卷积神经网络学习(第十周周报)
本文系统阐述卷积神经网络的核心原理与应用。第一部分介绍CNN将图像转化为三维张量,通过卷积层提取局部特征,利用感受野机制使神经元聚焦关键区域而非整图;第二部分详解参数共享通过复用相同滤波器权重扫描全图,解决特征位置无关性问题,大幅降低参数量;第三部分解析池化层压缩特征图尺寸,增强空间不变性并减少计算量。CNN通过感受野、参数共享与池化的协同设计,实现高效图像识别。This article syst
摘要
本文系统阐述卷积神经网络的核心原理与应用。第一部分介绍CNN将图像转化为三维张量,通过卷积层提取局部特征,利用感受野机制使神经元聚焦关键区域而非整图;第二部分详解参数共享通过复用相同滤波器权重扫描全图,解决特征位置无关性问题,大幅降低参数量;第三部分解析池化层压缩特征图尺寸,增强空间不变性并减少计算量。CNN通过感受野、参数共享与池化的协同设计,实现高效图像识别。
Abstract
This article systematically explains the core principles and applications of Convolutional Neural Networks. Part one describes how CNNs convert images into 3D tensors and extract local features via convolutional layers, where the receptive field mechanism enables neurons to focus on key regions instead of the entire image. Part two details parameter sharing, which reuses identical filter weights to scan the whole image, solving the position-invariance of features and drastically reducing parameters. Part three analyzes pooling layers that compress feature map