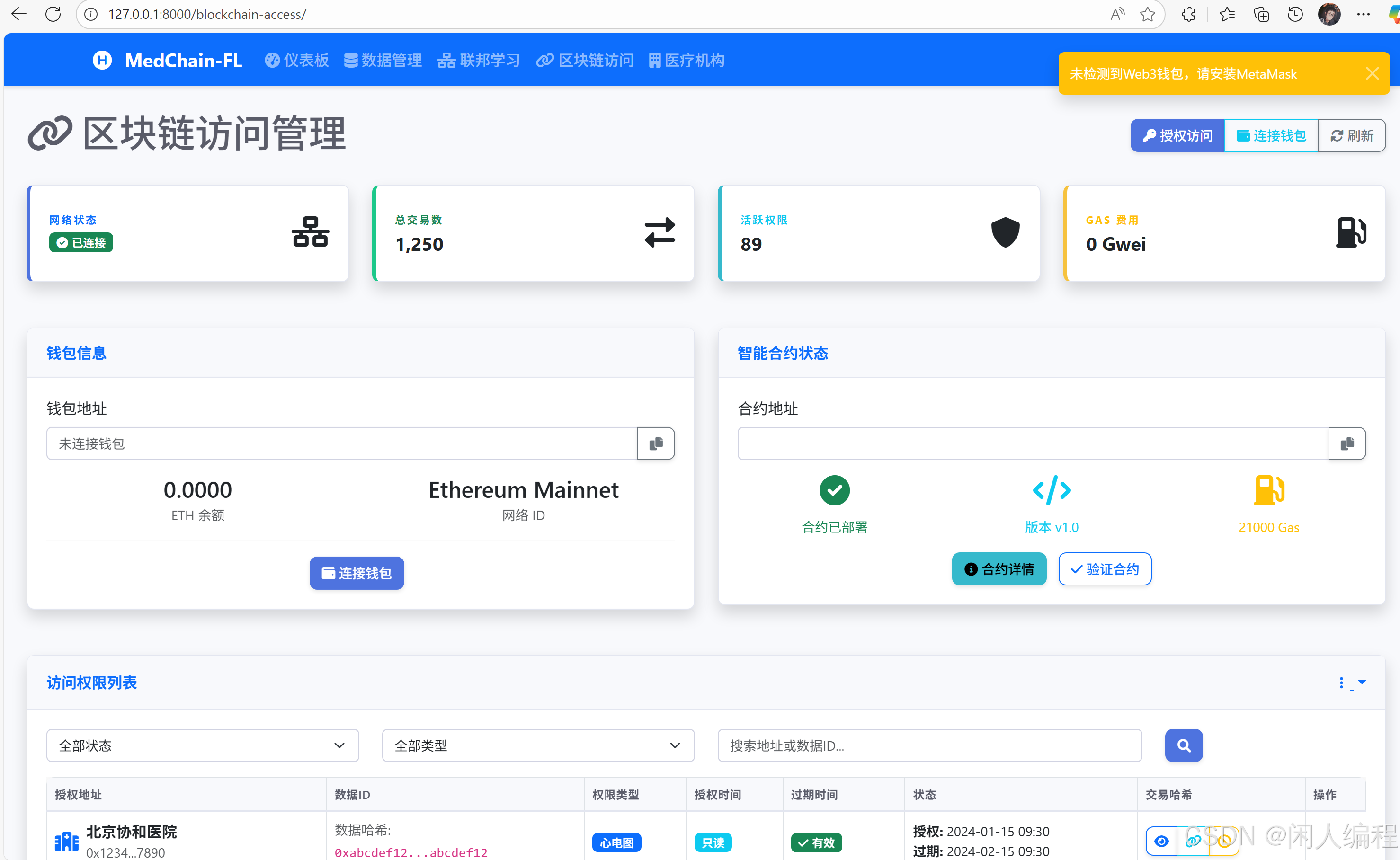
3.3 权限智能合约(Solidity)
- 功能设计:
- 数据所有者部署合约,绑定IPFS的
CID。 - 定义访问角色(医生、研究机构、患者本人)。
- 数据所有者部署合约,绑定IPFS的
- 合约逻辑示例:
contract MedicalAccess { mapping(bytes32 => address) public cidToOwner; // CID关联所有者 mapping(address => mapping(bytes32 => bool)) public permissions; // 权限表 // 授权函数 function grantAccess(bytes32 cid, address grantee) public { require(msg.sender == cidToOwner[cid], "Not owner"); permissions[grantee][cid] = true; } // 访问验证(链下服务调用) function checkAccess(address user, bytes32 cid) public view returns (bool) { return permissions[user][cid]; } }
4. 系统整合与工作流
- 数据上传:
- 医院加密数据 → 存储至IPFS → 记录
CID至权限合约。
- 医院加密数据 → 存储至IPFS → 记录
- 数据请求:
- 医生申请访问 → 合约验证权限 → 返回IPFS的
CID→ 解密数据。
- 医生申请访问 → 合约验证权限 → 返回IPFS的
- 联邦学习触发:
- 协调节点定期拉取各节点梯度 → 更新全局模型 → 分发新模型至医院。
5. 安全与隐私保护措施
- 数据层:
- IPFS传输使用
Libp2p加密通道。 - 本地存储加密密钥(硬件安全模块HSM)。
- IPFS传输使用
- 模型层:
- 联邦学习添加差分噪声(DP)防隐私推断。
- 合约层:
- 权限变更记录在链(不可篡改)。
6. 性能优化方向
- IPFS加速:Pin热门数据至专用节点(如Filecoin)。
- 联邦学习效率:
- 动态选择节点(基于数据质量和网络状态)。
- 压缩梯度传输(稀疏化+量化)。
- 合约成本:
- 采用Layer2(如Polygon)降低Gas费用。
7. 总结
通过结合IPFS(去中心化存储)、联邦学习(隐私安全训练)、权限合约(可控数据共享),本平台在保障患者隐私的前提下打破数据孤岛,为医疗AI研究提供合规基础设施。下一步将集成零知识证明(ZKP)优化权限验证效率。
附录:核心工具栈
- 存储:IPFS Cluster, Filecoin
- 联邦学习:PySyft, OpenFL
- 区块链:Ethereum/Solidity, Hardhat
- 前端:bootstrap+ jQuery.js(调用合约)
- 部分代码如下:
import torch
import numpy as np
from typing import List, Dict, Any, Optional, Tuple
from abc import ABC, abstractmethod
import logging
from collections import OrderedDict
logger = logging.getLogger(__name__)
class BaseAggregator(ABC):
"""
联邦学习聚合器基类
"""
def __init__(self, config: Dict[str, Any] = None):
self.config = config or {}
self.name = self.__class__.__name__
@abstractmethod
def aggregate(self, client_models: List[Dict[str, Any]],
client_weights: Optional[List[float]] = None) -> Dict[str, Any]:
"""
聚合客户端模型
Args:
client_models: 客户端模型列表
client_weights: 客户端权重列表
Returns:
聚合后的全局模型
"""
pass
def validate_models(self, client_models: List[Dict[str, Any]]) -> bool:
"""
验证客户端模型的有效性
"""
if not client_models:
logger.error("No client models provided for aggregation")
return False
# 检查模型结构一致性
first_model = client_models[0]
if 'parameters' not in first_model:
logger.error("Model parameters not found")
return False
first_params = first_model['parameters']
for i, model in enumerate(client_models[1:], 1):
if 'parameters' not in model:
logger.error(f"Model {i} missing parameters")
return False
if set(model['parameters'].keys()) != set(first_params.keys()):
logger.error(f"Model {i} has different parameter structure")
return False
return True
def _convert_to_tensors(self, parameters: Dict[str, Any]) -> Dict[str, torch.Tensor]:
"""
将参数转换为PyTorch张量
"""
tensors = {}
for name, param in parameters.items():
if isinstance(param, list):
tensors[name] = torch.tensor(param, dtype=torch.float32)
elif isinstance(param, torch.Tensor):
tensors[name] = param
else:
tensors[name] = torch.tensor(param, dtype=torch.float32)
return tensors
