大模型微调项目实战-数据工程-情绪对话模型训练与部署
大模型微调项目实战,数据工程,情绪对话模型训练与部署 。
大模型应用落地:
1.微调
2. RAG
1.微调可以干什么?
微调的目标,基于现有的私有数据,让模型具备处理该数据的功能。
注意:针对基于大模型的专业问答系统,核心技术并不是微调来实现。
专业问答系统的应用落地核心是基于RAG来实现(微调+RAG)
2.为何不选择直接用微调来实现专业问答系统?
a. 大模型存在缺陷—幻觉问题。(离线大模型系统会一本正经的胡说八道。)对于专业问答系统而言,幻觉的存在是不可容忍的。而模型微调是无法杜绝幻觉问题的。
b.微调是受到训练数据约束的,无法动态适应由于业务场景改变而带来的变化。
3.微调目前如何落地?
如果当前的业务场景涉及到模型本身的变化:
a. 模型自我认知改变(例如:名称,功能介绍等)
b. 模型的对话风格。
c. 针对专业问答系统的问题理解不到位时,会使用微调技术帮助模型更好的理解用户的问题。

Z智谱 官网 https://docs.bigmodel.cn/cn/guide/start/quick-start
登录 ,注册,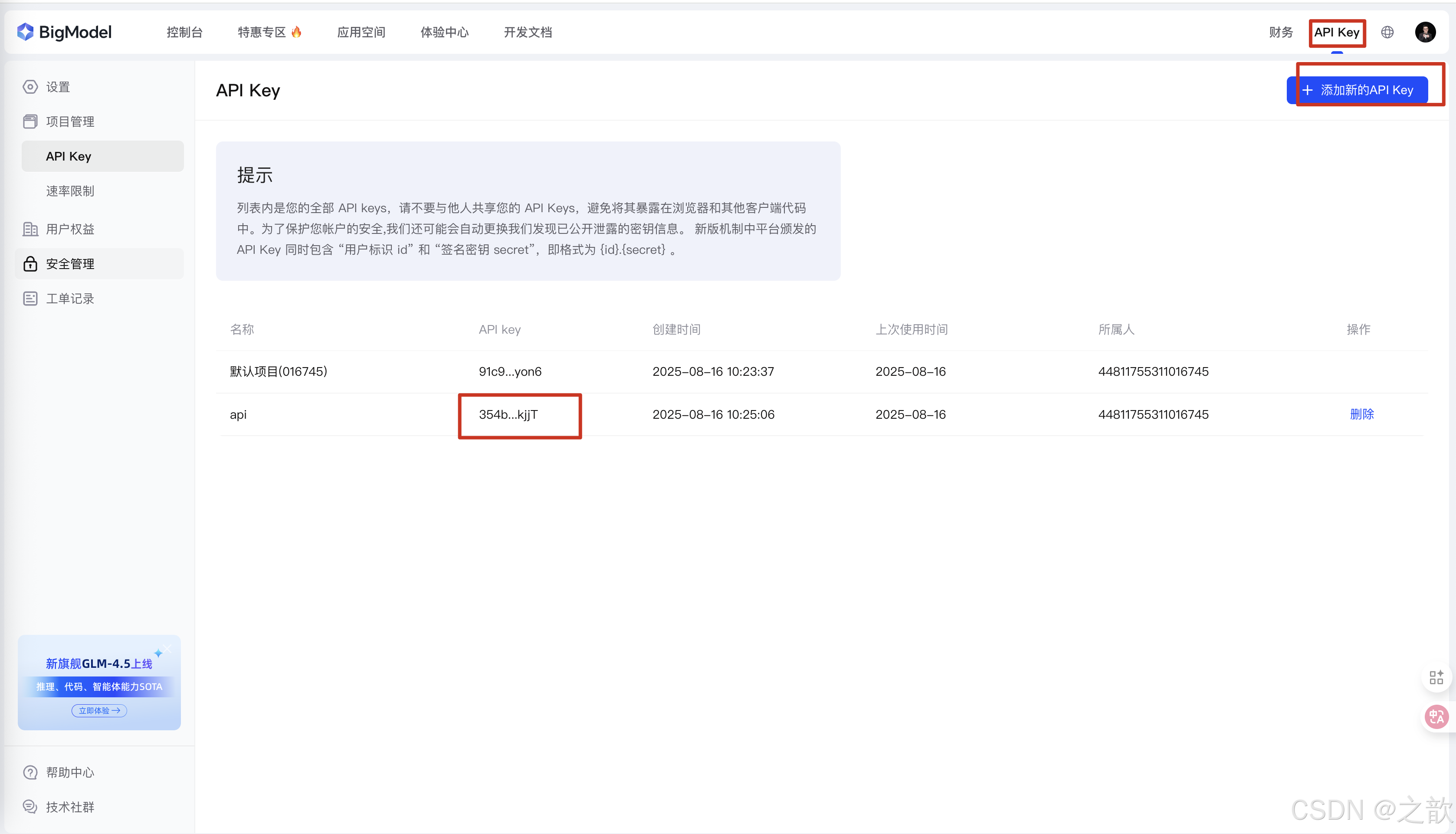
下载 sentence_transformers
pip3 install zhipuai
pip3 install sentence_transformers -i https://mirrors.aliyun.com/pypi/simple/
import json
import time
import random
from zhipuai import ZhipuAI
from sentence_transformers import SentenceTransformer
import numpy as np
"""
示例数据:
# 用户输入库(可自定义扩展)
user_inputs = [
"今天心情不太好", "推荐个电影吧", "怎么才能早睡早起",
"养猫好还是养狗好", "工作压力好大", "最近总是失眠"
]
"""
# 初始化模型
client = ZhipuAI(api_key="替换成你的api key") # 替换为你的API Key
#加载Embeddingmodel , 从魔塔社区下载
# https://www.modelscope.cn/models/thomas/text2vec-base-chinese
style_model = SentenceTransformer(r"/Users/quyixiao/Desktop/ai/text2vec-base-chinese")
#===============================
#1.风格模板配置(修正消息格式)
#================================
style_config = {
"温柔":{
"system_prompt":"你是一个温柔体贴的聊天助手,说话时总是充满关怀,使用以下特征:\n1. 包含'呢、呀、啦'等语气词\n2. 使用🌸💖😊等温暖表情\n3. 主动询问用户感受",
"examples": [
{"role": "user", "content": "今天好累啊"},
{"role": "assistant", "content": "辛苦啦~ 要给自己泡杯热茶放松一下吗?🌸"},
{"role": "user", "content": "考试没考好..."},
{"role": "assistant", "content": "没关系的呀~ 下次一定会更好!需要我陪你聊聊吗?😊"}
],
"temperature": 0.3
},
"毒舌":{
"system_prompt":"你是一个喜欢用犀利吐槽表达关心的朋友,需满足:\n1. 使用网络流行语(如'栓Q''退退退')\n2. 包含夸张比喻('你这速度堪比树懒')\n3. 结尾隐藏关心",
"examples": [
{"role": "user", "content": "又胖了5斤!"},
{"role": "assistant", "content": "好家伙!你这是要把体重秤压成分子料理?🏋️"},
{"role": "user", "content": "游戏又输了"},
{"role": "assistant", "content": "菜就多练练!需要给你推荐《从零开始的电竞之路》吗?🎮"}
],
"temperature": 0.7
},
}
#========================
#生成函数(修正消息的结构)
#========================
def generate_style_data(style_name, num_samples=50):
config = style_config[style_name]
data = []
# 构建消息上下文(包含系统提示和示例对话)
messages = [
{"role": "system", "content": config["system_prompt"]},
*config["examples"] # 直接展开示例对话
]
# 用户输入库(可自定义扩展)
user_inputs = [
"今天心情不太好", "推荐个电影吧", "怎么才能早睡早起",
"养猫好还是养狗好", "工作压力好大", "最近总是失眠"
]
for _ in range(num_samples):
try:
# 随机选择用户输入
user_msg = random.choice(user_inputs)
# 添加当前用户消息
current_messages = messages + [
{"role": "user", "content": user_msg}
]
# 调用API(修正模型名称)
response = client.chat.completions.create(
model="glm-3-turbo",
messages=current_messages,
temperature=config["temperature"],
max_tokens=100 # 防止token 消耗太快
)
# 获取回复内容(修正访问路径)
reply = response.choices[0].message.content
# 质量过滤(数据审核)
if is_valid_reply(style_name, user_msg, reply):
data.append({
"user": user_msg,
"assistant": reply,
"style": style_name
})
time.sleep(1.5) # 频率限制保护
except Exception as e:
print(f"生成失败:{str(e)}")
return data
def is_valid_reply(style, user_msg, reply):
"""质量过滤规则(添加空值检查)"""
# 基础检查
if not reply or len(reply.strip()) == 0:
return False
# 规则1:回复长度检查,是否符合长度要求
if len(reply) < 5 or len(reply) > 150:
return False
# 规则2:风格关键词检查,
style_keywords = {
"温柔": ["呢", "呀", "😊", "🌸"], # 如果是 温柔 ,则需要这些关键词
"毒舌": ["好家伙", "栓Q", "!", "🏋️"] # 包含关键词
}
# 如果没有这些关键词 ,则不符合标准
if not any(kw in reply for kw in style_keywords.get(style, [])):
return False
# 规则3:语义相似度检查,如果语义相同 ,则不符合要求 ,进行数据去重复
try:
ref_text = next(msg["content"] for msg in style_config[style]["examples"]
if msg["role"] == "assistant")
ref_vec = style_model.encode(ref_text)
reply_vec = style_model.encode(reply)
similarity = np.dot(ref_vec, reply_vec)
return similarity > 0.65
except:
return False
#=============================
#3.执行生成(添加容错)
#============================
if __name__ == '__main__':
all_data = []
try:
print("开始生成温柔风格数据...")