dimensions to enhance spatial invariance and decrease computational costs. By integrating receptive fields, parameter sharing, and pooling, CNNs achieve efficient image recognition.
1 卷积神经网络(CNN)
label维度可以决定分类种类的个数等,标准化图像输入模型生成预测,再通过交叉熵量化预测与真实值的偏差,这一监督学习过程为后续的梯度下降优化提供了明确的更新方向。
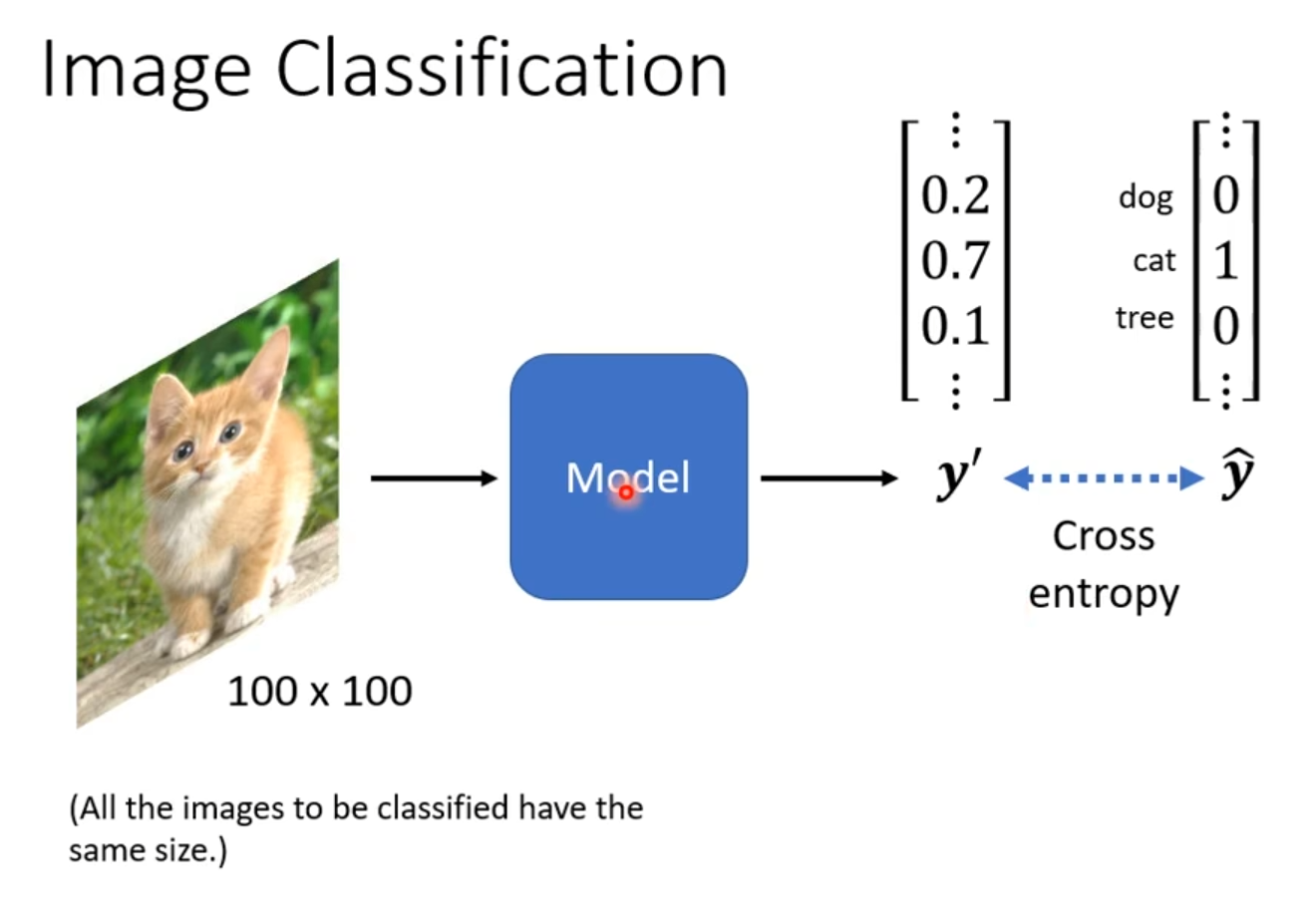
图1.1 猫咪识别过程图
机器可识别不出来图片的整体,我们要把图片做成三维的tensor,整个构图如同一条精炼的流水线:活生生的视觉对象→标准化像素矩阵→三通道张量分解→特征向量重组。如下图所示。
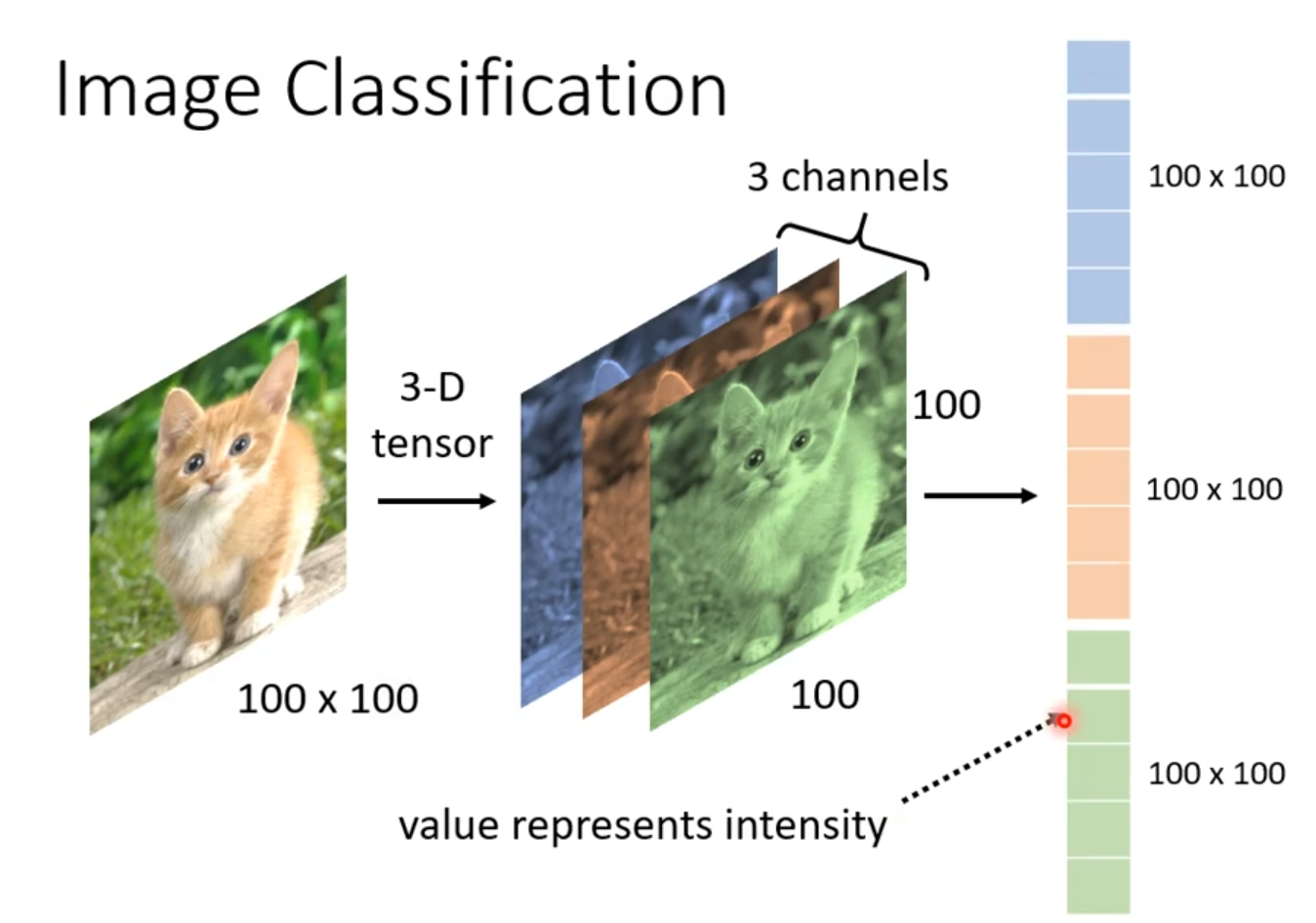
图1.2图片拆分图
2 简化方法
2.1 Receptive Field