def _convert_to_lists(self, tensors: Dict[str, torch.Tensor]) -> Dict[str, Any]:
"""
将PyTorch张量转换为列表
"""
parameters = {}
for name, tensor in tensors.items():
parameters[name] = tensor.tolist()
return parameters
class FedAvgAggregator(BaseAggregator):
"""
联邦平均聚合器 (FedAvg)
"""
def aggregate(self, client_models: List[Dict[str, Any]],
client_weights: Optional[List[float]] = None) -> Dict[str, Any]:
"""
使用联邦平均算法聚合模型
"""
if not self.validate_models(client_models):
raise ValueError("Invalid client models")
num_clients = len(client_models)
# 如果没有提供权重,使用数据样本数作为权重
if client_weights is None:
client_weights = []
for model in client_models:
data_samples = model.get('data_samples', 1)
client_weights.append(data_samples)
# 归一化权重
total_weight = sum(client_weights)
normalized_weights = [w / total_weight for w in client_weights]
logger.info(f"Aggregating {num_clients} models with FedAvg")
logger.info(f"Client weights: {normalized_weights}")
# 转换第一个模型参数为张量
global_params = self._convert_to_tensors(client_models[0]['parameters'])
# 初始化全局参数为零
for name in global_params:
global_params[name] = torch.zeros_like(global_params[name])
# 加权平均
for i, model in enumerate(client_models):
model_params = self._convert_to_tensors(model['parameters'])
weight = normalized_weights[i]
for name in global_params:
global_params[name] += weight * model_params[name]
# 构建聚合结果
aggregated_model = {
'parameters': self._convert_to_lists(global_params),
'aggregation_method': 'FedAvg',
'participating_clients': num_clients,
'client_weights': normalized_weights,
'metadata': {
'total_data_samples': sum(model.get('data_samples', 0) for model in client_models),
'average_training_loss': np.mean([model.get('training_loss', 0) for model in client_models]),
'average_training_accuracy': np.mean([model.get('training_accuracy', 0) for model in client_models])
}
}
logger.info(f"FedAvg aggregation completed. Total samples: {aggregated_model['metadata']['total_data_samples']}")
return aggregated_model
class FedProxAggregator(BaseAggregator):
"""
FedProx聚合器
"""
def __init__(self, config: Dict[str, Any] = None):
super().__init__(config)
self.mu = self.config.get('mu', 0.01) # 正则化参数
def aggregate(self, client_models: List[Dict[str, Any]],
client_weights: Optional[List[float]] = None) -> Dict[str, Any]:
"""
使用FedProx算法聚合模型
"""
if not self.validate_models(client_models):
raise ValueError("Invalid client models")
# 首先使用FedAvg进行基础聚合
fedavg_aggregator = FedAvgAggregator()
base_result = fedavg_aggregator.aggregate(client_models, client_weights)
# 添加FedProx特定的元数据
base_result['aggregation_method'] = 'FedProx'
base_result['metadata']['mu'] = self.mu
logger.info(f"FedProx aggregation completed with mu={self.mu}")
return base_result
class FedAdamAggregator(BaseAggregator):
"""
FedAdam聚合器
"""
def __init__(self, config: Dict[str, Any] = None):
super().__init__(config)
self.beta1 = self.config.get('beta1', 0.9)
self.beta2 = self.config.get('beta2', 0.999)
self.epsilon = self.config.get('epsilon', 1e-8)