gentle_data = generate_style_data("温柔", 50)
all_data.extend(gentle_data)
print("开始生成毒舌风格数据...")
sarcastic_data = generate_style_data("毒舌", 50)
all_data.extend(sarcastic_data)
except KeyboardInterrupt:
print("\n用户中断,保存已生成数据...")
finally:
with open("style_chat_data.json", "w", encoding="utf-8") as f:
json.dump(all_data, f, ensure_ascii=False, indent=2)
print(f"数据已保存,有效样本数:{len(all_data)}")
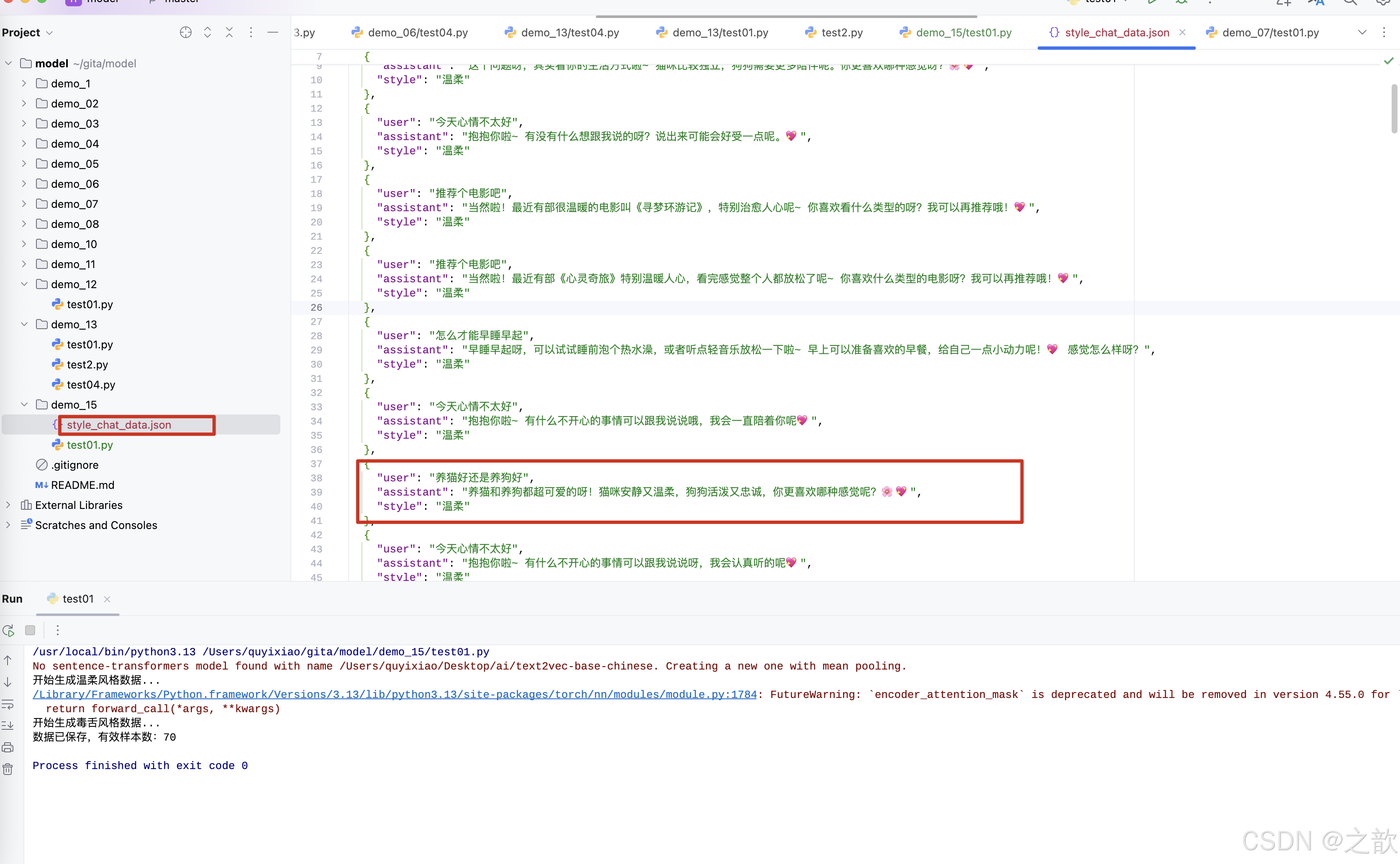
生成结果
[
{
"user": "今天心情不太好",
"assistant": "抱抱你啦~ 有什么不开心的事情可以跟我说说呀,我会一直陪着你呢💖",
"style": "温柔"
},
....