神经元无需观察整张图像,只需聚焦局部关键特征即可实现高效识别,如下图所示。
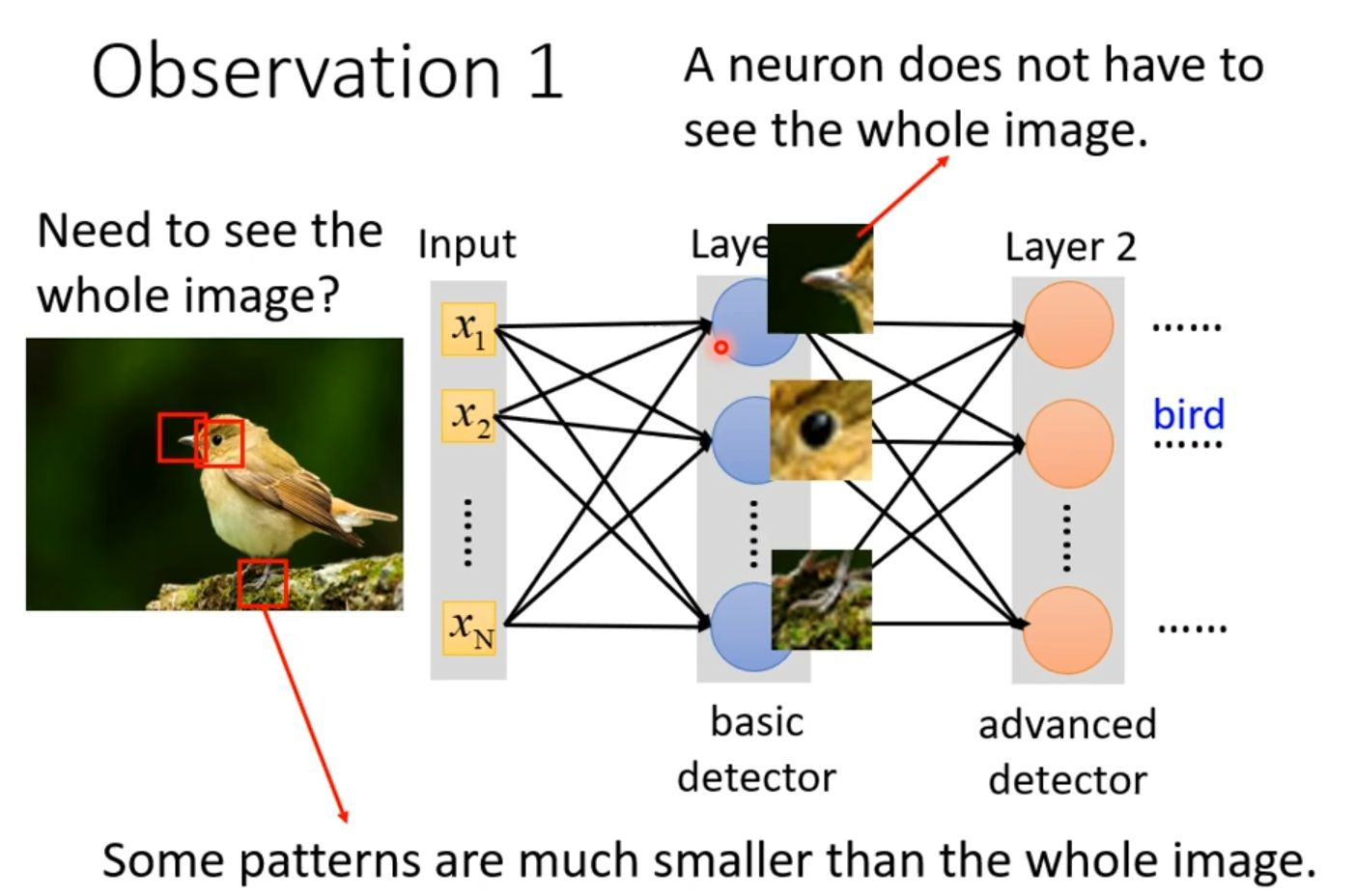
图2.1 receptive field示例图
由上图所示,整个架构揭示了深层网络的本质优势:低层捕捉局部细节,高层组合全局语义。感受野机制避免了全连接网络需要海量参数的缺陷(图中稀疏连接线象征参数共享),允许模型以有限计算资源高效解构复杂视觉信息。
神经元如何通过灵活的空间感知模式提升特征提取效率?图中以三维权重矩阵(3×3×3)为对象,用红色立方体框定一个局部区域,直观展现其核心特性。如下图所示。
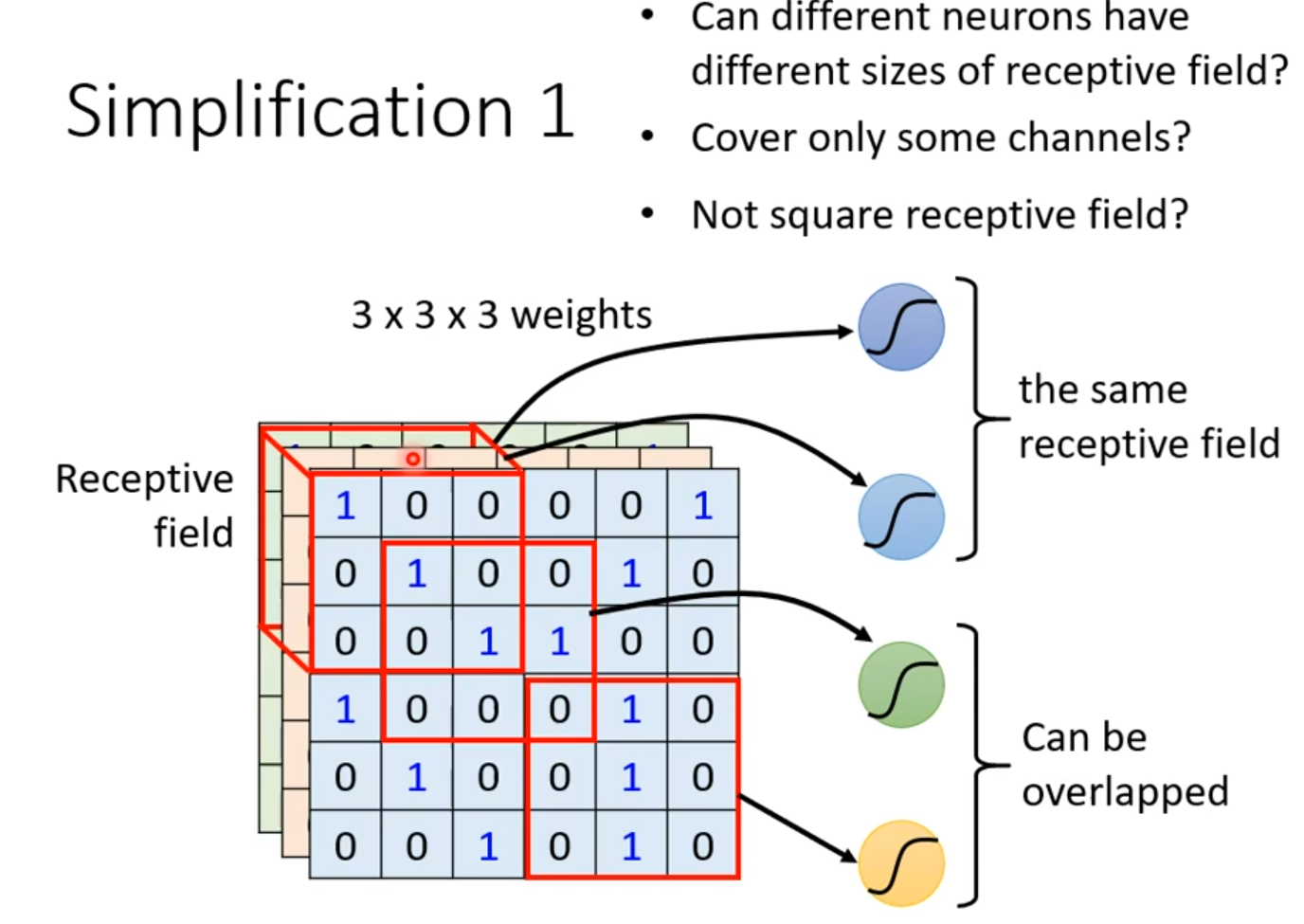
图2.2 3个3x3矩阵图
卷积神经网络中Receptive Field的标准实现范式。图中以三维张量(如100×100×3的像素网格)代表输入图像,红色矩形框标注的3×3区域即为单个Receptive Field的覆盖范围——它并非聚焦整个图像,而是仅提取其中一个小型局部区域的特征信息。