self.learning_rate = self.config.get('learning_rate', 0.001)
# 动量缓存
self.m_cache = None
self.v_cache = None
self.t = 0 # 时间步
def aggregate(self, client_models: List[Dict[str, Any]],
client_weights: Optional[List[float]] = None) -> Dict[str, Any]:
"""
使用FedAdam算法聚合模型
"""
if not self.validate_models(client_models):
raise ValueError("Invalid client models")
self.t += 1
# 首先计算梯度(客户端更新的平均值)
fedavg_aggregator = FedAvgAggregator()
avg_result = fedavg_aggregator.aggregate(client_models, client_weights)
avg_params = self._convert_to_tensors(avg_result['parameters'])
# 如果是第一次聚合,初始化动量缓存
if self.m_cache is None:
self.m_cache = {name: torch.zeros_like(param) for name, param in avg_params.items()}
self.v_cache = {name: torch.zeros_like(param) for name, param in avg_params.items()}
# 计算伪梯度(假设全局模型为零初始化)
pseudo_gradients = {name: param for name, param in avg_params.items()}
# Adam更新
updated_params = {}
for name in avg_params:
grad = pseudo_gradients[name]
# 更新一阶动量
self.m_cache[name] = self.beta1 * self.m_cache[name] + (1 - self.beta1) * grad
# 更新二阶动量
self.v_cache[name] = self.beta2 * self.v_cache[name] + (1 - self.beta2) * (grad ** 2)
# 偏差修正
m_hat = self.m_cache[name] / (1 - self.beta1 ** self.t)
v_hat = self.v_cache[name] / (1 - self.beta2 ** self.t)
# 参数更新
updated_params[name] = self.learning_rate * m_hat / (torch.sqrt(v_hat) + self.epsilon)
# 构建聚合结果
aggregated_model = {
'parameters': self._convert_to_lists(updated_params),
'aggregation_method': 'FedAdam',
'participating_clients': len(client_models),
'client_weights': client_weights,
'metadata': {
'beta1': self.beta1,
'beta2': self.beta2,
'epsilon': self.epsilon,
'learning_rate': self.learning_rate,
'time_step': self.t,
'total_data_samples': sum(model.get('data_samples', 0) for model in client_models)
}
}
logger.info(f"FedAdam aggregation completed at time step {self.t}")
return aggregated_model
class WeightedAggregator(BaseAggregator):
"""
基于性能的加权聚合器
"""
def __init__(self, config: Dict[str, Any] = None):
super().__init__(config)
self.weight_strategy = self.config.get('weight_strategy', 'accuracy') # 'accuracy', 'loss', 'data_size'
self.min_weight = self.config.get('min_weight', 0.01) # 最小权重
def aggregate(self, client_models: List[Dict[str, Any]],
client_weights: Optional[List[float]] = None) -> Dict[str, Any]:
"""
使用基于性能的加权聚合
"""
if not self.validate_models(client_models):
raise ValueError("Invalid client models")
# 计算权重
if client_weights is None:
client_weights = self._calculate_performance_weights(client_models)
# 使用FedAvg进行聚合
fedavg_aggregator = FedAvgAggregator()
result = fedavg_aggregator.aggregate(client_models, client_weights)
result['aggregation_method'] = 'WeightedAggregation'
result['metadata']['weight_strategy'] = self.weight_strategy
logger.info(f"Weighted aggregation completed using {self.weight_strategy} strategy")
return result
def _calculate_performance_weights(self, client_models: List[Dict[str, Any]]) -> List[float]:
"""
根据性能计算权重
"""
weights = []
if self.weight_strategy == 'accuracy':