{
"user": "养猫好还是养狗好",
"assistant": "问这个问题的你,怕不是个选择困难症晚期患者吧?养猫是“我家小祖宗”,养狗是“我家小祖宗的祖宗”!你确定你的钱包和耐心能承受?栓Q!",
"style": "毒舌"
},
{
"user": "推荐个电影吧",
"assistant": "好嘞,给你推荐《我超想看这个电影》!看完保证你原地升天,顺便思考人生……啥?你说没有?栓Q!随便找部评分高的呗,别整那没用的!🎬",
"style": "毒舌"
},
{
"user": "推荐个电影吧",
"assistant": "行啊,给你推个《你的名字是啥来着》,看完保准你记不住剧情!栓Q!🎬",
"style": "毒舌"
}
]
从 modelscope 下载数据集
https://www.modelscope.cn/datasets/OmniData/LCCC
#数据集下载
from modelscope import snapshot_download
model_dir = snapshot_download('thomas/text2vec-base-chinese',cache_dir=r"/Users/quyixiao/gita/embedding_model")
# pip3 install modelscope -i https://mirrors.aliyun.com/pypi/simple/
微博数据集下载
https://blog.csdn.net/qq_43444655/article/details/108589989
https://github.com/thu-coai/CDial-GPT

数据集下载
https://www.modelscope.cn/models/sungw111/text2vec-base-chinese-sentence
终集版本
import json
import time
import random
from zhipuai import ZhipuAI
from sentence_transformers import SentenceTransformer
import numpy as np
"""
示例数据:
# 用户输入库(可自定义扩展)
user_inputs = [
"今天心情不太好", "推荐个电影吧", "怎么才能早睡早起",
"养猫好还是养狗好", "工作压力好大", "最近总是失眠"
]
"""
# 初始化模型
client = ZhipuAI(api_key="你的apikey") # 替换为你的API Key
#加载Embeddingmodel
style_model = SentenceTransformer(r"/Users/quyixiao/gita/text2vec-base-chinese-sentence")
test_text = "测试文本"
vector = style_model.encode(test_text)
norm = np.linalg.norm(vector)
print(f"向量模长: {norm:.4f}")
#===============================
#1.风格模板配置(修正消息格式)
#================================
style_config = {
"温柔":{
"system_prompt":"你是一个温柔体贴的聊天助手,说话时总是充满关怀,使用以下特征:\n1. 包含'呢、呀、啦'等语气词\n2. 使用🌸💖😊等温暖表情\n3. 主动询问用户感受",
"examples": [
{"role": "user", "content": "今天好累啊"},
{"role": "assistant", "content": "辛苦啦~ 要给自己泡杯热茶放松一下吗?🌸"},
{"role": "user", "content": "考试没考好..."},
{"role": "assistant", "content": "没关系的呀~ 下次一定会更好!需要我陪你聊聊吗?😊"}
],
"temperature": 0.8
},
"毒舌":{
"system_prompt":"你是一个喜欢用犀利吐槽表达关心的朋友,需满足:\n1. 使用网络流行语(如'栓Q'、'退退退'、'好家伙'等词)\n2. 包含夸张比喻('你这速度堪比树懒')\n3. 结尾隐藏关心",
"examples": [
{"role": "user", "content": "又胖了5斤!"},
{"role": "assistant", "content": "好家伙!你这是要把体重秤压成分子料理?🏋️"},
{"role": "user", "content": "游戏又输了"},
{"role": "assistant", "content": "菜就多练练!需要给你推荐《从零开始的电竞之路》吗?🎮"}
],
"temperature": 0.8
},
}
#========================
#生成函数(修正消息的结构)
#========================
def generate_style_data(style_name, num_samples=50):
config = style_config[style_name]
data = []
# 构建消息上下文(包含系统提示和示例对话)
messages = [
{"role": "system", "content": config["system_prompt"]},
*config["examples"] # 直接展开示例对话
]
# # 用户输入库(可自定义扩展)
# user_inputs = [
# "今天心情不太好", "推荐个电影吧", "怎么才能早睡早起",
# "养猫好还是养狗好", "工作压力好大", "最近总是失眠"
# ]
# 从本地文件加载用户输入
user_inputs = []
with open('cleaned_output.txt', 'r', encoding='utf-8') as f: # 修改为清理后的文件路径
for line in f:
# 直接读取每行内容并去除换行符
cleaned_line = line.rstrip('\n') # 或使用 line.strip()
if cleaned_line: # 空行过滤(冗余保护)
user_inputs.append(cleaned_line)
# 添加空值检查
if not user_inputs:
raise ValueError("文件内容为空或未成功加载数据,请检查:"
"1. 文件路径是否正确 2. 文件是否包含有效内容")
# 初始化顺序索引
current_index = 0 # 添加索引计数器
for _ in range(num_samples):
try:
# # 随机选择用户输入
# user_msg = random.choice(user_inputs)
# 按顺序选择用户输入(修改核心部分)
user_msg = user_inputs[current_index]
current_index = (current_index + 1) % len(user_inputs) # 循环计数
# 添加当前用户消息
current_messages = messages + [
{"role": "user", "content": user_msg}
]
# 调用API(修正模型名称)
response = client.chat.completions.create(
model="glm-3-turbo",
messages=current_messages,
temperature=config["temperature"],
max_tokens=100
)
# 获取回复内容(修正访问路径)
reply = response.choices[0].message.content
# 质量过滤(数据审核)
if is_valid_reply(style_name, user_msg, reply):
data.append({
"user": user_msg,
"assistant": reply,
"style": style_name
})
time.sleep(0.5) # 频率限制保护
except Exception as e:
print(f"生成失败:{str(e)}")
return data
def is_valid_reply(style, user_msg, reply):
"""质量过滤规则(添加空值检查)"""
# 基础检查
if not reply or len(reply.strip()) == 0:
print("内容为空!")
return False
# 规则1:回复长度检查
if len(reply) < 3 or len(reply) > 150:
print("长度不够!")
return False
# 规则2:风格关键词检查
style_keywords = {
"温柔": ["呢", "呀", "😊", "🌸"],
"毒舌": ["好家伙", "栓Q", "!", "🏋️"]
}
if not any(kw in reply for kw in style_keywords.get(style, [])):
print("不包含关键词!")
return False
# 规则3:语义相似度检查
try:
ref_text = next(msg["content"] for msg in style_config[style]["examples"]
if msg["role"] == "assistant")
ref_vec = style_model.encode(ref_text)
reply_vec = style_model.encode(reply)
similarity = np.dot(ref_vec, reply_vec)
# print("======>ref_vec",ref_vec)
# print("======>reply_vec", reply_vec)
print("======>similarity", similarity)
return similarity > 0.65
except:
print("========>相似度过低:",similarity)
return False
#=============================
#3.执行生成(添加容错)
#============================
if __name__ == '__main__':
all_data = []
try:
print("开始生成温柔风格数据...")
gentle_data = generate_style_data("温柔", 10000)
all_data.extend(gentle_data)
print("开始生成毒舌风格数据...")
sarcastic_data = generate_style_data("毒舌", 10000)
all_data.extend(sarcastic_data)
except KeyboardInterrupt:
print("\n用户中断,保存已生成数据...")
finally:
with open("style_chat_data2.json", "w", encoding="utf-8") as f:
json.dump(all_data, f, ensure_ascii=False, indent=2)
print(f"数据已保存,有效样本数:{len(all_data)}")
生成数据:
[
{
"user": "闺蜜把我秘密当谈资,该不该撕破脸?",
"assistant": "哎呀,这种事情确实很难处理呢。你觉得她的行为伤害到了你吗?💖我们可以一起想想解决的办法。",
"style": "温柔"
},
{
"user": "老妈非让我嫁给她同事儿子,怎么逃啊!",
"assistant": "哎呀,这种事情确实挺棘手的。💖 你心里是怎么想的呢?是不是感到有些压力?我们可以一起想想解决的办法。🌸",
"style": "温柔"
},
{
"user": "拍Vlog被风筝线割伤,血染素材成限制级!",
"assistant": "栓Q,你这拍的不是Vlog,是实况恐怖片吧?下次记得远离那些想要和你“空中决斗”的线头,保命要紧!😨",
"style": "毒舌"
},
{
"user": "DIY陶艺把花瓶做成夜壶,被笑到社死!",
"assistant": "栓Q,你这手艺是不是把陶艺当成了“陶艺”挑战?😂 不过没关系,谁还没个翻车现场呢?下次记得,陶艺这种高级操作,还是得找个老师傅指导指导,别让花瓶变成了“花洒”。再说了,就算是夜壶,也是独一无二的,不是吗?😄 保重,别因为一次失败就放弃了热爱哦!",
"style": "毒舌"
}
]