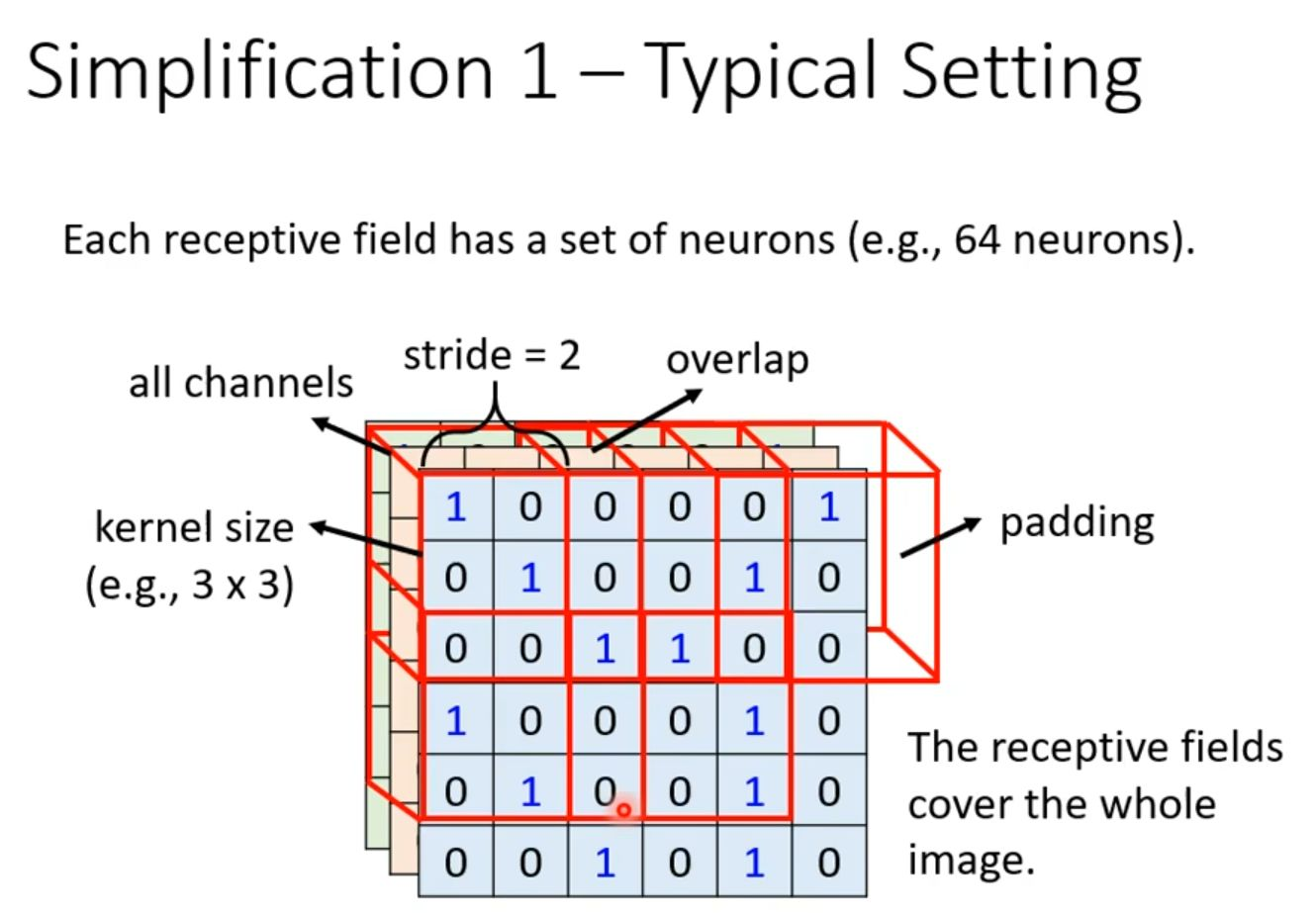
图2.3各个参数参考图
如上图所示,通过3×3小窗口的滑动扫描代替全图处理,大幅降低参数量;步长2的移动平衡了计算效率与特征连续性;每个局部区域由多神经元协同解析,实现从像素到语义的层次化抽象。红色方框的动态延展轨迹如同编织一张密集而自适应的特征捕捉网。
2.2 Parameter Sharing
同一个图案可能在图片的各个地方,可以通过参数共享来减少参数量。由下图可以得到。
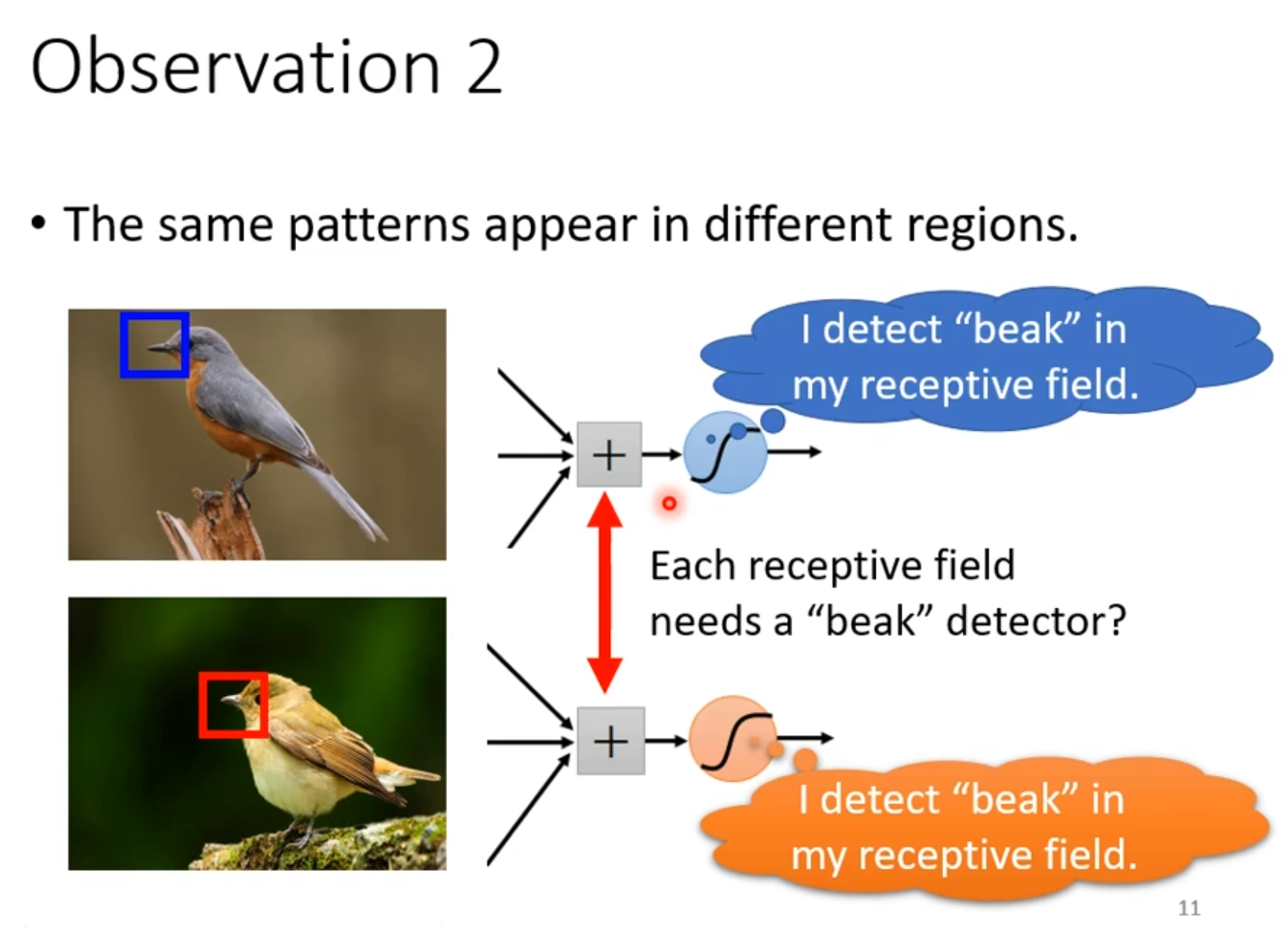
图2.4 特征与图片位置无关图
特征具有位置无关性。这自然引出卷积网络的破局思路——共享检测器权重,使同一个特征提取单元通过滑动窗口机制扫描整张图像。
通过对比实验揭示了神经网络设计中参数共享机制的核心价值,其核心逻辑在于:当多个神经元负责检测相同感受野内的特征时,强制它们独立学习参数将导致灾难性的模型膨胀。由下图可知。
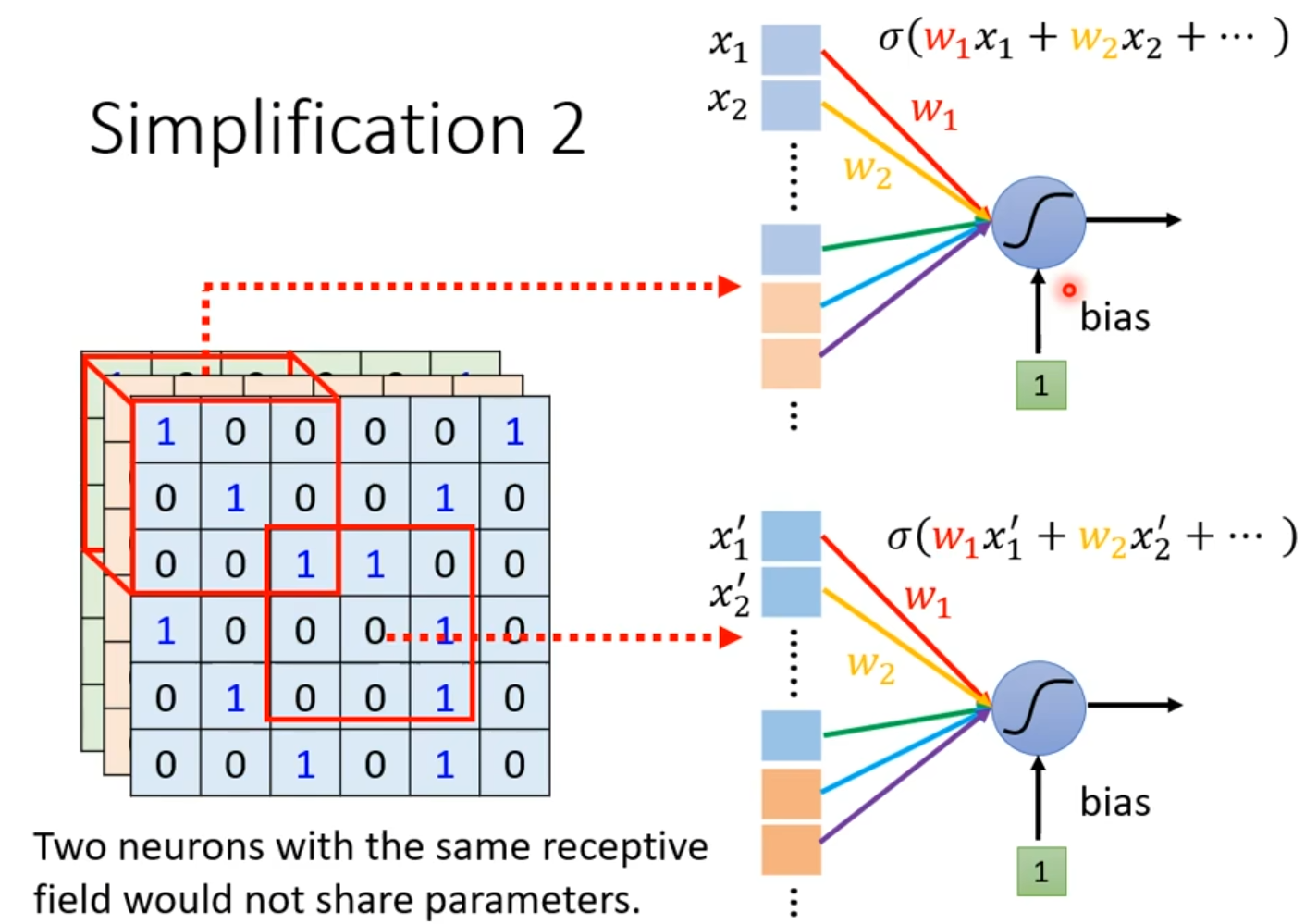
图2.5 输入不同neuron计算也不同