accuracies = [model.get('training_accuracy', 0) for model in client_models]
# 使用softmax归一化
exp_acc = [np.exp(acc) for acc in accuracies]
sum_exp = sum(exp_acc)
weights = [exp_acc[i] / sum_exp for i in range(len(exp_acc))]
elif self.weight_strategy == 'loss':
losses = [model.get('training_loss', float('inf')) for model in client_models]
# 损失越小权重越大
inv_losses = [1.0 / (loss + 1e-8) for loss in losses]
sum_inv = sum(inv_losses)
weights = [inv_loss / sum_inv for inv_loss in inv_losses]
elif self.weight_strategy == 'data_size':
data_sizes = [model.get('data_samples', 1) for model in client_models]
total_size = sum(data_sizes)
weights = [size / total_size for size in data_sizes]
else:
# 默认均等权重
weights = [1.0 / len(client_models)] * len(client_models)
# 确保最小权重
weights = [max(w, self.min_weight) for w in weights]
# 重新归一化
total_weight = sum(weights)
weights = [w / total_weight for w in weights]
return weights
class TrimmedMeanAggregator(BaseAggregator):
"""
修剪均值聚合器(用于拜占庭容错)
"""
def __init__(self, config: Dict[str, Any] = None):
super().__init__(config)
self.trim_ratio = self.config.get('trim_ratio', 0.1) # 修剪比例
def aggregate(self, client_models: List[Dict[str, Any]],
client_weights: Optional[List[float]] = None) -> Dict[str, Any]:
"""
使用修剪均值聚合
"""
if not self.validate_models(client_models):
raise ValueError("Invalid client models")
num_clients = len(client_models)
trim_count = int(num_clients * self.trim_ratio)
logger.info(f"Trimmed mean aggregation: trimming {trim_count} clients from each end")
# 转换所有模型参数为张量
all_params = []
for model in client_models:
params = self._convert_to_tensors(model['parameters'])
all_params.append(params)
# 对每个参数进行修剪均值计算
param_names = list(all_params[0].keys())
global_params = {}
for param_name in param_names:
# 收集所有客户端的该参数
param_values = [params[param_name] for params in all_params]
# 计算修剪均值
trimmed_mean = self._compute_trimmed_mean(param_values, trim_count)
global_params[param_name] = trimmed_mean
# 构建聚合结果
aggregated_model = {
'parameters': self._convert_to_lists(global_params),
'aggregation_method': 'TrimmedMean',
'participating_clients': num_clients,
'metadata': {
'trim_ratio': self.trim_ratio,
'trimmed_clients': trim_count * 2,
'effective_clients': num_clients - trim_count * 2
}
}
logger.info(f"Trimmed mean aggregation completed. Effective clients: {aggregated_model['metadata']['effective_clients']}")
return aggregated_model
def _compute_trimmed_mean(self, param_values: List[torch.Tensor], trim_count: int) -> torch.Tensor:
"""
计算参数的修剪均值
"""
# 将张量堆叠
stacked = torch.stack(param_values, dim=0)
# 对每个位置进行排序和修剪
sorted_values, _ = torch.sort(stacked, dim=0)
# 修剪最大和最小值
if trim_count > 0:
trimmed = sorted_values[trim_count:-trim_count]
else:
trimmed = sorted_values
# 计算均值
return torch.mean(trimmed, dim=0)
class AggregatorFactory:
"""
聚合器工厂类
"""
_aggregators = {
'fedavg': FedAvgAggregator,
'fedprox': FedProxAggregator,
'fedadam': FedAdamAggregator,
'weighted': WeightedAggregator,
'trimmed_mean': TrimmedMeanAggregator