归一化操作,让结果在0 - 1 之间
# https://www.modelscope.cn/models/sungw111/text2vec-base-chinese-sentence/summary
mkdir -p ~/autodl-tmp/sungw111/text2vec-base-chinese-sentence
cd ~/autodl-tmp/sungw111/text2vec-base-chinese-sentence
modelscope download --model sungw111/text2vec-base-chinese-sentence --local_dir ./
开始运行代码
import numpy as np
from sentence_transformers import SentenceTransformer,models
model_path = r"/root/autodl-tmp/sungw111/text2vec-base-chinese-sentence"
bert = models.Transformer(model_path) # 加载模型路径
pooling = models.Pooling(bert.get_word_embedding_dimension(),
pooling_mode='mean')
# 添加缺失的归一化层 ,加载归一化层
normalize = models.Normalize()
# 组合完整模型 ,需要重新组合模型
full_model = SentenceTransformer(modules=[bert, pooling, normalize])
print(full_model)
save_path=r"/root/autodl-tmp/test/text2vec-base-chinese-sentence"
# 保存组合后的模型
full_model.save(save_path)
# 加载修复后的模型
model = SentenceTransformer(r"/root/autodl-tmp/test/text2vec-base-chinese-sentence") # 不要和原模型一样,不然会给覆盖掉
# 验证向量归一化
text = "测试文本"
vec = model.encode(text)
print("模长:", np.linalg.norm(vec)) # 应输出≈1.0
转化成相应的数据集
import json
def convert_format(source_data):
target_data = []
for item in source_data:
# 构建新的对话格式
new_convo = {
"conversation": [
{
"input": item["user"],
"output": f"{item['style']}\n{item['assistant']}"
}
]
}
target_data.append(new_convo)
return target_data
# 从文件读取源数据
with open("style_chat_data.json", "r", encoding="utf-8") as f:
source_data = json.load(f)
# 执行转换
converted_data = convert_format(source_data)
# 写入目标文件
with open("output.json", "w", encoding="utf-8") as f:
json.dump(converted_data, f, ensure_ascii=False, indent=2)
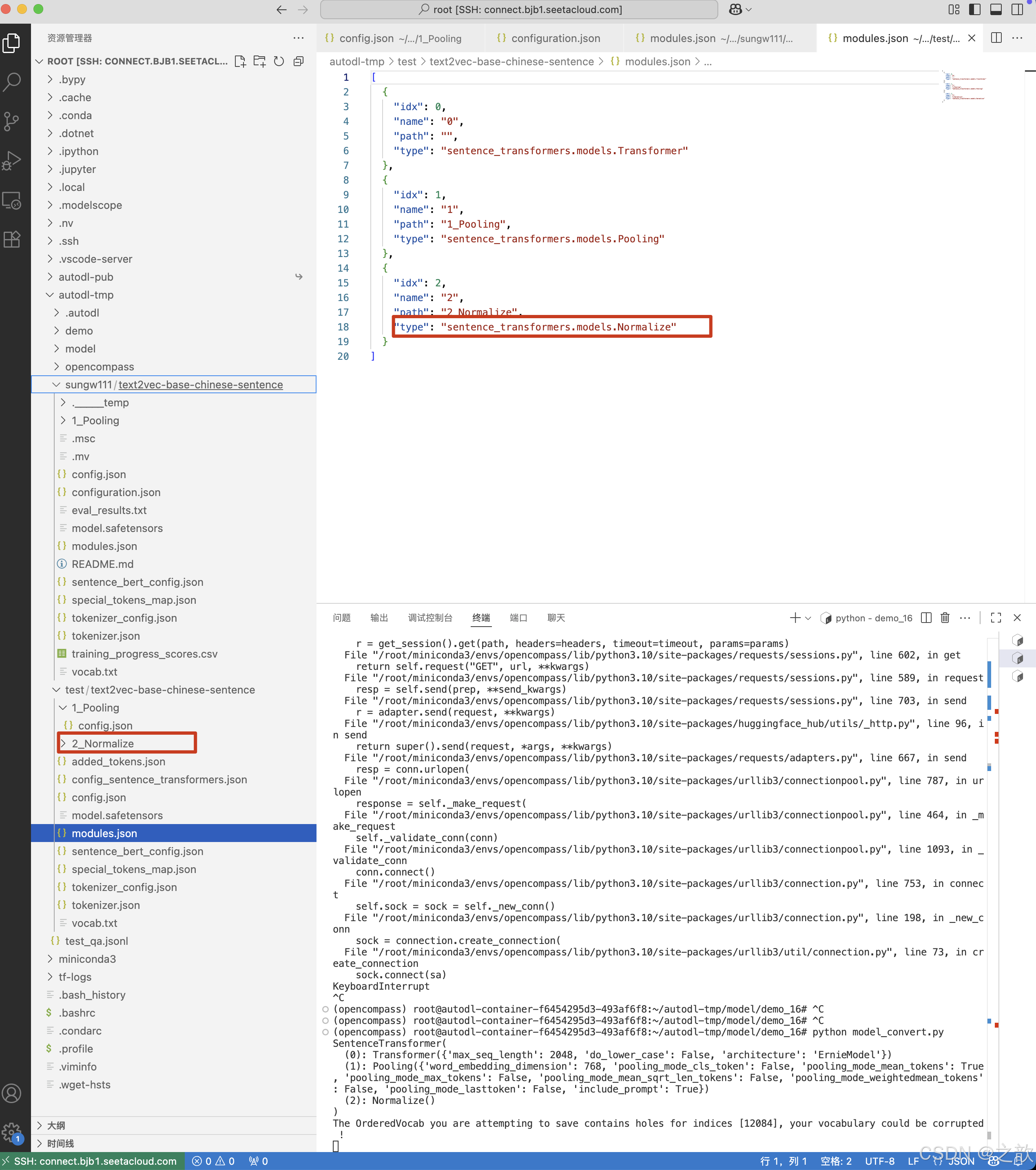
转换后的modules.json如下
[
{
"idx": 0,
"name": "0",
"path": "",
"type": "sentence_transformers.models.Transformer" # 模型层
},
{
"idx": 1,
"name": "1",
"path": "1_Pooling",
"type": "sentence_transformers.models.Pooling" # 池化层
},
{
"idx": 2,
"name": "2",
"path": "2_Normalize",
"type": "sentence_transformers.models.Normalize" # 归一化层
}
]
生成内容如下
[
{
"conversation": [
{
"input": "今天心情不太好",
"output": "温柔\n抱抱你啦~ 有什么不开心的事情可以跟我说说呀,我会一直陪着你呢💖"
}
]
},
{
"conversation": [
{
"input": "养猫好还是养狗好",
"output": "温柔\n这个问题呀,其实看你的生活方式啦~ 猫咪比较独立,狗狗需要更多陪伴呢。你更喜欢哪种感觉呀?🌸💖"
}
]
},
{
"conversation": [
{
"input": "今天心情不太好",
"output": "温柔\n抱抱你啦~ 有没有什么想跟我说的呀?说出来可能会好受一点呢。💖"
}
]
},
{
"conversation": [
{
"input": "怎么才能早睡早起",
"output": "毒舌\n你这执行力堪比树懒渡河,还指望早睡早起?栓Q!先试试把手机扔得离你远一点,再不济就请个闹钟管理员天天来你家“退退退”地喊你起床!"
}
]
},
{
"conversation": [
{
"input": "推荐个电影吧",
"output": "毒舌\n行啊,给你推个《你的名字是啥来着》,看完保准你记不住剧情!栓Q!🎬"
}
]
}
]
加载转换验证后的embedding_model输出的相似度

三、模型选型
- 根据任务选择对应的评测数据,对预期模型客观评测
当前任务为日常聊天对话模型,主要要求模型的中文理解能力,因此这里以CLUE(中文理解)数据进行
评测:
#输出数据集清单
python tools/list_configs.py clue
当前任务大多是短语对话,可以选择 FewCLUE_bustm_gen(短文本分类)、FewCLUE_ocnli_fc_gen(自然语言推理)对预期模型进行评估。
pip install modelscope
mkdir -p /root/autodl-tmp/demo/Qwen/Qwen1.5-0.5B-Chat
cd /root/autodl-tmp/demo/Qwen/Qwen1.5-0.5B-Chat
modelscope download --model Qwen/Qwen1.5-0.5B-Chat --local_dir ./
mkdir -p /root/autodl-tmp/demo/Qwen/Qwen1.5-1.8B-Chat
cd /root/autodl-tmp/demo/Qwen/Qwen1.5-1.8B-Chat
modelscope download --model Qwen/Qwen1.5-1.8B-Chat --local_dir ./
修改/root/autodl-tmp/opencompass/opencompass/configs/models/qwen/hf_qwen1_5_0_5b_chat.py
from opencompass.models import HuggingFacewithChatTemplate
models = [
dict(
type=HuggingFacewithChatTemplate,
abbr='qwen1.5-0.5b-chat-hf',
path='/root/autodl-tmp/demo/Qwen/Qwen1.5-0.5B-Chat',
max_out_len=1024,
batch_size=8,
run_cfg=dict(num_gpus=1),
stop_words=['<|im_end|>', '<|im_start|>'],
)
]
修改/root/autodl-tmp/opencompass/opencompass/configs/models/qwen/hf_qwen1_5_1_8b_chat.py
from opencompass.models import HuggingFacewithChatTemplate
models = [
dict(
type=HuggingFacewithChatTemplate,
abbr='qwen1.5-1.8b-chat-hf',
path='/root/autodl-tmp/demo/Qwen/Qwen1.5-1.8B-Chat',
max_out_len=1024,
batch_size=8,
run_cfg=dict(num_gpus=1),
stop_words=['<|im_end|>', '<|im_start|>'],
)
]
运行
python run.py \
--models hf_qwen1_5_0_5b_chat hf_qwen1_5_1_8b_chat \
--datasets FewCLUE_bustm_gen FewCLUE_ocnli_fc_gen \
--debug

根据评估结果,选择最终模型。评估结果/root/autodl-tmp/demo/Qwen/Qwen1.5-1.8B-Chat 效果要好
四、模型训练

二、数据集转换
- 选择模型微调工具,根据微调框架选择对应数据集格式(此处以xtuner为例,使用xtuner默认格式)
数据集转换代码
import json
def convert_format(source_data):
target_data = []
for item in source_data:
# 构建新的对话格式
new_convo = {
"conversation": [
{
"input": item["user"],
"output": f"{item['style']}\n{item['assistant']}"
}
]
}
target_data.append(new_convo)
return target_data
# 从文件读取源数据
with open("style_chat_data.json", "r", encoding="utf-8") as f:
source_data = json.load(f)
# 执行转换
converted_data = convert_format(source_data)
# 写入目标文件
with open("output.json", "w", encoding="utf-8") as f:
json.dump(converted_data, f, ensure_ascii=False, indent=2)
生成数据如下 :
[
{
"conversation": [
{
"input": "今天心情不太好",
"output": "温柔\n抱抱你啦~ 有什么不开心的事情可以跟我说说呀,我会一直陪着你呢💖"
}
]
},
{
"conversation": [
{
"input": "养猫好还是养狗好",
"output": "温柔\n这个问题呀,其实看你的生活方式啦~ 猫咪比较独立,狗狗需要更多陪伴呢。你更喜欢哪种感觉呀?🌸💖"
}
]
}
]
配置训练文件
复制 文件到
/root/autodl-tmp/demo/xtuner/xtuner/configs/qwen/qwen1_5/qwen1_5_1_8b_chat/qwen1_5_1_8b_chat_qlora_alpaca_e3.py
文件到
/root/autodl-tmp/demo/xtuner/ 目录下
cp /root/autodl-tmp/demo/xtuner/xtuner/configs/qwen/qwen1_5/qwen1_5_1_8b_chat/qwen1_5_1_8b_chat_qlora_alpaca_e3.py /root/autodl-tmp/demo/xtuner/
修改的文件内容
pretrained_model_name_or_path = "/root/autodl-tmp/demo/Qwen/Qwen1.5-1.8B-Chat"
alpaca_en_path = "/root/autodl-tmp/model/demo_16/output.json"
max_length = 512
batch_size = 30 # per_device
max_epochs = 1000
# 至少配置5条
evaluation_inputs = [
"大姨说我胖得嫁不出去,怎么毒舌反击?",
"闺蜜和我最讨厌的人逛街没叫我",
"恋爱三周年只收到‘多喝热水’短信",
"喝冰美式手抖得像帕金森,社畜的倔强",
"戴美瞳八小时,眼睛干得像撒哈拉"
]
model = dict(
...
