(AAAI 2025)多模态检索卷疯了,不知道怎么入手?这几个idea直接拿去
多模态正成为AI科研的前沿方向,它通过融合视觉、语言、语音等多源信息,打破单一模态的局限,推动模型更接近人类智能。近年来,从基础大模型到跨模态应用,多模态已成为顶会热点。而在市场层面,无论是智能医疗、自动驾驶还是人机交互,企业都在加速布局,产业价值潜力巨大,未来或将引领新一轮AI革命。
关注gongzhonghao【计算机sci论文精选】
多模态正成为AI科研的前沿方向,它通过融合视觉、语言、语音等多源信息,打破单一模态的局限,推动模型更接近人类智能。近年来,从基础大模型到跨模态应用,多模态已成为顶会热点。而在市场层面,无论是智能医疗、自动驾驶还是人机交互,企业都在加速布局,产业价值潜力巨大,未来或将引领新一轮AI革命。
今天小图给大家精选3篇AAAI有关多模态方向的论文,请注意查收!
论文一:Multimodal Variational Autoencoder: A Barycentric View
方法:
文章首先提出将多模态数据的联合分布建模为各模态编码分布的Wasserstein barycenter,通过最优传输方法寻找最能代表所有模态的“中心”分布。随后,作者设计了一种新的损失函数,结合重建误差与Wasserstein距离最小化,使得模型能够在不同模态间高效共享潜变量信息并减少模态偏差。最后,整套方法通过端到端训练,支持任意模态的输入与缺失模态的重建,有效提升了跨模态生成与表征一致性的能力,为多模态学习带来了更强的理论解释和实用表现。
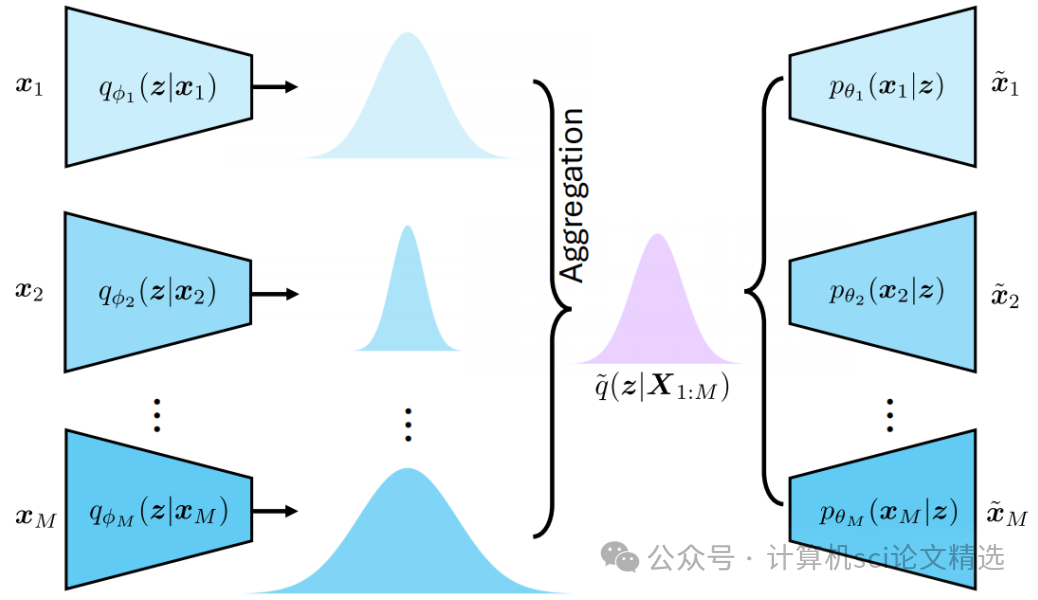
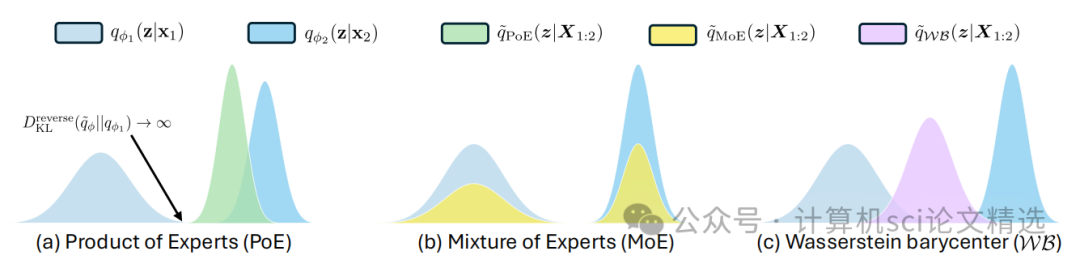
创新点:
-
首次将barycenter理论引入多模态VAE,通过最优传输理论实现不同模态分布的高效对齐。
-
利用Wasserstein距离衡量和优化各模态间的联合分布,提高表示空间的一致性和鲁棒性。
-
在多模态生成与推断任务中,系统性地展示了新方法在多项基准数据集上的优越性能,超越了传统VAE及其变体。
论文链接:
https://doi.org/10.1609/aaai.v39i19.34209
图灵学术论文辅导
论文二:PM-INR: Prior-Rich Multi-Modal Implicit Large-Scale Scene Neural Representation.