}
@classmethod
def create_aggregator(cls, aggregator_type: str, config: Dict[str, Any] = None) -> BaseAggregator:
"""
创建聚合器实例
Args:
aggregator_type: 聚合器类型
config: 配置参数
Returns:
聚合器实例
"""
aggregator_type = aggregator_type.lower()
if aggregator_type not in cls._aggregators:
raise ValueError(f"Unknown aggregator type: {aggregator_type}. "
f"Available types: {list(cls._aggregators.keys())}")
aggregator_class = cls._aggregators[aggregator_type]
return aggregator_class(config)
@classmethod
def get_available_aggregators(cls) -> List[str]:
"""
获取可用的聚合器类型
"""
return list(cls._aggregators.keys())
@classmethod
def register_aggregator(cls, name: str, aggregator_class: type):
"""
注册新的聚合器
Args:
name: 聚合器名称
aggregator_class: 聚合器类
"""
if not issubclass(aggregator_class, BaseAggregator):
raise ValueError("Aggregator class must inherit from BaseAggregator")
cls._aggregators[name.lower()] = aggregator_class
logger.info(f"Registered new aggregator: {name}")
def aggregate_models(client_models: List[Dict[str, Any]],
aggregator_type: str = 'fedavg',
aggregator_config: Dict[str, Any] = None,
client_weights: Optional[List[float]] = None) -> Dict[str, Any]:
"""
便捷函数:聚合客户端模型
Args:
client_models: 客户端模型列表
aggregator_type: 聚合器类型
aggregator_config: 聚合器配置
client_weights: 客户端权重
Returns:
聚合后的全局模型
"""
aggregator = AggregatorFactory.create_aggregator(aggregator_type, aggregator_config)
return aggregator.aggregate(client_models, client_weights)
def evaluate_aggregation_quality(global_model: Dict[str, Any],
client_models: List[Dict[str, Any]]) -> Dict[str, float]:
"""
评估聚合质量
Args:
global_model: 全局模型
client_models: 客户端模型列表
Returns:
质量指标字典
"""
metrics = {}
# 计算参数差异
global_params = global_model['parameters']
param_diffs = []
for model in client_models:
client_params = model['parameters']
diff = 0
count = 0
for name in global_params:
if name in client_params:
global_tensor = torch.tensor(global_params[name], dtype=torch.float32)
client_tensor = torch.tensor(client_params[name], dtype=torch.float32)
diff += torch.norm(global_tensor - client_tensor).item()
count += 1
if count > 0:
param_diffs.append(diff / count)
if param_diffs:
metrics['average_parameter_difference'] = np.mean(param_diffs)
metrics['std_parameter_difference'] = np.std(param_diffs)
metrics['max_parameter_difference'] = np.max(param_diffs)
metrics['min_parameter_difference'] = np.min(param_diffs)
# 计算性能指标
if all('training_accuracy' in model for model in client_models):
accuracies = [model['training_accuracy'] for model in client_models]
metrics['client_accuracy_mean'] = np.mean(accuracies)
metrics['client_accuracy_std'] = np.std(accuracies)
if all('training_loss' in model for model in client_models):
losses = [model['training_loss'] for model in client_models]
metrics['client_loss_mean'] = np.mean(losses)
metrics['client_loss_std'] = np.std(losses)
return metrics

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 33
33 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)