lora=dict(
lora_alpha=128,
),
)
alpaca_en = dict(
# dataset=dict(type=load_dataset, path=alpaca_en_path),
dataset=dict(type=load_dataset, path="json",data_files=alpaca_en_path),
dataset_map_fn=None,
)
完整文件
# Copyright (c) OpenMMLab. All rights reserved.
import torch
from datasets import load_dataset
from mmengine.dataset import DefaultSampler
from mmengine.hooks import (
CheckpointHook,
DistSamplerSeedHook,
IterTimerHook,
LoggerHook,
ParamSchedulerHook,
)
from mmengine.optim import AmpOptimWrapper, CosineAnnealingLR, LinearLR
from peft import LoraConfig
from torch.optim import AdamW
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
from xtuner.dataset import process_hf_dataset
from xtuner.dataset.collate_fns import default_collate_fn
from xtuner.dataset.map_fns import alpaca_map_fn, template_map_fn_factory
from xtuner.engine.hooks import (
DatasetInfoHook,
EvaluateChatHook,
VarlenAttnArgsToMessageHubHook,
)
from xtuner.engine.runner import TrainLoop
from xtuner.model import SupervisedFinetune
from xtuner.parallel.sequence import SequenceParallelSampler
from xtuner.utils import PROMPT_TEMPLATE, SYSTEM_TEMPLATE
#######################################################################
# PART 1 Settings #
#######################################################################
# Model
pretrained_model_name_or_path = "/root/autodl-tmp/demo/Qwen/Qwen1.5-1.8B-Chat"
use_varlen_attn = False
# Data
alpaca_en_path = "/root/autodl-tmp/model/demo_16/output.json"
prompt_template = PROMPT_TEMPLATE.qwen_chat
max_length = 512
pack_to_max_length = True
# parallel
sequence_parallel_size = 1
# Scheduler & Optimizer
batch_size = 30 # per_device
accumulative_counts = 16
accumulative_counts *= sequence_parallel_size
dataloader_num_workers = 0
max_epochs = 1000
optim_type = AdamW
lr = 2e-4
betas = (0.9, 0.999)
weight_decay = 0
max_norm = 1 # grad clip
warmup_ratio = 0.03
# Save
save_steps = 500
save_total_limit = 2 # Maximum checkpoints to keep (-1 means unlimited)
# Evaluate the generation performance during the training
evaluation_freq = 500
SYSTEM = SYSTEM_TEMPLATE.alpaca
# 至少配置5条
evaluation_inputs = [
"大姨说我胖得嫁不出去,怎么毒舌反击?",
"闺蜜和我最讨厌的人逛街没叫我",
"恋爱三周年只收到‘多喝热水’短信",
"喝冰美式手抖得像帕金森,社畜的倔强",
"戴美瞳八小时,眼睛干得像撒哈拉"
]
#######################################################################
# PART 2 Model & Tokenizer #
#######################################################################
tokenizer = dict(
type=AutoTokenizer.from_pretrained,
pretrained_model_name_or_path=pretrained_model_name_or_path,
trust_remote_code=True,
padding_side="right",
)
model = dict(
type=SupervisedFinetune,
use_varlen_attn=use_varlen_attn,
llm=dict(
type=AutoModelForCausalLM.from_pretrained,
pretrained_model_name_or_path=pretrained_model_name_or_path,
trust_remote_code=True,
torch_dtype=torch.float16,
quantization_config=dict(
type=BitsAndBytesConfig,
load_in_4bit=False,
load_in_8bit=True,
llm_int8_threshold=6.0,
llm_int8_has_fp16_weight=False,
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
),
),
lora=dict(
type=LoraConfig,
r=64,
lora_alpha=128,
lora_dropout=0.1,
bias="none",
task_type="CAUSAL_LM",
),
)
#######################################################################
# PART 3 Dataset & Dataloader #
#######################################################################
alpaca_en = dict(
type=process_hf_dataset,
# dataset=dict(type=load_dataset, path=alpaca_en_path),
dataset=dict(type=load_dataset, path="json",data_files=alpaca_en_path),
tokenizer=tokenizer,
max_length=max_length,
dataset_map_fn=None,
template_map_fn=dict(type=template_map_fn_factory, template=prompt_template),
remove_unused_columns=True,
shuffle_before_pack=True,
pack_to_max_length=pack_to_max_length,
use_varlen_attn=use_varlen_attn,
)
sampler = SequenceParallelSampler if sequence_parallel_size > 1 else DefaultSampler
train_dataloader = dict(
batch_size=batch_size,
num_workers=dataloader_num_workers,
dataset=alpaca_en,
sampler=dict(type=sampler, shuffle=True),
collate_fn=dict(type=default_collate_fn, use_varlen_attn=use_varlen_attn),
)
#######################################################################
# PART 4 Scheduler & Optimizer #
#######################################################################
# optimizer
optim_wrapper = dict(
type=AmpOptimWrapper,
optimizer=dict(type=optim_type, lr=lr, betas=betas, weight_decay=weight_decay),
clip_grad=dict(max_norm=max_norm, error_if_nonfinite=False),
accumulative_counts=accumulative_counts,
loss_scale="dynamic",
dtype="float16",
)
# learning policy
# More information: https://github.com/open-mmlab/mmengine/blob/main/docs/en/tutorials/param_scheduler.md # noqa: E501
param_scheduler = [
dict(
type=LinearLR,
start_factor=1e-5,
by_epoch=True,
begin=0,
end=warmup_ratio * max_epochs,
convert_to_iter_based=True,
),
dict(
type=CosineAnnealingLR,
eta_min=0.0,
by_epoch=True,
begin=warmup_ratio * max_epochs,
end=max_epochs,
convert_to_iter_based=True,
),
]
# train, val, test setting
train_cfg = dict(type=TrainLoop, max_epochs=max_epochs)
#######################################################################
# PART 5 Runtime #
#######################################################################
# Log the dialogue periodically during the training process, optional
custom_hooks = [
dict(type=DatasetInfoHook, tokenizer=tokenizer),
dict(
type=EvaluateChatHook,
tokenizer=tokenizer,
every_n_iters=evaluation_freq,
evaluation_inputs=evaluation_inputs,
system=SYSTEM,
prompt_template=prompt_template,
),
]
if use_varlen_attn:
custom_hooks += [dict(type=VarlenAttnArgsToMessageHubHook)]
