荣登CVPR 2025:卷王必看,多模态融合轻松收割高分
多模态融合正迎来技术与应用的双重爆发,从视觉+语言到语音+传感器,各种模态的组合不断涌现新玩法。随着跨模态对齐、轻量化建模和任务协同优化等方法的快速演进,学术界不断刷新SOTA,产业界也在医疗、自动驾驶、AIGC等场景大规模落地。CVPR 2025的赛场上,这一领域无疑将继续成为焦点,谁能抓住下一个突破口,谁就能定义多模态的未来。
关注gongzhonghao【CVPR顶会精选】
多模态融合正迎来技术与应用的双重爆发,从视觉+语言到语音+传感器,各种模态的组合不断涌现新玩法。随着跨模态对齐、轻量化建模和任务协同优化等方法的快速演进,学术界不断刷新SOTA,产业界也在医疗、自动驾驶、AIGC等场景大规模落地。CVPR 2025的赛场上,这一领域无疑将继续成为焦点,谁能抓住下一个突破口,谁就能定义多模态的未来。
今天小图给大家精选3篇CVPR有关多模态方向的论文,快来抓住多模态的风口!
论文一:DTOS: Dynamic Time Object Sensing with Large Multimodal Model
方法:
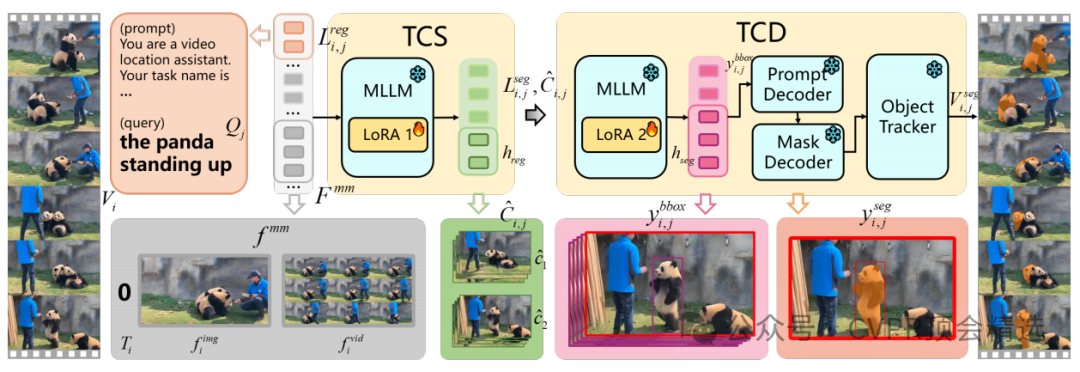
文章首先将任务分解为视频片段采样和目标分割两个子任务,分别由文本引导的片段采样器和文本引导的片段检测器完成。TCS通过特殊标记生成候选片段,TCD则在这些片段中精确定位目标并生成分割掩码。此外,文章还设计了多模态输入序列,通过图像网格压缩技术平衡空间细节和时间效率,进一步提升了模型的性能。

创新点:
-
引入特殊标记构建多答案响应模板,解决了多模态大语言模型在处理时空引用时的重复退化问题,提升了数值回归的准确性。
-
提出文本引导的片段采样器,根据用户指令选择与之对齐的视频片段,避免了视频采样查询中视觉信息的丢失,确保了时间分辨率的一致性。
-
首次采用特殊标记实现多目标时空定位,通过解码隐藏状态回归事件边界和目标检测框坐标,有效解决了多引用问题。
论文链接:
https://cvpr.thecvf.com/virtual/2025/poster/32970
图灵学术论文辅导
论文二:M3GYM: A Large-Scale Multimodal Multi-view Multi-person Pose Dataset for Fitness Activity Understanding in Real-world Settings
方法:
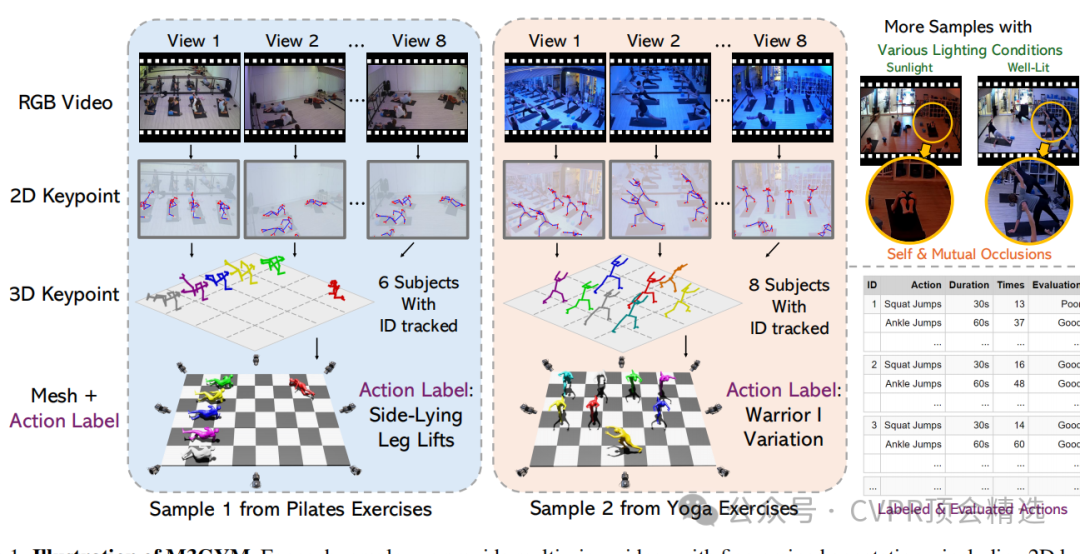
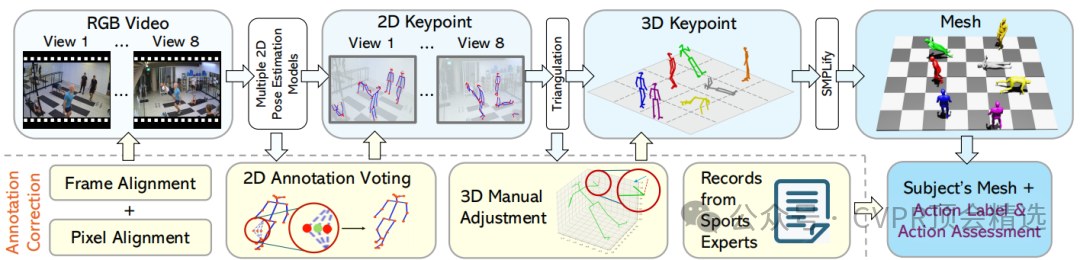
文章首先在真实健身房环境中布置8个摄像头,采集了涵盖多种健身活动的多视角视频数据;接着通过半自动标注流程,对视频进行帧对齐、关键点检测、三维重建和手动校验,生成高质量的标注数据;最后在数据集上进行了多种人体姿态估计任务的基准测试,验证了数据集对模型泛化能力的提升效果。
创新点:
-
构建了一个涵盖真实健身房场景的大规模数据集,填补了现有数据集在真实健身场景中的空白。
-
提供了多视角视频和精细标注,为多视角人体姿态估计提供了丰富的数据支持。
-
设计了半自动标注流程,确保了标注的准确性和高效性,为高质量数据集的构建奠定了基础。
论文链接:
https://cvpr.thecvf.com/virtual/2025/poster/32762
图灵学术论文辅导
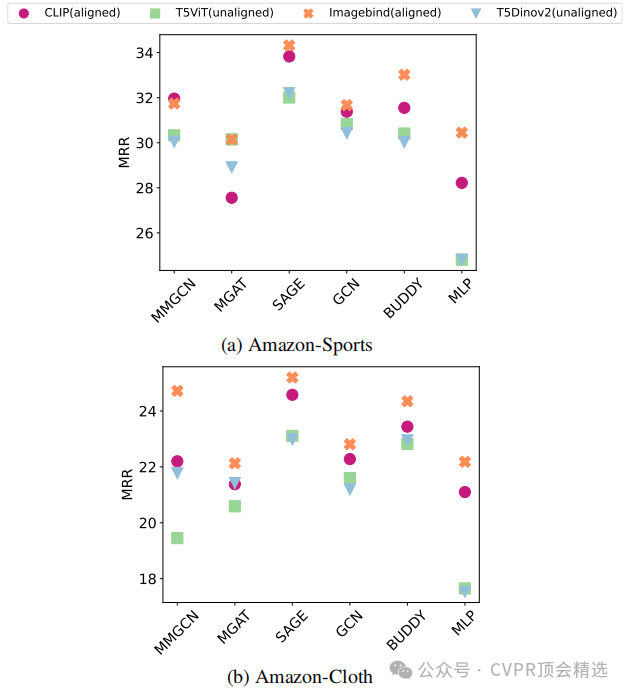
论文三:Mosaic of Modalities: A Comprehensive Benchmark for Multimodal Graph Learning
方法:
文章首先精心设计了七个具有不同规模和任务的多模态图数据集,涵盖了从数千到数百万边的范围,为多模态图学习提供了多样化的实验基础;接着标准化了多种图神经网络和知识图谱嵌入方法,并结合先进的特征编码器,探索了多模态特征在图学习中的融合方式;最后通过广泛的实验分析,验证了多模态特征相较于单模态特征在提升图学习性能方面的显著优势,为该领域的研究提供了宝贵的实证支持。
创新点:
-
首次构建了一个涵盖多种模态信息的图学习基准,为多模态图学习提供了丰富的实验场景。
-
提供了标准化GNN架构、KGE方法、特征编码器、数据加载器和评估器,确保了不同方法在多模态图数据上的公平比较,为研究者提供了一个统一的评估平台。
-
深入分析了不同特征编码策略在多模态图学习中的表现,为未来多模态图学习模型的设计提供了重要参考。
论文链接:
https://cvpr.thecvf.com/virtual/2025/poster/33008
本文选自gongzhonghao【CVPR顶会精选】

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 22
22 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)