由上图,图中左侧的立方体特征图被红色实线框定一个2×2的局部区域,该区域同时为右侧两个神经元单元提供输入数据——但关键矛盾在于:这两个神经元单元被设计为完全独立运作,右侧对称结构的神经元单元生动暴露了独立参数的冗余性。
这说明了对同一感受野内的相同视觉模式,模型被迫训练两套功能重复的特征检测器。
下面共享方式中,每个field只有一组filter。如下图所示。
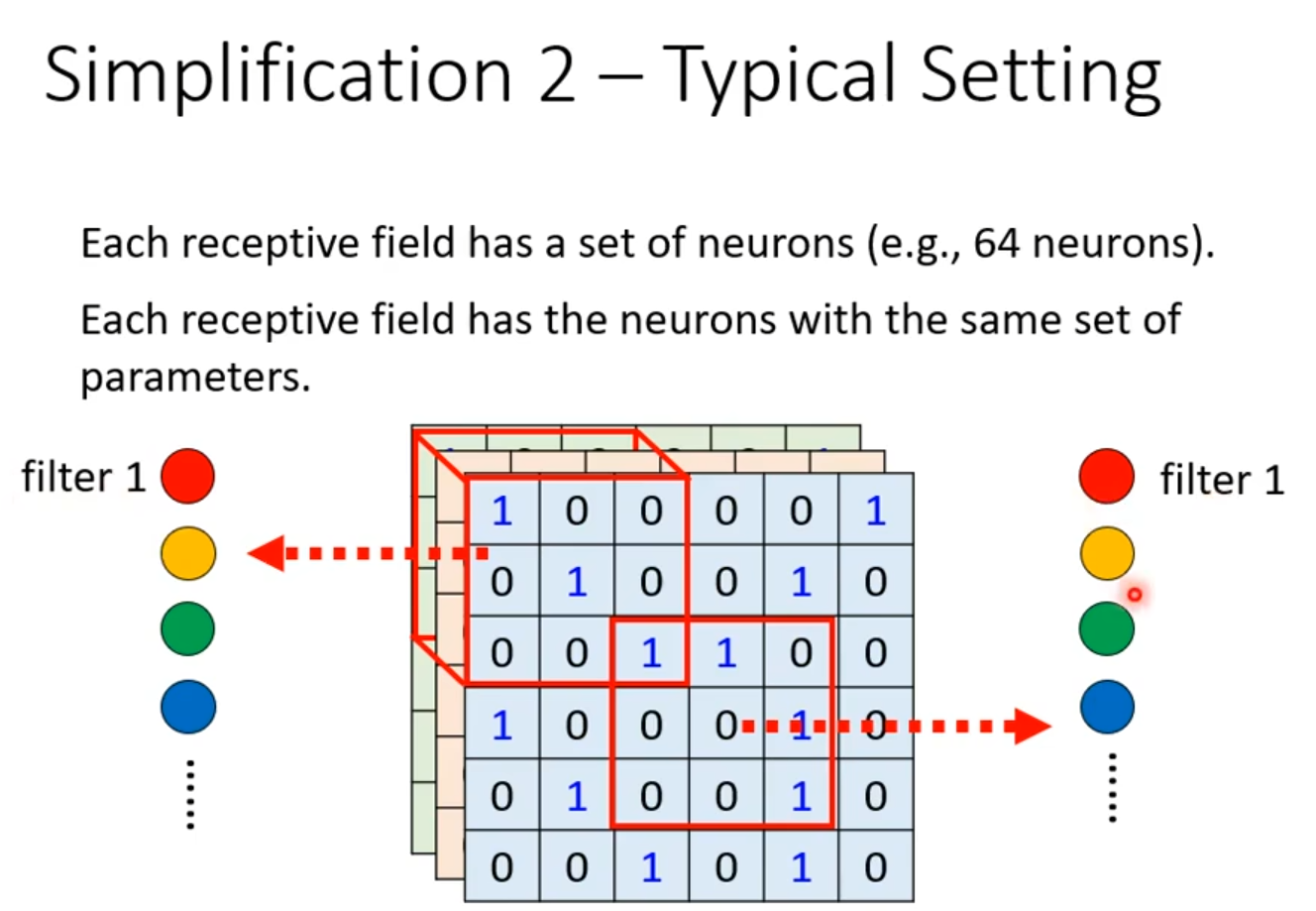
图2.6常见的共享方式图
field通过减少图像观测部分来减少参数个数,降低了model弹性;parameter sharing通过不同的neuron之间共享进一步减少参数的个数,这两个部分共同组成了卷积层。如下图所示。
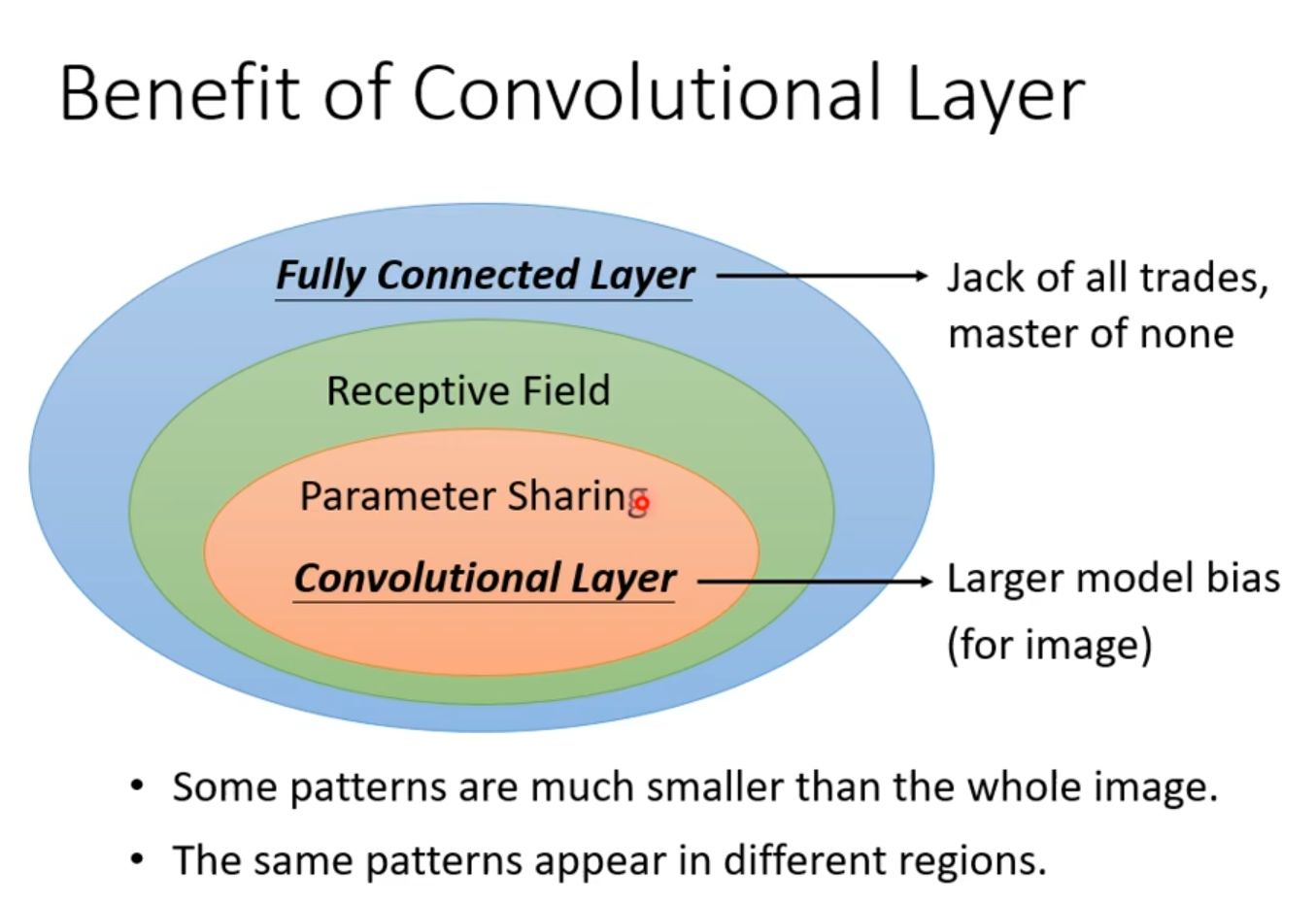
图2.7 Parameter sharing的包含关系图
还有另一种共享方式,利用可学习的Filter在输入图像上滑动扫描,逐层提取空间特征。如下图所示。
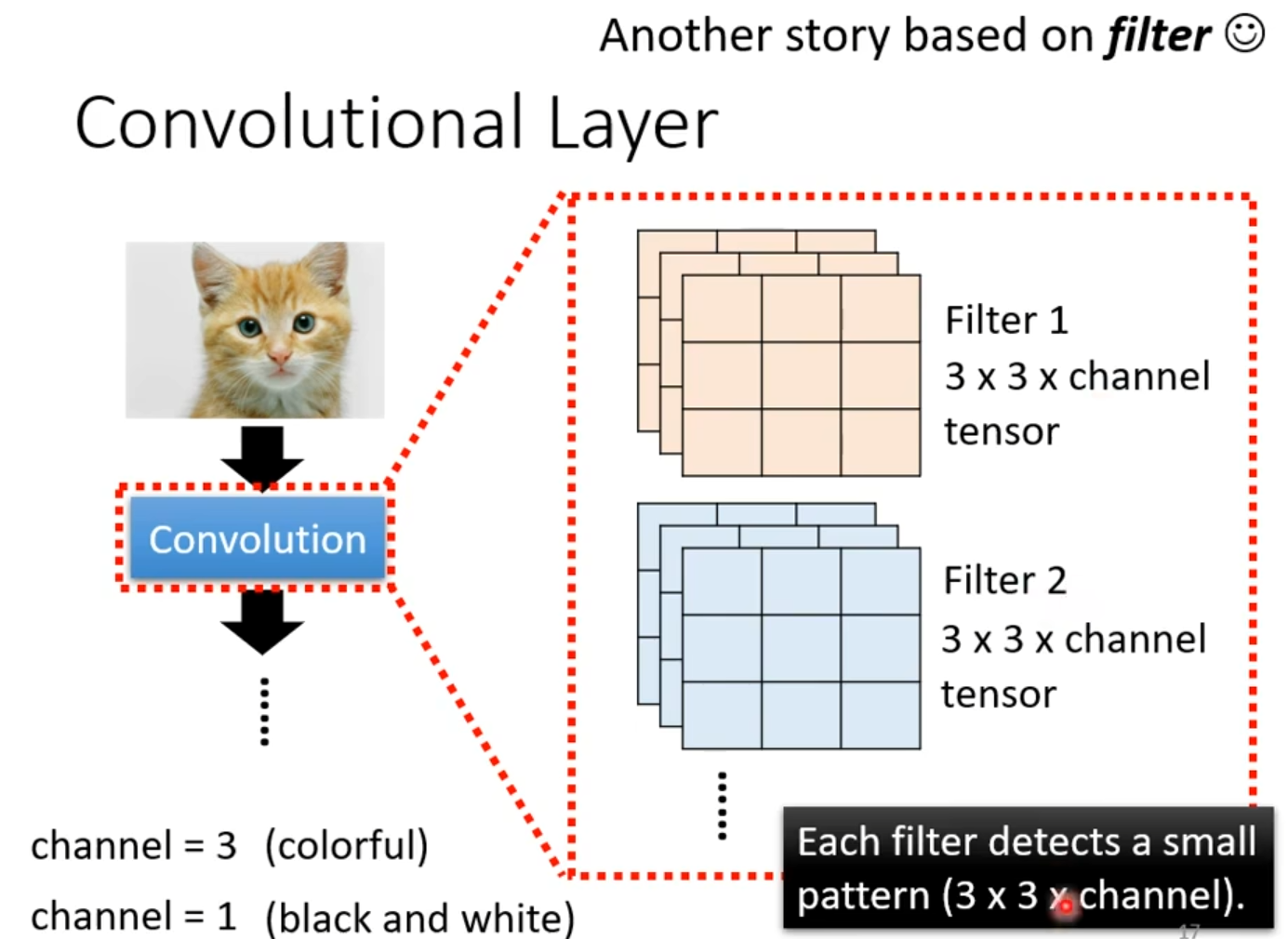