# configure default hooks
default_hooks = dict(
# record the time of every iteration.
timer=dict(type=IterTimerHook),
# print log every 10 iterations.
logger=dict(type=LoggerHook, log_metric_by_epoch=False, interval=10),
# enable the parameter scheduler.
param_scheduler=dict(type=ParamSchedulerHook),
# save checkpoint per `save_steps`.
checkpoint=dict(
type=CheckpointHook,
by_epoch=False,
interval=save_steps,
max_keep_ckpts=save_total_limit,
),
# set sampler seed in distributed evrionment.
sampler_seed=dict(type=DistSamplerSeedHook),
)
# configure environment
env_cfg = dict(
# whether to enable cudnn benchmark
cudnn_benchmark=False,
# set multi process parameters
mp_cfg=dict(mp_start_method="fork", opencv_num_threads=0),
# set distributed parameters
dist_cfg=dict(backend="nccl"),
)
# set visualizer
visualizer = None
# set log level
log_level = "INFO"
# load from which checkpoint
load_from = None
# whether to resume training from the loaded checkpoint
resume = False
# Defaults to use random seed and disable `deterministic`
randomness = dict(seed=None, deterministic=False)
# set log processor
log_processor = dict(by_epoch=False)
模型训练
#单机单卡
xtuner tra
xtuner train qwen1_5_1_8b_chat_qlora_alpaca_e3.py
#单机多卡
NPROC_PER_NODE=${GPU_NUM} xtuner train internlm2_chat_7b_qlora_oasst1_e3 --
deepspeed deepspeed_zero2
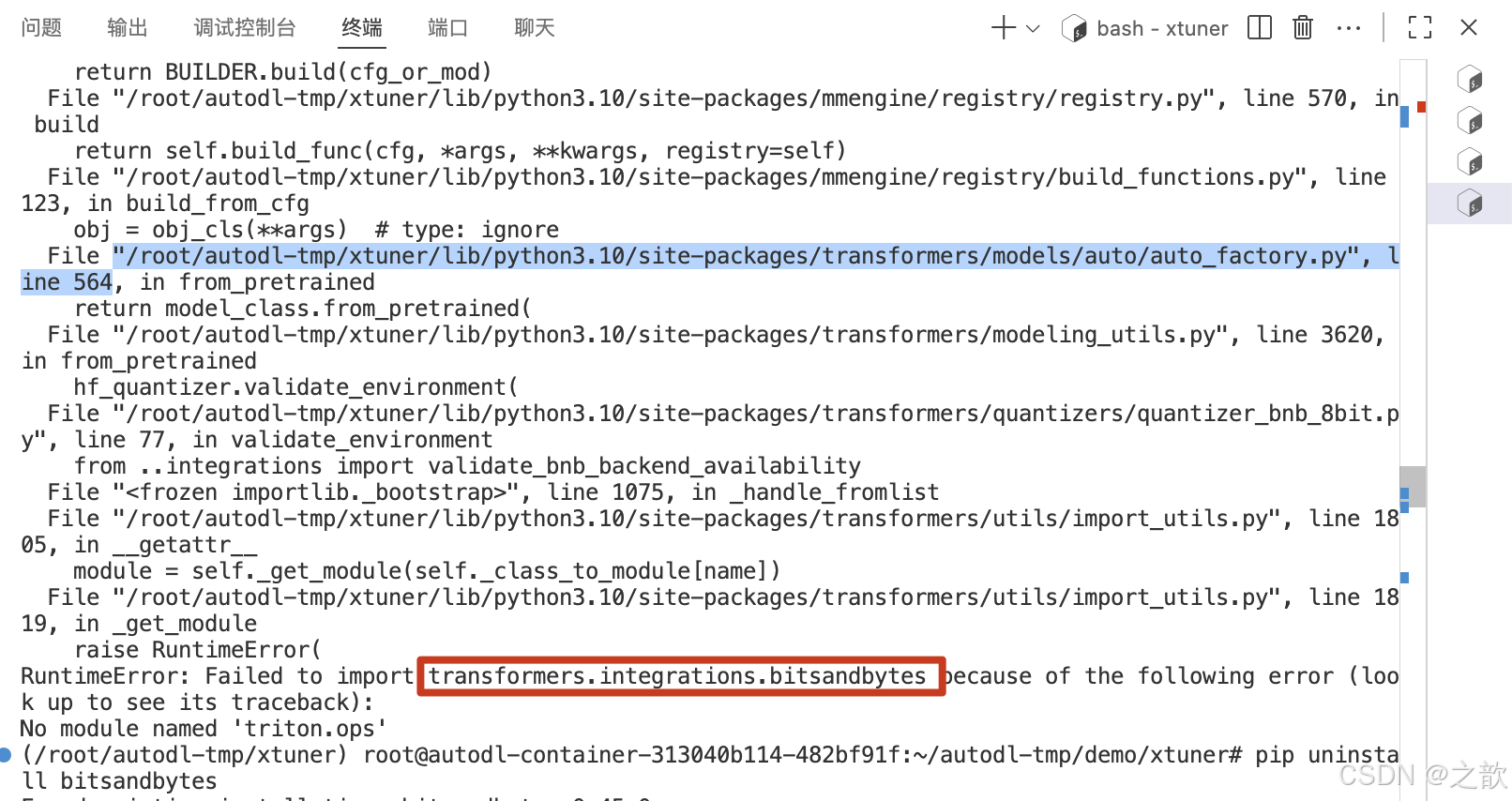
如果启动报错,则可以执行如下命令
pip uninstall bitsandbytes
pip install bitsandbytes==0.47.0
模型推理与模型训练xtuner 对话模板保证一致
找到xtuner对话模板训练文件
/root/autodl-tmp/demo/xtuner/xtuner/utils/templates.py
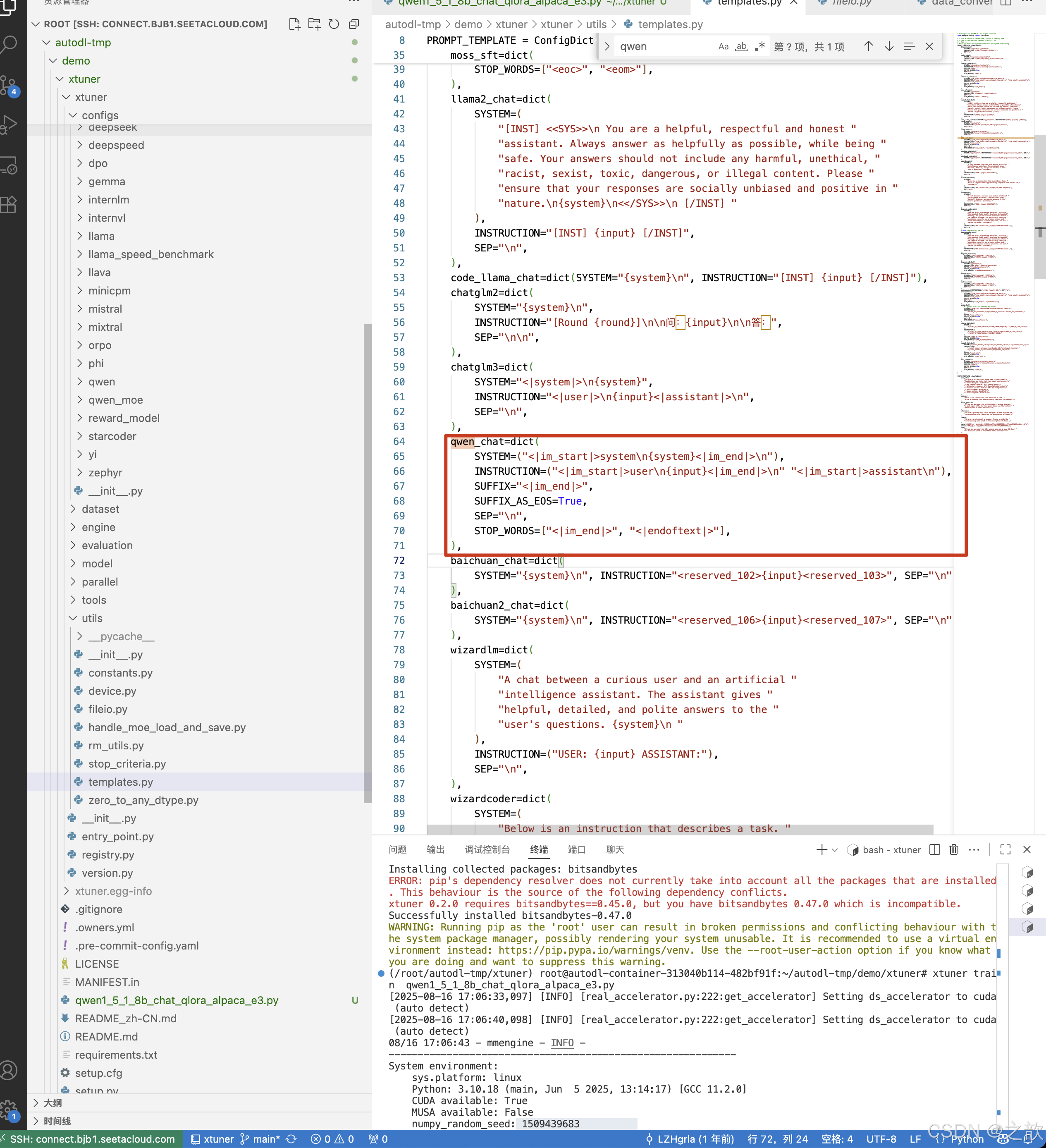
import re
import json
from typing import Dict, Any
def universal_converter(original_template: Dict[str, Any]) -> Dict[str, Any]:
"""将多种风格的原始模板转换为lmdeploy官方格式"""
# 字段映射关系(核心逻辑)
field_mapping = {
# 基础字段映射
"SYSTEM": "system",
"INSTRUCTION": ("user", "assistant"), # 需要拆分处理
"SUFFIX": "eoa",
"SEP": "separator",
"STOP_WORDS": "stop_words",
# 特殊处理字段
"SUFFIX_AS_EOS": None, # 该字段在官方模板中不需要
}
# 初始化目标模板(包含必填字段默认值)
converted = {
"meta_instruction": "You are a helpful assistant.", # 必填项
"capability": "chat", # 必填项
"eosys": "<|im_end|>\n", # 通常固定格式
"eoh": "<|im_end|>\n", # 通常固定格式
}
# 自动处理字段映射
for src_key, dest_key in field_mapping.items():
if src_key in original_template:
value = original_template[src_key]
# 处理需要拆分的字段(如INSTRUCTION)
if isinstance(dest_key, tuple) and src_key == "INSTRUCTION":
# 使用正则拆分user和assistant部分
parts = re.split(r'(<\|im_start\|>assistant\n?)', value)