方法:
作者首先构建了多模态输入通道,将图像、深度图和语义标签等多源信息通过融合模块进行统一编码,形成丰富的场景先验。接着,他们利用隐式神经表示网络,以高维潜变量表征场景,实现对任意视角的细致合成。最后,通过端到端训练优化整体系统,使模型能够在大规模室外环境下自适应多模态信息,从而生成高质量、多样性的场景视图,兼顾细节和全局一致性。
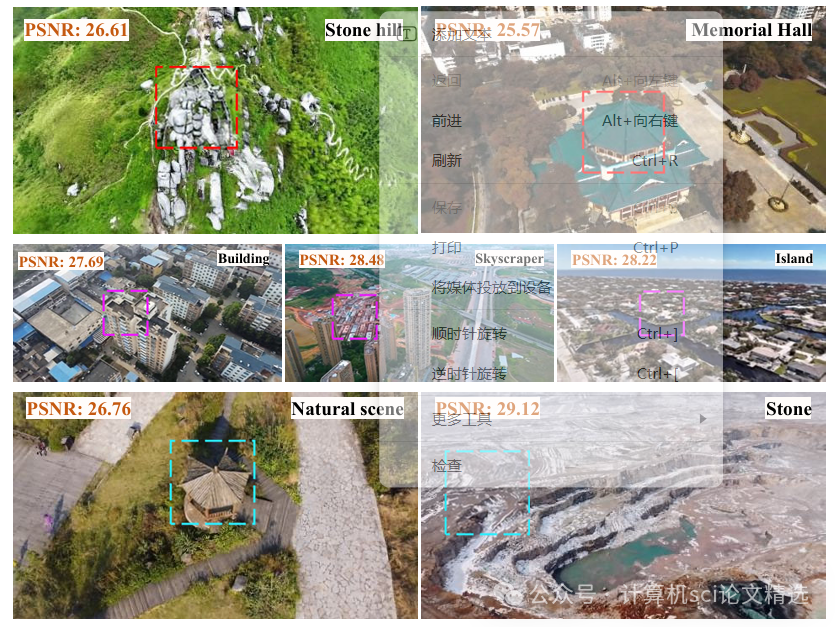
创新点:
-
创新性地设计了多模态先验融合模块,实现了来自不同感知源的信息统一集成。
-
提出了隐式神经表示结构,使模型能够灵活适应大规模场景的复杂几何与光照变化。
-
在多项公开数据集上实证优于主流方法,特别在视图合成的细节表现与泛化能力方面取得了显著提升。

论文链接:
https://doi.org/10.1609/aaai.v38i7.28481
图灵学术论文辅导
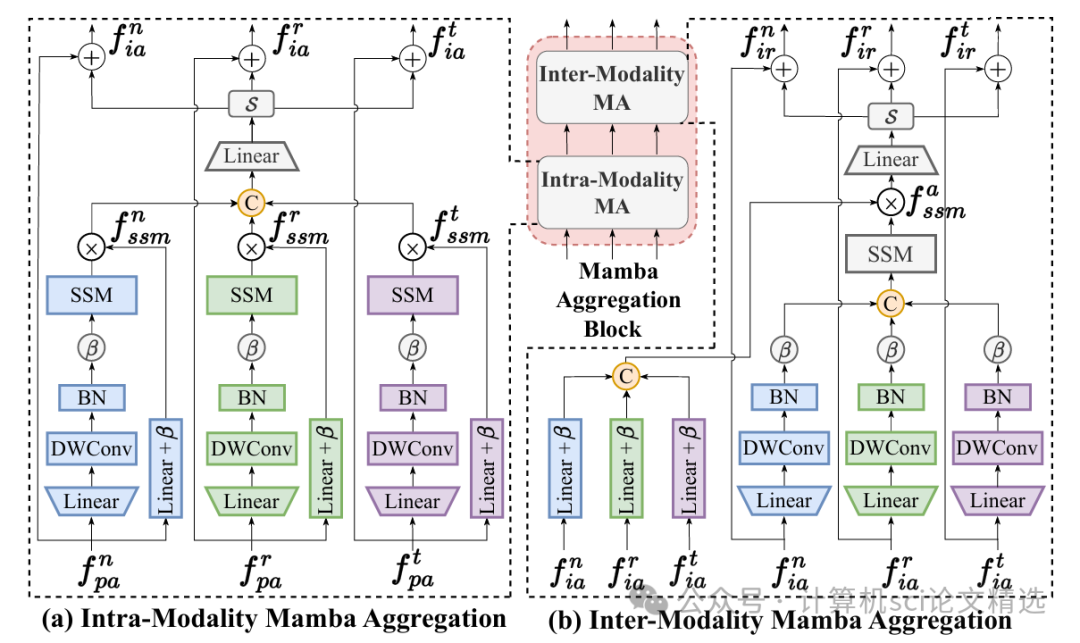
论文三:MambaPro: Multi-Modal Object Re-identification with Mamba Aggregation and Synergistic Prompt
方法:
作者设计的MambaPro框架首先利用PFA模块对来自不同模态的视觉和语义特征进行深度聚合,实现信息互补与冗余剔除的平衡。随后,SRP机制自适应地为不同输入生成提示信号,引导模型关注关键模态和时序片段,从而缓解模态间的异质性和信息不均的问题。整体系统通过端到端训练,能够高效处理长序列数据,并在多项主流数据集上实现了对比方法难以达到的高精度重识别效果。
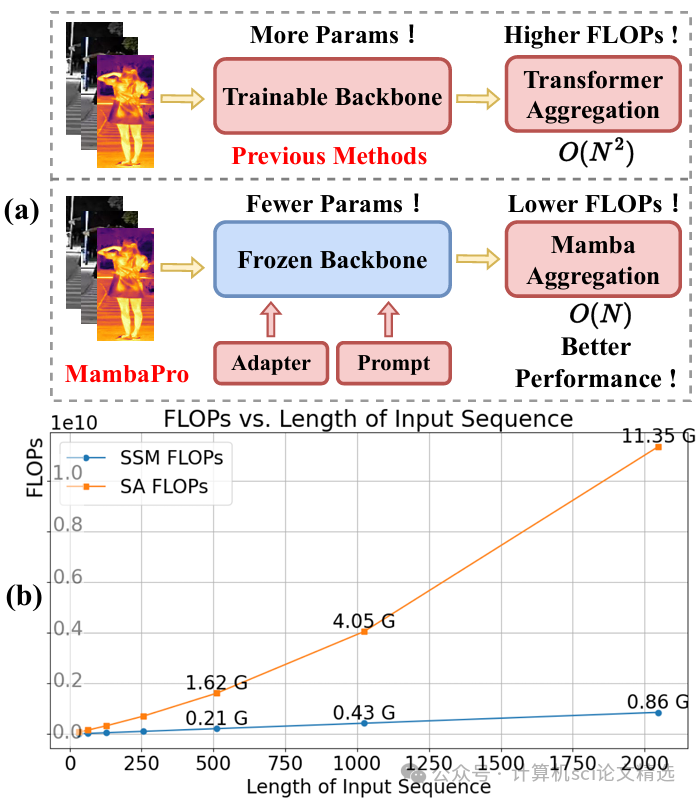
创新点:
-
首次引入Mamba聚合机制,实现各模态信息的高效融合,极大增强了跨模态特征表达能力。
-
提出了协同提示机制,动态适应不同场景和模态间语义偏差,提升模型泛化能力。
-
实验设计了专门针对长序列处理的结构,有效捕捉时序依赖,显著优于现有多模态重识别方法。
论文链接:
https://doi.org/10.1609/aaai.v39i8.32879
本文选自gongzhonghao【计算机sci论文精选】

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 14
14 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)