图2.8 Convolution相关方式
如上图所示,左侧的橘色小猫图片是三维输入张量(高度×宽度×通道数),其中彩色图像通道数为3(红绿蓝),黑白图像则为单通道(图中标注"channel=3"与"channel=1")。关键转换过程通过向下箭头指向蓝色"Convolution"方块示意,此处发生卷积运算。
通过和原图的内积得到特征图,这个图可以看成新的图片,有多少个filter就有多少个channel。
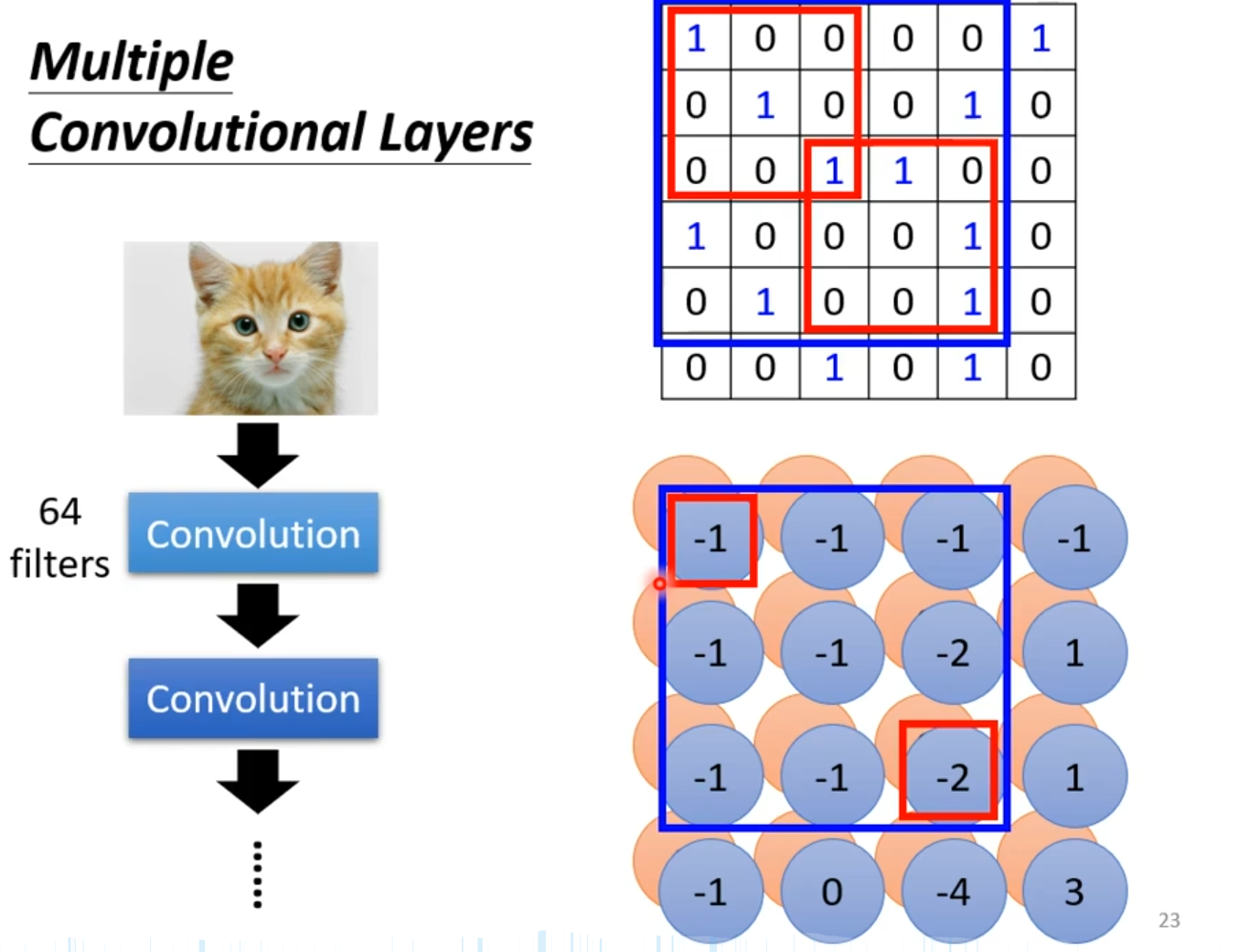
2.3 Pooling
Pooling即把偶数行去掉,把奇数列去掉,然后就能使得图片变成原来的1/4。下图即是通过卷积层逐层捕获视觉模式,再经池化层实现信息浓缩。
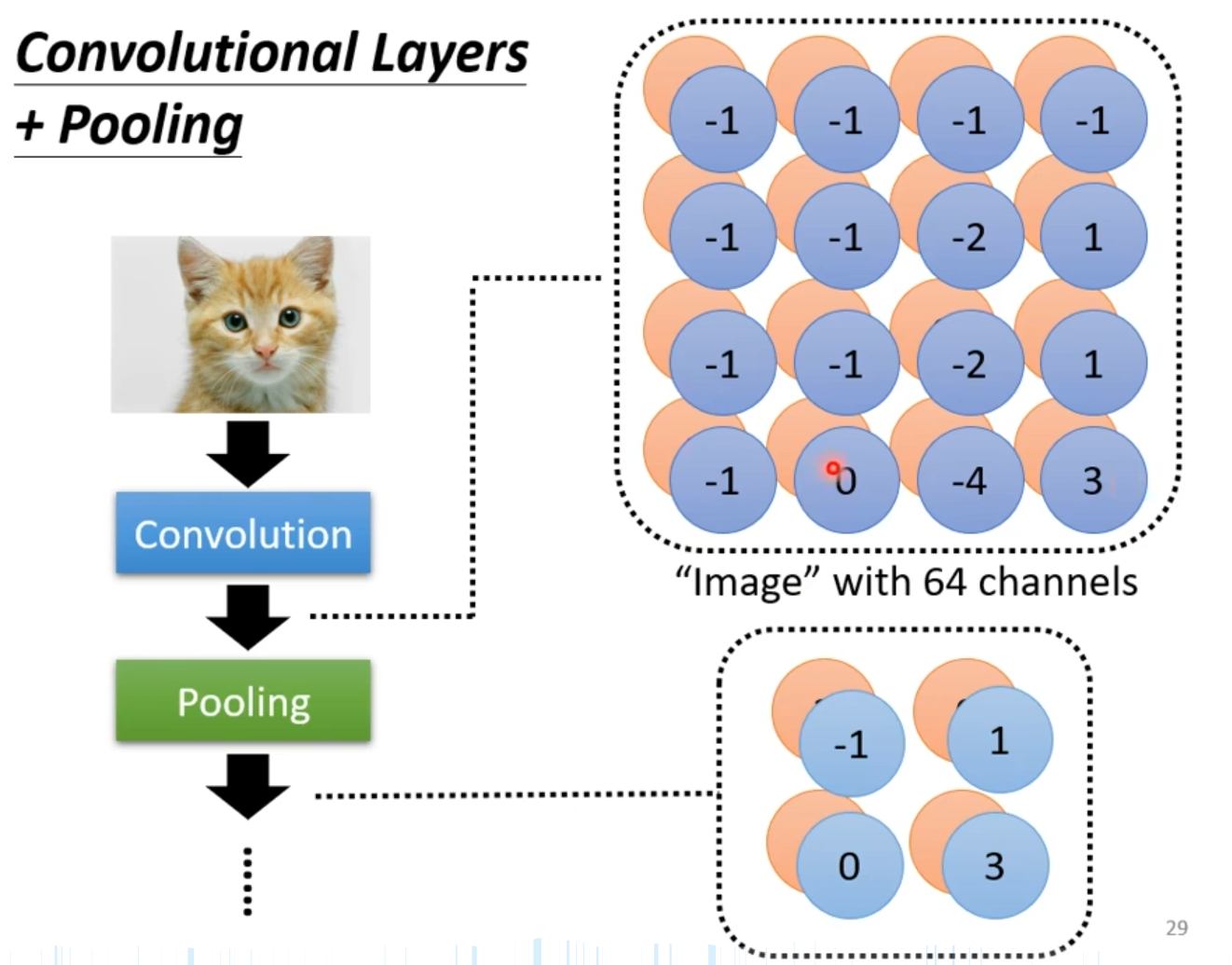
图3.1卷积+池化层图
Convolution:输入图像通过蓝色"Convolution"模块后,被转化为一个含64个通道的特征图组。每个通道由大量彩色圆形构成,圆形内的数字表示不同位置的激活强度。这象征64个独立滤波器对原始图像的扫描结果——每个滤波器如一把微型探针,在图像上滑动时提取特定纹理或边缘模式,最终生成64张响应特征图,每张图记录该模式在全图的分布强度。
Pooling:64通道的特征图进一步输入绿色"Pooling"模块。右下角虚线框内的缩小版圆形阵列揭示了池化效果:保留核心信息的同时大幅压缩尺寸。例如,原本密集排布的区域被提炼为稀疏的关键点,尺寸显著小于顶部原图。这一过程如同将高清照片缩略为像素块——通过最大池化保留局部最强响应,或通过平均池化概括区域趋势,目的都是降低空间分辨率,增强特征的空间不变性,并减少后续计算量。
3 总结
CNN的核心设计通过三步实现高效图像识别:首先将输入图像拆解为三维张量,利用感受野机制让神经元仅关注局部关键区域;其次通过参数共享让同一组滤波器权重滑动扫描整张图像,既捕捉特征的平移不变性,又大幅压缩参数量;最后经池化层对特征图进行降维。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 28
28 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)