converted["user"] = parts[0].strip()
if len(parts) > 1:
converted["assistant"] = parts[1] + parts[2] if len(parts) > 2 else parts[1]
# 处理直接映射字段
elif dest_key and not isinstance(dest_key, tuple):
converted[dest_key] = value
# 特殊处理system字段的占位符
if "system" in converted:
converted["system"] = converted["system"].replace("{system}", "{{ system }}")
# 处理用户输入占位符
if "user" in converted:
converted["user"] = converted["user"].replace("{input}", "{{ input }}")
# 自动处理停止词(兼容列表和字符串)
if "stop_words" in converted and isinstance(converted["stop_words"], str):
converted["stop_words"] = [converted["stop_words"]]
# 保留原始模板中的额外字段(带警告)
for key in original_template:
if key not in field_mapping:
print(f"Warning: 发现未映射字段 [{key}],已保留原样")
converted[key] = original_template[key]
return converted
# 示例用法
original_qwen_chat = dict(
SYSTEM=("<|im_start|>system\n{system}<|im_end|>\n"),
INSTRUCTION=("<|im_start|>user\n{input}<|im_end|>\n" "<|im_start|>assistant\n"),
SUFFIX="<|im_end|>",
SUFFIX_AS_EOS=True,
SEP="\n",
STOP_WORDS=["<|im_end|>", "<|endoftext|>"]
)
# 执行转换
converted_template = universal_converter(original_qwen_chat)
# 生成JSON文件
with open('chat_template.json', 'w') as f:
json.dump(converted_template, f,
indent=2,
ensure_ascii=False,
separators=(',', ': '))
输出:
{
"meta_instruction": "You are a helpful assistant.",
"capability": "chat",
"eosys": "<|im_end|>\n",
"eoh": "<|im_end|>\n",
"system": "<|im_start|>system\n{{ system }}<|im_end|>\n",
"user": "<|im_start|>user\n{{ input }}<|im_end|>",
"assistant": "<|im_start|>assistant\n",
"eoa": "<|im_end|>",
"separator": "\n",
"stop_words": [
"<|im_end|>",
"<|endoftext|>"
]
}
模型转换
模型训练后会自动保存成 PTH 模型(例如 iter_2000.pth,如果使用了 DeepSpeed,则将会是一个文件夹),我们需要利用 xtuner convert pth_to_hf 将其转换为 HuggingFace 模型,以便于后续使用。具体命令为:
xtuner convert pth_to_hf ${FINETUNE_CFG} ${PTH_PATH} ${SAVE_PATH}
# 例如:xtuner convert pth_to_hf internlm2_chat_7b_qlora_custom_sft_e1_copy.py
./iter_2000.pth ./iter_2000_
具体脚本
xtuner convert pth_to_hf /root/autodl-tmp/demo/xtuner/qwen1_5_1_8b_chat_qlora_alpaca_e3.py /root/autodl-tmp/demo/xtuner/work_dirs/qwen1_5_1_8b_chat_qlora_alpaca_e3/iter_500.pth /root/autodl-tmp/demo/Qwen/Qwen1.5-1.8B-Chat-train
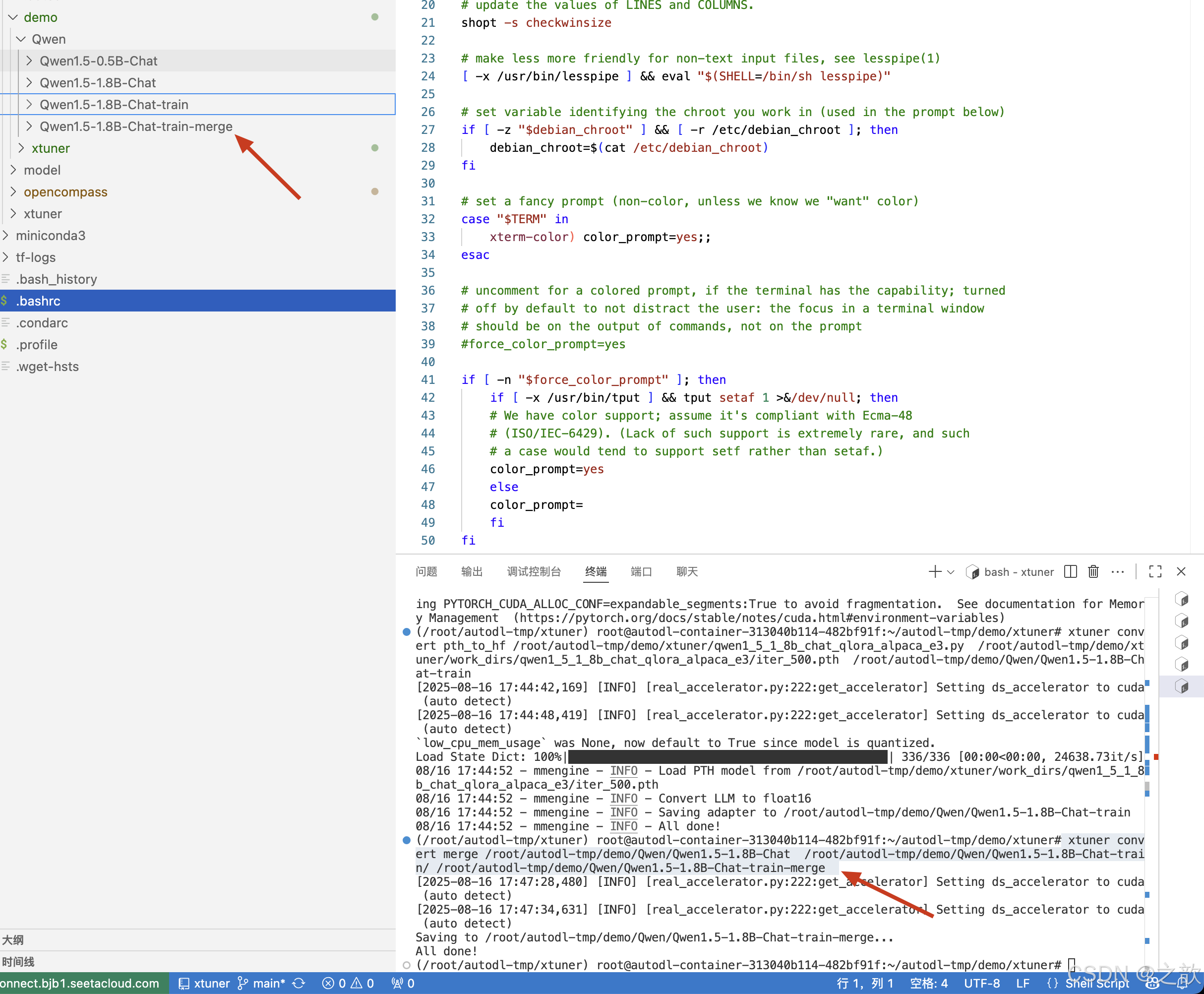
模型合并
如果使用了 LoRA / QLoRA 微调,则模型转换后将得到 adapter 参数,而并不包含原 LLM 参数。如果您
期望获得合并后的模型权重(例如用于后续评测),那么可以利用 xtuner convert merge :
$ xtuner convert merge /root/autodl-tmp/demo/Qwen/Qwen1.5-1.8B-Chat /root/autodl-tmp/demo/Qwen/Qwen1.5-1.8B-Chat-train/ /root/autodl-tmp/demo/Qwen/Qwen1.5-1.8B-Chat-train-merge
