常用大模型架构整理
本文介绍了Transformer及其衍生模型GPT和BERT的架构原理。Transformer采用纯注意力机制,通过编码器-解码器结构实现并行计算,其中位置编码解决序列顺序问题,自注意力机制捕捉全局依赖关系。GPT基于Transformer解码器,通过无监督预训练和微调实现文本生成任务;BERT则利用Transformer编码器,通过掩码语言模型和下一句预测任务进行预训练,擅长理解任务。三种模型在
一、Transformer模型架构
Transformer是一个纯粹基于注意力的架构(自注意力同时具有并行计算和最大路径长度这俩个优势),没有用到任何的RNN和CNN网络,虽然Transformer模型中也有编码器、解码器,但是在架构和原理实现上,与Seq2Seq还是有较大差距。
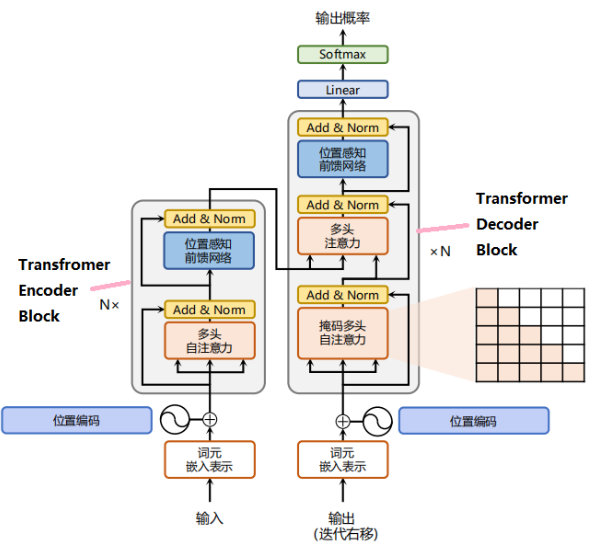
编码器端:经过词嵌入层(Input Embedding)和位置编码层(Positional Encoding),得到最终输入,流经自注意力层(Multi-Head Attention(多头注意力))、残差和归一化层(Add&Norm)、前馈神经网络(Feed Forward)、残差和归一化层(Add&Norm),得到编码器端的输出(后续和解码器端交互)。
解码器端:经过词嵌入层(Input Embedding)和位置编码层(Positional Encoding),得到最终输入,流经掩码自注意力层(Masked Multi-Head Attention(掩码多头注意力),把未来的词全部mask掉)、残差和归一化层(Add&Norm)、交互注意力层(把编码端的输出和解码端的信息进行交互,Q矩阵来自解码端,K\V矩阵均来自编码端的输出)、残差和归一化层(Add&Norm)、前馈神经网络(Feed Forward)、残差和归一化层(Add&Norm),得到解码器端的输出。
1.位置编码
Transformer将token序列一次性输入模型,不使用循环的形式,解决了遗忘问题,上下文捕捉问题,时间复杂度问题。但是带来了新的问题,因为是并行输入,模型没办法知道每个token在句子中的相对和绝对的位置信息,而位置关系对于NLP任务来说非常重要。为了解决这个问题,Transformer把token的顺序信号加到词向量上帮助模型学习这些信息,这就是位置编码。
a.基于正弦和余弦函数的编码
使用sin/cos函数作为位置编码函数的原因:
1)每个时间步都有唯一的编码
2)在不同长度的句子中,俩个时间步之间的距离应该一致。
3)模型不受句子长短的影响,并且编码范围是有界的。
4)同一时间序列中,每个连续的编码应该是等步长的,即线性相关的。
5)位置编码应该能表示token的绝对或相对位置关系。
公式:
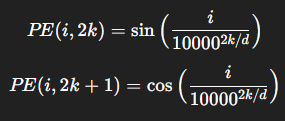
解释:
若d=4,词嵌入维度为4
-
第 0 维:sin(i)
-
第 1 维:cos(i)
-
第 2 维:sin(i/100)
-
第 3 维:cos(i/100)
2.自注意力机制
对于一句话里的某个词,我们不只是看他自己,而失去关注序列中其他所有词,并分配不同的权重,决定哪些词对于当前词更重要。
公式:
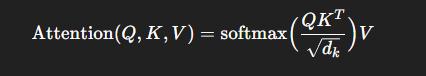
解释:
Q:来自解码器的输入(我需要哪些信息?)
K:来自编码器的输出(我是某个信息点的表示,可以被索引到?)
V:来自编码器的输出(我的实际内容,别人如果觉得我重要就把我带走。)
缩放因子dk:避免点积过大导致softmax过陡。
3.Mask
在Encoder里,自注意力可以让每个词看到句子里的所有词,没问题(方便理解词义)。
但是在Decoder里:情况不同:
生成第t个词时,模型不能提前看到未来的词(即t+1,t+2...)否则就作弊了,所以我们要生成一个掩码盖住未来的词,防止模型作弊。
如何实现:
构建一个上三角为最小值的权重矩阵M,加入到注意力机制的运算中,使得被M盖住的词权重为极小值(极大减少对模型预测的影响)。
4.前馈神经网络(Feed Forward)
前馈神经网络是一个逐位置、两层全连接+非线性的小型MLP,用来增强模型的表达能力。
如何实现:
1)线性投影(增加维度)
2)ReLU激活(提取高维特征)
3)线性投影(降低维度)
二、GPT模型架构
GPT模型是一种基于Transformer架构的生成式预训练模型,采用无监督的学习方式进行预训练,然后通过微调适应特定的任务。GPT模型的结构由多层decoder组成,每个decoder由多头自注意力机制和前馈神经网络组成,基于这些结构GPT模型能够学习到更加丰富的语义表示。
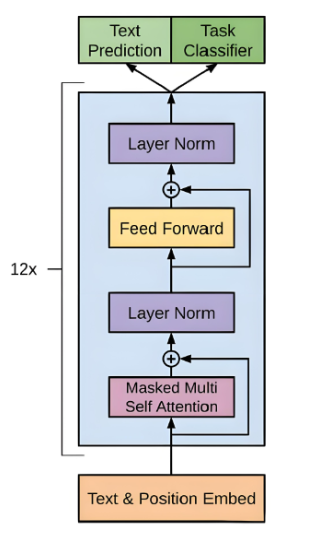
1.模型结构
1)输入:一句话的词向量+位置编码
2)Decoder堆叠:包含Masked Self-Aaatention + 前馈神经网络 + 残差/归一化
3)输出:softmax得到词的概率分布,采样或贪心得到下一个词
2.主要应用
1)自然语言生成
2)知识问答&推理
3)代码生成
三、Bert模型架构
Bert模型是一种基于Transformer架构的预训练模型,Bert只使用了经典Transformer架构中的Encoder部分,侧重于理解句子中上下文含义,适合词语级别的任务。
Bert通过掩码语言模型和下一句预测任务进行训练。
1.主要预训练任务
1)掩码语言模型:在输入序列中,Bert随机掩盖一些词语,然后要求模型预测这些被掩盖的词语,通过这个任务,Bert可以学习到在给定上下文的情况下,预测缺失词语的能力。
2)下一句预测:在一些自然语言处理任务中,理解句子之间的关系非常重要。为了让模型学习句子级别的关系,Bert使用了NSP任务,该任务要求模型判断俩个句子是否是连续的,即一个句子是否是另一个句子的下一句。通过这个任务,Bert能够学习到句子级别的语义关系和推理能力。
2.主要应用
1)文本分类
2)句子对任务
3)问答任务

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 14
14 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)