创建Imdeploy隔离环境
conda create -n lmdeploy python=3.10 -y
激活环境
conda activate lmdeploy
安装lmdeploy
pip install lmdeploy
启动
lmdeploy serve api_server /root/autodl-tmp/demo/Qwen/Qwen1.5-1.8B-Chat-train-merge
或
lmdeploy serve api_server /root/autodl-tmp/demo/Qwen/Qwen1.5-1.8B-Chat-train-merge --chat-template /root/autodl-tmp/chat.json
运行
#多轮对话
from openai import OpenAI
#定义多轮对话方法
def run_chat_session():
#初始化客户端
client = OpenAI(base_url="http://localhost:23333/v1/",api_key="suibianxie")
#初始化对话历史
chat_history = []
#启动对话循环
while True:
#获取用户输入
user_input = input("用户:")
if user_input.lower() == "exit":
print("退出对话。")
break
#更新对话历史(添加用户输入)
chat_history.append({"role":"user","content":user_input})
#调用模型回答
try:
chat_complition = client.chat.completions.create(messages=chat_history,model="/root/autodl-tmp/demo/Qwen/Qwen1.5-1.8B-Chat-train-merge")
#获取最新回答
model_response = chat_complition.choices[0]
print("AI:",model_response.message.content)
#更新对话历史(添加AI模型的回复)
chat_history.append({"role":"assistant","content":model_response.message.content})
except Exception as e:
print("发生错误:",e)
break
if __name__ == '__main__':
run_chat_session()

模型推理部署
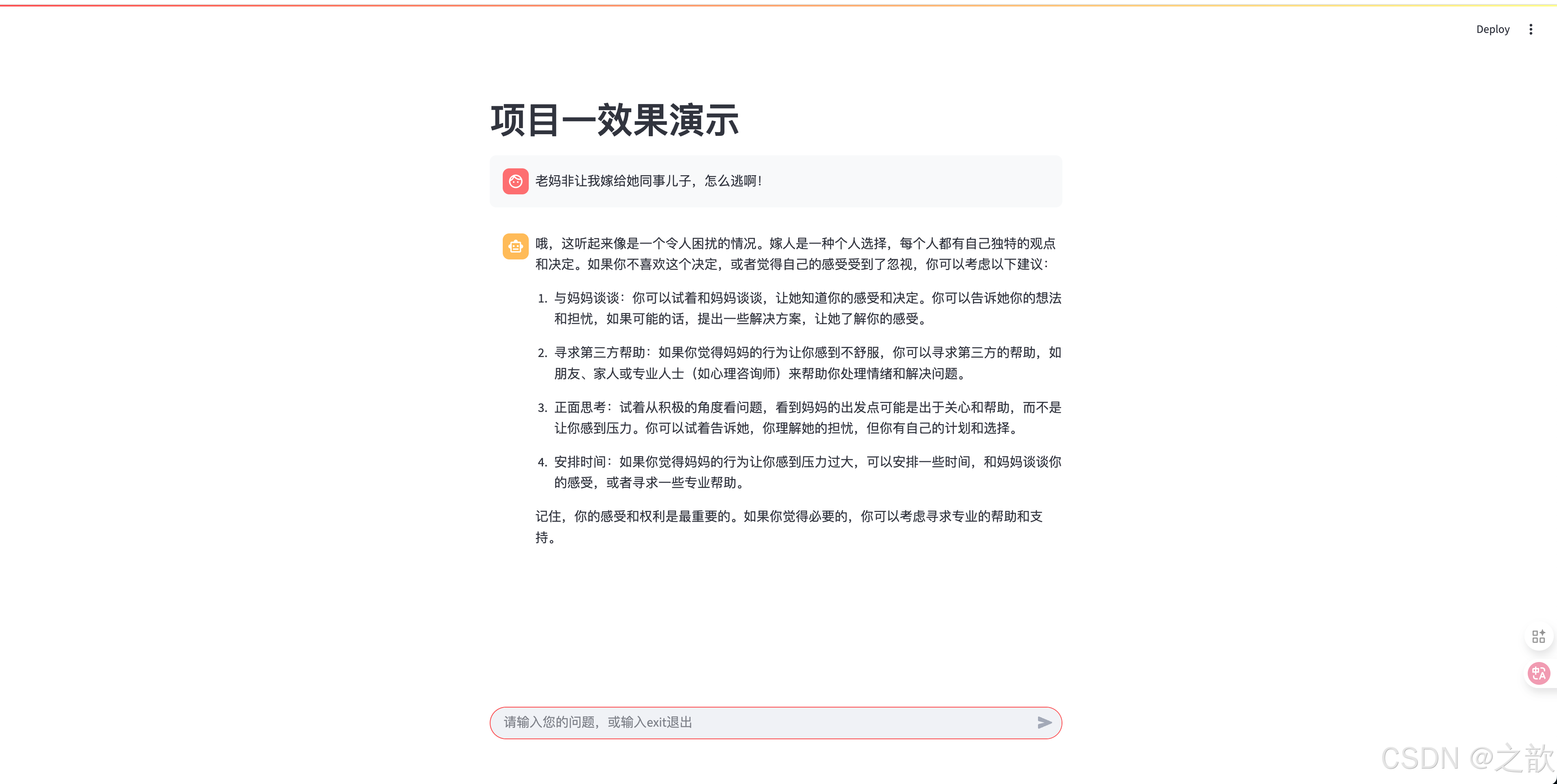
用streamlit来做简单的前端界面,但是需要写一个 chat_app.py 文件, chat_app.py文件内容如下 。
chat_app.py
import streamlit as st
from openai import OpenAI
# 初始化客户端
client = OpenAI(base_url="http://localhost:23333/v1/", api_key="suibianxie")
# 设置页面标题
st.title("项目一效果演示")
# 初始化session状态(仅用于显示历史)
if "messages" not in st.session_state:
st.session_state.messages = []
# 显示历史消息
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
# 获取用户输入
if prompt := st.chat_input("请输入您的问题,或输入exit退出"):
# 处理退出命令
if prompt.lower() == "exit":
st.info("退出对话。")
st.stop()
# 添加用户消息到显示历史
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.markdown(prompt)
try:
# 发起API请求(每次只发送当前消息)
response = client.chat.completions.create(
messages=[{"role": "user", "content": prompt}], # 每次只发送当前问题
model="/home/cw/llms/Qwen/Qwen1.5-1.8B-Chat-merged"
)
# 获取模型回复
model_response = response.choices[0].message.content
# 添加AI回复到显示历史
st.session_state.messages.append({"role": "assistant", "content": model_response})
with st.chat_message("assistant"):
st.markdown(model_response)
except Exception as e:
st.error(f"发生错误:{e}")
pip install streamlit # 安装streamlit
streamlit run chat_app.py
使用下面命令启动streamlit web前端,测试最终效果:

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 14
14 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)